
数据结构——Stack&Queue
栈
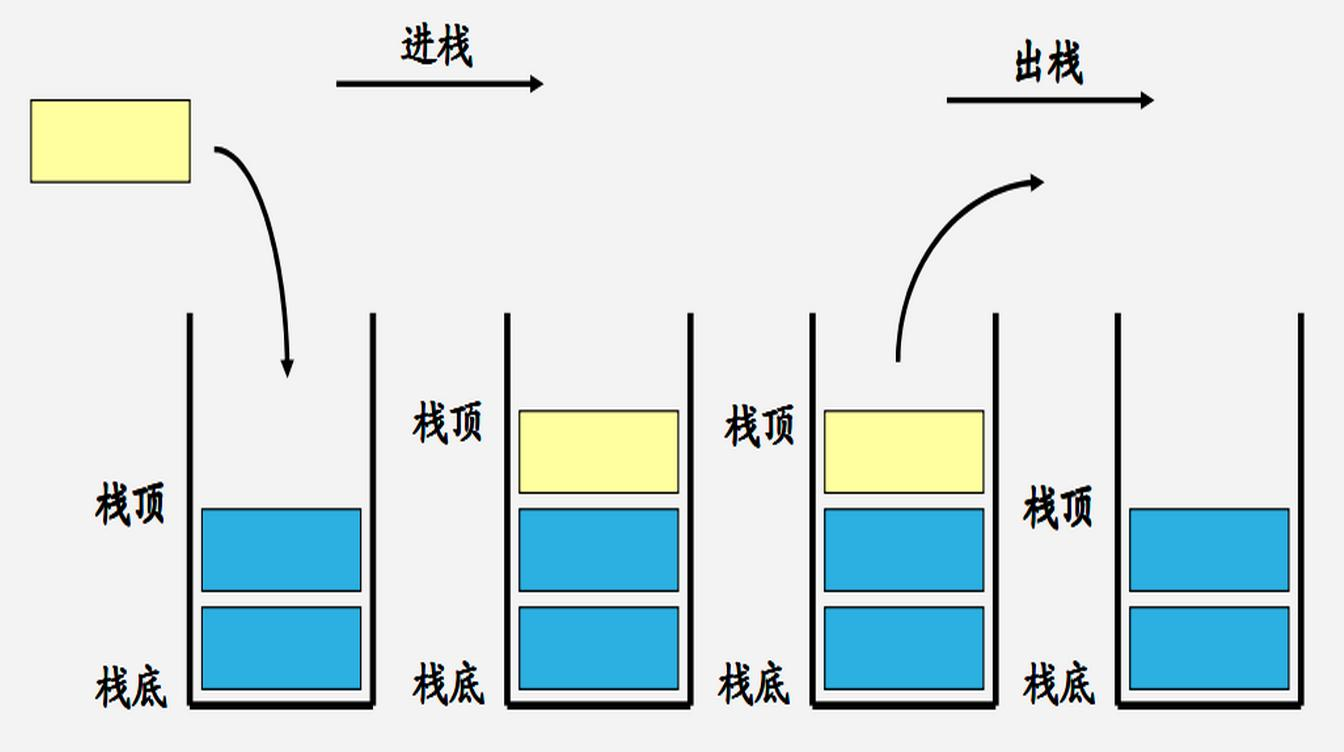
我们一般使用的也就只有push(压入),pop(调出)
- Pushnew数据
- Poplast数据
这就是所谓的Last In-First Out
队列
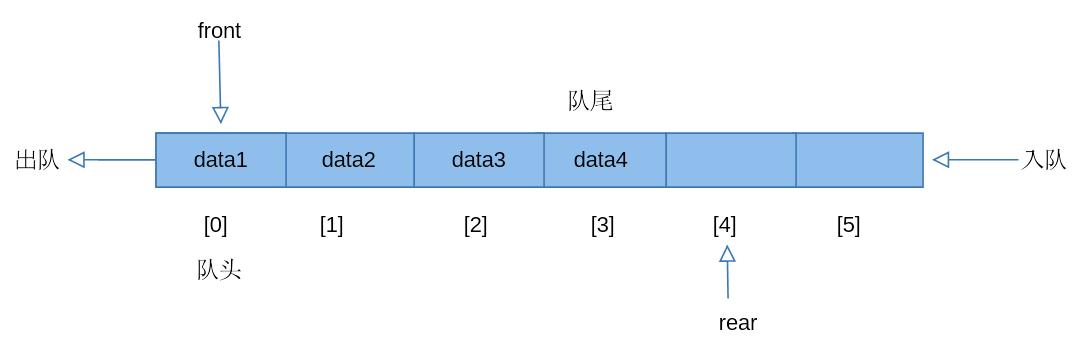
对于Queue来讲,我们一般使用的也只有:
- Enqueue new数据 (入队)
- Dequeue oldest数据 (出队)
这也就是所谓的First in-First out
Linux 内存管理
栈(stack)
栈又称堆栈,由编译器自动分配释放,行为类似数据结构中的栈(先进后出)。堆栈主要有三个用途:
- 为函数内部声明的非静态局部变量(C语言中称“自动变量”)提供存储空间。
- 记录函数调用过程相关的维护性信息,称为栈帧(Stack Frame)或过程活动记录(Procedure Activation Record)。它包括函数返回地址,不适合装入寄存器的函数参数及一些寄存器值的保存。除递归调用外,堆栈并非必需。因为编译时可获知局部变量,参数和返回地址所需空间,并将其分配于BSS段。
- 临时存储区,用于暂存长算术表达式部分计算结果或alloca()函数分配的栈内内存。
持续地重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每个线程都有属于自己的栈。向栈中不断压入数据时,若超出其容量就会耗尽栈对应的内存区域,从而触发一个页错误。此时若栈的大小低于堆栈最大值RLIMIT_STACK(通常是8M),则栈会动态增长,程序继续运行。映射的栈区扩展到所需大小后,不再收缩。
Linux中ulimit -s命令可查看和设置堆栈最大值,当程序使用的堆栈超过该值时, 发生栈溢出(Stack Overflow),程序收到一个段错误(Segmentation Fault)。注意,调高堆栈容量可能会增加内存开销和启动时间。
堆栈既可向下增长(向内存低地址)也可向上增长, 这依赖于具体的实现。本文所述堆栈向下增长。
堆栈的大小在运行时由内核动态调整。
堆(heap)
堆用于存放进程运行时动态分配的内存段,可动态扩张或缩减。堆中内容是匿名的,不能按名字直接访问,只能通过指针间接访问。当进程调用malloc(C)/new(C++)等函数分配内存时,新分配的内存动态添加到堆上(扩张);当调用free(C)/delete(C++)等函数释放内存时,被释放的内存从堆中剔除(缩减) 。
分配的堆内存是经过字节对齐的空间,以适合原子操作。堆管理器通过链表管理每个申请的内存,由于堆申请和释放是无序的,最终会产生内存碎片。堆内存一般由应用程序分配释放,回收的内存可供重新使用。若程序员不释放,程序结束时操作系统可能会自动回收。
堆的末端由break指针标识,当堆管理器需要更多内存时,可通过系统调用brk()和sbrk()来移动break指针以扩张堆,一般由系统自动调用。
使用堆时经常出现两种问题:
-
- 释放或改写仍在使用的内存(“内存破坏”);
- 2)未释放不再使用的内存(“内存泄漏”)。当释放次数少于申请次数时,可能已造成内存泄漏。泄漏的内存往往比忘记释放的数据结构更大,因为所分配的内存通常会圆整为下个大于申请数量的2的幂次(如申请212B,会圆整为256B)。
注意,堆不同于数据结构中的”堆”,其行为类似链表。
栈和堆的区别
- 管理方式:栈由编译器自动管理;堆由程序员控制,使用方便,但易产生内存泄露。
- 生长方向:栈向低地址扩展(即”向下生长”),是连续的内存区域;堆向高地址扩展(即”向上生长”),是不连续的内存区域。这是由于系统用链表来存储空闲内存地址,自然不连续,而链表从低地址向高地址遍历。
- 空间大小:栈顶地址和栈的最大容量由系统预先规定(通常默认2M或10M);堆的大小则受限于计算机系统中有效的虚拟内存,32位Linux系统中堆内存可达2.9G空间。
- 存储内容:栈在函数调用时,首先压入主调函数中下条指令(函数调用语句的下条可执行语句)的地址,然后是函数实参,然后是被调函数的局部变量。本次调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的指令地址,程序由该点继续运行下条可执行语句。堆通常在头部用一个字节存放其大小,堆用于存储生存期与函数调用无关的数据,具体内容由程序员安排。
- 分配方式:栈可静态分配或动态分配。静态分配由编译器完成,如局部变量的分配。动态分配由alloca函数在栈上申请空间,用完后自动释放。堆只能动态分配且手工释放。
- 分配效率:栈由计算机底层提供支持:分配专门的寄存器存放栈地址,压栈出栈由专门的指令执行,因此效率较高。堆由函数库提供,机制复杂,效率比栈低得多。Windows系统中VirtualAlloc可直接在进程地址空间中分配一块内存,快速且灵活。
- 分配后系统响应:只要栈剩余空间大于所申请空间,系统将为程序提供内存,否则报告异常提示栈溢出。
- 操作系统为堆维护一个记录空闲内存地址的链表。当系统收到程序的内存分配申请时,会遍历该链表寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点空间分配给程序。若无足够大小的空间(可能由于内存碎片太多),有可能调用系统功能去增加程序数据段的内存空间,以便有机会分到足够大小的内存,然后进行返回。,大多数系统会在该内存空间首地址处记录本次分配的内存大小,供后续的释放函数(如free/delete)正确释放本内存空间。
- 此外,由于找到的堆结点大小不一定正好等于申请的大小,系统会自动将多余的部分重新放入空闲链表中。
- 碎片问题:栈不会存在碎片问题,因为栈是先进后出的队列,内存块弹出栈之前,在其上面的后进的栈内容已弹出。而频繁申请释放操作会造成堆内存空间的不连续,从而造成大量碎片,使程序效率降低。
- 可见,堆容易造成内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和内核态切换,内存申请的代价更为昂贵。所以栈在程序中应用最广泛,函数调用也利用栈来完成,调用过程中的参数、返回地址、栈基指针和局部变量等都采用栈的方式存放。所以,建议尽量使用栈,仅在分配大量或大块内存空间时使用堆。
- 使用栈和堆时应避免越界发生,否则可能程序崩溃或破坏程序堆、栈结构,产生意想不到的后果。
Go 内存管理
前言
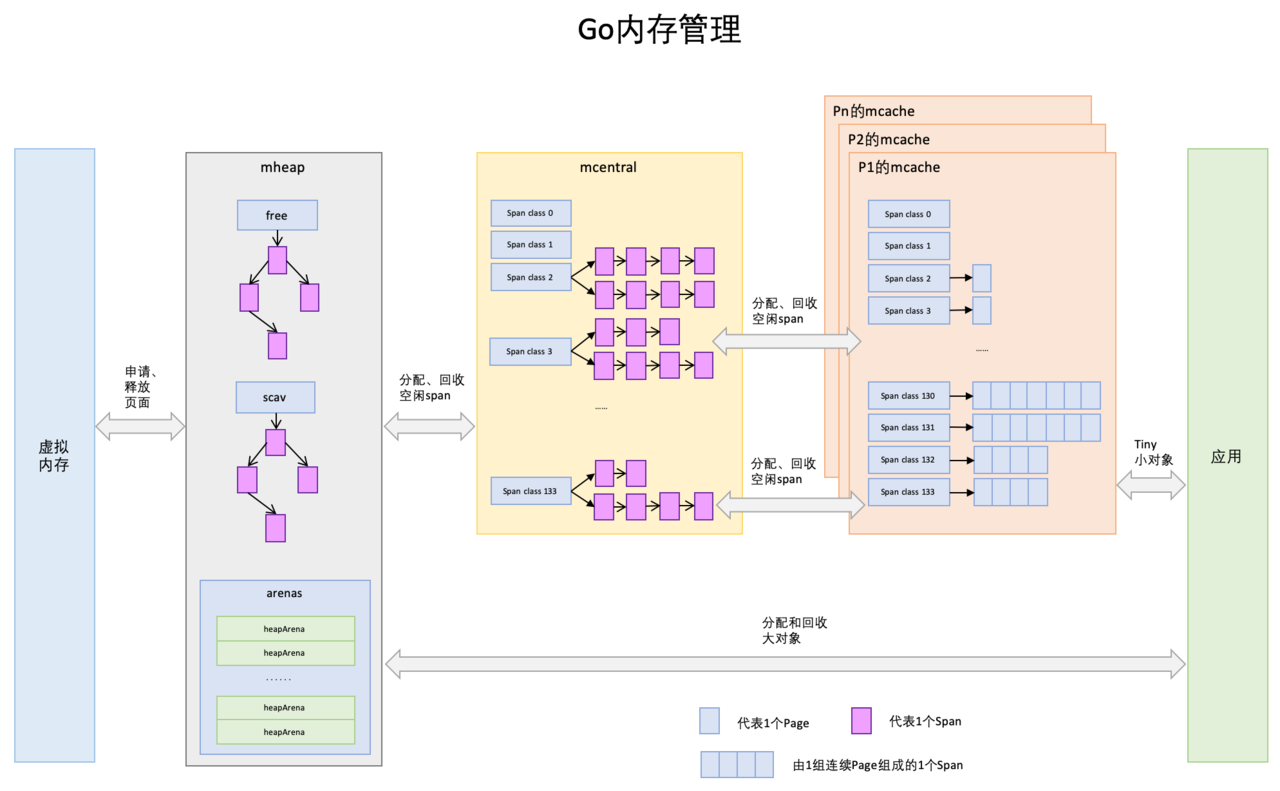
这篇文章主要介绍Go内存分配和Go内存管理,会轻微涉及内存申请和释放,以及Go垃圾回收。从非常宏观的角度看,Go的内存管理就是下图这个样子,我们今天主要关注其中标红的部分。
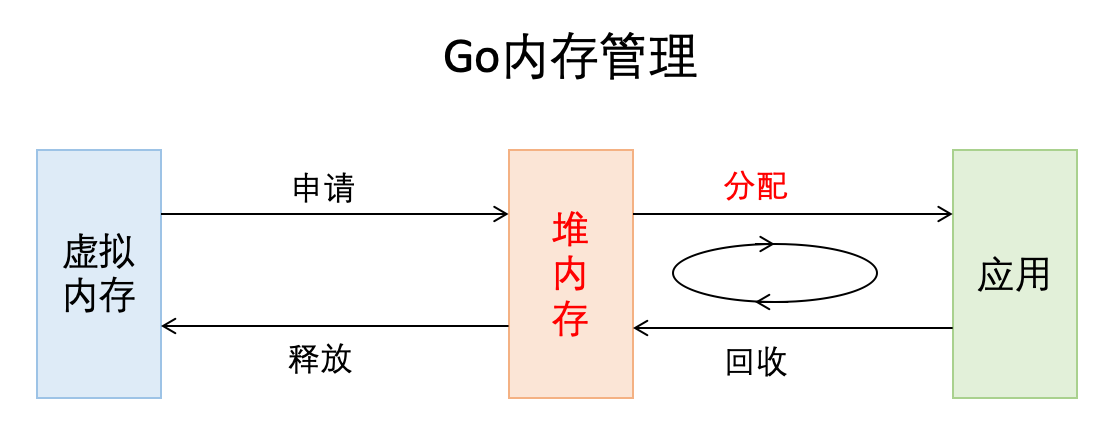
Go这门语言抛弃了C/C++中的开发者管理内存的方式,实现了主动申请与主动释放管理,增加了逃逸分析和GC,将开发者从内存管理中释放出来,让开发者有更多的精力去关注软件设计,而不是底层的内存问题。这是Go语言成为高生产力语言的原因之一。
我们不需要精通内存的管理,因为它确实很复杂,但掌握内存的管理,可以让你写出更高质量的代码,另外,还能助你定位Bug。这篇文章采用层层递进的方式,依次会介绍关于存储的基本知识,Go内存管理的 “前辈” TCMalloc,然后是Go的内存管理和分配,最后是总结。这么做的目的是,希望各位能通过全局的认识和思考,拥有更好的编码思维和架构思维。
正文
1. 存储基础知识回顾
CPU速度很快,但硬盘等持久存储很慢,如果CPU直接访问磁盘,磁盘可以拉低CPU的速度,机器整体性能就会低下,为了弥补这2个硬件之间的速率差异,所以在CPU和磁盘之间增加了比磁盘快很多的内存。
三级Cache分别是L1、L2、L3,它们的速率是三个不同的层级,L1速率最快,与CPU速率最接近,是RAM速率的100倍,L2速率就降到了RAM的25倍,L3的速率更靠近RAM的速率。
看到这了,你有没有Get到整个存储体系的分层设计?自顶向下,速率越来越低,访问时间越来越长,从磁盘到CPU寄存器,上一层都可以看做是下一层的缓存。看了分层设计,下面开始正式介绍内存。
1.2. 虚拟内存
虚拟内存是当代操作系统必备的一项重要功能,对于进程而言虚拟内存屏蔽了底层了RAM和磁盘,并向进程提供了远超物理内存大小的内存空间。我们看一下虚拟内存的分层设计。
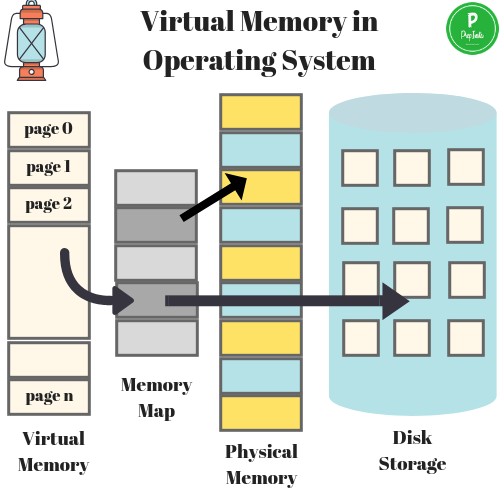
上图展示了某进程访问数据,当Cache没有命中的时候,访问虚拟内存获取数据的过程。在访问内存,实际访问的是虚拟内存,虚拟内存通过页表查看,当前要访问的虚拟内存地址,是否已经加载到了物理内存。如果已经在物理内存,则取物理内存数据,如果没有对应的物理内存,则从磁盘加载数据到物理内存,并把物理内存地址和虚拟内存地址更新到页表。
物理内存就是磁盘存储缓存层,在没有虚拟内存的时代,物理内存对所有进程是共享的,多进程同时访问同一个物理内存会存在并发问题。而引入虚拟内存后,每个进程都有各自的虚拟内存,内存的并发访问问题的粒度从多进程级别,可以降低到多线程级别。
1.3. 栈和堆
我们现在从虚拟内存,再进一层,看虚拟内存中的栈和堆,也就是进程对内存的管理。
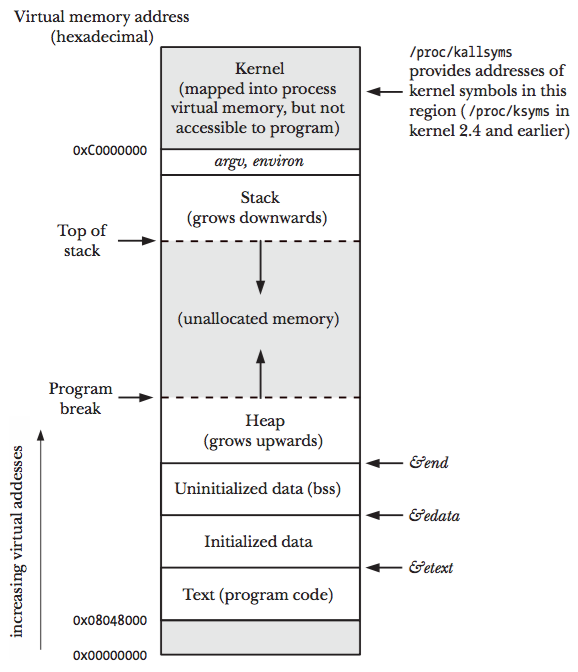
上图展示了一个进程的虚拟内存划分,代码中使用的内存地址都是虚拟内存地址,而不是实际的物理内存地址。栈和堆只是虚拟内存上2块不同功能的内存区域:
- 栈在高地址,从高地址向低地址增长
- 堆在低地址,从低地址向高地址增长
栈和堆相比有这么几个好处:
- 栈的内存管理简单,分配比堆上快。
- 栈的内存不需要回收,而堆需要进行回收,无论是主动free,还是被动的垃圾回收,这都需要花费额外的CPU。
- 栈上的内存有更好的局部性,堆上内存访问就不那么友好了,CPU访问的2块数据可能在不同的页上,CPU访问数据的时间可能就上去了。
1.4. 堆内存管理
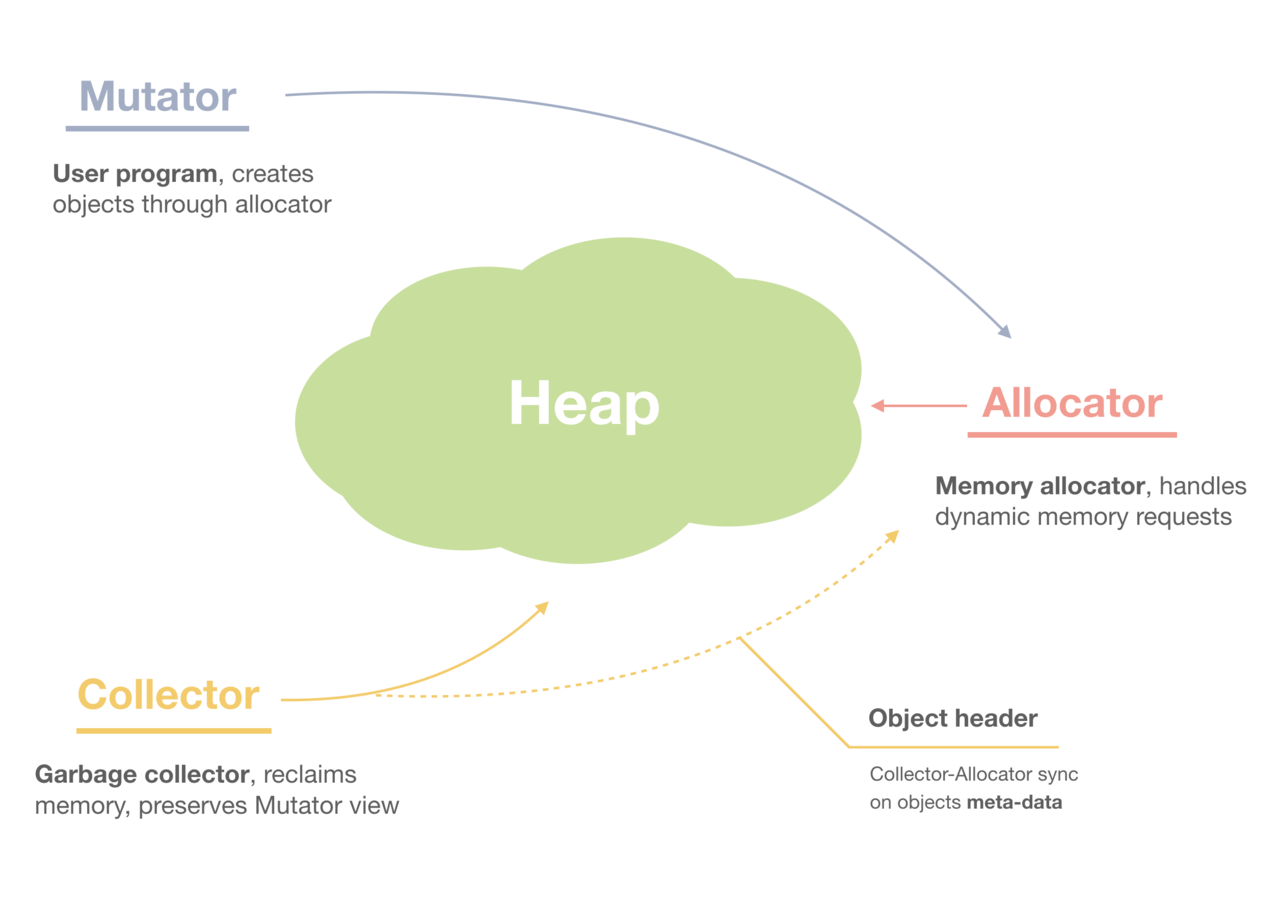
当我们说内存管理的时候,主要是指堆内存的管理,因为栈的内存管理不需要程序去操心,这小节看下堆内存管理到底完成了什么。如上图所示主要是3部分,分别是分配内存块,回收内存块和组织内存块。
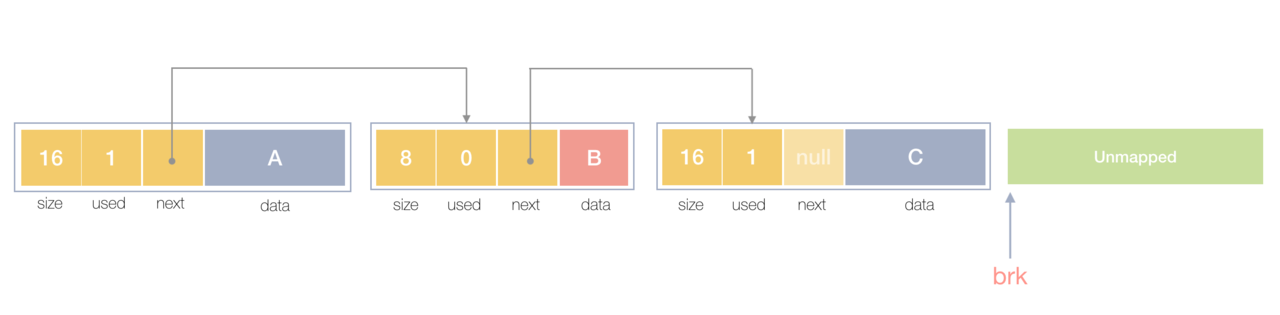
在一个最简单的内存管理中,堆内存最初会是一个完整的大块,即未分配任何内存。当发现内存申请的时候,堆内存就会从未分配内存分割出一个小内存块(block),然后用链表把所有内存块连接起来。需要一些信息描述每个内存块的基本信息,比如大小(size)、是否使用中(used)和下一个内存块的地址(next),内存块实际数据存储在data中。
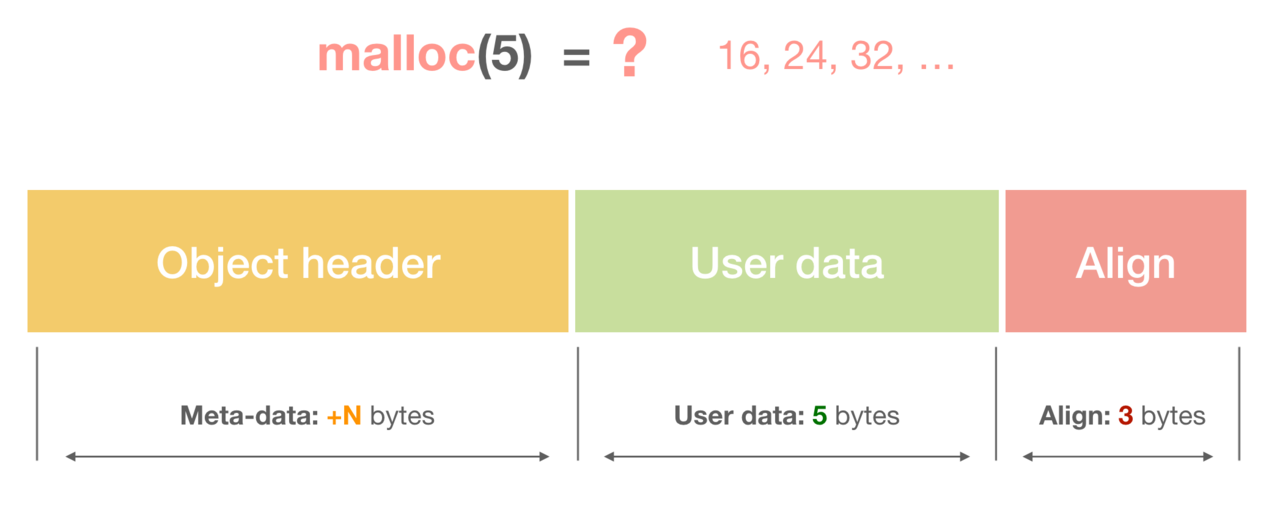
一个内存块包含了3类信息,如下图所示,元数据、用户数据和对齐字段,内存对齐是为了提高访问效率。下图申请5Byte内存的时候,就需要进行内存对齐。
释放内存实质是把使用的内存块从链表中取出来,然后标记为未使用,当分配内存块的时候,可以从未使用内存块中优先查找大小相近的内存块,如果找不到,再从未分配的内存中分配内存。
上面这个简单的设计中还没考虑内存碎片的问题,因为随着内存不断的申请和释放,内存上会存在大量的碎片,降低内存的使用率。为了解决内存碎片,可以将2个连续的未使用的内存块合并,减少碎片。
以上就是内存管理的基本思路,关于基本的内存管理,想了解更多,可以阅读这篇文章《Writing a Memory Allocator》,本节的3张图片也是来自这篇文章。
2. TCMalloc
TCMalloc是Thread Cache Malloc的简称,是Go内存管理的起源,Go的内存管理是借鉴了TCMalloc,随着Go的迭代,Go的内存管理与TCMalloc不一致地方在不断扩大,但其主要思想、原理和概念都是和TCMalloc一致的,如果跳过TCMalloc直接去看Go的内存管理,也许你会似懂非懂。
掌握TCMalloc的理念,无需去关注过多的源码细节,就可以为掌握Go的内存管理打好基础,基础打好了,后面知识才扎实。
在Linux操作系统中,其实有不少的内存管理库,比如glibc的ptmalloc,FreeBSD的jemalloc,Google的tcmalloc等等,为何会出现这么多的内存管理库?本质都是在多线程编程下,追求更高内存管理效率:更快的分配是主要目的。
我们前面提到引入虚拟内存后,让内存的并发访问问题的粒度从多进程级别,降低到多线程级别。然而同一进程下的所有线程共享相同的内存空间,它们申请内存时需要加锁,如果不加锁就存在同一块内存被2个线程同时访问的问题。
TCMalloc的做法是什么呢?为每个线程预分配一块缓存,线程申请小内存时,可以从缓存分配内存,这样有2个好处:
- 为线程预分配缓存需要进行1次系统调用,后续线程申请小内存时直接从缓存分配,都是在用户态执行的,没有了系统调用,缩短了内存总体的分配和释放时间,这是快速分配内存的第二个层次。
- 多个线程同时申请小内存时,从各自的缓存分配,访问的是不同的地址空间,从而无需加锁,把内存并发访问的粒度进一步降低了,这是快速分配内存的第三个层次。
2.1. 基本原理
下面就简单介绍下TCMalloc,细致程度够我们理解Go的内存管理即可。
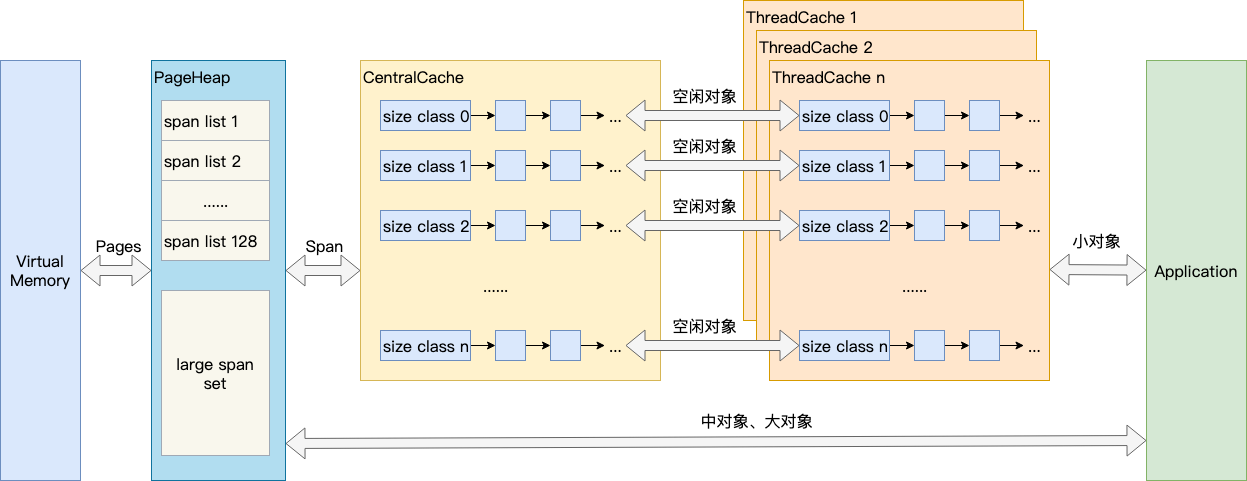
结合上图,介绍TCMalloc的几个重要概念:
- Page:操作系统对内存管理以页为单位,TCMalloc也是这样,只不过TCMalloc里的Page大小与操作系统里的大小并不一定相等,而是倍数关系。《TCMalloc解密》里称x64下Page大小是8KB。
- Span:一组连续的Page被称为Span,比如可以有2个页大小的Span,也可以有16页大小的Span,Span比Page高一个层级,是为了方便管理一定大小的内存区域,Span是TCMalloc中内存管理的基本单位。
- ThreadCache:ThreadCache是每个线程各自的Cache,一个Cache包含多个空闲内存块链表,每个链表连接的都是内存块,同一个链表上内存块的大小是相同的,也可以说按内存块大小,给内存块分了个类,这样可以根据申请的内存大小,快速从合适的链表选择空闲内存块。由于每个线程有自己的ThreadCache,所以ThreadCache访问是无锁的。
- CentralCache:CentralCache是所有线程共享的缓存,也是保存的空闲内存块链表,链表的数量与ThreadCache中链表数量相同,当ThreadCache的内存块不足时,可以从CentralCache获取内存块;当ThreadCache内存块过多时,可以放回CentralCache。由于CentralCache是共享的,所以它的访问是要加锁的。
- PageHeap:PageHeap是对堆内存的抽象,PageHeap存的也是若干链表,链表保存的是Span。当CentralCache的内存不足时,会从PageHeap获取空闲的内存Span,然后把1个Span拆成若干内存块,添加到对应大小的链表中并分配内存;当CentralCache的内存过多时,会把空闲的内存块放回PageHeap中。
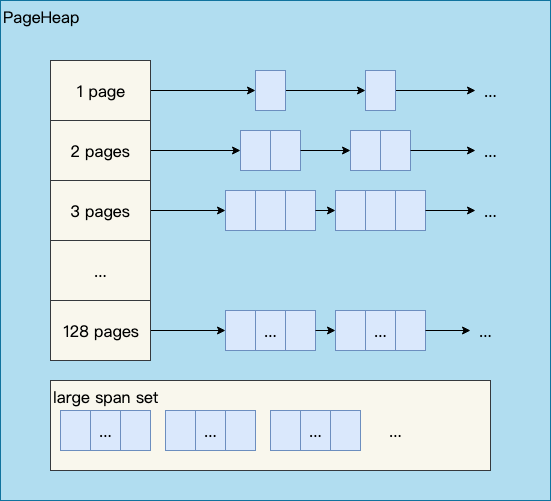
如下图所示,分别是1页Page的Span链表,2页Page的Span链表等,最后是large span set,这个是用来保存中大对象的。毫无疑问,PageHeap也是要加锁的。
前文提到了小、中、大对象,Go内存管理中也有类似的概念,我们看一眼TCMalloc的定义:
- 小对象大小:0~256KB
- 中对象大小:257~1MB
- 大对象大小:>1MB
小对象的分配流程:ThreadCache -> CentralCache -> HeapPage,大部分时候,ThreadCache缓存都是足够的,不需要去访问CentralCache和HeapPage,无系统调用配合无锁分配,分配效率是非常高的。
中对象分配流程:直接在PageHeap中选择适当的大小即可,128 Page的Span所保存的最大内存就是1MB。
大对象分配流程:从large span set选择合适数量的页面组成span,用来存储数据。
3. Go内存管理
前文提到Go内存管理源自TCMalloc,但它比TCMalloc还多了2件东西:逃逸分析和垃圾回收,这是2项提高生产力的绝佳武器。这一大章节,我们先介绍Go内存管理和Go内存分配,最后涉及一点垃圾回收和内存释放。
3.1. Go内存管理的基本概念
Go内存管理的许多概念在TCMalloc中已经有了,含义是相同的,只是名字有一些变化。先给大家上一幅宏观的图,借助图一起来介绍。

- Page:与TCMalloc中的Page相同,x64架构下1个Page的大小是8KB。上图的最下方,1个浅蓝色的长方形代表1个Page。
- Span:Span与TCMalloc中的Span相同,Span是内存管理的基本单位,代码中为mspan,一组连续的Page组成1个Span,所以上图一组连续的浅蓝色长方形代表的是一组Page组成的1个Span,另外,1个淡紫色长方形为1个Span。
- mcache:mcache与TCMalloc中的ThreadCache类似,mcache保存的是各种大小的Span,并按Span class分类,小对象直接从mcache分配内存,它起到了缓存的作用,并且可以无锁访问。但是mcache与ThreadCache也有不同点,TCMalloc中是每个线程1个ThreadCache,Go中是每个P拥有1个mcache。因为在Go程序中,当前最多有GOMAXPROCS个线程在运行,所以最多需要GOMAXPROCS个mcache就可以保证各线程对mcache的无锁访问,线程的运行又是与P绑定的,把mcache交给P刚刚好。
- mcentral:mcentral与TCMalloc中的CentralCache类似,是所有线程共享的缓存,需要加锁访问。它按Span级别对Span分类,然后串联成链表,当mcache的某个级别Span的内存被分配光时,它会向mcentral申请1个当前级别的Span。但是mcentral与CentralCache也有不同点,CentralCache是每个级别的Span有1个链表,mcache是每个级别的Span有2个链表,这和mcache申请内存有关,稍后我们再解释。
- mheap:mheap与TCMalloc中的PageHeap类似,它是堆内存的抽象,把从OS申请出的内存页组织成Span,并保存起来。当mcentral的Span不够用时会向mheap申请内存,而mheap的Span不够用时会向OS申请内存。mheap向OS的内存申请是按页来的,然后把申请来的内存页生成Span组织起来,同样也是需要加锁访问的。但是mheap与PageHeap也有不同点:mheap把Span组织成了树结构,而不是链表,并且还是2棵树,然后把Span分配到heapArena进行管理,它包含地址映射和span是否包含指针等位图,这样做的主要原因是为了更高效的利用内存:分配、回收和再利用。
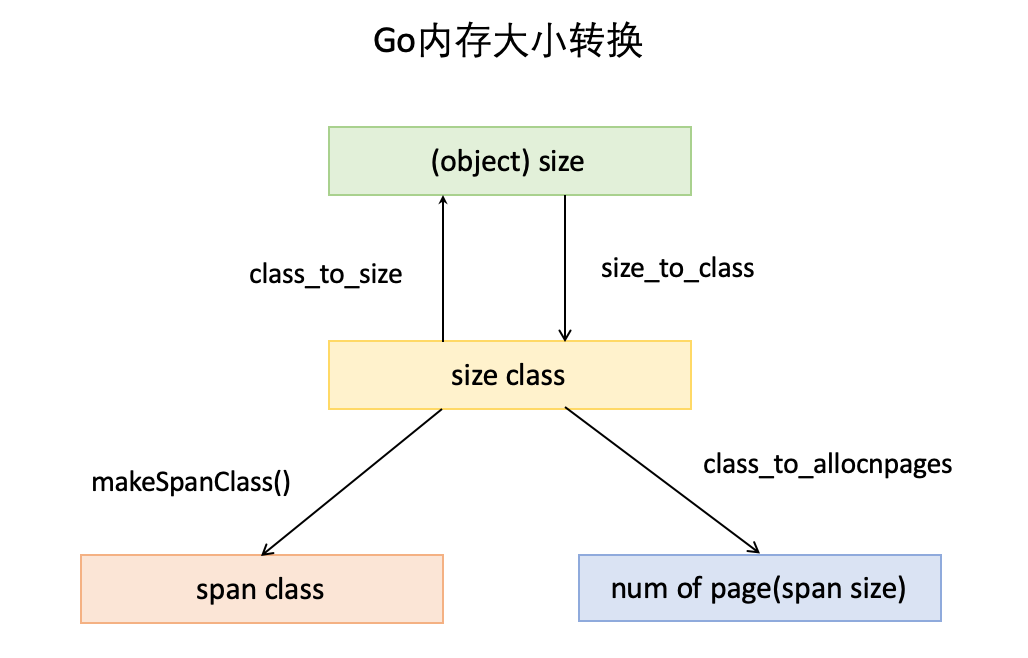
- object size:代码里简称size,指申请内存的对象大小。
- size class:代码里简称class,它是size的级别,相当于把size归类到一定大小的区间段,比如size[1,8]属于size class 1,size(8,16]属于size class 2。
- span class:指span的级别,但span class的大小与span的大小并没有正比关系。span class主要用来和size class做对应,1个size class对应2个span class,2个span class的span大小相同,只是功能不同,1个用来存放包含指针的对象,一个用来存放不包含指针的对象,不包含指针对象的Span就无需GC扫描了。
- num of page:代码里简称npage,代表Page的数量,其实就是Span包含的页数,用来分配内存。
3.2. Go内存分配
Go中的内存分类并不像TCMalloc那样分成小、中、大对象,但是它的小对象里又细分了一个Tiny对象,Tiny对象指大小在1Byte到16Byte之间并且不包含指针的对象。小对象和大对象只用大小划定,无其他区分。
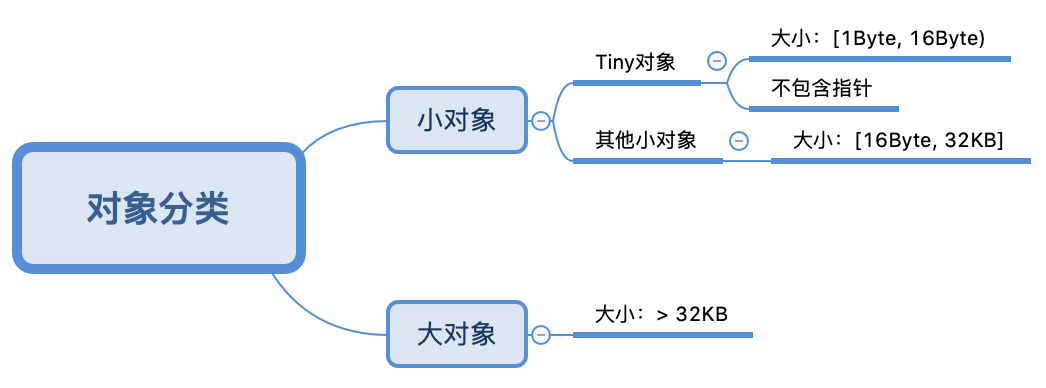
小对象是在mcache中分配的,而大对象是直接从mheap分配的,从小对象的内存分配看起。
3.1.1. 小对象的内存分配
大小转换这一小节,我们介绍了转换表,size class从1到66共66个,代码中_NumSizeClasses=67代表了实际使用的size class数量,即67个,从0到67,size class 0实际并未使用到。
上文提到1个size class对应2个span class:
numSpanClasses = _NumSizeClasses * 2
numSpanClasses为span class的数量为134个,所以span class的下标是从0到133,所以上图中mcache标注了的span class是,span class 0到span class 133。每1个span class都指向1个span,也就是mcache最多有134个span。
为对象寻找span
寻找span的流程如下:
- 计算对象所需内存大小size
- 根据size到size class映射,计算出所需的size class
- 根据size class和对象是否包含指针计算出span class
- 获取该span class指向的span
以分配一个不包含指针的,大小为24Byte的对象为例,根据映射表:
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// 4 48 8192 170 32 31.52%
对应的size class为3,它的对象大小范围是(16,32]Byte,24Byte刚好在此区间,所以此对象的size class为3。
Size class到span class的计算如下:
// noscan为true代表对象不包含指针
func makeSpanClass(sizeclass uint8, noscan bool) spanClass {
return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
}
所以对应的span class为7,所以该对象需要的是span class 7指向的span。
span class = 3 << 1 | 1 = 7
从span分配对象空间
Span可以按对象大小切成很多份,这些都可以从映射表上计算出来,以size class 3对应的span为例,span大小是8KB,每个对象实际所占空间为32Byte,这个span就被分成了256块,可以根据span的起始地址计算出每个对象块的内存地址。

随着内存的分配,span中的对象内存块,有些被占用,有些未被占用,比如上图,整体代表1个span,蓝色块代表已被占用内存,绿色块代表未被占用内存。当分配内存时,只要快速找到第一个可用的绿色块,并计算出内存地址即可,如果需要还可以对内存块数据清零。
当span内的所有内存块都被占用时,没有剩余空间继续分配对象,mcache会向mcentral申请1个span,mcache拿到span后继续分配对象。
mcache向mcentral申请span
mcentral和mcache一样,都是0~133这134个span class级别,但每个级别都保存了2个span list,即2个span链表:
- nonempty:这个链表里的span,所有span都至少有1个空闲的对象空间。这些span是mcache释放span时加入到该链表的。
- empty:这个链表里的span,所有的span都不确定里面是否有空闲的对象空间。当一个span交给mcache的时候,就会加入到empty链表。
这两个东西名称一直有点绕,建议直接把empty理解为没有对象空间就好了。
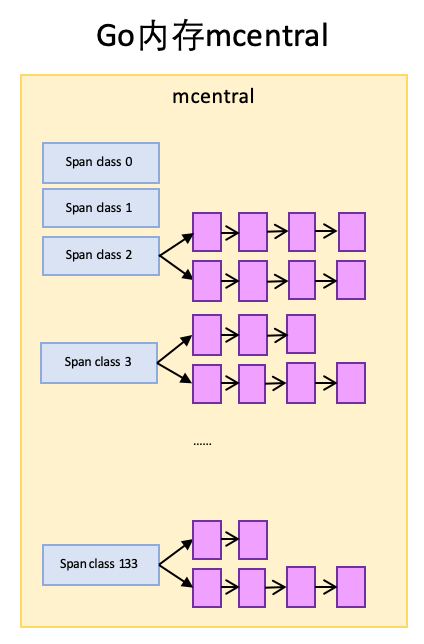
mcache向mcentral申请span时,mcentral会先从nonempty搜索满足条件的span,如果没有找到再从emtpy搜索满足条件的span,然后把找到的span交给mcache。
mheap的span管理
mheap里保存了两棵二叉排序树,按span的page数量进行排序:
- free:free中保存的span是空闲并且非垃圾回收的span。
- scav:scav中保存的是空闲并且已经垃圾回收的span。
如果是垃圾回收导致的span释放,span会被加入到scav,否则加入到free,比如刚从OS申请的的内存也组成的Span。
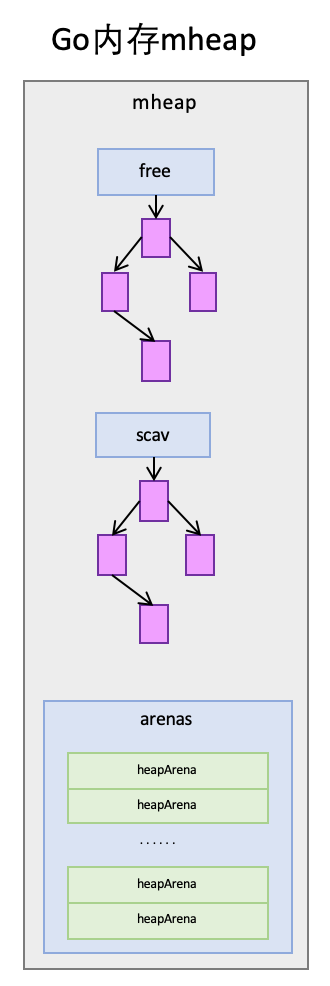
mheap中还有arenas,由一组heapArena组成,每一个heapArena都包含了连续的pagesPerArena个span,这个主要是为mheap管理span和垃圾回收服务。mheap本身是一个全局变量,它里面的数据,也都是从OS直接申请来的内存,并不在mheap所管理的那部分内存以内。
mcentral向mheap申请span
当mcentral向mcache提供span时,如果empty里也没有符合条件的span,mcentral会向mheap申请span。
此时,mcentral需要向mheap提供需要的内存页数和span class级别,然后它优先从free中搜索可用的span。如果没有找到,会从scav中搜索可用的span。如果还没有找到,它会向OS申请内存,再重新搜索2棵树,必然能找到span。如果找到的span比需要的span大,则把span进行分割成2个span,其中1个刚好是需求大小,把剩下的span再加入到free中去,然后设置需要的span的基本信息,然后交给mcentral。
mheap向OS申请内存
当mheap没有足够的内存时,mheap会向OS申请内存,把申请的内存页保存为span,然后把span插入到free树。在32位系统中,mheap还会预留一部分空间,当mheap没有空间时,先从预留空间申请,如果预留空间内存也没有了,才向OS申请。
3.1.2. 大对象的内存分配
大对象的分配比小对象省事多了,99%的流程与mcentral向mheap申请内存的相同,所以不重复介绍了。不同的一点在于mheap会记录一点大对象的统计信息,详情见mheap.alloc_m()。
3.2. Go垃圾回收和内存释放
如果只申请和分配内存,内存终将枯竭。Go使用垃圾回收收集不再使用的span,调用mspan.scavenge()把span释放还给OS(并非真释放,只是告诉OS这片内存的信息无用了,如果你需要的话,收回去好了),然后交给mheap,mheap对span进行span的合并,把合并后的span加入scav树中,等待再分配内存时,由mheap进行内存再分配,Go垃圾回收也是一个很强的主题,计划后面单独写一篇文章介绍。
现在我们关注一下,Go程序是怎么把内存释放给操作系统的?释放内存的函数是sysUnused,它会被mspan.scavenge()调用:
func sysUnused(v unsafe.Pointer, n uintptr) {
// MADV_FREE_REUSABLE is like MADV_FREE except it also propagates
// accounting information about the process to task_info.
madvise(v, n, _MADV_FREE_REUSABLE)
}
注释说 _MADV_FREE_REUSABLE 与 MADV_FREE 的功能类似,它的功能是给内核提供一个建议:这个内存地址区间的内存已经不再使用,可以进行回收。但内核是否回收,以及什么时候回收,这就是内核的事情了。如果内核真把这片内存回收了,当Go程序再使用这个地址时,内核会重新进行虚拟地址到物理地址的映射。所以在内存充足的情况下,内核也没有必要立刻回收内存。
4. Go的栈内存
最后提一下栈内存。从一个宏观的角度看,内存管理不应当只有堆,也应当有栈。每个goroutine都有自己的栈,栈的初始大小是2KB,100万的goroutine会占用2G,但goroutine的栈会在2KB不够用时自动扩容,当扩容为4KB的时候,百万goroutine会占用4GB。
总结
Go的内存分配原理就不再回顾了,它主要强调两个重要的思想:
- 使用缓存提高效率。在存储的整个体系中到处可见缓存的思想,Go内存分配和管理也使用了缓存,利用缓存一是减少了系统调用的次数,二是降低了锁的粒度、减少加锁的次数,从这2点提高了内存管理效率。
- 以空间换时间,提高内存管理效率。空间换时间是一种常用的性能优化思想,这种思想其实非常普遍,比如Hash、Map、二叉排序树等数据结构的本质就是空间换时间,在数据库中也很常见,比如数据库索引、索引视图和数据缓存等,再如Redis等缓存数据库也是空间换时间的思想。
Golang之变量去哪儿
写过C/C++的同学都知道,调用著名的malloc和new函数可以在堆上分配一块内存,这块内存的使用和销毁的责任都在程序员。一不小心,就会发生内存泄露,搞得胆战心惊。
切换到Golang后,基本不会担心内存泄露了。虽然也有new函数,但是使用new函数得到的内存不一定就在堆上。堆和栈的区别对程序员“模糊化”了,当然这一切都是Go编译器在背后帮我们完成的。
一个变量是在堆上分配,还是在栈上分配,是经过编译器的逃逸分析之后得出的结论。
这篇文章,就将带领大家一起去探索逃逸分析——变量到底去哪儿,堆还是栈?
什么是逃逸分析
以前写C/C++代码时,为了提高效率,常常将pass-by-value(传值)“升级”成pass-by-reference,企图避免构造函数的运行,并且直接返回一个指针。
你一定还记得,这里隐藏了一个很大的坑:在函数内部定义了一个局部变量,然后返回这个局部变量的地址(指针)。这些局部变量是在栈上分配的(静态内存分配),一旦函数执行完毕,变量占据的内存会被销毁,任何对这个返回值作的动作(如解引用),都将扰乱程序的运行,甚至导致程序直接崩溃。比如下面的这段代码:
int *foo ( void )
{
int t = 3;
return &t;
}
有些同学可能知道上面这个坑,用了个更聪明的做法:在函数内部使用new函数构造一个变量(动态内存分配),然后返回此变量的地址。因为变量是在堆上创建的,所以函数退出时不会被销毁。但是,这样就行了吗?new出来的对象该在何时何地delete呢?调用者可能会忘记delete或者直接拿返回值传给其他函数,之后就再也不能delete它了,也就是发生了内存泄露。关于这个坑,大家可以去看看《Effective C++》条款21,讲得非常好!
C是公认的语法最复杂的语言,据说没有人可以完全掌握C的语法。而这一切在Go语言中就大不相同了。像上面示例的C++代码放到Go里,没有任何问题。
你表面的光鲜,一定是背后有很多人为你撑起的!Go语言里就是编译器的逃逸分析。它是编译器执行静态代码分析后,对内存管理进行的优化和简化。
在编译原理中,分析指针动态范围的方法称之为逃逸分析。通俗来讲,当一个对象的指针被多个方法或线程引用时,我们称这个指针发生了逃逸。
更简单来说,逃逸分析决定一个变量是分配在堆上还是分配在栈上。
为什么要逃逸分析
前面讲的C/C中出现的问题,在Go中作为一个语言特性被大力推崇。真是C/C之砒霜Go之蜜糖!
C/C++中动态分配的内存需要我们手动释放,导致猿们平时在写程序时,如履薄冰。这样做有他的好处:程序员可以完全掌控内存。但是缺点也是很多的:经常出现忘记释放内存,导致内存泄露。所以,很多现代语言都加上了垃圾回收机制。
Go的垃圾回收,让堆和栈对程序员保持透明。真正解放了程序员的双手,让他们可以专注于业务,“高效”地完成代码编写。把那些内存管理的复杂机制交给编译器,而程序员可以去享受生活。
逃逸分析这种“骚操作”把变量合理地分配到它该去的地方,“找准自己的位置”。即使你是用new申请到的内存,如果我发现你竟然在退出函数后没有用了,那么就把你丢到栈上,毕竟栈上的内存分配比堆上快很多;反之,即使你表面上只是一个普通的变量,但是经过逃逸分析后发现在退出函数之后还有其他地方在引用,那我就把你分配到堆上。真正地做到“按需分配”
如果变量都分配到堆上,堆不像栈可以自动清理。它会引起Go频繁地进行垃圾回收,而垃圾回收会占用比较大的系统开销(占用CPU容量的25%)。
堆和栈相比,堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片。栈内存分配则会非常快。栈分配内存只需要两个CPU指令:“PUSH”和“RELEASSE”,分配和释放;而堆分配内存首先需要去找到一块大小合适的内存块,之后要通过垃圾回收才能释放。
通过逃逸分析,可以尽量把那些不需要分配到堆上的变量直接分配到栈上,堆上的变量少了,会减轻分配堆内存的开销,同时也会减少gc的压力,提高程序的运行速度。
逃逸分析是怎么完成的
Go逃逸分析最基本的原则是:如果一个函数返回对一个变量的引用,那么它就会发生逃逸。
简单来说,编译器会分析代码的特征和代码生命周期,Go中的变量只有在编译器可以证明在函数返回后不会再被引用的,才分配到栈上,其他情况下都是分配到堆上。
Go语言里没有一个关键字或者函数可以直接让变量被编译器分配到堆上,相反,编译器通过分析代码来决定将变量分配到何处。
对一个变量取地址,可能会被分配到堆上。但是编译器进行逃逸分析后,如果考察到在函数返回后,此变量不会被引用,那么还是会被分配到栈上。套个取址符,就想骗补助?Too young!
简单来说,编译器会根据变量是否被外部引用来决定是否逃逸:
如果函数外部没有引用,则优先放到栈中;
如果函数外部存在引用,则必定放到堆中;
针对第一条,可能放到堆上的情形:定义了一个很大的数组,需要申请的内存过大,超过了栈的存储能力。
逃逸分析实例
Go提供了相关的命令,可以查看变量是否发生逃逸。
还是用上面我们提到的例子:
package main
import "fmt"
func foo() *int {
t := 3
return &t;
}
func main() {
x := foo()
fmt.Println(*x)
}
foo函数返回一个局部变量的指针,main函数里变量x接收它。执行如下命令:
go build -gcflags '-m -l' main.go
加-l是为了不让foo函数被内联。得到如下输出:
# command-line-arguments
src/main.go:7:9: &t escapes to heap
src/main.go:6:7: moved to heap: t
src/main.go:12:14: *x escapes to heap
src/main.go:12:13: main ... argument does not escape
foo函数里的变量t逃逸了,和我们预想的一致。让我们不解的是为什么main函数里的x也逃逸了?这是因为有些函数参数为interface类型,比如fmt.Println(a ...interface{}),编译期间很难确定其参数的具体类型,也会发生逃逸。
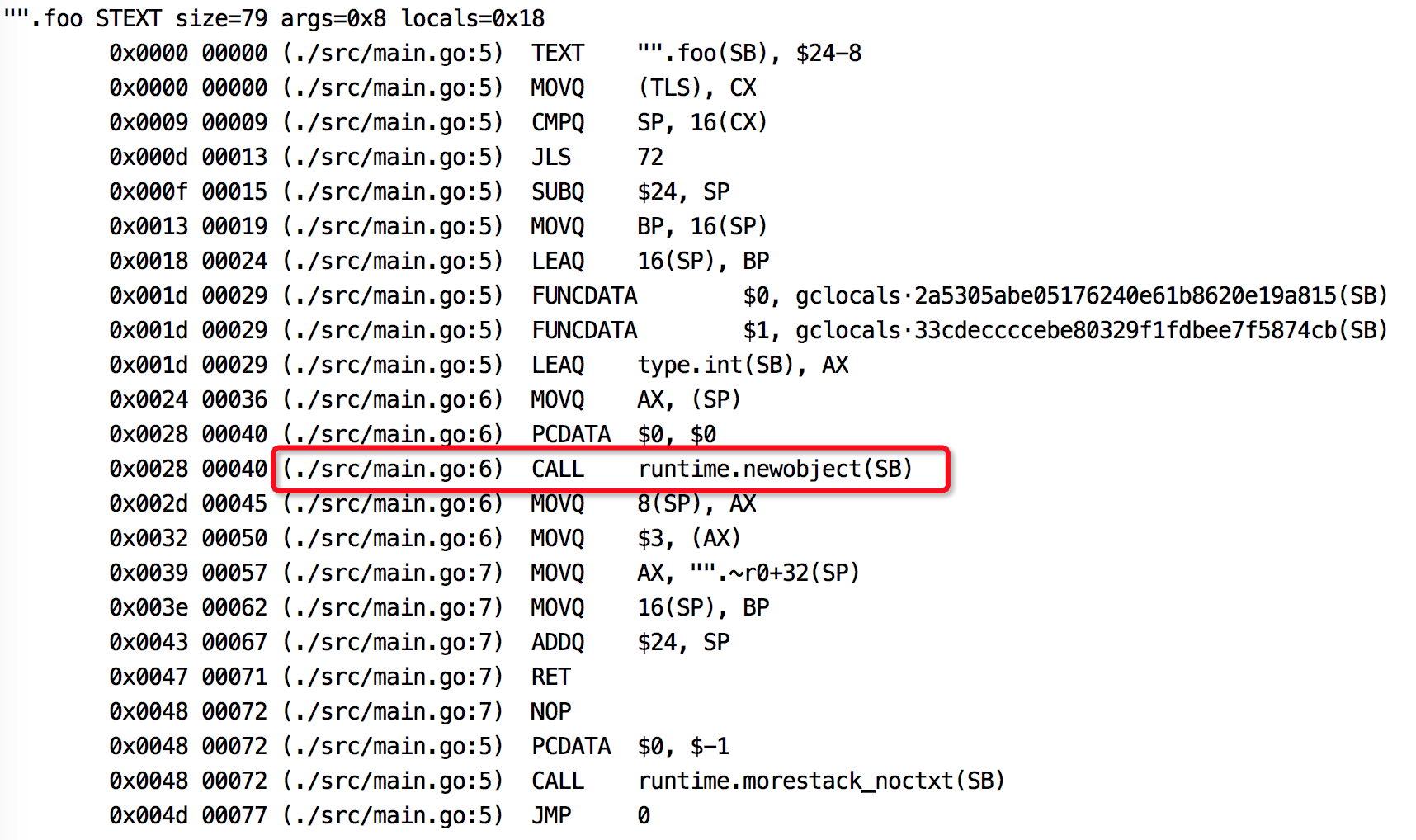
使用反汇编命令也可以看出变量是否发生逃逸。
go tool compile -S main.go
截取部分结果,图中标记出来的说明t是在堆上分配内存,发生了逃逸。
总结
堆上动态分配内存比栈上静态分配内存,开销大很多。
变量分配在栈上需要能在编译期确定它的作用域,否则会分配到堆上。
Go编译器会在编译期对考察变量的作用域,并作一系列检查,如果它的作用域在运行期间对编译器一直是可知的,那么就会分配到栈上。
简单来说,编译器会根据变量是否被外部引用来决定是否逃逸。对于Go程序员来说,编译器的这些逃逸分析规则不需要掌握,我们只需通过go build -gcflags '-m'命令来观察变量逃逸情况就行了。
不要盲目使用变量的指针作为函数参数,虽然它会减少复制操作。但其实当参数为变量自身的时候,复制是在栈上完成的操作,开销远比变量逃逸后动态地在堆上分配内存少的多。
最后,尽量写出少一些逃逸的代码,提升程序的运行效率。
图解Go语言内存分配
Go语言内置运行时(就是runtime),抛弃了传统的内存分配方式,改为自主管理。这样可以自主地实现更好的内存使用模式,比如内存池、预分配等等。这样,不会每次内存分配都需要进行系统调用。
Golang运行时的内存分配算法主要源自 Google 为 C 语言开发的TCMalloc算法,全称Thread-Caching Malloc。核心思想就是把内存分为多级管理,从而降低锁的粒度。它将可用的堆内存采用二级分配的方式进行管理:每个线程都会自行维护一个独立的内存池,进行内存分配时优先从该内存池中分配,当内存池不足时才会向全局内存池申请,以避免不同线程对全局内存池的频繁竞争。
基础概念
Go在程序启动的时候,会先向操作系统申请一块内存(注意这时还只是一段虚拟的地址空间,并不会真正地分配内存),切成小块后自己进行管理。
申请到的内存块被分配了三个区域,在X64上分别是512MB,16GB,512GB大小。
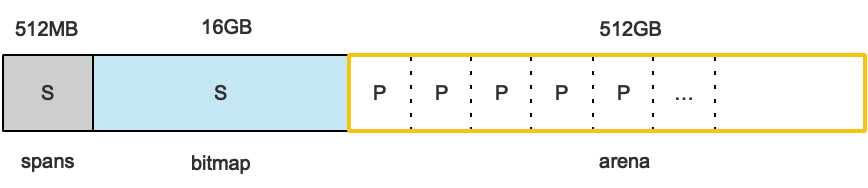
arena区域就是我们所谓的堆区,Go动态分配的内存都是在这个区域,它把内存分割成8KB大小的页,一些页组合起来称为mspan。
bitmap区域标识arena区域哪些地址保存了对象,并且用4bit标志位表示对象是否包含指针、GC标记信息。bitmap中一个byte大小的内存对应arena区域中4个指针大小(指针大小为 8B )的内存,所以bitmap区域的大小是512GB/(4*8B)=16GB。
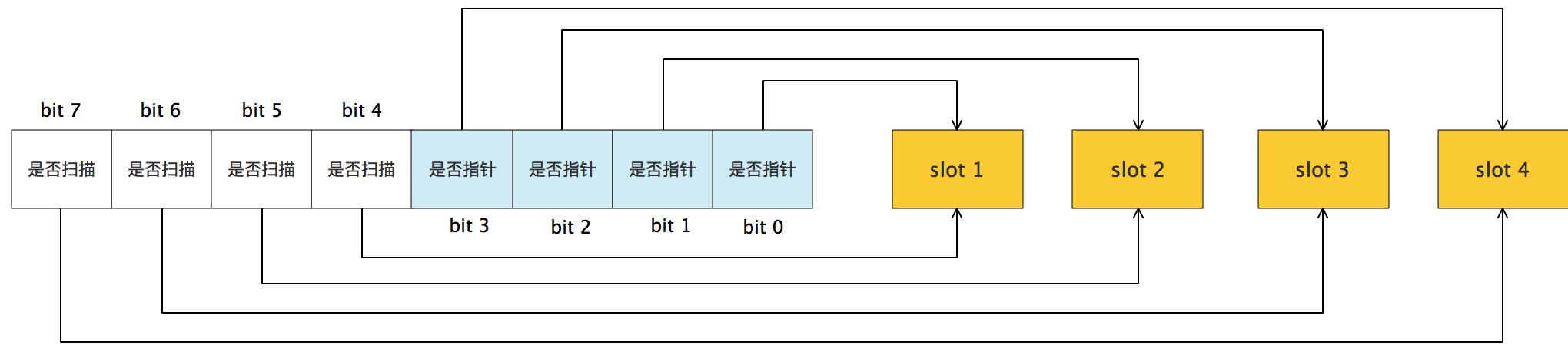
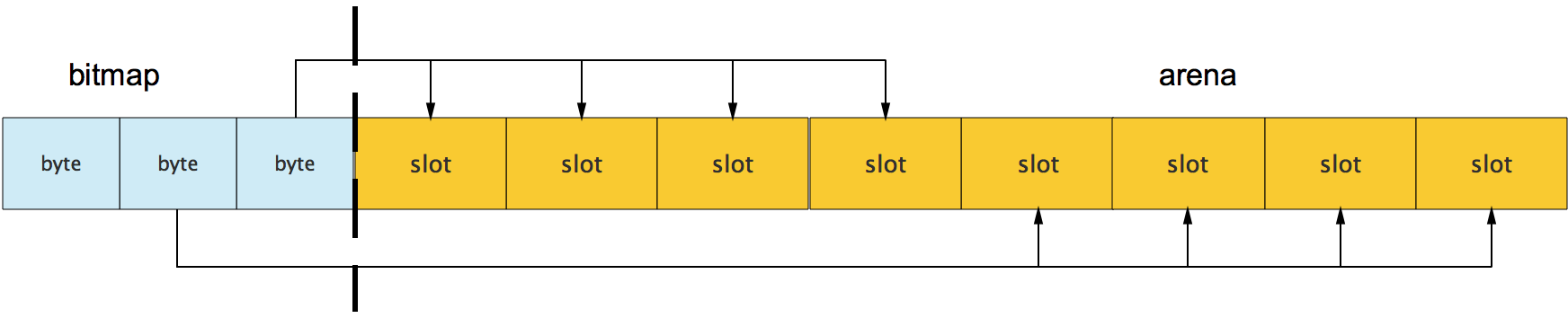
从上图其实还可以看到bitmap的高地址部分指向arena区域的低地址部分,也就是说bitmap的地址是由高地址向低地址增长的。
spans区域存放mspan(也就是一些arena分割的页组合起来的内存管理基本单元,后文会再讲)的指针,每个指针对应一页,所以spans区域的大小就是512GB/8KB*8B=512MB。除以8KB是计算arena区域的页数,而最后乘以8是计算spans区域所有指针的大小。创建mspan的时候,按页填充对应的spans区域,在回收object时,根据地址很容易就能找到它所属的mspan。
内存管理单元
mspan:Go中内存管理的基本单元,是由一片连续的8KB的页组成的大块内存。注意,这里的页和操作系统本身的页并不是一回事,它一般是操作系统页大小的几倍。一句话概括:mspan是一个包含起始地址、mspan规格、页的数量等内容的双端链表。
每个mspan按照它自身的属性Size Class的大小分割成若干个object,每个object可存储一个对象。并且会使用一个位图来标记其尚未使用的object。属性Size Class决定object大小,而mspan只会分配给和object尺寸大小接近的对象,当然,对象的大小要小于object大小。还有一个概念:Span Class,它和Size Class的含义差不多,
这是因为其实每个 Size Class有两个mspan,也就是有两个Span Class。其中一个分配给含有指针的对象,另一个分配给不含有指针的对象。这会给垃圾回收机制带来利好,之后的文章再谈。
如下图,mspan由一组连续的页组成,按照一定大小划分成object。
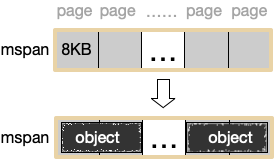
Go1.9.2里mspan的Size Class共有67种,每种mspan分割的object大小是8*2n的倍数,这个是写死在代码里的:
// path: /usr/local/go/src/runtime/sizeclasses.go
const _NumSizeClasses = 67
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536,1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
根据mspan的Size Class可以得到它划分的object大小。 比如Size Class等于3,object大小就是32B。 32B大小的object可以存储对象大小范围在17B~32B的对象。而对于微小对象(小于16B),分配器会将其进行合并,将几个对象分配到同一个object中。
数组里最大的数是32768,也就是32KB,超过此大小就是大对象了,它会被特别对待,这个稍后会再介绍。顺便提一句,类型Size Class为0表示大对象,它实际上直接由堆内存分配,而小对象都要通过mspan来分配。
对于mspan来说,它的Size Class会决定它所能分到的页数,这也是写死在代码里的:
// path: /usr/local/go/src/runtime/sizeclasses.go
const _NumSizeClasses = 67
var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 3, 2, 3, 1, 3, 2, 3, 4, 5, 6, 1, 7, 6, 5, 4, 3, 5, 7, 2, 9, 7, 5, 8, 3, 10, 7, 4}
比如当我们要申请一个object大小为32B的mspan的时候,在class_to_size里对应的索引是3,而索引3在class_to_allocnpages数组里对应的页数就是1。
mspan结构体定义:
// path: /usr/local/go/src/runtime/mheap.go
type mspan struct {
//链表前向指针,用于将span链接起来
next *mspan
//链表前向指针,用于将span链接起来
prev *mspan
// 起始地址,也即所管理页的地址
startAddr uintptr
// 管理的页数
npages uintptr
// 块个数,表示有多少个块可供分配
nelems uintptr
//分配位图,每一位代表一个块是否已分配
allocBits *gcBits
// 已分配块的个数
allocCount uint16
// class表中的class ID,和Size Classs相关
spanclass spanClass
// class表中的对象大小,也即块大小
elemsize uintptr
}
我们将mspan放到更大的视角来看:
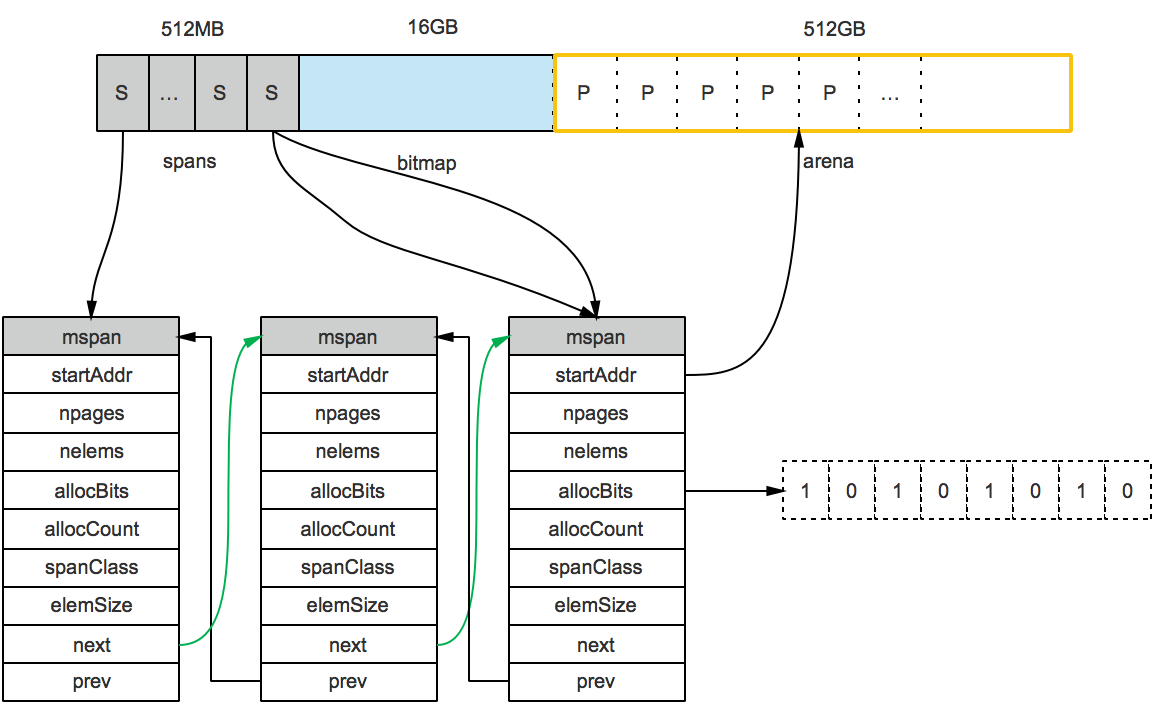
上图可以看到有两个S指向了同一个mspan,因为这两个S指向的P是同属一个mspan的。所以,通过arena上的地址可以快速找到指向它的S,通过S就能找到mspan,回忆一下前面我们说的mspan区域的每个指针对应一页。
假设最左边第一个mspan的Size Class等于10,根据前面的class_to_size数组,得出这个msapn分割的object大小是144B,算出可分配的对象个数是8KB/144B=56.89个,取整56个,所以会有一些内存浪费掉了,Go的源码里有所有Size Class的mspan浪费的内存的大小;再根据class_to_allocnpages数组,得到这个mspan只由1个page组成;假设这个mspan是分配给无指针对象的,那么spanClass等于20。
startAddr直接指向arena区域的某个位置,表示这个mspan的起始地址,allocBits指向一个位图,每位代表一个块是否被分配了对象;allocCount则表示总共已分配的对象个数。
这样,左起第一个mspan的各个字段参数就如下图所示:

内存管理组件
内存分配由内存分配器完成。分配器由3种组件构成:mcache, mcentral, mheap。
mcache
mcache:每个工作线程都会绑定一个mcache,本地缓存可用的mspan资源,这样就可以直接给Goroutine分配,因为不存在多个Goroutine竞争的情况,所以不会消耗锁资源。
mcache的结构体定义:
//path: /usr/local/go/src/runtime/mcache.go
type mcache struct {
alloc [numSpanClasses]*mspan
}
numSpanClasses = _NumSizeClasses << 1
mcache用Span Classes作为索引管理多个用于分配的mspan,它包含所有规格的mspan。它是_NumSizeClasses的2倍,也就是67*2=134,为什么有一个两倍的关系,前面我们提到过:为了加速之后内存回收的速度,数组里一半的mspan中分配的对象不包含指针,另一半则包含指针。
对于无指针对象的mspan在进行垃圾回收的时候无需进一步扫描它是否引用了其他活跃的对象。 后面的垃圾回收文章会再讲到,这次先到这里。
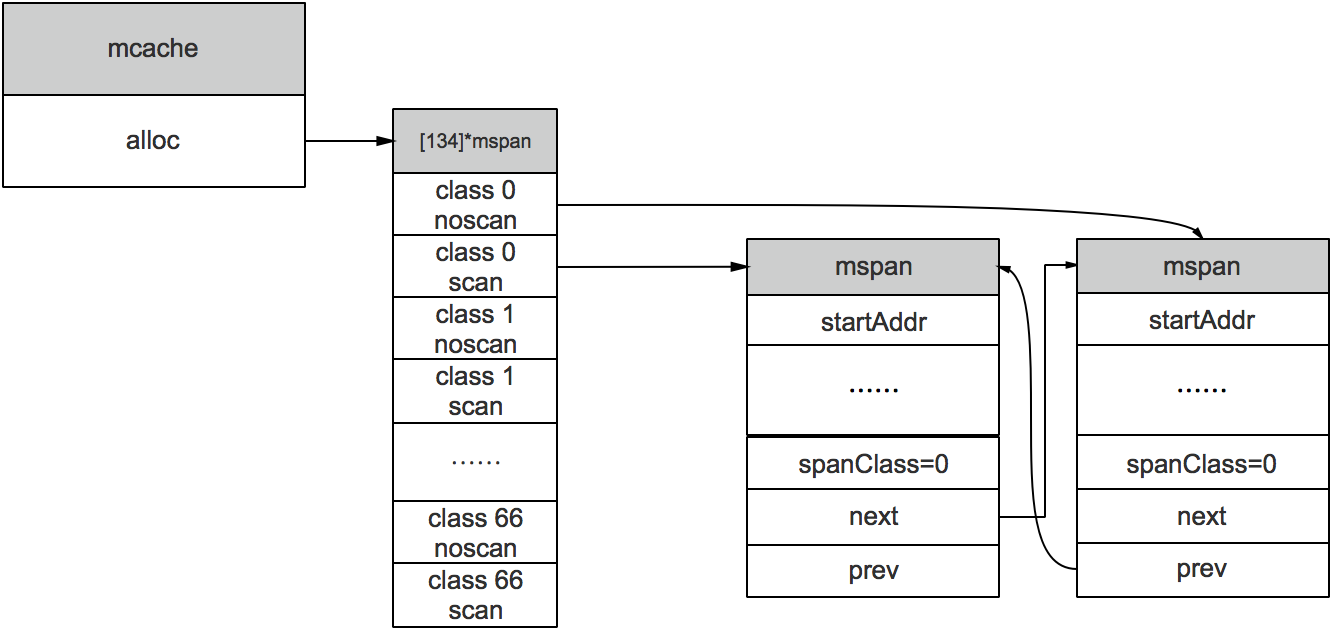
mcache在初始化的时候是没有任何mspan资源的,在使用过程中会动态地从mcentral申请,之后会缓存下来。当对象小于等于32KB大小时,使用mcache的相应规格的mspan进行分配。
mcentral
mcentral:为所有mcache提供切分好的mspan资源。每个central保存一种特定大小的全局mspan列表,包括已分配出去的和未分配出去的。 每个mcentral对应一种mspan,而mspan的种类导致它分割的object大小不同。当工作线程的mcache中没有合适(也就是特定大小的)的mspan时就会从mcentral获取。
mcentral被所有的工作线程共同享有,存在多个Goroutine竞争的情况,因此会消耗锁资源。结构体定义:
//path: /usr/local/go/src/runtime/mcentral.go
type mcentral struct {
// 互斥锁
lock mutex
// 规格
sizeclass int32
// 尚有空闲object的mspan链表
nonempty mSpanList
// 没有空闲object的mspan链表,或者是已被mcache取走的msapn链表
empty mSpanList
// 已累计分配的对象个数
nmalloc uint64
}
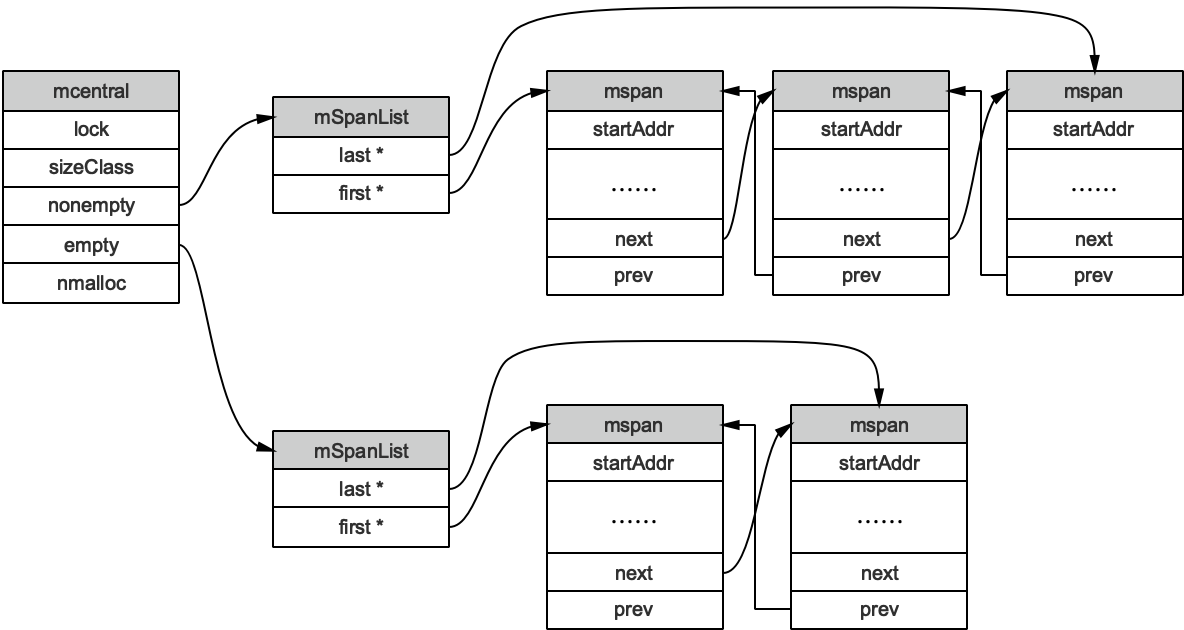
empty表示这条链表里的mspan都被分配了object,或者是已经被cache取走了的mspan,这个mspan就被那个工作线程独占了。而nonempty则表示有空闲对象的mspan列表。每个central结构体都在mheap中维护。
简单说下mcache从mcentral获取和归还mspan的流程:
- 获取,加锁;从nonempty链表找到一个可用的mspan;并将其从nonempty链表删除;将取出的mspan加入到empty链表;将mspan返回给工作线程;解锁。
- 归还,加锁;将mspan从empty链表删除;将mspan加入到nonempty链表;解锁。
mheap
mheap:代表Go程序持有的所有堆空间,Go程序使用一个mheap的全局对象_mheap来管理堆内存。
当mcentral没有空闲的mspan时,会向mheap申请。而mheap没有资源时,会向操作系统申请新内存。mheap主要用于大对象的内存分配,以及管理未切割的mspan,用于给mcentral切割成小对象。
同时我们也看到,mheap中含有所有规格的mcentral,所以,当一个mcache从mcentral申请mspan时,只需要在独立的mcentral中使用锁,并不会影响申请其他规格的mspan。
mheap结构体定义:
//path: /usr/local/go/src/runtime/mheap.go
type mheap struct {
lock mutex
// spans: 指向mspans区域,用于映射mspan和page的关系
spans []*mspan
// 指向bitmap首地址,bitmap是从高地址向低地址增长的
bitmap uintptr
// 指示arena区首地址
arena_start uintptr
// 指示arena区已使用地址位置
arena_used uintptr
// 指示arena区末地址
arena_end uintptr
central [67*2]struct {
mcentral mcentral
pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte
}
}
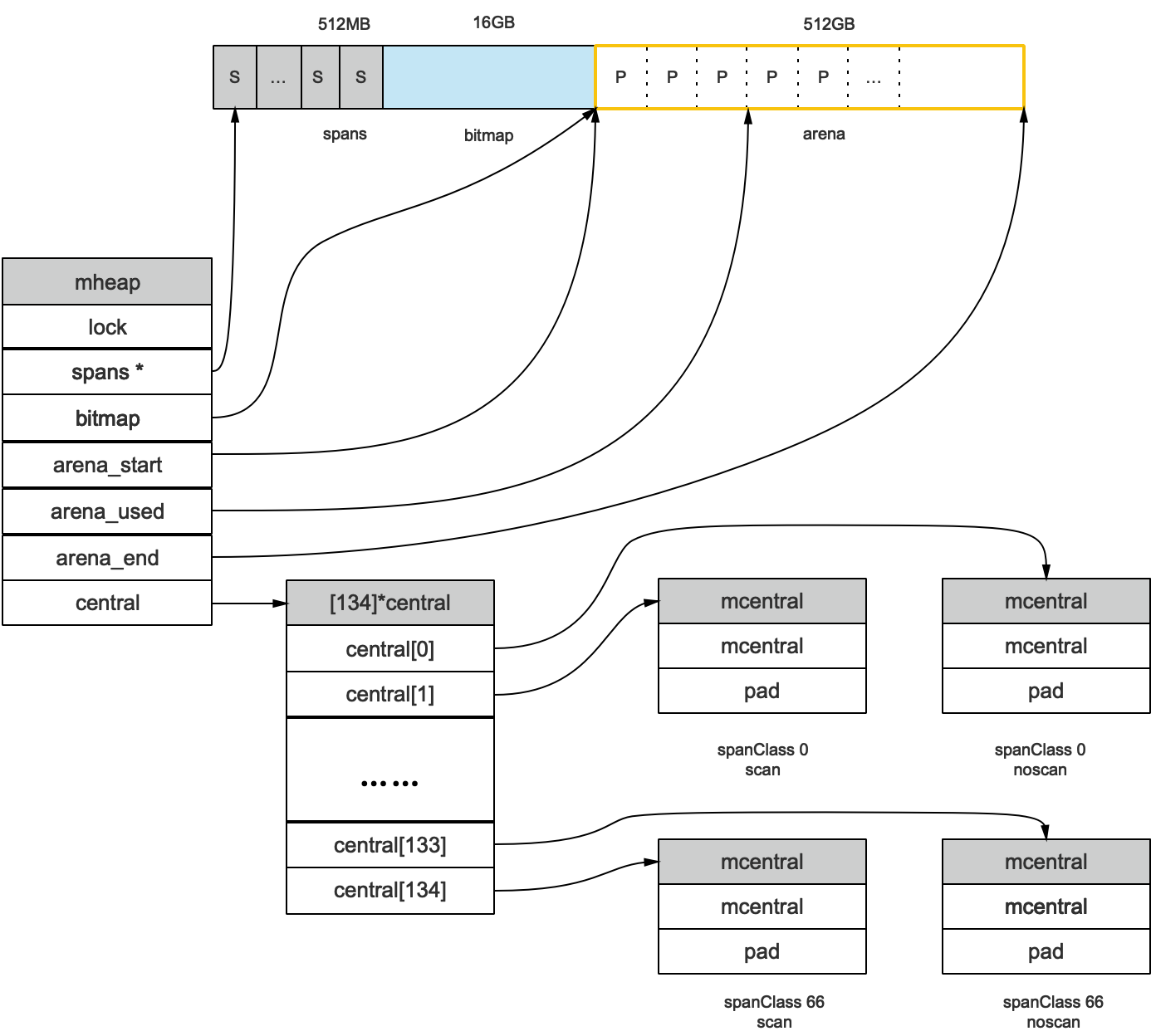
上图我们看到,bitmap和arena_start指向了同一个地址,这是因为bitmap的地址是从高到低增长的,所以他们指向的内存位置相同。
内存分配流程
上一篇文章《Golang之变量去哪儿》中我们提到了,变量是在栈上分配还是在堆上分配,是由逃逸分析的结果决定的。通常情况下,编译器是倾向于将变量分配到栈上的,因为它的开销小,最极端的就是"zero garbage",所有的变量都会在栈上分配,这样就不会存在内存碎片,垃圾回收之类的东西。
Go的内存分配器在分配对象时,根据对象的大小,分成三类:小对象(小于等于16B)、一般对象(大于16B,小于等于32KB)、大对象(大于32KB)。
大体上的分配流程:
- 32KB 的对象,直接从mheap上分配;
- <=16B 的对象使用mcache的tiny分配器分配;
- (16B,32KB] 的对象,首先计算对象的规格大小,然后使用mcache中相应规格大小的mspan分配;
- 如果mcache没有相应规格大小的mspan,则向mcentral申请
- 如果mcentral没有相应规格大小的mspan,则向mheap申请
- 如果mheap中也没有合适大小的mspan,则向操作系统申请
总结
Go语言的内存分配非常复杂,它的一个原则就是能复用的一定要复用。源码很难追,后面可能会再来一篇关于内存分配的源码阅读相关的文章。简单总结一下本文吧。
文章从一个比较粗的角度来看Go的内存分配,并没有深入细节。一般而言,了解它的原理,到这个程度也可以了。
- Go在程序启动时,会向操作系统申请一大块内存,之后自行管理。
- Go内存管理的基本单元是mspan,它由若干个页组成,每种mspan可以分配特定大小的object。
- mcache, mcentral, mheap是Go内存管理的三大组件,层层递进。mcache管理线程在本地缓存的mspan;mcentral管理全局的mspan供所有线程使用;mheap管理Go的所有动态分配内存。
- 极小对象会分配在一个object中,以节省资源,使用tiny分配器分配内存;一般小对象通过mspan分配内存;大对象则直接由mheap分配内存。
- Go语言区别于C/C++,虽然变量申请在堆空间上,但是它有自动回收垃圾的功能,所以这些堆地址空间也无需我们手动回收,系统会在需要释放的时刻自动进行垃圾回收。
- Go 语言中,包变量(全局变量) 一直常驻在内存中知道程序的结束,然后被系统垃圾回收,也就是说包变量的生命周期是整个程序的执行时间
- Go 语言中,局部变量 在函数中定于的变量,它有一个动态的生命周期:每次执行的时候就创建一个新的实体,一直生存到没有人使用(例如没有外部指针指向它,函数退出的时候没有路径访问到这个变量)这个时候它占用的空间就会被回收。结论:并不是定义在函数内部的局部变量在访问退出函数时候就被回收!