
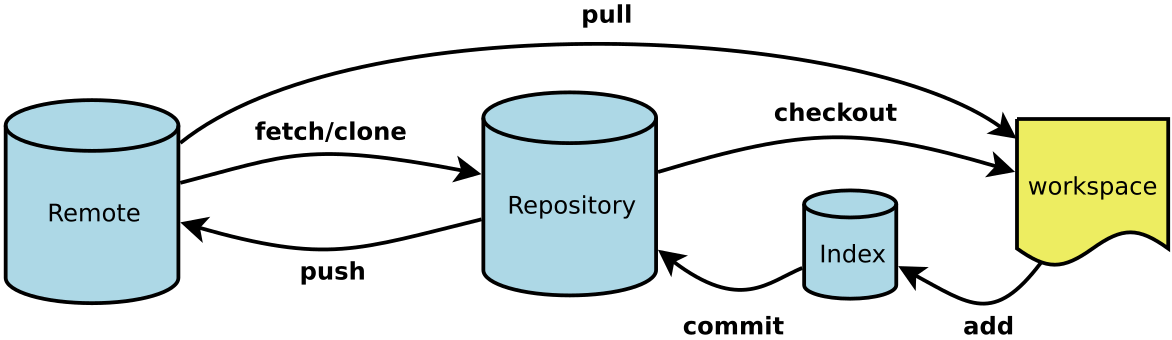
Git基本原理介绍
1. Git 初始化代码仓库
执行完成如下命令之后,我们可以得到下图所示的内容,右侧的就是 git 为我们创建的代码仓库,其中包含了用于版本管理所需要的内容。
# 左边执行
$ mkdir git-demo
$ cd git-demo && git init
watch -n 1 -d find .
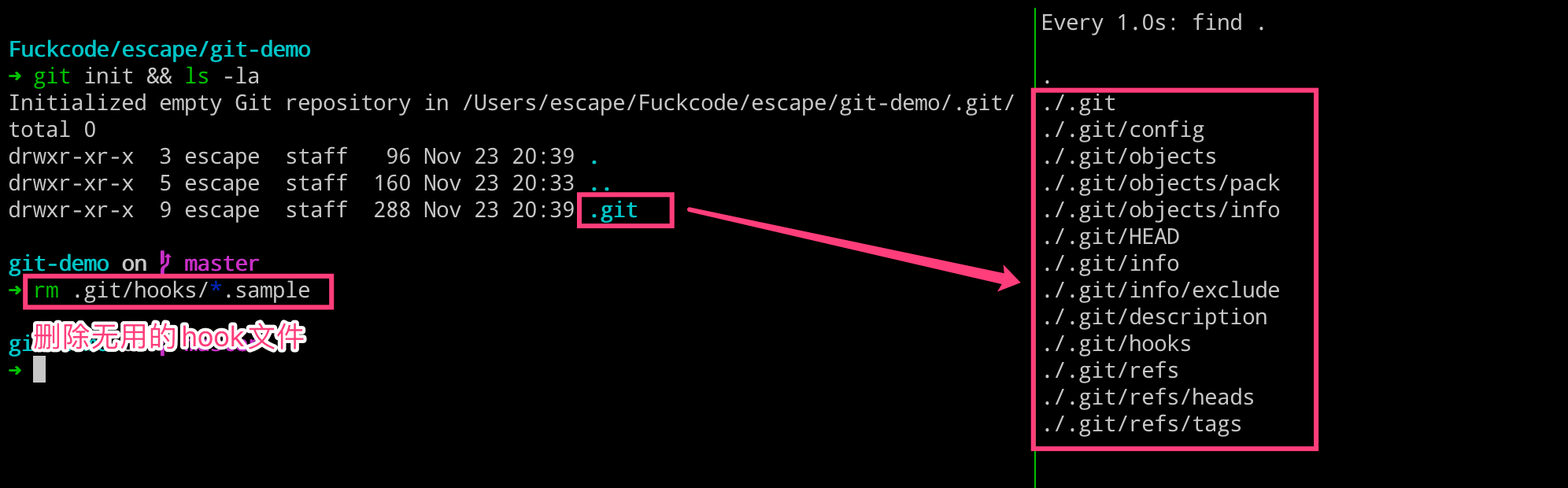
我们这里可以一起看下生成的 .git 目录的结构如何:
➜ tree .git
.git
├── HEAD
├── config
├── description
├── hooks
├── info
│ └── exclude
├── objects
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
[1] .git/config - 当前代码仓库本地的配置文件
- 本地配置文件(.git/config)和全局配置文件(~/.gitconfig)
- 通过执行如下命令,可以将用户配置记录到本地代码仓库的配置文件中去
git config user.name "demo"
git config user.email "demo@demo.com"
➜ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
ignorecase = true
precomposeunicode = true
[user]
name = demo
email = demo@demo.com
[2] .git/objects - 当前代码仓库代码的存储位置
- blob 类型
- commit 类型
- tree 类型
# 均无内容
➜ ll .git/objects
total 0
drwxr-xr-x 2 escape staff 64B Nov 23 20:39 info
drwxr-xr-x 2 escape staff 64B Nov 23 20:39 pack
➜ ll .git/objects/info
➜ ll .git/objects/pack
[3] .git/info - 当前仓库的排除等信息
➜ cat ./.git/info/exclude
# git ls-files --others --exclude-from=.git/info/exclude
# Lines that start with '#' are comments.
# For a project mostly in C, the following would be a good set of
# exclude patterns (uncomment them if you want to use them):
# *.[oa]
# *~
[4] .git/hooks - 当前代码仓库默认钩子脚本
./.git/hooks/commit-msg.sample
./.git/hooks/pre-rebase.sample
./.git/hooks/pre-commit.sample
./.git/hooks/applypatch-msg.sample
./.git/hooks/fsmonitor-watchman.sample
./.git/hooks/pre-receive.sample
./.git/hooks/prepare-commit-msg.sample
./.git/hooks/post-update.sample
./.git/hooks/pre-merge-commit.sample
./.git/hooks/pre-applypatch.sample
./.git/hooks/pre-push.sample
./.git/hooks/update.sample
[5] .git/HEAD - 当前代码仓库的分支指针
➜ cat .git/HEAD
ref: refs/heads/master
[6] .git/refs - 当前代码仓库的头指针
# 均无内容
➜ ll .git/refs
total 0
drwxr-xr-x 2 escape staff 64B Nov 23 20:39 heads
drwxr-xr-x 2 escape staff 64B Nov 23 20:39 tags
➜ ll .git/refs/heads
➜ ll .git/refs/tags
[7] .git/description - 当前代码仓库的描述信息
➜ cat .git/description
Unnamed repository; edit this file 'description' to name the repository.
2. add 之后发生了什么
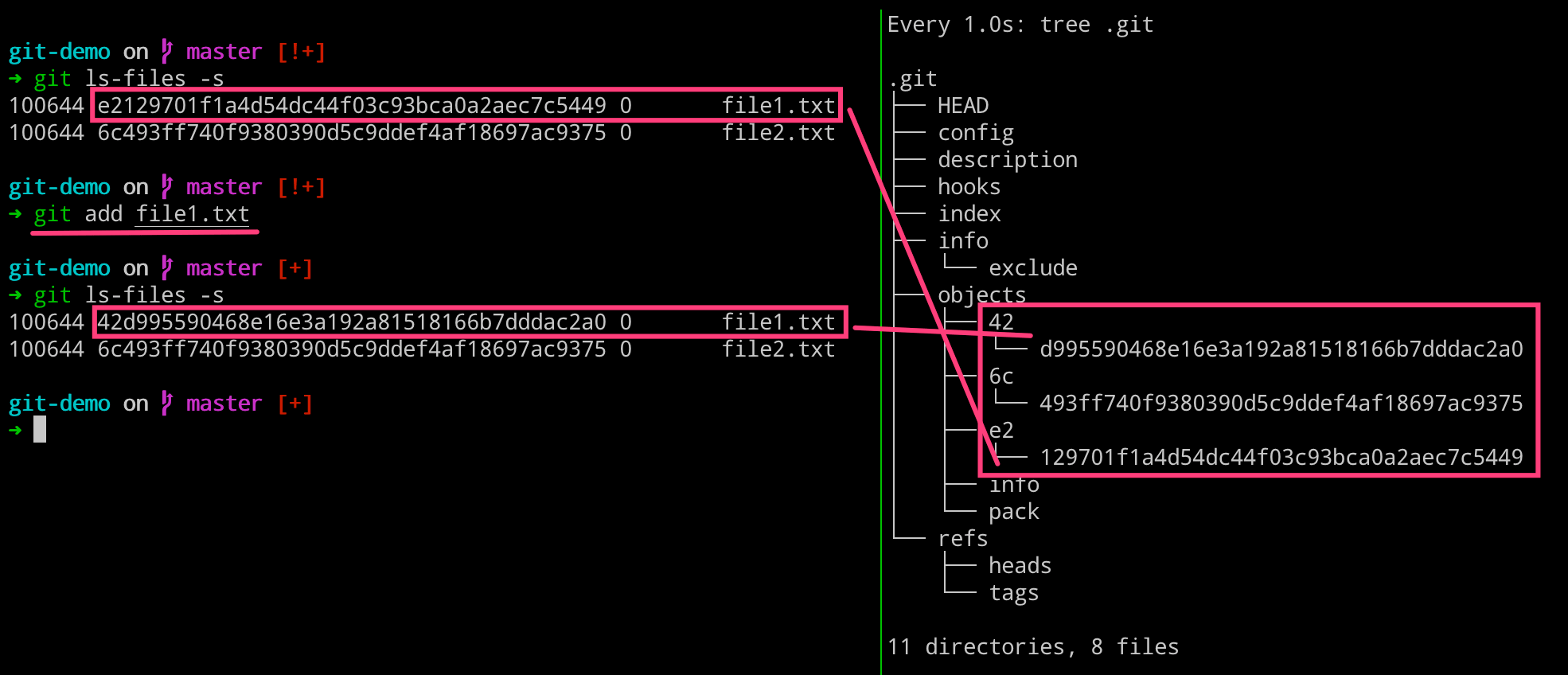
执行完成如下命令之后,我们可以得到下图所示的内容,我们发现右侧新增了一个文件,但是 git 目录里面的内容丝毫没有变化。这是因为,我们现在执行的修改默认是放在工作区的,而工作区里面的修改不归 git 目录去管理。
而当我们执行 git status 命令的时候,git 又可以识别出来现在工作区新增了一个文件,这里怎么做到的呢?—— 详见[3.理解 blob 对象和 SHA1]部分
而当我们执行 git add 命令让 git 帮助我们管理文件的时候,发现右侧新增了一个目录和两个文件,分别是 8d 目录、index 和 0e41.. 文件。
# 左边执行
$ echo "hello git" > helle.txt
$ git status
$ git add hello.txt
# 右边执行
$ watch -n 1 -d find .

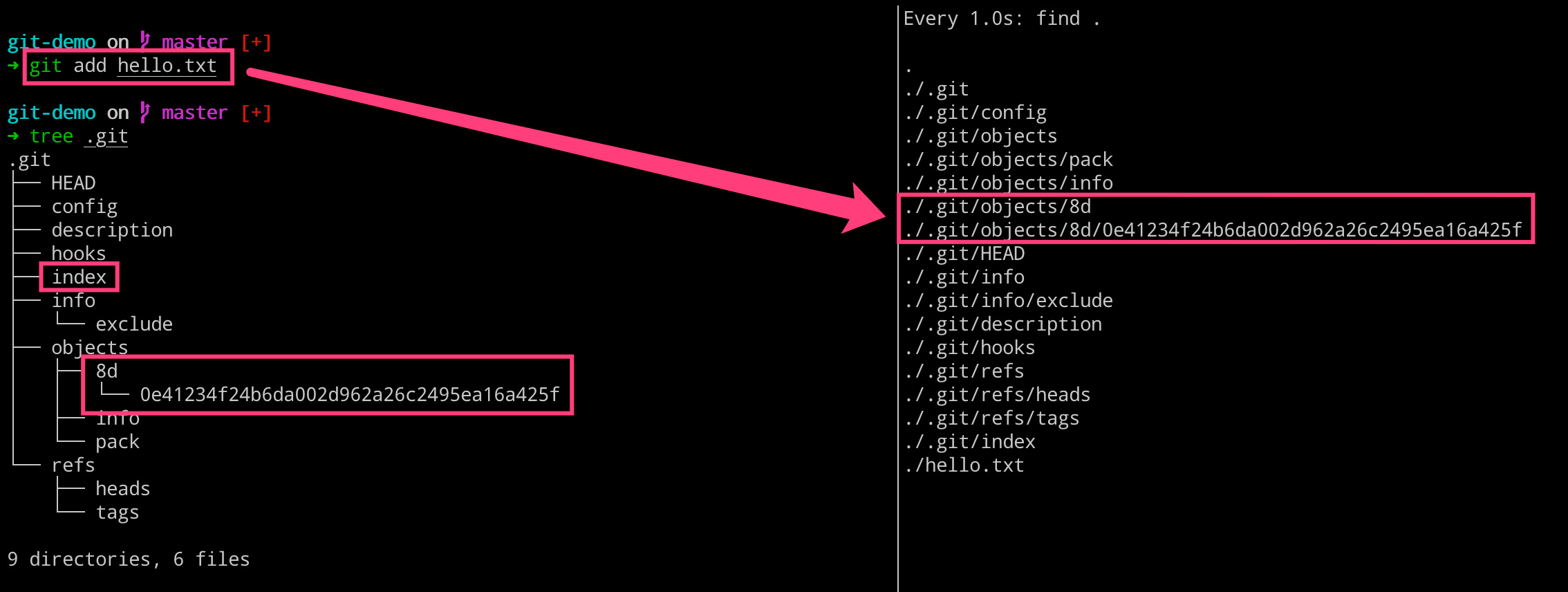
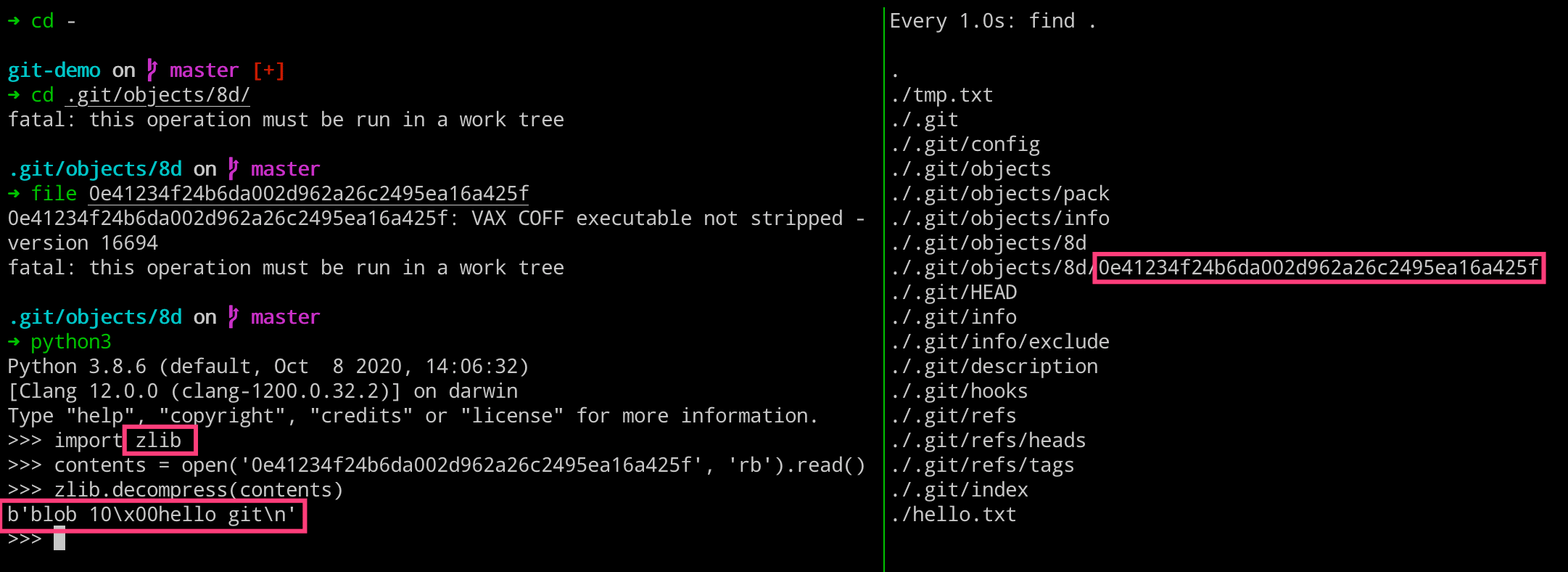
我们这里重点看下,生成的 8d 这个目录以及下面的文件。而其名称的由来是因为 git 对其进行了一个叫做 SHA1 的 Hash 算法,用于将文件内容或者字符串变成这么一串加密的字符。
# 查看objects的文件类型
$ git cat-file -t 8d0e41
blob
# 查看objects的文件内容
$ git cat-file -p 8d0e41
hello git
# 查看objects的文件大小
$ git cat-file -s 8d0e41
10
# 拼装起来
blob 10\0hello git
现在我们就知道了,执行 git add 命令将文件从工作区添加到暂存区里面,git 会把帮助我们生成一些 git 的对象,它存储的是文件的内容和文件类型并不存储文件名称。
为了验证我们上述的说法,我们可以添加同样的内容到另一个文件,然后进行提交,来观察 .git 目录的变化。我们发现,右侧的 objects 目录并没有新增目录和文件。这就可以证明,blob 类型的 object 只存储的是文件的内容,如果两个文件的内容一致的话,则只需要存储一个 object 即可。
话说这里 object 为什么没有存储文件名称呢?这里因为 SHA1 的 Hash 算法计算哈希的时候,本身就不包括文件名称,所以取什么名称都是无所谓的。那问题来了,就是文件名的信息都存储到哪里去了呢?—— 详见[3.理解 blob 对象和 SHA1]部分
# 左边执行
$ echo "hello git" > tmp.txt
$ git add tmp.txt
# 右边执行
$ watch -n 1 -d find .
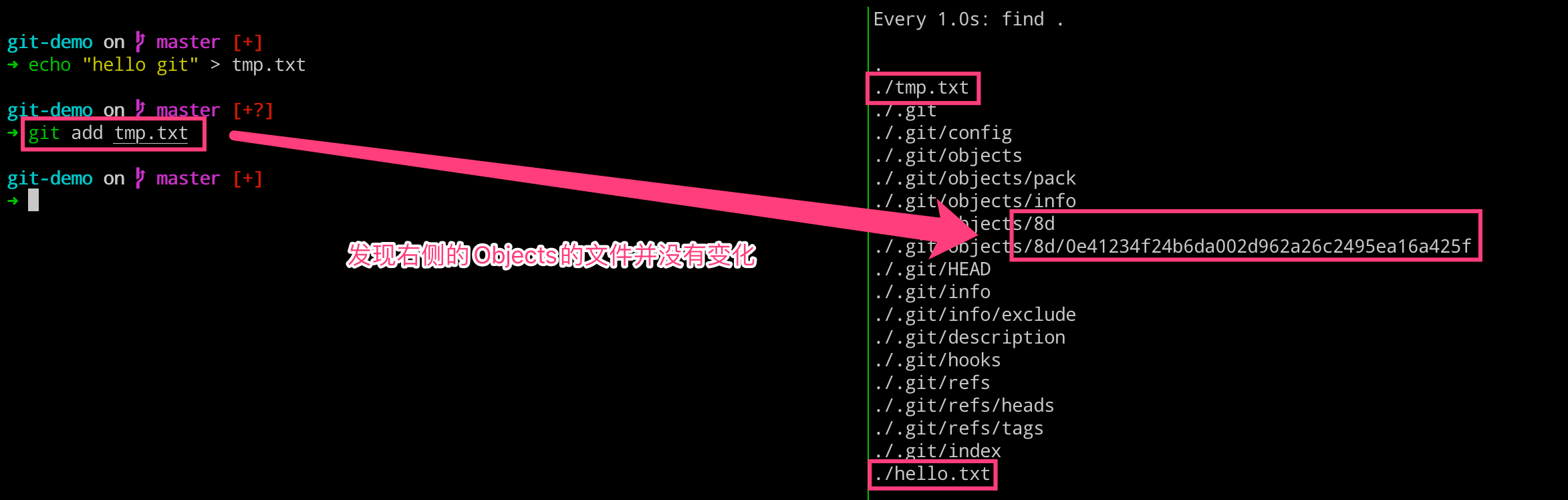
3. 理解 blob 对象和 SHA1
Hash 算法是把任意长度的输入通过散列算法变化成固定长度的输出,根据算法的不同,生成的长度也有所不同。
Hash 算法
MD5 - 128bit - 不安全 - 文件校验
SHA1 - 160bit(40位) - 不安全 - Git存储
SHA256 - 256bit - 安全 - docker镜像
SHA512 - 512bit - 安全
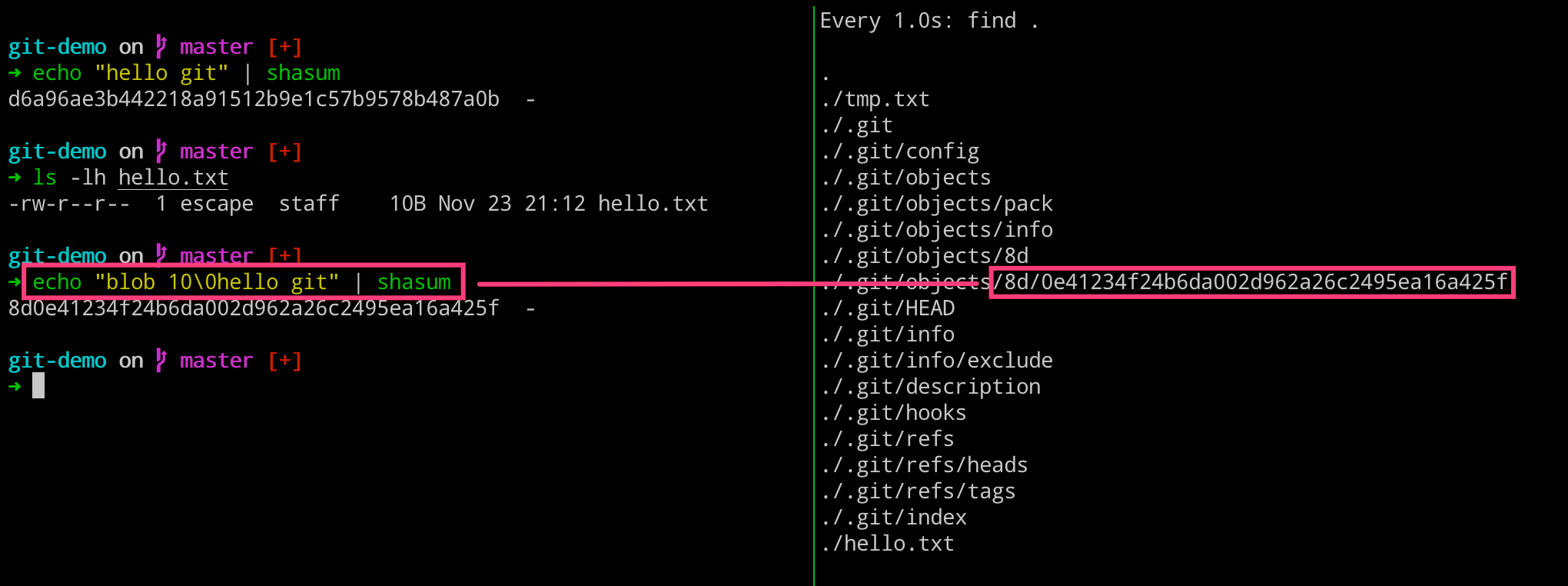
但是,当我们使用工具对上述文件内容进行 SHA1 计算的时候,会发现并没有我们在 .git 目录里面看到的那样,这是为什么呢?
➜ echo "hello git" | shasum
d6a96ae3b442218a91512b9e1c57b9578b487a0b -
这里因为 git 工具的计算方式,是使用 类型 长度\0 内容 的方式进行计算的。这里,我们算了下文件内容只有九位,但是这里是十位,这里因为内容里面有换行符的存在导致的。现在我们就可以使用 git cat-file 命令来拼装 git 工具存储的完整内容了。
➜ ls -lh hello.txt
-rw-r--r-- 1 escape staff 10B Nov 23 21:12 hello.txt
➜ echo "blob 10\0hello git" | shasum
8d0e41234f24b6da002d962a26c2495ea16a425f -
# 拼装起来
blob 10\0hello git
当我们使用 cat 命令来查看 object 对象里面的内容的时候,发现看着像是一串乱码。其实这是 git 工具将文件的原始内容进行一个压缩,然后再存储到 object 对象里面。奇怪的是,我们发现压缩之后的内容反而比原始内容还大!
这是因为其进行了压缩,存储了一些压缩相关的信息。上例所示的比原始文件大,是因为我们创建的内容实在是太小了。当我们常见一个比较大的文件时,就会看到压缩之后的文件大小远小于原始文件的。
➜ cat .git/objects/8d/0e41234f24b6da002d962a26c2495ea16a425f
xKOR04`HWH,6A%
➜ ls -lh .git/objects/8d/0e41234f24b6da002d962a26c2495ea16a425f
-r--r--r-- 1 escape staff 26B Nov 23 21:36 .git/objects/8d/0e41234f24b6da002d962a26c2495ea16a425f
➜ file .git/objects/8d/0e41234f24b6da002d962a26c2495ea16a425f
.git/objects/8d/0e41234f24b6da002d962a26c2495ea16a425f: VAX COFF executable not stripped - version 16694
其实,我们这里也是可以通过 python 代码来获取二进制 object 对象的内容的。
import zlib
contents = open('0e41234f24b6da002d962a26c2495ea16a425f', 'rb').read()
zlib.decompress(contents)
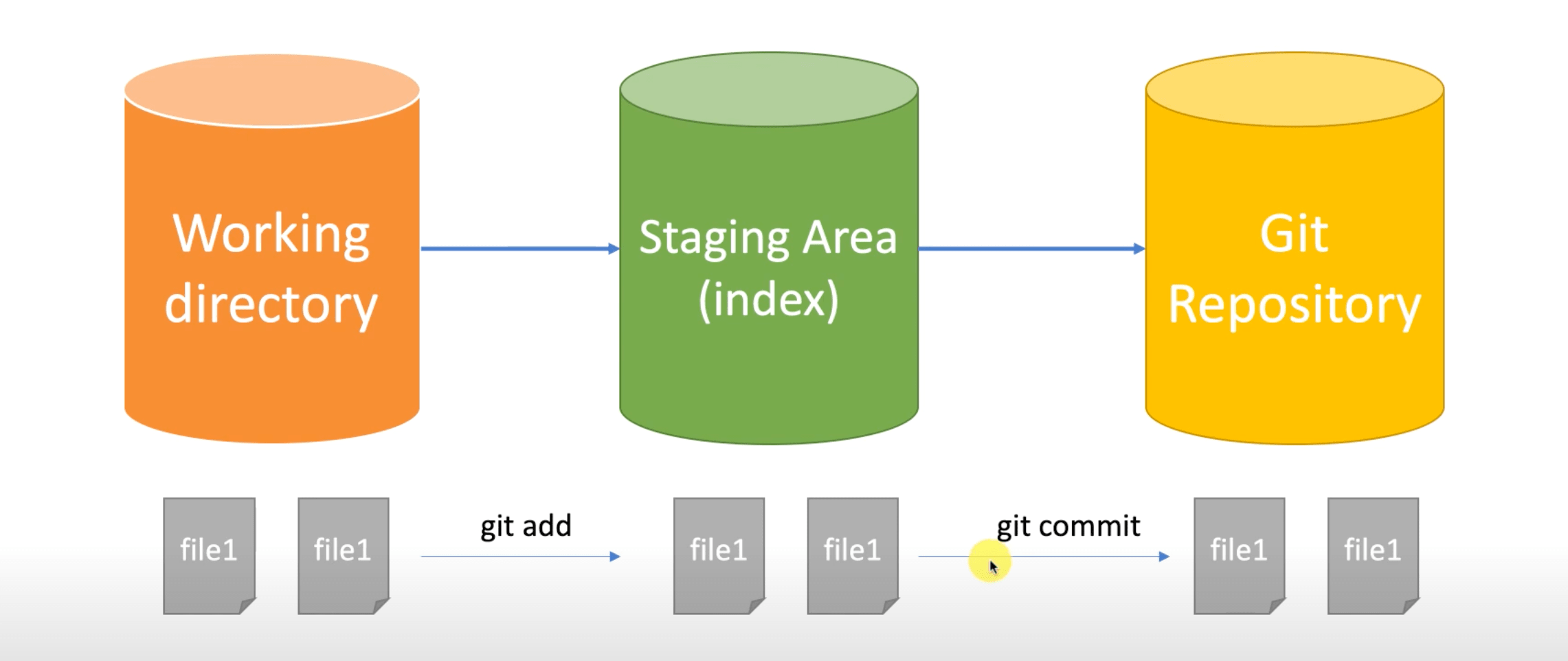
4. 聊聊工作区和暂存区
之前的章节我们也聊到了,当我们执行 git status 命令的时候,git 工具怎么知道我们有一个文件没有追踪,以及文件名的信息都存储到哪里去了?
这一切的答案,都要从工作区和索引区讲起。git 根据其存储的状态不同,将对应状态的“空间”分为工作区、暂存区(也可称为索引区)和版本区三类。具体示例,可以参考下图。
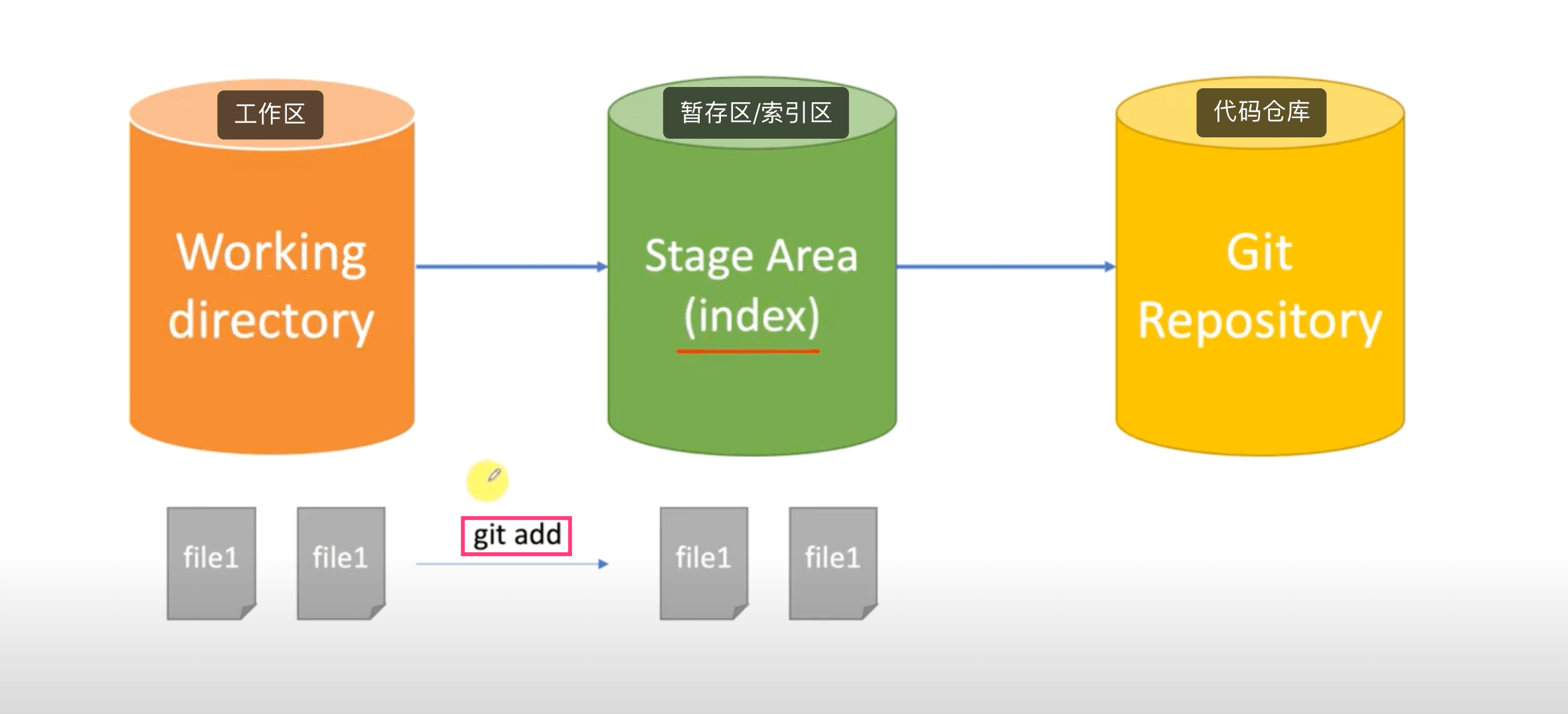
而更加深层次的理解,就要从执行 git add 命令后生成相关的 object 对象,但是其存储的是文件的类容、大小和内容,并不包含文件名称的信息。而文件名称相关的信息就包含在生成的 index 文件(索引文件)里面。
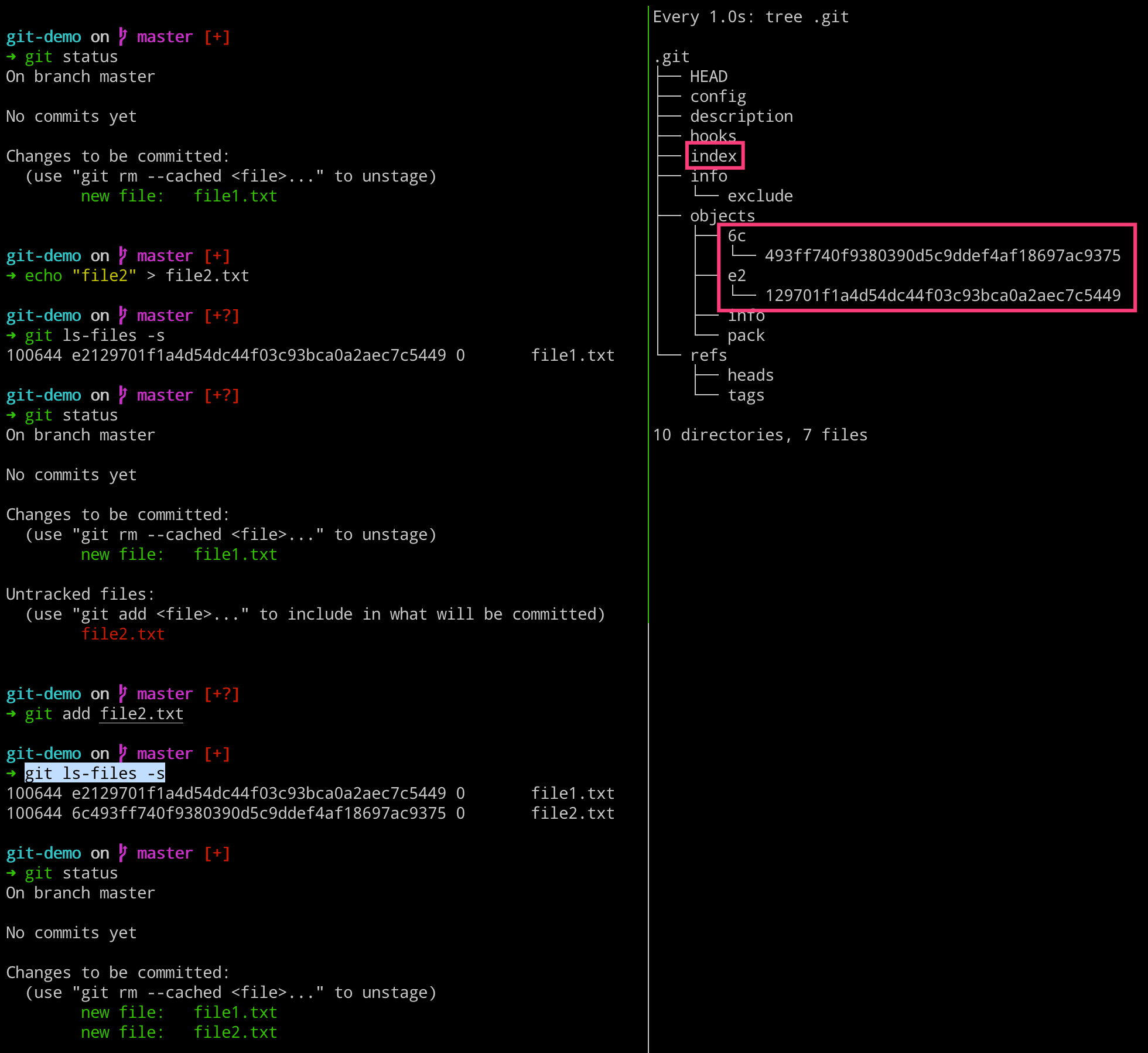
当我们直接查看 index 文件里面的内容,发现使我们无法理解的乱码,但是通过基本的输出,我们可以看到其文件名称。要想查看 index 文件的内容,可以通过 git 提供的相关命令进行查看。
# 左边执行
$ echo "file1" > file1.txt
$ git add file1.txt
$ cat .git/index
$ git ls-files # 列出当前暂存区的文件列表信息
$ git ls-files -s # 列出当前暂存区文件的详细信息
# 右边执行
$ watch -n 1 -d tree .git

当添加文件的时候,文件或目录会从工作区流向暂存区,加之一些其他操作,会导致工作区和暂存区是会有一定差别的。这就会导致,当我们执行 git status 的结果就是两者的差别。
经过如下操作,会使工作区和暂存区和的内容不一致了,通过命令我们也是可以查看区别的。当我们使用 add 命令将新文件添加到暂存区的时候,会发现这下就一致了。
# 左边执行
$ git status
$ echo "file2" > file2.txt
$ git ls-files -s
$ git status
$ git add file2.txt
$ git ls-files -s
$ git status
# 右边执行
$ watch -n 1 -d tree .git
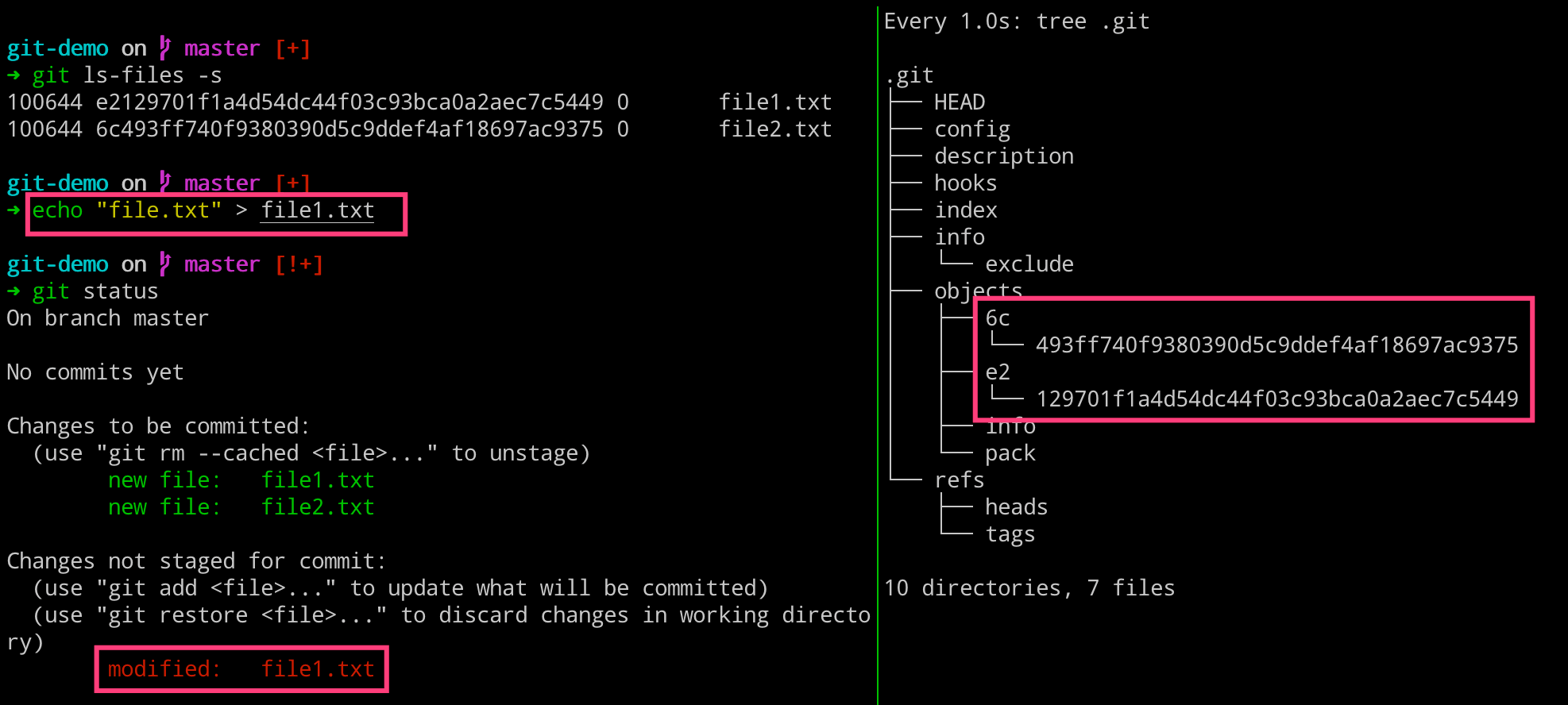
如果我们这里去修改一个文件的话,很显然这个时候我们的工作区和暂存区又不一致了。当我们使用命令去查看文件状态的时候,发现一个文件被修改了,而 git 是怎么知道的呢?咳咳,就是通过查找 index 文件的内容,找到对应文件名称以及其内部引用的 object 对象,与工作区的文件内容进行对比而来的。
# 左边执行
$ git ls-files -s
$ echo "file.txt" > file1.txt
$ git status
# 右边执行
$ watch -n 1 -d tree .git
而这个时候,我们再使用 git add 命令将其修改内容保存至暂存区的话,会发现对应文件的 object 的 blob 对象的引用值发生改变了。这时可以发现,objects 目录下面有三个对象了,其中 file1.txt 占了两个,但是文件却只有两个。通过命令查看对应 blob 对象的内容,发现各有不同。
# 左边执行
$ git ls-files -s
$ git add file1.txt
$ git ls-files -s
# 右边执行
$ watch -n 1 -d tree .git
5. 理解 commit 提交原理
Git 仓库中的提交记录保存的是你的目录下所有文件的快照,就像是把整个目录复制,然后再粘贴一样,但比复制粘贴优雅许多!Git 希望提交记录尽可能地轻量,因此在你每次进行提交时,它并不会盲目地复制整个目录。条件允许的情况下,它会将当前版本与仓库中的上一个版本进行对比,并把所有的差异打包到一起作为一个提交记录。Git 还保存了提交的历史记录。这也是为什么大多数提交记录的上面都有父节点的原因。
当我们使用 add 命令将工作区提交到暂存区,而暂存区其实保存的是当前文件的一个状态,其中包括有哪些目录和文件,以及其对应的大小和内容等信息。但是我们最终是需要将其提交到代码仓库(本地)的,而其命令就是 git commit 了。
而当我们执行 git commit 命令的时候,究竟都发生了什么呢?可以看到当提交之后,.git 目录中生成了两个信息的 object 对象,其中 logs 和 refs 目录都有新的文件生成。通过如下操作,我们可以查看到其提交的类型和对应内容。
# 左边执行
$ git commit -m "1st commit"
$ git cat-file -t 6e4a700 # 查看commit对象的类型
$ git cat-file -p 6e4a700 # 查看commit对象的内容
$ git cat-file -t 64d6ef5 # 查看tree对象的类型
$ git cat-file -p 64d6ef5 # 查看tree对象的内容
# 右边执行
$ watch -n 1 -d tree .git
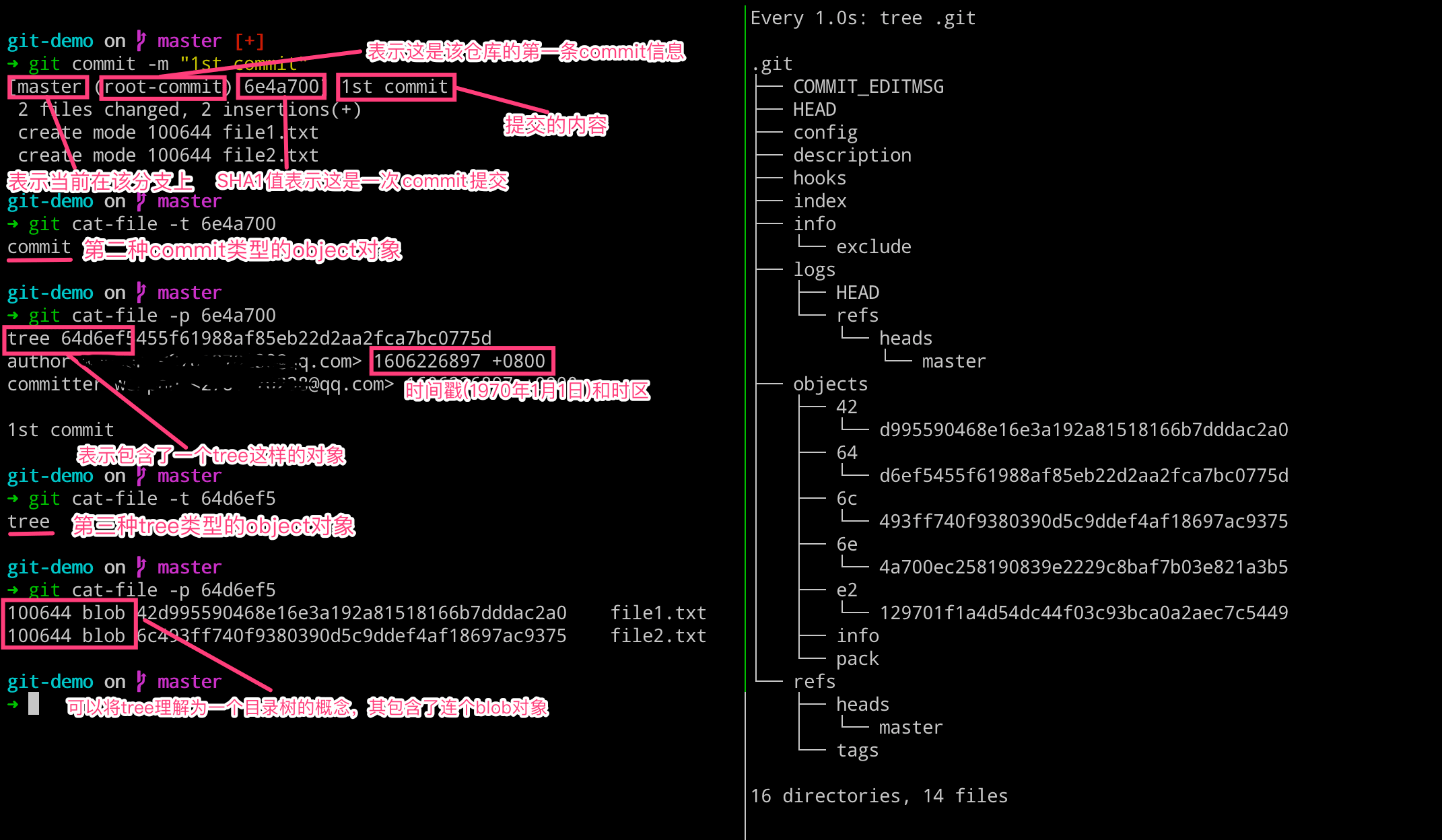
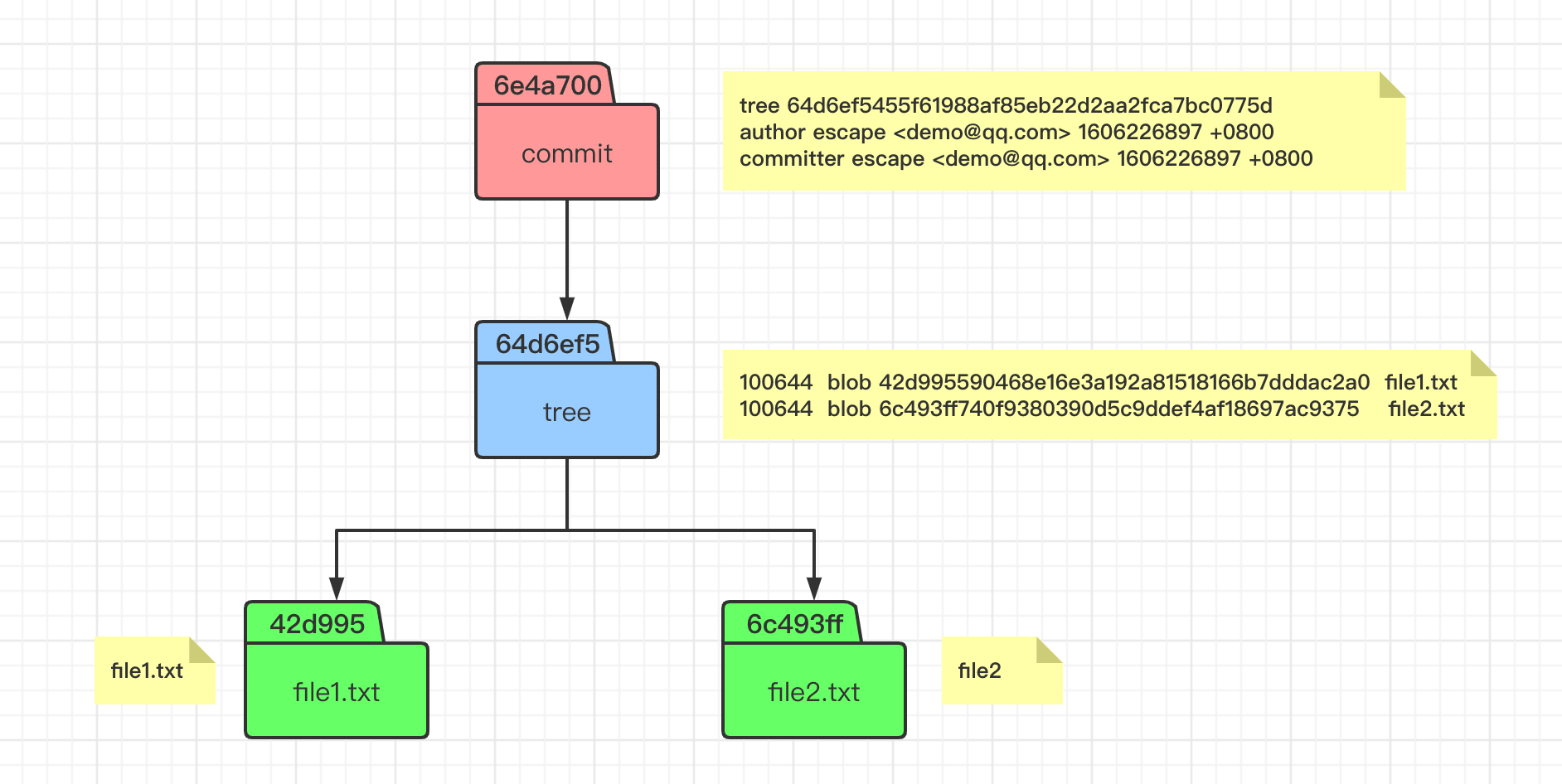
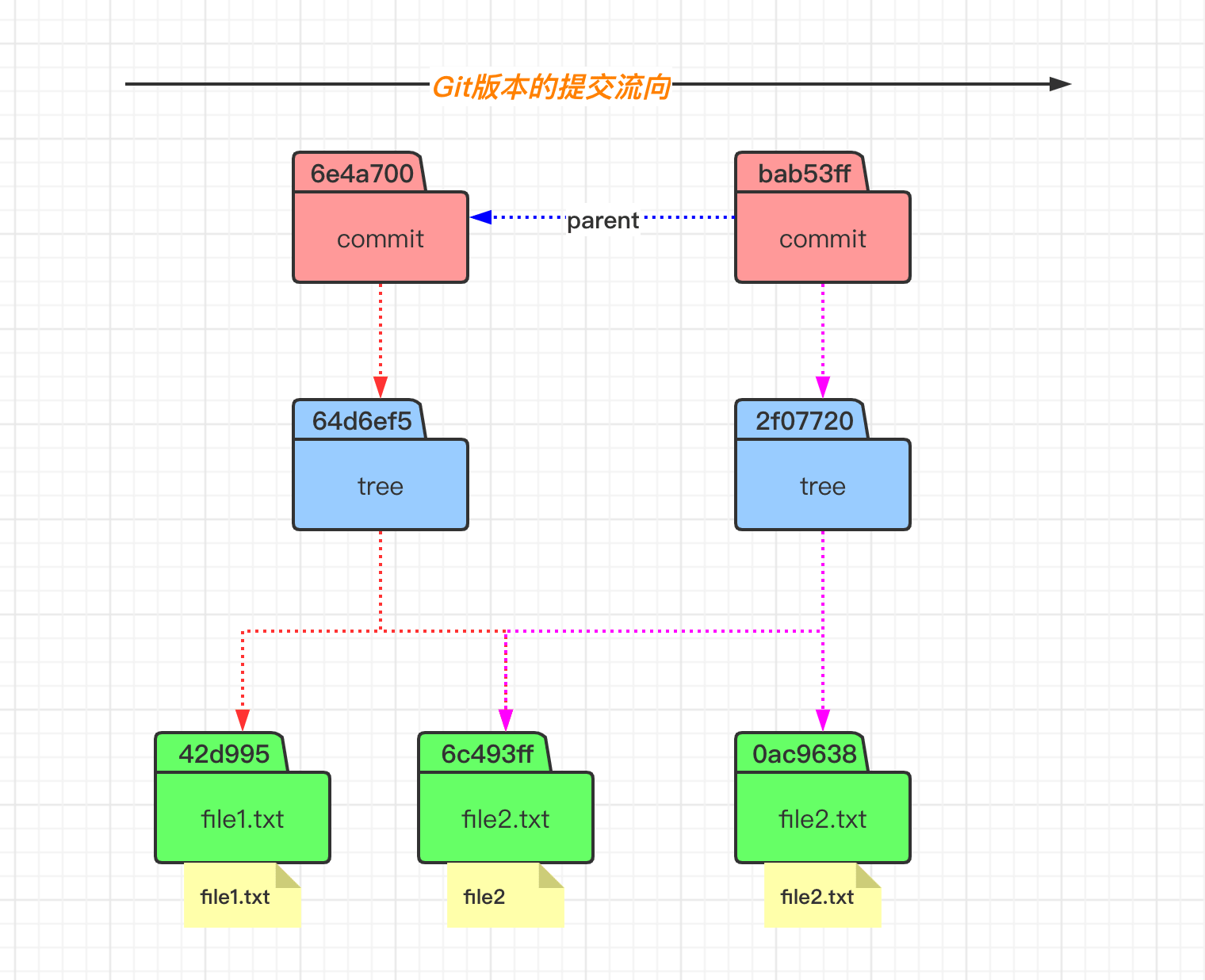
这样我们就理解了,当我们执行 git commit 命令之后,会生成一个 commit 对象和一个 tree 对象。commit 对象内容里面包含了一个 tree 对象和相关提交信息,而 tree 对象里面则包含了这次我们提交版本里面的文件状态(文件名称和 blob 对象),这样我们就知道了这次提交的变动了。
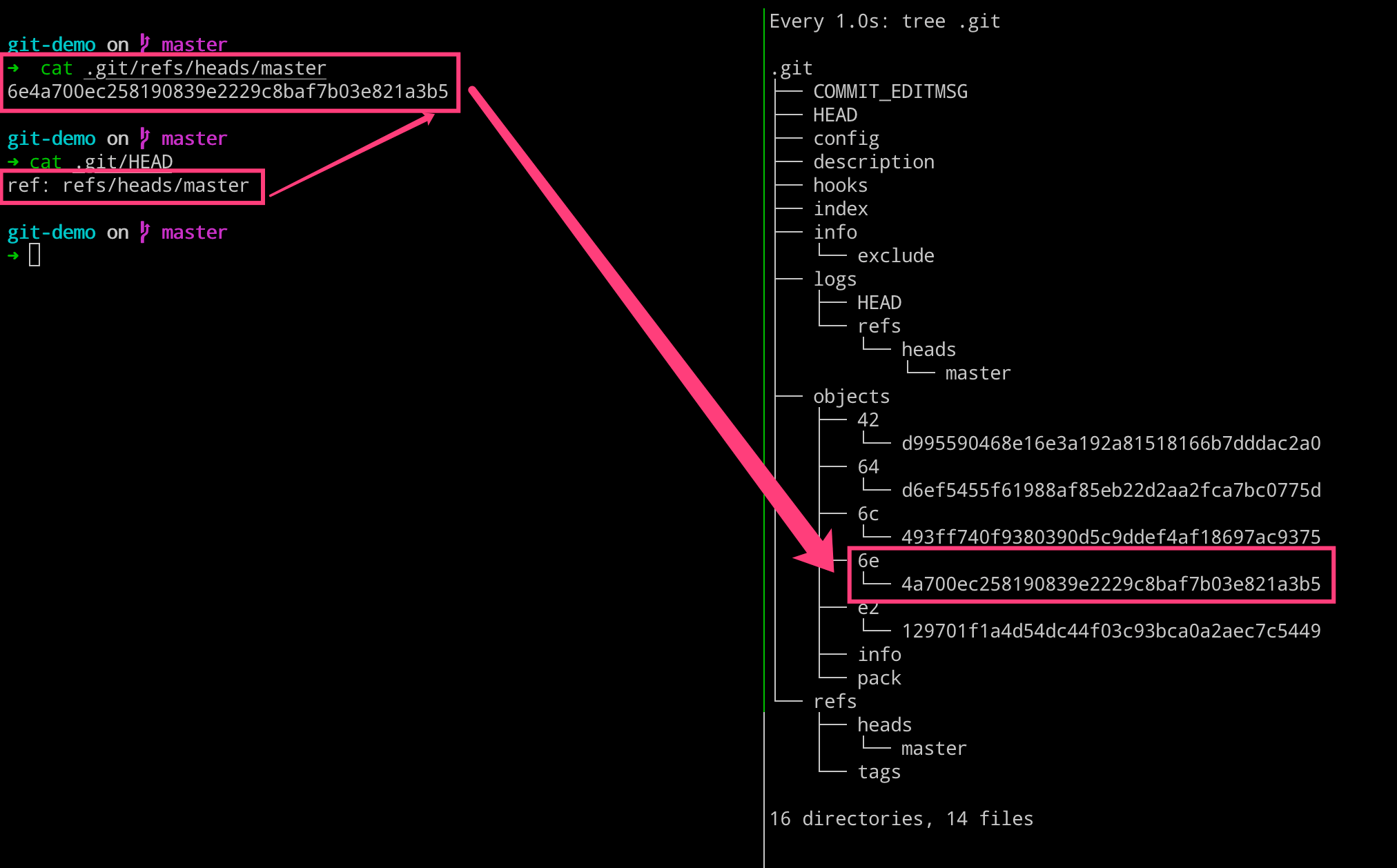
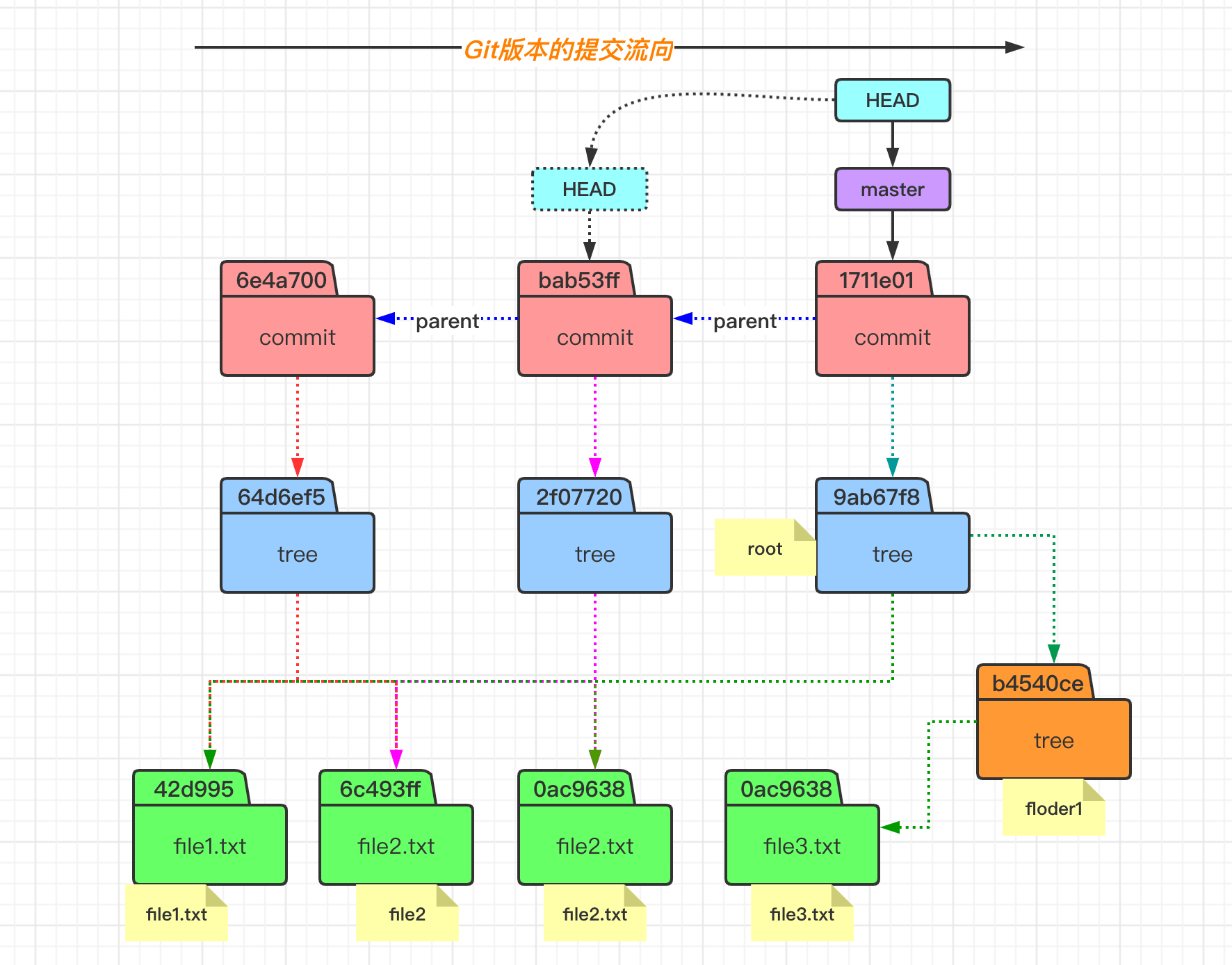
我们这次提交之后,处理 objects 目录发生变动之外,还有一些其他的变化。比如 logs 和 refs 的目录有所变化。我们查看 refs 目录里面的内容,发现其指向了 6e4a70 这个 commit 对象,即当前 master 分支上面最新的提交就是这个 6e4a70 了。
而这个 6e4a70 这个 commit 对象,有一个 HEAD 的指向,就是 .git 目录下的 HEAD 文件。其实质就是一个指针,其永远指向我们当前工作的分支,即这里我们工作在 master 分支上。当我们切换分支的时候,这个文件的指向也会随机改变的。
# 左边执行
$ cat .git/refs/heads/master
$ cat .git/HEAD
# 右边执行
$ watch -n 1 -d tree .git
6. 加深理解 commit 提交
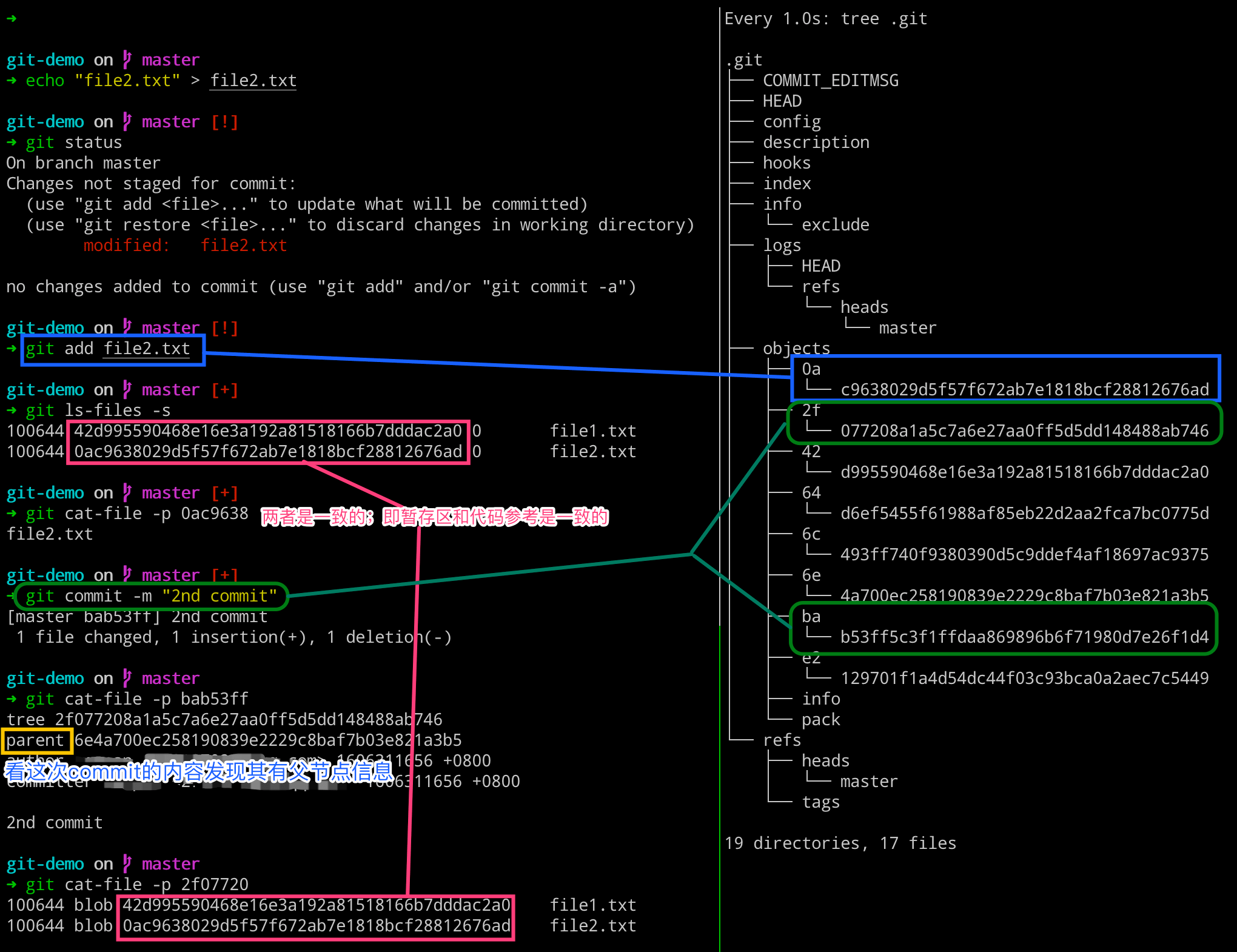
当我们再次对 file2.txt 文件的内容进行变更、添加以及提交之后,发现在提交的时候,查看的 commit 对象的内容时,其包含有父节点的 commit 信息。而对于理解的话,可以看看下面的这个提交流程图。
# 左边执行
$ echo "file2.txt" > file2.txt
$ git status
$ git add file2.txt
$ git ls-files -s
$ git cat-file -p 0ac9638
$ git commit -m "2nd commit"
$ git cat-file -p bab53ff
$ git cat-file -p 2f07720
# 右边执行
$ watch -n 1 -d tree .git
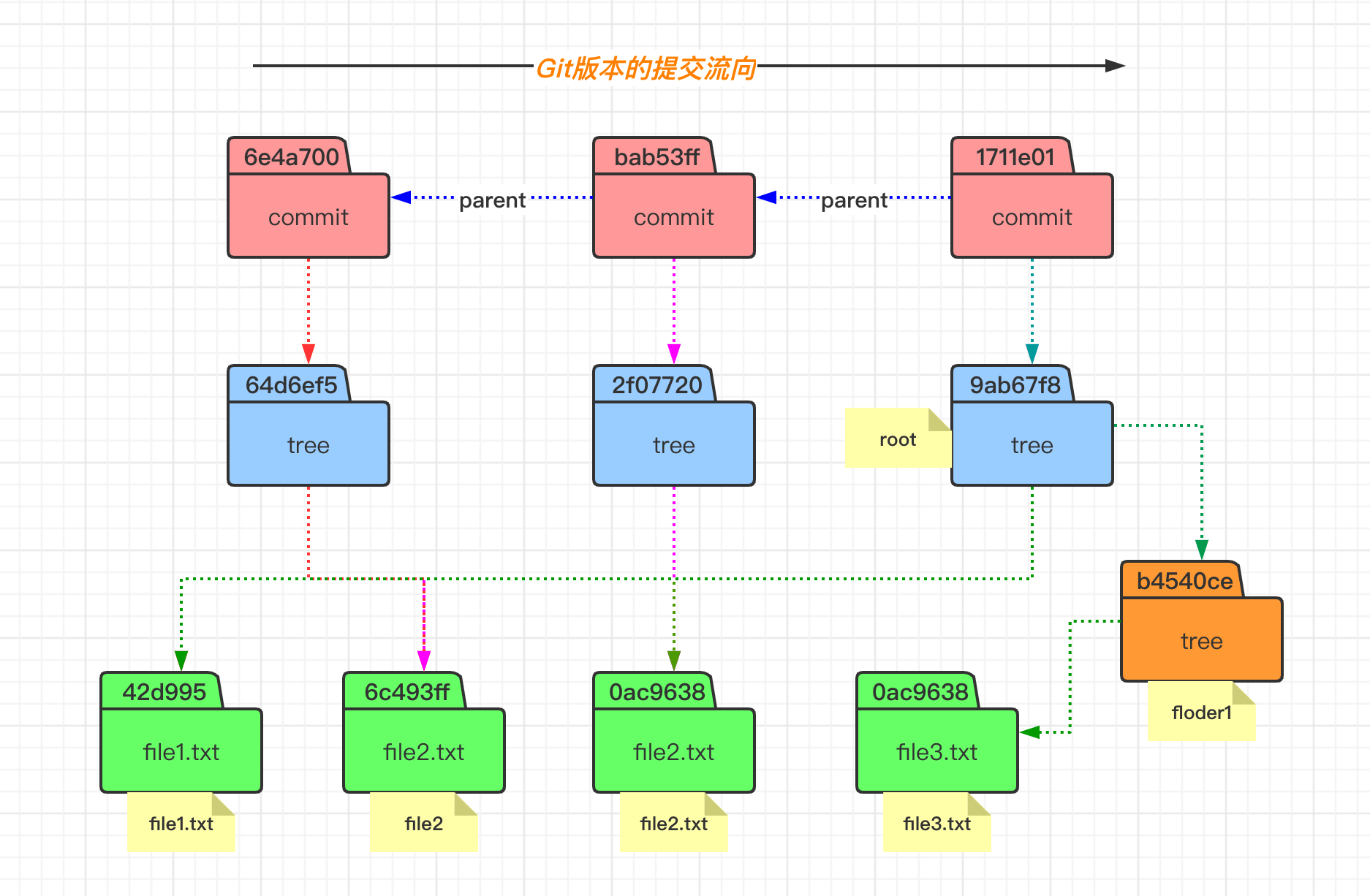
在 Git 中空文件夹是不算在追踪范围内的,而且添加文件夹并不会增加 object 对象。当我们查看 index 内容的时候,会发现文件名称是包含相对路径的。
而当我们通过 commit 命令提交之后,会发现生成了三个 object 对象,因为 commit 操作不会生成 blob 对象,所以分别是一个 commit 对象和两个 tree 对象。可以发现,tree 对象里面有包含了一个目录的 tree,其里面包含对象文件内容。
下图所示的文件状态,可以体会到 git 中版本的概念。即 commit 对象指向一个该版本中的文件目录树的根(tree),然后 tree 在指向 blob 对象(文件)和 tree 对象(目录),这样就可以无限的往复下去形成一个完整的版本。
# 左边执行
$ mkdir floder1
$ echo "file3" > floder1/file3.txt
$ git add floder1
$ git ls-files -s
$ git commit -m "3rd commit"
$ git cat-file -p 1711e01
$ git cat-file -p 9ab67f8
# 右边执行
$ watch -n 1 -d tree .git
7. 文件的生命周期状态
现在,我们已经基本理解了文件如何在工作区、暂存区以及代码仓库之间进行状态的跟踪和同步。在 Git 的操作中,文件的可能状态有哪些,以及如何进行状态切换的,我们这里一起总结一下!

8. Branch 和 HEAD 的意义
到底什么是分支?分支切换又是怎么一回事?我们通过查看 Git 的官方文档,就可以得到,分支就是一个有名字的(master/dev)指向 commit 对象的一个指针。
我们在初始化仓库的时候,提供会默认给我们分配一个叫做 master 的分支(在最新的版本默认仓库已经变更为main了),而 master 分支就是指向最新的一次提交。为什么需要给分支起名字呢?就是为了方便我们使用和记忆,可以简单理解为 alias 命令的意义一致。
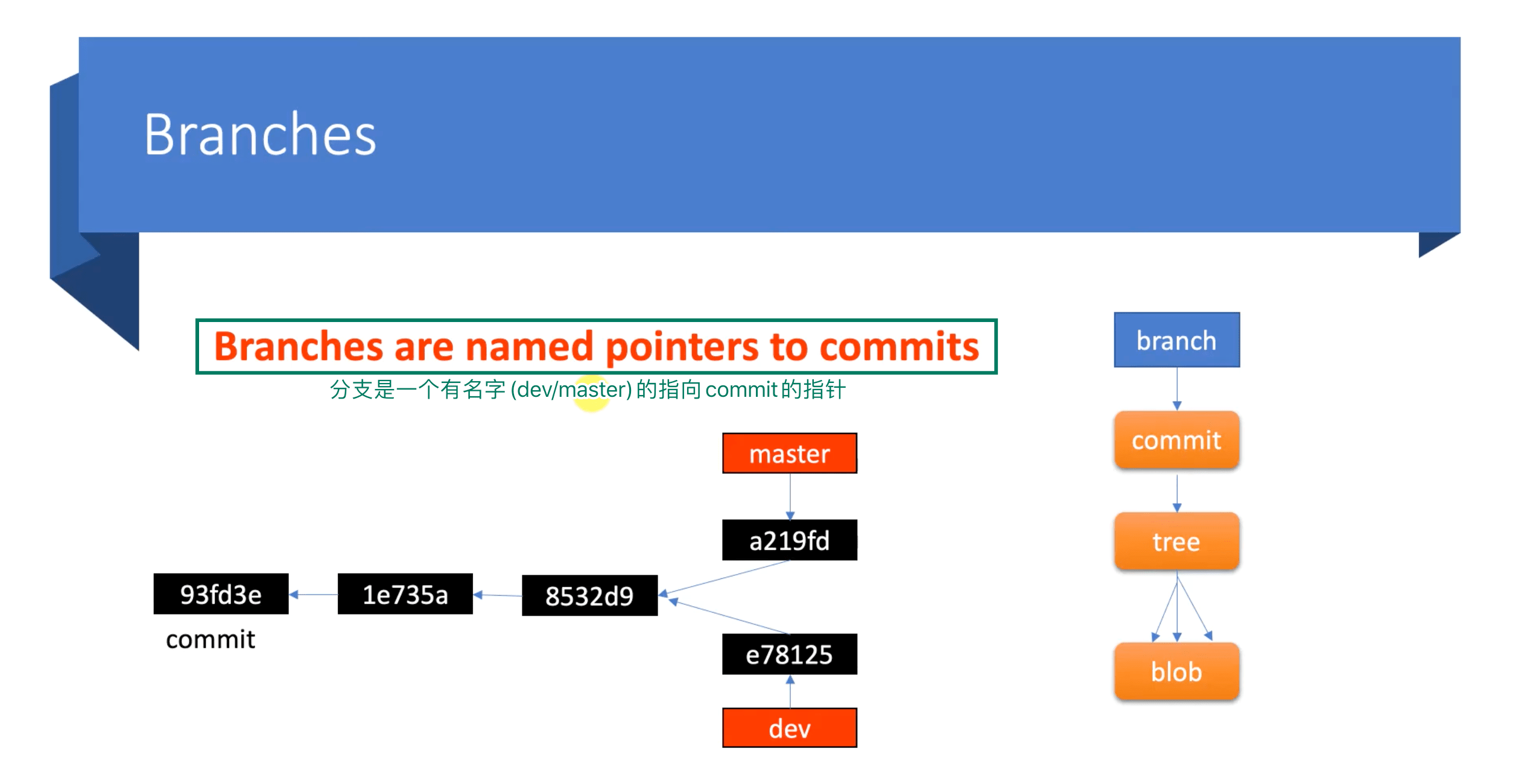
有了上述基础,我们就需要考虑下,分支到底是如何实现和工作的。要实现一个分支,我们最基本需要解决两个问题,第一个就是需要存储每一个分支指向的 commit,第二个问题就是在切换分支的时候帮助我们标识当前分支。
在 git 中,它有一个非常特殊的 HEAD 文件。而 HEAD 文件是一个指针,其有一个特性就是总会指向当前分支的最新的一个 commit 对象。而这个 HEAD 文件正好,解决了我们上面提出的两个问题。
当我们从 master 切换分支到 dev 的时候,HEAD 文件也会随即切换,即指向 dev 这个指针。设计就是这么美丽,不愧是鬼才,好脑袋。

# 左边执行
$ cat .git/HEAD
$ cat .git/refs/heads/master
$ git cat-file -t 1711e01
# 右边执行
$ glo = git log
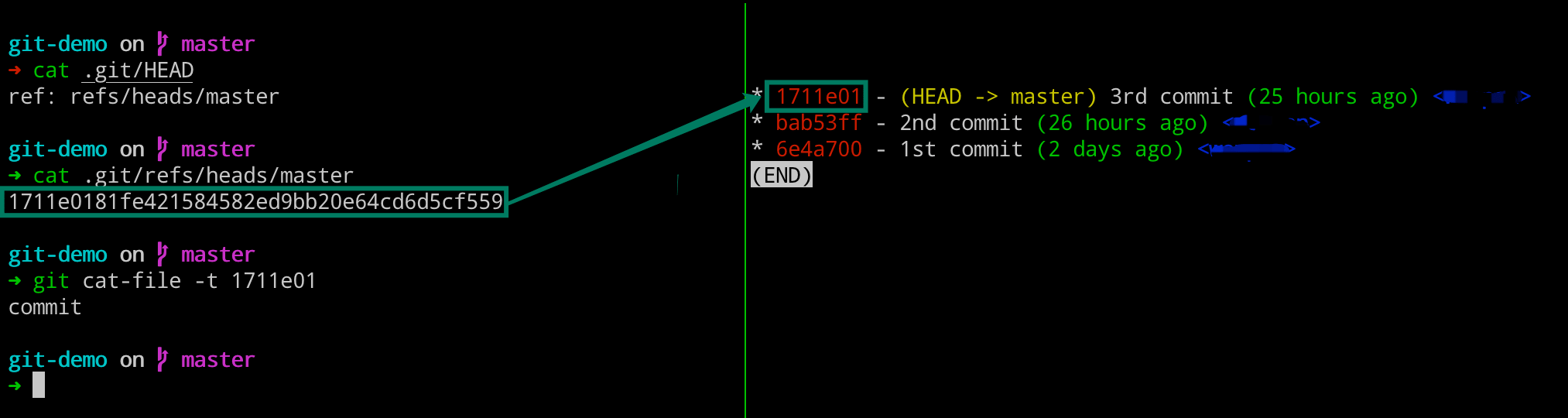
9. 分支操作的背后逻辑
这里我们可以看到分支切换之后,HEAD 指向发生变动了。
# 左边执行
$ git branch
$ git branch dev
$ ll .git/refs/heads
$ cat .git/refs/heads/master
$ cat .git/refs/heads/dev
$ cat .git/HEAD
$ git checkout dev
$ cat .git/HEAD
# 右边执行
$ glo = git log
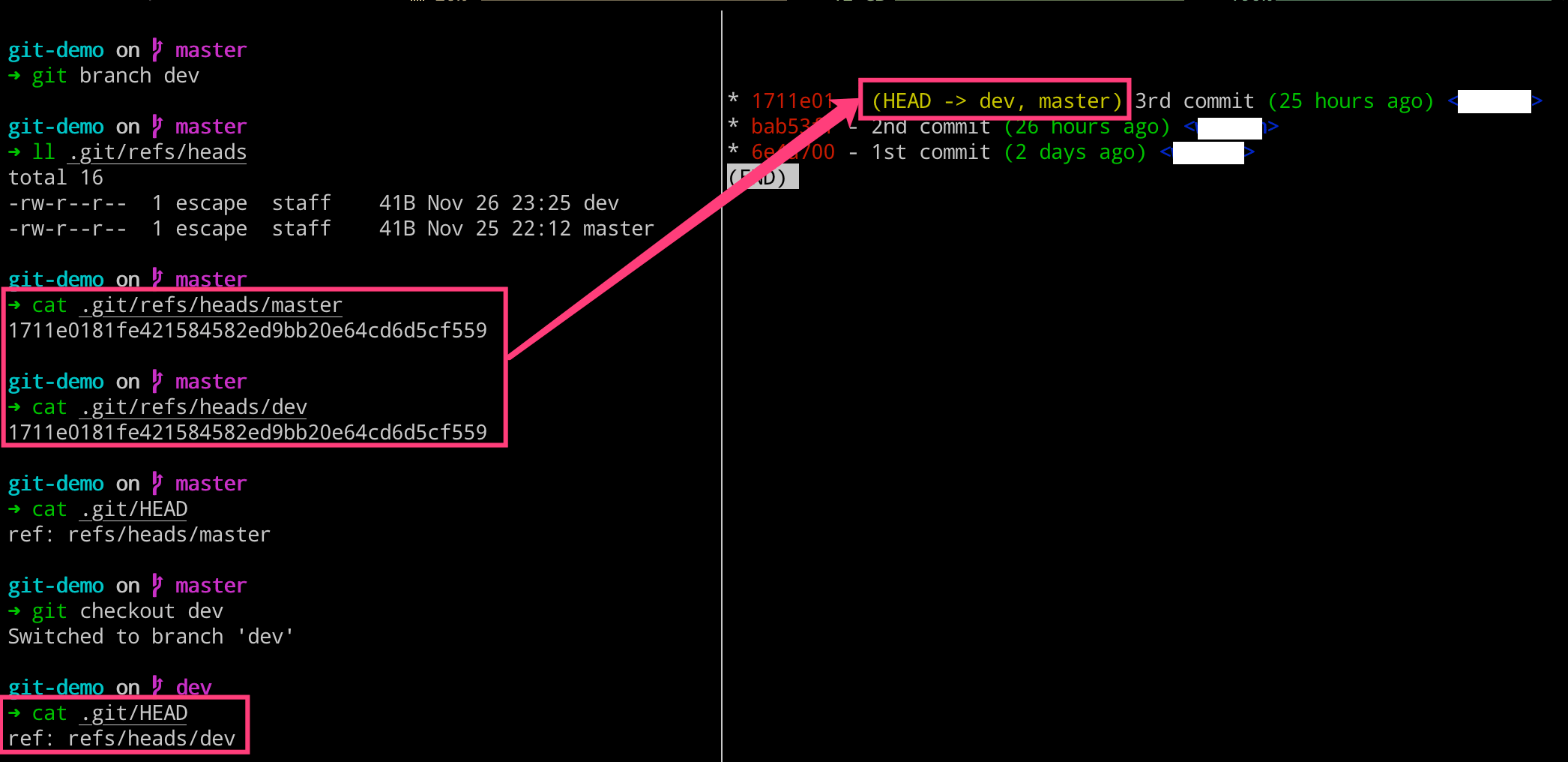
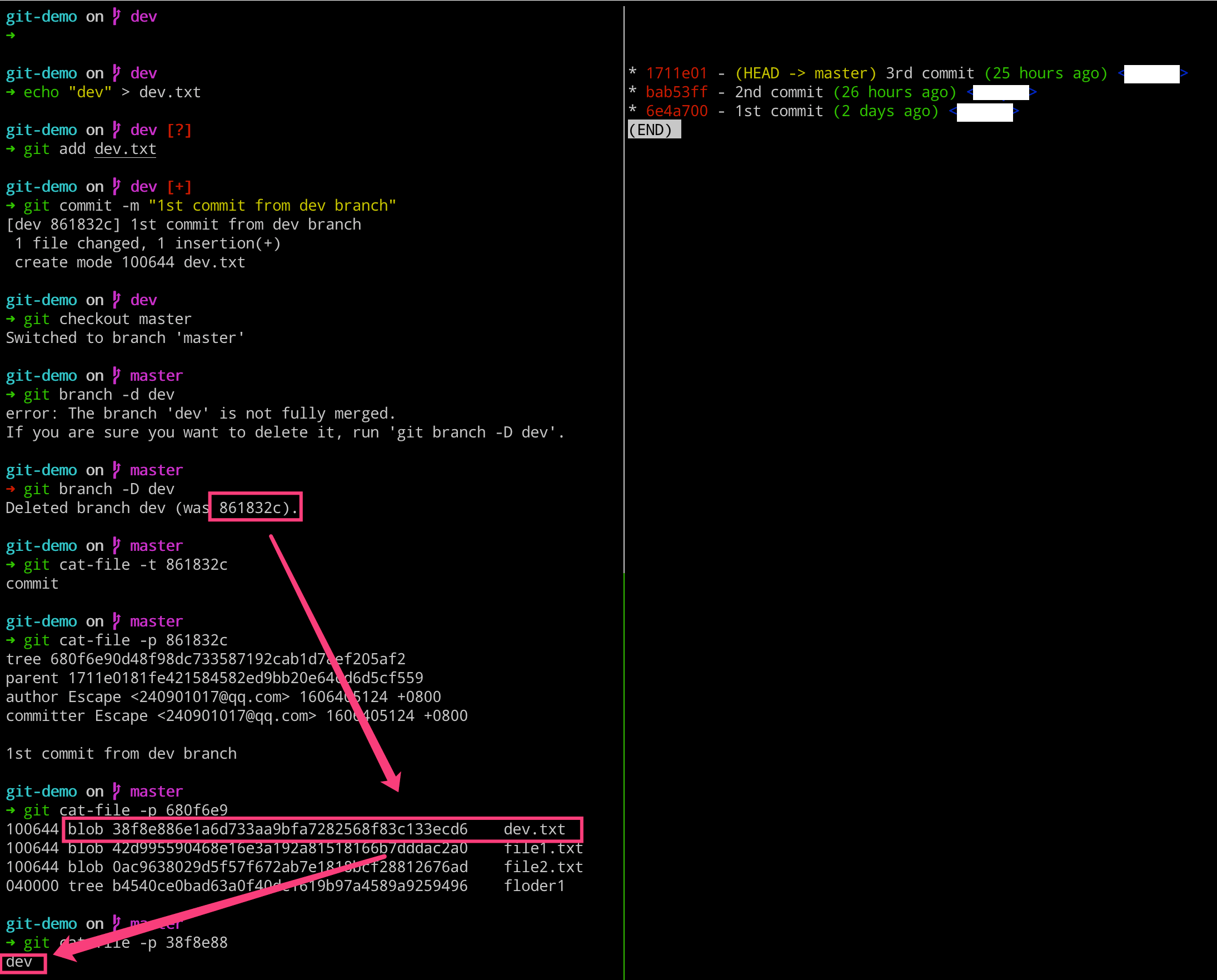
这里需要注意的是,即使我们删除了分支,但是该分支上一些特有的对象并不会被删除的。这些对象其实就是我们俗称的垃圾对象,还有我们多次使用 add 命令所产生的也有垃圾对象,而这些垃圾对象怎么清除和回收呢?后续,我们会涉及到的。
# 左边执行
$ echo "dev" > dev.txt
$ git add dev.txt
$ git commit -m "1st commit from dev branch"
$ git checkout master
$ git branch -d dev
$ git branch -D dev
$ git cat-file -t 861832c
$ git cat-file -p 861832c
$ git cat-file -p 680f6e9
$ git cat-file -p 38f8e88
# 右边执行
$ glo = git log
10. checkout 和 commit 操作
我们执行 checkout 命令的时候,其不光可以切换分支,而且可以切换到指定的 commit 上面,即 HEAD 文件会指向某个 commit 对象。在 Git 里面,将 HEAD 文件没有指向 master 的这个现象称之为 detached HEAD。
这里不管 HEAD 文件指向的是分支名称也好,是 commit 对象也罢,其实本质都是一样的,因为分支名称也是指向某个 commit 对象的。
# 左边执行
$ git checkout 6e4a700
$ git log
# 右边执行
$ glo = git log
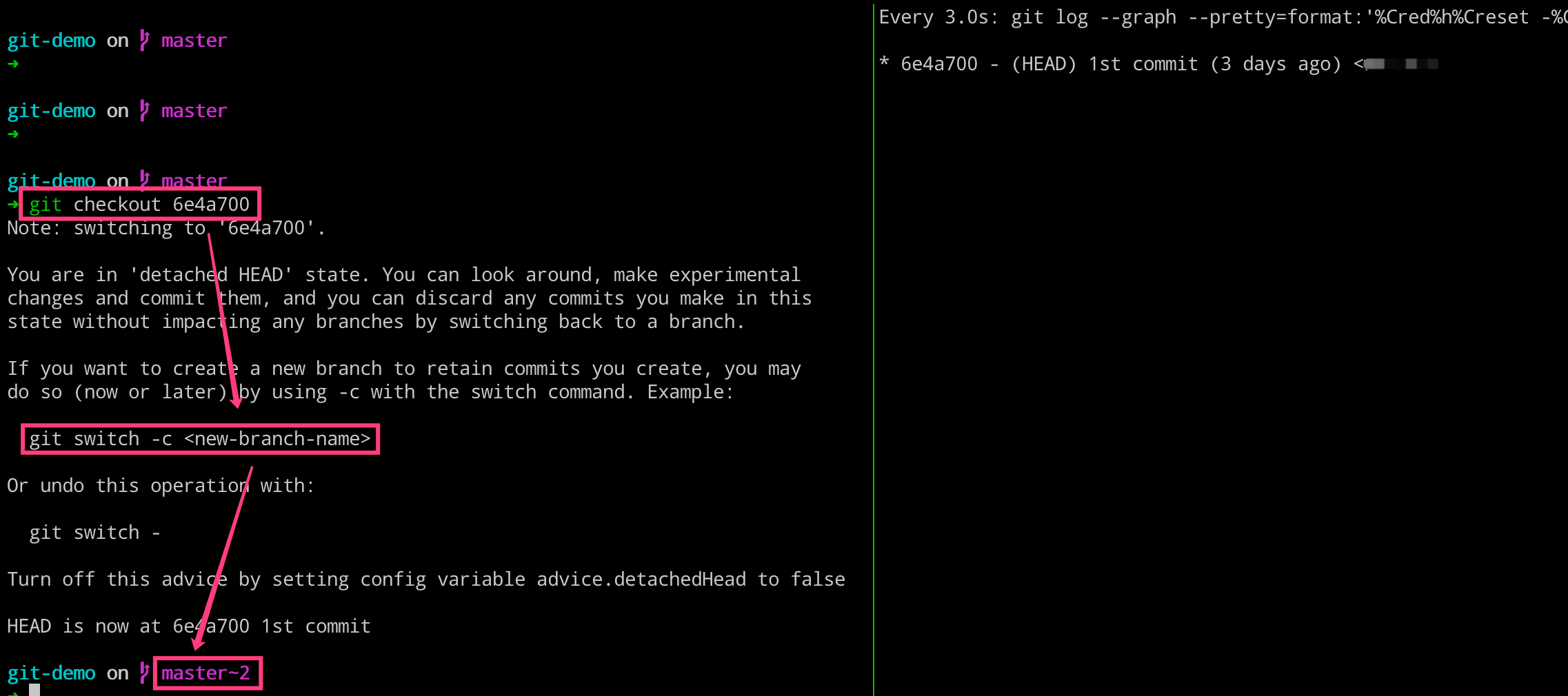
当我们切换到指定的 commit 的时候,如果需要在对应的 commit 上继续修改代码提交的话,可以使用上述图片中提及的 swtich 命令创建新分支,再进行提交。但是,通常我们都不会着玩,都会使用 checkout 命令来创建新分支的。
$ git checkout -b tmp
$ git log
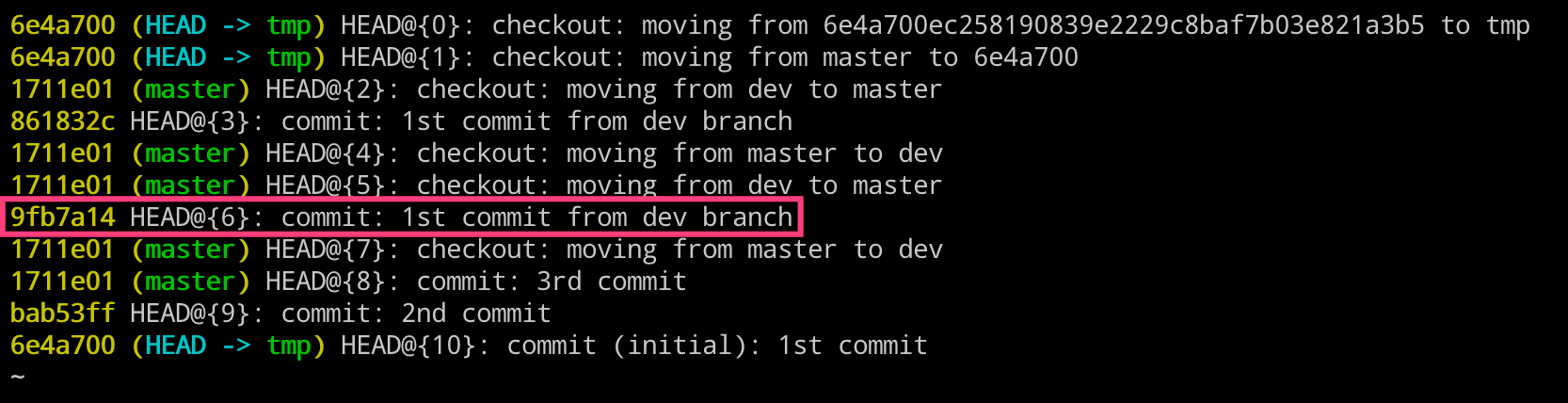
即使可以这样操作,我们也很少使用。还记得我们上一章节创建的 dev 分支吗?我们创建了该分支并有了一个新的提交,但是没有合并到 master 分支就直接删除了。现在再使用 log 命令查看的话,是看不到了。
实际,真的看不到了吗?大家要记住,在 Git 里面任何的操作,比如分支的删除。它只是删除了指向某个特定 commit 的指针引用而已,而那个 commit 本身并不会被删除,即 dev 分支的那个 commit 提交还是在的。
那我们怎么找到这个 commit 呢?找到之后,我们就可以在上面继续工作,或者找到之前的文件数据等。
第一种方法
- [费劲不太好,下下策]
- 在 objects 目录下面,自己一个一个看,然后切换过去。
第二种方法
- [推荐的操作方式]
- 使用 Git 提供的 git reflog 专用命令来查找。
- 该命令的作用就是用于将我们之前的所有操作都记录下来。
# 左边执行
$ git reflog
$ git checkout 9fb7a14
$ git checkout -b dev
# 右边执行
$ glo = git log
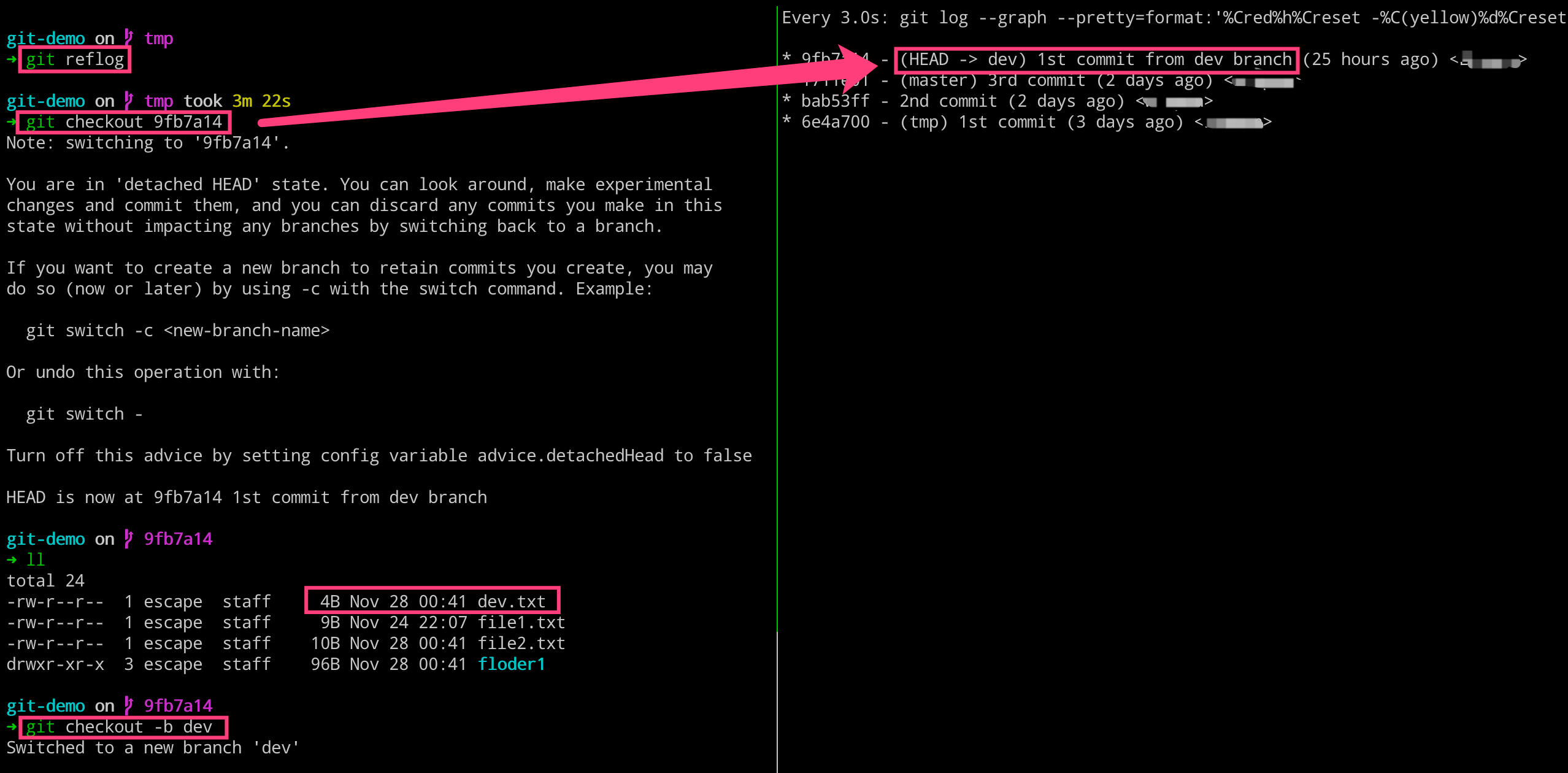
11. 聊聊 diff 的执行逻辑
就在本节中中,我们使用上节的仓库,修改文件内容之后,看看 diff 命令都输出了哪些内容呢?我们这里一起来看看,研究研究!
$ echo "hello" > file1.txt
$ git diff
$ git cat-file -p 42d9955
$ git cat-file -p ce01362
# 下述命令原理也是一样的
$ git diff --cached
$ git diff HEAD
12. Git 如何添加远程仓库
[1] 初始化仓库
$ git init
$ git add README.md
$ git commit -m "first commit"
[2] 关联远程仓库
当我们使用上述命令来关联远程服务器仓库的时候,我们本地 .git 目录也是会发生改变的。通过命令查看 .git/config 文件的话,可以看到配置文件中出现了 [remote] 字段。
# 关联远程仓库
$ git remote add origin git@github.com:escapelife/git-demo.git
➜ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
ignorecase = true
precomposeunicode = true
[remote "origin"]
url = git@github.com:escapelife/git-demo.git
fetch = +refs/heads/*:refs/remotes/origin/*
[3] 推送本地分支
当我们执行如下命令,将本地 master 分支推送到远程 origin 仓库的 master 分支。之后,我们登陆 GitHub 就可以看到推送的文件及目录内容了。
推送分支内容的时候,会列举推送的 objects 数量,并将其内容进行压缩,之后推送到我们远程的 GitHub 仓库,并且创建了一个远程的 master 分支(origin 仓库)。
# 推送本地分支
$ git push -u origin master
推送之后,我们可以发现,本地的 .git 生成了一些文件和目录,它们都是什么呢?如下所示,会新增四个目录和两个文件,皆为远程仓库的信息。当我们通过命令查看 master 这个文件的内容时,会发现其也是一个 commit 对象。此时与我们本地 master 分支所指向的一致。而其用于表示远程仓库的当前版本,用于和本地进行区别和校对的。
➜ tree .git
├── logs
│ ├── HEAD
│ └── refs
│ ├── heads
│ │ ├── dev
│ │ ├── master
│ │ └── tmp
│ └── remotes # 新增目录
│ └── origin # 新增目录
│ └── master # 新增文件
└── refs
├── heads
│ ├── dev
│ ├── master
│ └── tmp
├── remotes # 新增目录
│ └── origin # 新增目录
│ └── master # 新增文件
└── tags
13. 远程仓库存储代码
当我们编写完代码之后,将其提交到对应的远程服务器上面,其存储结构和我们地址是一模一样的。如果我们仔细想想的话,不一样的话才见怪了。
Git 本来就是代码的分发平台,无中心节点,即每个节点都是主节点,所以其存储的目录结构都是一直的。这样,不管哪一个节点的内容发生丢失或缺失的话,我们都可以通过其他节点来找到。而 Git 服务器就是一个可以帮助我们,实时都可以找到的节点,而已。
Git实用技巧记录
如果我们希望能够快速了解或体验一下 Git 的操作的话,我这里推荐搭建前往这个网站进行学习,其不需要我们安装工具,而且我们的每一步操作都可以在右侧实时看到状态,对于我们学习和理解 Git 工作方式和原理非常有帮助的。
https://oschina.gitee.io/learn-git-branching/
1. 常见企业工作流程
主要介绍,企业中常用的 Git 工作流程!
Git Flow
- 主干分支
- 稳定分支
- 开发分支
- 补丁分支
- 修改分支
Github Flow
- 创建分支
- 添加提交
- 提交 PR 请求
- 讨论和评估代码
- 部署检测
- 合并代码
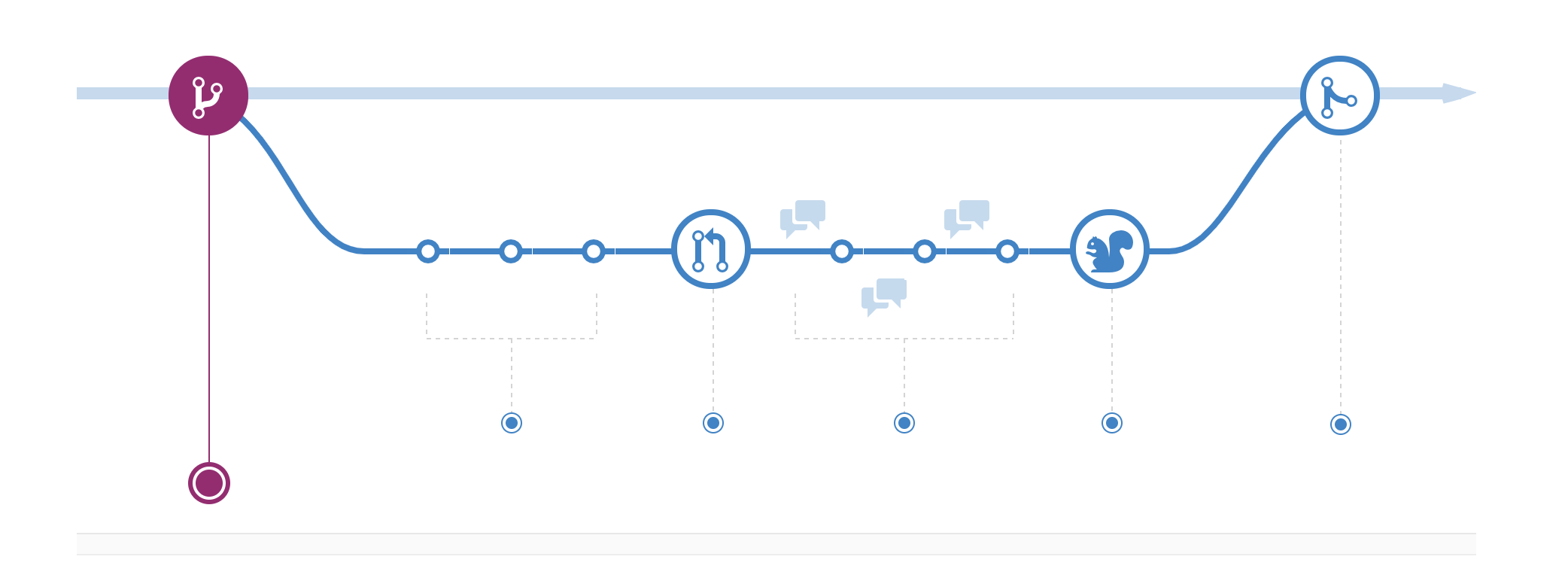
Gitlab Flow
- 带生产分支
- 带环境分支
- 带发布分支
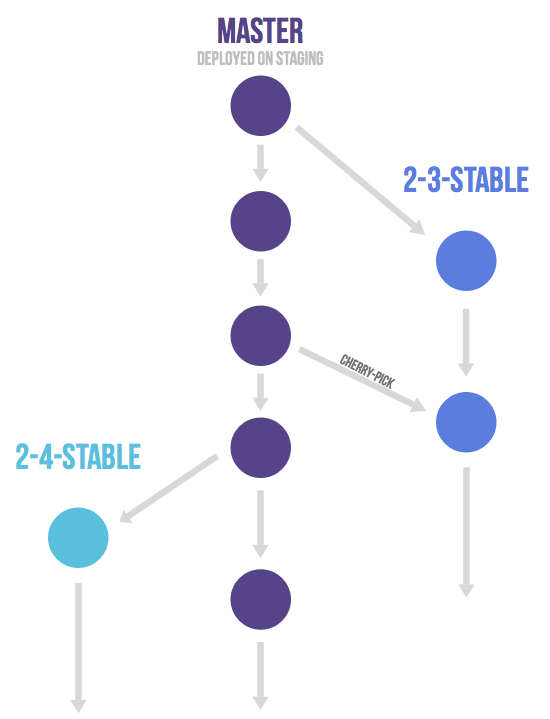
2. 日常使用最佳实践
使用命令行代替图形化界面
使用命令行来操作,简洁且效率高
提交应该尽可能的表述提交修改内容
- 区分 subject 和 body 内容,使用空行隔开
- subject 一般不超过 50 个字符
- body 每一行的长度控制在 72 个字符
- subject 结尾不需要使用句号或者点号结尾
- body 用来详细解释此次提交具体做了什么
使用 .gitignore 文件来排除无用文件
可使用模板文件,然后根据项目实际进行修改
基于分支或 fork 的开发模式
不要直接在主干分支上面进行开发
在新建的分支上进行功能的开发和问题的修复
使用 release 分支和 tag 标记进行版本管理
使用 release 分支发布代码和版本维护(release/1.32)
使用 tag 来标记版本(A-大feature功能.B-小feature功能.C-只修bug)
3. 常用命令汇总整理
日常使用只要记住 6 个命令就可以了。
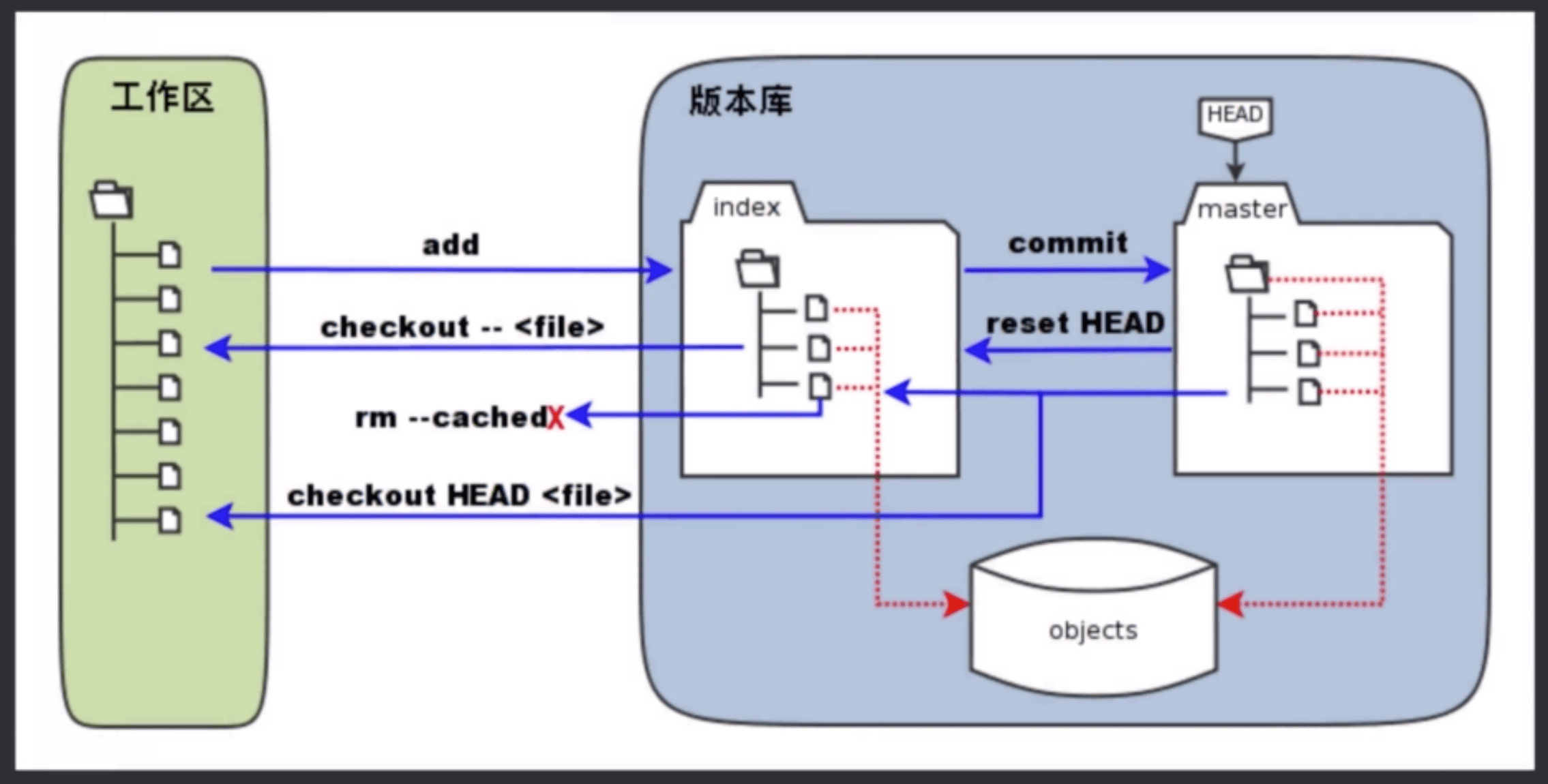
# 工作区 -> 暂存区
$ git add <file/dir>
# 暂存区 -> 本地仓库
$ git commit -m "some info"
# 本地仓库 -> 远程仓库
$ git push origin master # 本地master分支推送到远程origin仓库
# 工作区 <- 暂存区
$ git checkout -- <file> # 暂存区文件内容覆盖工作区文件内容
# 暂存区 <- 本地仓库
$ git reset HEAD <file> # 本地仓库文件内容覆盖暂存区文件内容
# 本地仓库 <- 远程仓库
$ git clone <git_url> # 克隆远程仓库
$ git fetch upstream master # 拉取远程代码到本地但不应用在当前分支
$ git pull upstream master # 拉取远程代码到本地但应用在当前分支
$ git pull --rebase upstream master # 如果平时使用rebase合并代码则加上
# 工作区 <- 本地仓库
$ git reset <commit> # 本地仓库覆盖到工作区(保存回退文件内容修改)
$ git reset --mixed <commit> # 本地仓库覆盖到工作区(保存回退文件内容修改)
$ git reset --soft <commit> # 本地仓库覆盖到工作区(保留修改并加到暂存区)
$ git reset --hard <commit> # 本地仓库覆盖到工作区(不保留修改直接删除掉)
4. 配置实用参数选项
虽然配置比较简单,但是非常有用!
[1] 全局配置
# 用户信息
$ git config --global user.name "your_name"
$ git config --global user.email "your_email"
# 文本编辑器
$ git config --global core.editor "nvim"
# 分页器
$ git config --global core.pager "more"
# 别名
$ git config --global alias.gs "git status"
# 纠错
$ git config --global help.autocorrect 1
[2] 个人配置
# 不加--global参数的话,则为个人配置
$ git config --list
$ git config user.name
$ git config user.name "your_name"
# 如果在项目中设置,则保存在.git/config文件里面
$ cat .git/config
[user]
name = "your_name"
......
5. 合并和变基的选择
到底什么时候使用 merge 操作,什么时候使用 rebase 操作呢?
[1] 使用 merge 操作 - Python 中的 Requests 库在使用
支持使用 merge 的开发者,他们认为仓库的提交历史就是记录实际发生过什么,它是针对于历史的一个文档,本身其实是有价值的,我们不应该随意修改。我们改变历史的话,就相当于使用“谎言”来掩盖实际发生过的事情,而这些痕迹是应该被保留的。可能,这样并不是很好。
# 3rd的两个分支的commit修改相同内容
* 62a322d - (HEAD->master) Merge branch 'hotfix3' into master
|\
| * 6fa8f4a - (hotfix3) 3rd commit in hotfix3
* | 548d681 - 3rd commit in master
|/
* 6ba4a08 - 2nd commit
* 22afcc1 - 1st commit
[2] 使用 rebase 操作 - Python 中的 Django 库在使用
支持使用 rebase 的开发者,他们认为提交历史是项目过程中发生过的事情,需要项目的主干非常的干净。而使用 merge 操作会生成一个 merge 的 commit 对象,让提交历史多了一些非常多余的内容。
当我们后期,使用 log 命令参看提交历史的话,会发现主干的提交历史非常的尴尬。比如,同样的修改内容重复提交了两次,这显然是分支合并导致的问题。
# 3rd的两个分支的commit修改相同内容
* 697167e - (HEAD -> master, hotfix) 3rd commit
* 6ba4a08 - 2nd commit (2 minutes ago)
* 22afcc1 - 1st commit (3 minutes ago)
[3] 两者的使用原则
总的原则就是,只对尚未推送或分享给其他人的本地修改执行变基操作清理历史,从不对已经推送到仓库的提交记录执行变基操作,这样,你才可能享受到两种方式带来的便利。
6. 更新仓库提交历史
Git 提供了一些工具,可以帮助我们完善版本库中的提交内容,比如:
[1] 合并多个 commit 提交记录
日常开发中,我们为了完成一个功能或者特性,提交很多个 commit 记录。但是在最后,提交 PR 之前,一般情况下,我们是应该整理下这些提交记录的。有些 commit 需要合并起来,或者需要将其删除掉,等等。
# 调整最近五次的提交记录
$ git rebase -i HEAD~5
$ git rebase -i 5af4zd35 # 往前第六次的commit值
reword c2aeb6e 3rd commit
squash 25a3122 4th commit
pick 5d36f1d 5th commit
fixup bd5d32f 6th commit
drop 581e96d 7th commit
# 查看提交历史记录
$ git log
* ce813eb - (HEAD -> master) 5th commit
* aa2f043 - 3rd commit -> modified
* 6c5418f - 2nd commit
* c8f7dea - 1st commit
| 编号 | 选项列表 | 对应含义解释 |
|---|---|---|
| 1 | p/pick | 使用这个 commit 记录 |
| 2 | r/reword | 使用这个 commit 记录;并且修改提交信息 |
| 3 | e/edit | 使用这个 commit 记录;rebase 时会暂停允许你修改这个 commit |
| 4 | s/squash | 使用这个 commit 记录;会将当前 commit 与上一个 commit 合并 |
| 5 | f/fixup | 与 squash 选项相同;但不会保存当前 commit 的提交信息 |
| 6 | x/exec | 执行其他 shell 命令 |
| 7 | d/drop | 移除这个 commit 记录 |
[2] 删除意外调试的测试代码
有时候提交之后,我们才发现提交的历史记录中存在这一些问题,而这个时候我们又不想新生成一个 commit 记录,且达到一个修改的目录。即,修改之前的 commit 提交记录。
# 不使用分页器
$ git --no-pager log --oneline -1
d5e96d9 (HEAD -> master) say file
# 改变提交信息并加入暂存区
$ echo "hello" > say.txt
$ git add -u
# 改变当前最新一次提交记录
$ git commit --amend
# 改变且息不改变提交信
$ git commit --amend --no-edit
# 改变当前最新一次提交记录并修改信息
$ git commit --amend -m "some_info"
# 不使用分页器
$ git --no-pager log --oneline -1
9e1e0eb (HEAD -> master) say file
[3] 取消多个 commit 中的部分提交
我们开发了一个功能,而在上线的时候,产品经理说这个功能的部分特性已经不需要了,即相关特性的提交记录和内容就可以忽略/删除掉了。
# 回滚操作(可多次执行回滚操作)
# 彻底上次提交记录;也可是PR的提交记录
# 默认会生成一个类型为reverts的新commit对象
$ git revert 3zj5sldl
[4] 合并某些特定的 commit 提交
我们不希望合并整个分支,而是需要合并该分支的某些提交记录就可以了。
# 摘樱桃
$ git cherry-pick -x z562e23d
7. 使用引用日志记录
如何找回我们丢失的内容和记录?
我们之前说过,使用下面命令回退内容、强制推送代码、删除本地分支,都是非常危险的操作,因为重置之后我们就没有办法在找到之前的修改内容了。
# 回退
$ git reset --hard <commit>
# 推送
$ git push origin master -f
# 分支
$ git branch -D <branch_name>
其实 Git 给我们留了一个后门,就是使用 relflog 命令来找回之前的内容,只不过是相对来说麻烦一些。而原理也很简答,就是在我们使用 Git 命令操作仓库的时候,Git 偷偷地帮助我们把所有的操作记录了下来。
# 查看日志记录
$ git --no-pager log --oneline -1
4bc8703 (HEAD -> master) hhhh
# 回退到上次提交
$ git reset --hard HEAD~1
# 查看引用日志记录
$ git reflog
6a89f1b (HEAD -> master) HEAD@{0}: reset: moving to HEAD~1
4bc8703 HEAD@{1}: commit (amend): hhhh
# 找回内容
$ git cherry-pick 4bc8703
8. 批量修改历史提交
批量修改历史提交虽然不常用,但是理解的话可以省下很多时间!
之前我们学习到的命令都是针对于一个或者多个 commit 提交信息进行修改的,如果我们需要全局修改历史提交呢?当然,Git 中也是支持全局修改历史提交的,比如全局修改邮箱地址,或者将一个文件从全局历史中删除或修改。
- 开源项目中使用了公司邮箱进行提交了
- 提交文件中包含隐私性的密码相关信息
- 提交时将大文件提交到了仓库代码中了
这里我们可以使用 filter-brach 的方式进行修改,但是建议在使用之前,新建一个分支,在上面进行测试没有问题之后,再在主干上操作,防止出现问题,背个大锅在身上。
# 创建分支
$ git branch -b testing
# 修改邮箱地址
$ git filter-branch --commit-filter '
if [ "$GIT_AUTHOR_EMAIL" == "escape@escapelife.site" ]; then
GIT_AUTHOR_NAME="escape";
GIT_AUTHOR_EMAIL="escape@gmail.com";
git commit-tree "$@"
else
git commit-tree "$@"
fi' HEAD
9. 灵活使用钩子函数
主要介绍.git/hooks 目录下面的示例钩子函数!
- 在 Git 里面有两类,分别对应客户端和服务端钩子函数。客户端的钩子函数,是在执行提交和合并之类的操作时调用的。而服务端钩子函数,就是当服务端收到代码提交之后,可以出发代码检查和持续集成的步骤。作为开发者我们并不会搭建 Git 服务器,所以基本不会涉及。
- 下面就是 Git 自带的钩子脚本,但是自带的都以 .sample 作为后缀,表示并没有启用,表示为一个示例。如果需要启用的话,将 .sample 作为后缀删除掉,即可。而其钩子脚本的对应内容,都是使用 Shell 语法进行编写的。
➜ ll .git/hooks
total 112
-rwxr-xr-x applypatch-msg.sample
-rwxr-xr-x commit-msg.sample
-rwxr-xr-x fsmonitor-watchman.sample
-rwxr-xr-x post-update.sample
-rwxr-xr-x pre-applypatch.sample
-rwxr-xr-x pre-commit.sample
-rwxr-xr-x pre-merge-commit.sample
-rwxr-xr-x pre-push.sample # 不会推送包含WIP的commit提交
-rwxr-xr-x pre-rebase.sample
-rwxr-xr-x pre-receive.sample
-rwxr-xr-x prepare-commit-msg.sample
-rwxr-xr-x update.sample
- 其实,钩子脚本使用任何语言编写都是可以的,只要你让程序返回对应的退出码就可以了。
- 正常的代码合入流程就是,我们本地修改之后,提一个 PR 请求并通过 Github 的 CI 检查,接下来进行代码评审,最后被合并入主干。但是,好的一个习惯就是,在代码提交之前就应该保证代码不会出现语法错误等基础问题,比如通过 flake8 和 PEP8 标准等。
- 这个时候我们就可以使用 pre-commit 这个 Github 的开源项目了,其本质就是给项目添加钩子函数的一个脚本,可以保证我们在提交代码或者推送代码之前,先检查代码的质量。
- 而 pre-commit-hooks 这个项目里面包含的就是,现在所支持的钩子脚本,即开箱即用的钩子脚本集合。而其钩子脚本的对应内容,都是使用 Python 语法进行编写的。
# 安装方式
$ pip install pre-commit
# 指定hook类型(即在哪里检查)
$ pre-commit install -f --hook-type pre-push
# 配置需要执行的检查
$ cat .pre-commit-config.yaml
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v2.9.2
hooks:
- id: trailing-whitespace
- id: flake8
# 执行push操作时检查
$ git push origin master
10. 快速克隆大型项目
在大项目中工作中,拉取代码非常占时间!
- 我们如果想为 Linux 或 Python 这样的大型项目贡献提交的时候,首先遇到的问题就是,如果快速的 clone 该项目到本地。因为改项目提交历史超多且仓库巨大,加了国内网络的问题,可能等项目完全拉下来的时候,我们的热情都消减下去了。
- 好在 Git 也帮我们想到了这样的问题,我们可以使用 --depth 参数值拉取远程仓库上面最新一次的提交历史,并不包含项目历史记录,即 .git/objects/ 目录下的对象只是本地的,并不包含之前的多次修改产生的对象。
# 克隆不包含之前历史
$ git clone http://xxx.xx.xxx/xxx --depth=1
- 但是,有时间我们可能会需要 clone 仓库中的某个 tag 版本对应下的内容。如果我们直接使用 clone 命令是无法做到的,需要执行如下操作,即可完美解决。
# 克隆特定版本代码
$ git init xxx-15-0-1
$ git remote add origin http://xxx.xx.xxx/xxx
$ git -c protocol.version=2 fetch origin 15.0.1 --depth=1
$ git checkout FETCH_HEAD
- 上面的效果已经基本可以满足我们日常使用需求了,但是不幸的是,你现在接受了一个机器学习的项目,里面包含了大量的 lfs 文件,现在 clone 又会变得非常慢。可以使用如下操作来避免,Git 工具主动拉去 lfs 文件,来达到目录。
# 克隆不包含LFS数据
$ GIT_LFS_SKIP_SMUDGE=1 git clone http://xxx.xx.xxx/xxx
11. 如何处理工作中断
如果在多路运转的时候,还能够高效的进行开发!
- 比如,我们现在正在一个分支为项目添加一个小的功能,此时,产品经理找到你说是线上环境现在有一个 bug 需要让你来修复下。但是,此时我们添加的小功能并没有完成。
- 如果此时,我们直接切换到主干分支的话,会将之前分支没有来得及提交的内容全部都带到了主干分支上来,这是我们不想看到的情况。此时,我们需要保存上个分支的工作状态,在我们修改完成线上 bug 之后,再继续工作。
- 好在 Git 也帮我们想到了这样的问题,我们可以使用 stash 子命令帮助我们将当前工作区、暂存区当中的修改都保存到堆栈之中。等到需要处理的时候,再弹出堆栈中的内容,我们再次进行开发。
➜ git stash -h
usage: git stash list [<options>]
or: git stash show [<options>] [<stash>]
or: git stash drop [-q|--quiet] [<stash>]
or: git stash ( pop | apply ) [--index] [-q|--quiet] [<stash>]
or: git stash branch <branchname> [<stash>]
or: git stash clear
or: git stash [push [-p|--patch] [-k|--[no-]keep-index] [-q|--quiet]
[-u|--include-untracked] [-a|--all] [-m|--message <message>]
[--pathspec-from-file=<file> [--pathspec-file-nul]]
[--] [<pathspec>...]]
or: git stash save [-p|--patch] [-k|--[no-]keep-index] [-q|--quiet]
[-u|--include-untracked] [-a|--all] [<message>]
# 存储当前的修改但不用提交commit
$ git stash
# 保存当前状态包括untracked的文件
$ git stash -u
# 展示所有stashes信息
$ git stash list
# 回到某个stash状态
$ git stash apply <stash@{n}>
# 删除储藏区
$ git stash drop <stash@{n}>
# 回到最后一个stash的状态并删除这个stash信息
$ git stash pop
# 删除所有的stash信息
$ git stash clear
# 从stash中拿出某个文件的修改
$ git checkout <stash@{n}> -- <file-path>
- 其实比较保险的做法就是,将当前的所有修改进行 push 并保存到远程仓库里面。这样的好处在于,可以远端备份我们的修改,不会害怕本地文件丢失等问题。等到我们需要继续开发的时候,拉下对应内容,再想办法进行补救,比如使用 --amend 或者 reset 命令。
# 将工作区和暂存区覆盖最近一次提交
$ git commit --amend
$ git commit --amend -m "some_info"
# 回退到指定版本并记录修改内容(--mixed)
# 本地仓库覆盖到工作区(保存回退文件内容修改)
$ git reset a87f328
$ git reset HEAD~
$ git reset HEAD~2
$ git reset <tag>~2
$ git reset --mixed <commit/reference>
# 本地仓库覆盖到工作区(不保留修改直接删除掉)
$ git reset --soft <commit/reference>
# 本地仓库覆盖到工作区(保留修改并加到暂存区)
$ git reset --hard <commit/reference>
Git 使用实例
git
git status
git config --list
# 创建项目
git init
git config --show-origin
git config --global user.name "***"
git config --global user.email "*****"
git config --list
git add .
git commit "创建项目"
git status
git commit -m "创建项目"
git status
# git config –list 命令就可以打印出所有目前生效的配置项.
# 带上--show-origin参数, 在每行配置项上同步打印出该配置项来源的配置文件路径
git config --list --show-origin
file:/root/.gitconfig user.name=***
file:/root/.gitconfig user.email=***
file:.git/config core.repositoryformatversion=0
file:.git/config core.filemode=true
file:.git/config core.bare=false
file:.git/config core.logallrefupdates=true
file:.git/config remote.origin.url=git@***/ceshi.git
file:.git/config remote.origin.fetch=+refs/heads/*:refs/remotes/origin/*
file:.git/config branch.master.remote=origin
file:.git/config branch.master.merge=refs/heads/master
file:.git/config branch.dev.remote=origin
file:.git/config branch.dev.merge=refs/heads/dev
# 如果要用 ssh 推送,就要用 git@,不能用 https
# git remote add origin https://***/ceshi.git
git remote set-url origin git@***/ceshi.git
git push --set-upstream origin master
git checkout -b dev
# 查看分支
git branch
git push origin
git push origin --set-upstream origin dev
git push --set-upstream origin dev
git add .
git commit -m "测试分支"
git push --set-upstream origin dev
git checkout master
git branch
# 合并分支
git merge dev
git status
git push --set-upstream origin dev
git push --set-upstream origin
其他命令
# 更新远程分支列表
git remote update origin --prune
# 查看所有分支
git branch -a
# 删除远程分支Chapater6
git push origin --delete Chapater6
# 删除本地分支 Chapater6
git branch -d Chapater6
Git使用的奇技
1. Git 版本对比相关操作
# [1] 输出工作区和暂存区的不同。
git diff
# [2] 展示暂存区和最近版本的不同
git diff --cached
# [3] 展示暂存区、工作区和最近版本的不同
git diff HEAD
# [4] 展示本地仓库中任意两个 commit 之间的文件变动
git diff <commit-id> <commit-id>
2. Git 分支管理相关操作
# [1] 展示本地分支关联远程仓库
git branch -vv
# [2] 列出所有远程分支
git branch -r
# [3] 列出本地和远程分支
git branch -a
# [4] 查看远程分支和本地分支的对应关系
git remote show origin
# [5] 删除本地分支
# 创建并切换到本地分支
git checkout -b <branch-name>
# 删除本地分支
git branch -d <local-branchname>
# 重命名本地分支
git branch -m <new-branch-name>
# 快速切换到上一个分支
git checkout -
# 跨分支提交
git checkout <branch-name> && git cherry-pick <commit-id>
# [6] 删除远程分支
git push origin --delete <remote-branchname>
# [7] 远程删除了分支本地也想删除
git remote prune origin
# [8] 关联远程分支
# 关联之后 git branch -vv 就可以展示关联的远程分支名了
# 同时推送到远程仓库直接 git push 命令且不需要指定远程仓库了
git branch -u origin/mybranch
3. Git 文件处理相关操作
# [1] 展示所有 tracked 的文件
git ls-files -t
# [2] 展示所有 untracked 的文件
git ls-files --others
# [3] 展示所有忽略的文件
git status --ignored
git ls-files --others -i --exclude-standard
# [4] 强制删除 untracked 的文件
# 使用clean命令后,删除的文件无法找回
# 不会影响tracked的文件的改动,只会删除untracked的文件
# 如果不指定文件文件名,则清空所有工作的untracked文件
git clean <file-name> -f
# [5] 强制删除 untracked 的目录
# 如果不指定目录名称,则清空所有工作的untracked目录
git clean <directory-name> -df
# [6] 清除 gitignore 文件中记录的文件
git clean -X -f
# [7] 恢复删除的文件
# 得到deleting_commit信息
git rev-list -n 1 HEAD -- <file_path>
# 回到删除文件deleting_commit之前的状态
git checkout <deleting_commit>^ -- <file_path>
4. Git 远程仓库相关操作
# [1] 列出所有远程仓库
git remote
# [2] 修改远程仓库的 url 地址
git remote set-url origin <URL>
# [3] 增加远程仓库地址
git remote add origin <remote-url>
5. Git 存储状态相关操作
# [1] 存储当前的修改但不用提交 commit
git stash
# [2] 保存当前状态包括 untracked 的文件
git stash -u
# [3] 展示所有 stashes 信息
git stash list
# [4] 回到某个 stash 状态
git stash apply <stash@{n}>
# [5] 回到最后一个 stash 的状态并删除这个 stash 信息
git stash pop
# [6] 删除所有的 stash 信息
git stash clear
# [7] 从 stash 中拿出某个文件的修改
git checkout <stash@{n}> -- <file-path>
6. Git 配置代码相关操作
# [1] 配置 ssh 代理
# 直接使用shadowsocks提供的socks5代理端口
$ cat ~/.ssh/config
Host gitlab.com
ProxyCommand nc -X 5 -x 127.0.0.1:1080 %h %p
Host github.com
ProxyCommand nc -X 5 -x 127.0.0.1:1080 %h %p
# [2] 配置 http 和 socks 代理
# 适用于 privoxy 将 socks 协议转为 http 协议的 http 端口
git config --global socks.proxy '127.0.0.1:1080'
git config --global http.proxy 'http://127.0.0.1:8001'
git config --global https.proxy 'http://127.0.0.1:8001'
7. Git 其他高级相关操作
# [1] 把某一个分支到导出成一个文件
git bundle create <file> <branch-name>
# [2] 把某一个文件导入成一个分支
# 新建一个分支,分支内容就是上面 git bundle create 命令导出的内容
git clone repo.bundle <repo-dir> -b <branch-name>
# [3] 修改上一个 commit 的描述
# 如果暂存区有改动同时也会将暂存区的改动提交到上一个commit中去
git commit --amend
# [4] 查看某段代码是谁写的
git blame <file-name>
# [5] 回到某个 commit 状态并删除后面的 commit 提交
# 和revert命令不同,reset 命令会抹去某个commit_id之后的所有commit提交
# 默认就是-mixed参数
git reset <commit-id>
# 回退至上个版本将重置HEAD到另外一个commit
# 并且重置暂存区以便和HEAD相匹配,但是也到此为止,工作区不会被更改
git reset -- mixed HEAD^
# 回退至三个版本之前,只回退了commit的信息,暂存区和工作区与回退之前保持一致
# 如果还要提交,直接commit即可
git reset -- soft HEAD~3
# 彻底回退到指定commit-id的状态,暂存区和工作区也会变为指定commit-id版本的内容
git reset -- hard <commit-id>
# [6] 回到远程仓库的状态
# 抛弃本地所有的修改,回到远程仓库的状态
git fetch --all && git reset --hard origin/master
# [7] 重设第一个 commit 信息
# 也就是把所有的改动都重新放回工作区并清空所有的commit信息,这样就可以重新提交第一个commit了
git update-ref -d HEAD
# [8] 查找已经删除的文件提交
# 模糊查找
git log --all --full-history -- "**/thefile.*"
# 精确查找
git log --all --full-history -- <path-to-file>
git log --diff-filter=D --summary | grep <file_name> | awk '{print $4; exit}' | xargs git log --all --
# 查看所有删除文件
git log --diff-filter=D --summary | grep delete
# 查看产出文件是谁提交的
git log --diff-filter=D --summary | grep -C 10 <file_name>
8. Git 给 Github 配置 RSS
/* Repo releases */
https://github.com/:owner/:repo/releases.atom
/* Repo commits */
https://github.com/:owner/:repo/commits.atom
/* Private feed (You can find Subscribe to your news feed in dashboard page after login) */
https://github.com/:user.private.atom?token=:secret
/* Repo tags */
https://github.com/:user/:repo/tags.atom
/* User activity */
https://github.com/:user.atom
Git多个用户ID适配
Git 是一个分布式版本控制软件,最初由 林纳斯·托瓦兹 创作,于 2005 年以 GPL 协议发布。最初目的是为更好地管理 Linux 内核开发而设计。很多著名的软件都使用 Git 进行版本控制,其中包括 Linux 内核、X.Org 服务器和 OLPC 内核等项目的开发流程。
1. 背景介绍
Git 的 git config 命令可以让你为 Git 设置用户名、邮箱等全局选项和配置。其有很多选项和配置,其中一个就是 includeIf 选项,它能够帮助我们在拥有多个 Git 用户的时候可以灵活的切换到对应的用户上,且使用起来非常方便。
比如说,我们在工作时间需要处理公司的工作,不管是 GitHub 也好,还是 GitLab 也罢。同时,我们又在业余的时间为开源项目提交代码做贡献。在这种情况下,我们肯定不想在这两种不同的情况下使用一个共同的配置。我们肯定是希望,在不同的情况下使用不同的配置,尤其是当我们只有一台计算的话。
我的情况就是上述表述的那样,所以我需要在 Git 配置中保留两种不同的邮件 ID。这样一来,上班时间使用公司邮箱进行代码的提交,而在下班之后可以使用 GitHub 的邮箱进行自己茶余饭后的娱乐。而应该如何配置呢?这就是一个非常总要的问题了!
2. 选项使用
在 2017 年,Git 新发布的版本 2.13.0 包含了一个新的功能 includeIf 配置,可以把匹配的路径使用对应的配置用户名和邮箱。
其中 includeIf.condition.path 变量,是 include 配置指令的一部分,其允许我们通过条件过滤的方式设置属于我们自己的自定义配置。includeIf 指令支持三个子关键字,分别是:gitdir、gitdir/I 和 onbranch。
[1] gitdir
关键字 gitdir:后面的内容用于全局匹配(golb模式),如果 Git 目录与模式匹配,则满足 include 条件。Git 仓库的配置,可以由程序自己发现或者通过 GIT_DIR 环境变量来配置。该模式下,可以使用标准的通配符之外,还附加了两个额外的通配符,分别是 **/ 和 /** 两种,它们用于匹配多个路径。
如果该模式以 ~/ 开头的话,~ 将被环境变量 HOME 的内容所替代。如果模式以 ./ 开头的话,它将被包含当前配置文件的目录替换。
如果该模式不以 ~/ 开头的话,则 ./、/ 和 **/ 将自动预置。例如,我们将匹配模式从 foo/bar 变为 **/foo/bar 的话,将匹配 /any/path/to/foo/bar。如果模式以 / 结束的话,** 将被自动被添加到其尾部。例如,我们设置模式默认为 foo/ 的话,将变成 foo/** 这样。换句话说,它递归地匹配 foo 和里面的所有内容。
[2] gitdir/I
关键字 gitdir/I:这与 gitdir 相同,只是匹配是大小写不敏感的,例如在不区分大小写的文件系统上。
[3] onbranch
关键字 onbranch:后面的数据被认为是一个模式 ! 该模式下,可以使用标准的通配符之外,还附加了两个额外的通配符,分别是 **/ 和 /** 两种,它们用于匹配多个路径。如果在工作树中,当前签出的分支的名称与模式匹配,则满足 include 条件。
如果模式以 / 结束的话,** 将被自动添加。例如,我们设置模式默认为 foo/ 的话,将变成 foo/** 这样,它匹配所有以 foo/ 开头的分支。如果您的分支是按层次结构组织的,并且您希望将配置应用于该层次结构中的所有分支,那么这是非常有用的。
[core]
filemode = false
[diff]
external = /usr/local/bin/diff-wrapper
renames = true
[branch "devel"]
remote = origin
merge = refs/heads/devel
; include if $GIT_DIR is /path/to/foo/.git
[includeIf "gitdir:/path/to/foo/.git"]
path = /path/to/foo.inc
; include for all repositories inside /path/to/group
[includeIf "gitdir:/path/to/group/"]
path = /path/to/foo.inc
; include for all repositories inside $HOME/to/group
[includeIf "gitdir:~/to/group/"]
path = /path/to/foo.inc
; relative paths are always relative to the including
; file (if the condition is true); their location is not
; affected by the condition
[includeIf "gitdir:/path/to/group/"]
path = foo.inc
; include only if we are in a worktree where foo-branch is
; currently checked out
[includeIf "onbranch:foo-branch"]
path = foo.inc
3. 内容配置
[1] 全局配置文件
~/.gitconfig 里面原有的 user 部分需要删除掉
~/.gitconfig 里面的 includeIf 后面的 path 需要以 / 结尾
个人项目目录和公司项目目录需要是非包含关系,即非父子目录等
# 配置文件地址
# 全局通用配置文件
$HOME/.gitconfig
# 一切献给了开源
[includeIf "gitdir:~/github_dir/"]
# 个人项目配置文件
path = ~/.git/.gitconfig-github
# 一切献给了工作
[includeIf "gitdir:~/working_dir/"]
# 公司项目配置文件
path = ~/.git/.gitconfig-working
[2] 个人项目配置文件
$ cat ~/.git/.gitconfig-github
[user]
name = yourname-self
email = yourname-self@gmail.com
[3] 公司项目配置文件
$ cat ~/.git/.gitconfig-working
[user]
name = yourname-self
email = yourname-self@gmail.com
解决.git目录过大问题
Git 是一个分布式版本控制软件,最初由 林纳斯·托瓦兹 创作,于 2005 年发布。最初目的是为更好地管理 Linux 内核开发。Git 在本地磁盘上就保存着所有有关当前项目的历史更新,处理速度快。Git 中的绝大多数操作都只需要访问本地文件和资源,不用实时联网。
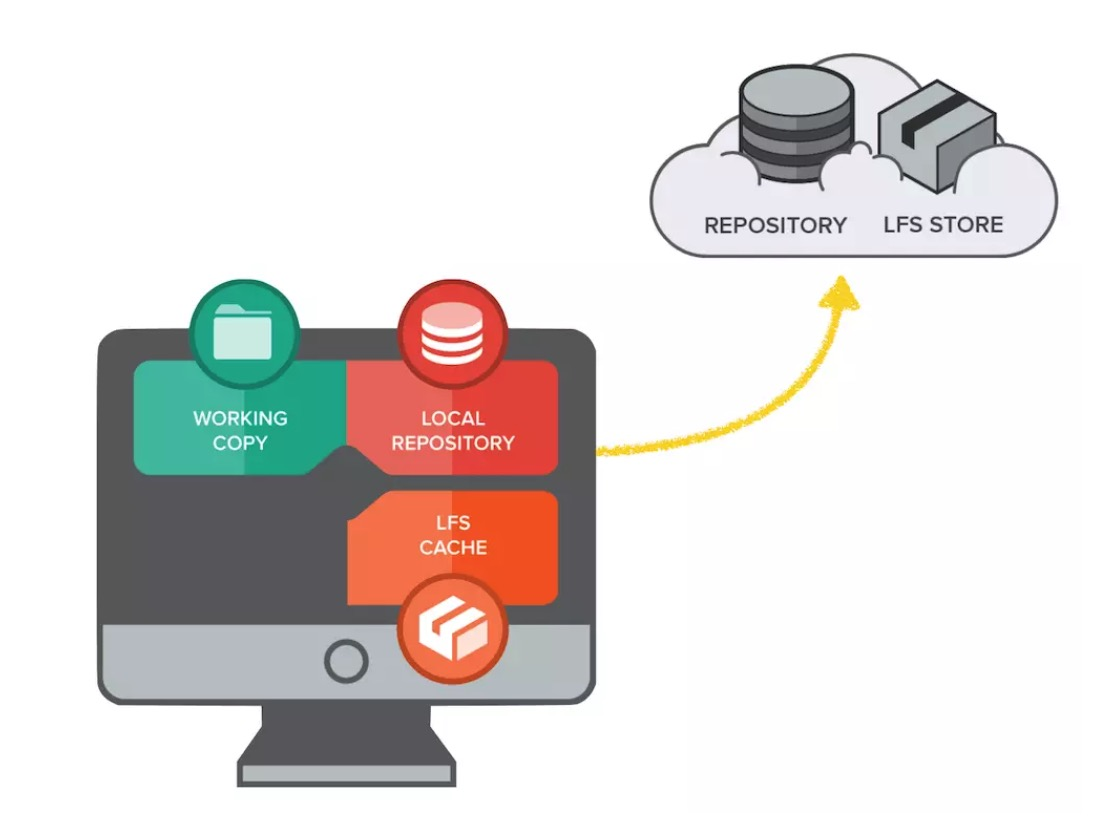
- Git LFS(Large File Storage - ⼤⽂件存储)是可以把⾳乐、图⽚、视频等指定的任意⽂件存在 Git 仓库之外,⽽在 Git 仓库中⽤⼀个占⽤空间 1KB 不到的⽂本指针来代替的⼩⼯具。通过把⼤⽂件存储在 Git 仓库之外,可以减⼩ Git 仓库本身的体积,使克隆 Git 仓库的速度加快,也使得 Git 不会因为仓库中充满⼤⽂件⽽损失性能。
- 使⽤ Git LFS,在默认情况下,只有当前签出的 commit 下的 LFS 对象的当前版本会被下载。此外,我们也可以做配置,只取由 Git LFS 管理的某些特定⽂件的实际内容,⽽对于其他由 Git LFS 管理的⽂件则只保留⽂件指针,从⽽节省带宽,加快克隆仓库的速度;也可以配置⼀次获取⼤⽂件的最近版本,从⽽能⽅便地检查⼤⽂件的近期变动。
1. 问题描述
我们使用过 Git 的同学都知道,随着代码的更新迭代,仓库的体积越来越大。如果操作和使用都比较恰当的情况下,仓库体积不会突增的。但是如果使用不恰当的话,那就非常尴尬了,比如我们下面要说的这种情况,.git 这个隐藏目录特别大。
虽然 .git 这个隐藏目录并不算在代码体积之后,但是我们拉代码的时候,是需要拉下来的,因为里面包含之前的提交记录等信息。这就会导致,原本平和的心情变得焦躁了,因为下载速度变的很慢。
➜ du -d 1 -h
680M ./.git
500K ./misc
68K ./docker
...
1.1G .
2. 原因解释
当我们使用 git add 和 git commit 命令的过程中,Git 不知不觉就会帮我们创建出来了 blob 文件对象,然后更新 index 索引,再然后创建 tree 对象,最后创建出了 commit 对象。这些 commit 对象指向了顶层 tree 对象以及先前的 commit 对象。
而上述创建出来的对象,都以文件的方式保存在 .git/objects 目录下。所以,当我们在使用的过程中,提交了一个体积特别大的文件,就会被 Git 追踪记录在 .git/objects 文件夹下面。
此时,如果我们再次删除这个体积特别大的文件,其实 Git 只会记录了我们删除的这个操作,但并不会把文件从 .git 文件夹下面真正的删除,即 .git 文件夹完全不会变小。
3. 解决方法
根本上的解决方式就是,及时使用 lfs 来追踪记录大文件!
[方法一] 重建仓库
重建仓库的这种做法,算是一种比较一劳永逸且相对而言比较简单的方式。既然现在的仓库已经让我们无法忍受,与其这样,还不是删除重建来的爽快。但是,这种做法一般情况下,都是不可行,除非是自己的本地项目。
[方法二] 删除大文件
第二种做法就是,直接找到 .git 目录下的大文件,将其删除掉,之后推送到远程代码库里面。这样做的前提是,删除所有其他分支,保留 master 或者 main 分支。这里需要注意的是,操作有风险,后果请自负。
# 查找大文件
$ git verify-pack -v .git/objects/pack/*.idx
12235d...dewaaaa34 tree 135 137 144088922
a453ab...34se212qz blob 3695898 695871 144734158
......
# 筛除前五个且保留第一列
$ git verify-pack \
-v .git/objects/pack/*.idx | \
sort -k 3 -n | tail -5 | awk '{print$1}'
12q626a...23a3
2z32ax1...azfd
......
# 查找出最大的5个文件和对应Commit信息
$ git rev-list --objects --all | \
grep "$(git verify-pack -v .git/objects/pack/*.idx | \
sort -k 3 -n | tail -5 | awk '{print$1}')"
91266a...sdfa3 data/xxx.pkl
232ax1...acafd data/yyy.pkl
......
# rev-list: 列出Git仓库中的所有提交记录
# --objects: 列出该提交涉及的所有文件ID
# --all: 所有分支的提交(位于/refs下的所有引用)
# verify-pack: 显示已打包的内容(找大文件)
# 将其删除掉
$ git filter-branch \
--force --prune-empty --index-filter \
"git rm -rf --cached --ignore-unmatch YOU-FILE-NAME" \
--tag-name-filter cat -- --all
# filter-branch: 重写Git仓库中的提交
# --index-filter: 指定后面命令进行删除
# --all: 所有分支的提交(位于/refs下的所有引用)
# 强制推送
$ git push --force --all
# 彻底清除
$ rm -rf .git/refs/original/
$ git reflog expire --expire=now --all
$ git gc --prune=now
[方法三] 使用工具清理
幸好,Github 上面有一个叫做 git-filter-branch 的工具,就是帮助我们来清理大文件对象的,其使用 Scala 语言进行编写的,且操作起来也十分方便。只需要简单几步,就可以完成我们的需要。最新版需要确保本地的 java 为 Jdk8+。
# 下载封装好的jar包
$ wget https://repo1.maven.org/maven2/com/madgag/bfg/1.13.0/bfg-1.13.0.jar
# 克隆的时候需要--mirror参数
$ git clone --mirror git://example.com/big-repo.git
# 运行BFG来清理存储库
$ java -jar bfg.jar --strip-blobs-bigger-than 100M big-repo.git
# 去除脏数据
$ cd big-repo.git
$ git reflog expire --expire=now --all
$ git gc --prune=now --aggressive
# 推送上去
# 此推将更新远程服务器上的所有refs分支
$ git push
# 删除所有的名为'id_dsa'或'id_rsa'的文件
$ java -jar bfg.jar --delete-files id_{dsa,rsa} my-repo.git
# 删除所有大于50M的文件
$ java -jar bfg.jar --strip-blobs-bigger-than 50M my-repo.git
# 删除文件夹下所有的文件
$ java -jar bfg.jar --delete-folders doc my-repo.git
[方法四] 使用 migrate 命令优化 .git 目录
迁移已有的 git 仓库,使⽤ git lfs 来进行管理。重写历史后的提交需执⾏ git commit --force,请确认在本地的操作合适⽆误后再进⾏提交。如有迁移⾄ git lfs 前的仓库有多份拷⻉,其他拷⻉可能需要执⾏ git reset --hard origin/master 来重置其本地的分⽀,注意执⾏ git reset --hard 命令将会丢失本地的改动。
git lfs migrate 用来将当前已经被 GIT 储存库(.git)保存的文件以 LFS 文件的形式保存
# 重写master分⽀
# 将历史提交(指的是.git目录)中的*.zip都⽤lfs进⾏管理
$ git lfs migrate import --include-ref=master --include="*.zip"
# 重写所有分⽀及标签
# 将历史提交(指的是.git目录)中的*.rar,*.zip都⽤lfs进⾏管理
$ git lfs migrate import --everything --include="*.rar,*.zip"
# 切换后需要把切换之后的本地分支提交到远程仓库了,需要手动push更新远程仓库中的各个分支
$ git lfs push --force
# 切换成功后,GIT仓库的大小可能并没有变化
# 主要原因可能是之前的提交还在,因此需要做一些清理工作
# 如果不是历史记录非常重要的仓库,建议不要像上述这么做,而是重新建立一个新的仓库
$ git reflog expire --expire-unreachable=now --all
$ git gc --prune=now
4. 总结教训
比较好的避免上述问题的出现,就是及时使用 lfs 来追踪、记录和管理大文件。这样大文件既不会污染我们的 .git 目录,也可以让我们更方便的使用。
# 1.开启lfs功能
$ git lfs install
# 2.追踪所有后缀名为“.psd”的文件
$ git lfs track "*.iso"
# 3.追踪单个文件
git lfs track "logo.png"
# 4.提交存储信息文件
$ git add .gitattributes
# 5.提交并推送到GitHub仓库
$ git add .
$ git commit -m "Add some files"
$ git push origin master
同时,还有一个方法,就是灵活使用 .gitignore 文件,及时排除我们仓库不需要的特殊目录或者文件,从而不会让不应该存在的文件,出现在我们的代码仓库里面。
.DS_Store
node_modules
/dist
*.zip
*.tar.gz
Git常见零碎问题汇总
1. GIT 分支已经删除
远程获取分支最新代码,提示远程分支已经不存在了
问题描述:下拉代码的时候提示分支不太对。
# 获取最新代码报错
➜ git pull
Your configuration specifies to merge with the ref 'refs/heads/ipo_user'
from the remote, but no such ref was fetched.
解决方法:后面发现该分支已经在远程仓库中删除了,所以需要切换到其他分支。
# 切换到dev分支
➜ git checkout dev
2. LFS 提交方式不对
LFS 获取文件的时候,获取的文件状态不太对
问题描述:查看仓库状态的时候,发现有文件已经删除了,但是 checkout 的时候,提示操作不当。
# 当前仓库状态
➜ git status
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: data/model/app1.zip
deleted: data/model/app2.zip
# 执行checkout命令没有效果
➜ git checkout -- data/model/app1.zip
Encountered 1 file(s) that should have been pointers, but weren't:
data/model/app1.zip
解决方法:清除缓存并执行硬重置。
# 操作需谨慎
➜ git rm --cached -r .
➜ git reset --hard
3. LFS 撤销历史提交
修改历史提交的操作需要谨慎处理
问题描述:在仓库修改 lfs 的 track 文件的时候,本应该会添加 "*.iso" 号结果修改成了错了 ".iso",导致 push 上去发现参数文件没有使用 lfs 文件。现在的需要,将这一次关于 lfs 的提交 rewrite 掉。
# 普通文件的处理方式
$ git reset –hard ^HEAD
$ git push origin master
解决方法:lfs 工具提供了 migrate 命令来处理这个问题。
# 使用migrate命令
$ git lfs migrate import --include="data/app_mold/*" --everything
# 推送报错表示分支有保护机制,去掉之后在推送即可
$ git push --force
Locking support detected on remote "origin". Consider enabling it with:
......
! [remote rejected] master -> master (pre-receive hook declined)
error: failed to push some refs to 'git@xxx.xxx.com:xxx/app.git'
4. LFS 需要输入密码
多为本地秘钥的缓存时间已经过去
问题描述:提送 lfs 信息,提示需要输入密码。
# 提示信息如下所示
Authentication failed for 'https://______.git'
解决方法:添加本地公私钥并设置缓存时间。
# [1] 使用SSH连接
$ cd ~/.ssh
$ ssh-keygen -t rsa -C "xxxxxx@yy.com"
$ ssh -T git@github.com
# [2] 修改缓存时间
$ git config --global credential.helper 'cache --timeout=3600'
# [3] 本地储存起来
$ git config --global credential.helper store
5. LFS 无法获取文件
使用新版本的 LFS 工具
问题描述:某个环境发现如下报错,排除原因发现是对应仓库的 lfs 文件并没有从远程仓库拉下来。服务更新都是使用的 CI/CD 工具,但是其他服务器获取 lfs 文件并没有任何问题,而且登录服务器手动执行 git lfs pull 也是可以正常执行的,这就很奇怪了。排除了自动部署工具的默认参数和对应的 git 工具配置并没有发现任何有用的信息
# 报错信息如下
2020-xx-xx xx:xx:xx: I tensorflow/stream_executor/platform/default/dso_loader.cc:28]
Traceback (most recent call last):
File "/usr/lib/python3.6/runpy.py", line 113, in _run_module_as_main
"__main__", mod_spec)
......
File "/data/app_test/.../hhkc/.../network.py", line 54, in <module>
from transformers.modeling_hhkc import (
ImportError: cannot import name 'HhkcLayerNorm'
解决方法:最后,发现是因为 git-lfs 工具的版本太低导致其默认参数和新版的不一致,这才导致自动部署工具获取 lfs 文件异常。这几台出问题的服务器,当时安装 lfs 工具都是使用 apt 来安装的,所以默认的仓库对应的软件版本号比较低,所以按照官方网站的更新方式部署更新之后,一切都变得正常了。
# 老版本的lfs工具(git-lfs/2.3.4)
$ git lfs env | grep "dTransfers"
DownloadTransfers=basic
UploadTransfers=basic
# 新版本的lfs工具(git-lfs/2.12.0)
DownloadTransfers=basic,lfs-standalone-file
UploadTransfers=basic,lfs-standalone-file
# git-lfs-standalone-file
为文件URL(本地路径)提供独立传输适配器
https://github.com/git-lfs/git-lfs/blob/master/docs/man/git-lfs-standalone-file.1.ronn
# 官方提供的更新方式
$ curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
$ sudo apt-get install git-lfs
$ git lfs install
6. Git 切换分支不存在
查看 git 的 config 信息获取远程信息细节
问题描述: 在一个测试仓库上面需要临时切换分支,但是切换分支的时候提示如下错误,提示没有找到匹配的分支。但是登陆远程仓库,发现对应的分支是存在的。想到有可能是因为没有更新代码导致无法获取远程仓库的分支信息,随即执行这个 git fetch 命令,但是报错依旧,且通过 git branch -a 也看不到对应的分支信息。
# 报错提示
$ git checkout bugfix_login_error
error: pathspec 'bugfix_login_error' did not match any file(s) known to git.
解决方法: 后来,排查了一下 .git 目录文件夹里面的信息,随即发现了问题原因。即远程仓库的获取只是对标于 master 分支,所以我们通过执行 git fetch 命令之后也是无法获取远程仓库的分支信息的,按照如下修改即可解决。
# 发现远程仓库的获取只是对标于master分支
$ cat .git/config
[remote "origin"]
url = git@github.com/EscapeLife/app-demo.git
fetch = +refs/heads/master:refs/remotes/origin/master
[branch "master"]
remote = origin
merge = refs/heads/master
# 应该为带 * 的匹配方式
[remote "origin"]
fetch = +refs/heads/*:refs/remotes/origin/*
问题原因: 我们正常克隆仓库的时候,对应的 config 配置就是带 * 的样式,但是为什么这个环境的配置会修改了呢?后来发现是因为这个环境是通过 CI 进行自动更新的,而 CI 配置了只获取指定分支的代码,即拉去代码的时候就指定了,这也就导致配置文件也就跟着 变更 了。
# 让Git每次只拉取远程的master分支,而不是远程的所有分支
$ git fetch origin master:refs/remotes/origin/master
7. GIT 显示中文乱码
Git 命令显示中文和解决中文乱码
问题描述:使用 git status 命令查看文档或者目录改动时,显示不出中文文件名和中文文件名称,非常不方便。
# 显示中文乱码
➜ git status
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
deleted: 234\123\234\654\234/954\236\952/.vscode/settings.json
解决方法:在默认设置下,中文文件名在工作区状态输出,中文名不能正确显示,而是显示为八进制的字符编码。将 git 配置文件 core.quotepath(引用路径) 项设置为 false,即可显示中文。要注意的是,这样设置后,你的 git bash 终端也要设置成中文和 utf-8 编码,才能正确显示中文。
# [修改方式一] 临时修改
➜ git config core.quotepath false
# [修改方式二] 全局配置
➜ git config --global core.quotepath false
# [修改方式三] 编辑/etc/gitconfig文件
➜ vim /etc/gitconfig
[core]
quotepath = false # 引用路径不再是八进制
Git变基使用方式
变基 rebase 的特点:把分叉的提交历史“整理”成一条直线,看上去更直观。
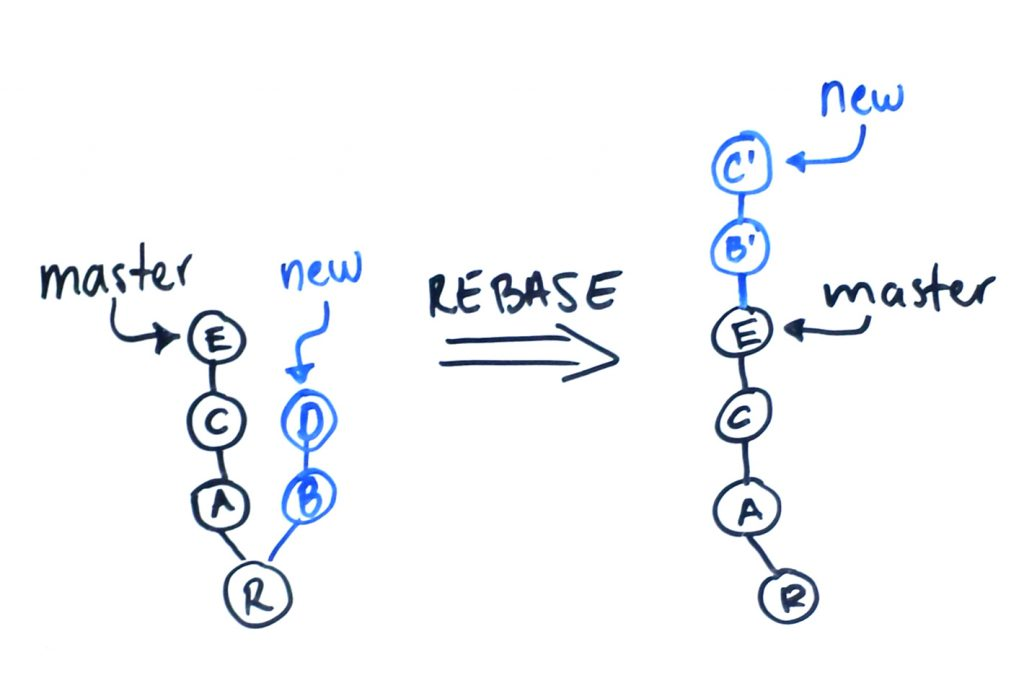
1. Rebase:产生意义
在 Git 中整合来自不同分支的修改主要有两种方法:merge 以及 rebase。对应 merge 操作来说,想必我们都已经使用过很多次了,而 rebase 又是用在哪里呢?已经其正确的使用方式,到底是什么呢?
我们使用 Git 进行产品开发的代码管理,势必是会存在多人在同一个分支上协同工作的问题,这样就很容易出现冲突。而遇到冲突的时候,一般情况都是已经有人在该分支上面提交代码了,我们不得不先将其他的提交 pull 到本地,然后在本地合并(如果有冲突的话),最后才能 push 成功。
$ git push origin master
To github.com:xxx/xxx.git
! [rejected] master -> master (fetch first)
error: failed to push some refs to 'git@github.com:xxx/xxx.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
但是我们会发现提交记录会变得有点嘎里嘎气的,强迫症的你可能需要一条干净的直线,因为太多无用的 commit 很让人不舒服。而且不利于每天下午的 code review 代码检视,同时也会污染分支提交记录。
如果使用 rebase 操作的话,可以把本地未 push 的分叉提交历史整理成直线。rebase 的目的是使得我们在查看历史提交的变化时更容易,因为分叉的提交需要三方对比。
$ git log --graph --pretty=oneline --abbrev-commit
* e0ea545 (HEAD -> master) Merge branch 'master' of github.com:xxx/xxx
|\
| * f005ed4 (origin/master) add email info
* | 582d922 add author info
* | 8875536 add comment info
|/
* d1be385 init hello repo
......
2. Rebase:合并纪录
主要讲述如何将之前 commit 提交信息进行合并
这个时候,就该 rebase 上场了,其会使原本分叉的提交立马变成一条直线!这种神奇的操作,其实原理非常简单。注意观察,Git 把我们本地的提交“挪动”了位置,放到了 f005ed4 之后,这样,整个提交历史就成了一条直线。rebase 操作前后,最终的提交内容是一致的,但是,我们本地的 commit 修改内容已经变化了,它们的修改不再基于 d1be385,而是基于 f005ed4,但最后的提交 7e61ed4 内容是一致的。
$ git rebase
First, rewinding head to replay your work on top of it...
Applying: add comment
Using index info to reconstruct a base tree...
M hello.py
Falling back to patching base and 3-way merge...
Auto-merging hello.py
Applying: add author
Using index info to reconstruct a base tree...
M hello.py
Falling back to patching base and 3-way merge...
Auto-merging hello.py
# 再用 git log 看看发现变成直线了
$ git log --graph --pretty=oneline --abbrev-commit
* 7e61ed4 (HEAD -> master) add author info
* 3611cfe add comment info
* f005ed4 (origin/master) add email info
* d1be385 init hello repo
......
当然,我们也可以指定对最近的多少次的提交纪录进行合并。需要注意的是,不要合并已经提交到仓库的提交,不然会有问题。

# 合并最近的3次提交纪录
# 之后就会自动进入vi编辑模式
$ git rebase -i HEAD~3
s 7e61ed4 add author info
s 3611cfe add comment info
s f005ed4 add email info
# 最好编辑退出即可
# 如果你异常退出了vi窗口,不要紧张,执行下面操作即可
$ git rebase --edit-todo
$ git rebase --continue
3. Rebase:分支合并
假设你们团队一直在 master 分支上面开发,但是因为新功能所以切了一个 dev 分支出来。这时,你的同事完成了自己开发的部分 hotfix 并将其合入了 master 分支,此时你的分支已经落后于 master 分支了。
恰巧,这时你需要同步 master 分支上面的改动,进行测试。我们就需要 merge 代码到自己的分支上。此时,我们会发现本地有一些 merge 信息。强迫症的你,可能认为这样会污染我们自己的原本干净的提交记录,想要保持一份干净的提交记录。此时,我们就是使用 rebase 了。
我们使用 git rebase 命令,先回退到同事 hotfix,后合并 master 分支:
- 首先,git 会把 dev 分支里面的每个 commit 取消掉;
- 其次,把上面的操作临时保存成 patch 文件,存在 .git/rebase 目录下;
- 然后,把dev 分支更新到最新的 master 分支;
- 最后,把上面保存的 patch 文件应用到 dev 分支上;
从 commit 记录上可以看出来,dev 分支是基于 hotfix 合并后的 master,自然而然的成为了最领先的分支,而且没有 merge 的 commit 记录,是不是感觉很舒服了。
# 我们自己在dev分支上面
$ git rebase master
4. Rebase:使用建议
不能忽视一个重要的事实:rebase 会改写历史记录
下面是一些在使用 rebase 当中需要注意的地方:
- 最好是该分支只有你自己在使用,否则请谨慎操作。
- 只使用 rebase 来清理本地的提交记录,千万不要尝试对已发布的提交进行操作。
虽然 rebase 相对于我们已知的整合操作来说有着比较显著的优点,但是这也是在很大程度上取决于个人的喜好。一些团队喜欢使用 rebase,而另一些可能倾向于使用 merge 合并。此外,rebase 相对于 merge 合并来说是比较复杂的,除非你和你的团队确定会用到 rebase 操作。
使用Git进行大文件存储
大文件存储(LFS)是可以把音乐、图片、视频等指定的任意文件存在 Git 仓库之外,而在 Git 仓库中用一个占用空间 1KB 不到的文本指针来代替的小工具。通过把大文件存储在 Git 仓库之外,可以减小 Git 仓库本身的体积,使克隆 Git 仓库的速度加快,也使得 Git 不会因为仓库中充满大文件而损失性能。

1. 背景介绍
Git LFS 是 Github 开发的一个 Git 的扩展,用于实现 Git 对大文件的支持。
在游戏开发过程中,设计资源占用了很大一部分空间。像 png、psd 等文件是二进制(blob)的体积也很庞大。但 Git 的 diff/patch 等是基于文件行的。对于二进制文件来说,Git 需要存储每次 commit 的改动。每次当二进制文件修改发生变化时,都会产生额外的提交量,导致 clone 和 pull 的数据量大增,在线仓库的体积也会迅速增长。
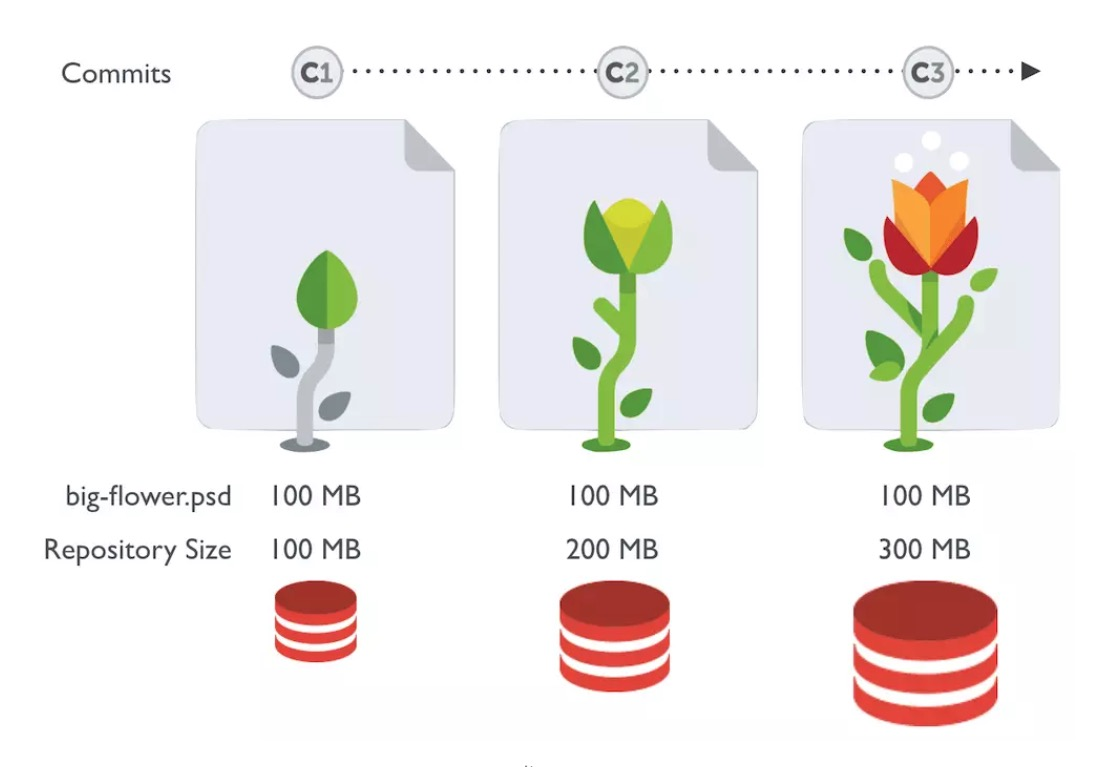
LFS(Large File Storage)就是为了解决这一问题而产生的工具。它将你所标记的大文件保存至另外的仓库,而在主仓库仅保留其轻量级指针。那么在你检出版本时,根据指针的变化情况下更新对应的大文件,而不是在本地保存所有版本的大文件。
2. 安装扩展
安装 Git LFS 需要 Git 的版本不低于 1.8.5
# Mac
$ brew install git-lfs
$ git lfs install
# Linux
$ curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
$ sudo apt-get install git-lfs
$ git lfs install
3. 快速使用
# 1.开启lfs功能
$ git lfs install
# 2.追踪所有后缀名为“.psd”的文件
$ git lfs track "*.iso"
# 3.追踪单个文件
git lfs track "logo.png"
# 4.提交存储信息文件
$ git add .gitattributes
# 5.提交并推送到GitHub仓库
$ git add .
$ git commit -m "Add some files"
$ git push origin master
# 只推送仓库本身⽽不推送任何LFS对象
$ git push --no-verify backup master
# 仅获取指定⽬录下的LFS对象 - 包含指定的⽂件夹
$ git config lfs.fetchinclude 'images/**'
# 仅获取指定⽬录下的LFS对象 - 排除指定的⽂件夹
$ git config lfs.fetchexclude 'images/**'
# 也可以同时使⽤⿊⽩名单规则
$ git config lfs.fetchinclude 'videos/**'
$ git config lfs.fetchexclude 'videos/chameleon.mp4'
# ⼀次获取LFS对象的最近版本(同时下载过去7天内的版本)
$ git config lfs.fetchrecentcommitsdays 7
4. 使用文档
git lfs
[1] 常用命令

# 克隆包含“Git LFS”文件的远程仓库到本地
$ git clone git@gitlab.example.com:group/project.git
# 已经克隆了仓库且想要获取远程存储库中的最新LFS对象
$ git lfs fetch origin master
# 获取最新的LFS对象当本地仓库
$ git lfs pull
# 推送本地的LFS修改到远程仓库
$ git lfs push
[2] 生疏命令

# 防止在多人协作的场景下冲突
# -----------------------------------------------------------------------
# 在使用文件锁定之前,要做的第一件事是告诉LFS哪种文件是可锁定的
# 以下命令就是将PNG文件存储在LFS中,并将其标记为可锁定的状态
$ git lfs track "*.png" --lockable
# 执行上述命令后,将创建或更新具有以下内容的名为.gitattributes的文件
*.png filter=lfs diff=lfs merge=lfs -text lockable
# 准备好之后,先将其中一个文档给锁定了
$ git lfs lock images/banner.png
Locked images/banner.png
# 这会将文件以您的名字锁定在服务器上注册
$ git lfs locks
images/banner.png joe ID:123
# 推送更改后,您可以解锁文件,以便其他人也可以编辑它
$ git lfs unlock --id=123
$ git lfs unlock images/banner.png
# 如果出于某种原因需要解锁未被您锁定的文件
# 可以使用--force标志,只要您对项目具有maintainer访问权限即可
$ git lfs unlock --id=123 --force
# 迁移可以使用,但并没那么美好(将GIT对象转为LFS对象)
# -----------------------------------------------------------------------
# 将所有本地分支上匹配到的文件提交历史版本都转换为LFS上面
# 这个时候无论你切换到哪个分支,都会出现.gitattributes文件,且内容都是一样的
$ git lfs migrate import --include="*.bin" --everything
$ git lfs push --force
# 如果只想更新某个分支的话,可以使用如下命令
# 切换后需要把切换之后的本地分支提交到远程仓库了,需要手动push更新远程仓库中的各个分支
$ git lfs migrate import --include="*.bin" --include-ref=refs/heads/master
$ git lfs push --force
# 当其他人员再次使用pull去远程拉取的时候会失败
# 可以使用下面命令来把远程仓库被修改的历史与本地仓库历史做合并,但是最好是重新拉取
$ git lfs pull --allow-unrelated-histories
# 切换成功后,GIT仓库的大小可能并没有变化
# 主要原因可能是之前的提交还在,因此需要做一些清理工作
# 如果不是历史记录非常重要的仓库,建议不要像上述这么做,而是重新建立一个新的仓库
$ git reflog expire --expire-unreachable=now --all
$ git gc --prune=now
[3] 完整命令
# High level commands
# -----------------------------------------------------------------------
* git lfs checkout:
Populate working copy with real content from Git LFS files.
* git lfs fsck:
Check Git LFS files for consistency.
* git lfs install:
Install Git LFS configuration.
* git lfs lock:
Set a file as "locked" on the Git LFS server.
* git lfs locks:
List currently "locked" files from the Git LFS server.
* git lfs logs:
Show errors from the Git LFS command.
* git lfs migrate:
Migrate history to or from Git LFS
* git lfs prune:
Delete old Git LFS files from local storage
* git lfs pull:
Fetch Git LFS changes from the remote & checkout any required working tree
files.
* git lfs push:
Push queued large files to the Git LFS endpoint.
* git lfs uninstall:
Uninstall Git LFS by removing hooks and smudge/clean filter configuration.
* git lfs unlock:
Remove "locked" setting for a file on the Git LFS server.
# Low level commands
# -----------------------------------------------------------------------
* git lfs clean:
Git clean filter that converts large files to pointers.
* git lfs pointer:
Build and compare pointers.
* git lfs pre-push:
Git pre-push hook implementation.
* git lfs filter-process:
Git process filter that converts between large files and pointers.
* git lfs smudge:
Git smudge filter that converts pointer in blobs to the actual content.
Git的工作流程
1. 分支管理
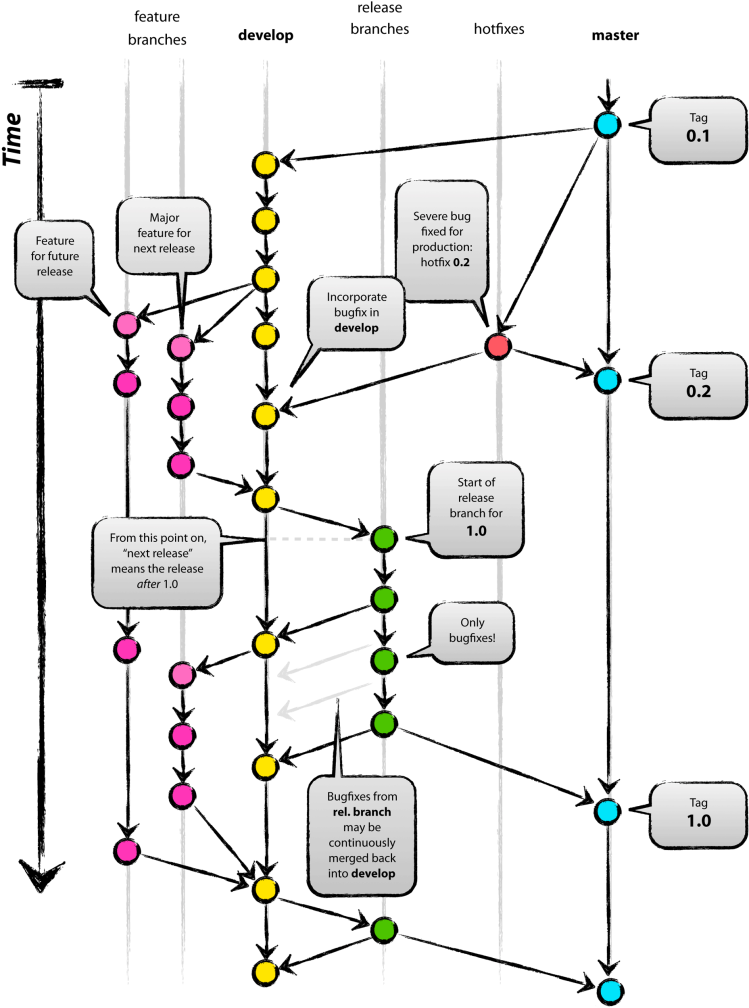
团队开发中,遵循一个合理、清晰的 Git 使用流程,是非常重要的。否则,每个人都提交一堆杂乱无章的 commit,项目很快就会变得难以协调和维护。
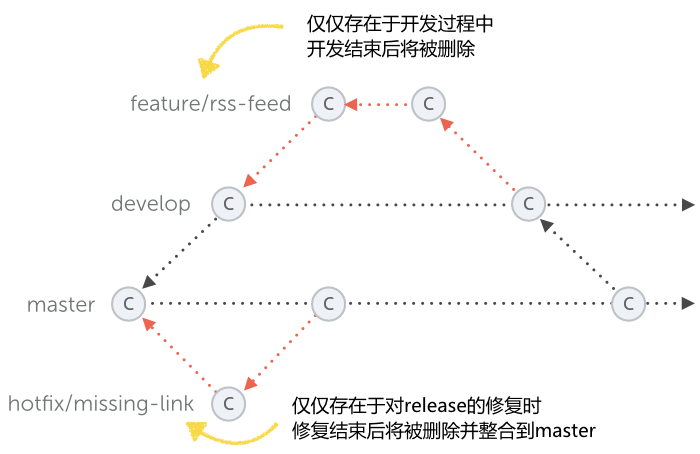
[1] develop 分支 - 开发分支
develop 分支作为常驻开发分支,用来汇总下个版本的功能提交。在下个版本的 release 分支创建之前不允许提交非下个版本的功能到 develop 分支,develop 分支内容会自动发布到内网开发环境。确保 develop 分支随时可编译、可运行,上面的功能模块是相对稳定、干净的,随时可以在 develop 上拉 feature 分支进行开发。
[2] feature 分支 - 功能分支
对于新功能开发,应从 develop 上切出一个 feature 分支进行开发,命名格式为 feature/project。其中功能名使用小写单词结合中划线连缀方式,如 feature/update-web-style。feature 分支进行编译通过并自测通过后,再合并到主干 develop 分支上。
[3] 补丁分支 - hotfix branch
所谓补丁分支,就是当代码已经部署到了正式环境之后发现没有预测到底 Bug 时,通过补丁分支进行修改之后,生成补丁进行修复。当然也可以说不使用布丁分支,重新发布新版本也是可以的,但是这样还是不太合理。
[4] master 分支 - 主分支
当 develop 分支开发完成一个版本的时候,测试没有问题之后就可以将其提交之后合并到 master分支了,master 分支内容会自动发布到内网正式环境。需要注意的是,一般情况从开发分支合入到主干分支不会有代码冲突的,如果有的话那就是没有按照上述流程严格执行的结果。
[5] release 分支 - 预发布分支
最后就到了发包的最后阶段了,将已经在 master 内网正式环境上测试没有问题的版本合入 release 分支,打包给客户部署或者更新线上环境,完成最后的更新操作。
2. 代码规范
提交代码其实是有很多讲究的,如果我们都按照自己的想法随意的提交代码,到最后自己都不知道当时这次提交到底是为了解决什么问题了。良好的代码提交习惯即有利于自己之后的审查,也有助于其他人观看,同时利用脚本来提取有价值的信息。如查看人个人的工作量,每日的工作任务,等等。
[1] 提交模板 - commit model
我们更多使用的是如下简化版 commit 模板:
# 模板格式
<提交类型>-<项目名称>: <本次代码提交的动机>
# 示例说明
feat-Pandas: update runtime to V1.3.0
[2] 类型分类 - brand list
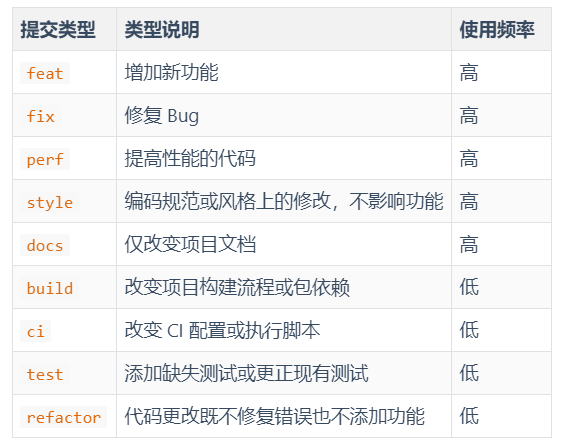
3. 使用技巧
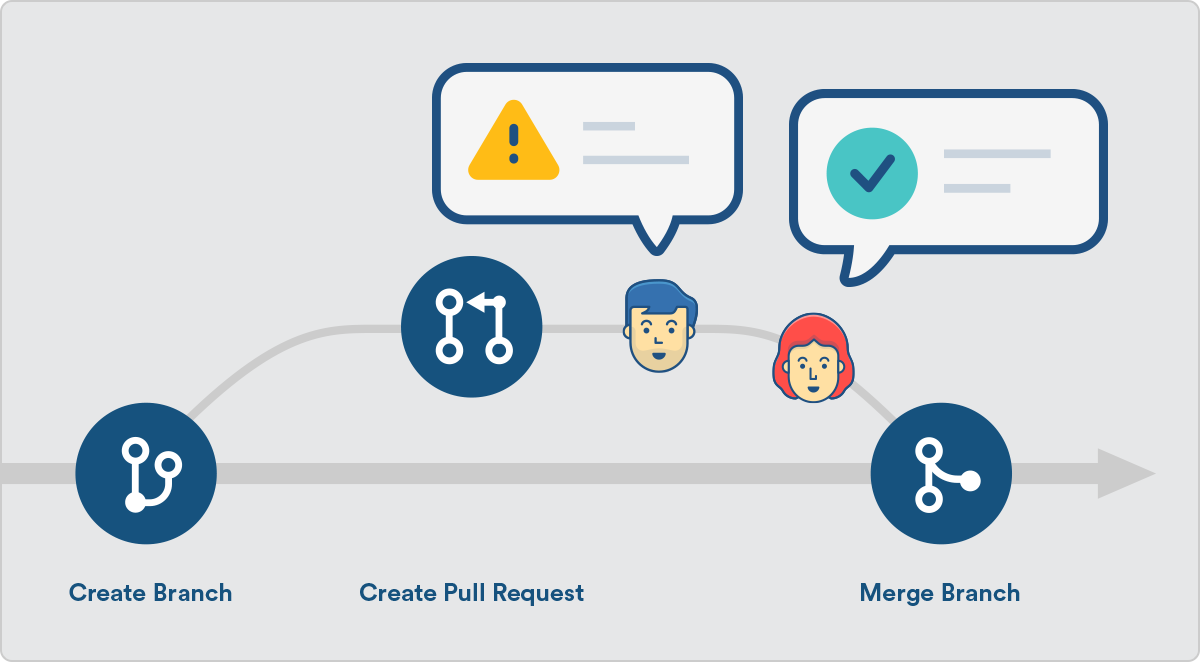
[1] 代码合并 - pull request
功能分支合并进 master 分支,必须通过 Pull Request 操作,在 Gitlab 里面叫做 Merge Request。Pull Request 本质其实就是一种对话机制,你可以在提交的时候附加上有用的信息,并 @ 相关的核心开发者或团队,引起他们的注意。让他们为了的代码把好最后一道关卡,保证你的代码质量。
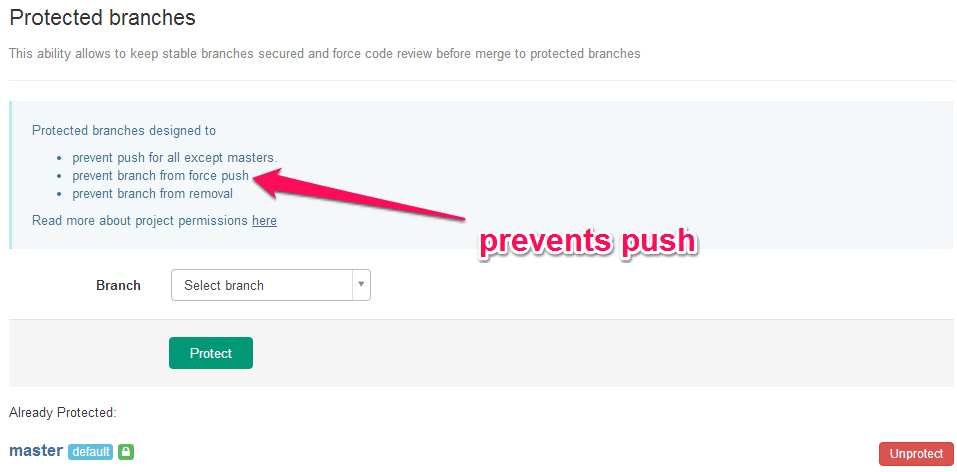
[2] 分支保护 - protected branch
master 分支应该受到保护,不是每个人都可以修改这个分支,以及拥有审批 Pull Request 的权力。Github 和 Gitlab 都提供“保护分支”这个功能。
[3] 新建问题 - issue
Issue 用于Bug 追踪和需求管理。建议先新建 Issue,再新建对应的功能分支。功能分支总是为了解决一个或多个 Issue。功能分支的名称,可以与 issue 的名字保持一致,并且以 issue 的编号起首,比如 15-change-password。
开发完成后,在提交说明里面,可以写上"fixes #15" 或者 "closes #67"。Github 和 gitlab 规定,只要 commit message 里面有下面这些动词+编号,就会关闭对应的 issue。
# 以下词语都可以关闭对应issue
close
closes
closed
fix
fixes
fixed
resolve
resolves
resolved
这种方式还可以一次关闭多个 issue,或者关闭其他代码库的 issue,格式是 username/repository#issue_number。Pull Request 被接受以后,issue 关闭,原始分支就应该删除。如果以后该 issue 重新打开,新分支可以复用原来的名字。
[4] 冲突解决 - merge
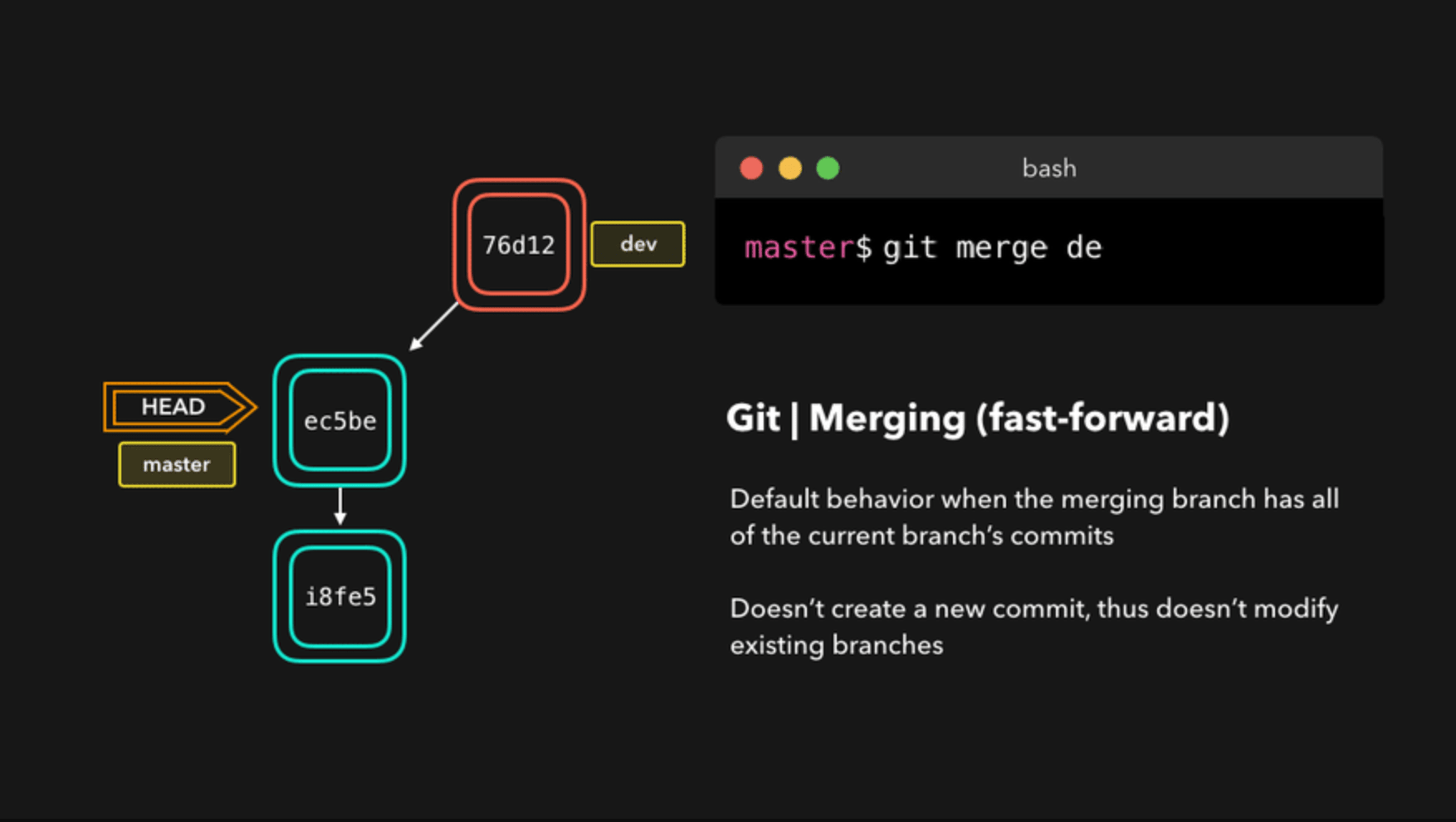
Git 有两种合并:一种是 “直进式合并” (fast forward)不生成单独的合并节点;另一种是 “非直进式合并” (none fast-forword)会生成单独节点。
前者不利于保持 commit 信息的清晰,也不利于以后的回滚,建议总是采用后者(即使用--no-ff参数)只要发生合并,就要有一个单独的合并节点。
[5] 合并提交 - squash
为了便于他人阅读你的提交,也便于 cherry-pick 或撤销代码变化,在发起 Pull Request 之前,应该把多个 commit 合并成一个。

前提是,该分支只有你一个人开发,且没有跟 master 合并过。这可以采用 rebase 命令附带的 squash 操作,具体方法请参考《Git 使用规范流程》。
# 第一步:新建分支
$ git checkout master
$ git pull
$ git checkout -b myfeature
# 第二步:提交分支
$ git add .
$ git status
$ git commit -m "this is a test."
# 第三步:与主干同步
$ git fetch origin
$ git rebase origin/master
# 第四步:合并多个commit为一个
# i参数表示互动并打开一个互动界面进行下一步操作
# 会列出当前分支最新的几个commit,越下面越新
# 默认是pick类型,squash和fixup可以用来合并commit
$ git rebase -i origin/master
pick 07c5abd Introduce OpenPGP and teach basic usage
s de9b1eb Fix PostChecker::Post#urls
s 3e7ee36 Hey kids, stop all the highlighting
pick fa20af3 git interactive rebase, squash, amend
# 第六步:推送到远程仓库并发出合并请求
# 要加上force参数是因为rebase以后分支历史改变了
$ git push --force origin myfeature
