
快速读懂内存条标签
内存标签


需要了解的参数
8GB
1Rx4
PC3-2400R
RC1-10
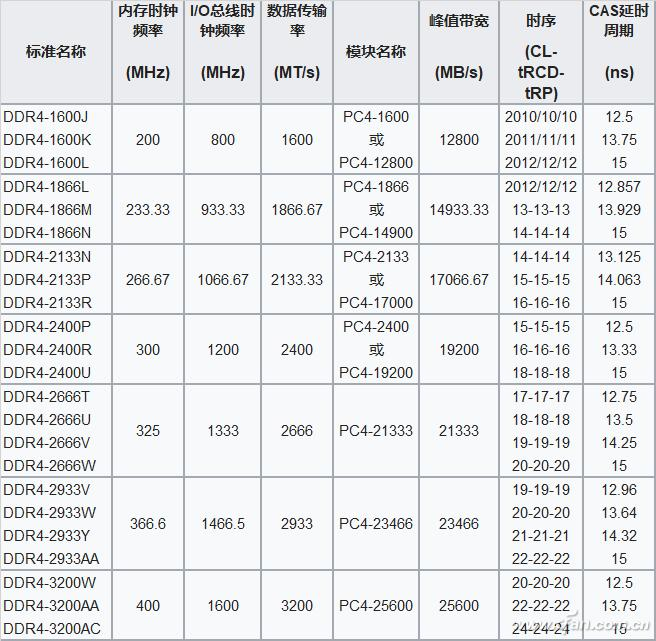
DDR4 内存速度
RANK 和 BANK
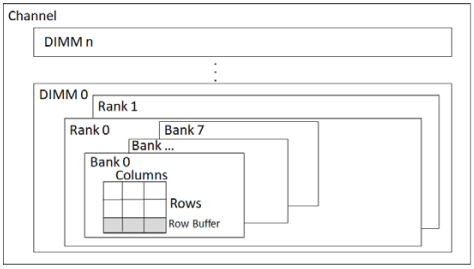
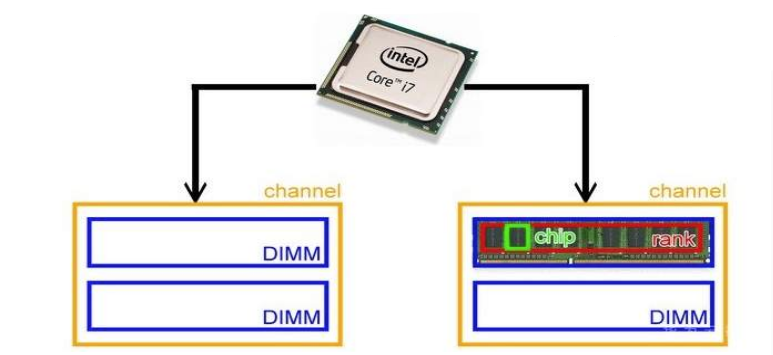
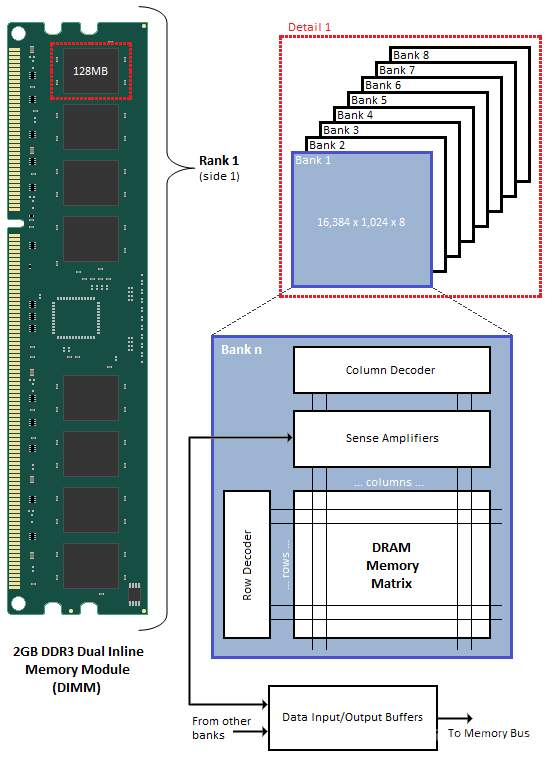
Rank就是每次CPU取的位宽,比如CPU是64位的,那么一个Rank也是64位的,但是内存颗粒没那么大的位宽,通常就是组合成64位,上图就是8个8bit的颗粒一起组成64bit的位宽,因此这8个颗粒合起来称作一个Rank。
一个颗粒就是一个Bank group,图中可以看到一个颗粒由几个Bank组成,总的容量是128MB,Bank的内部结构就是行和列的存储阵列组成。
另外很多人是根据内存的单双面来判断是几个Rank,其实这样是错误的,如上面例子中内存容量是1G的单Rank内存条,如果内存选择的颗粒是4bit的,那么就需要16个颗粒来组成64bit的位宽,那么反面也会有8个颗粒,但是这个内存条也是单Rank的内存。
如果上面内存有2面都是8bit和8个颗粒,那么这个内存就是双Rank的内存条,看出来评判标准就是内存的位宽。
CPU一次只能操作一个Rank,所以每个channel都会出一个rank选择线,选通的Rank才能够访问。
举例说明 1Rx4
x 后面的数代表单个内存颗粒的位宽,例如一些“AMD专用内存”的x4代表的就是单个颗粒为4-bit,要组成单条内存的64-bit至少需要64/4=16个颗粒(这也就是为什么绝大多数专用内存是双面颗粒的原因,因为窄条单面放不下16个颗粒),而我们最常见的内存颗粒是8-bit的,所以一条内存至少是8颗粒。
R代表Rank,通俗点说就是内存颗粒的倍数,因为有时候单倍的颗粒的容量不能满足需要,所以通过增大RANK数来加倍内存颗粒数以增加容量。
颗粒数量的计算公式是Rank数64/单个颗粒的位宽,例如2Rx8就是264/8=16个颗粒,1Rx16就是164/16=4个颗粒。1R4 就是 1*64/4=16
要注意,Rank数和内存的单面双面是没有关系的!x后面的数字也不是颗粒的数量。
相同频率下 x16为什么比x8慢
一句话答案:x16的内存颗粒有2个bank group,而x8的内存颗粒有4个bank group:
我们拿Micron的8Gb内存颗粒[2]举例。同意提供8G bit的容量,它有三种Fuze:
Configuration
– 2 Gig x 4 2G4
– 1 Gig x 8 1G8
– 512 Meg x 16 512M16
分别是2G x 4;1G x 8;512M x 16。同样容量,厂家提供这三种配置有它们不同的应用场景:
- x4主要用来搭建大容量内存条(想想为什么)。但因为每个rank都需要16个颗粒,所以信号完整性要求高,一般用在服务器领域。
- x8是出货量最大的,最通用的配置,一般消费市场大部分就是这种配置。
- x16因为只需要4个颗粒,应用于嵌入式或者PCB空间受限的场合,消费品市场见于低端产品。
x16和x8/x4的主要区别是Bank Group减半了:
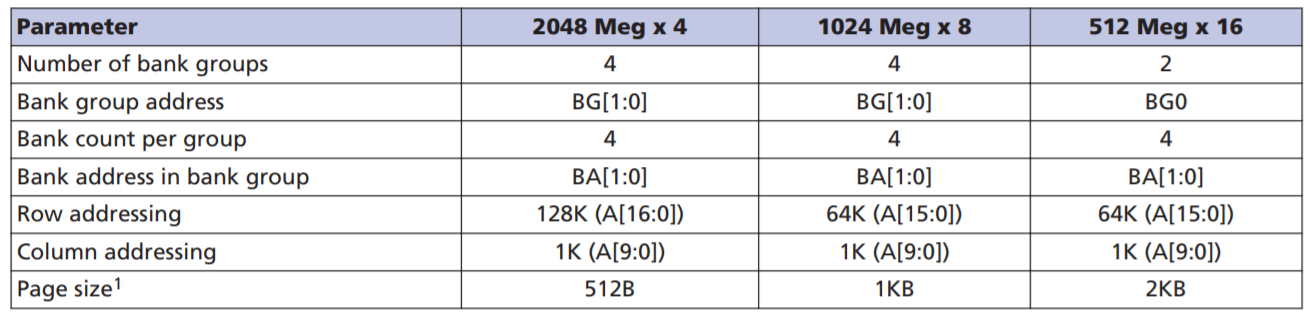
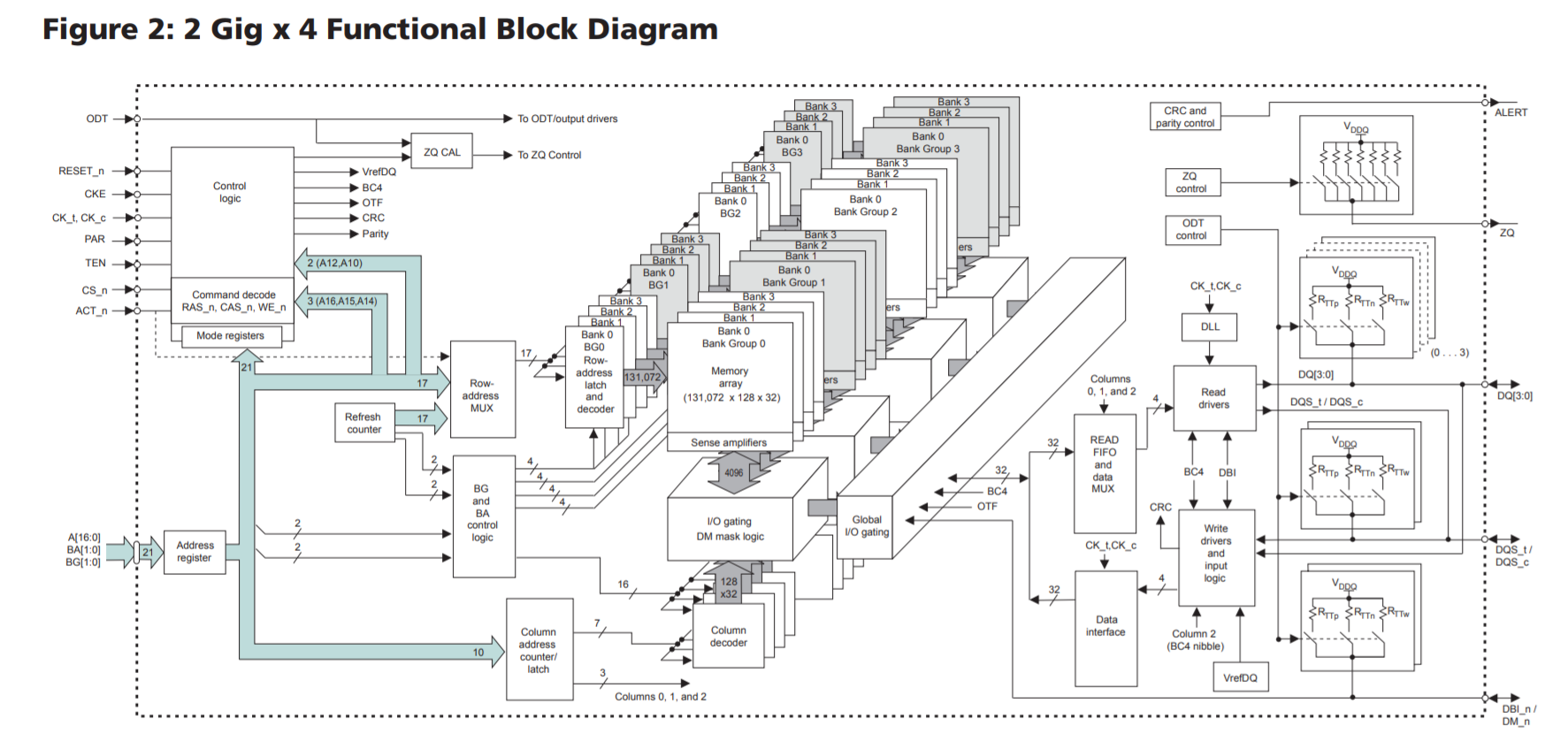
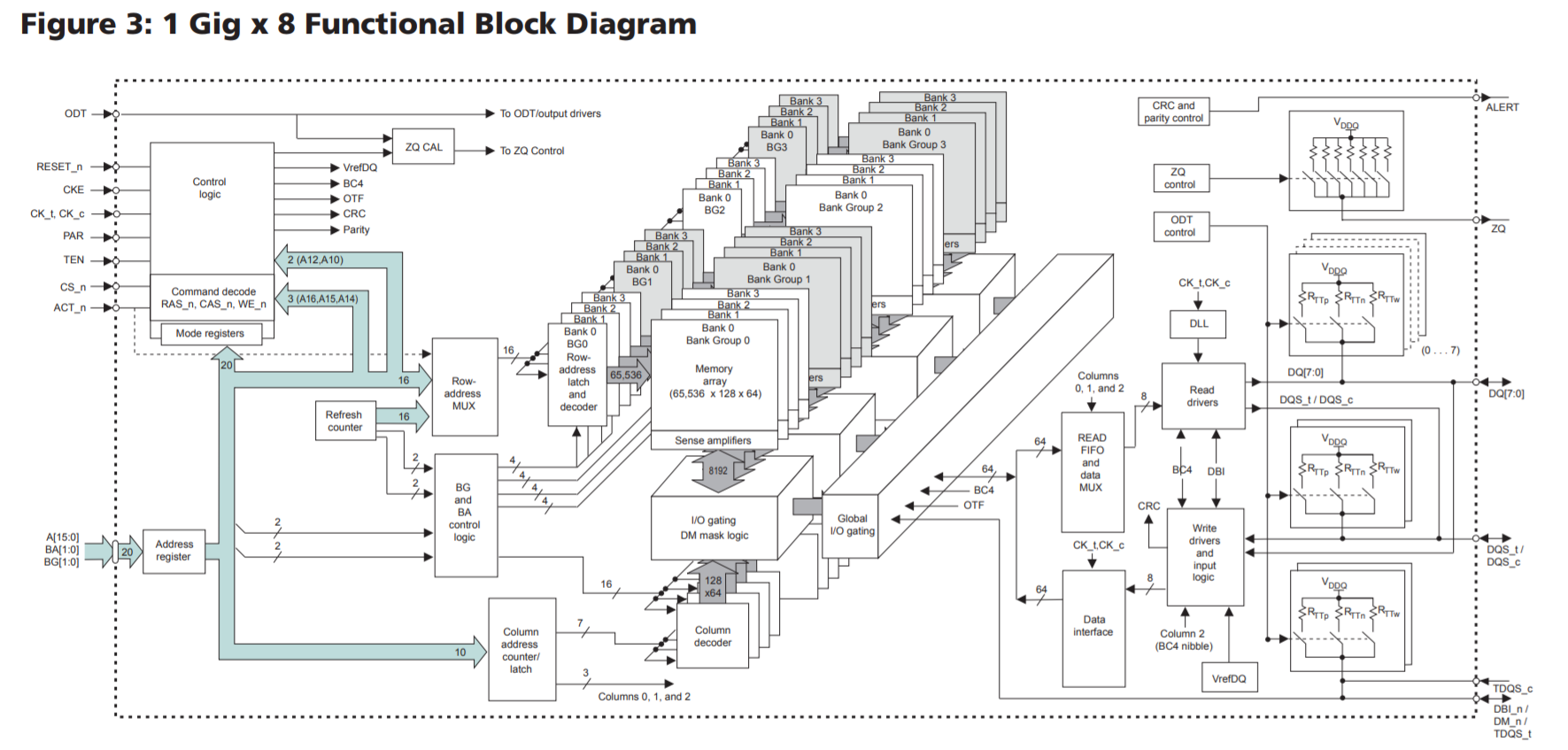
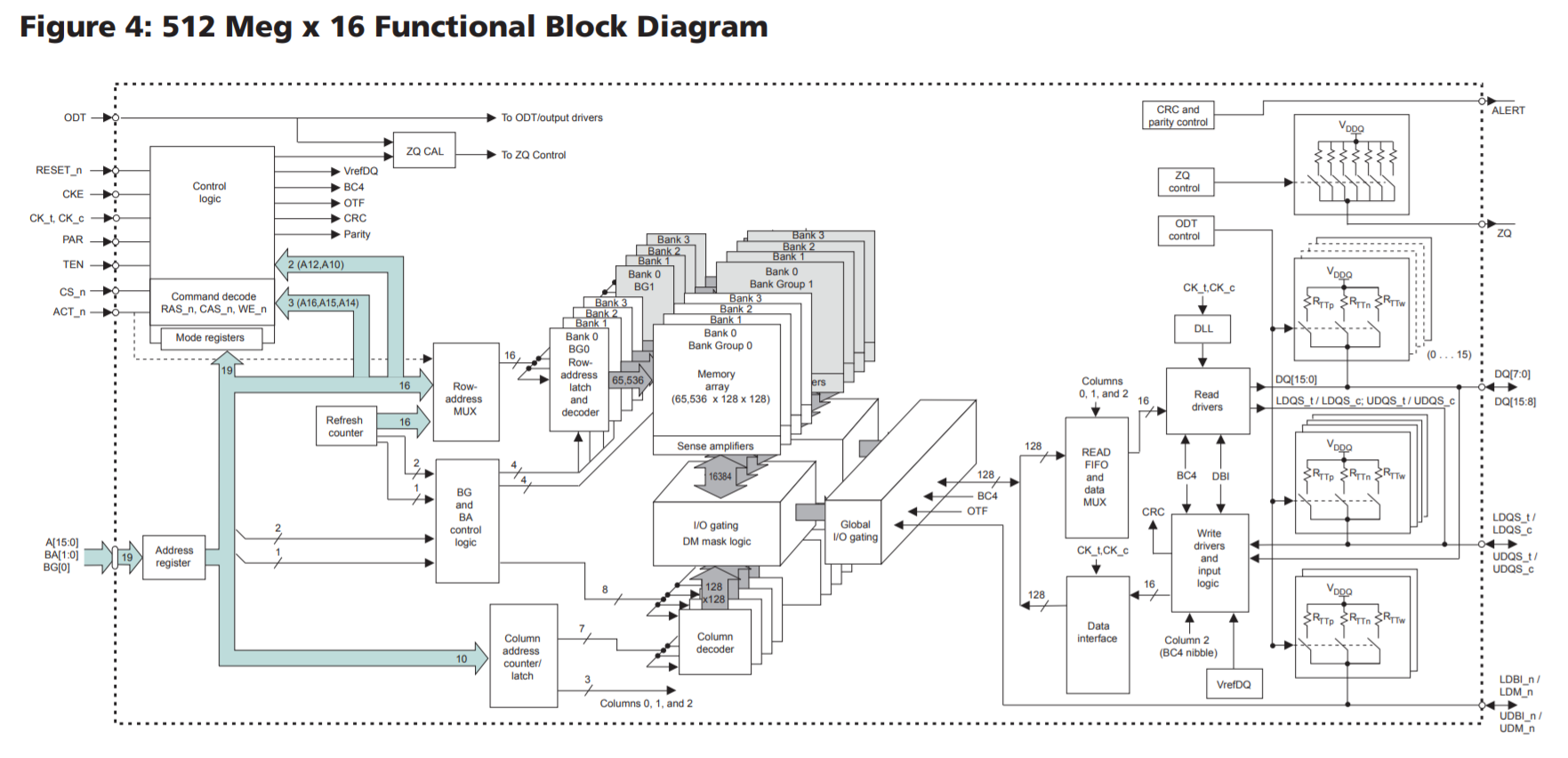
我们看到有4个Group。而x16只有2个group:
Bank Group是DDR4引入的,有助于提高性能。在不同BG读取或者写入数据时,可以部分并发,延迟较少。这里引入两个新的Timings:tCCD_S和tCCD_L。CCD代表“Column to Column Delay”。S是Short,L是Long。每个Group都可以单独工作,一次完整的8n prefetch不需要等待另一个group,所以是短的delay,也就是tCCD_S,一般是4。Group内部,每次都要等待一个更长的时间,也就是tCCD_L,tCCD_L随不同频率各不相同。
我们这个例子颗粒中是多少呢?
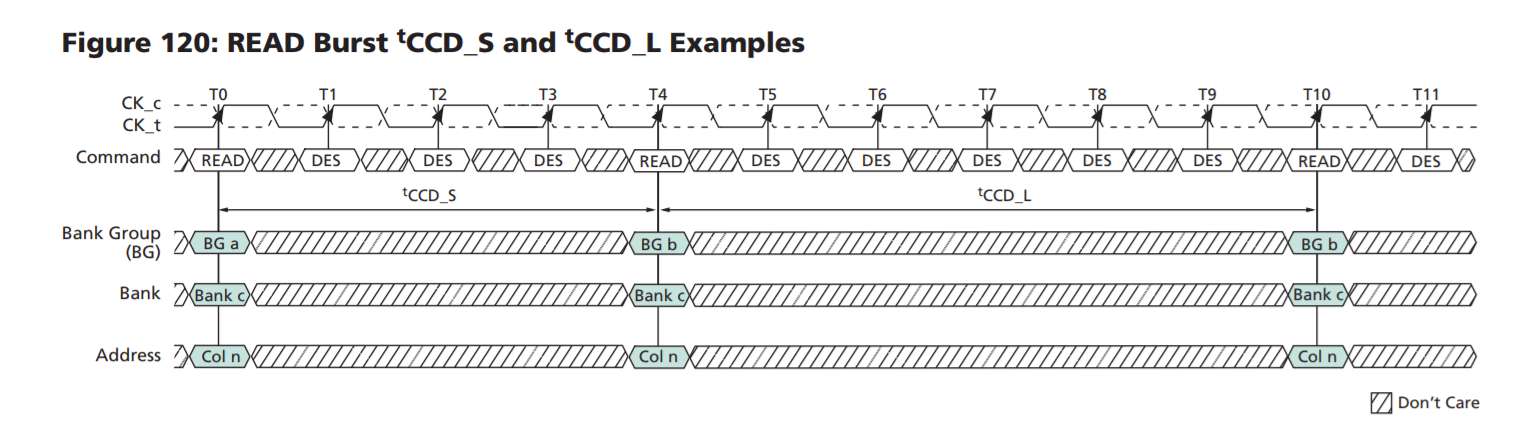
tCCD_L是T10-T4,是6。比tCCD_S高了50%。
如果我们的数据十分凑巧,都分布在不同的group中,Bank Group会带来巨大的性能提升。最好情况下,2个bank groups和16n prefetch的提升一样,4个bank groups和32n prefetch一样。如果我们的数据刚好都在一个bank group中,频率又十分高,最坏情况,bank group不会带来任何好处。借助Bank interleave,我们的实际情况一般在最好和最坏之间。
x16只有两个bank group,而x8有四个bank group,这带来绝大的性能差异。如这位网友和Linus的结果,某些workload下有20%之多!这么大的性能差异,足以抵消一两代CPU带来的性能提升。
深入理解硬件原理
时延(Latency)
CL
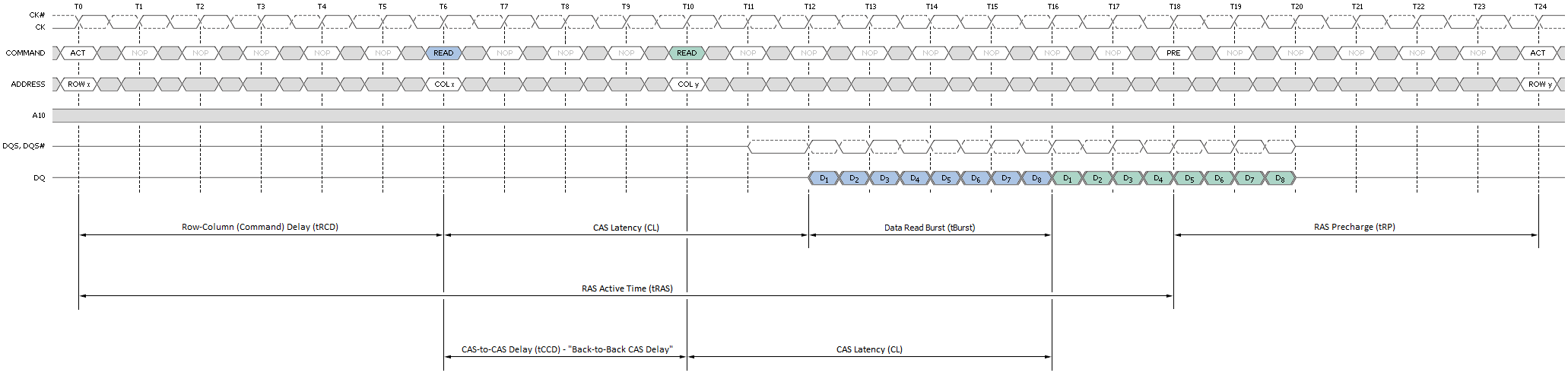
CL: CAS Latency。CL是指CAS发出之后,仍要经过一定的时间才能有数据输出,从CAS与读取命令发出到第一笔数据输出的这段时间,被定义为CL(CAS Latency,CAS时延)。由于CL只在读取时出现,所以CL又被称为读取时延(RL,Read Latency)。也就是我们上面第3步读取时需要的时间。CL是延迟里面最重要的参数,有时会单独在内存标签上标出如CLx。它告诉我们多少个时钟周期后我们才能拿到数据,CL7的内存会延迟7个周期才能给我们数据,CL9的则要等9个。所以越小我们越能更快的拿到数据。注意这里的周期是真正的周期而不是标注的DDR3 1333MHz的周期,因为一个周期传输两次,真正的周期只是1/2,这里是666MHz。如下图,是CL7和CL9的
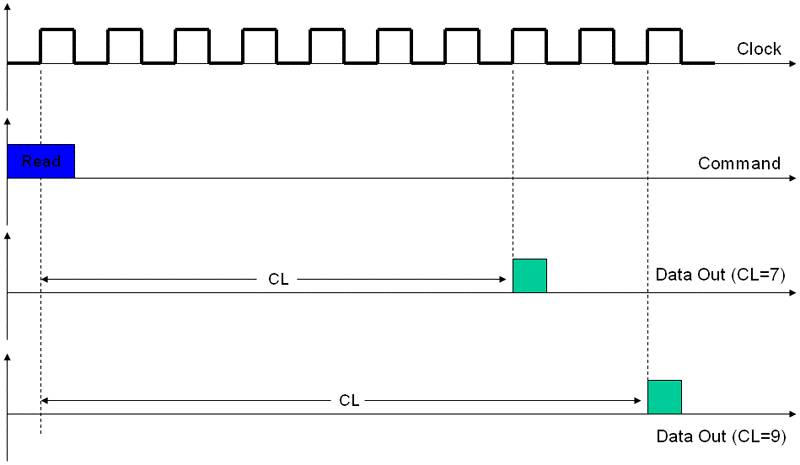
如果相同频率的内存,CL7可以比CL9有22%的效能提高。
tRCD
tRCD:RAS到CAS时延。在发送列读写命令时必须要与行有效命令有一个间隔,这是根据芯片存储阵列电子元件响应时间所制定的延迟。即步骤1和2要间隔的时间。这个间隔当然也是越快越好了,下面是个tRCD=3的例子:
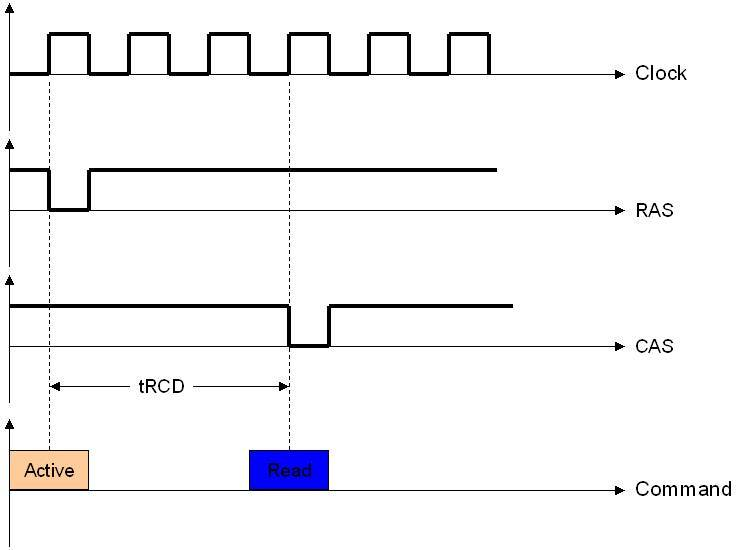
你也可以看出这个时间也是激活命令和读命令的间隔。
tRP
tRP: 预充电有效周期(Precharge command Period)。在上一次传输完成后到下一次行激活前有个预充电过程,要经过一段充电时间才能允许发送RAS。也就是步骤1的准备工作要做多久。下面是个例子:
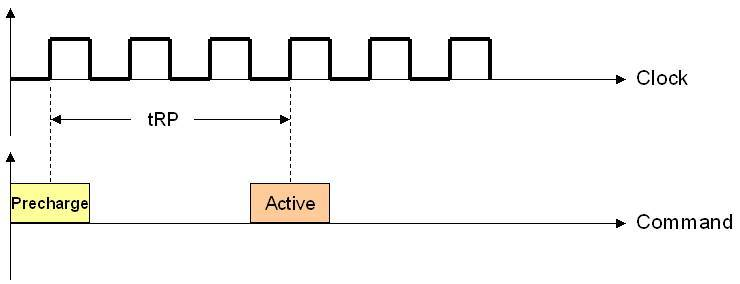
还有两个类似的时延tRAS和CMD。总之,所有这些时延共同构成了整体时延,而时延是越小越好。
SPD
每个DIMM在板子上都有块小的存储芯片(EEPROM),上面详细记录了包括这些的很多参数,还有生产厂家的代码等等,这也是BIOS为什么能知道我们插了哪种内存的原因。
注意
实际上随着DDR的一步步进化,这些延迟的时钟周期个数也在步步提高,但由于频率的加快,实际上是在时间是在慢慢的减少的。