
IRQ
IRQ全称为Interrupt Request,即是“中断请求”的意思,也就是硬件设备请求CPU处理自己的发送的事件。
为了防止不同的硬件使用相同的中断信号,Linux设计了一套中断请求系统, 使得计算机系统中的每个设备被分配了各自的中断号(IRQ), 以确保此设备的中断请求的唯一性.
可以使用 cat /proc/interrupts 查看
cat /proc/interrupts
CPU0 CPU1
0: 126 0 IO-APIC 2-edge timer
1: 9 0 IO-APIC 1-edge i8042
4: 713 0 IO-APIC 4-edge ttyS0
6: 0 3 IO-APIC 6-edge floppy
8: 0 0 IO-APIC 8-edge rtc0
9: 0 0 IO-APIC 9-fasteoi acpi
11: 333 0 IO-APIC 11-fasteoi virtio3, uhci_hcd:usb1, virtio2
12: 0 15 IO-APIC 12-edge i8042
14: 595822 0 IO-APIC 14-edge ata_piix
15: 0 0 IO-APIC 15-edge ata_piix
24: 0 0 PCI-MSI 98304-edge virtio1-config
25: 0 7122754 PCI-MSI 98305-edge virtio1-req.0
26: 0 0 PCI-MSI 81920-edge virtio0-config
27: 1533623 0 PCI-MSI 81921-edge virtio0-input.0
28: 1664631 2 PCI-MSI 81922-edge virtio0-output.0
29: 1 930580 PCI-MSI 81923-edge virtio0-input.1
30: 0 1093273 PCI-MSI 81924-edge virtio0-output.1
NMI: 0 0 Non-maskable interrupts
LOC: 799294397 801656038 Local timer interrupts
SPU: 0 0 Spurious interrupts
PMI: 0 0 Performance monitoring interrupts
IWI: 0 0 IRQ work interrupts
RTR: 0 0 APIC ICR read retries
RES: 336497157 335041691 Rescheduling interrupts
CAL: 22347354 22273263 Function call interrupts
TLB: 49839188 49730697 TLB shootdowns
TRM: 0 0 Thermal event interrupts
THR: 0 0 Threshold APIC interrupts
DFR: 0 0 Deferred Error APIC interrupts
MCE: 0 0 Machine check exceptions
MCP: 1861 1861 Machine check polls
ERR: 0
MIS: 0
PIN: 0 0 Posted-interrupt notification event
NPI: 0 0 Nested posted-interrupt event
PIW: 0 0 Posted-interrupt wakeup event
输出的第一列就是 IRQ 号
相关命令
cat /proc/interrupts # 查看硬中断
ls /proc/irq # 此目录存放了所有interrupts中的irq编号对应的目录
0 1 10 11 12 13 14 15 2 24 25 26 27 28 29 3 30 4 5 6 7 8 9 default_smp_affinity
# default_smp_affinity 此目录的此文件指定了默认如何使用哪颗cpu核心
cd /proc/irq/27
ls
affinity_hint effective_affinity effective_affinity_list node smp_affinity smp_affinity_list spurious virtio0-input.0
cat smp_affinity
1 # 存放的是一个位掩码bit,使用16进制表示此irq使用哪颗cpu。
cat smp_affinity_list
0 # 与不带list的功能类似。但是使用的是十进制进行表示使用个cpu,所以可读性更好些。
SMP IRQ affinity
从2.4 内核(2001年)开始, Linux改进了分配特定中断到指定的处理器(或处理器组)的功能. 这被称为SMP IRQ affinity, 它可以控制系统如何响应各种硬件事件. 允许你限制或者重新分配服务器的工作负载, 从而让服务器更有效的工作. 以网卡中断为例,在没有设置SMP IRQ affinity时, 所有网卡中断都关联到CPU0, 这导致了CPU0负载过高,而无法有效快速的处理网络数据包,导致了瓶颈。 通过SMP IRQ affinity技术, 把网卡多个中断分配到多个CPU上,可以分散CPU压力,提高数据处理速度。
RSS 与 RPS 的关系图
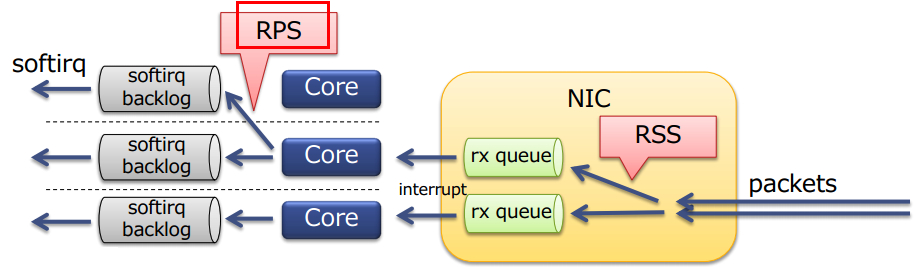
RSS
RSS(接收端调整),也叫多队列接收,是通过一些基于硬件的接收队列来分配网络接收进程,从而使入站网络流量可以由多个 CPU 进行处理。RSS 可以用来缓解接收中断进程中由于单个 CPU 过载而出现的瓶颈,并减少网络延迟。
要确定您的网络接口卡是否支持 RSS,须查看多个中断请求队列是否在 /proc/interrupts 中有相关的接口。例如,如果用户对 virtio0 接口有兴趣:
cat /proc/interrupts | grep virtio0
26: 0 0 PCI-MSI 81920-edge virtio0-config
27: 1534386 1 PCI-MSI 81921-edge virtio0-input.0
28: 1 0 PCI-MSI 81922-edge virtio0-output.0
29: 0 1807081 PCI-MSI 81923-edge virtio0-input.1
30: 1 0 PCI-MSI 81924-edge virtio0-output.1
或者可以直接查看网卡中断号
lspci # 查看网卡 PCI 地址
00:05.0 Ethernet controller: Red Hat, Inc. Virtio network device
# 列出网卡设备的中断请求
ls /sys/devices/pci0000\:00/0000\:00\:05.0/msi_irqs/
26 27 28 29 30
RSS 是默认启用的。RSS 的队列数(或是需要运行网络活动的 CPU )会由适当的网络驱动程序来进行配置。
也可以手动配置,关闭 irqbalance,然后参考 CPU 位图章节配置。
RPS 与 RFS
RPS 全称是 Receive Packet Steering, 这是Google工程师 Tom Herbert (therbert@google.com )提交的内核补丁, 在2.6.35进入Linux内核. 这个patch采用软件模拟的方式,实现了多队列网卡所提供的功能,分散了在多CPU系统上数据接收时的负载, 把软中断分到各个CPU处理,而不需要硬件支持,大大提高了网络性能。
RFS 全称是 Receive Flow Steering, 这也是Tom提交的内核补丁,它是用来配合RPS补丁使用的,是RPS补丁的扩展补丁,它把接收的数据包送达应用所在的CPU上,提高cache的命中率。
这两个补丁往往都是一起设置,来达到最好的优化效果, 主要是针对单队列网卡多CPU环境(多队列多重中断的网卡也可以使用该补丁的功能,但多队列多重中断网卡有更好的选择:SMP IRQ affinity)
RPS(接收端包控制)与 RSS类似,用于将数据包指派至特定的 CPU 进行处理。但是,RPS 是在软件级别上执行的,这有助于防止单个网络接口卡的软件队列成为网络流量中的瓶颈。
较之于基于硬件的 RSS ,RPS 有几个优点:
- RPS 可以用于任何网络接口卡。
- 易于添加软件过滤器至 RPS 来处理新的协议。
- RPS 不会增加网络设备的硬件中断率。但是会引起内处理器间的中断。
RPS (Receive Packet Steering,接收包控制,接收包引导)是 RSS 的一种软件实现。因为是软件实现的,意味着任何网卡都可以使用这个功能,即便是那些只有一个接收队列的网卡。但是,因为它是软件实现的,这意味着 RPS 只能在 packet 通过 DMA 进入内存后,RPS 才能开始工作。
这意味着,RPS 并不会减少 CPU 处理硬件中断和 NAPI poll(软中断最重要的一部分)的时间,但是可以在 packet 到达内存后,将 packet 分到其他 CPU,从其他 CPU 进入协议栈。
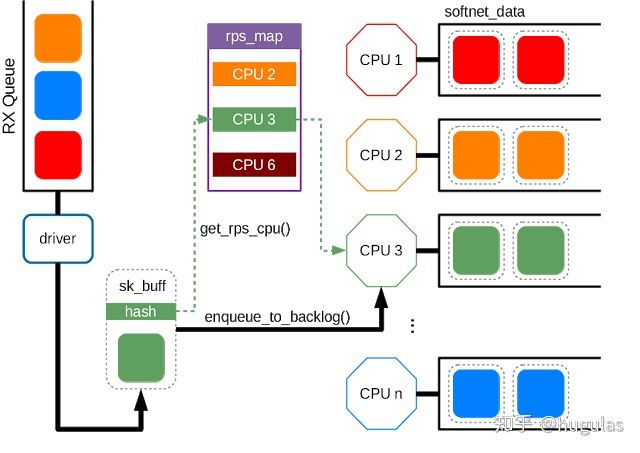
原理
RPS: RPS实现了数据流的hash归类,并把软中断的负载均衡分到各个cpu,实现了类似多队列网卡的功能。由于RPS只是单纯的把同一流的数据包分发给同一个CPU核来处理了,但是有可能出现这样的情况,即给该数据流分发的CPU核和执行处理该数据流的应用程序的CPU核不是同一个:数据包均衡到不同的cpu,这个时候如果应用程序所在的cpu和软中断处理的cpu不是同一个,此时对于cpu cache的影响会很大。那么RFS补丁就是用来确保应用程序处理的cpu跟软中断处理的cpu是同一个,这样就充分利用cpu的cache。
=>应用RPS之前: 所有数据流被分到某个CPU, 多CPU没有被合理利用, 造成瓶颈
=>应用RPS之后: 同一流的数据包被分到同个CPU核来处理,但可能出现cpu cache迁跃
=>应用RPS+RFS之后: 同一流的数据包被分到应用所在的CPU核
RPS 原理图
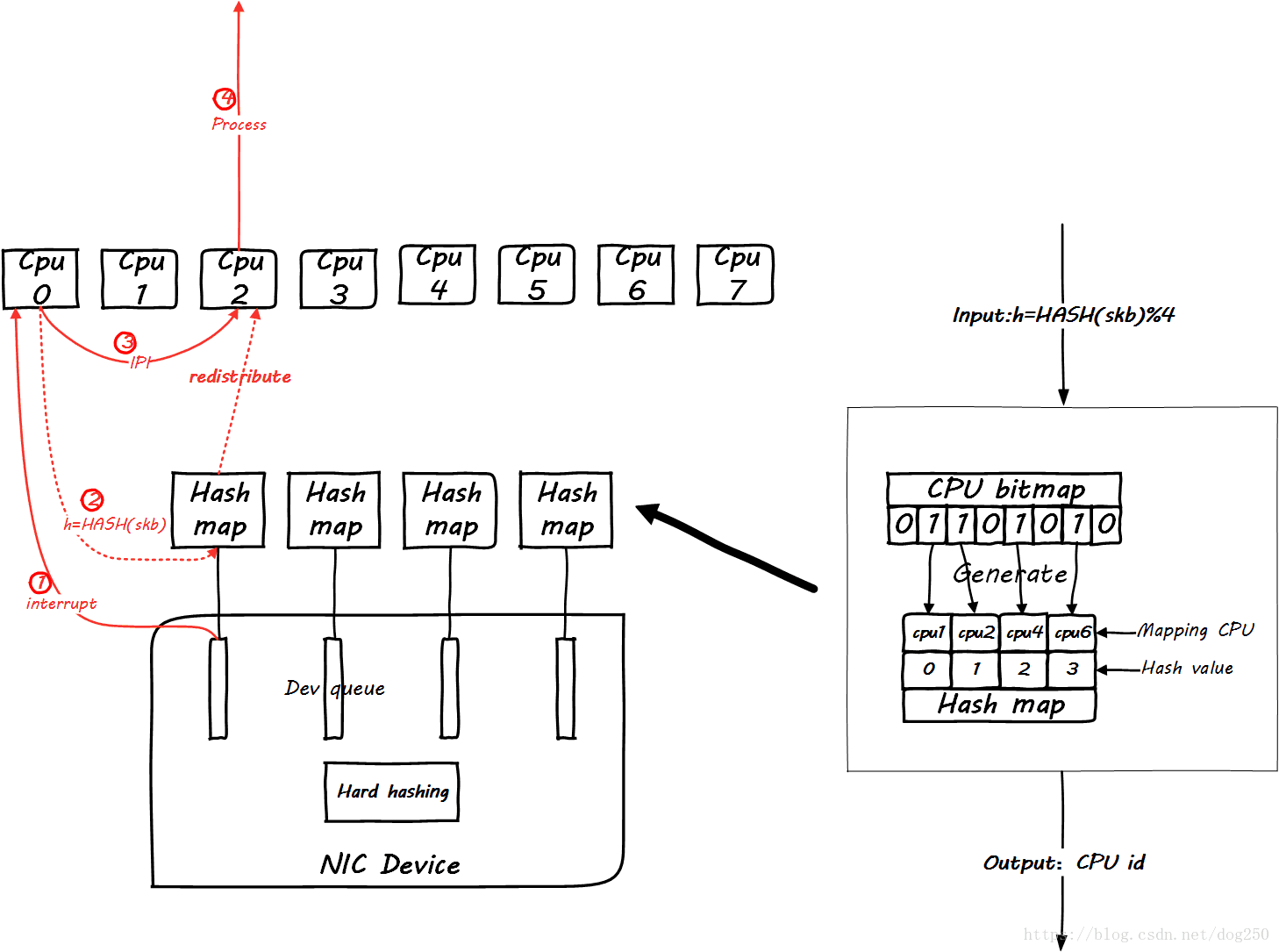
其实就是一个软件对CPU负载重分发的机制。其使能的作用点在CPU开始处理软中断的开始,即下面的地方:
netif_rx_internal
netif_receive_skb_internal
RFS 原理图
RFS在RPS的基础上,充分考虑到同一个五元组flow进程上下文和软中断上下文之间处理CPU的一致性,为此在socket层面也要有相应的处理。
非常遗憾的是,一张图无法把这一切全部表达,那么我们分阶段进行,首先看同一个五元组flow第一个包到达的情形:
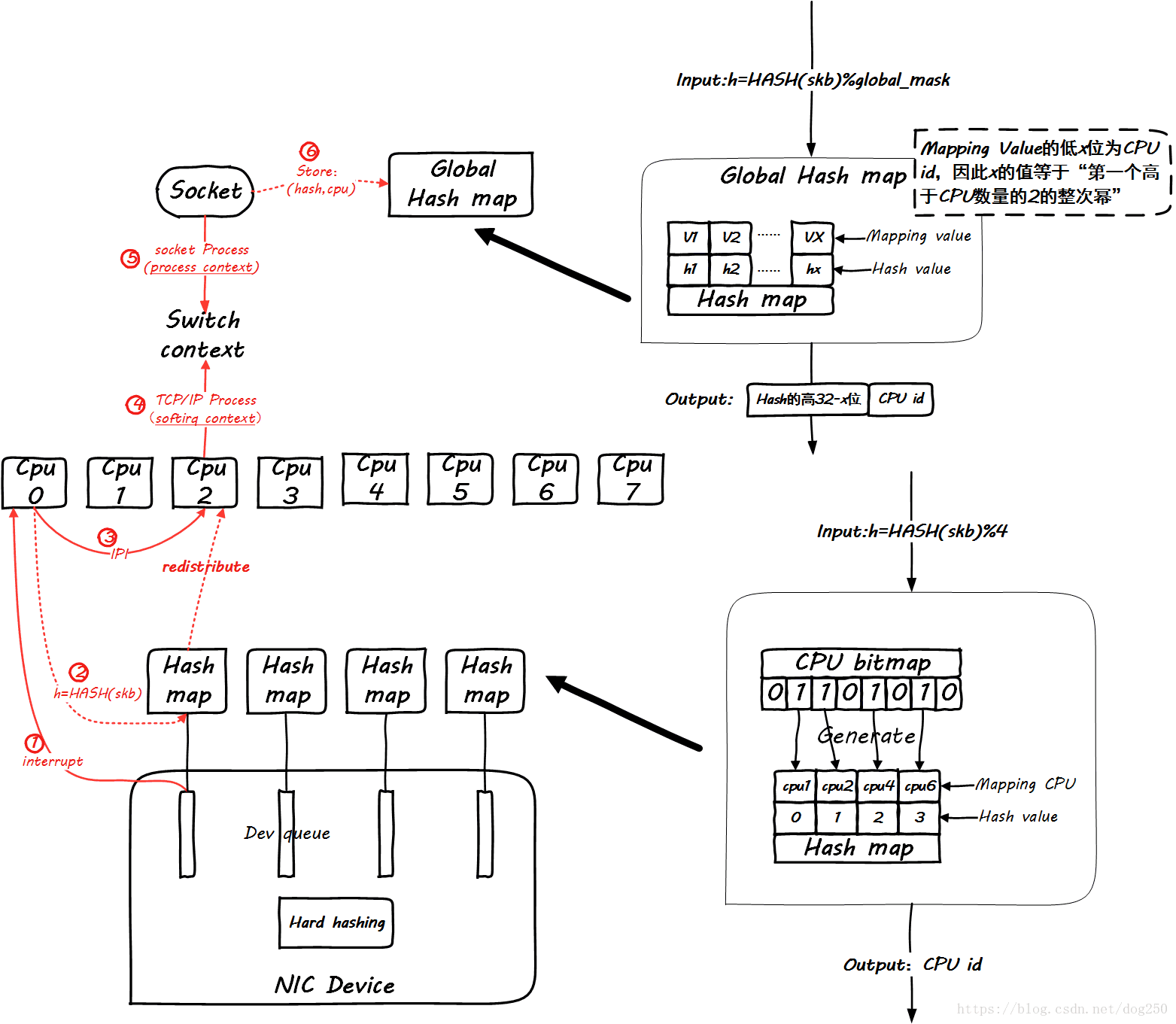
显然,global mapping作为全局映射,空间必须足够大才能容纳足够多的流,不然会相互覆盖。我建议设置成最大并发连接数的2倍。
然后,当同一个flow的后续包到来时,我们看一下global mapping如何起作用。先来看后续第一个包到来时的情景:
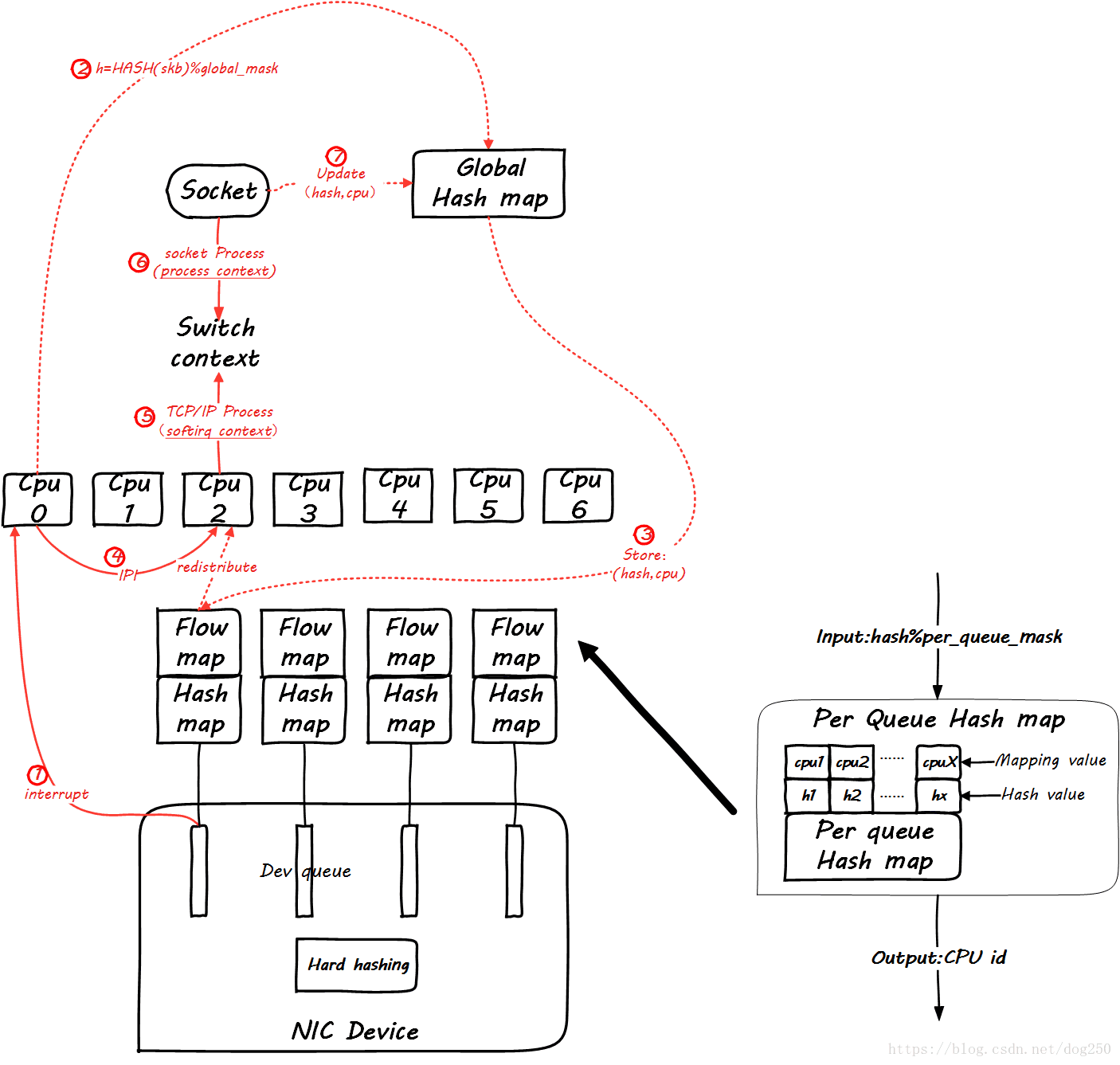
仔细看图,这里增加了一个Per Queue Hash map,这些map是从global map生成的,此后的数据包再到达时,就可以查这个map了:
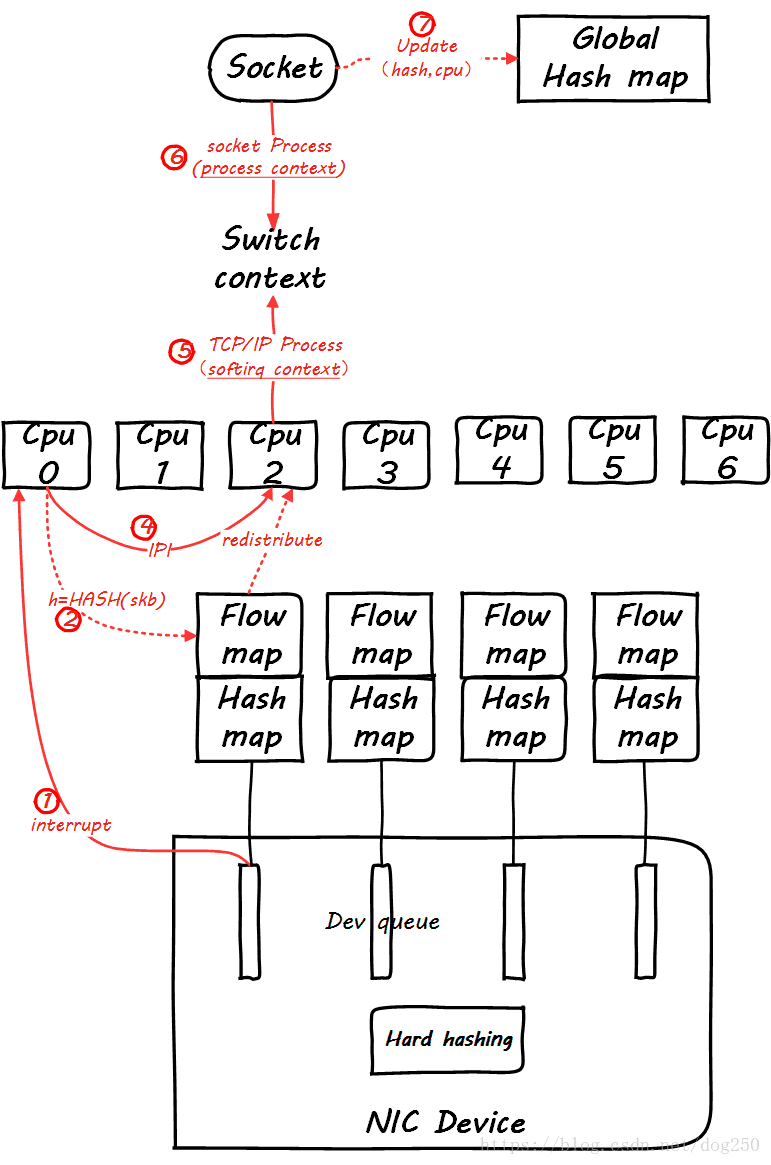
然而,这并没有看出来RFS和RPS的不同。
你能保证处理softirq和处理socket的是同一个CPU吗?你不能,有可能tcp_v4_rcv是CPU0在处理,然后在data_ready中把socket进程唤醒,然而调度器将进程wakeup到CPU1上了,这样在update global hash map的时候,就会更新一个不同的CPU,这个时候RFS的作用就体现了,RFS会把Per Queue Hash Map也更新了,进而接下来的数据包会全部重定向到新的CPU上,然而RPS并不会这么做。
RFS也不是只要发现CPU变了就无条件切换,而是要满足一个条件,即:
**同一个流上次enqueue到旧CPU的数据包全部被处理完毕 **
如此可以保证同一个流处理的串行性,同时处理协议头的时候还能充分利用Hot cacheline。
RPS 加速 Accelerated RFS
基本就是可以把软件发现的配置反向注入到硬件,需要硬件支持,不多说。
总结
有时候太均匀太平等了并不是好事。
在CPU运行繁重的用户态业务逻辑的时候,把中断打到同一个CPU上反而有一个天然限流的作用,要注意,先要找到瓶颈在哪里。如果瓶颈在业务逻辑的处理,那么当你启用RPS/RFS之后,你会发现用户态服务指标毫无起色,同时发现softirq飙高,这并不是一件好事。
参考下面的图示:
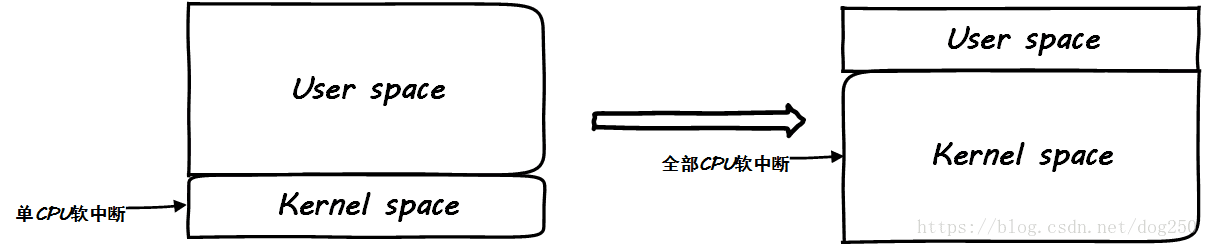
这样好吗?为了所谓内核态处理的优雅均衡,挤压了用户态的CPU时间,这是典型的初学者行为,为了内核而优化内核
其实,OS内核的作用只有一个,就是服务用户态业务逻辑的处理!
配置 RPS
每个网络设备和接收队列都要配置 RPS,在 /sys/class/net/device/queues/rx-queue/rps_cpus 文件中,device 是网络设备的名称(比如 eth0),rx-queue 是适当的接收队列名称(例如 rx-0)。
rps_cpus 文件的默认值为 0。这会禁用 RPS,以便处理网络中断的 CPU 也能处理数据包。
要启用 RPS,配置适当的 rps_cpus 文件以及特定网络设备和接收队列中须处理数据包的 CPU 。
rps_cpus 文件使用以逗号隔开的 CPU 位图。因此,要让 CPU 在一个接口为接收队列处理中断,请将它们在位图里的位置值设为 1。
例如,用 CPU 0、1、2 和 3 处理中断,将 rps_cpus 的值设为 00001111 (1+2+4+8),或 f(十六进制的值为 15)。
对于单一传输队列的网络设备,配置 RPS 以在同一内存区使用 CPU 可获得最佳性能。在非 NUMA 的系统中,这意味着可以使用所有空闲的 CPU。如果网络中断率极高,排除处理网络中断的 CPU 也可以提高性能。
对于多队列的网络设备,配置 RPS 和 RSS 通常都不会有好处,因为 RSS 配置是默认将 CPU 映射至每个接收队列。但是,如果硬件队列比 CPU 少,RPS依然有用,并且配置 RPS 是来在同一内存区使用 CPU。
配置脚本一例
#!/bin/bash
# Enable RPS (Receive Packet Steering)
rfc=4096
cc=$(grep -c processor /proc/cpuinfo)
rsfe=$(echo $cc*$rfc | bc)
sysctl -w net.core.rps_sock_flow_entries=$rsfe
for fileRps in $(ls /sys/class/net/eth*/queues/rx-*/rps_cpus)
do
echo fff > $fileRps
done
for fileRfc in $(ls /sys/class/net/eth*/queues/rx-*/rps_flow_cnt)
do
echo $rfc > $fileRfc
done
tail /sys/class/net/eth*/queues/rx-*/{rps_cpus,rps_flow_cnt}
配置脚本一例
#!/bin/bash
# chkconfig: 2345 90 60
### BEGIN INIT INFO
# Provides: rps
# Required-Start: $local_fs $remote_fs $network $syslog
# Required-Stop: $local_fs $remote_fs $network $syslog
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: enable rps config for ubuntu
# Description: enabele rps which is a kernel tweak for network performance
### END INIT INFO
NAME=rps
DESC=rps
# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
# cpupower frequency-set -g performance
# activate rps/rfs by script: https://gist.github.com/wsgzao/18828f69147635f3e38a14690a633daf
# double ring buffer size: ethtool -G p1p1 [rx|tx] 4096, ethtool -g p1p1
# double NAPI poll budget: sysctl -w net.core.netdev_budget=600
rps() {
net_interface=`ip link show | grep "state UP" | awk '{print $2}' | egrep -v '^docker|^veth' | tr ":\n" " "`
for em in ${net_interface[@]}
do
rq_count=`ls /sys/class/net/$em/queues/rx-* -d | wc -l`
rps_flow_cnt_value=`expr 32768 / $rq_count`
for ((i=0; i< $rq_count; i++))
do
echo $rps_flow_cnt_value > /sys/class/net/$em/queues/rx-$i/rps_flow_cnt
done
flag=0
while [ -f /sys/class/net/$em/queues/rx-$flag/rps_cpus ]
do
echo `cat /sys/class/net/$em/queues/rx-$flag/rps_cpus | sed 's/0/f/g' ` > /sys/class/net/$em/queues/rx-$flag/rps_cpus
flag=$(($flag+1))
done
done
echo 32768 > /proc/sys/net/core/rps_sock_flow_entries
sysctl -p
}
check_rps() {
ni_list=`ip link show | grep "state UP" | awk '{print $2}' | egrep -v "^docker|^veth" | tr ":\n" " "`
for n in $ni_list
do
rx_queues=`ls /sys/class/net/$n/queues/ | grep "rx-[0-9]"`
for q in $rx_queues
do
rps_cpus=`cat /sys/class/net/$n/queues/$q/rps_cpus`
rps_flow_cnt=`cat /sys/class/net/$n/queues/$q/rps_flow_cnt`
echo "[$n]" $q "--> rps_cpus =" $rps_cpus ", rps_flow_cnt =" $rps_flow_cnt
done
done
rps_sock_flow_entries=`cat /proc/sys/net/core/rps_sock_flow_entries`
echo "rps_sock_flow_entries =" $rps_sock_flow_entries
}
case "$1" in
start)
echo -n "Starting $DESC: "
rps
check_rps
;;
stop)
echo -n "Stop is not supported. "
;;
restart|reload|force-reload)
echo -n "Restart is not supported. "
;;
status)
check_rps
;;
*)
echo "Usage: $0 [start|status]"
;;
esac
exit 0
配置 RFS
RFS(接收端流的控制)扩展了 RPS 的性能以增加 CPU 缓存命中率,以此减少网络延迟。RPS 仅基于队列长度转发数据包,RFS 使用 RPS 后端预测最合适的 CPU,之后会根据应用程序处理数据的位置来转发数据包。这增加了 CPU 的缓存效率。
RFS 是默认禁用的。要启用 RFS,用户须编辑两个文件:
/proc/sys/net/core/rps_sock_flow_entries
设置此文件至同时活跃连接数的最大预期值。
对于中等服务器负载,推荐值为 32768 。
所有输入的值四舍五入至最接近的2的幂。
/sys/class/net/device/queues/rx-queue/rps_flow_cnt
将 device 改为想要配置的网络设备名称(例如,eth0),将 rx-queue 改为想要配置的接收队列名称(例如,rx-0)。
将此文件的值设为 rps_sock_flow_entries 除以 N,其中 N 是设备中接收队列的数量。例如,如果 rps_flow_entries 设为 32768,并且有 16 个配置接收队列,那么 rps_flow_cnt 就应设为 2048。
对于单一队列的设备,rps_flow_cnt 的值和 rps_sock_flow_entries 的值是一样的。
同时开启 RPS 和 RSS 后的流程图
RSS是由/sys/class/net//queues/rx-/rps_cpus来控制的。这个文件实现了CPU的位图。默认,当值是0,RPS是无效的,数据包是由中断的CPU来处理的。Documentation/IRQ-affinity.txt 解释了CPU是怎么由位图来设置的。
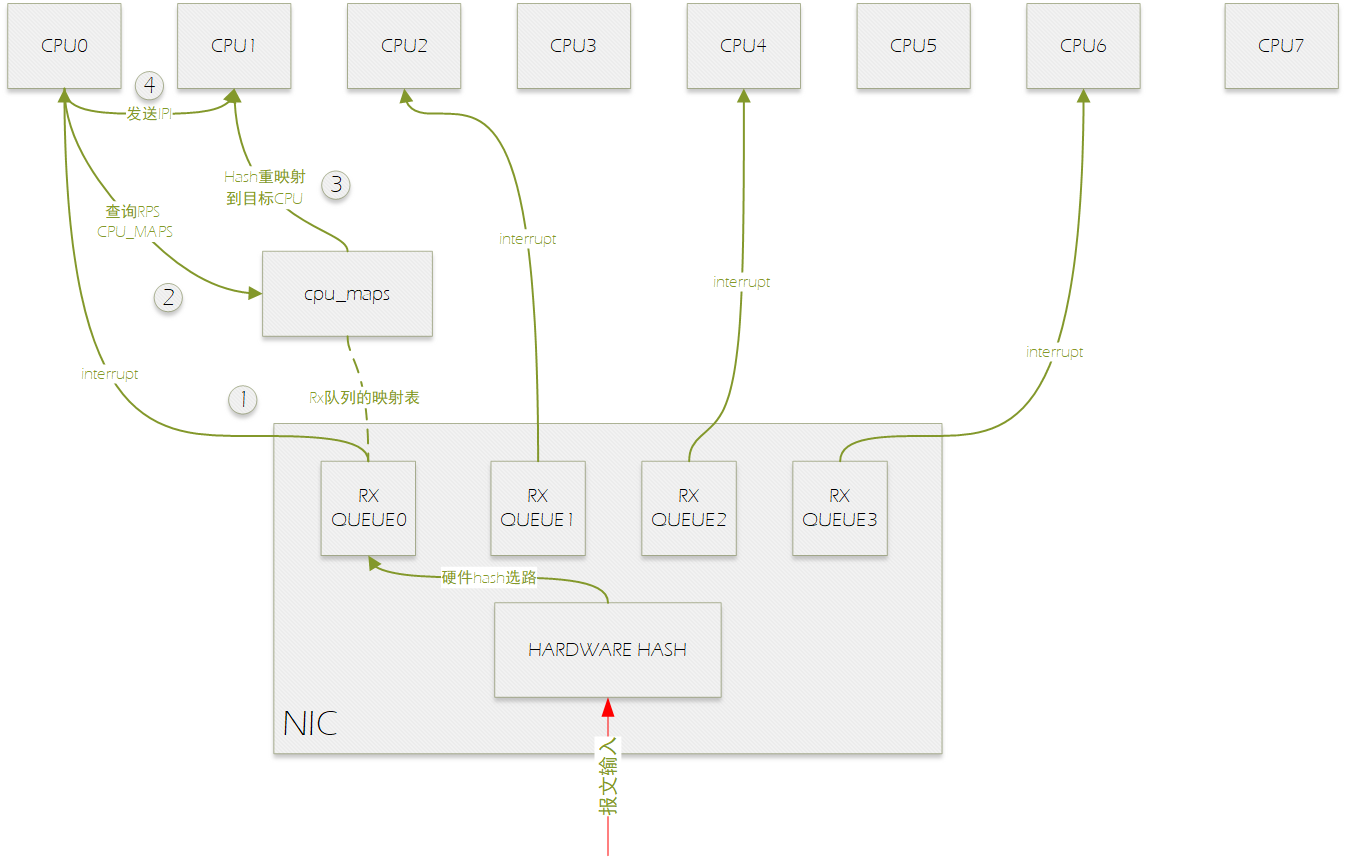
如上图所示,网卡有四个接收多列,分别绑定到cpu0,2,4,6上,报文输入处理流程如下:
0.报文进入网卡后,硬件hash选择RX QUEUE。
1.RX QUEUE0硬件中断CPU0。
2.CPU0在软中断中处理该报文时,进行RPS选择目标CPU进行处理,通过查询RXQUEUE0的rps_maps选择的目标CPU为CPU1。
3.将报文送到CP1的backlog虚拟NAPI报文输入队列中。
4.向CPU1发送IPI。
关闭 irablance
对于高级网卡而言,为了提高性能,他们在硬件驱动层面就实现了一个网卡多个irq的情况,但是由于RHEL默认的irqblance功能,他们可能会不均匀的使用cpu核心,这样不仅会浪费多核心cpu,也会造cpu的cs过多。所以我们需要关闭irqblance,然后手动指定irq。下图是已经做过优化的网卡情况:
CPU bit patterns(CPU 位图)
为了配合smp_affinity,我们还需要将二进制转换为16进制。
Binary Hex
CPU 0 0001 1
CPU 1 0010 2
CPU 2 0100 4
CPU 3 1000 8
计算方法
通过组合这些位模式(基本上,只是添加十六进制值),我们一次可以寻址多个处理器。 例如,如果我想要同时与 CPU0 和 CPU2 通话,结果是:
Binary Hex
CPU 0 0001 1
+ CPU 2 0100 4
-----------------------
both 0101 5
如果要使用所有 CPU,
Binary Hex
CPU 0 0001 1
CPU 1 0010 2
CPU 2 0100 4
+ CPU 3 1000 8
-----------------------
both 1111 f
请住,我们使用字母“a”到“f”来表示数字十六进制表示法中的“10”到“15”。
计算cpu的二进制掩码使用0/1表示,比如原文的4核cpu,使用第0颗cpu时:0001。当指定使用第2颗cpu时:0100。当我们要使用第0和第2颗cpu时:0101。
所以数字的数量表示cpu的数量,而1表示使用那颗cpu核心。而最右边的数字表示第0颗cpu
每四位二进制数可以表示四个CPU,如果24核CPU,cpu1 表示如下:
000000000000000000000010
转换为16进制就是"2"。
另外还需要注意的是smp_affinity最大可以是ffffffff(8),表示成二进制就是32个1,
也就是说,RPS功能最大可以指定到32个cpu。