
select 进阶
nil的通道永远阻塞
当case上读一个通道时,如果这个通道是nil,则该case永远阻塞。这个功能有1个妙用,select通常处理的是多个通道,当某个读通道关闭了,但不想select再继续关注此case,继续处理其他case,把该通道设置为nil即可。
下面是一个合并程序等待两个输入通道都关闭后才退出的例子,就使用了这个特性。
func combine(inCh1, inCh2 <-chan int) <-chan int {
// 输出通道
out := make(chan int)
// 启动协程合并数据
go func() {
defer close(out)
for {
select {
case x, open := <-inCh1:
if !open {
inCh1 = nil
break
}
out <- x
case x, open := <-inCh2:
if !open {
inCh2 = nil
break
}
out <- x
}
// 当ch1和ch2都关闭是才退出
if inCh1 == nil && inCh2 == nil {
break
}
}
}()
return out
}
如何跳出for-select
break在select内的并不能跳出for-select循环。看下面的例子,consume函数从通道inCh不停读数据,期待在inCh关闭后退出for-select循环,但结果是永远没有退出。
既然break不能跳出for-select,那怎么办呢?给你3个锦囊:
- 在满足条件的case内,使用return,如果有结尾工作,尝试交给defer。
- 在select外for内使用break挑出循环,如combine函数。
- 使用goto。
package main
import (
"fmt"
)
func combine(inCh1, inCh2 <-chan int) <-chan int {
// 输出通道
out := make(chan int)
// 启动协程合并数据
go func() {
defer close(out)
for {
select {
case x, open := <-inCh1:
if !open {
inCh1 = nil
break
}
out <- x
case x, open := <-inCh2:
if !open {
inCh2 = nil
break
}
out <- x
}
// 当ch1和ch2都关闭是才退出
if inCh1 == nil && inCh2 == nil {
break
}
}
}()
return out
}
func product() chan int {
out := make(chan int, 1000)
defer close(out)
for i := 0; i < 1000; i++ {
out <- i
}
return out
}
func consume(inCh <-chan int) {
i := 0
defer fmt.Println("combine-routine exit")
for {
fmt.Printf("for: %d\n", i)
select {
case x, open := <-inCh:
if !open {
return
}
fmt.Printf("read: %d\n", x)
}
i++
}
}
func main() {
inCh1 := product()
inCh2 := product()
out := combine(inCh1, inCh2)
consume(out)
}
select{}永远阻塞
select{}的效果等价于创建了1个通道,直接从通道读数据:
ch := make(chan int)
<-ch
但是,这个写起来多麻烦啊!没select{}简洁啊。
但是,永远阻塞能有什么用呢!?
当你开发一个并发程序的时候,main函数千万不能在子协程干完活前退出啊,不然所有的协程都被迫退出了,还怎么提供服务呢?
比如,写了个Web服务程序,端口监听、后端处理等等都在子协程跑起来了,main函数这时候能退出吗?
select应用场景
最后,介绍下我常用的select场景:
J* 无阻塞的读、写通道。即使通道是带缓存的,也是存在阻塞的情况,使用select可以完美的解决阻塞读写,这篇文章我之前发在了个人博客,后面给大家介绍下。
- 给某个请求/处理/操作,设置超时时间,一旦超时时间内无法完成,则停止处理。
- select本色:多通道处理
无阻塞读写Golang channel
阻塞场景
阻塞场景共4个,有缓存和无缓冲各2个。
无缓冲通道
无缓冲通道的特点是,发送的数据需要被读取后,发送才会完成,它阻塞场景:
- 通道中无数据,但执行读通道。
- 通道中无数据,向通道写数据,但无协程读取。
// 场景1
func ReadNoDataFromNoBufCh() {
noBufCh := make(chan int)
<-noBufCh
fmt.Println("read from no buffer channel success")
// Output:
// fatal error: all goroutines are asleep - deadlock!
}
// 场景2
func WriteNoBufCh() {
ch := make(chan int)
ch <- 1
fmt.Println("write success no block")
// Output:
// fatal error: all goroutines are asleep - deadlock!
}
注:示例代码中的Output注释代表函数的执行结果,每一个函数都由于阻塞在通道操作而无法继续向下执行,最后报了死锁错误。
有缓冲通道
有缓存通道的特点是,有缓存时可以向通道中写入数据后直接返回,缓存中有数据时可以从通道中读到数据直接返回,这时有缓存通道是不会阻塞的,它阻塞的场景是:
- 通道的缓存无数据,但执行读通道。
- 通道的缓存已经占满,向通道写数据,但无协程读。
// 场景1
func ReadNoDataFromBufCh() {
bufCh := make(chan int, 1)
<-bufCh
fmt.Println("read from no buffer channel success")
// Output:
// fatal error: all goroutines are asleep - deadlock!
}
// 场景2
func WriteBufChButFull() {
ch := make(chan int, 1)
// make ch full
ch <- 100
ch <- 1
fmt.Println("write success no block")
// Output:
// fatal error: all goroutines are asleep - deadlock!
}
使用Select实现无阻塞读写
select是执行选择操作的一个结构,它里面有一组case语句,它会执行其中无阻塞的那一个,如果都阻塞了,那就等待其中一个不阻塞,进而继续执行,它有一个default语句,该语句是永远不会阻塞的,我们可以借助它实现无阻塞的操作。
面示例代码是使用select修改后的无缓冲通道和有缓冲通道的读写,以下函数可以直接通过main函数调用,其中的Ouput的注释是运行结果,从结果能看出,在通道不可读或者不可写的时候,不再阻塞等待,而是直接返回。
// 无缓冲通道读
func ReadNoDataFromNoBufChWithSelect() {
bufCh := make(chan int)
if v, err := ReadWithSelect(bufCh); err != nil {
fmt.Println(err)
} else {
fmt.Printf("read: %d\n", v)
}
// Output:
// channel has no data
}
// 有缓冲通道读
func ReadNoDataFromBufChWithSelect() {
bufCh := make(chan int, 1)
if v, err := ReadWithSelect(bufCh); err != nil {
fmt.Println(err)
} else {
fmt.Printf("read: %d\n", v)
}
// Output:
// channel has no data
}
// select结构实现通道读
func ReadWithSelect(ch chan int) (x int, err error) {
select {
case x = <-ch:
return x, nil
default:
return 0, errors.New("channel has no data")
}
}
// 无缓冲通道写
func WriteNoBufChWithSelect() {
ch := make(chan int)
if err := WriteChWithSelect(ch); err != nil {
fmt.Println(err)
} else {
fmt.Println("write success")
}
// Output:
// channel blocked, can not write
}
// 有缓冲通道写
func WriteBufChButFullWithSelect() {
ch := make(chan int, 1)
// make ch full
ch <- 100
if err := WriteChWithSelect(ch); err != nil {
fmt.Println(err)
} else {
fmt.Println("write success")
}
// Output:
// channel blocked, can not write
}
// select结构实现通道写
func WriteChWithSelect(ch chan int) error {
select {
case ch <- 1:
return nil
default:
return errors.New("channel blocked, can not write")
}
}
使用Select+超时改善无阻塞读写
使用default实现的无阻塞通道阻塞有一个缺陷:当通道不可读或写的时候,会立即返回。实际场景,更多的需求是,我们希望,尝试读一会数据,或者尝试写一会数据,如果实在没法读写,再返回,程序继续做其它的事情。
使用定时器替代default可以解决这个问题。比如,我给通道读写数据的容忍时间是500ms,如果依然无法读写,就即刻返回,修改一下会是这样:
func ReadWithSelect(ch chan int) (x int, err error) {
timeout := time.NewTimer(time.Microsecond * 500)
select {
case x = <-ch:
return x, nil
case <-timeout.C:
return 0, errors.New("read time out")
}
}
func WriteChWithSelect(ch chan int) error {
timeout := time.NewTimer(time.Microsecond * 500)
select {
case ch <- 1:
return nil
case <-timeout.C:
return errors.New("write time out")
}
}
结果就会变成超时返回:
read time out
write time out
read time out
write time out
channel 使用场景
channel的使用场景
把channel用在数据流动的地方:
- 消息传递、消息过滤
- 信号广播
- 事件订阅与广播
- 请求、响应转发
- 任务分发
- 结果汇总
- 并发控制
- 同步与异步
- …
channel的基本操作和注意事项
channel存在3种状态:
- nil,未初始化的状态,只进行了声明,或者手动赋值为nil
- active,正常的channel,可读或者可写
- closed,已关闭,千万不要误认为关闭channel后,channel的值是nil
channel可进行3种操作:
- 读
- 写
- 关闭
把这3种操作和3种channel状态可以组合出9种情况:
|操作 |nil的channel |正常channel| 已关闭channel |
| - | - | - | - |
|<- ch |阻塞 |成功或阻塞 |读到零值 |
|ch <- |阻塞 |成功或阻塞 |panic |
|close(ch) |panic | 成功 |panic |
对于nil通道的情况,也并非完全遵循上表,有1个特殊场景:当nil的通道在select的某个case中时,这个case会阻塞,但不会造成死锁。
常用操作
1. 使用for range读channel
使用for-range读取channel,这样既安全又便利,当channel关闭时,for循环会自动退出,无需主动监测channel是否关闭,可以防止读取已经关闭的channel,造成读到数据为通道所存储的数据类型的零值。
for x := range ch{
fmt.Println(x)
}
2. 使用v,ok := <-ch + select操作判断channel是否关闭
v,ok := <-ch + select操作判断channel是否关闭
ok的结果和含义:
- true:读到通道数据,不确定是否关闭,可能channel还有保存的数据,但channel已关闭。
- false:通道关闭,无数据读到。
从关闭的channel读值读到是channel所传递数据类型的零值,这个零值有可能是发送者发送的,也可能是channel关闭了。
_, ok := <-ch 与 select 配合使用的,当ok为false时,代表了channel已经close。
下面解释原因, _,ok := <-ch 对应的函数是
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool)
入参 block 含义是当前 goroutine 是否可阻塞,当 block 为 false 代表的是 select 操作,不可阻塞当前 goroutine 的在 channel 操作,否则是普通操作(即_, ok不在select中)。返回值 selected 代表当前操作是否成功,主要为select服务,返回received代表是否从channel读到有效值。它有3种返回值情况:
- block为false,即执行select时,如果channel为空,返回(false,false),代表select操作失败,没接收到值。
- 否则,如果channel已经关闭,并且没有数据,ep即接收数据的变量设置为零值,返回(true,false),代表select操作成功,但channel已关闭,没读到有效值。
- 否则,其他读到有效数据的情况,返回(true,ture)。
我们考虑_, ok := <-ch和select结合使用的情况。
情况1:当chanrecv返回(false,false)时,本质是select操作失败了,所以相关的case会阻塞,不会执行,比如下面的代码:
func main() {
ch := make(chan int)
select {
case v, ok := <-ch:
fmt.Printf("v: %v, ok: %v\n", v, ok)
default:
fmt.Println("nothing")
}
}
// 结果:
// nothing
情况2:下面的结果会是零值和false:
func main() {
ch := make(chan int)
// 增加关闭
close(ch)
select {
case v, ok := <-ch:
fmt.Printf("v: %v, ok: %v\n", v, ok)
}
}
// v: 0, ok: false
情况3的received为true,即_, ok中的ok为true,不做讨论了,只讨论ok为false的情况。
最后ok为false的时候,只有情况2,此时channel必然已经关闭,我们便可以在select中用ok判断channel是否已经关闭。
下面例子展示了,向channel写数据然后关闭,依然可以从已关闭channel读到有效数据,但channel关闭且没有数据时,读不到有效数据,ok为false,可以确定当前channel已关闭。
// demo_select6.go
func main() {
ch := make(chan int, 1)
// 发送1个数据关闭channel
ch <- 1
close(ch)
print("close channel\n")
// 不停读数据直到channel没有有效数据
for {
select {
case v, ok := <-ch:
print("v: ", v, ", ok:", ok, "\n")
if !ok {
print("channel is close\n")
return
}
default:
print("nothing\n")
}
}
}
// 结果
// close channel
// v: 1, ok:true
// v: 0, ok:false
// channel is close
3. 使用select处理多个channel
需要对多个通道进行同时处理,但只处理最先发生的channel时
select可以同时监控多个通道的情况,只处理未阻塞的case。当通道为nil时,对应的case永远为阻塞,无论读写。特殊关注:普通情况下,对nil的通道写操作是要panic的。
// 分配job时,如果收到关闭的通知则退出,不分配job
func (h *Handler) handle(job *Job) {
select {
case h.jobCh<-job:
return
case <-h.stopCh:
return
}
}
4. 使用channel的声明控制读写权限
协程对某个通道只读或只写时:
- 使代码更易读、更易维护,
- 防止只读协程对通道进行写数据,但通道已关闭,造成panic。
如果协程对某个channel只有写操作,则这个channel声明为只写。
如果协程对某个channel只有读操作,则这个channe声明为只读。
// 只有generator进行对outCh进行写操作,返回声明
// <-chan int,可以防止其他协程乱用此通道,造成隐藏bug
func generator(int n) <-chan int {
outCh := make(chan int)
go func(){
for i:=0;i<n;i++{
outCh<-i
}
}()
return outCh
}
// consumer只读inCh的数据,声明为<-chan int
// 可以防止它向inCh写数据
func consumer(inCh <-chan int) {
for x := range inCh {
fmt.Println(x)
}
}
5. 使用缓冲channel增强并发
有缓冲通道可供多个协程同时处理,在一定程度可提高并发性。
// 无缓冲
ch1 := make(chan int)
ch2 := make(chan int, 0)
// 有缓冲
ch3 := make(chan int, 1)
使用5个do协程同时处理输入数据
func test() {
inCh := generator(100)
outCh := make(chan int, 10)
for i := 0; i < 5; i++ {
go do(inCh, outCh)
}
for r := range outCh {
fmt.Println(r)
}
}
func do(inCh <-chan int, outCh chan<- int) {
for v := range inCh {
outCh <- v * v
}
}
6. 为操作加上超时
需要超时控制的操作, 使用select和time.After,看操作和定时器哪个先返回,处理先完成的,就达到了超时控制的效果
func doWithTimeOut(timeout time.Duration) (int, error) {
select {
case ret := <-do():
return ret, nil
case <-time.After(timeout):
return 0, errors.New("timeout")
}
}
func do() <-chan int {
outCh := make(chan int)
go func() {
// do work
}()
return outCh
}
7. 使用time实现channel无阻塞读写
并不希望在channel的读写上浪费时间, 是为操作加上超时的扩展,这里的操作是channel的读或写
func unBlockRead(ch chan int) (x int, err error) {
select {
case x = <-ch:
return x, nil
case <-time.After(time.Microsecond):
return 0, errors.New("read time out")
}
}
func unBlockWrite(ch chan int, x int) (err error) {
select {
case ch <- x:
return nil
case <-time.After(time.Microsecond):
return errors.New("read time out")
}
}
注:time.After等待可以替换为default,则是channel阻塞时,立即返回的效果
8. 使用close(ch)关闭所有下游协程
退出时,显示通知所有协程退出, 所有读ch的协程都会收到close(ch)的信号
func (h *Handler) Stop() {
close(h.stopCh)
// 可以使用WaitGroup等待所有协程退出
}
// 收到停止后,不再处理请求
func (h *Handler) loop() error {
for {
select {
case req := <-h.reqCh:
go handle(req)
case <-h.stopCh:
return
}
}
}
9. 使用chan struct{}作为信号channel
使用channel传递信号,而不是传递数据时, 传递空struct, 因为空 struct 不占用内存
// 上例中的Handler.stopCh就是一个例子,stopCh并不需要传递任何数据
// 只是要给所有协程发送退出的信号
type Handler struct {
stopCh chan struct{}
reqCh chan *Request
}
10. 使用channel传递结构体的指针而非结构体
使用channel传递结构体数据时, channel本质上传递的是数据的拷贝,拷贝的数据越小传输效率越高,传递结构体指针,比传递结构体更高效
reqCh chan *Request
// 好过
reqCh chan Request
11. 使用channel传递channel
channel可以用来传递变量,channel自身也是变量,可以传递自己。
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
func main() {
reqs := []int{1, 2, 3, 4, 5, 6, 7, 8, 9}
// 存放结果的channel的channel
outs := make(chan chan int, len(reqs))
var wg sync.WaitGroup
wg.Add(len(reqs))
for _, x := range reqs {
o := handle(&wg, x)
outs <- o
}
go func() {
wg.Wait()
close(outs)
}()
// 读取结果,结果有序
for o := range outs {
fmt.Println(<-o)
}
}
// handle 处理请求,耗时随机模拟
func handle(wg *sync.WaitGroup, a int) chan int {
out := make(chan int)
go func() {
time.Sleep(time.Duration(rand.Intn(3)) * time.Second)
out <- a
wg.Done()
}()
return out
}
协程池
oroutine是非常轻量的,不会暂用太多资源,基本上有多少任务,我们可以开多少goroutine去处理。但有时候,我们还是想控制一下。
比如,我们有A、B两类工作,不想把太多资源花费在B类务上,而是花在A类任务上。对于A,我们可以来1个开一个goroutine去处理,对于B,我们可以使用一个协程池,协程池里有5个线程去处理B类任务,这样B消耗的资源就不会太多。
控制使用资源并不是协程池目的,使用协程池是为了更好并发、程序鲁棒性、容错性等。
协程池指的是预先分配固定数量的goroutine处理相同的任务,和线程池是类似的,不同点是协程池中处理任务的是协程,线程池中处理任务的是线程。
最简单的协程池模型
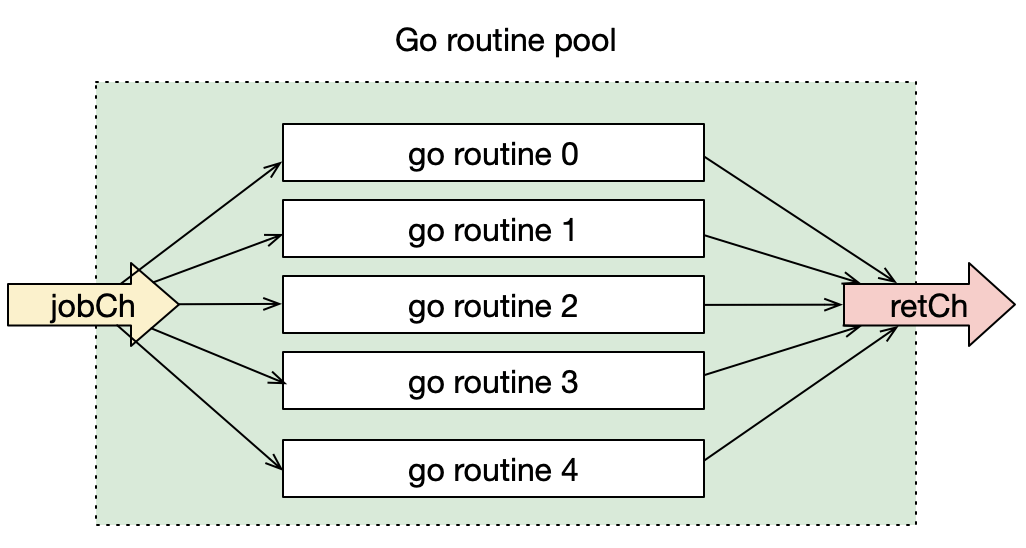
上面这个图展示了最简单的协程池的样子。先把协程池作为一个整体看,它使用2个通道,左边的jobCh是任务通道,任务会从这个通道中流进来,右边的retCh是结果通道,协程池处理任务后得到的结果会写入这个通道。至于协程池中,有多少协程处理任务,这是外部不关心的。
看一下协程池内部,图中画了5个goroutine,实际goroutine的数量是依具体情况而定的。协程池内每个协程都从jobCh读任务、处理任务,然后将结果写入到retCh。
func workerPool(n int, jobCh <-chan int, retCh chan<- string) {
for i := 0; i < n; i++ {
go worker(i, jobCh, retCh)
}
}
func worker(id int, jobCh <-chan int, retCh chan<- string) {
cnt := 0
for job := range jobCh {
cnt++
ret := fmt.Sprintf("worker %d processed job: %d, it's the %dth processed by me.", id, job, cnt)
retCh <- ret
}
}
workerPool()会创建1个简单的协程池,协程的数量可以通入参数n执行,并且还指定了jobCh和retCh两个参数。
worker()是协程池中的协程,入参分布是它的ID、job通道和结果通道。使用for-range从jobCh读取任务,直到jobCh关闭,然后一个最简单的任务:生成1个字符串,证明自己处理了某个任务,并把字符串作为结果写入retCh。
func main() {
jobCh := genJob(10000)
retCh := make(chan string, 10000)
workerPool(5, jobCh, retCh)
time.Sleep(time.Second)
close(retCh)
for ret := range retCh {
fmt.Println(ret)
}
}
func genJob(n int) <-chan int {
jobCh := make(chan int, 200)
go func() {
for i := 0; i < n; i++ {
jobCh <- i
}
close(jobCh)
}()
return jobCh
}
main()启动genJob获取存放任务的通道jobCh,然后创建retCh,它的缓存空间是200,并使用workerPool启动一个有5个协程的协程池。1s之后,关闭retCh,然后开始从retCh中读取协程池处理结果,并打印。
genJob启动一个协程,并生产n个任务,写入到jobCh。
示例运行结果如下,一共产生了10个任务,显示大部分工作都被worker 2这个协程抢走了,如果我们设置的任务成千上万,协程池长时间处理任务,每个协程处理的工作数量就会均衡很多。
➜ go run simple_goroutine_pool.go
worker 2 processed job: 4
worker 2 processed job: 5
worker 2 processed job: 6
worker 2 processed job: 7
worker 2 processed job: 8
worker 2 processed job: 9
worker 0 processed job: 1
worker 3 processed job: 2
worker 4 processed job: 3
worker 1 processed job: 0
回顾
最简单的协程池模型就这么简单,再回头看下协程池及周边由哪些组成:
- 协程池内的一定数量的协程。
- 任务队列,即jobCh,存在协程池不能立即处理任务的情况,所以需要队列把任务先暂存。
- 结果队列,即retCh,同上,协程池处理任务的结果,也存在不能被下游立刻提取的情况,要暂时保存。
程池最简要(核心)的逻辑是所有协程从任务读取任务,处理后把结果存放到结果队列。
并发协程的优雅退出
goroutine作为Golang并发的核心,我们不仅要关注它们的创建和管理,当然还要关注如何合理的退出这些协程,不(合理)退出不然可能会造成阻塞、panic、程序行为异常、数据结果不正确等问题。
goroutine在退出方面,不像线程和进程,不能通过某种手段强制关闭它们,只能等待goroutine主动退出。但也无需为退出、关闭goroutine而烦恼,下面就介绍3种优雅退出goroutine的方法,只要采用这种最佳实践去设计,基本上就可以确保goroutine退出上不会有问题,尽情享用。
1:使用for-range退出
for-range是使用频率很高的结构,常用它来遍历数据,range能够感知channel的关闭,当channel被发送数据的协程关闭时,range就会结束,接着退出for循环。
它在并发中的使用场景是:当协程只从1个channel读取数据,然后进行处理,处理后协程退出。下面这个示例程序,当in通道被关闭时,协程可自动退出
go func(in <-chan int) {
// Using for-range to exit goroutine
// range has the ability to detect the close/end of a channel
for x := range in {
fmt.Printf("Process %d\n", x)
}
}(inCh)
2:使用 ,ok 退出
for-select也是使用频率很高的结构,select提供了多路复用的能力,所以for-select可以让函数具有持续多路处理多个channel的能力。但select没有感知channel的关闭,这引出了2个问题:
- 继续在关闭的通道上读,会读到通道传输数据类型的零值,如果是指针类型,读到nil,继续处理还会产生nil。
- 继续在关闭的通道上写,将会panic。
问题2可以这样解决,通道只由发送方关闭,接收方不可关闭,即某个写通道只由使用该select的协程关闭,select中就不存在继续在关闭的通道上写数据的问题
问题1可以使用,ok来检测通道的关闭,使用情况有2种。
如果某个通道关闭后,需要退出协程,直接return即可
示例代码中,该协程需要从in通道读数据,还需要定时打印已经处理的数量,有2件事要做,所有不能使用for-range,需要使用for-select,当in关闭时,ok=false,我们直接返回。
go func() {
// in for-select using ok to exit goroutine
for {
select {
case x, ok := <-in:
if !ok {
return
}
fmt.Printf("Process %d\n", x)
processedCnt++
case <-t.C:
fmt.Printf("Working, processedCnt = %d\n", processedCnt)
}
}
}()
某个通道关闭了,不再处理该通道,而是继续处理其他case
如果某个通道关闭了,不再处理该通道,而是继续处理其他case,退出是等待所有的可读通道关闭。我们需要使用select的一个特征:select不会在nil的通道上进行等待。这种情况,把只读通道设置为nil即可解决。
go func() {
// in for-select using ok to exit goroutine
for {
select {
case x, ok := <-in1:
if !ok {
in1 = nil
}
// Process
case y, ok := <-in2:
if !ok {
in2 = nil
}
// Process
case <-t.C:
fmt.Printf("Working, processedCnt = %d\n", processedCnt)
}
// If both in channel are closed, goroutine exit
if in1 == nil && in2 == nil {
return
}
}
}()
3:使用退出通道退出
使用,ok来退出使用for-select协程,解决是当读入数据的通道关闭时,没数据读时程序的正常结束。想想下面这2种场景,,ok还能适用吗?
- 接收的协程要退出了,如果它直接退出,不告知发送协程,发送协程将阻塞。
- 启动了一个工作协程处理数据,如何通知它退出?
使用一个专门的通道,发送退出的信号,可以解决这类问题。以第2个场景为例,协程入参包含一个停止通道stopCh,当stopCh被关闭,case <-stopCh会执行,直接返回即可。
当我启动了100个worker时,只要main()执行关闭stopCh,每一个worker都会都到信号,进而关闭。如果main()向stopCh发送100个数据,这种就低效了。
func worker(stopCh <-chan struct{}) {
go func() {
defer fmt.Println("worker exit")
// Using stop channel explicit exit
for {
select {
case <-stopCh:
fmt.Println("Recv stop signal")
return
case <-t.C:
fmt.Println("Working .")
}
}
}()
return
}
最佳实践回顾
- 发送协程主动关闭通道,接收协程不关闭通道。技巧:把接收方的通道入参声明为只读,如果接收协程关闭只读协程,编译时就会报错。
- 协程处理1个通道,并且是读时,协程优先使用for-range,因为range可以关闭通道的关闭自动退出协程。
,ok可以处理多个读通道关闭,需要关闭当前使用for-select的协程。- 显式关闭通道stopCh可以处理主动通知协程退出的场景。
Golang并发的次优选择:sync包
我们都知道Golang并发优选channel,但channel不是万能的,Golang为我们提供了另一种选择:sync。
sync包提供了:
- Mutex:互斥锁
- RWMutex:读写锁
- WaitGroup:等待组
- Once:单次执行
- Cond:信号量
- Pool:临时对象池
- Map:自带锁的map
互斥锁
常做并发工作的朋友对互斥锁应该不陌生,Golang里互斥锁需要确保的是某段时间内,不能有多个协程同时访问一段代码(临界区)。
互斥锁被称为Mutex,它有2个函数,Lock()和Unlock()分别是获取锁和释放锁,如下:
type Mutex
func (m *Mutex) Lock(){}
func (m *Mutex) Unlock(){}
Mutex的初始值为未锁的状态,并且Mutex通常作为结构体的匿名成员存在。
单例
package main
import (
"fmt"
"sync"
"time"
)
type UserInfo struct {
Name string
}
var (
lock sync.Mutex
instance *UserInfo
)
func getInstance() (*UserInfo, error) {
lock.Lock()
defer lock.Unlock()
if instance == nil {
if instance == nil {
instance = &UserInfo{
Name: "fan",
}
}
}
return instance, nil
}
func main() {
for i := 0; i < 10; i++ {
go func() {
userInfo, err := getInstance()
if err != nil {
fmt.Println(err)
}
fmt.Println(*userInfo)
}()
}
time.Sleep(2 * time.Second)
}
读写锁
读写锁是互斥锁的特殊变种,如果是计算机基本知识扎实的朋友会知道,读写锁来自于读者和写者的问题,这个问题就不介绍了,介绍下我们的重点:读写锁要达到的效果是同一时间可以允许多个协程读数据,但只能有且只有1个协程写数据。
也就是说,读和写是互斥的,写和写也是互斥的,但读和读并不互斥。具体讲,当有至少1个协程读时,如果需要进行写,就必须等待所有已经在读的协程结束读操作,写操作的协程才获得锁进行写数据。当写数据的协程已经在进行时,有其他协程需要进行读或者写,就必须等待已经在写的协程结束写操作。
读写锁是RWMutex,它有5个函数,它需要为读操作和写操作分别提供锁操作,这样就4个了:
- Lock()和Unlock()是给写操作用的。
- RLock()和RUnlock()是给读操作用的。
RLocker()能获取读锁,然后传递给其他协程使用。使用较少。
type RWMutex
func (rw *RWMutex) Lock(){}
func (rw *RWMutex) RLock(){}
func (rw *RWMutex) RLocker() Locker{}
func (rw *RWMutex) RUnlock(){}
func (rw *RWMutex) Unlock(){}
读写锁实例:
package main
import (
"fmt"
"strconv"
"sync"
"time"
)
var (
wg sync.WaitGroup
lock sync.RWMutex
data int64
)
func read() {
defer lock.RUnlock()
// defer wg.Done()
lock.RLock()
time.Sleep(time.Millisecond) //模拟读取耗时
fmt.Println(data)
}
func write() {
defer lock.Unlock()
defer wg.Done()
lock.Lock()
data++
}
func main() {
start := time.Now()
wg.Add(1)
go func() {
for i := 0; i < 10000; i++ {
wg.Add(1)
go write()
}
wg.Done()
}()
wg.Add(1)
go func() {
count := 0
for range time.Tick(time.Millisecond) {
go read()
count++
if count == 1000 {
break
}
}
wg.Done()
}()
wg.Wait()
fmt.Println("最终结果:" + strconv.Itoa(int(data)))
d := time.Since(start)
fmt.Println(d)
}
等待组
互斥锁和读写锁大多数人可能比较熟悉,而对等待组(WaitGroup)可能就不那么熟悉,甚至有点陌生,所以先来介绍下等待组在现实中的例子。
type WaitGroup
func (wg *WaitGroup) Add(delta int){}
func (wg *WaitGroup) Done(){}
func (wg *WaitGroup) Wait(){}
单次执行
在程序执行前,通常需要做一些初始化操作,但触发初始化操作的地方是有多处的,但是这个初始化又只能执行1次,怎么办呢?
使用Once就能轻松解决,once对象是用来存放1个无入参无返回值的函数,once可以确保这个函数只被执行1次。
type Once
func (o *Once) Do(f func()){}
官方示例
package main
import (
"fmt"
"sync"
)
func main() {
var once sync.Once
onceBody := func() {
fmt.Println("Only once")
}
done := make(chan bool)
for i := 0; i < 10; i++ {
go func() {
once.Do(onceBody)
done <- true
}()
}
for i := 0; i < 10; i++ {
<-done
}
}
执行结果
go run .\main.go
Only once