
如何在 Linux 上划分VLAN
在某些场景中,我们希望在Linux服务器(CentOS / RHEL)上的同一网卡分配来自不同VLAN的多个ip。这可以通过启用VLAN标记接口来实现,但要实现这一点,首先必须确保交换机上添加多个vlan。
假设我们有一个Linux服务器,其中有两个以太网卡(ens33和ens38),第一个网卡(ens33)用于数据流量,第二个网卡(ens38)用于控制/管理流量。对于数据流,将使用多个vlan(将在数据流网卡上分配来自不同vlan的多个ip)。
假设从交换机连接到服务器数据流量网卡的端口被配置为Trunk,通过映射多个vlan到它。下面是映射到数据流量网卡的vlan:
- VLAN ID (200),172.168.10.0/24
- VLAN ID (300),172.168.20.0/24
在CentOS 7 /RHEL 7 / CentOS 8 /RHEL 8系统上使用VLAN标记接口,必须加载内核模块8021q。
使用以下命令加载内核模块“8021q”
# 先列出模块,发现没有8021q模块。
lsmod | grep -i 8021q
# 加载模块
modprobe --first-time 8021q
lsmod | grep -i 8021q
8021q 33080 0
garp 14384 1 8021q
mrp 18542 1 8021q
使用modinfo命令列出8021q的信息:
modinfo 8021q
modinfo 8021q
filename: /lib/modules/4.18.0-305.19.1.el8_4.x86_64/kernel/net/8021q/8021q.ko.xz
version: 1.8
license: GPL
alias: rtnl-link-vlan
rhelversion: 8.4
srcversion: 9ED84410A02CB0DF7507067
depends: mrp,garp
intree: Y
name: 8021q
vermagic: 4.18.0-305.19.1.el8_4.x86_64 SMP mod_unload modversions
sig_id: PKCS#7
signer: CentOS kernel signing key
sig_key: 32:FE:47:EE:D6:E3:A6:7B:D5:8D:C6:22:34:2B:C6:16:72:D5:1C:52
sig_hashalgo: sha256
signature: ...
现在使用ip命令创建vlan 200和vlan 300到ens33网卡:
# 创建vlan 200和vlan 300
ip link add link ens33 name ens33.200 type vlan id 200
ip link add link ens33 name ens33.300 type vlan id 300
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:05:23:c2 brd ff:ff:ff:ff:ff:ff
inet 192.168.50.128/24 brd 192.168.50.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe05:23c2/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:05:23:cc brd ff:ff:ff:ff:ff:ff
4: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:05:23:d6 brd ff:ff:ff:ff:ff:ff
5: ens33.200@ens33: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 00:0c:29:05:23:c2 brd ff:ff:ff:ff:ff:ff
6: ens33.300@ens33: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 00:0c:29:05:23:c2 brd ff:ff:ff:ff:ff:ff
发现ens33.200和ens33.300的链路状态为DOWN,下面启用它们。
ip link set ens33.200 up
ip link set ens33.300 up
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:05:23:c2 brd ff:ff:ff:ff:ff:ff
inet 192.168.50.128/24 brd 192.168.50.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe05:23c2/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:05:23:cc brd ff:ff:ff:ff:ff:ff
4: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:05:23:d6 brd ff:ff:ff:ff:ff:ff
5: ens33.200@ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:0c:29:05:23:c2 brd ff:ff:ff:ff:ff:ff
inet6 fe80::20c:29ff:fe05:23c2/64 scope link
valid_lft forever preferred_lft forever
6: ens33.300@ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:0c:29:05:23:c2 brd ff:ff:ff:ff:ff:ff
inet6 fe80::20c:29ff:fe05:23c2/64 scope link tentative
valid_lft forever preferred_lft forever
下面为两个vlan 分配ip地址:
ip address add 172.168.10.51/24 dev ens33.200
ip address add 172.168.20.51/24 dev ens33.300
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:05:23:c2 brd ff:ff:ff:ff:ff:ff
inet 192.168.50.128/24 brd 192.168.50.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe05:23c2/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:05:23:cc brd ff:ff:ff:ff:ff:ff
4: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:05:23:d6 brd ff:ff:ff:ff:ff:ff
5: ens33.200@ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:0c:29:05:23:c2 brd ff:ff:ff:ff:ff:ff
inet 172.168.10.51/24 scope global ens33.200
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe05:23c2/64 scope link
valid_lft forever preferred_lft forever
6: ens33.300@ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:0c:29:05:23:c2 brd ff:ff:ff:ff:ff:ff
inet 172.168.20.51/24 scope global ens33.300
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe05:23c2/64 scope link
valid_lft forever preferred_lft forever
可以看到ens33.200和ens33.300已经配置好ip地址了。
但是上面使用ip address添加的VLAN和地址不会永久生效的。重启系统之后都不存在了。我们需要把这些配置保存在配置文件里面。
首先修改ifcfg-ens33的配置文件,其次创建ifcfg-ens33.200和ifcfg-ens33.300配置文件:
vim /etc/sysconfig/network-scripts/ifcfg-ens33.200
DEVICE=ens33.200
BOOTPROTO=none
ONBOOT=yes
IPADDR=172.168.10.51
PREFIX=24
NETWORK=172.168.10.0
VLAN=yes
vim /etc/sysconfig/network-scripts/ifcfg-ens33.300
DEVICE=ens33.300
BOOTPROTO=none
ONBOOT=yes
IPADDR=172.168.20.51
PREFIX=24
NETWORK=172.168.20.0
VLAN=yes
交换机常用的光模块及光接口
以太网交换机常用的光模块有SFP,GBIC,XFP,XENPAK。
- SFP:Small Form-factor Pluggabletransceiver ,小封装可插拔收发器
- GBIC:GigaBit Interface Converter,千兆以太网接口转换器
- XFP: 10-Gigabit small Form-factorPluggable transceiver 万兆以太网接口
- XENPAK: 10 Gigabit EtherNet TransceiverPAcKage万兆以太网接口收发器集合封装

光纤知识
光纤是传输光波的导体。光纤从光传输的模式来分可分为单模光纤和多模光纤。
在单模光纤中光传输只有一种基模模式,也就是说光线只沿光纤的内芯进行传输。由于完全避免了模式射散使得单模光纤的传输频带很宽因而适用于高速,长距离的光纤通讯。
在多模光纤中光传输有多个模式,由于色散或像差,这种光纤的传输性能较差,频带窄,传输速率较小,距离较短。
光纤的特性参数
光纤的结构预制的石英光纤棒拉制而成,通信用的多模光纤和单模光纤的外径都为125μm。
纤体分为两个区域:纤芯(Core)和包层(Cladding layer)。单模光纤纤芯直径为8~10μm,多模光纤纤芯径有两种标准规格,芯径分别为62.5μm(美国标准)和50μm(欧洲标准)。
接口光纤规格有这样的描述:62.5μm/125μm多模光纤,其中62.5μm就是指光纤的芯径,125μm就是指光纤的外径。
单模光纤使用的光波长为1310nm或1550 nm。
多模光纤使用的光波长多为850 nm。
从颜色上可以区分单模光纤和多模光纤。单模光纤外体为黄色,多模光纤外体为橘红色。
多模和单模光纤的区别
多模:可以传播数百到上千个模式的光纤,称为多模(MM)光纤。根据折射率在纤芯和包层的径向分布情况,又可分为阶跃多模光纤和渐变多模光纤。几乎所有的多模光纤尺寸均为50/125μm或62.5/125μm,并且带宽(光纤的信息传输量)通常为200MHz到2GHz。多模光端机通过多模光纤可进行长达5公里的传输。以发光二极管或激光器为光源。
单模:只能传播一个模式的光纤称为单模光纤。标准单模(SM)光纤折射率分布和阶跃型光纤相似,只是纤芯直径比多模光纤小得多。
单模光纤的尺寸为9-10/125μm,并且较之多模光纤具有无限量带宽和更低损耗的特性。而单模光端机多用于长距离传输,有时可达到150至200公里。采用LD或光谱线较窄的LED作为光源。
使用光缆时传输损耗如何?
这取决于传输光的波长以及所使用光纤的种类。
- 850nm波长用于多模光纤时: 3.0分贝/公里
- 1310nm波长用于多模光纤时: 1.0分贝/公里
- 1310nm波长用于单模光纤时: 0.4分贝/公里
- 1550nm波长用于单模光纤时: 0.2分贝/公里
单模/多模光纤可以和单模/多模光模块可以混用吗?
|光模块类型|光纤类型| 是否可以正常工作|
|-|-|-|
|单模光模块|多模光纤|短距离可以工作,但无法保障效果|
|单模光模块|单模光纤|正常工作|
|多模光模块|单模光纤|无法工作|
|多模光模块|多模光纤|正常工作|
多模光纤能和单模光模块一起使用吗?如果不能,那么原因是什么?
答:不能。多模光纤最好和多模光模块一起使用,因为多模和单模的转换器必须是相应的波长和光收发功能才能实现光电转换,所以多模光纤能和单模光模块一起使用无法保障使用效果。
如何实现VLAN间三层通信呢
通过路由器为每个VLAN分配一个物理接口实现VLAN间通信
实现方法:在路由器上为每个VLAN分配一个单独的接口,并使用一条物理链路连接到二层交换机上。
当VLAN间的主机需要通信时,数据会经由路由器进行三层路由,并被转发到目的VLAN内的主机,这样就可以实现VLAN之间的相互通信。
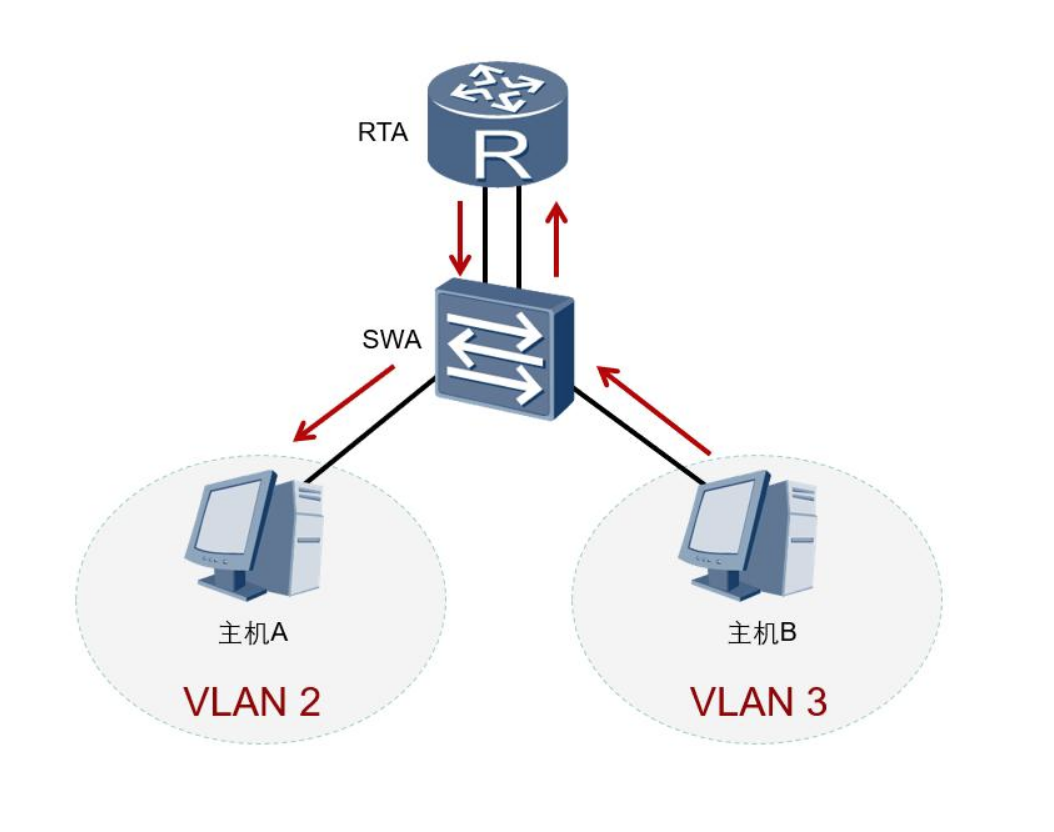
优点:配置维护简单;
缺点:
- 成本太高,每增加一个vlan就需要一个端口和一条物理链路,浪费资源;
- 可扩展性差,当vlan增加到一定数量后,路由器上可能没有那么多端口支撑;
- 某些VLAN之间的主机可能不需要频繁进行通信,每个vlan占用一个端口会导致路由器的接口利用率很低。
因此,实际应用中不会采用这种方案来解决VLAN间的通信问题。
单臂路由实现VLAN间通信
实现方法:
- 在交换机和路由器之间仅使用一个端口+一条物理链路连接。
- 一个物理端口上设置多个逻辑子接口的方式实现不同vlan间通信。
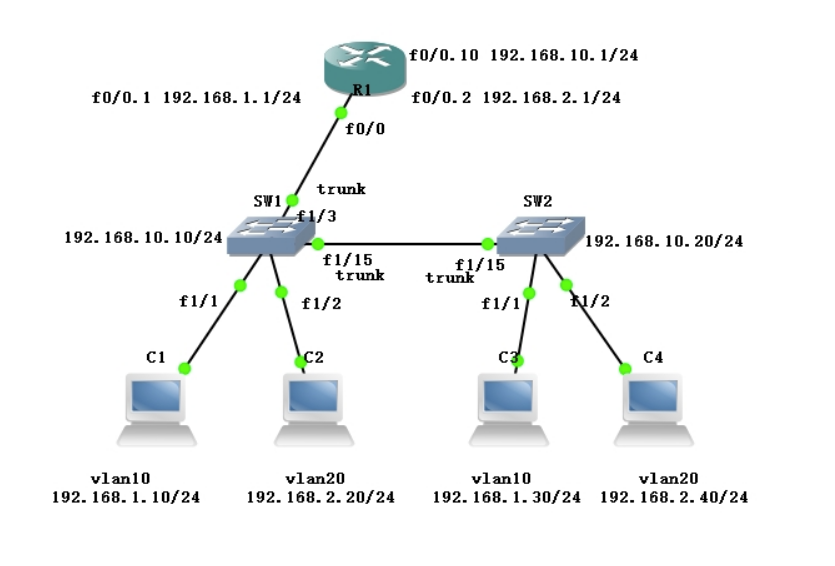
配置思路:
- 在交换机上,把连接到路由器的端口配置成Trunk类型的端口,并允许相关VLAN的帧通过。
- 在路由器上需要创建子接口,逻辑上把连接路由器的物理链路分成了多条。一个子接口代表了一条归属于某个VLAN的逻辑链路。
配置子接口时,需要注意以下几点:
- 必须为每个子接口分配一个IP地址。该IP地址与子接口所属VLAN位于同一网段。
- 需要在子接口上配置802.1Q封装,来剥掉和添加VLAN Tag,从而实现VLAN间互通。
- 在子接口上执行命令arp broadcast enable使能子接口的ARP广播功能。
优点:节省端口和物理链路,成本低,可扩展性好,端口利用率高;
缺点:配置复杂,单点故障
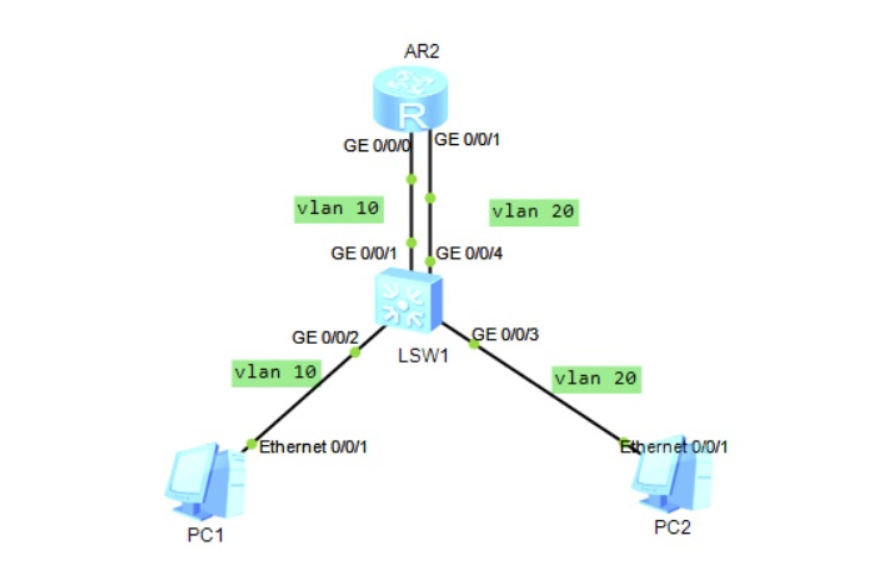
Vlanif接口实现VLAN间互通
实现方法:
- 在三层交换机上配置VLANIF接口来实现VLAN间路由。
- 如果网络上有多个VLAN,则需要给每个VLAN配置一个VLANIF接口,并给每个VLANIF接口配置一个IP地址。
- 用户设置的缺省网关就是三层交换机中VLANIF接口的IP地址。
交换机是如何转发带有VLAN的数据帧的
网络中的所有主机属于同一个广播域,容易造成广播报文泛滥,浪费网络带宽,造成链路拥塞;
广播域太大,同一广播域下的主机都可以互相通信,容易带来安全性问题。
VLAN技术可以隔离广播域,缩小广播域的范围,从而解决了上述问题。
VLAN的通信原则
同一个VLAN内的主机共享同一个广播域,它们之间可以直接进行二层通信;
VLAN间的主机属于不同的广播域,不能直接实现二层互通。
VLAN优点
既能够隔离广播域,又能够提升网络的安全性。
VLAN报文格式
带有VLAN的数据帧比正常以太网数据帧多了Tag字段,VLAN Tag长4个字节,直接添加在以太网帧头中。
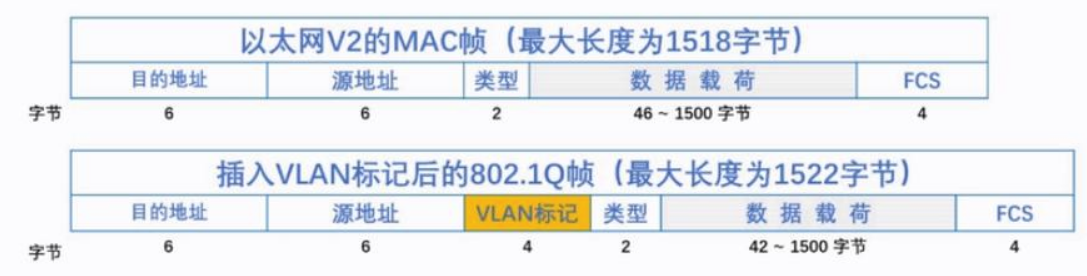
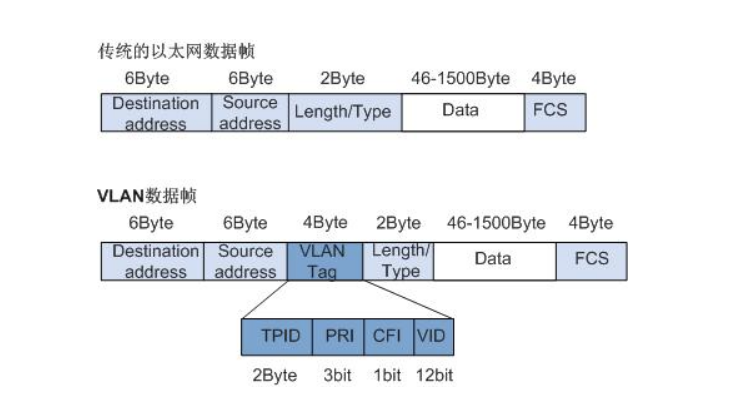
Tag字段组成:
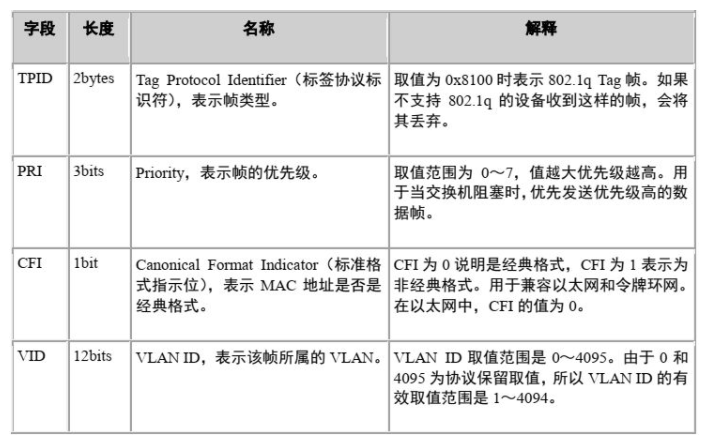
- TPID:Tag Protocol Identifier,2字节,固定取值,0x8100,是IEEE定义的新类型,表明这是一个携带802.1Q标签的帧。如果不支持802.1Q的设备收到这样的帧,会将其丢弃。
- TCI:Tag Control Information,2字节。帧的控制信息,详细说明如下
- Priority:3比特,表示帧的优先级,取值范围为0~7,值越大优先级越高。当交换机阻塞时,优先发送优先级高的数据帧。
- CFI:Canonical Format Indicator,1比特。CFI表示MAC地址是否是经典格式。CFI为0说明是经典格式,CFI为1表示为非经典格式。用于区分以太网帧、FDDI(Fiber Distributed Digital Interface)帧和令牌环网帧。在以太网中,CFI的值为0。
- VLAN Identifier:VLAN ID,12比特,可配置的VLAN ID取值范围为0~4095,但是0和4095在协议中规定为保留的VLAN ID,不能给用户使用。
在Tag字段中,主要关注的就是VLAN Identifier, 这个字段表示该数据帧带的vlan id是多少。
PVID
PVID即Port VLAN ID,代表端口的缺省VLAN。
为什么需要PVID?
交换机从对端设备收到的帧有可能是Untagged的数据帧,但所有以太网帧在交换机中都是以Tagged的形式来被处理和转发的,因此交换机必须给端口收到的Untagged数据帧添加上Tag。
为了实现此目的,必须为交换机配置端口的缺省VLAN。
交换机收到Untagged数据帧的处理方式
当该端口收到Untagged数据帧时,交换机将给它加上该缺省VLAN的VLAN Tag。
缺省情况下,交换机每个端口的PVID是1。
VLAN的划分
我们知道vlan可以隔离广播域,那么如何去划分vlan呢?下面介绍下5种vlan的划分方法,重点关注基于端口的VLAN划分方式。
基于端口划分
根据交换机的端口编号来划分VLAN。
通过为交换机的每个端口配置不同的PVID,来将不同端口划分到VLAN中。初始情况下,交换机的端口处于VLAN1中。
优点:此方法配置简单,但是当主机移动位置时,需要重新配置VLAN。
基于MAC地址划分
根据主机网卡的MAC地址划分VLAN。
此划分方法需要网络管理员提前配置网络中的主机MAC地址和VLAN ID的映射关系。如果交换机收到不带标签的数据帧,会查找之前配置的MAC地址和VLAN映射表,根据数据帧中携带的MAC地址来添加相应的VLAN标签。
优点:在使用此方法配置VLAN时,即使主机移动位置也不需要重新配置VLAN。
基于IP子网划分
交换机在收到不带标签的数据帧时,根据报文携带的IP地址给数据帧添加VLAN标签。
基于协议划分
根据数据帧的协议类型(或协议族类型)、封装格式来分配VLAN ID。
网络管理员需要首先配置协议类型和VLAN ID之间的映射关系。
基于策略划分
使用几个条件的组合来分配VLAN标签。这些条件包括IP子网、端口和IP地址等。只有当所有条件都匹配时,交换机才为数据帧添加VLAN标签。另外,针对每一条策略都是需要手工配置的。
VLAN工作原理
2种链路类型
VLAN链路分为两种类型:Access链路和Trunk链路。
接入链路(Access Link):连接用户主机和交换机的链路称为接入链路。如本例所示,图中主机和交换机之间的链路都是接入链路。
干道链路(Trunk Link):连接交换机和交换机的链路称为干道链路。如本例所示,图中交换机之间的链路都是干道链路。干道链路上通过的帧一般为带Tag的VLAN帧。
3种端口类型
学习了vlan的概念,我们知道网络中的数据帧要么是没有加上VLAN标记的标准以太网帧(untagged frame),要么是带有VLAN标记的以太网帧(tagged frame)。
那么不同类型的接口是如何发送和接收带有vlan标记的以太网数据帧的呢?
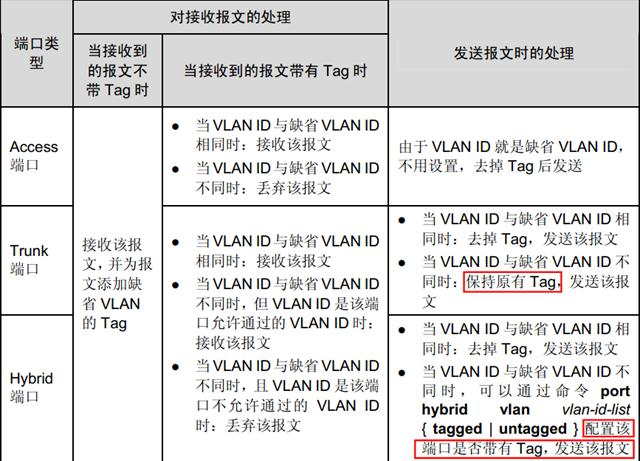
Access接口
Access端口是交换机上用来连接用户主机的端口,它只能连接接入链路,并且只能允许唯一的VLAN ID通过本端口。
Access端口收发数据帧的规则如下:
- 如果该端口收到对端设备发送的帧是untagged(不带VLAN标签),交换机将强制加上该端口的PVID。如果该端口收到对端设备发送的帧是tagged(带VLAN标签),交换机会检查该标签内的VLAN ID。当VLAN ID与该端口的PVID相同时,接收该报文。当VLAN ID与该端口的PVID不同时,丢弃该报文。
- Access端口发送数据帧时,总是先剥离帧的Tag,然后再发送。Access端口发往对端设备的以太网帧永远是不带标签的帧。
Trunk端口
Trunk端口是交换机上用来和其他交换机连接的端口,它只能连接干道链路。Trunk端口允许多个VLAN的帧(带Tag标记)通过。
Trunk端口收发数据帧的规则如下:
- 当接收到对端设备发送的不带Tag的数据帧时,会添加该端口的PVID,如果PVID在允许通过的VLAN ID列表中,则接收该报文,否则丢弃该报文。接收到对端设备发送的带Tag的数据帧时,检查VLAN ID是否在允许通过的VLAN ID列表中。如果VLAN ID在接口允许通过的VLAN ID列表中,则接收该报文。否则丢弃该报文。
- 端口发送数据帧时,当VLAN ID与端口的PVID相同,且是该端口允许通过的VLAN ID时,去掉Tag,发送该报文。
- 当VLAN ID与端口的PVID不同,且是该端口允许通过的VLAN ID时,保持原有Tag,发送该报文。
Hybrid端口
Access端口发往其他设备的报文,都是Untagged数据帧,而Trunk端口仅在一种特定情况下才能发出untagged数据帧,其它情况发出的都是Tagged数据帧。
Hybrid端口是交换机上既可以连接用户主机,又可以连接其他交换机的端口。
Hybrid端口既可以连接接入链路又可以连接干道链路。Hybrid端口允许多个VLAN的帧通过,并可以在出端口方向将某些VLAN帧的Tag剥掉。华为设备默认的端口类型是Hybrid。
Hybrid端口收发数据帧的规则如下:
- 当接收到对端设备发送的不带Tag的数据帧时,会添加该端口的PVID,如果PVID在允许通过的VLAN ID列表中,则接收该报文,否则丢弃该报文。
- 当接收到对端设备发送的带Tag的数据帧时,检查VLAN ID是否在允许通过的VLAN ID列表中。如果VLAN ID在接口允许通过的VLAN ID列表中,则接收该报文,否则丢弃该报文。
- Hybrid端口发送数据帧时,将检查该接口是否允许该VLAN数据帧通过。如果允许通过,则可以通过命令配置发送时是否携带Tag。
链路聚合技术详解
什么是链路聚合
从端口的角度定义:链路聚合(Link Aggregation)是指将多个物理端口汇聚在一起,形成一个逻辑端口,以实现出/入流量吞吐量在各成员端口的负荷分担,交换机根据用户配置的端口负载分担方式决定数据包从哪个成员端口发送到对端的交换机。
从链路的角度定义:链路聚合(Link Aggregation)是把两台设备之间的多条物理链路聚合在一起,当做一条逻辑链路来使用。这两台设备可以是一对路由器,一对交换机,或者是一台路由器和一台交换机。一条聚合链路可以包含多条成员链路,默认最多为8条。
链路聚合的作用
- 链路聚合能够提高链路带宽。理论上,通过聚合几条链路,一个聚合口的带宽可以扩展为所有成员口带宽的总和,这样就有效地增加了逻辑链路的带宽。
- 链路聚合为网络提供了高可靠性。配置了链路聚合之后,如果一个成员接口发生故障,该成员口的物理链路会把流量切换到另一条成员链路上。
- 链路聚合在一个聚合口上实现负载均衡。一个聚合口可以把流量分散到多个不同的成员口上,通过成员链路把流量发送到同一个目的地,将网络产生拥塞的可能性降到最低。
几个概念
- 聚合链路/成员链路
把聚合后得到的逻辑链路称为聚合链路,把聚合链路中的每一条物理链路称为成员链路。 - 聚合端口/成员端口
把聚合后得到的逻辑端口称为聚合端口,把聚合端口中的每一个物理端口称为成员端口。 - Eth-Trunk链路/Eth-Trunk端口
聚合链路也被称为Eth-Trunk链路,聚合端口也被称为Eth-Trunk端口。
链路聚合工作模式
链路聚合包含两种模式:手动负载均衡模式和静态LACP(Link Aggregation Control Protocol)模式。
手工负载分担模式
- 手工负载分担模式下,Eth-Trunk的建立、成员接口的加入由手工配置,没有链路聚合控制协议的参与。
- 该模式下所有活动链路都参与数据的转发,平均分担流量,因此称为负载分担模式。如果某条活动链路故障,链路聚合组自动在剩余的活动链路中平均分担流量。
使用场景:
当需要在两个直连设备间提供一个较大的链路带宽而设备又不支持LACP协议时,可以使用手工负载分担模式。
静态LACP模式
- 在静态LACP模式中,链路两端的设备相互发送LACP报文,协商聚合参数。协商完成后,两台设备确定活动接口和非活动接口。
- 在静态LACP模式中,需要手动创建一个Eth-Trunk口,并添加成员口。
- 静态LACP模式也叫M:N模式。M代表活动成员链路,用于在负载均衡模式中转发数据。N代表非活动链路,用于冗余备份。
- 如果一条活动链路发生故障,该链路传输的数据被切换到一条优先级最高的备份链路上,这条备份链路转变为活动状态。
两种链路聚合模式的主要区别
- 在静态LACP模式中,一些链路充当备份链路。
- 在手动负载均衡模式中,所有的成员口都处于转发状态。
链路聚合的条件
在一个聚合口中,聚合链路两端的物理口(即成员口)的所有参数必须一致,包括物理口的数量,传输速率,双工模式和流量控制模式。成员口可以是二层接口或三层接口。
负载分担的方式
链路聚合带来数据包乱序问题
数据流在聚合链路上传输,数据顺序必须保持不变。一个数据流可以看做是一组MAC地址和IP地址相同的帧。
两台设备间的SSH或SFTP连接可以看做一个数据流。
- 如果未配置链路聚合,只是用一条物理链路来传输数据,那么一个数据流中的帧总是能按正确的顺序到达目的地。
- 配置了链路聚合后,多条物理链路被绑定成一条聚合链路,一个数据流中的帧通过不同的物理链路传输。如果第一个帧通过一条物理链路传输,第二个帧通过另外一条物理链路传输,这样一来同一数据流的第二个数据帧就有可能比第一个数据帧先到达对端设备,从而产生接收数据包乱序的情况。
如何解决数据包乱序
为了避免数据包乱序的问题,Eth-Trunk采用逐流负载分担的机制。
这种机制把数据帧中的地址通过HASH算法生成HASH-KEY值,然后根据这个数值在Eth-Trunk转发表中寻找对应的出接口,不同的MAC或IP地址HASH得出的HASH-KEY值不同,从而出接口也就不同。
这样既保证了同一数据流的帧在同一条物理链路转发,又实现了流量在聚合组内各物理链路上的负载分担,即逐流的负载分担。逐流负载分担能保证包的顺序,但不能保证带宽利用率。
负载分担的类型
- 根据报文的源MAC地址进行负载分担;
- 根据报文的目的MAC地址进行负载分担;
- 根据报文的源IP地址进行负载分担;
- 根据报文的目的IP地址进行负载分担;
- 根据报文的源MAC地址和目的MAC地址进行负载分担;
- 根据报文的源IP地址和目的IP地址进行负载分担;
- 根据报文的VLAN、源物理端口等对L2、IPv4、IPv6和MPLS报文进行增强型负载分担
链路聚合的配置案例
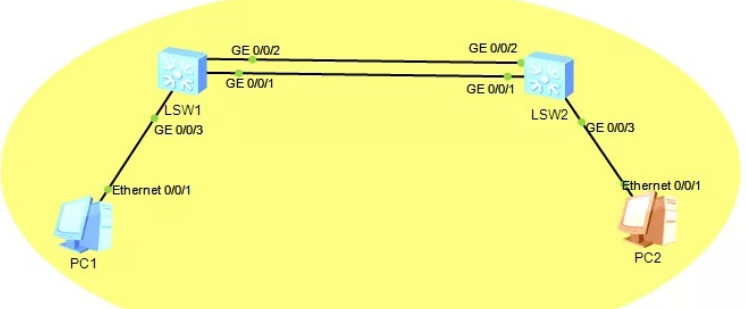
[LSW1]interface Eth-Trunk 1
[LSW1-Eth-Trunk1]interface GigabitEthernet0/0/1
[LSW1-GigabitEthernet0/0/1]eth-trunk 1
[LSW1-GigabitEthernet0/0/1]interface GigabitEthernet0/0/2
[LSW1-GigabitEthernet0/0/2]eth-trunk 1
[LSW2]interface Eth-Trunk 1
[LSW2-Eth-Trunk1]interface GigabitEthernet0/0/1
[LSW2-GigabitEthernet0/0/1]eth-trunk 1
[LSW2-GigabitEthernet0/0/1]interface GigabitEthernet0/0/2
[LSW2-GigabitEthernet0/0/2]eth-trunk 1
通过执行interface Eth-trunk
trunk-id用来唯一标识一个Eth-Trunk口,该参数的取值可以是0到63之间的任何一个整数。如果指定的Eth-Trunk口已经存在,执行interface eth-trunk命令会直接进入该Eth-Trunk口视图。
检查链路聚合是否成功:
display eth-trunk 1
执行display interface eth-trunk
- 如果Eth-Trunk口处于UP状态,表明接口正常运行。
- 如果接口处于Down状态,表明所有成员口物理层发生故障。
- 如果管理员手动关闭端口,接口处于Administratively DOWN状态。可以通过接口状态的改变发现接口故障,所有接口正常情况下都应处于Up状态。
如上图所示,在两台交换机之间配置静态LACP模式的链路聚合
[LSW1]interface Eth-Trunk 1
[LSW1-Eth-Trunk1] mode lacp-static
[LSW1-Eth-Trunk1]interface GigabitEthernet0/0/1
[LSW1-GigabitEthernet0/0/1]eth-trunk 1
[LSW1-GigabitEthernet0/0/1]interface GigabitEthernet0/0/2
[LSW1-GigabitEthernet0/0/2]eth-trunk 1
[LSW2]interface Eth-Trunk 1
[LSW2-Eth-Trunk1] mode lacp-static
[LSW2-Eth-Trunk1]interface GigabitEthernet0/0/1
[LSW2-GigabitEthernet0/0/1]eth-trunk 1
[LSW2-GigabitEthernet0/0/1]interface GigabitEthernet0/0/2
[LSW2-GigabitEthernet0/0/2]eth-trunk 1
检查链路聚合是否成功:
display eth-trunk 1
执行display interface eth-trunk 1命令,可以确认两台设备间是否已经成功实现链路聚合。端口处于select状态表示是激活端口。
通过静态路由实现负载分担和主备路由
静态路由
什么是静态路由
静态路由是指由管理员手动配置和维护的路由。
如何理解静态路由呢?配置一条静态路由就是告诉路由器怎么去往某一个目的IP或IP网段?就好比我们需要去某个地方,别人直接告诉我们往哪个方向走。
静态路由相比动态路由的优缺点
优点:静态路由配置简单,并且无需像动态路由那样占用路由器的CPU资源来计算和进行路由更新。
缺点:当网络拓扑发生变化时,静态路由不会自动适应拓扑改变,而是需要管理员手动进行调整。
静态路由配置
ip route-static ip-address { mask | mask-length } interface-type interface-number [ nexthop-address ] 命令用来配置静态路由。
参数ip-address指定了一个网络或者主机的目的地址,参数mask指定了一个子网掩码或者前缀长度。
注意
- 如果使用了广播接口如以太网接口作为出接口,则必须要指定下一跳地址;
- 如果使用了串口作为出接口,则可以通过参数interface-type和interface-number(如Serial 1/0/0)来配置出接口,此时不必指定下一跳地址。
实例
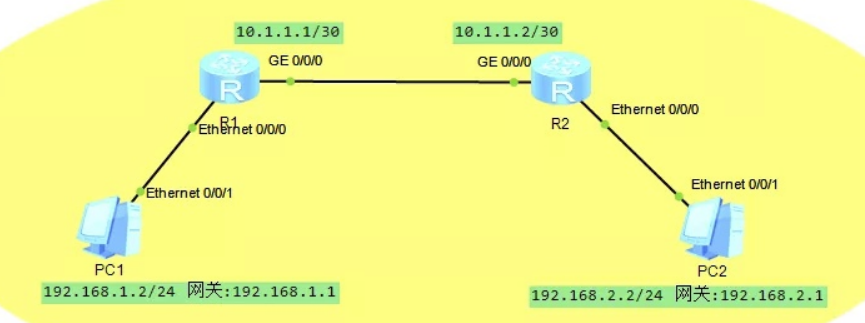
路由器R1上配置接口IP和去往PC2的静态路由:
ip route-static 192.168.2.0 255.255.255.0 10.1.1.2
路由器R2上配置接口IP和去往PC2的静态路由:
ip route-static 192.168.1.0 255.255.255.0 10.1.1.1
静态路由如何实现负载分担和主备路由
负载分担
静态路由支持到达同一目的地的等价负载分担。
当源网络和目的网络之间存在多条链路时,可以通过等价路由来实现流量负载分担。这些等价路由具有相同的目的网络和掩码、优先级和度量值。

本示例中R1和R2之间有两条链路相连,通过使用等价的静态路由来实现流量负载分担。
在R1和R2上配置了两条静态路由,它们具有相同的目的IP地址和子网掩码、优先级(都为60)、路由开销(都为0),但下一跳不同。在R1和R2互相通信时,就会使用这两条等价静态路由将数据进行负载分担。
R1的等价静态路由配置:
ip route-static 192.168.2.0 255.255.255.0 10.1.1.2
ip route-static 192.168.2.0 255.255.255.0 10.1.2.2
在配置完静态路由之后,可以使用display ip routing-table命令来验证配置结果。
在本示例中,红框部分代表路由表中的静态路由。这两条路由具有相同的目的地址和掩码,并且有相同的优先级和度量值,但是它们的下一跳地址和出接口不同。此时,R1就可以通过这两条等价路由实现负载分担。
R2的等价静态路由配置:
ip route-static 192.168.1.0 255.255.255.0 10.1.1.1
ip route-static 192.168.1.0 255.255.255.0 10.1.2.1
静态路由实现主备路由:
在配置多条静态路由时,可以修改静态路由的优先级,使一条静态路由的优先级高于其他静态路由,从而实现静态路由的备份,也叫浮动静态路由。

在本示例中,R1和R2上配置了两条静态路由。正常情况下,这两条静态路由是等价的。通过配置preference 100,使第二条静态路由的优先级要低于第一条(值越大优先级越低)。路由器只把优先级最高的静态路由加入到路由表中。
当加入到路由表中静态路由出现故障时,优先级低的静态路由才会加入到路由表并承担数据转发业务。
R1的配置:配置一条的静态路由的preference 为 100
ip route-static 192.168.2.0 255.255.255.0 10.1.1.2
ip route-static 192.168.2.0 255.255.255.0 10.1.2.2 preference 100
从display ip routing-table命令的回显信息中可以看出,通过修改静态路由优先级实现了浮动静态路由。
正常情况下,路由表中应该显示两条有相同目的地、但不同下一跳和出接口的等价路由。由于修改了优先级,回显中只有一条默认优先级为60的静态路由。另一条静态路由的优先级是100,该路由优先级低,所以不会显示在路由表中。
R2的配置:配置一条的静态路由的preference 为 100
ip route-static 192.168.1.0 255.255.255.0 10.1.1.1
ip route-static 192.168.1.0 255.255.255.0 10.1.2.1 preference 100
当主用静态路由出现物理链路故障或者接口故障时,该静态路由不能再提供到达目的地的路径,所以在路由表中会被删除。此时,浮动静态路由会被加入到路由表,以保证报文能够从备份链路成功转发到目的地。
在主用静态路由的物理链路恢复正常后,主用静态路由会重新被加入到路由表,并且数据转发业务会从浮动静态路由切换到主用静态路由,而浮动静态路由会在路由表中再次被隐藏。
在R1上关闭接口,查看下路由表可以发现浮动静态路由被加入路由表;
特殊的静态路由——缺省路由
当路由表中没有与报文的目的地址匹配的表项时,设备可以选择缺省路由作为报文的转发路径。在路由表中,缺省路由的目的网络地址为0.0.0.0,掩码也为0.0.0.0。
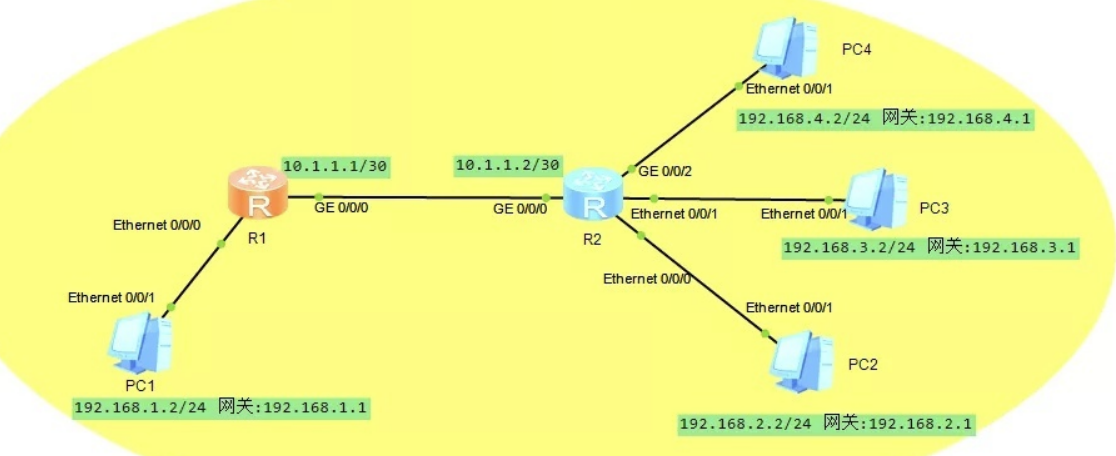
在本示例中,R1使用缺省路由转发到达未知目的地址的报文。缺省静态路由的默认优先级也是60。在路由选择过程中,缺省路由会被最后匹配。
ip route-static 0.0.0.0 0.0.0.0 10.1.1.2
ip route-static 192.168.2.0 255.255.255.0 10.1.1.2
ip route-static 192.168.2.0 255.255.255.0 10.1.1.2 preference 100
配置缺省路由后,可以使用display ip routing-table命令来查看该路由的详细信息。在本示例中,目的地址在路由表中没能匹配的所有报文都将通过GigabitEthernet 0/0/0接口转发到下一跳地址10.1.1.2。
静态路由的应用场景
静态路由一般适用于结构简单的网络。在复杂网络环境中,一般会使用动态路由协议来生成动态路由。
即使是在复杂网络环境中,合理地配置一些静态路由也可以改进网络的性能。
ARP代理技术详解

主机A需要与主机B通信时,目的IP地址与本机的IP地址处于同一网段,但是处于不同的广播域,所以主机A将会以广播形式发送ARP Request报文,请求主机B的MAC地址。但是,广播报文无法被路由器转发,所以主机B无法收到主机A的ARP请求报文,当然也就无法应答。
在路由器上启用代理ARP功能,就可以解决这个问题。
启用代理ARP后,路由器收到这样的请求,会查找路由表,如果存在主机B的路由表项,路由器将会使用自己的G0/0/0接口的MAC地址来回应该ARP request。
主机A收到ARP reply后,将以路由器的G0/0/0接口MAC地址作为目的MAC地址进行数据转发。
什么是ARP代理
proxy ARP就是通过使用一个主机(通常为router),来作为指定的设备对另一设备的ARP请求作出应答。
本例中就是使用R1来对主机A的请求作出应答。
ARP代理解决了什么问题
ARP代理可以解决同一网段的主机在不同的广播域不能通信的问题。
这里需要注意下必须在同一网段,如果不是同一网段,主机A根本就不会发送ARP请求报文,不同网段之间的主机需要借助网关实现通信,ARP代理只能解决同一网段的但是跨广播域的两台主机通信。
路由器开启 arp 代理
interface G0/0/0
ip address 10.0.10.2 255.255.255.0
arp-proxy enable