
CPU 优化
频率检测
turbostat 工具是 内核工具 数据包的一部分。支持在 AMD 64 和 Intel® 64 处理器的系统中使用。需要 root 特权来运行,处理器支持时间戳计时器以及 APERF 和 MPERF 型号的特定寄存器。
物理cpu个数为2,核心数为14,支持超线程,逻辑cpu数为56
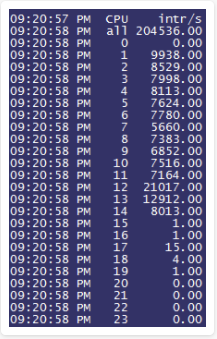
[root@kdc ~]# turbostat
Core CPU Avg_MHz Busy% Bzy_MHz TSC_MHz IRQ SMI CPU%c1 CPU%c3 CPU%c6 CPU%c7 CoreTmp PkgTmp Pkg%pc2 Pkg%pc3 Pkg%pc6 PkgWatt RAMWatt PKG_% RAM_%
- - 489 21.85 2240 2396 179920 0 34.25 2.92 40.98 0.00 52 53 0.02 0.00 0.00 106.40 35.77 0.00 0.00
0 0 373 16.01 2339 2394 6409 0 58.08 10.00 15.91 0.00 50 53 0.03 0.00 0.00 54.33 18.65 0.00 0.00
0 28 1161 41.94 2776 2394 5845 0 32.15
1 1 209 12.16 1726 2394 3513 0 28.67 4.72 54.45 0.00 48
1 29 154 9.24 1669 2394 897 0 31.59
2 2 161 7.59 2125 2394 1373 0 59.86 0.54 32.02 0.00 52
2 30 1550 58.64 2649 2394 3500 0 8.80
3 3 745 31.91 2342 2394 3943 0 16.91 2.23 48.95 0.00 47
3 31 155 8.89 1751 2394 1110 0 39.93
4 4 196 11.69 1682 2394 2720 0 21.52 3.11 63.68 0.00 46
4 32 144 9.63 1497 2394 740 0 23.58
5 5 205 10.66 1929 2394 1879 0 22.19 1.80 65.35 0.00 47
5 33 133 9.00 1483 2394 789 0 23.86
6 6 289 15.49 1873 2394 2292 0 15.25 2.19 67.08 0.00 47
6 34 155 9.58 1619 2394 794 0 21.15
8 7 511 19.78 2589 2394 2584 0 36.76 2.16 41.30 0.00 47
8 35 955 34.24 2797 2394 8606 0 22.30
9 8 419 21.52 1951 2394 2291 0 7.46 0.91 70.12 0.00 46
9 36 157 9.66 1627 2394 827 0 19.32
10 9 190 12.14 1570 2394 3053 0 18.69 3.05 66.13 0.00 46
10 37 144 9.53 1511 2394 769 0 21.29
11 10 705 31.18 2266 2394 3060 0 13.89 1.41 53.53 0.00 48
11 38 133 8.23 1619 2394 677 0 36.83
12 11 1722 62.91 2744 2394 5394 0 11.84 2.17 23.09 0.00 48
12 39 210 8.82 2385 2394 1122 0 65.93
13 12 131 5.92 2227 2394 1197 0 66.02 0.97 27.09 0.00 51
13 40 1568 59.84 2627 2394 3608 0 12.10
14 13 922 35.78 2583 2394 4422 0 45.07 9.30 9.85 0.00 47
14 41 234 11.76 1994 2394 11654 0 69.09
0 14 433 22.75 1909 2394 3296 0 27.06 2.35 47.83 0.00 46 53 0.00 0.00 0.00 52.08 17.12 0.00 0.00
0 42 304 14.58 2089 2394 1919 0 35.24
1 15 1092 43.08 2541 2394 5555 0 25.26 2.45 29.21 0.00 46
1 43 219 9.24 2381 2394 3627 0 59.11
2 16 536 28.64 1875 2394 4098 0 25.02 3.73 42.61 0.00 47
2 44 167 7.72 2167 2394 1744 0 45.94
3 17 522 28.71 1821 2394 3850 0 21.56 2.73 46.99 0.00 48
3 45 133 7.28 1825 2394 1150 0 42.99
4 18 578 30.62 1893 2394 3776 0 24.21 2.47 42.70 0.00 47
4 46 155 6.78 2284 2396 996 0 48.10
5 19 935 43.21 2165 2400 9257 0 26.41 3.38 26.99 0.00 50
5 47 259 11.92 2173 2400 1220 0 57.71
6 20 787 34.76 2265 2400 4529 0 23.69 3.05 38.50 0.00 49
6 48 228 10.52 2166 2400 1777 0 47.93
8 21 532 26.44 2013 2400 3529 0 38.83 4.27 30.46 0.00 46
8 49 268 13.05 2053 2400 1481 0 52.23
9 22 536 27.18 1973 2400 3814 0 38.08 3.24 31.50 0.00 47
9 50 293 12.88 2271 2400 3006 0 52.38
10 23 1101 43.63 2524 2400 5137 0 23.73 1.58 31.06 0.00 49
10 51 273 10.92 2497 2400 2043 0 56.43
11 24 840 40.02 2100 2400 9376 0 21.51 1.97 36.50 0.00 48
11 52 125 6.81 1829 2400 1046 0 54.73
12 25 496 26.07 1902 2400 3607 0 32.71 1.57 39.65 0.00 50
12 53 745 29.88 2492 2400 3079 0 28.90
13 26 786 37.32 2107 2400 4487 0 27.52 2.42 32.74 0.00 47
13 54 252 12.38 2033 2400 1335 0 52.46
14 27 794 36.23 2192 2400 4335 0 29.41 1.87 32.48 0.00 46
14 55 345 17.01 2026 2400 1783 0 48.64
Bzy_MHz CPU 不空闲时的平均时钟频率(即处于“c0”状态)
TSC_MHz 在整个间隔期间 TSC 运行的平均 MHz。
IRQ 在测量间隔期间由该 CPU 服务的中断数。系统总行是跨所有 CPU 服务的中断的总和。 turbostat 解析 /proc/interrupts 以生成此摘要。
如果 TSC 低于CPU标准频率,则服务器可能开启了节能,需要从 BIOS 和 系统层面调整。
也可以用下面命令查看个状态的时间
turbostat --show sysfs --quiet sleep 10
10.003837 sec
C1 C1E C3 C6 C7s C1% C1E% C3% C6% C7s%
4 21 2 2 459 0.14 0.82 0.00 0.00 98.93
1 17 2 2 130 0.00 0.02 0.00 0.00 99.80
0 0 0 0 31 0.00 0.00 0.00 0.00 99.95
2 1 0 0 52 1.14 6.49 0.00 0.00 92.21
1 2 0 0 52 0.00 0.08 0.00 0.00 99.86
0 0 0 0 71 0.00 0.00 0.00 0.00 99.89
0 0 0 0 25 0.00 0.00 0.00 0.00 99.96
0 0 0 0 74 0.00 0.00 0.00 0.00 99.94
0 1 0 0 24 0.00 0.00 0.00 0.00 99.84
EIST
EIST-智能降频技术,它能够根据不同的系统工作量自动调节处理器的电压和频率,以减少耗电量和发热量。
节能
CentOS7 中关闭节能
#!/bin/bash
if ! grep "processor.max_cstate=1 intel_idle.max_cstate=0 intel_pstate=disable idle=poll" /etc/default/grub -q ;then
sed -i '/GRUB_CMDLINE_LINUX/{s/"$//g;s/$/ processor.max_cstate=1 intel_idle.max_cstate=0 intel_pstate=disable idle=poll"/}' /etc/default/grub
/sbin/grub2-mkconfig -o /boot/grub2/grub.cfg >/dev/null
if [ "$?" = 0 ] ;then
/bin/rpm -e tuned
echo ok
# grep "processor.max_cstate=1 " /etc/default/grub
fi
else
echo "no need add"
fi
通过使用processor.max_cstates = 1命令行选项进行引导,可以防止系统进入节电状态。
可以添加idle = poll选项以在空闲状态之外获得最快的时间。
性能测试
sysbench
安装
yum -y install sysbench
测试
sysbench cpu --cpu-max-prime=20000 --threads=2 run
测试结果
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 2 // 指定线程数为2
Initializing random number generator from current time
Prime numbers limit: 20000 // 每个线程产生的素数上限均为2万个
Initializing worker threads...
Threads started!
CPU speed:
events per second: 650.74 // 所有线程每秒完成了650.74次event
General statistics:
total time: 10.0017s // 共耗时10秒
total number of events: 6510 // 10秒内所有线程一共完成了6510次event
Latency (ms):
min: 3.03 // 完成1次event的最少耗时3.03秒
avg: 3.07 // 所有event的平均耗时3.07毫秒
max: 3.27 // 完成1次event的最多耗时3.27毫秒
95th percentile: 3.13 // 95%次event在3.13秒毫秒内完成
sum: 19999.91 // 每个线程耗时10秒,2个线程叠加耗时就是20秒
Threads fairness:
events (avg/stddev): 3255.0000/44.00 // 平均每个线程完成3255次event,标准差为44
execution time (avg/stddev): 10.0000/0.00 // 每个线程平均耗时10秒,标准差为0
如果有2台服务器进行CPU性能对比,当素数上限和线程数一致时:
相同时间,比较event
相同event,比较时间
时间和event都相同,比较stddev(标准差)
关闭 irqbalance
关闭irqbalance,通过手动绑定中断的方法优化性能。
systemctl stop irqbalance.service
systemctl disable irqbalance.service
systemctl status irqbalance.service
网络优化
检测工具
ethtool
yum -y install ethtool net-tools
ethX 查询ethx网口基本设置,其中x是对应网卡的编号,如eth0、eth1等。
-k 查询网卡的Offload信息。
-K 修改网卡的Offload信息。
-c 查询网卡聚合信息。
-C 修改网卡聚合信息。
-l 查看网卡队列数。
-L 设置网卡队列数。
参数含义
rx-checksumming 接收包校验和。
tx-checksumming 发送包校验和。
scatter-gather 分散-聚集功能,是网卡支持TSO的必要条件之一。
tcp-segmentation-offload 简称为TSO,利用网卡对TCP数据包分片。
Combined 网卡队列数。
adaptive-rx 接收队列的动态聚合执行开关。
adaptive-tx 发送队列的动态聚合执行开关。
tx-usecs 产生一个中断之前至少有一个数据包被发送之后的微秒数。
tx-frames 产生中断之前发送的数据包数量。
rx-usecs 产生一个中断之前至少有一个数据包被接收之后的微秒数。
rx-frames 产生中断之前接收的数据包数量。
性能优化
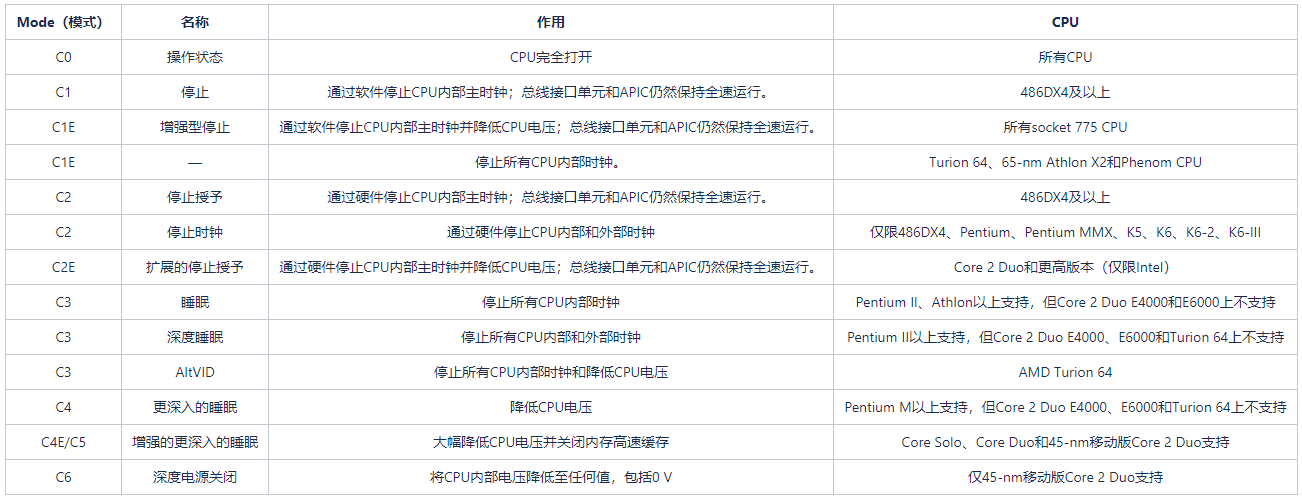
BIOS 中 PCIE Max Payload Size大小配置
网卡自带的内存和CPU使用的内存进行数据传递时,是通过PCIE总线进行数据搬运的。Max Payload Size为每次传输数据的最大单位(以字节为单位),它的大小与PCIE链路的传送效率成正比,该参数越大,PCIE链路带宽的利用率越高。
按照进入BIOS界面的步骤进入BIOS,选择“Advanced > Max Payload Size”,将“Max Payload Size”的值设置为“512B”。
网络NUMA绑核
原理
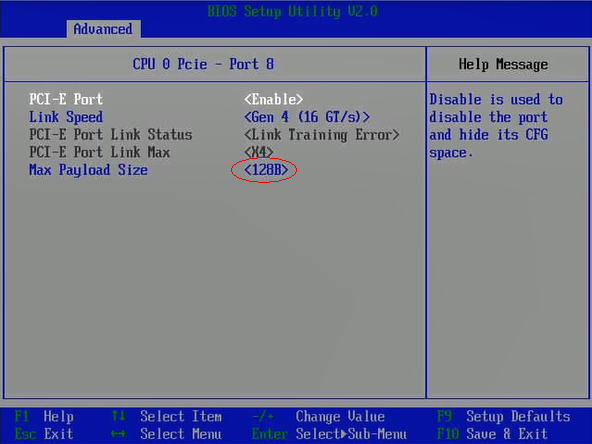
当网卡收到大量请求时,会产生大量的中断,通知内核有新的数据包,然后内核调用中断处理程序响应,把数据包从网卡拷贝到内存。当网卡只存在一个队列时,同一时间数据包的拷贝只能由某一个core处理,无法发挥多核优势,因此引入了网卡多队列机制,这样同一时间不同core可以分别从不同网卡队列中取数据包。
在网卡开启多队列时,操作系统通过Irqbalance服务来确定网卡队列中的网络数据包交由哪个CPU core处理,但是当处理中断的CPU core和网卡不在一个NUMA时,会触发跨NUMA访问内存。因此,我们可以将处理网卡中断的CPU core设置在网卡所在的NUMA上,从而减少跨NUMA的内存访问所带来的额外开销,提升网络处理性能。
图1 自动绑定:中断绑定随机,出现跨NUMA访问内存
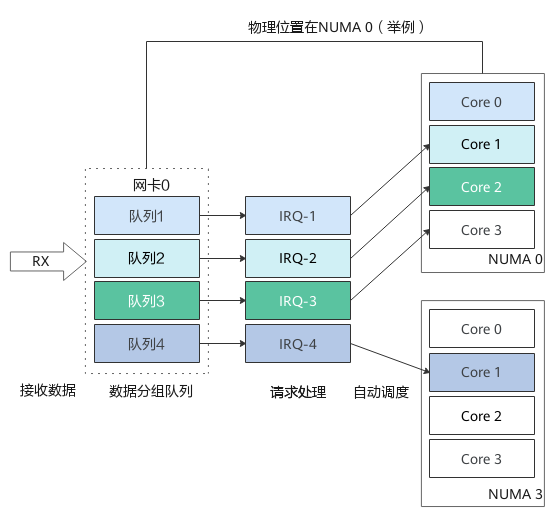
图2 NUMA绑定:中断绑定到指定核,避免跨NUMA访问内存
修改方式
停止irqbalance。
systemctl stop irqbalance.service
systemctl disable irqbalance.service
查看并设置网卡队列个数为CPU的核数。
# ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 2
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 2
ethtool -L eth0 combined 2
查询中断号。
cat /proc/interrupts | grep $eth | awk -F ':' '{print $1}'
根据中断号,将每个中断分别绑定在一个核上,其中cpuNumber是core的编号,从0开始。
echo $cpuNumber > /proc/irq/$irq/smp_affinity_list
开启 TSO
原理
当一个系统需要通过网络发送一大段数据时,计算机需要将这段数据拆分为多个长度较短的数据,以便这些数据能够通过网络中所有的网络设备,这个过程被称作分段。TCP分段卸载将TCP的分片运算(如将要发送的1M字节的数据拆分为MTU大小的包)交给网卡处理,无需协议栈参与,从而降低CPU的计算量和中断频率。
修改方式
使用ethtool工具打开网卡和驱动对TSO(TCP Segmentation Offload)的支持。如下命令中的参数“$eth”为待调整配置的网卡设备名称,如eth0,eth1等。
ethtool -K $eth tso on
说明:
要使用TSO功能,物理网卡需同时支持TCP校验计算和分散-聚集 (Scatter Gather) 功能。
查看网卡是否支持TSO:
ethtool -k $eth
rx-checksumming: on
tx-checksumming: on
scatter-gather: on
tcp-segmentation-offload: on
开启 LRO
原理
LRO(Large Receive Offload),通过将接收到的多个TCP数据聚合成一个大的数据包传递给网络协议栈处理,减少上层协议栈处理开销,提高系统接收TCP数据包的能力。
该特性在存在大量网络小包IO的情况下尤为明显。
修改方式
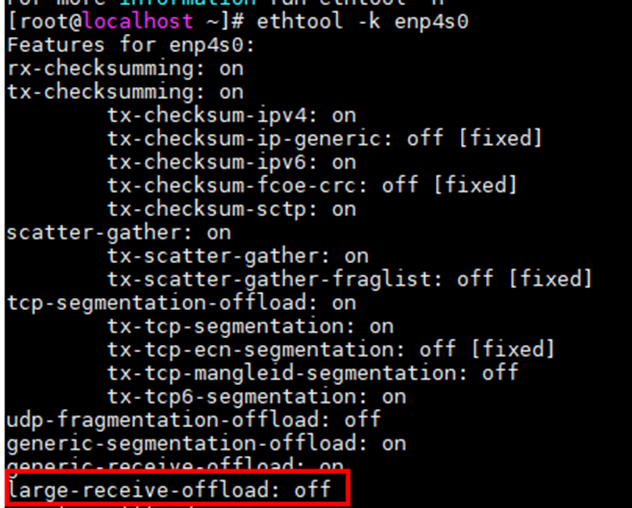
执行如下命令查看网卡LRO功能是否开启:
ethtool -k $eth
ethtool -K $eth lro on
说明:
开启LRO后,单个数据包的延时会增加,需结合业务综合评估是否需要开启。
单队列网卡软中断散列(RPS、RFS)
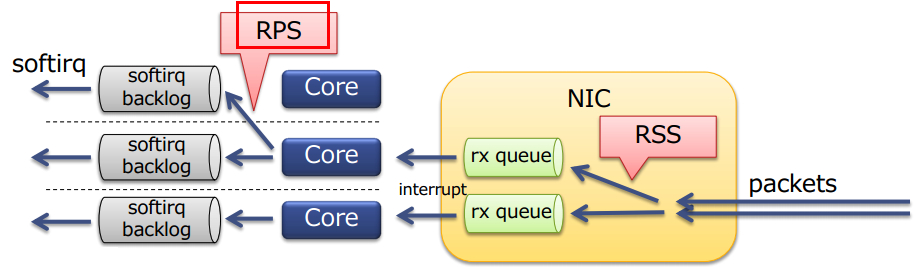
原理
RPS全称是Receive Packet Steering,从Linux内核版本2.6.35开始引入。RPS采用软件模拟的方式,实现了多队列网卡所提供的功能,分散了在多CPU系统上数据接收时的负载, 把软中断分到各个CPU处理,而不需要硬件支持,大大提高了网络性能。
对单队列网卡可以使用RPS将中断分散到各个core处理,避免软中断集中到一个core导致该core软中断过高形成性能瓶颈。
修改方式
通过直接修改网卡队列参数设置RPS,能够立即生效,无需重启服务器。
修改前:
/sys/class/net/eth0/queues/rx-0/rps_cpus 0
/sys/class/net/eth0/queues/rx-0/rps_flow_cnt 0
/proc/sys/net/core/rps_sock_flow_entries 0
修改后
echo ff > /sys/class/net/eth0/queues/rx-0/rps_cpus
echo 4096 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt
echo 32768 > /proc/sys/net/core/rps_sock_flow_entries
说明:
这里以单个网卡为例说明,ff对应的是core 0-7,意思是将软中断散列到0-7个core上。如果是多个网卡,对应的ff需要修改。将并发活动连接的最大预期数目设置为32768,是因为这个是linux官方内核推荐值。
TCP checksum优化
原理
TCP校验和(checksum)是一个端到端的校验和,由发送端计算,然后由接收端验证。其目的是为了发现TCP首部和数据在发送端到接收端之间发生的任何改动。如果接收方检测到校验和有差错,则TCP段会被直接丢弃。
通常TCP checksum是由内核网络驱动来实现的,而且在5.6之前的内核版本是使用普通的算法实现。
部分网卡驱动是支持TCP校验和功能的,可以通过ethtool -k 网卡名称 | grep checksumming查看是否支持。
如果网卡驱动不支持,且内核态do_csum函数热点占用过高的情况下,可以通过修改内核合入checksum优化算法来提升性能。
修改方式
5.6之前的内核可以通过合入checksum优化算法补丁提升性能,修改后需要重新编译内核(详情可参考内核源码编译安装)。
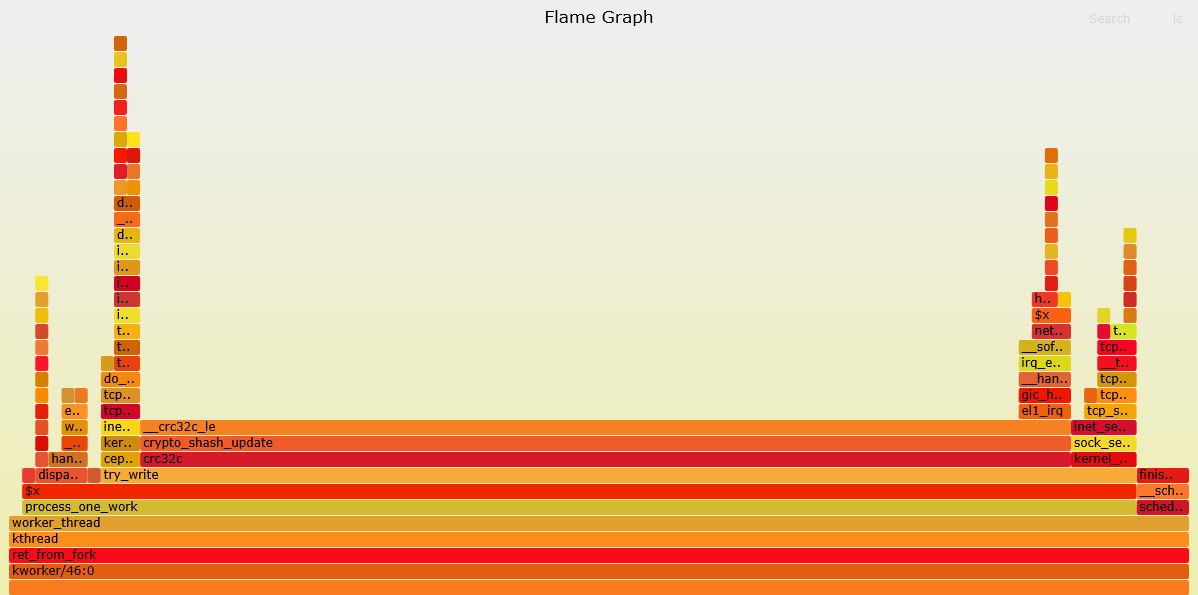
内核CRC32优化
原理
CRC32算法在网络通信、存储等方面常用于数据正确性校验。以网络通信方面为例,在收到网络包之后,先通过CRC32算法计算校验值,并与收到的CRC32值做对比,以确定数据的完整性。
Linux内核(4.14)包含了CRC32算法的C语言实现,但是性能不高,可能会成为性能瓶颈。同时,在高版本内核(5.0以上版本),已经合入AArch64架构下的CRC指令实现。当内核态中CRC32函数调用占比很高,成为瓶颈时,可以考虑合入该实现,提升性能。
内核态CRC32占比高火焰图如图1:
修改方式
在高版本的内核中(Kernel 5.x),已经实现了通过CRC指令的CRC32校验方式,该方式效率更高,能大大减少CRC32算法耗时。接下来介绍如何将该实现合入到kernel 4.x中。
修改方式可以参考:Linux内核态CRC32算法优化。
修改后需要重新编译内核,详情可参考:操作系统内核源码编译。
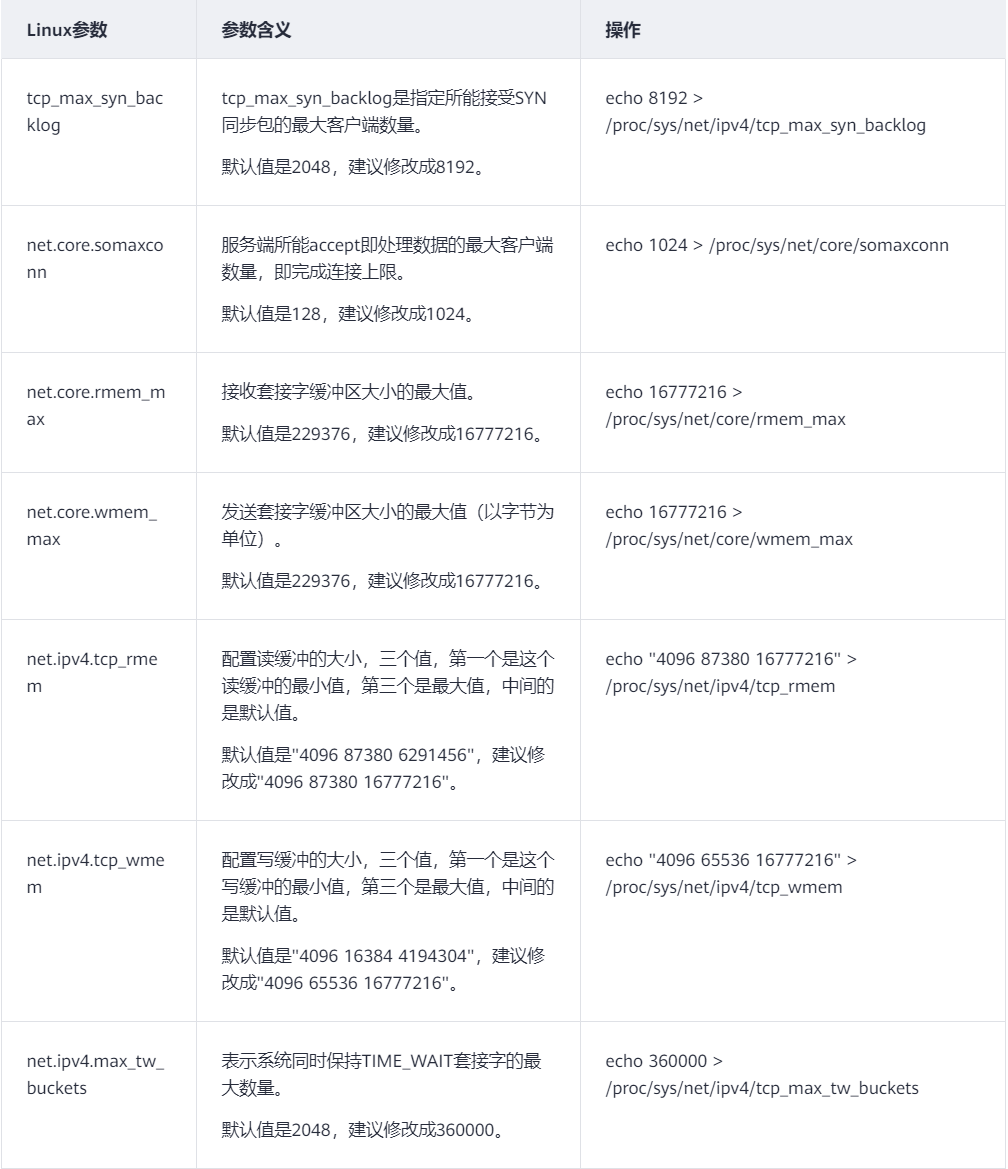
网络参数调优
内存优化
内核参数优化
vm.max_map_count
max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量
如启动 es 报错:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
查看当前值
sysctl -a|grep vm.max_map_count
临时修改
sysctl -w vm.max_map_count=262144
永久修改
vim /etc/sysctl.conf
vm.max_map_count=262144
sysctl -p
文件句柄优化
查看
# ulimit -a
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 14997
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 100001
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 14997
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
临时修改
ulimit -n 100001
永久修改
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
reboot
增加 swap 分区
云服务内存较小,经常遇到 oom,虽然 swap 分区性能不好,但总比系统奔溃强。
Swap(交换内存)是硬盘上的一个空间,当物理内存耗尽,交换内存就会被使用。当一个 Linux 系统内存不足时,不活跃的内存页,将会被从 RAM 空间 移动到 Swap 内存交换空间。
Swap 空间可能以独立的内存交换分区或者一个 swap 文件形式存在。通常,在虚拟机上运行 CentOS,没有现成的内存交换分区,因此唯一的选择就是创建一个 swap 文件。
一、创建并且激活 Swap 文件
01.开始创建用于内存交换空间的文件:
sudo fallocate -l 4G /swapfile
02.设置文件权限以便只有 root 用户可以读写 swap 文件:
sudo chmod 600 /swapfile
03.下一步,在这个文件上设置 Linux swap:
sudo mkswap /swapfile
04.执行下面的命令激活 swap 空间:
sudo swapon /swapfile
05.通过使用swapon或者free命令来验证 swap 空间是否已经激活,像下面这样:
sudo swapon --show
06.通过在/etc/fstab文件中添加一条 swap 条目来持久化这些修改。
vim /etc/fstab
/swapfile swap swap defaults 0 0
二、调整 Swappiness 值
Swappiness 是一个 Linux Kernel 属性值,它定义了系统使用 swap 空间的频率。Swappiness 取值范围从 0 到 100。一个较低的值使得 kernel 尽可能避免使用交换内存,而较高的值将使得 kernel 尽可能的使用交换内存空间。
在 CentOS 8 上 swappiness 默认值是 30。你可以通过输入下面的命令检测当前的 swappiness 值:
cat /proc/sys/vm/swappiness
30
当 swappiness 值为 30 的时候,它是适合桌面版本和开发版本的机器的,而对于生产服务器,你可能需要调低这个值。 例如,将 swappiness 值调低为 10,输入:
sudo sysctl vm.swappiness=10
想要持久化这个参数,应该将下面的内容粘贴到/etc/sysctl.conf文件,并且重新启动:
vm.swappiness=10
最优的 swappiness 值依赖于你的系统工作量和你的内存是如何被使用的。你应该一点一点增加这个参数值,来寻找最优值。
三、移除一个 Swap 文件
01.通过输入下面命令,取消激活 swap 空间:
sudo swapoff -v /swapfile
02.从/etc/fstab文件中移除 swap 条目/swapfile swap swap defaults 0 0。
03.使用rm删除实际的 swap 文件:
sudo rm /swapfile
磁盘IO优化
性能检测
iostat 工具
yum -y install sysstat
iostat -d -k -x 1 100
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
vda 0.00 10.00 0.00 140.00 0.00 25.00 0.00 71.43 0.00 0.80 0.01 0.00 14.00 1.10 1.10
常用参数
-c 显示CPU使用情况。
-d 显示磁盘使用情况。
-k 以KB为单位显示。
-m 以M为单位显示。
-p 显示磁盘单个的情况。
-t 显示时间戳。
-x 显示详细信息。
参数含义
rrqm/s 每秒合并放入请求队列的读操作数。
wrqm/s 每秒合并放入请求队列的写操作数。
r/s 每秒磁盘实际完成的读I/O设备次数。
w/s 每秒磁盘实际完成的写I/O设备次数。
rkB/s 每秒从磁盘读取KB数。
wkB/s 每秒写入磁盘的KB数。
avgrq-sz平均请求数据大小,单为为扇区(512B)。
avgqu-sz平均I/O队列长度(操作请求数)。
await 平均每次设备I/O操作的等待时间(毫秒)。
svctm 平均每次设备I/O操作的响应时间(毫秒)。
%util 用于I/O操作时间的百分比,即使用率。
重要参数详解:
- rrqm/s和wrqm/s,每秒合并后的读或写的次数(合并请求后,可以增加对磁盘的批处理,对HDD还可以减少寻址时间)。如果值在统计周期内为非零,也可以看出数据的读或写操作的是连续的,反之则是随机的。
- 如果%util接近100%(即使用率为百分百),说明产生的I/O请求太多,I/O系统已经满负荷,相应的await也会增加,CPU的wait时间百分比也会增加(通过TOP命令查看),这时很明显就是磁盘成了瓶颈,拖累整个系统。这时可以考虑更换更高性的能磁盘,或优化软件以减少对磁盘的依赖。
- await(读写请求的平均等待时长)需要结合svctm 参考。svctm的和磁盘性能直接有关,它是磁盘内部处理的时长。await的大小一般取决于svctm以及I/O队列的长度和。svctm一般会小于await,如果svctm比较接近await,说明I/O几乎没有等待时间(处理时间也会被算作等待的一部分时间);如果wait大于svctm,差的过高的话一定是磁盘本身IO的问题;这时可以考虑更换更快的磁盘,或优化应用。
- 队列长度(avgqu-sz)也可作为衡量系统I/O负荷的指标,但是要多统计一段时间后查看,因为有时候只是一个峰值过高。
性能测试
FIO
准备
注意 : 性能测试建议直接通过写裸盘的方式进行测试,会得到较为真实的数据。但直接测试裸盘会破坏文件系统结构,导致数据丢失,请在测试前确认磁盘中数据已备份。
# yum 安装
yum install libaio-devel fio
# 手动安装
yum install libaio-devel
wget http://brick.kernel.dk/snaps/fio-2.2.10.tar.gz
tar -zxvf fio-2.2.10.tar.gz
cd fio-2.2.10
make $ make install
命令解析
fio 分顺序读,随机读,顺序写,随机写,混合随机读写模式。
filename=/dev/sdb1 # 测试文件名称,通常选择需要测试的盘的 data 目录
direct=1 # 测试过程绕过机器自带的 buffer。使测试结果更真实
rw=randwrite # 测试随机写的 I/O
rw=randrw # 测试随机写和读的 I/O
bs=16k # 单次 io 的块文件大小为 16k
bsrange=512-2048 # 同上,提定数据块的大小范围
size=5G # 本次的测试文件大小为 5g,以每次 4k 的 io 进行测试
numjobs=30 # 本次的测试线程为 30 个
runtime=1000 # 测试时间 1000 秒,如果不写则一直将 5g 文件分 4k 每次写完为止
ioengine=psync #io 引擎使用 psync 方式
rwmixwrite=30 # 在混合读写的模式下,写占 30%
group_reporting # 关于显示结果的,汇总每个进程的信息
lockmem=1G # 只使用 1g 内存进行测试
zero_buffers # 用 0 初始化系统 buffer
nrfiles=8 # 每个进程生成文件的数量
# 顺序读
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
# 顺序写
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
# 随机读
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
# 随机写
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
# 混合随机读写
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=100 -group_reporting -name=mytest -ioscheduler=noop
# 复制下面的配置内容,将 directory=/path/to/test 修改为你测试硬盘挂载目录的地址,并另存为 fio.conf
[global]
ioengine=libaio
direct=1
thread=1
norandommap=1
randrepeat=0
runtime=60
ramp_time=6
size=1g
directory=/path/to/test
[read4k-rand]
stonewall
group_reporting
bs=4k
rw=randread
numjobs=8
iodepth=32
[read64k-seq]
stonewall
group_reporting
bs=64k
rw=read
numjobs=4
iodepth=8
[write4k-rand]
stonewall
group_reporting
bs=4k
rw=randwrite
numjobs=2
iodepth=4
[write64k-seq]
stonewall
group_reporting
bs=64k
rw=write
numjobs=2
iodepth=4
# 测试
fio fio.conf
实际测试范例
b=9475KB/s, mint=100138msec, maxt=100138msec
WRITE: io=380816KB, aggrb=3802KB/s, minb=3802KB/s, maxb=3802KB/s, mint=100138msec, maxt=100138msec
Disk stats (read/write):
sda: ios=59211/24192, merge=0/289, ticks=2951434/63353, in_queue=3092383, util=99.97%
测试结果如上,主要关注 bw 和 iops 结果
- bw:磁盘的吞吐量,这个是顺序读写考察的重点
- iops:磁盘的每秒读写次数,这个是随机读写考察的重点
read : io=948896KB, bw=9475.1KB/s, iops=592, runt=100138msec
write: io=380816KB, bw=3802.1KB/s, iops=237, runt=100138msec
IO 参数调优
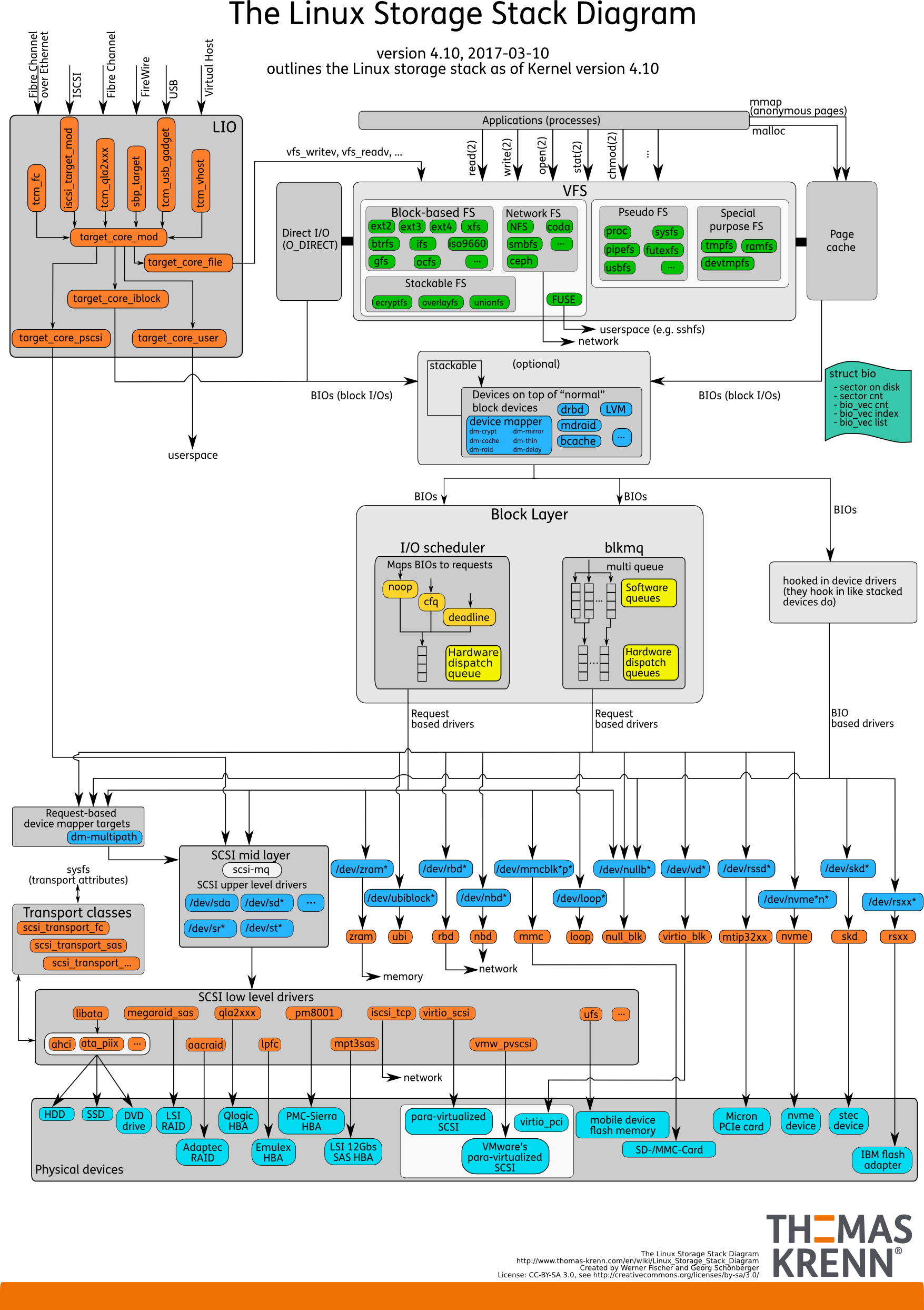
整体认知 IO 栈
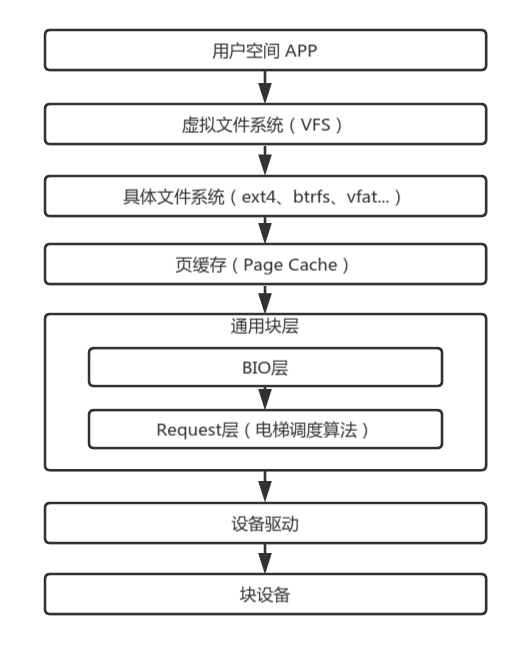
用户空间 通过虚拟文件系统 提供的统一的IO系统调用,从用户态切到内核态。虚拟文件系统通过调用具体文件系统注册的回调,把需求传递到 具体的文件系统 中。紧接着 具体的文件系统 根据自己的管理逻辑,换算到具体的磁盘块地址,从页缓存 寻找块设备的缓存数据。读操作一般是同步的,如果在 页缓存 没有缓存数据,则向通用块层发起一次磁盘读。 通用块层合并和排序所有进程产生的的IO请求,经过 设备驱动 从 块设备 读取真正的数据。最后是逐层返回。读取的数据既拷贝到用户空间的buffer中,也会在页缓存中保留一份副本,以便下次快速访问。
如果 页缓存 没命中,同步读会一路通到 块设备 ,而对于 异步写,则是把数据放到 页缓存 后返回,由内核回刷进程在合适时候回刷到 块设备 。
根据这个流程,具体包括以下几个方面:
- 交换分区(swap)
- 文件系统(ext4)挂载选项优化
- 页缓存(Page Cache)缓存及脏数据优化
- Request层(IO调度算法)调度算法优化
文件系统调优
inode 和 block 关系
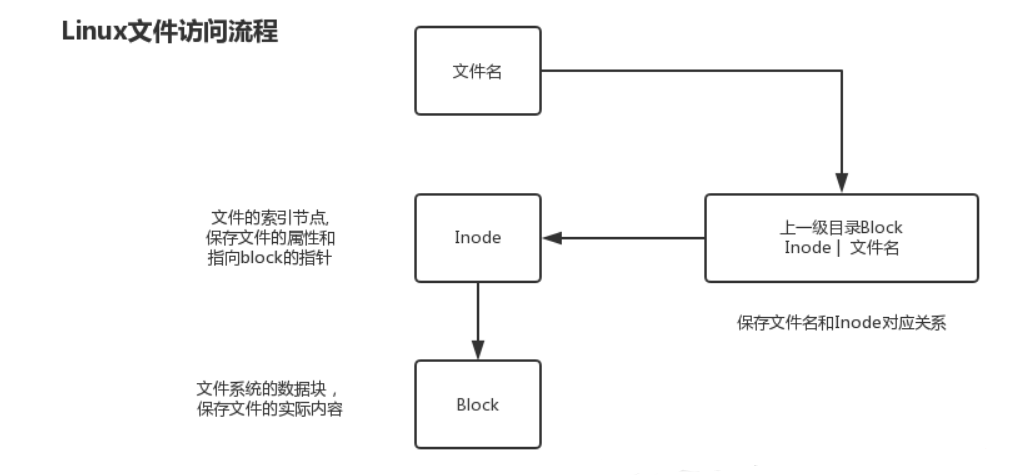
inode是文件的唯一标识,文件名和inode的对应关系存放在上一级目录的block中;inode里有指向文件block的指针和文件的属性,从而通过block获得文件数据。
inode节点的数量跟数据块有关。但是他们不是简单的正比例或者反比例的关系。如现在有一个25KB的文件,而数据块的大小则为4KB。则此时这个文件会占用7个数据块,但是只占用了一个inode节点。另外还有一种比较特殊的情况,如在系统的/proc目录下的文件实际上并不存在。也就是说并不占用数据块。但是仍然需要占用一个节点。所以说,数据块跟inode节点之间没有存在比例关系。
在最坏的情况下就是节点数量同数据块数量同时用完。
因为 inode 是 256 字节,如果设置过多的 inode,就会造成空间的浪费。
总的来说:
- 磁盘格式化文件系统后,会分为inode和block两部分;
- inode存放文件属性和指向block的指针;
- 文件名和inode对应关系存放在上级目录里的block;
- inode默认256B,block默认4K;
- 通过df -i 查看inode数量及使用量;
- 查看 inode 和 block 大小 dumpe2fs /dev/sda1 | egrep "Inode size|Block size";
- 一个文件至少占用一个inode和block,硬链接占用同一个inode;
- 一个block只能被一个文件使用,block太小,性能差,block太大,浪费空间;
- 通常,一块空间能放多少文件取决于inode和block的数量和大小,如果文件很小,那么block或inode就容易耗尽;如果文件很大,则应该用block的总数除以一个文件占用的block的数量得出存放文件的数目。
- 解决 inode 节点满的一般方法就是删除占用 inode 节点的异常文件(小文件)
- inode数量在格式化时指定,后期无法修改,当前也不能简单粗暴地重新格式化。
XFS 文件系统调优
以xfs文件系统为例,解释文件系统调优步骤。
建议在文件系统的mount参数上加上noatime,nobarrier两个选项。命令为(其中数据盘以及数据目录以实际为准):
mount -o noatime,nobarrier /dev/sdb /data
一般来说,Linux会给文件记录了三个时间,change time, modify time和access time。
- access time指文件最后一次被读取的时间。
- modify time指的是文件的文本内容最后发生变化的时间。
- change time指的是文件的inode最后发生变化(比如位置、用户属性、组属性等)的时间。
一般来说,文件都是读多写少,而且我们也很少关心某一个文件最近什么时间被访问了。所以,我们建议采用noatime选项,文件系统在程序访问对应的文件或者文件夹时,不会更新对应的access time。这样文件系统不记录access time,避免浪费资源。
现在的很多文件系统会在数据提交时强制底层设备刷新cache,避免数据丢失,称之为write barriers。但是,其实我们数据库服务器底层存储设备要么采用RAID卡,RAID卡本身的电池可以掉电保护;要么采用Flash卡,它也有自我保护机制,保证数据不会丢失。所以我们可以安全的使用nobarrier挂载文件系统。
对于ext3, ext4和 reiserfs文件系统可以在mount时指定barrier=0。
对于xfs可以指定nobarrier选项。
ext4 文件系统调优
ext4挂载参数: data
- ext4有3种日志模式,分别是ordered,writeback,journal。
jorunal:把元数据与数据一并写入到日志块。性能差不多折半,因为数据写了两次,但最安全 - writeback: 把元数据写入日志块,数据不写入日志块,但不保证数据先落盘。性能最高,但由于不保证元数据与数据的顺序,也是掉电最不安全的
- ordered:与writeback相似,但会保证数据先落盘,再是元数据。折中性能以保证足够的安全,这是大多数PC上推荐的默认的模式
在不需要担心掉电的服务器环境,我们完全可以使用writeback的日志模式,以获取最高的性能。
# mount -o remount,rw,data=writeback /home
mount: /home not mounted or bad option
# dmesg
[235737.532630] EXT4-fs (vda1): Cannot change data mode on remount
如果执行失败或是系统盘,可以写在 fstab 中,重启解决
# cat /etc/fstab
UUID=... /home ext4 defaults,rw,data=writeback...
ext4挂载参数:noatime
Linux上对每个文件都记录了3个时间戳
|时间戳 |全称|含义|
|-|-|-|
|atime |access time|访问时间,就是最近一次读的时间|
|mtime|data modified time|数据修改时间,就是内容最后一次改动时间|
|ctime|status change time|文件状态(元数据)的改变时间,比如权限,所有者等|
我们编译执行的Make可以根据修改时间来判断是否要重新编译,而atime记录的访问时间其实在很多场景下都是多余的。所以,noatime应运而生。不记录atime可以大量减少读造成的元数据写入量,而元数据的写入往往产生大量的随机IO。
mount -o ...noatime... /home
ext4挂载参数:nobarrier
这主要是决定在日志代码中是否使用写屏障(write barrier),对日志提交进行正确的磁盘排序,使易失性磁盘写缓存可以安全使用,但会带来一些性能损失。从功能来看,跟writeback和ordered日志模式非常相似。没研究过这方面的源码,说不定就是一回事。不管怎么样,禁用写屏障毫无疑问能提高写性能。
mount -o ...nobarrier... /home
ext4挂载参数:delalloc
delalloc是 delayed allocation 的缩写,如果使能,则ext4会延缓申请数据块直至超时。为什么要延缓申请呢?在inode中采用多级索引的方式记录了文件数据所在的数据块编号,如果出现大文件,则会采用 extent 区段的形式,分配一片连续的块,inode中只需要记录开始块号与长度即可,不需要索引记录所有的块。这除了减轻inode的压力之外,连续的块可以把随机写改为顺序写,加快写性能。连续的块也符合 局部性原理,在预读时可以加大命中概率,进而加快读性能。
mount -o ...delalloc... /home
ext4挂载参数:inode_readahead_blks
ext4从inode表中预读的indoe block最大数量。访问文件必须经过inode获取文件信息、数据块地址。如果需要访问的inode都在内存中命中,就不需要从磁盘中读取,毫无疑问能提高读性能。其默认值是32,表示最大预读 32 × block_size 即 64K 的inode数据,在内存充足的情况下,我们毫无疑问可以进一步扩大,让其预读更多。
mount -o ...inode_readahead_blks=4096... /home
ext4挂载参数:journal_async_commit
commit块可以不等待descriptor块,直接往磁盘写。这会加快日志的速度。
mount -o ...journal_async_commit... /home
ext4挂载参数:commit
ext4一次缓存多少秒的数据。默认值是5,表示如果此时掉电,你最多丢失5s的数据量。设置更大的数据,就可以缓存更多的数据,相对的掉电也有可能丢失更多的数据。在此服务器不怕掉电的情况,把数值加大可以提高性能。
mount -o ...commit=1000... /home
ext4挂载参数汇总
最终在不能umount情况下,我执行的调整挂载参数的命令为:
mount -o remount,rw,noatime,nobarrier,delalloc,inode_readahead_blks=4096,journal_async_commit,commit=1800 /home
此外,在/etc/fstab中也对应修改过来,避免重启后优化丢失
cat /etc/fstab
UUID=... /home ext4 defaults,rw,noatime,nobarrier,delalloc,inode_readahead_blks=4096,journal_async_commit,commit=1800,data=writeback 0 0
...
缓存参数调优
如何选择IO调度器 /sys/block/$/queue/scheduler
概述
最新版本的Linux内核已经完全切到multi-queue架构,因此single-queue下的IO调度算法在最新内核可能已经销声匿迹了。但实际上,multi-queue的IO调度算法很大程度上参考了single-queue的IO调度算法,因此一定程度上可以类推。

| 单队列调度算法 | 多队列调度算法 |
|---|---|
| deadline | mq-deadline |
| cfq | bfq |
| noop | none |
| kyber |
为什么需要IO调度呢?在最开始的时候,Linux存储在磁盘上。磁盘盘片高速旋转,通过磁臂的移动读取数据。磁臂的移动是物理上的机械上的移动,它无法瞬移,这速度是很慢的。如果我们读取的数据位置很随机,一会在A地点,一会在隔着老远的B地点,移动的时间就全做了无用功,这也就是我们说的随机读写性能慢的原因。如果读取的数据地址是连续的,即使不是连续的也是地址接近的,那么移动磁臂的时间损耗就少了。在最开始,IO调度的作用就是为了合并相近的IO请求,减少磁臂的移动损耗。
单队列的架构,一个块设备只有一个全局队列,所有请求都要往这个队列里面塞,这在多核高并发的情况下,尤其像服务器动则32个核的情况下,为了保证互斥而加的锁就导致了非常大的开销。此外,如果磁盘支持多队列并行处理,单队列的模型不能充分发挥其优越的性能。
多队列的架构下,创建了Software queues和Hardware dispatch queues两级队列。Software queues是每个CPU core一个队列,且在其中实现IO调度。由于每个CPU一个单独队列,因此不存在锁竞争问题。Hardware Dispatch Queues的数量跟硬件情况有关,每个磁盘一个队列,如果磁盘支持并行N个队列,则也会创建N个队列。在IO请求从Software queues提交到Hardware Dispatch Queues的过程中是需要加锁的。理论上,多队列的架构的效率最差也只是跟单队列架构持平。
单队列调度算法
单队列架构下,常用的调度算法有3种:noop,deadline和cfq
noop
noop只会对请求做一些简单的排序,其本质就是一个FIFO的队列,只会简单地合并临近的IO请求后,本质还是按先来先处理的原则提交给磁盘。
根据它的原理,我们可以发现它倾向于饿死读利于写,为什么呢?异步写是把数据直接放到page cache的,也就意味着可以通过page cache缓存大量的写数据,再一次性往下提交IO请求。而读呢?读一般是同步的,也就意味着必须在读完一笔后再读下一笔,两次读之间是可能被写请求插足的。
cfq
CFQ算法会为每个进程单独创建一个队列,保存该进程产生的所有IO请求。不同队列之间按时间片来调度,以此保证每个进程都能很好的分到I/O带宽。这IO的时间片调度跟进程调度是非常相似的,进程调度有进程优先级,而IO调度也有IO优先级。
CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP的缺点是,先来的IO请求并不一定能被满足,可能会出现饿死的情况。
当一个同步队列中的请求不足一定数量时,这个设备可以空闲一会,即使其它队列里可能有请求等待处理。通常,同步请求之间在磁盘上的物理位置是连续的,所以让磁盘稍等一会来接收更多连续的请求,这样做可以提高吞吐量。
deadline
deadline确保请求在一个用户可配置的时间内得到响应,避免请求饿死。其分别为读IO和写IO提供不同的FIFO队列,读FIFO队列的最大等待时间是500ms,写FIFO队列的最大等待时间是5s。deadline会把提交时间相近的请求放在一批。在同一批中,请求会被排序。当一批请求达到了大小上限或着定时器超时,这批请求就会提交到设备队列上去。
选择调度算法
- 对闪存等存储介质,优先使用noop调度算法
- 个人PC使用cfq调度算法
- 对IO压力比较重,且功能比较单一的场景,例如数据库服务器,使用deadline调度算法
为什么闪存等介质,例如固态硬盘SSD,要选择noop调度算法?
noop先来先处理的做法对磁盘来说时间损耗非常大,大量浪费了磁盘磁臂移动的时间。但是对闪存设备,例如mmc、nand等,却是最好的选择,因为闪存设备的物理结构跟磁盘完全不同,其通过一些规范的命令即可读取数据,没有磁臂这东西。此时IO调度算法里的排序、合并其实没太大意义,反而浪费了CPU和内存。
为什么个人PC要用cfq调度算法?
在个人PC的场景上,往往需要打开大量的程序,创建大量的进程。每个进程都可能有IO的请求。在这场景下,我们需要的是如何确保不同进程或进程组间IO资源使用的公平性。总不能因为A进程要拷贝电影,独占了IO资源,导致B进程无法打开文档不是?
cfq调度算法是以进程之间公平享用IO资源为出发点设计的,所以,个人PC建议使用cfq调度算法,但cfq调度算法不仅仅用于个人PC,准确来说,cfq调度算法适用于有大量进程的多用户系统。
为什么deadline调度算法适用于数据库?
deadline是一种以提高机械硬盘吞吐量为思考出发点的调度算法,所以准确来说,deadline调度算法适用于IO压力比较重,且业务功能单一的场景,而数据库毫无疑问是最为匹配的场景了。
华为官方给出的 MySQL 在 CentOS 系统中的优化值

磁盘预读 /sys/block/$DEVICE-NAME/queue/read_ahead_kb
文件预取的原理,就是根据局部性原理,在读取数据时,会多读一定量的相邻数据缓存到内存。如果预读的数据是后续会使用的数据,那么系统性能会提升,如果后续不使用,就浪费了磁盘带宽。在磁盘顺序读的场景下,调大预取值效果会尤其明显。
在顺序读比较多的场景中,我们可以增大磁盘的预读数据
文件预取参数由文件read_ahead_kb指定,CentOS中为 “/sys/block/$DEVICE-NAME/queue/read_ahead_kb” ($DEVICE-NAME为磁盘名称),如果不确定,则通过命令以下命令来查找。
find / -name read_ahead_kb
此参数的默认值128KB,可使用echo来调整,仍以CentOS为例,将预取值调整为4096KB:
echo 4096 > /sys/block/$DEVICE-NAME/queue/read_ahead_kb
调整磁盘队列长度 /sys/block/sdb/queue/nr_requests
我们可以优化内核块设备 I/O 的选项。比如,可以调整磁盘队列的长度 /sys/block/sdb/queue/nr_requests,适当增大队列长度,可以提升磁盘的吞吐量(当然也会导致 I/O 延迟增大)。
华为官方给出的 MySQL 在 CentOS 系统中的优化值

Linux 脏数据回刷参数与调优
简介
Linux用cache/buffer缓存数据,且有个回刷任务在适当时候把脏数据回刷到存储介质中。不同场景对触发回刷的时机的需求也不一样,对IO回刷触发时机的选择,是IO性能优化的一个重要方法。
Linux内核在/proc/sys/vm中有透出数个配置文件,可以对触发回刷的时机进行调整。
配置概述
| 配置文件 | 功能 | 默认值 |
|---|---|---|
| dirty_background_ratio | 触发回刷的脏数据占可用内存的百分比 | 0 |
| dirty_background_bytes | 触发回刷的脏数据量 | 10 |
| dirty_bytes | 触发同步写的脏数据量 | 0 |
| dirty_ratio | 触发同步写的脏数据占可用内存的百分比 | 20 |
| dirty_expire_centisecs | 脏数据超时回刷时间(单位:1/100s) | 3000 |
| dirty_writeback_centisecs | 回刷进程定时唤醒时间(单位:1/100s) | 500 |
参数解析:
1、vm.dirty_background_ratio
内存可以填充脏数据的百分比。这些脏数据稍后会写入磁盘,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。比如,我有32G内存,那么有3.2G(10%的比例)的脏数据可以待着内存里,超过3.2G的话就会有后台进程来清理。
2、vm.dirty_ratio
可以用脏数据填充的绝对最大系统内存量,当系统到达此点时,必须将所有脏数据提交到磁盘,同时所有新的I/O块都会被阻塞,直到脏数据被写入磁盘。这通常是长I/O卡顿的原因,但这也是保证内存中不会存在过量脏数据的保护机制。
3、vm.dirty_background_bytes 和 vm.dirty_bytes
另一种指定这些参数的方法。如果设置 xxx_bytes版本,则 xxx_ratio版本将变为0,反之亦然。
4、vm.dirty_expire_centisecs
指定脏数据能存活的时间。在这里它的值是30秒。当 pdflush/flush/kdmflush 在运行的时候,他们会检查是否有数据超过这个时限,如果有则会把它异步地写到磁盘中。毕竟数据在内存里待太久也会有丢失风险。
5、vm.dirty_writeback_centisecs
指定多长时间 pdflush/flush/kdmflush 这些进程会唤醒一次,然后检查是否有缓存需要清理。
可以通过下面方式看内存中有多少脏数据:
$ cat /proc/vmstat | egrep "dirty|writeback"
nr_dirty 106
nr_writeback 0
nr_writeback_temp 0
nr_dirty_threshold 3934012
nr_dirty_background_threshold 1964604
注意:
1、XXX_ratio 和 XXX_bytes 是同一个配置属性的不同计算方法,优先级 XXX_bytes > XXX_ratio
2、可用内存并不是系统所有内存,而是free pages + reclaimable pages
3、脏数据超时表示内存中数据标识脏一定时间后,下次回刷进程工作时就必须回刷
4、回刷进程既会定时唤醒,也会在脏数据过多时被动唤醒。
5、dirty_background_XXX与dirty_XXX的差别在于前者只是唤醒回刷进程,此时应用依然可以异步写数据到Cache,当脏数据比例继续增加,触发dirty_XXX的条件,不再支持应用异步写。
6、可回收内存达到dirty_background_XXX计算的阈值,只是唤醒脏数据回刷工作后直接返回,并不会等待回收完成,最终回收工作还是看writeback进程
7、将缓存写入磁盘时,有一个默认120秒的超时时间。如果IO子系统的处理速度不够快,不能在120秒将缓存中的数据全部写入磁盘(dirty_expire_centisecs 中设置的时间)。IO系统响应缓慢,导致越来越多的请求堆积,最终系统内存全部被占用,导致系统失去响应。所以,vm.dirty_background_ratio 的值要根据具体情况而定,要考虑磁盘的写入性能,不要一味地增大,否则会导致 CPU load 飙升,系统 call trace
配置示例
场景1:尽可能不丢数据
有些产品形态的数据非常重要,例如行车记录仪。在满足性能要求的情况下,要做到尽可能不丢失数据。
/* 此配置不一定适合您的产品,请根据您的实际情况配置 */
dirty_background_ratio = 5 # 当脏数据达到可用内存的5%时唤醒回刷进程
dirty_ratio = 10 # 当脏数据达到可用内存的10%时,应用每一笔数据都必须同步等待
dirty_writeback_centisecs = 50 # 每隔500ms唤醒一次回刷进程
dirty_expire_centisecs = 100 # 内存中脏数据存在时间超过1s则在下一次唤醒时回刷
场景2:追求更高性能
例如服务器。此时不需要考虑数据安全问题,要做到尽可能高的IO性能。
/* 此配置不一定适合您的产品,请根据您的实际情况配置 */
dirty_background_ratio = 50 # 当脏数据达到可用内存的50%时唤醒回刷进程
dirty_ratio = 80 # 当脏数据达到可用内存的80%时,应用每一笔数据都必须同步等待
dirty_writeback_centisecs = 2000 # 每隔20s唤醒一次回刷进程
dirty_expire_centisecs = 12000 # 内存中脏数据存在时间超过120s则在下一次唤醒时回刷
与场景1相比,场景2的配置通过 增大Cache,延迟回刷唤醒时间来尽可能缓存更多数据,进而实现提高性能
场景3:突然的IO峰值拖慢整体性能
突然间大量的数据写入,导致瞬间IO压力飙升,导致瞬间IO性能狂跌
/* 此配置不一定适合您的产品,请根据您的实际情况配置 */
dirty_background_ratio = 5 # 当脏数据达到可用内存的5%时唤醒回刷进程
dirty_ratio = 80 # 当脏数据达到可用内存的80%时,应用每一笔数据都必须同步等待
dirty_writeback_centisecs = 500 # 每隔5s唤醒一次回刷进程
dirty_expire_centisecs = 3000 # 内存中脏数据存在时间超过30s则在下一次唤醒时回刷
这样的配置,通过 增大Cache总容量,更加频繁唤醒回刷的方式,解决IO峰值的问题,此时能保证脏数据比例保持在一个比较低的水平,当突然出现峰值,也有足够的Cache来缓存数据。
优化案例
SSD阵列卡方案优化:考虑使用RAID 50替代RAID 10(小米)
大家都知道SSD成本比较高,而不少用户在考虑可用性时都会选用RAID 10作阵列,这样无疑又增加了成本。然而RAID 10的可用性也并非百分百完美。为了能够平衡可用性和成本,因此最近一直在研究性价比更高的RAID 50,它提供了接近RAID 10的可用性并且接近RAID 5的成本,像是在高可用的RAID 10和低成本的RAID 5之间的取了一个平衡点。
为了能够直观了解不同RAID类型下的故障可用性,我们首先做个简单的可用性分析(以8盘RAID 10的同等容量作对比):
RAID 50中:4块盘组成单组RAID 5,然后两组RAID 5再组成RAID 0最后得到8块盘的RAID 50
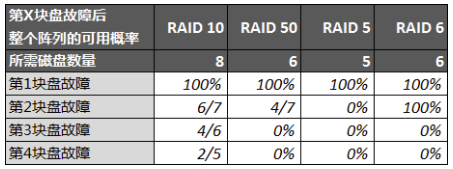
前置条件:
条带默认设置都是128K,阵列卡下SSD在条带化后存在数据位偏移(Offset),非4KB原生对齐;再加上阵列卡缓存以及SSD缓存,影响8K+的随机性能已经不是条带大小;
案例分析:
- 第1块盘的容错概率都是100%,可见磁盘阵列最基本的能力就是容错,然而不同级别的阵列能够提供的数据保护能力也是不同的;
- 从第2块盘开始除了RAID 6能够提供100%的故障可用性以外,其他包括RAID 10在内都不能提供完美的解决方案。同时我们可以发现RAID 5的容错能力是四者中最差的,但是要达到同样容量所需要的盘数量也是最少的,如果故障运维较为及时的话RAID 5是一个性价比较高的方案,不然在第一块盘故障后至阵列修复期间如果发生第二块盘故障就会导整个阵列故障(数据全部丢失),这就是风险所在;
- RAID 6当然是较为可靠的方案,但是它要牺牲两块盘的容量并且性能也较差(后面有性能测试说明),所以要权衡性能和可用性;
- 当然重点还是RAID 10和50:我们发现50在第二块盘故障时的可用概率和10比较接近,由于上述案例中只有两组RAID 5因此只能提供至最多两块盘的容错,如果RAID 5的组数量更多的话能够容错的盘数也将更多,且可用概率也会更高。
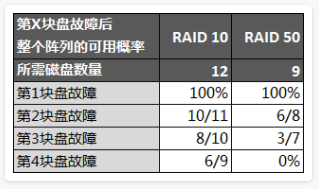
我们以9块盘RAID 50(3组RAID 5)为例作分析(达到相同容量的RAID 10需要12块盘):
再以12块盘RAID 50(4组RAID 5)为例作分析(达到相同容量的RAID 10需要16块盘):
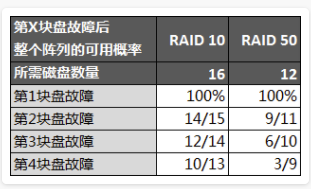
上面对比中RAID 50已经能够容忍第3甚至第4块盘的故障,只是可用性相比RAID 10低了些,但是两者都不能达到完美的100%,所以权衡可用性和成本RAID 50还是有相当大的优势。
接下来看看性能,为了能够很好地分析性能,我们沿用了第一组对比方案的作性能分析:
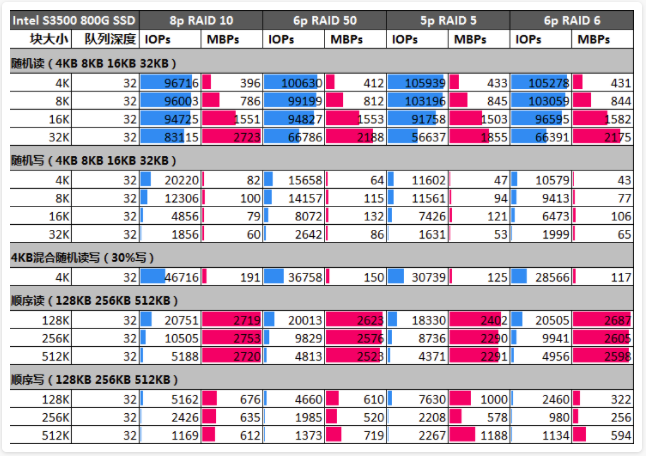
随机读分析:
理论上认为R10性能最好,真实测试数据显示4K、8K数据块下R5、R50、R6的性能都要优于R10;
当数据块增大到16K、32K时,R10的多盘优势才被逐渐体现出来。
随机写分析:
4K由于R50、R5由于有大量校验计算一定程度上影响了性能,但随着数据块逐渐增大,盘数量的优势也显现出来。当数据块达到和超过8K时,R50性能全面超越了R10;
R10由于存在R1的写同步问题,因此只有4块盘在支撑并发写,随着数据块的增大,R50和R5的多盘性能优势开始发挥。
混合随机读写分析:
得益多盘和无校验计算,混合读写R10领先;R50其次,和R10相差27%,性能也较为接近,R5和R50性能为线性关系,R6性能最差。
顺序读分析:
由于不存在校验计算,顺序读性能基本上由盘的数量决定;R50和R10性能也较为接近,同盘数的R6和R50性能相当,而盘数较少的R5性能相对前三者要弱一些,符合预期。至于为何R10性能无法线性增加,主要是因为阵列卡本身的性能限制。
顺序写分析:
顺序写R5被优化得最好;R50由于需要同时计算两次校验因此损失了一些性能,和R10性能相当,当数据块达到512K时,多盘优势进一步体现出来了,拉开了与R10的差距;R6由于校验和计算的实现较为复杂,顺序写性能也是最差的。
再来看看这些阵列方案的性能和容错特性:
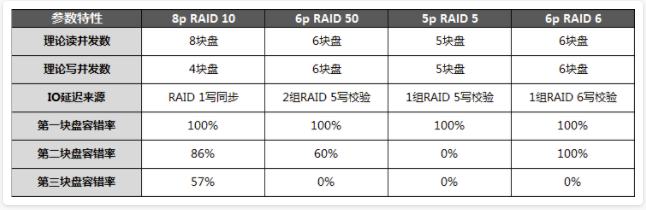
性能测试结论:
- 性能测试显示,相同容量的R50和R10性能接近:其中小块文件的随机读R50要全面好于R10,随机写4K虽然R50和R10差距在28%,但是块增大后R50要全面优于R10。顺序读写方面,R50和R10十分接近。
- 容错方面,R50接近R10:第二块盘容错率R50十分接近R10,两者相差30%。R10的优势主要是在有一定的概率提供第三、甚至第四块磁盘的容错率,但是考虑到并非100%容错,因此从容错角度来看R50虽然和R10有一些差距,但也已体现出较好的容错率,至少优于R5。而且R50搭配灵活,甚至可以指定3组R5以达到最大3块磁盘的容错;
- 成本方面,R50有很大优势:按这个配置计算R50只有R10的3/4。
总结
RAID 50提供了接近RAID 10性能、可用性以及接近RAID 5成本的特性,具有较好的整体性价比优势,所以考虑使用RAID 50替换RAID 10把!
SSD优化案例:读策略优化和中断多核绑定(小米)
业务场景
应用IO模型:大量读线程同时访问多块SSD,请求均为4KB随机读,并且被请求的数据有一定间隔连续性;
服务器硬件配置:LSI SAS 2308直连卡 + 8块SSD
优化前应用QPS:27K
第一轮优化:读策略优化
通过 /sys/block/sdx/queue/read_ahead_kb 观察到预读大小为128KB,进一步观察iostat情况:
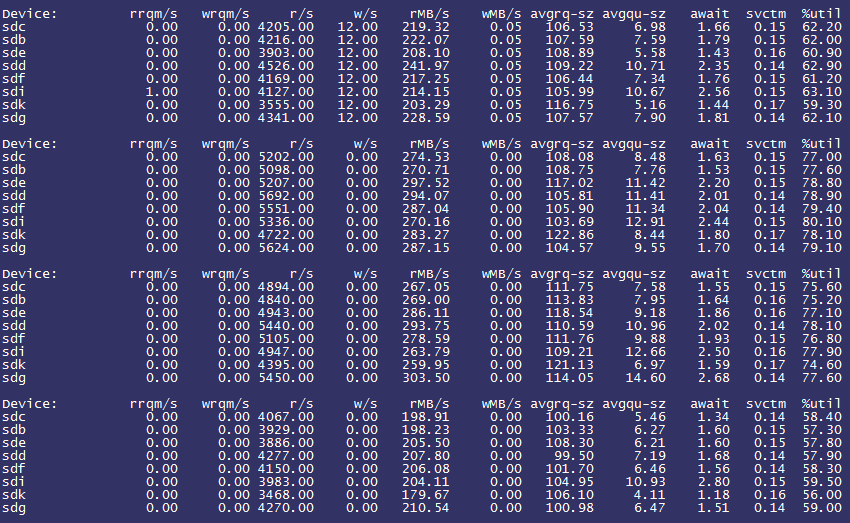
观察到每块SSD的rMB/s十分高,平均已经达到了250MB/s+,初步判断是由于read_ahead_kb的设置影响了应用的读效率(即预先读取了过多不必要的数据)。遂将read_ahead_kb设置为0,观察iostat情况如下:
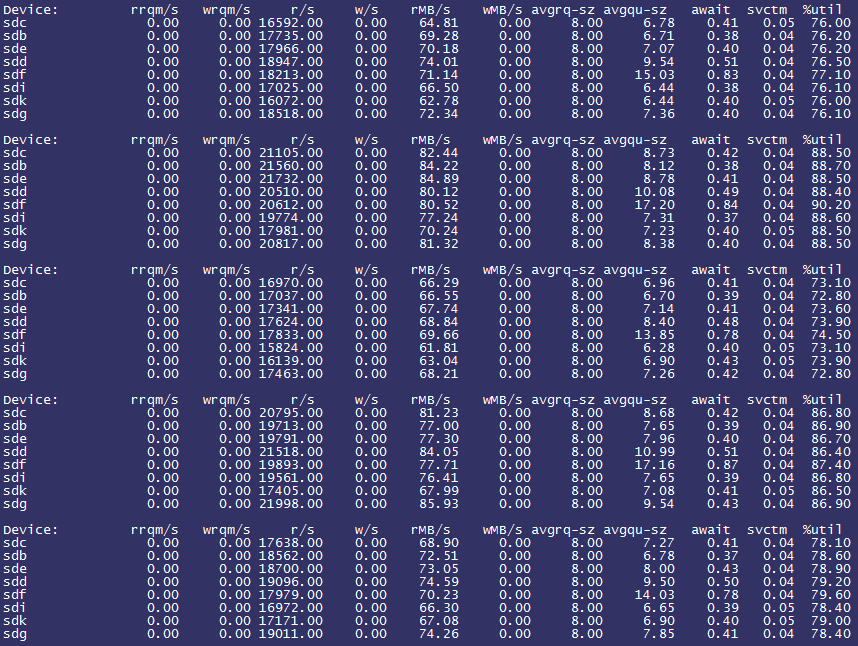
而应用QPS却下降至25K!
分析原因:由于之前有预读功能存在,因此部分数据已经被预先读取而减轻了SSD的访问压力。将read_ahead_kb设置为0后,所有的读访问均通过随机读实现,一定程度上加重了SSD的访问压力(可以观察到之前%util大约在60~80%之间波动,而预读改成0之后%util则在80~90%之间波动)
尝试16K预读
通过IO模型了解到每次请求的数据大小为4KB,因此将read_ahead_kb设置为16KB进行尝试,结果QPS由25K猛增到34K!
观察iostat情况如下:
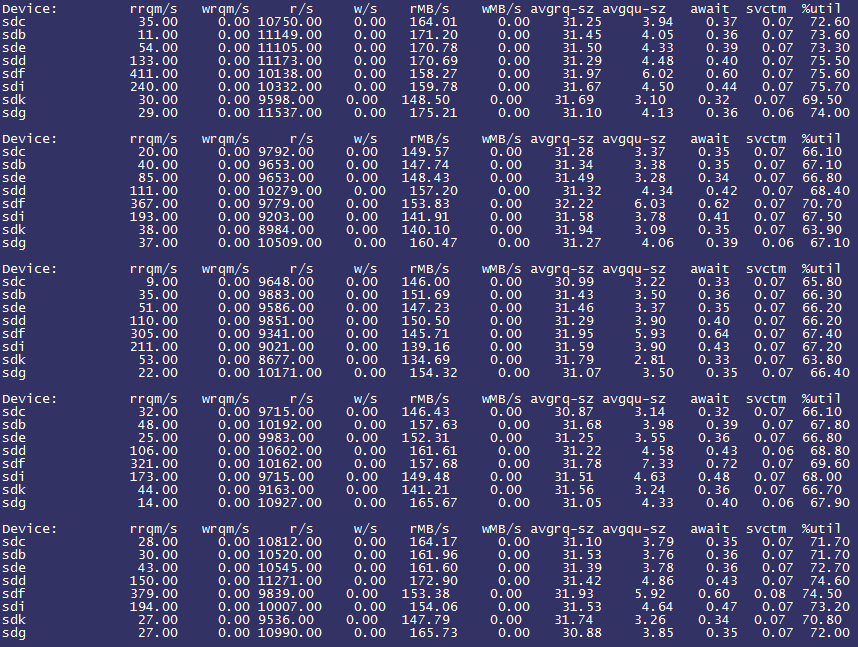
%util降了不少,而且通过rrqm/s可以发现出现了一部分读合并的请求,这说明优化确有成效。
此时CPU_WA也由原来的平均30%下降到20%,这说明处理器等待IO的时间减少了,进一步验证了IO优化的有效性。
第二轮优化:直连卡中断多核绑定
考虑到SSD的随机读写能力较强(通过上面的iostat可以发现),在多盘环境下每秒产生的IO请求数也已接近100K,了解到LSI SAS 2308芯片的IOPs处理极限大约在250K左右,因此判断直连卡控制芯片本身并不存在瓶颈。
其实我们担心更多的是如此大量的IO请求数必定会产生庞大数量的中断请求,如果中断请求全部落在处理器的一个核心上,可能会对单核造成较高的压力,甚至将单核压力打死。因此单核的中断请求的处理能力就有可能成为整个IO系统的瓶颈所在,于是我们通过mpstat观察每个核心上的中断数:
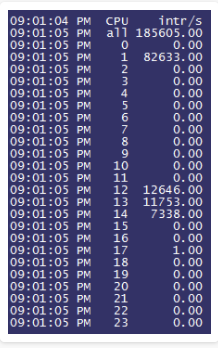
可以发现第二个核心中断数已经达到了十分恐怖的80K!再来观察实际的处理器核心压力情况,为了能够更加直观地了解,我们用了比较准确的i7z工具来观察:
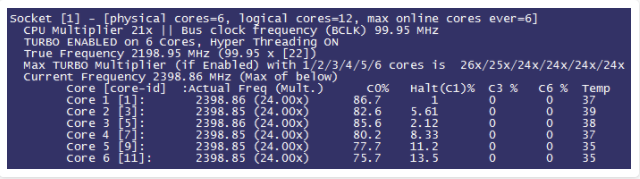
果然不出所料,Core 1的Halt(idle)已经到了1,充分说明第二个核心确实已经满载。
那么通过观察/proc/interrupt的情况再来进一步验证我们的假设,:
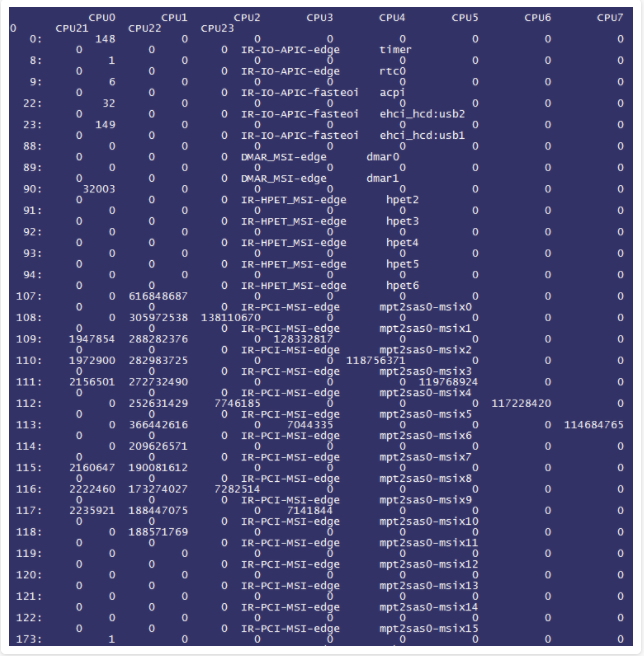
我们截取了片段,可以发现mpt2sas0-misx的大部分压力都集中在了CPU 1上,并且我们发现直连卡模式是支持多队列的(注意观察irq号从107至122,mpt2sas驱动总共有16个中断号),因此我们将实际在处理中断的irq号107至118分别绑定至不同的核心上(这里就不再赘述有关多核绑定的原理,有兴趣的同学可以百度搜索以上命令的含义):
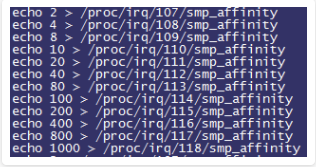
随后我们惊奇地观察到应用的QPS由34K再次猛增至39K!
通过观察mpstat发现大量的中断被平均分散到了不同的处理器核心上:
并且CPU_WA也由平均20%下降到15%,io wait被进一步优化!
优化总结:
- 通过以上两个优化方法将应用的QPS由27K优化至39K,并且处理器的iowait由30%下降至15%,优化收效显著;
- SSD的优化要根据实际的应用IO模型和设备的理论极限值进行综合考虑,同时还要考虑到各个层面的瓶颈(包括内核、IO策略、磁盘接口速率、连接控制芯片等)。
硬件调优
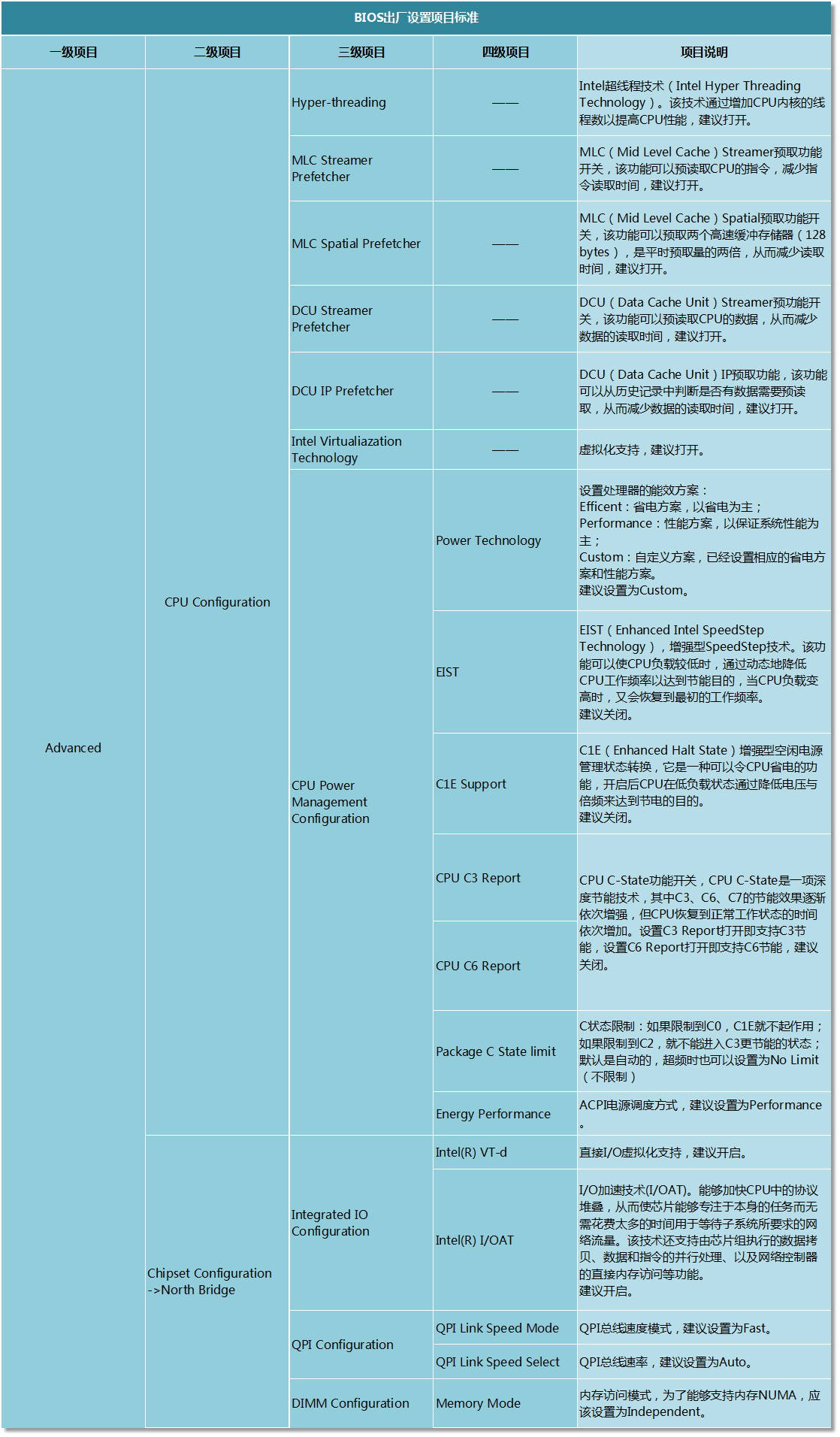
BIOS
服务器BIOS主要设置项目解说
有关BIOS主要设置项的说明:
1、处理器节电相关:C1E、C-State、电源模式、EIST等;
2、内存NUMA模式和访问速率等;
3、处理器超线程、虚拟化和直接IO访问等;
4、处理器指令优化:MLC、DCU等;
下表给出了详细设置项目的解说(以超微服务器BIOS设置项目为例):
网络优化
web 性能测试
网站压力测试工具 - Hey
安装
Linux 64-bit: https://hey-release.s3.us-east-2.amazonaws.com/hey_linux_amd64
Mac 64-bit: https://hey-release.s3.us-east-2.amazonaws.com/hey_darwin_amd64
Windows 64-bit: https://hey-release.s3.us-east-2.amazonaws.com/hey_windows_amd64
参数解析
Usage: hey [options...] <url>
Options:
-n 指定运行的总请求数。默认值为200。
-c 客户端并发执行的请求数,默认为50。总请求数不能小于并发数。
-q 客户端发送请求的速度限制,以每秒响应数QPS为单位,默认没有限制。
-z 发送请求的持续时长,超时后程序停止并退出。若指定了持续时间,则忽略总请求数(-n),例如-z 10s,-z 3m
-o 输出类型。若没有提供,则打印摘要。CSV是唯一支持的格式,结果以逗号分隔各个指标项。
-m 是HTTP方法,例GET,POST,PUT,DELETE,HEAD,OPTIONS方法
-H 代表HTTP请求头,可以用-H连续添加多个请求头。
-t 每个请求的超时时间(以秒为单位)。默认值为20s,数值0代表永不超时。
-A HTTP Accept header.
-d HTTP request body.
-D HTTP request body from file. For example, /home/user/file.txt or ./file.txt.
-T Content-type, defaults to "text/html".
-a Basic authentication, username:password.
-x HTTP Proxy address as host:port.
-h2 Enable HTTP/2.
-host HTTP Host header.
-disable-compression Disable compression.禁用压缩
-disable-keepalive Disable keep-alive, prevents re-use of TCP
connections between different HTTP requests.禁用保持活动状态,防止重新使用不同的HTTP请求之间的TCP连接。
-disable-redirects Disable following of HTTP redirects,禁用HTTP重定向
-cpus Number of used cpu cores.
(default for current machine is 8 cores)
简明示例
# 指定时长的get请求:客户端(-c)并发为2, 持续发送请求2s (-c)
hey -z 5s -c 2 https://www.baidu.com/
# 指定请求总数的get请求:运行2000次(-n),客户端并发为50(-c)
hey -n 2000 -c 50 https://www.baidu.com/
# 指定host的get请求:使用的cpu核数为2 (-cpus), 压测时长为5s(-z), 并发数为2
hey -z 5s -c 2 -cpus 2 -host "baidu.com" https://220.181.38.148
# 请求带header的get接口:压测时长为5s (-z), 客户端发送请求的速度为128QPS, 请求头用-H添加
hey -z 5s -q 128 -H "client-ip:0.0.0.0" -H "X-Up-Calling-Line-Id:X.L.Xia" https://www.baidu.com/
# 请求post请求
hey -z 5s -c 50 -m POST -H "info:firstname=xiuli; familyname=xia" -d "year=2020&month=1&day=21" https://www.baidu.com/
# 代理模式,需额外配置proxy:因部分ip频繁发请求有风险,故可用-x设置白名单代理向服务器发请求
hey -z 5s -c 10 -x "http://127.0.0.1:8001" http://baidu.com/
# shell for循环实现压测
for i in `seq 10`; do curl -v http://baidu.com; done

