
网络相关
K8s中的external-traffic-policy
什么是external-traffic-policy
在k8s的Service对象(申明一条访问通道)中,有一个“externalTrafficPolicy”字段可以设置。有2个值可以设置:Cluster或者Local。
- 1)Cluster表示:流量可以转发到其他节点上的Pod。
- 2)Local表示:流量只发给本机的Pod。
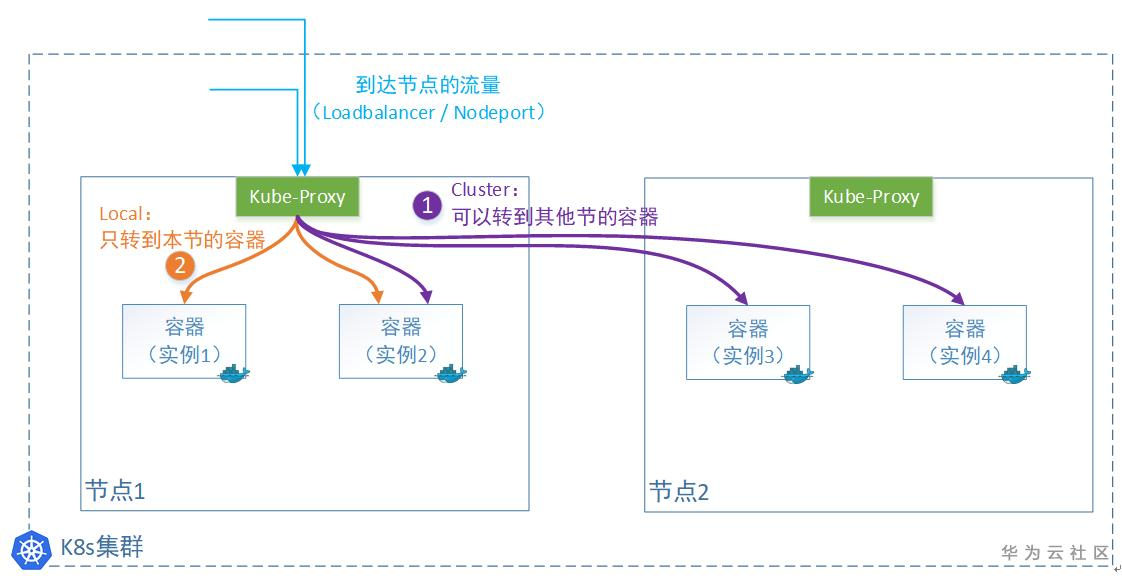
这2种模式有什么区别
选择(1)Cluster
注:这个是默认模式,Kube-proxy不管容器实例在哪,公平转发。
Kube-proxy转发时会替换掉报文的源IP。即:容器收的报文,源IP地址,已经被替换为上一个转发节点的了。
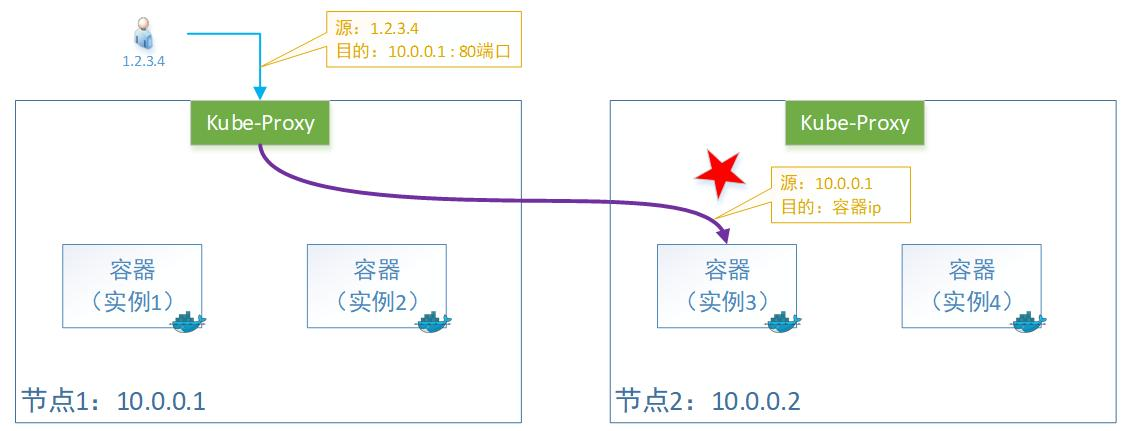
原因是Kube-proxy在做转发的时候,会做一次SNAT (source network address translation),所以源IP变成了节点1的IP地址。
注意: snat确保回去的报文可以原路返回,不然回去的路径不一样,客户会认为非法报文的。(我发给张三的,怎么李四给我回应?丢弃!)
这种模式好处是负载均衡会比较好,因为无论容器实例怎么分布在多个节点上,它都会转发过去。当然,由于多了一次转发,性能会损失一丢丢。
选择(2)Local
这种情况下,只转发给本机的容器,绝不跨节点转发。
Kube-proxy转发时会保留源IP。即:容器收到的报文,看到源IP地址还是用户的。
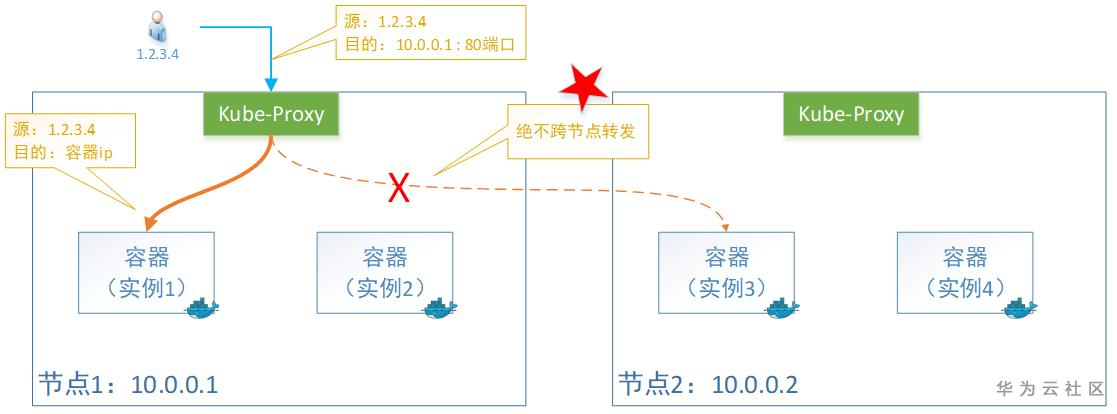
缺点是负载均衡可能不是很好,因为一旦容器实例分布在多个节点上,它只转发给本机,不跨节点转发流量。当然,少了一次转发,性能会相对好一丢丢。
注:这种模式下的Service类型只能为外部流量,即:LoadBalancer 或者 NodePort 两种,否则会报错。
同时,由于本机不会跨节点转发报文,所以要想所有节点上的容器有负载均衡,就需要上一级的Loadbalancer来做了。
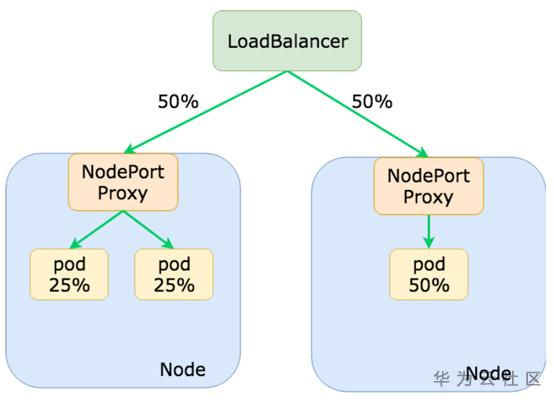
想要解决负载不均衡的问题:可以给Pod容器设置反亲和,让这些容器平均的分布在各个节点上(不要聚在一起)。
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- my-app
topologyKey: kubernetes.io/hostname
HostPort
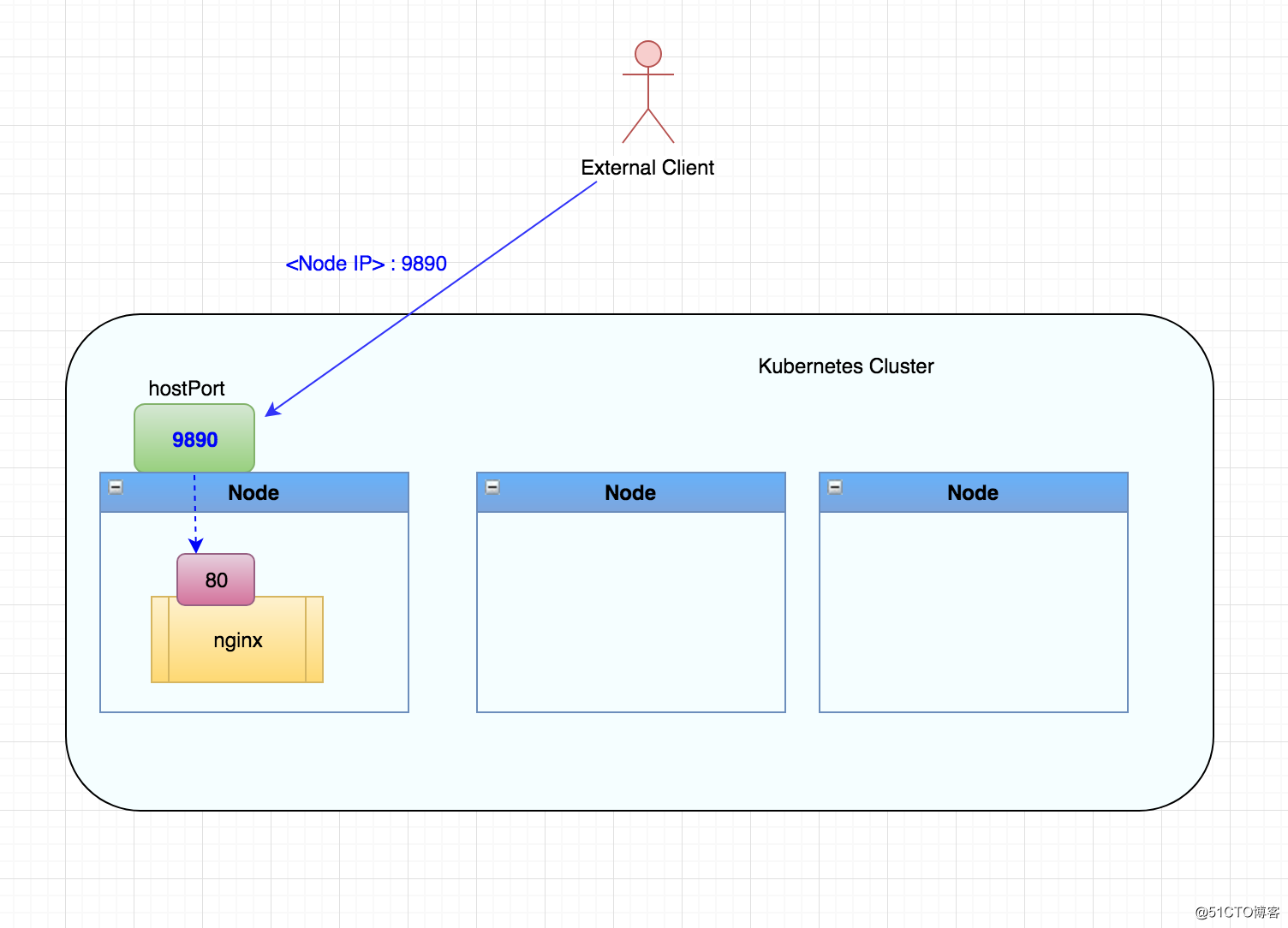
如下是我们的Nginx工作负载的Kubernetes YAML如何指定'ports'部分下的HostPort设置:
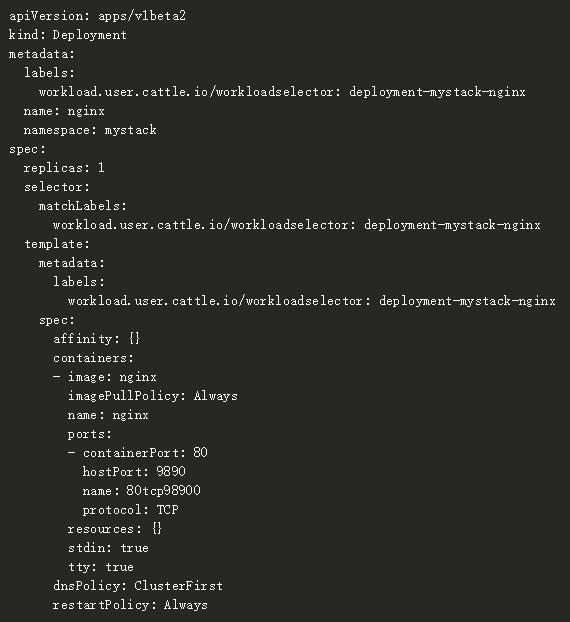
HostPort的优点:
- 通过HostPort设置,您可以请求暴露主机上的任何可用端口。
- 配置很简单,HostPort设置直接放在Kubernetes pod规范中。与NodePort相比,不需要创建其他对象来暴露应用程序。
HostPort的缺点:
- 使用HostPort会限制pod的调度,因为只有那些具有指定端口可用的主机才能用于部署。
- 如果工作负载的规模大于Kubernetes集群中的节点数,部署会失败。
- 指定了相同HostPort的任何两个工作负载,都将无法部署在同一节点上。
- 如果运行pod的主机出现故障,Kubernetes将不得不将pod重新安排到不同的节点。如此一来,可以访问工作负载的IP地址将发生变化,从而破坏应用程序的外部客户端。当pod重新启动时也会发生同样的事情,Kubernetes会在不同的节点上重新安排它们。
集群管理
worker 节点使用 kubectl
将 master 节点 /etc/kubernetes/admin.conf文件拷贝到 worker 节点相同目录下,然后配置环境变量:
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile # 立即生效
建立临时 pod 用以检测网络
busybox 网络检测 pod
apiVersion: v1
kind: Pod
metadata:
name: busybox1
namespace: default
spec:
nodeName: master
containers:
- name: busybox
image: busybox:1.28.4
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
使用 calicoctl 命令访问 etcd 获取结果
vim /etc/calico/calicoctl.cfg
apiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
etcdEndpoints: https://etcd1:2379,https://etcd2:2379,https://etcd3:2379
etcdKeyFile: /etc/calico/key.pem
etcdCertFile: /etc/calico/cert.pem
etcdCACertFile: /etc/calico/ca.pem
测试https网页忽略证书检查
curl 'https://x.x.x.x/get_ips' -k
wget 'https://x.x.x.x/get_ips' --no-check-certificate
清空 var 目录造成 ssh 无法登录
CentOS7上的SSH无法启动,报告/var/empty/sshd must be owned by root and not group or world-writable
chown -R root.root /var/empty/sshd
chmod 744 /var/empty/sshd
tcpdump 抓取数据包
tcpdump 抓取icmp数据包
tcpdump -n -i eth1 icmp
tcpdump -n -i ethname -vv port 22 && tcp
tcpdump -n -i ethname -vv port 8080 && udp -w log.pcap
tcpdump -i calicba2f87f6bb -e -nn
容器内抓包
问题定位技巧:容器内抓包
在使用 kubernetes 跑应用的时候,可能会遇到一些网络问题,比较常见的是服务端无响应(超时)或回包内容不正常,如果没找出各种配置上有问题,这时我们需要确认数据包到底有没有最终被路由到容器里,或者报文到达容器的内容和出容器的内容符不符合预期,通过分析报文可以进一步缩小问题范围。那么如何在容器内抓包呢?本文提供实用的脚本一键进入容器网络命名空间(netns),使用宿主机上的tcpdump进行抓包。
kubectl get pod -o wide
kubectl describe pods -n crm-sprod sc-facade-b5cf7d9dc-jbsp4 | grep docker 获取container id
进入pod所在服务器
docker inspect -f {} 2eb97134de41d974b22d7b21e3fe6cec45debed7c4a231c1a1a4d270df567505
获取到pid
进入pod的network namespace
nsenter -n --target pid
这时已经进入 pod 的 netns,可以执行宿主机上的 ip a 或 ifconfig 来查看容器的网卡,执行 netstat -tunlp 查看当前容器监听了哪些端口,再通过 tcpdump 抓包:
tcpdump -i eth0 -w test.pcap port 80
然后拷贝到本地用wireshark分析
存储相关
k8s之configmap和secret
configmap:把配置文件放在配置中心上,然后多个pod读取配置中心的配置文件,不过,configmap中的配置信息都是明文的,所以不安全;
secret:功能和configmap一样,只不过配置中心存储的配置文件不是明文的.configmap和secret也是专属于某个名称空间的.
容器热更新
当 ConfigMap 作为 volume 进行挂载时,它的内容是会更新的。
更新操作由 kubelet 的 Pod 同步循环触发。每次进行 Pod 同步时(默认每 10 秒一次),Kubelet 都会将 Pod 的所有 ConfigMap volume 标记为”需要重新挂载(RequireRemount)“,而 kubelet 中的 volume 控制循环会发现这些需要重新挂载的 volume,去执行一次挂载操作。
在 ConfigMap 的重新挂载过程中,kubelet 会先比较远端的 ConfigMap 与 volume 中的 ConfigMap 是否一致,再做更新。要注意,”拿远端的 ConfigMap” 这个操作可能是有缓存的,因此拿到的并不一定是最新版本。
由此,我们可以知道,ConfigMap 作为 volume 确实是会自动更新的,但是它的更新存在延时,最多的可能延迟时间是:
Pod 同步间隔(默认10秒) + ConfigMap 本地缓存的 TTL
kubelet 上 ConfigMap 的获取是否带缓存由配置中的 ConfigMapAndSecretChangeDetectionStrategy 决定
注意,假如使用了 subPath 将 ConfigMap 中的某个文件单独挂载到其它目录下,那这个文件是无法热更新的(这是 ConfigMap 的挂载逻辑决定的)
当然,配置文件更新完不代表业务逻辑就更新了,我们还需要通知应用重新读取配置进行业务逻辑上的更新。比如对于 Nginx,就需要发送一个 SIGHUP 信号量。
每次都手动让 Nginx 读取更新后的配置文件,很繁琐。我们可以使用 Reloader 自动让 pod 滚动更新。
Reloader
https://github.com/stakater/Reloader
部署
kubectl apply -f https://raw.githubusercontent.com/stakater/Reloader/master/deployments/kubernetes/reloader.yaml
默认将监听所有 namespace 下 secret 和 configmap 的变化。
使用
在 deployment 中添加注解
kind: Deployment
metadata:
annotations:
reloader.stakater.com/auto: "true"
spec:
template: metadata:
或者直接执行命令:
kubectl patch deployments.apps my-app -p '{"metadata": {"annotations": {"reloader.stakater.com/auto": "true"}}}'
然后我们更改configMap清单,重新apply过后,我们可以看到pod会删除重启
处理容器数据磁盘被写满
容器数据磁盘被写满造成的危害:
- 不能创建 Pod (一直 ContainerCreating)
- 不能删除 Pod (一直 Terminating)
- 无法 exec 到容器
判断是否被写满:
容器数据目录大多会单独挂数据盘,路径一般是 /var/lib/docker,也可能是 /data/docker 或 /opt/docker
可通过 docker info 确定:
$ docker info
...
Docker Root Dir: /var/lib/docker
...
如果没有单独挂数据盘,则会使用系统盘存储。判断是否被写满:
$ df
Filesystem 1K-blocks Used Available Use% Mounted on
...
/dev/vda1 51474044 4619112 44233548 10% /
...
/dev/vdb 20511356 20511356 0 100% /var/lib/docker
解决方法
先恢复业务,清理磁盘空间
重启 dockerd (清理容器日志输出和可写层文件)
重启前需要稍微腾出一点空间,不然重启 docker 会失败,可以手动删除一些docker的log文件或可写层文件,通常删除log:
$ cd /var/lib/docker/containers
$ du -sh * # 找到比较大的目录
$ cd dda02c9a7491fa797ab730c1568ba06cba74cecd4e4a82e9d90d00fa11de743c
$ cat /dev/null > dda02c9a7491fa797ab730c1568ba06cba74cecd4e4a82e9d90d00fa11de743c-json.log.9 # 删除log文件
注意: 使用 cat /dev/null > 方式删除而不用 rm,因为用 rm 删除的文件,docker 进程可能不会释放文件,空间也就不会释放;log 的后缀数字越大表示越久远,先删除旧日志。
将该 node 标记不可调度,并将其已有的 pod 驱逐到其它节点,这样重启dockerd就会让该节点的pod对应的容器删掉,容器相关的日志(标准输出)与容器内产生的数据文件(可写层)也会被清理:
kubectl drain 10.179.80.31
重启 dockerd:
systemctl restart dockerd
取消不可调度的标记:
kubectl uncordon 10.179.80.31
定位根因,彻底解决
问题定位方法见附录,这里列举根因对应的解决方法:
日志输出量大导致磁盘写满:
减少日志输出
增大磁盘空间
减小单机可调度的pod数量
可写层量大导致磁盘写满: 优化程序逻辑,不写文件到容器内或控制写入文件的大小与数量
镜像占用空间大导致磁盘写满:
增大磁盘空间
删除不需要的镜像
附录
查看docker的磁盘空间占用情况
$ docker system df -v
Images space usage:
REPOSITORY TAG IMAGE ID CREATED SIZE SHARED SIZE UNIQUE SIZE CONTAINERS
<none> <none> 0b3c861abf6d 28 hours ago 1.148GB 1.059GB 88.35MB 0
<none> <none> 03b2a5a29f4d 28 hours ago 1.148GB 1.059GB 88.35MB 0
<none> <none> 2c2db87bf715 28 hours ago 1.148GB 1.059GB 88.35MB 0
<none> <none> b13fca81aa1b 29 hours ago 1.148GB 1.059GB 88.35MB 0
<none> <none> c2f2028c63bc 29 hours ago 1.148GB 1.059GB 88.35MB 0
<none> <none> 91d3dc864ada 29 hours ago 1.148GB 1.059GB 88.35MB 0
<none> <none> 8129c875763a 29 hours ago 1.148GB 1.059GB 88.35MB 0
<none> <none> 601b391d98ed 29 hours ago 1.148GB 1.059GB 88.35MB 0
<none> <none> d2480f276ae5 29 hours ago 1.148GB 1.059GB 88.35MB 0
172.21.0.8/devops/gin-demo latest 51b86726859e 29 hours ago 6.399MB 0B 6.399MB 0
<none> <none> 161ccfcb3145 29 hours ago 1.148GB 1.059GB 88.35MB 0
<none> <none> 5b66508631da 30 hours ago 1.148GB 1.059GB 88.35MB 0
golang latest 8735189b1527 7 days ago 940.6MB 940.6MB 0B 0
172.21.0.8/devops/nginx latest dd34e67e3371 8 days ago 133.2MB 0B 133.2MB 0
goharbor/harbor-exporter v2.3.1 719fd825651e 5 weeks ago 81.02MB 36.55MB 44.47MB 0
goharbor/chartmuseum-photon v2.3.1 3aba4510af16 5 weeks ago 178.2MB 36.55MB 141.6MB 0
goharbor/redis-photon v2.3.1 4a0d49a4ece0 5 weeks ago 190.8MB 36.55MB 154.3MB 1
goharbor/trivy-adapter-photon v2.3.1 a285847f857a 5 weeks ago 164MB 36.55MB 127.4MB 0
goharbor/notary-server-photon v2.3.1 87a2dbfd122e 5 weeks ago 109.7MB 36.55MB 73.13MB 0
goharbor/notary-signer-photon v2.3.1 7e29ff33ec85 5 weeks ago 106.9MB 36.55MB 70.32MB 0
goharbor/harbor-registryctl v2.3.1 91e798004920 5 weeks ago 132MB 36.55MB 95.48MB 1
goharbor/registry-photon v2.3.1 972ce19b1882 5 weeks ago 81.24MB 36.55MB 44.69MB 1
goharbor/nginx-photon v2.3.1 3b3ede1db494 5 weeks ago 44.34MB 36.55MB 7.784MB 1
goharbor/harbor-log v2.3.1 40a54594fe22 5 weeks ago 194.4MB 36.55MB 157.8MB 1
goharbor/harbor-jobservice v2.3.1 d6e174ae0a00 5 weeks ago 170.7MB 36.55MB 134.1MB 1
goharbor/harbor-core v2.3.1 f05acc3947d6 5 weeks ago 157.5MB 36.55MB 121MB 1
goharbor/harbor-portal v2.3.1 4a15c5622fda 5 weeks ago 57.56MB 36.55MB 21.01MB 1
goharbor/harbor-db v2.3.1 b16a9c81ef03 5 weeks ago 262.8MB 36.55MB 226.2MB 1
goharbor/prepare v2.3.1 4ce629d59c20 5 weeks ago 287.7MB 36.55MB 251.1MB 0
ceph/ceph-grafana 6.7.4 3b1077a63311 5 weeks ago 486.2MB 0B 486.2MB 1
ceph/ceph v16 6933c2a0b7dd 6 weeks ago 1.201GB 0B 1.201GB 5
kubernetesui/dashboard v2.3.1 e1482a24335a 2 months ago 220MB 0B 220MB 0
quay.io/coreos/flannel v0.14.0 8522d622299c 3 months ago 67.93MB 0B 67.93MB 0
quay.io/prometheus/node-exporter v1.1.2 c19ae228f069 5 months ago 25.97MB 0B 25.97MB 0
quay.io/brancz/kube-rbac-proxy v0.8.0 ad393d6a4d1b 9 months ago 48.95MB 0B 48.95MB 0
kubernetesui/metrics-scraper v1.0.6 48d79e554db6 10 months ago 34.55MB 0B 34.55MB 0
prom/prometheus v2.18.1 de242295e225 15 months ago 140MB 2.648MB 137.3MB 1
prom/alertmanager v0.20.0 0881eb8f169f 20 months ago 52.08MB 2.648MB 49.43MB 0
prom/node-exporter v0.18.1 e5a616e4b9cf 2 years ago 22.93MB 0B 22.93MB 1
Containers space usage:
CONTAINER ID IMAGE COMMAND LOCAL VOLUMES SIZE CREATED STATUS NAMES
f77fe681058e ceph/ceph "/usr/bin/ceph-osd -…" 0 0B 37 hours ago Up 37 hours ceph-aeef8b18-f27e-11eb-8817-525400d203e5-osd.1
8a8e08d49aa8 ceph/ceph "/usr/bin/ceph-osd -…" 0 0B 37 hours ago Up 37 hours ceph-aeef8b18-f27e-11eb-8817-525400d203e5-osd.0
3318900b84ed ceph/ceph:v16 "/usr/bin/ceph-mgr -…" 0 12.1kB 37 hours ago Up 37 hours ceph-aeef8b18-f27e-11eb-8817-525400d203e5-mgr.server1.csdcgh
9e241e877dff ceph/ceph "/usr/bin/ceph-crash…" 0 0B 37 hours ago Up 37 hours ceph-aeef8b18-f27e-11eb-8817-525400d203e5-crash.server1
ed5945eefdc1 ceph/ceph:v16 "/usr/bin/ceph-mon -…" 0 0B 37 hours ago Up 37 hours ceph-aeef8b18-f27e-11eb-8817-525400d203e5-mon.server1
072c509a5316 ceph/ceph-grafana:6.7.4 "/bin/sh -c 'grafana…" 0 4.58kB 37 hours ago Up 37 hours ceph-aeef8b18-f27e-11eb-8817-525400d203e5-grafana.server1
50604c3ad7e9 prom/prometheus:v2.18.1 "/bin/prometheus --c…" 0 0B 37 hours ago Up 37 hours ceph-aeef8b18-f27e-11eb-8817-525400d203e5-prometheus.server1
ab39aeacb3a8 prom/node-exporter:v0.18.1 "/bin/node_exporter …" 0 0B 37 hours ago Up 37 hours ceph-aeef8b18-f27e-11eb-8817-525400d203e5-node-exporter.server1
efaa16355059 goharbor/nginx-photon:v2.3.1 "nginx -g 'daemon of…" 3 2B 5 days ago Up 35 hours (healthy) nginx
39c377257da9 goharbor/harbor-jobservice:v2.3.1 "/harbor/entrypoint.…" 0 1.57MB 5 days ago Up 35 hours (healthy) harbor-jobservice
98bc172d251a goharbor/harbor-core:v2.3.1 "/harbor/entrypoint.…" 0 1.57MB 5 days ago Up 35 hours (healthy) harbor-core
204641cbfd33 goharbor/harbor-registryctl:v2.3.1 "/home/harbor/start.…" 1 1.57MB 5 days ago Up 37 hours (healthy) registryctl
a7dc4c50a19e goharbor/redis-photon:v2.3.1 "redis-server /etc/r…" 0 0B 5 days ago Up 35 hours (healthy) redis
41f35c561d90 goharbor/harbor-portal:v2.3.1 "nginx -g 'daemon of…" 3 2B 5 days ago Up 35 hours (healthy) harbor-portal
e54fe0ab5f29 goharbor/harbor-db:v2.3.1 "/docker-entrypoint.…" 0 64B 5 days ago Up 37 hours (healthy) harbor-db
5c66d3476876 goharbor/registry-photon:v2.3.1 "/home/harbor/entryp…" 0 1.57MB 5 days ago Up 35 hours (healthy) registry
68d211836ec6 goharbor/harbor-log:v2.3.1 "/bin/sh -c /usr/loc…" 2 56B 5 days ago Up 37 hours (healthy) harbor-log
Local Volumes space usage:
VOLUME NAME LINKS SIZE
792afe5f78ee1ff9aa0f31b025c186d75c7aad0085e3f2829b485844e7ee7e9c 1 0B
a9300105f36cca0b62b08c8e21de9fd6e0bf2ec202e00fad8480aa494f407f35 1 40B
d3573ddda98c65c0501d2db5090e59c7be2a903777bbde1a0fb9502f68fbe460 1 0B
a59cbc3cabb41eb60535484abd3ab56c44fcc35308716eb179a54eccd20a7bd7 1 0B
c68a051cd7f7d570103a5c812e57bead90b5f3dec7c7a69821bbabdf13d607b6 1 0B
cb50e35b60a6579860eb92fbbcf2ebeb523775b578d0ab5397552008ea36d7f1 1 40B
09b4804bf57a1640981aa969d6573f78ff670c6389092f6c0eb1fd1bc78596b8 1 0B
2f86493a9243535160b8c3cc677502eaee01c4b6e7f68375d5ad5eff64cd48b8 1 0B
969c01f2a39d03d1c9cdc14d7e649c823cd218d26a99b44c28d0ac8c293c918d 1 4B
Build cache usage: 0B
CACHE ID CACHE TYPE SIZE CREATED LAST USED USAGE SHARED
定位容器写满磁盘的原因
进入容器数据目录(假设是 /var/lib/docker,并且存储驱动是 aufs):
$ cd /var/lib/docker
$ du -sh *
88K buildkit
42M containers
16M image
116K network
13G overlay2
16K plugins
4.0K runtimes
4.0K swarm
4.0K tmp
4.0K trust
224K volumes
找出日志输出量大的 pod
TKE 的 pod 中每个容器输出的日志最大存储 1G (日志轮转,最大10个文件,每个文件最大100m,可用 docker inpect 查看):
$ docker inspect fef835ebfc88
[
{
...
"HostConfig": {
...
"LogConfig": {
"Type": "json-file",
"Config": {
"max-file": "10",
"max-size": "100m"
}
},
...
查看哪些容器日志输出量大:
$ cd /var/lib/docker/containers
$ du -sh *
44K 072c509a5316c06c0a0c67239f406b70b97226555952d25a611f8960b09d862e
1.8M 204641cbfd33f0bef002af3505c6ccce802468e56f0763f4e14d811159893812
2.3M 3318900b84edbae035678bc61dd17d8946db9cb530baf2f7ea3fbff5f510828f
9.0M 39c377257da9aa3ba85931b9c28305662595e38bad5df9c3629b159dc9d811c5
2.6M 41f35c561d90e9ee272837795d0e8f2f4a0cf98ace9065a88b5791ba03eaea19
60K 50604c3ad7e9cc38628ecd42161025b7a3789895acd21730dbc544f851ac3dab
40K 5b6ef8890d59785ca1622d32bea48b991fc09504533ba4abfe89e52630f1b73a
2.1M 5c66d347687626c011d5edd929716113e101ece9ee5406b2f96ff82fbde18928
44K 68d211836ec68cb4ac94ecbf237a5a8b00466617895deb3acd26b1d8db6d5620
36K 8a8e08d49aa8e2754f8cea303f0cb654056326ab4adf81b43a71df458898c162
588K 98bc172d251a4975ad7d740eb54088942316b174f6c8da97a4569445173b4032
40K 9e241e877dff7bd995aa3b02ecc846b3b178432972323fd21307edd4f6dcb990
252K a7dc4c50a19ec40f91c8d867dfbce06e0defe4b6889c805e4103ef23d309c6ac
40K ab39aeacb3a8f48f1f671c728db38d9433c541efe0a2027d750e430ade0658ae
48K e54fe0ab5f29ba027c85d50a49cbbdfdca772d693e6e48190d2a3bad59de8706
22M ed5945eefdc113c62a0c1d68dc3453e1ed7fdb06aabfa17ffe84418e2ae47a6f
600K efaa16355059d2fd692e4c13f18673ff5c60388d6da4dc8452e02ccfcf5f51cc
36K f77fe681058eaa711b56f9166831f3c7ee3519ced4f72df3d9bc98e9d83e129e
目录名即为容器id,使用前几位与 docker ps 结果匹配可找出对应容器,最后就可以推算出是哪些 pod 搞的鬼
运维命令
获取 Pod 和节点
如何查找非 running 状态的 Pod 呢?
kubectl get pods -A --field-selector=status.phase!=Running | grep -v Complete
顺便一说,--field-selector 是个值得深入一点的参数。
如何获取节点列表及其内存容量:
kubectl get no -o json | \
> jq -r '.items | sort_by(.status.capacity.memory)[]|[.metadata.name,.status.capacity.memory]| @tsv'
worker1 3826328Ki
worker2 3826328Ki
获取节点列表,其中包含运行在每个节点上的 Pod 数量
kubectl get po -o json --all-namespaces | \
> jq '.items | group_by(.spec.nodeName) | map({"nodeName": .[0].spec.nodeName, "count": length}) | sort_by(.count)'
[
{
"nodeName": "worker1",
"count": 11
},
{
"nodeName": "worker2",
"count": 19
}
]
有时候 DaemonSet 因为某种原因没能在某个节点上启动。手动搜索会有点麻烦:
$ ns=my-namespace
$ pod_template=my-pod
$ kubectl get node | grep -v \"$(kubectl -n ${ns} get pod --all-namespaces -o wide | fgrep ${pod_template} | awk '{print $8}' | xargs -n 1 echo -n "\|" | sed 's/[[:space:]]*//g')\"
使用 kubectl top 获取 Pod 列表并根据其消耗的 CPU 或 内存进行排序:
# CPU 排序
kubectl top pods -A | sort --reverse --key 3 --numeric
monitoring prometheus-k8s-0 34m 477Mi
kube-system kube-apiserver-worker1 34m 476Mi
kube-system kube-apiserver-worker2 21m 540Mi
kube-system kube-controller-manager-worker2 13m 80Mi
monitoring grafana-6dd5b5f65-plwgk 5m 56Mi
kube-system kube-proxy-wzpbb 3m 36Mi
kube-system kube-proxy-bp6g2 3m 28Mi
monitoring prometheus-adapter-59df95d9f5-p9tgb 2m 37Mi
monitoring node-exporter-pv7xb 2m 39Mi
kube-system kube-flannel-ds-7d8jg 2m 24Mi
default csi-rbdplugin-provisioner-5c7c467848-8n8wz 2m 191Mi
monitoring node-exporter-hvqqt 1m 40Mi
kube-system kube-scheduler-worker2 1m 30Mi
kube-system kube-scheduler-worker1 1m 32Mi
kube-system kube-flannel-ds-77xv9 1m 29Mi
monitoring prometheus-operator-7775c66ccf-vmvsq 0m 59Mi
monitoring kube-state-metrics-76f6cb7996-5sb7d 0m 63Mi
monitoring blackbox-exporter-55c457d5fb-7thcw 0m 40Mi
monitoring alertmanager-main-0 0m 34Mi
kube-system log-pilot-wj9tj 0m 26Mi
kube-system log-pilot-nwf9x 0m 13Mi
kube-system kube-eventer-5dbc97f5b-strgc 0m 16Mi
kube-system kube-controller-manager-worker1 0m 36Mi
kube-system coredns-78fcd69978-tnkz4 0m 22Mi
kube-system coredns-78fcd69978-f7xnk 0m 25Mi
halo halo-nginx-747bb8f59b-k6jm2 0m 7Mi
halo halo-deployment-745fb589c7-csqwk 0m 443Mi
default stakater-reloader-749b6cdb5-l8frx 0m 41Mi
default csi-rbdplugin-fvjq6 0m 67Mi
default csi-rbdplugin-bjnjh 0m 105Mi
# 内存排序
kubectl top pods -A | sort --reverse --key 4 --numeric
kube-system kube-apiserver-worker2 51m 555Mi
kube-system kube-apiserver-worker1 25m 476Mi
monitoring prometheus-k8s-0 38m 474Mi
halo halo-deployment-745fb589c7-csqwk 0m 443Mi
default csi-rbdplugin-provisioner-5c7c467848-8n8wz 2m 191Mi
default csi-rbdplugin-bjnjh 0m 105Mi
kube-system kube-controller-manager-worker2 11m 80Mi
default csi-rbdplugin-fvjq6 0m 67Mi
monitoring kube-state-metrics-76f6cb7996-5sb7d 0m 63Mi
monitoring prometheus-operator-7775c66ccf-vmvsq 0m 59Mi
monitoring grafana-6dd5b5f65-plwgk 2m 53Mi
default stakater-reloader-749b6cdb5-l8frx 0m 41Mi
monitoring node-exporter-hvqqt 1m 40Mi
monitoring blackbox-exporter-55c457d5fb-7thcw 0m 40Mi
monitoring node-exporter-pv7xb 1m 39Mi
monitoring prometheus-adapter-59df95d9f5-p9tgb 4m 37Mi
kube-system kube-controller-manager-worker1 0m 36Mi
kube-system kube-proxy-wzpbb 3m 35Mi
monitoring alertmanager-main-0 0m 34Mi
kube-system kube-scheduler-worker1 1m 32Mi
kube-system kube-scheduler-worker2 1m 30Mi
kube-system kube-flannel-ds-77xv9 1m 29Mi
kube-system kube-proxy-bp6g2 3m 28Mi
kube-system log-pilot-wj9tj 1m 26Mi
kube-system coredns-78fcd69978-f7xnk 1m 25Mi
kube-system kube-flannel-ds-7d8jg 1m 24Mi
kube-system coredns-78fcd69978-tnkz4 1m 22Mi
kube-system kube-eventer-5dbc97f5b-strgc 0m 16Mi
kube-system log-pilot-nwf9x 0m 13Mi
halo halo-nginx-747bb8f59b-k6jm2 0m 7Mi
获取 Pod 列表,并根据重启次数进行排序:
kubectl get pods —sort-by=.status.containerStatuses[0].restartCount
获取其它数据
如何输出 Pod 的 requests 和 limits
kubectl get pods -A -o=custom-columns='NAME:spec.containers[*].name,MEMREQ:spec.containers[*].resources.requests.memory,MEMLIM:spec.containers[*].resources.limits.memory,CPUREQ:spec.containers[*].resources.requests.cpu,CPULIM:spec.containers[*].resources.limits.cpu'
NAME MEMREQ MEMLIM CPUREQ CPULIM
driver-registrar,csi-rbdplugin,liveness-prometheus <none> <none> <none> <none>
driver-registrar,csi-rbdplugin,liveness-prometheus <none> <none> <none> <none>
csi-provisioner,csi-snapshotter,csi-attacher,csi-resizer,csi-rbdplugin,csi-rbdplugin-controller,liveness-prometheus <none> <none> <none> <none>
stakater-reloader <none> <none> <none> <none>
halo 500Mi 1Gi 500m 1
halo-nginx <none> <none> <none> <none>
coredns 70Mi 170Mi 100m <none>
coredns 70Mi 170Mi 100m <none>
kube-apiserver <none> <none> 250m <none>
kube-apiserver <none> <none> 250m <none>
kube-controller-manager <none> <none> 200m <none>
kube-controller-manager <none> <none> 200m <none>
kube-eventer 100Mi 250Mi 100m 500m
kube-flannel 50Mi 50Mi 100m 100m
kube-flannel 50Mi 50Mi 100m 100m
kube-proxy <none> <none> <none> <none>
kube-proxy <none> <none> <none> <none>
kube-scheduler <none> <none> 100m <none>
kube-scheduler <none> <none> 100m <none>
log-pilot 200Mi 500Mi 200m <none>
log-pilot 200Mi 500Mi 200m <none>
alertmanager,config-reloader 100Mi,50Mi 100Mi,50Mi 4m,100m 100m,100m
blackbox-exporter,module-configmap-reloader,kube-rbac-proxy 20Mi,20Mi,20Mi 40Mi,40Mi,40Mi 10m,10m,10m 20m,20m,20m
grafana 100Mi 200Mi 100m 200m
kube-state-metrics,kube-rbac-proxy-main,kube-rbac-proxy-self 190Mi,20Mi,20Mi 250Mi,40Mi,40Mi 10m,20m,10m 100m,40m,20m
node-exporter,kube-rbac-proxy 180Mi,20Mi 180Mi,40Mi 102m,10m 250m,20m
node-exporter,kube-rbac-proxy 180Mi,20Mi 180Mi,40Mi 102m,10m 250m,20m
prometheus-adapter <none> <none> <none> <none>
prometheus,config-reloader 400Mi,50Mi 50Mi 100m 100m
prometheus-operator,kube-rbac-proxy 100Mi,20Mi 200Mi,40Mi 100m,10m 200m,20m
网络
在排除 CNI(例如 Flannel)故障的时候,经常会需要检查路由来识别故障 Pod。Pod 子网在这里非常有用:
kubectl get nodes -o jsonpath='{.items[*].spec.podCIDR}' | tr " " "\n"
10.97.0.0/24
10.97.2.0/24
日志
使用可读的时间格式输出日志:
kubectl logs -f fluentbit-gke-qq9w9 -c fluentbit --timestamps
获取“前一个”容器的日志(例如崩溃的情况):
kubectl logs halo-deployment-745fb589c7-csqwk -n halo --previous
输出一个 Pod 中所有容器的日志:
kubectl -n my-namespace logs -f my-pod —all-containers
其它
把 Secret 复制到其它命名空间:
kubectl get secrets -o json --namespace namespace-old | \
jq '.items[].metadata.namespace = "namespace-new"' | \
kubectl create-f -
下面两个命令可以生成一个用于测试的自签发证书:
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=grafana.mysite.ru/O=MyOrganization"
kubectl -n myapp create secret tls selfsecret --key tls.key --cert tls.crt
kubernetes命令自动补全
echo "source <(kubectl completion bash)" >> ~/.bashrc
source ~/.bashrc
kubectl写yaml太累,找样例太麻烦?
用run命令生成
kubectl run --image=nginx my-deploy -o yaml --dry-run > my-deploy.yaml
用get命令导出
kubectl get statefulset/foo -o=yaml --export > new.yaml
Pod亲和性下面字段的拼写忘记了
kubectl explain pod.spec.affinity.podAffinity
监控集群组件
集群整体状态
kubectl cluster-info
更多集群信息
kubectl cluster-info dump
组件metrics
curl localhost:10250/stats/summary
组件监控状况
curl localhost:10250/healthz
Deployment升级与回滚
# 创建Deployment
kubectl run {deployment} --image={image} --replicas={rep.}
# 升级Deployment
kubectl set image deployment/nginx-deployment nginx=nignx:1.9.1
kubectl set resources deployment/nginx-deployment -c=nginx --limits=cpu=200m,memory=512Mi
# 升级策略
minReadySeconds: 5
strategy:
type: RollingUpdata
maxSurge: 1 #默认25%
maxUnavailable: 1 #默认25%
# 暂停Deployment
kubectl rollout pause deployment/nginx-deployment
# 恢复Deployment
kubectl rollout resume deployment/nginx-deployment
# 查询升级状态
kubectl rollout status deployment/nginx-deployment
# 查询升级历史
kubectl rollout history deploy/nginx-deployment
kubectl rollout history deploy/nginx-deployment --revision=2
# 回滚
kubectl rollout undo deployment/nginx-deployment --to-revision=2
# 应用弹性伸缩
kubectl scale deployment nginx-deployment --replicas=10
# 对接了Heapster,和HPA联动后
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
Node的隔离和恢复
apiVersion: v1
kind: Node
metadata:
name: kubernetes-minion1
labels:
kubernetes.io/hostname: kubernetes-minion1
spec:
unschedulable: true
然后,通过kubectl replace命令完成对Node状态的修改:
查看Node的状态,可以观察到在Node的状态中增加了一项SchedulingDisabled:
$ kubectl get nodes
NAME LABELS STATUS
kubernetes-minion1 kubernetes.io/hostname=kubernetes-minion1 Ready, SchedulingDisabled
对于后续创建的Pod,系统将不会再向该Node进行调度。
另一种方法是不使用配置文件,直接使用kubectl patch命令完成:
kubectl patch node kubernetes-minion1 -p '{"spec":{"unschedulable":true}}'
需要注意的是,将某个Node脱离调度范围时,在其上运行的Pod并不会自动停止,管理员需要手动停止在该Node上运行的Pod。
同样,如果需要将某个Node重新纳入集群调度范围,则将unschedulable设置为false,再次执行kubectl replace或kubectl patch命令就能恢复系统对该Node的调度。
设置默认namespace
运行kubectl命令的不便之一是,每次编写命令时,都需要在最后使用该--namespace 选项。运维人员通常会忘记这一点,最终在错误的namespace中创建对象(pod,service,deployment)。
使用此技巧,您可以在运行kubectl命令之前设置namespace首选项。在执行kubectl命令之前运行以下命令,它将为您的当前上下文保存所有后续kubectl命令的namespace:
kubectl config set-context $(kubectl config current-context) --namespace=mynamespace
查看资源利用率
安装 metrics-server 后可以运行 kubectl top 查看相关资源的占用率
kubectl top node
kubectl top pod -n namespace
资源与调度
将Pod调度到指定的Node
首先,我们可以通过kubectl label命令给目标Node打上一个特定的标签,下面是此命令的完整用法:
kubectl label nodes <node-name> <label-key>=<label-value>
这里,我们为kubernetes-minion1节点打上一个zone=north的标签,表明它是“北方”的一个节点:
$ kubectl label nodes kubernetes-minion1 zone=north
NAME LABELS STATUS
kubernetes-minion1 kubernetes.io/hostname=kubernetes-minion1,zone=north Ready
上述命令行操作也可以通过修改资源定义文件的方式,并执行kubectl replace -f xxx.yaml命令来完成。
然后,在Pod的配置文件中加入nodeSelector定义,以redis-master-controller.yaml为例:
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: master
image: kubeguide/redis-master
ports:
- containerPort: 6379
nodeSelector:
zone: north
运行kubectl create -f命令创建Pod,scheduler就会将该Pod调度到拥有zone=north标签的Node上去。
使用kubectl get pods -o wide命令可以验证Pod所在的Node:
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE NODE
redis-master-f0rqj 1/1 Running 0 19s kubernetes-minion1
如果我们给多个Node都定义了相同的标签(例如zone=north),则scheduler将会根据调度算法从这组Node中挑选一个可用的Node进行Pod调度。
这种基于Node标签的调度方式灵活性很高,比如我们可以把一组Node分别贴上“开发环境”“测试验证环境”“用户验收环境”这三组标签中的一种,此时一个Kubernetes集群就承载了3个环境,这将大大提高开发效率。
需要注意的是,如果我们指定了Pod的nodeSelector条件,且集群中不存在包含相应标签的Node时,即使还有其他可供调度的Node,这个Pod也最终会调度失败。
让 master 节点可调度
kubectl taint node master node-role.kubernetes.io/master-
kubectl taint node master node-role.kubernetes.io/master=""
使用 nodeName 指定 pod 调度节点
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01
给每个namespace添加默认的内存和CPU限额
是人就会犯错。我们假定某人写了个应用,他每秒就会打开一个数据库连接,但是不会关闭。这样集群中就有了一个内存泄漏的应用。假定我们把该应用部署到了没有限额设置的集群,那么该应用就会crash掉一个节点。
为了避免这种情况,Kubernetes允许为每个namespace设置默认的限额。要做到这很简单,我们只需创建一个limit range 的 yaml 并应用到特定namespace。以下是一个例子:
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
namespace: test
spec:
limits:
- default:
memory: 512Mi
cpu: 500m
defaultRequest:
memory: 256Mi
cpu: 100m
type: Container
将该内容创建一个yaml文件并将它应用到任何你想应用的namespace,例如namespace limit-example。使用了限额后,任何部署到该namespace的应用,假如没有主动设置限额,都将得到一个默认的512Mi的内存限额。
重要的线上应用改如何设置
节点资源不足时,会触发自动驱逐,将一些低优先级的 Pod 删除掉以释放资源让节点自愈。
- 没有设置 request,limit 的 Pod 优先级最低,容易被驱逐;
- request 不等于 limit 的其次;
- request 等于 limit 的 Pod 优先级较高,不容易被驱逐。
所以如果是重要的线上应用,不希望在节点故障时被驱逐导致线上业务受影响,就建议将 request 和 limit 设成一致。
怎样设置才能提高资源利用率
如果给给你的应用设置较高的 request 值,而实际占用资源长期远小于它的 request 值,导致节点整体的资源利用率较低。当然这对时延非常敏感的业务除外,因为敏感的业务本身不期望节点利用率过高,影响网络包收发速度。所以对一些非核心,并且资源不长期占用的应用,可以适当减少 request 以提高资源利用率。
如果你的服务支持水平扩容,单副本的 request 值一般可以设置到不大于 1 核,CPU 密集型应用除外。比如 coredns,设置到 0.1 核就可以,即 100m。
尽量避免使用过大的 request 与 limit
如果你的服务使用单副本或者少量副本,给很大的 request 与 limit,让它分配到足够多的资源来支撑业务,那么某个副本故障对业务带来的影响可能就比较大,并且由于 request 较大,当集群内资源分配比较碎片化,如果这个 Pod 所在节点挂了,其它节点又没有一个有足够的剩余可分配资源能够满足这个 Pod 的 request 时,这个 Pod 就无法实现漂移,也就不能自愈,加重对业务的影响。
相反,建议尽量减小 request 与 limit,通过增加副本的方式来对你的服务支撑能力进行水平扩容,让你的系统更加灵活可靠。
避免测试 namespace 消耗过多资源影响生产业务
若生产集群有用于测试的 namespace,如果不加以限制,可能导致集群负载过高,从而影响生产业务。可以使用 ResourceQuota 来限制测试 namespace 的 request 与 limit 的总大小。 示例:
apiVersion: v1
kind: ResourceQuota
metadata:
name: quota-test
namespace: test
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
如何让资源得到更合理的分配
设置 Request 能够解决让 Pod 调度到有足够资源的节点上,但无法做到更细致的控制。如何进一步让资源得到合理的使用?我们可以结合亲和性、污点与容忍等高级调度技巧,让 Pod 能够被合理调度到合适的节点上,让资源得到充分的利用。
使用亲和性
- 对节点有特殊要求的服务可以用节点亲和性 (Node Affinity) 部署,以便调度到符合要求的节点,比如让 MySQL 调度到高 IO 的机型以提升数据读写效率。
- 可以将需要离得比较近的有关联的服务用 Pod 亲和性 (Pod Affinity) 部署,比如让 Web 服务跟它的 Redis 缓存服务都部署在同一可用区,实现低延时。
- 也可使用 Pod 反亲和 (Pod AntiAffinity) 将 Pod 进行打散调度,避免单点故障或者流量过于集中导致的一些问题。
K8S 的设计就是假设节点是不可靠的。节点越多,发生软硬件故障导致节点不可用的几率就越高,所以我们通常需要给服务部署多个副本,根据实际情况调整 replicas 的值,如果值为 1 就必然存在单点故障,如果大于 1 但所有副本都调度到同一个节点了,那还是有单点故障,有时候还要考虑到灾难,比如整个机房不可用。
所以我们不仅要有合理的副本数量,还需要让这些不同副本调度到不同的拓扑域(节点、可用区),打散调度以避免单点故障,这个可以利用 Pod 反亲和性来做到,反亲和主要分强反亲和与弱反亲和两种。
先来看个强反亲和的示例,将 dns 服务强制打散调度到不同节点上:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- kube-dns
topologyKey: kubernetes.io/hostname
- labelSelector.matchExpressions 写该服务对应 pod 中 labels 的 key 与 value,因为 Pod 反亲和性是通过判断 replicas 的 pod label 来实现的。
- topologyKey 指定反亲和的拓扑域,即节点 label 的 key。这里用的 kubernetes.io/hostname 表示避免 pod 调度到同一节点,如果你有更高的要求,比如避免调度到同一个可用区,实现异地多活,可以用 failure-domain.beta.kubernetes.io/zone。通常不会去避免调度到同一个地域,因为一般同一个集群的节点都在一个地域,如果跨地域,即使用专线时延也会很大,所以 topologyKey 一般不至于用 failure-domain.beta.kubernetes.io/region。
- requiredDuringSchedulingIgnoredDuringExecution 调度时必须满足该反亲和性条件,如果没有节点满足条件就不调度到任何节点 (Pending)。
如果不用这种硬性条件可以使用 preferredDuringSchedulingIgnoredDuringExecution 来指示调度器尽量满足反亲和性条件,即弱反亲和性,如果实在没有满足条件的,只要节点有足够资源,还是可以让其调度到某个节点,至少不会 Pending。
我们再来看个弱反亲和的示例:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- kube-dns
topologyKey: kubernetes.io/hostname
注意到了吗?相比强反亲和有些不同哦,多了一个 weight,表示此匹配条件的权重,而匹配条件被挪到了 podAffinityTerm 下面。
使用污点与容忍
使用污点 (Taint) 与容忍 (Toleration) 可优化集群资源调度: 通过给节点打污点来给某些应用预留资源,避免其它 Pod 调度上来。 需要使用这些资源的 Pod 加上容忍,结合节点亲和性让它调度到预留节点,即可使用预留的资源。
驱逐
有时候我们需要对节点进行维护或进行版本升级等操作,操作之前需要对节点执行驱逐 (kubectl drain),驱逐时会将节点上的 Pod 进行删除,以便它们漂移到其它节点上,当驱逐完毕之后,节点上的 Pod 都漂移到其它节点了,这时我们就可以放心的对节点进行操作了。
有一个问题就是,驱逐节点是一种有损操作,驱逐的原理:
- 封锁节点 (设为不可调度,避免新的 Pod 调度上来)。
- 将该节点上的 Pod 删除。
- ReplicaSet 控制器检测到 Pod 减少,会重新创建一个 Pod,调度到新的节点上。
这个过程是先删除,再创建,并非是滚动更新,因此更新过程中,如果一个服务的所有副本都在被驱逐的节点上,则可能导致该服务不可用。
我们再来下什么情况下驱逐会导致服务不可用:
- 服务存在单点故障,所有副本都在同一个节点,驱逐该节点时,就可能造成服务不可用。
- 服务没有单点故障,但刚好这个服务涉及的 Pod 全部都部署在这一批被驱逐的节点上,所以这个服务的所有 Pod 同时被删,也会造成服务不可用。
- 服务没有单点故障,也没有全部部署到这一批被驱逐的节点上,但驱逐时造成这个服务的一部分 Pod 被删,短时间内服务的处理能力下降导致服务过载,部分请求无法处理,也就降低了服务可用性。
针对第一点,我们可以使用前面讲的反亲和性来避免单点故障。
针对第二和第三点,我们可以通过配置 PDB (PodDisruptionBudget) 来避免所有副本同时被删除,驱逐时 K8S 会 "观察" nginx 的当前可用与期望的副本数,根据定义的 PDB 来控制 Pod 删除速率,达到阀值时会等待 Pod 在其它节点上启动并就绪后再继续删除,以避免同时删除太多的 Pod 导致服务不可用或可用性降低,下面给出两个示例。
示例一 (保证驱逐时 nginx 至少有 90% 的副本可用):
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 90%
selector:
matchLabels:
app: zookeeper
示例二 (保证驱逐时 zookeeper 最多有一个副本不可用,相当于逐个删除并等待在其它节点完成重建):
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
maxUnavailable: 1
selector:
matchLabels:
app: zookeeper
优雅终止
概述
Pod 销毁时,会停止容器内的进程,通常在停止的过程中我们需要执行一些善后逻辑,比如等待存量请求处理完以避免连接中断,或通知相关依赖进行清理等,从而实现优雅终止目的。本文介绍在 Kubernetes 场景下,实现容器优雅终止的最佳实践。
容器终止流程
我们先了解下容器在 Kubernetes 环境中的终止流程:
- Pod 被删除,状态置为 Terminating。
- kube-proxy 更新转发规则,将 Pod 从 service 的 endpoint 列表中摘除掉,新的流量不再转发到该 Pod。
- 如果 Pod 配置了 preStop Hook ,将会执行。
- kubelet 对 Pod 中各个 container 发送 SIGTERM 信号以通知容器进程开始优雅停止。
- 等待容器进程完全停止,如果在 terminationGracePeriodSeconds 内 (默认 30s) 还未完全停止,就发送 SIGKILL 信号强制杀死进程。
- 所有容器进程终止,清理 Pod 资源。
preStop Hook
在容器因 API 请求或者管理事件(诸如存活态探针、启动探针失败、资源抢占、资源竞争等) 而被终止之前,此回调会被调用。 如果容器已经处于已终止或者已完成状态,则对 preStop 回调的调用将失败。 在用来停止容器的 TERM 信号被发出之前,回调必须执行结束。 Pod 的终止宽限周期在 PreStop 回调被执行之前即开始计数,所以无论 回调函数的执行结果如何,容器最终都会在 Pod 的终止宽限期内被终止。 没有参数会被传递给处理程序。
管理K8s日志
管理K8s组件日志
组件日志
/var/log/kube-apiserver.log
/var/log/kube-proxy.log
/var/log/kube-controller-manager.log
/var/log/kubelet.log
使用systemd管理
journalctl -u kubelet
使用K8s插件部署
kubectl logs -f kube-proxy
管理K8s应用日志
容器标准输出截获
kubectl logs -f {pod name} -c {container name}
docker logs -f {docker name}
日志文件挂载到主机目录
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- image: test-webserver
name: test-container
volumeMounts:
- mountPath: /log
name: log-volume
volumes:
- name: log-volume
hostPath:
path: /var/k8s/log
如何让服务进行平滑更新?
触发 Deployment 更新
使用 kubectl rollout 命令让 pod 优雅滚动重启
kubectl rollout restart deployment xxxx
如何让服务进行平滑更新?
解决了服务单点故障和驱逐节点时导致的可用性降低问题后,我们还需要考虑一种可能导致可用性降低的场景,那就是滚动更新。为什么服务正常滚动更新也可能影响服务的可用性呢?别急,下面我来解释下原因。
假如集群内存在服务间调用:
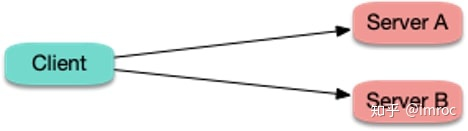
当 server 端发生滚动更新时:

发生两种尴尬的情况:
-
- 旧的副本很快销毁,而 client 所在节点 kube-proxy 还没更新完转发规则,仍然将新连接调度给旧副本,造成连接异常,可能会报 "connection refused" (进程停止过程中,不再接受新请求) 或 "no route to host" (容器已经完全销毁,网卡和 IP 已不存在)。
-
- 新副本启动,client 所在节点 kube-proxy 很快 watch 到了新副本,更新了转发规则,并将新连接调度给新副本,但容器内的进程启动很慢 (比如 Tomcat 这种 java 进程),还在启动过程中,端口还未监听,无法处理连接,也造成连接异常,通常会报 "connection refused" 的错误。
针对第一种情况,可以给 container 加 preStop,让 Pod 真正销毁前先 sleep 等待一段时间,等待 client 所在节点 kube-proxy 更新转发规则,然后再真正去销毁容器。这样能保证在 Pod Terminating 后还能继续正常运行一段时间,这段时间如果因为 client 侧的转发规则更新不及时导致还有新请求转发过来,Pod 还是可以正常处理请求,避免了连接异常的发生。听起来感觉有点不优雅,但实际效果还是比较好的,分布式的世界没有银弹,我们只能尽量在当前设计现状下找到并实践能够解决问题的最优解。
针对第二种情况,可以给 container 加 ReadinessProbe (就绪检查),让容器内进程真正启动完成后才更新 Service 的 Endpoint,然后 client 所在节点 kube-proxy 再更新转发规则,让流量进来。这样能够保证等 Pod 完全就绪了才会被转发流量,也就避免了链接异常的发生。
最佳实践 yaml 示例:
apiVersion: v1
kind: Pod
metadata:
name: helloweb1
labels:
app: helloweb
spec:
containers:
- name: helloweb
image: med1tator/helloweb:v1
readinessProbe:
httpGet:
path: /healthz
port: 80
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 30
timeoutSeconds: 10
lifecycle:
preStop:
exec:
command: ["/bin/bash", "-c", "sleep 10"]
ports:
- containerPort: 80
健康检查怎么配才好?
我们都知道,给 Pod 配置健康检查也是提高服务可用性的一种手段,配置 ReadinessProbe (就绪检查) 可以避免将流量转发给还没启动完全或出现异常的 Pod;配置 LivenessProbe (存活检查) 可以让存在 bug 导致死锁或 hang 住的应用重启来恢复。但是,如果配置配置不好,也可能引发其它问题,这里根据一些踩坑经验总结了一些指导性的建议:
- 不要轻易使用 LivenessProbe,除非你了解后果并且明白为什么你需要它,参考 Liveness Probes are Dangerous
- 如果使用 LivenessProbe,不要和 ReadinessProbe 设置成一样 (failureThreshold 更大)
探测逻辑里不要有外部依赖 (db, 其它 pod 等),避免抖动导致级联故障 - 业务程序应尽量暴露 HTTP 探测接口来适配健康检查,避免使用 TCP 探测,因为程序 hang 死时, TCP 探测仍然能通过 (TCP 的 SYN 包探测端口是否存活在内核态完成,应用层不感知)
kubernetes 最佳实践:优雅热更新
当kubernetes对服务滚动更新的期间,默认配置的情况下可能会让部分连接异常(比如连接被拒绝),我们来分析下原因并给出最佳实践
滚动更新场景
使用 deployment 部署服务并关联 service
- 修改 deployment 的 replica 调整副本数量来滚动更新
- 升级程序版本(修改镜像tag)触发 deployment 新建 replicaset 启动新版本的 pod
- 使用 HPA (HorizontalPodAutoscaler) 来对 deployment 自动扩缩容
更新过程连接异常的原因
滚动更新时,service 对应的 pod 会被创建或销毁,也就是 service 对应的 endpoint 列表会新增或移除endpoint,更新期间可能让部分连接异常,主要原因是:
- pod 被创建,还没完全启动就被 endpoint controller 加入到 service 的 endpoint 列表,然后 kube-proxy 配置对应的路由规则(iptables/ipvs),如果请求被路由到还没完全启动完成的 pod,这时 pod 还不能正常处理请求,就会导致连接异常
- pod 被销毁,但是从 endpoint controller watch 到变化并更新 service 的 endpoint 列表到 kube-proxy 更新路由规则这期间有个时间差,pod可能已经完全被销毁了,但是路由规则还没来得及更新,造成请求依旧还能被转发到已经销毁的 pod ip,导致连接异常
最佳实践
- 针对第一种情况,可以给 pod 里的 container 加 readinessProbe (就绪检查),这样可以让容器完全启动了才被endpoint controller加进 service 的 endpoint 列表,然后 kube-proxy 再更新路由规则,这时请求被转发到的所有后端 pod 都是正常运行,避免了连接异常
- 针对第二种情况,可以给 pod 里的 container 加 preStop hook,让 pod 真正销毁前先 sleep 等待一段时间,留点时间给 endpoint controller 和 kube-proxy 清理 endpoint 和路由规则,这段时间 pod 处于 Terminating 状态,在路由规则更新完全之前如果有请求转发到这个被销毁的 pod,请求依然可以被正常处理,因为它还没有被真正销毁
最佳实践 yaml 示例:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
component: nginx
template:
metadata:
labels:
component: nginx
spec:
containers:
- name: nginx
image: "nginx"
ports:
- name: http
hostPort: 80
containerPort: 80
protocol: TCP
readinessProbe:
httpGet:
path: /healthz
port: 80
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 15
timeoutSeconds: 1
lifecycle:
preStop:
exec:
command: ["/bin/bash", "-c", "sleep 30"]
配置健康检测
liveness
自定义检测命令
Liveness检测让我们可以自定义条件来判断容器是否健康,如果检测失败,则K8s会重启容器,我们来个例子实践下,准备如下yaml配置并保存为liveness.yaml:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness
spec:
restartPolicy: OnFailure
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10 # 容器启动 10 秒之后开始检测
periodSeconds: 5 # 每隔 5 秒再检测一次
启动进程首先创建文件 /tmp/healthy,30 秒后删除,在我们的设定中,如果 /tmp/healthy 文件存在,则认为容器处于正常状态,反正则发生故障。
livenessProbe 部分定义如何执行 Liveness 检测:
检测的方法是:通过 cat 命令检查 /tmp/healthy 文件是否存在。如果命令执行成功,返回值为零,K8s 则认为本次 Liveness 检测成功;如果命令返回值非零,本次 Liveness 检测失败。
initialDelaySeconds: 10 指定容器启动 10 之后开始执行 Liveness 检测,我们一般会根据应用启动的准备时间来设置。比如某个应用正常启动要花 30 秒,那么 initialDelaySeconds 的值就应该大于 30。
periodSeconds: 5 指定每 5 秒执行一次 Liveness 检测。K8s 如果连续执行 3 次 Liveness 检测均失败,则会杀掉并重启容器。
http 检测
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: k8s.gcr.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
tcp 检测
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
Readiness
Liveness 检测和 Readiness 检测是两种 Health Check 机制,如果不特意配置,Kubernetes 将对两种检测采取相同的默认行为,即通过判断容器启动进程的返回值是否为零来判断检测是否成功。
两种检测的配置方法完全一样,支持的配置参数也一样。不同之处在于检测失败后的行为:Liveness 检测是重启容器;Readiness 检测则是将容器设置为不可用,不接收 Service 转发的请求。
Liveness 检测和 Readiness 检测是独立执行的,二者之间没有依赖,所以可以单独使用,也可以同时使用。用 Liveness 检测判断容器是否需要重启以实现自愈;用 Readiness 检测判断容器是否已经准备好对外提供服务。
生产环境中的kubernetes 优先级与抢占
基本原理
优先级与抢占是为了确保一个高优先级的pod在调度失败后,可以通过"挤走" 低优先级的pod,腾出空间后保证它可以调度成功。 我们首先需要在集群中声明PriorityClass来定义优先等级数值和抢占策略,
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high
value: 10000
preemptionPolicy: Never
globalDefault: false
description: "This priority class should be used for high priority service pods."
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low
value: -999
globalDefault: false
description: "This priority class should be used for log priority service pods."
如上所示定义了两个PriorityClass对象。然后就可以在pod中声明使用它了:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: nginx
name: high-nginx
spec:
replicas: 1
selector:
matchLabels:
run: nginx
template:
metadata:
labels:
run: nginx
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
resources:
limits:
cpu: "500m"
priorityClassName: high
这个 Pod 通过 priorityClassName 字段。声明了要使用名叫 high-priority 的 PriorityClass。当这个 Pod 被提交给 Kubernetes 之后,Kubernetes 的 Priority AdmissionController 就会自动将这个 Pod 的spec.priority 字段设置为10000。
如下:
preemptionPolicy: Never
priority: 10000
priorityClassName: high
Pod创建好之后,调度器就会根据创建的priority进行调度的决策,首先会在等待队列中优先调度,如果调度失败就会进行抢占: 依次遍历所有的node找出最适合的node,将该nodename填充在spec.nominatedNodeName字段上,然后等待被抢占的pod全都退出后再次尝试调度到该node之上。具体的逻辑请自行阅读相关代码,此处不在赘述。
生产环境使用方式
- v1.14版本的kubernetes该feature已经GA,默认开启,但此时我们往往没有做好准备,如果直接给pod设置优先级会导致很多意料之外的抢占,造成故障。 (参见How a Production Outage Was Caused Using Kubernetes Pod Priorities)。所以建议在初次使用的时候还是先显式关闭抢占,只设置优先级,等集群中所有的pod都有了各自的优先级之后再开启,此时所有的抢占都是可预期的。可以通过kube-scheduler 配置文件中的disablePreemption: true进行关闭
- 调度器是根据优先级pod.spec.priority数值来决定优先级的,而用户是通过指定pod.sepc.priorityclass的名字来为pod选择优先级的,此时就需要Priority AdmissionController根据priorityclass name为pod自动转换并设置对应的priority数值。我们需要确保该admissionController开启,如果你的kube-apiserver中还是通过--admission-control flag来指定admissionoController的话需要手动添加Priority admissonController,如果是通过--enable-admission-plugins来指定的话,无需操作,该admissionController默认开启。
- 按照集群规划创建对应的PriorityClass及其对应的抢占策略,目前支持两种策略: Never, PreemptLowerPriority。 Never可以指定不抢占其他pod, 即使该pod优先级特别高,这对于一些离线任务较为友好。 非抢占调度在v1.15中为alpha, 需要通过--feature-gates=NonPreemptingPriority=true 进行开启。
- 在创建好了PriorityClass之后,需要防止高优先级的pod过分占用太多资源,使用resourceQuota机制来限制其使用量,避免低优先级的pod总是被高优先级的pod压制,造成资源饥饿。resoueceQuote可以通过指定scope为PriorityClass来限定某个优先级能使用的资源量:
apiVersion: v1
kind: ResourceQuota
metadata:
name: high-priority
spec:
hard:
pods: "10"
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["high"]
如上即为限制高优先级的pod最多能创建10个。operator指定了作用的对象,operator: In可以显式指定作用于的哪些priorityClass,operator: Exists则指定作用于该namespace下的所有priorityClass。
有时候我们想要只有priorityClass对应的resourceQuota存在之后才能创建pod,确保所有的priorityClass的pod资源都是受控的。 如果那个namespacew没有该resourceQuota则拒绝该pod的创建,该操作可以通过指定--admission-control-config-file文件来设置,内容如下:
apiVersion: apiserver.k8s.io/v1alpha1
kind: AdmissionConfiguration
plugins:
- name: "ResourceQuota"
configuration:
apiVersion: resourcequota.admission.k8s.io/v1beta1
kind: Configuration
limitedResources:
- resource: pods
matchScopes:
- scopeName: PriorityClass
operator: In
values: ["high"]
该配置定义了: "high"优先级的pod只能在指定的namespaces下创建,该namespaces有作用于"high"优先级的resouceQuota,上面第四步中的resouceQuota即可满足要求。
scopeName定义了作用的对象为priorityClass, operator指定了作用的范围,可以是In操作符,指定某几个value, 也可以是Exits操作符,指定所有的PriorityClass必须有对应的quota存在, 否则该namespace就无法创建该优先级的pod,这些操作符与上面resouceQuota中定义的一一对应。通过这样就限制了一些优先级只能在有资源约束的namespace下创建。
- 如果没有显式指定优先级,则默认的优先级值为0,需要结合业务规划决定是否有必要调整默认优先级。
- 对于一些daemonset需要显式设置较高的优先级来防止被抢占,在部署一个新的daemonset的时候需要考虑是否会造成大规模pod的抢占。
- 等到所有的优先级设置完毕之后就可以开启抢占功能了,此时集群中所有pending 的高优先级pod就会瞬间抢占,还是需要额外小心,确保集群中高优先级的pod不会导致低优先级的pod大规模被kill,如果我们提前设置了对应的resource quota值,则会有一定的资源约束。
- 优先级和抢占对于资源的精细化运营考验很大,对于resource quota的设置需要十分精细,需要考虑两个维度来设置: namespace层面和priority层面,我们既希望限制namespace使用的资源,有希望某个priority使用的资源,防止低优先级的pod资源饥饿。 可以在初期只考虑namespace层面的限制,priority层面通过上层业务来保证,例如创建任务的时候保证集群中高优先级的资源使用量不超过50%等。
CoreDNS 添加自定义DNS解析记录
这里用到的是 CoreDNS 的 hosts plugin 插件。该插件仅支持 A, AAAA, 和 PTR 记录。
在线修改 coredns 的 configmap,不用重启哦。
配置
kubectl edit configmap coredns -n kube-system
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
hosts {
192.168.1.122 demo1.xx.com
192.168.1.123 demo2.xx.com
fallthrough
}
prometheus :9153
forward . /etc/resolv.conf {
prefer_udp
}
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
labels:
addonmanager.kubernetes.io/mode: EnsureExists
name: coredns
namespace: kube-system
还要注意的是 forward plugin 插件。用于设置 upstream Nameservers 上游 DNS 服务器。CoreDNS 就是通过它让容器能够解析外网的。
这里设置的是宿主机的 /etc/resolv.conf 文件中的 nameservers。
另外,在 kuberntets 中,pod 的默认 dnsPolicy 不是 Default,而是 ClusterFirst。
"ClusterFirst": Any DNS query that does not match the configured cluster domain suffix,
such as "www.kubernetes.io", is forwarded to the upstream nameserver inherited from the node.
“ClusterFirst”:任何与配置的集群域后缀不匹配的 DNS 查询,
例如“www.kubernetes.io”,被转发到从节点继承的上游名称服务器。
Kubernetes Pod dnsPolicy 配置
在Kubernetes中,可以针对每个Pod设置DNS的策略,通过PodSpec下的dnsPolicy字段可以指定相应的策略,目前支持的策略如下:
Default: Pod继承所在宿主机的设置,也就是直接将宿主机的/etc/resolv.conf内容挂载到容器中。ClusterFirst: 默认的配置,所有请求会优先在集群所在域查询,如果没有才会转发到上游DNS。ClusterFirstWithHostNet: 和ClusterFirst一样,不过是Pod运行在hostNetwork:true的情况下强制指定的。None: 1.9版本引入的一个新值,这个配置忽略所有配置,以Pod的dnsConfig字段为准。
为什么会想起找一下dnsPolicy的文档呢,也是因为Pod里默认使用了ClusterFirst策略,导致经常有DNS请求出现timeout问题,想用一个简单的办法继承宿主机的配置,现在看来比较简单了,直接设置dnsPolicy:Default就可以了。
针对上面说的dnsConfig字段,也有个详细的说明:
dnsConfig字段包括下面几个属性:
nameservers: DNS Server的列表,最多3个IP/searches: search域名列表,也就是/etc/resolv.conf中的search字段的配置,最多配置6个options: u选项列表,也就是/etc/resolv.conf中的option字段的配置
一个测试的yaml
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: dns-example
spec:
containers:
- name: test
image: nginx
dnsPolicy: "None"
dnsConfig:
nameservers:
- 1.2.3.4
searches:
- ns1.svc.cluster.local
- my.dns.search.suffix
options:
- name: ndots
value: "2"
- name: edns0
最后Pod中的/etc/resolv.conf配置就如下:
nameserver 1.2.3.4
search ns1.svc.cluster.local my.dns.search.suffix
options ndots:2 edns0