
概述
排查集群状态异常问题通常从 Node 和 Kubernetes 服务 的状态出发,定位出具体的异常服务,再进而寻找解决方法。集群状态异常可能的原因比较多,常见的有
- 虚拟机或物理机宕机
- 网络分区
- Kubernetes 服务未正常启动
- 数据丢失或持久化存储不可用(一般在公有云或私有云平台中)
- 操作失误(如配置错误)
按照不同的组件来说,具体的原因可能包括
- kube-apiserver 无法启动会导致
- 集群不可访问
- 已有的 Pod 和服务正常运行(依赖于 Kubernetes API 的除外)
- etcd 集群异常会导致
- kube-apiserver 无法正常读写集群状态,进而导致 Kubernetes API 访问出错
- kubelet 无法周期性更新状态
- kube-controller-manager/kube-scheduler 异常会导致
- 复制控制器、节点控制器、云服务控制器等无法工作,从而导致 Deployment、Service 等无法工作,也无法注册新的 Node 到集群中来
- 新创建的 Pod 无法调度(总是 Pending 状态)
- Node 本身宕机或者 Kubelet 无法启动会导致
- Node 上面的 Pod 无法正常运行
- 已在运行的 Pod 无法正常终止
- 网络分区会导致 Kubelet 等与控制平面通信异常以及 Pod 之间通信异常
为了维持集群的健康状态,推荐在部署集群时就考虑以下
- 在云平台上开启 VM 的自动重启功能
- 为 Etcd 配置多节点高可用集群,使用持久化存储(如 AWS EBS 等),定期备份数据
- 为控制平面配置高可用,比如多 kube-apiserver 负载均衡以及多节点运行 * kube-controller-manager、kube-scheduler 以及 kube-dns 等
- 尽量使用复制控制器和 Service,而不是直接管理 Pod
- 跨地域的多 Kubernetes 集群
排查命令
查看 Node 状态
一般来说,可以首先查看 Node 的状态,确认 Node 本身是不是 Ready 状态
$ kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
worker1 Ready control-plane,master 13d v1.22.0 10.0.8.6 <none> CentOS Linux 8 4.18.0-305.12.1.el8_4.x86_64 docker://20.10.8
worker2 Ready control-plane,master 13d v1.22.0 10.0.8.12 <none> CentOS Linux 8 4.18.0-305.12.1.el8_4.x86_64 docker://20.10.8
$ kubectl describe node worker2
Name: worker2
Roles: control-plane,master
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
key=worker
kubernetes.io/arch=amd64
kubernetes.io/hostname=worker2
kubernetes.io/os=linux
node-role.kubernetes.io/control-plane=
node-role.kubernetes.io/master=
node.kubernetes.io/exclude-from-external-load-balancers=
Annotations: csi.volume.kubernetes.io/nodeid: {"rbd.csi.ceph.com":"worker2"}
flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"8a:b3:78:94:72:ef"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 10.0.8.12
kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Mon, 16 Aug 2021 13:16:42 +0800
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: worker2
AcquireTime: <unset>
RenewTime: Sun, 29 Aug 2021 22:50:28 +0800
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Sat, 28 Aug 2021 11:54:29 +0800 Sat, 28 Aug 2021 11:54:29 +0800 FlannelIsUp Flannel is running on this node
MemoryPressure False Sun, 29 Aug 2021 22:48:37 +0800 Mon, 16 Aug 2021 19:04:51 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Sun, 29 Aug 2021 22:48:37 +0800 Mon, 16 Aug 2021 19:04:51 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Sun, 29 Aug 2021 22:48:37 +0800 Mon, 16 Aug 2021 19:04:51 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Sun, 29 Aug 2021 22:48:37 +0800 Sat, 28 Aug 2021 11:54:11 +0800 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 10.0.8.12
Hostname: worker2
Capacity:
cpu: 2
ephemeral-storage: 61860632Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3826328Ki
pods: 110
Allocatable:
cpu: 2
ephemeral-storage: 57010758357
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3723928Ki
pods: 110
System Info:
Machine ID: c40cf0ab524d4500be70362f0930e659
System UUID: c40cf0ab-524d-4500-be70-362f0930e659
Boot ID: eee83d62-48d5-4dab-a87f-5cb0ecc36243
Kernel Version: 4.18.0-305.12.1.el8_4.x86_64
OS Image: CentOS Linux 8
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://20.10.8
Kubelet Version: v1.22.0
Kube-Proxy Version: v1.22.0
PodCIDR: 10.97.2.0/24
PodCIDRs: 10.97.2.0/24
Non-terminated Pods: (19 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default csi-rbdplugin-fvjq6 0 (0%) 0 (0%) 0 (0%) 0 (0%) 9d
default csi-rbdplugin-provisioner-5c7c467848-8n8wz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 8d
default stakater-reloader-749b6cdb5-l8frx 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d10h
kube-system coredns-78fcd69978-f7xnk 100m (5%) 0 (0%) 70Mi (1%) 170Mi (4%) 13d
kube-system coredns-78fcd69978-tnkz4 100m (5%) 0 (0%) 70Mi (1%) 170Mi (4%) 13d
kube-system kube-apiserver-worker2 250m (12%) 0 (0%) 0 (0%) 0 (0%) 2d2h
kube-system kube-controller-manager-worker2 200m (10%) 0 (0%) 0 (0%) 0 (0%) 13d
kube-system kube-eventer-5dbc97f5b-strgc 100m (5%) 500m (25%) 100Mi (2%) 250Mi (6%) 46h
kube-system kube-flannel-ds-77xv9 100m (5%) 100m (5%) 50Mi (1%) 50Mi (1%) 13d
kube-system kube-proxy-wzpbb 0 (0%) 0 (0%) 0 (0%) 0 (0%) 13d
kube-system kube-scheduler-worker2 100m (5%) 0 (0%) 0 (0%) 0 (0%) 13d
kube-system log-pilot-nwf9x 200m (10%) 0 (0%) 200Mi (5%) 500Mi (13%) 13d
monitoring alertmanager-main-0 104m (5%) 200m (10%) 150Mi (4%) 150Mi (4%) 13d
monitoring blackbox-exporter-55c457d5fb-7thcw 30m (1%) 60m (3%) 60Mi (1%) 120Mi (3%) 13d
monitoring grafana-6dd5b5f65-plwgk 100m (5%) 200m (10%) 100Mi (2%) 200Mi (5%) 13d
monitoring kube-state-metrics-76f6cb7996-5sb7d 40m (2%) 160m (8%) 230Mi (6%) 330Mi (9%) 13d
monitoring node-exporter-pv7xb 112m (5%) 270m (13%) 200Mi (5%) 220Mi (6%) 13d
monitoring prometheus-adapter-59df95d9f5-p9tgb 0 (0%) 0 (0%) 0 (0%) 0 (0%) 13d
monitoring prometheus-operator-7775c66ccf-vmvsq 110m (5%) 220m (11%) 120Mi (3%) 240Mi (6%) 13d
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1646m (82%) 1710m (85%)
memory 1350Mi (37%) 2400Mi (65%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events: <none>
如果是 NotReady 状态,则可以执行 kubectl describe node
查看日志
一般来说,Kubernetes 的主要组件有两种部署方法
- 直接使用 systemd 等启动控制节点的各个服务
- 使用 Static Pod 来管理和启动控制节点的各个服务
使用 systemd 等管理控制节点服务时,查看日志必须要首先 SSH 登录到机器上,然后查看具体的日志文件。如
journalctl -l -u kube-apiserver
journalctl -l -u kube-controller-manager
journalctl -l -u kube-scheduler
journalctl -l -u kubelet
journalctl -l -u kube-proxy
或者直接查看日志文件
/var/log/kube-apiserver.log
/var/log/kube-scheduler.log
/var/log/kube-controller-manager.log
/var/log/kubelet.log
/var/log/kube-proxy.log
查看 Pod 事件
$ kubectl describe pod halo-nginx-747bb8f59b-k6jm2 -n halo
Name: halo-nginx-747bb8f59b-k6jm2
Namespace: halo
Priority: 0
Node: worker1/10.0.8.6
Start Time: Sun, 29 Aug 2021 23:04:10 +0800
Labels: app=halo-nginx
pod-template-hash=747bb8f59b
Annotations: reloader.stakater.com/auto: true
Status: Running
IP: 10.97.0.60
IPs:
IP: 10.97.0.60
Controlled By: ReplicaSet/halo-nginx-747bb8f59b
Containers:
halo-nginx:
Container ID: docker://1ac4991c9b815a6a9334f991cdc6943cb97b47663e4f2bb6899336fd35381712
Image: nginx:latest
Image ID: docker-pullable://nginx@sha256:8f335768880da6baf72b70c701002b45f4932acae8d574dedfddaf967fc3ac90
Port: 443/TCP
Host Port: 0/TCP
State: Running
Started: Sun, 29 Aug 2021 23:04:11 +0800
Ready: True
Restart Count: 0
Environment:
aliyun_logs_catalina: stdout
aliyun_logs_access: /var/log/nginx/access.log
STAKATER_HALO_NGINX_CONF_CONFIGMAP: 3423d2e27708e43ebd0d6d18290f5a1f1e079123
Mounts:
/etc/nginx/cert from secret-cert-volume (rw)
/etc/nginx/nginx.conf from nginx-config-volume (rw,path="nginx.conf")
/var/log/nginx from nginx-access-log (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-9rbdj (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
nginx-config-volume:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: halo-nginx-conf
Optional: false
secret-cert-volume:
Type: Secret (a volume populated by a Secret)
SecretName: halo-nginx-cert
Optional: false
nginx-access-log:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
kube-api-access-9rbdj:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 46s kubelet Container image "nginx:latest" already present on machine
Normal Created 46s kubelet Created container halo-nginx
Normal Started 46s kubelet Started container halo-nginx
kube-apiserver 日志
PODNAME=$(kubectl -n kube-system get pod -l component=kube-apiserver -o jsonpath='{.items[0].metadata.name}')
kubectl -n kube-system logs $PODNAME --tail 100
kube-controller-manager 日志
PODNAME=$(kubectl -n kube-system get pod -l component=kube-controller-manager -o jsonpath='{.items[0].metadata.name}')
kubectl -n kube-system logs $PODNAME --tail 100
kube-scheduler 日志
PODNAME=$(kubectl -n kube-system get pod -l component=kube-scheduler -o jsonpath='{.items[0].metadata.name}')
kubectl -n kube-system logs $PODNAME --tail 100
kube-dns 日志
PODNAME=$(kubectl -n kube-system get pod -l k8s-app=kube-dns -o jsonpath='{.items[0].metadata.name}')
kubectl -n kube-system logs $PODNAME -c kubedns
Kubelet 日志
查看 Kubelet 日志需要首先 SSH 登录到 Node 上。
journalctl -l -u kubelet
Kube-proxy 日志
Kube-proxy 通常以 DaemonSet 的方式部署
$ kubectl -n kube-system get pod -l component=kube-proxy
NAME READY STATUS RESTARTS AGE
kube-proxy-42zpn 1/1 Running 0 1d
kube-proxy-7gd4p 1/1 Running 0 3d
kube-proxy-87dbs 1/1 Running 0 4d
$ kubectl -n kube-system logs kube-proxy-42zpn
报错实例
Kube-proxy: error looking for path of conntrack
kube-proxy 报错,并且 service 的 DNS 解析异常
kube-proxy[2241]: E0502 15:55:13.889842 2241 conntrack.go:42] conntrack returned error: error looking for path of conntrack: exec: "conntrack": executable file not found in $PATH
解决方式是安装 conntrack-tools 包后重启 kube-proxy 即可。
HPA 不自动扩展 Pod
查看 HPA 的事件,发现
$ kubectl describe hpa php-apache
Name: php-apache
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Wed, 27 Dec 2017 14:36:38 +0800
Reference: Deployment/php-apache
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): <unknown> / 50%
Min replicas: 1
Max replicas: 10
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededGetScale the HPA controller was able to get the target's current scale
ScalingActive False FailedGetResourceMetric the HPA was unable to compute the replica count: unable to get metrics for resource cpu: unable to fetch metrics from API: the server could not find the requested resource (get pods.metrics.k8s.io)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 3m (x2231 over 18h) horizontal-pod-autoscaler unable to get metrics for resource cpu: unable to fetch metrics from API: the server could not find the requested resource (get pods.metrics.k8s.io)
这说明 metrics-server 未部署,可以参考 这里 部署。
网络排错
说到 Kubernetes 的网络,其实无非就是以下三种情况之一
- Pod 访问容器外部网络
- 从容器外部访问 Pod 网络
- Pod 之间相互访问
当然,以上每种情况还都分别包括本地访问和跨主机访问两种场景,并且一般情况下都是通过 Service 间接访问 Pod。
排查网络问题基本上也是从这几种情况出发,定位出具体的网络异常点,再进而寻找解决方法。网络异常可能的原因比较多,常见的有
CNI 网络插件配置错误,导致多主机网络不通,比如
IP 网段与现有网络冲突
插件使用了底层网络不支持的协议
忘记开启 IP 转发等
sysctl net.ipv4.ip_forward
sysctl net.bridge.bridge-nf-call-iptables
Pod 网络路由丢失,比如
kubenet 要求网络中有 podCIDR 到主机 IP 地址的路由,这些路由如果没有正确配置会导致 Pod 网络通信等问题
在公有云平台上,kube-controller-manager 会自动为所有 Node 配置路由,但如果配置不当(如认证授权失败、超出配额等),也有可能导致无法配置路由
主机内或者云平台的安全组、防火墙或者安全策略等阻止了 Pod 网络,比如
非 Kubernetes 管理的 iptables 规则禁止了 Pod 网络
公有云平台的安全组禁止了 Pod 网络(注意 Pod 网络有可能与 Node 网络不在同一个网段)
交换机或者路由器的 ACL 禁止了 Pod 网络
实例
Flannel Pods 一直处于 Init:CrashLoopBackOff 状态
Flannel 网络插件非常容易部署,只要一条命令即可
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
然而,部署完成后,Flannel Pod 有可能会碰到初始化失败的错误
$ kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-ckfdc 0/1 Init:CrashLoopBackOff 4 2m
kube-flannel-ds-jpp96 0/1 Init:CrashLoopBackOff 4 2m
查看日志会发现
$ kubectl -n kube-system logs kube-flannel-ds-jpp96 -c install-cni
cp: can't create '/etc/cni/net.d/10-flannel.conflist': Permission denied
这一般是由于 SELinux 开启导致的,关闭 SELinux 既可解决。有两种方法:
修改 /etc/selinux/config 文件方法:SELINUX=disabled
通过命令临时修改(重启会丢失):setenforce 0
Pod 无法解析 DNS
如果 Node 上安装的 Docker 版本大于 1.12,那么 Docker 会把默认的 iptables FORWARD 策略改为 DROP。这会引发 Pod 网络访问的问题。解决方法则在每个 Node 上面运行 iptables -P FORWARD ACCEPT,比如
echo "ExecStartPost=/sbin/iptables -P FORWARD ACCEPT" >> /etc/systemd/system/docker.service.d/exec_start.conf
systemctl daemon-reload
systemctl restart docker
如果使用了 flannel/weave 网络插件,更新为最新版本也可以解决这个问题。
DNS 无法解析也有可能是 kube-dns 服务异常导致的,可以通过下面的命令来检查 kube-dns 是否处于正常运行状态
$ kubectl get pods --namespace=kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
...
kube-dns-v19-ezo1y 3/3 Running 0 1h
...
如果 kube-dns Pod 处于正常 Running 状态,则需要进一步检查是否正确配置了 kube-dns 服务:
$ kubectl get svc kube-dns --namespace=kube-system
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns 10.0.0.10 <none> 53/UDP,53/TCP 1h
$ kubectl get ep kube-dns --namespace=kube-system
NAME ENDPOINTS AGE
kube-dns 10.180.3.17:53,10.180.3.17:53 1h
如果 kube-dns service 不存在,或者 endpoints 列表为空,则说明 kube-dns service 配置错误,可以重新创建 kube-dns service,比如
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "KubeDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.0.0.10
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
如何解决 Kubernetes 的 DNS 延迟问题
由于 Linux 内核中的缺陷,在 Kubernetes 集群中你很可能会碰到恼人的 DNS 间歇性 5 秒延迟问题(社区 issue 为 #56903[1])。虽然 issue 已经关闭了,但并不是说这个问题已经完全解决了,所以在管理和维护 Kubernetes 集群时,我们需要注意绕开这个缺陷。
为什么会有 DNS 间歇性延迟问题
为什么在 Kubernetes 集群会碰到这个间歇性 5 延迟的问题呢?Weave works 发布了一篇博客Racy conntrack and DNS lookup timeouts[2]详细介绍了问题的原因。
简单来说,由于 UDP 是无连接的,内核 netfilter 模块在处理同一个 socket 上的并发 UDP 包时就可能会有三个竞争问题。以下面的 conntrack 和 DNAT 工作流程为例:

由于 UDP 的 connect 系统调用不会立即创建 conntrack 记录,而是在 UDP 包发送之后才去创建,这就可能会导致下面三种问题:
- 两个 UDP 包在第一步 nf_conntrack_in 中都没有找到 conntrack 记录,所以两个不同的包就会去创建相同的 conntrack 记录(注意五元组是相同的)。
- 一个 UDP 包还没有调用 get_unique_tuple 时 conntrack 记录就已经被另一个 UDP 包确认了。
- 两个 UDP 包在 ipt_do_table 中选择了两个不同端点的 DNAT 规则。
所有这三种场景都会导致最后一步 __nf_conntrack_confirm 失败,从而一个 UDP 包被丢弃。由于 GNU C 库和 musl libc 库在查询 DNS 时,都会同时发出 A 和 AAAA DNS 查询,由于上述的内核竞争问题,就可能会发生其中一个包被丢掉的问题。丢弃之后客户端会超时重试,超时时间通常是 5 秒。
上述的第三个问题至今还没有修复,而前两个问题则已经修复了,分别包含在 5.0 和 4.19 中:
1. netfilter: nf_nat: skip nat clash resolution for same-origin entries[3] (包含在内核 v5.0 中)
2. netfilter: nf_conntrack: resolve clash for matching conntracks[4] (包含在内核 v4.19 中)
在公有云中,这些补丁有可能也会包含在旧的内核版本中。比如在 Azure 上,这两个问题已经包含在 v4.15.0-1030.31 和 v4.18.0-1006.6 中。
如何避免这个问题
要避免 DNS 延迟的问题,就要设法绕开上述三个问题,所以就有下面几种方法:
1、禁止并发 DNS 查询
- single-request-reopen: 发送 A 类型请求和 AAAA 类型请求使用不同的源端口,这样两个请求在 conntrack 表中不占用同一个表项,从而避免冲突
- single-request: 避免并发,改为串行发送 A 类型和 AAAA 类型请求,没有了并发,从而也避免了冲突
要给容器的 resolv.conf 加上 options 参数,有几个办法:
在容器的 “ENTRYPOINT” 或者 “CMD” 脚本中,执行 /bin/echo ‘options single-request-reopen’ >> /etc/resolv.conf
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -c
- "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf"
使用 template.spec.dnsConfig (k8s v1.9 及以上才支持):
dnsConfig:
options:
- name: single-request-reopen
使用 ConfigMap 覆盖 pod 里面的 /etc/resolv.conf:
configmap:
apiVersion: v1
data:
resolv.conf: |
nameserver 1.2.3.4
search default.svc.cluster.local svc.cluster.local cluster.local ec2.internal
options ndots:5 single-request-reopen timeout:1
kind: ConfigMap
metadata:
name: resolvconf
pod spec:
volumeMounts:
- name: resolv-conf
mountPath: /etc/resolv.conf
subPath: resolv.conf
...
volumes:
- name: resolv-conf
configMap:
name: resolvconf
items:
- key: resolv.conf
path: resolv.conf
2、禁用 IPv6 从而避免 AAAA 查询,比如可以给 Grub 配置 ipv6.disable=1 来禁止 ipv6(需要重启节点才可以生效)。
3、使用 TCP 协议,比如在 Pod 配置中开启 use-vc 选项强制 DNS 查询使用 TCP 协议:
dnsConfig:
options:
- name: single-request-reopen
- name: ndots
value: "5"
- name: use-vc
- 使用 Nodelocal DNS Cache[5],所有 Pod 的 DNS 查询都通过本地的 DNS 缓存查询,避免了 DNAT,从而也绕开了内核中的竞争问题。你可以执行下面的命令来部署它(注意它会修改 Kubelet 配置并重启 Kubelet):
kubectl apply -f https://github.com/feiskyer/kubernetes-handbook/raw/master/examples/nodelocaldns/nodelocaldns-kubenet.yaml
Service 无法访问
访问 Service ClusterIP 失败时,可以首先确认是否有对应的 Endpoints
kubectl get endpoints <service-name>
如果该列表为空,则有可能是该 Service 的 LabelSelector 配置错误,可以用下面的方法确认一下
# 查询 Service 的 LabelSelector
kubectl get svc <service-name> -o jsonpath='{.spec.selector}'
# 查询匹配 LabelSelector 的 Pod
kubectl get pods -l key1=value1,key2=value2
如果 Endpoints 正常,可以进一步检查
Pod 的 containerPort 与 Service 的 containerPort 是否对应
直接访问 podIP:containerPort 是否正常
再进一步,即使上述配置都正确无误,还有其他的原因会导致 Service 无法访问,比如
Pod 内的容器有可能未正常运行或者没有监听在指定的 containerPort 上
CNI 网络或主机路由异常也会导致类似的问题
kube-proxy 服务有可能未启动或者未正确配置相应的 iptables 规则,比如正常情况下名为 hostnames的服务会配置以下 iptables 规则或 IPVS 规则。
$ ipvsadm -L | grep worker1
TCP worker1:30086 rr
TCP worker1:30105 rr persistent 10800
TCP worker1:30257 rr
TCP worker1:30086 rr
TCP worker1:30105 rr persistent 10800
TCP worker1:30257 rr
TCP worker1:30086 rr
TCP worker1:30105 rr persistent 10800
TCP worker1:30257 rr
TCP worker1:https rr
-> worker1:sun-sr-https Masq 1 1 0
TCP worker1:domain rr
TCP worker1:9153 rr
TCP worker1:9115 rr
TCP worker1:19115 rr
TCP worker1:opsmessaging rr
TCP worker1:hbci rr
TCP worker1:https rr
TCP worker1:websm rr persistent 10800
TCP worker1:webcache rr
TCP worker1:https rr
TCP worker1:webcache rr
-> worker1:8680 Masq 1 0 0
TCP worker1:copycat rr persistent 10800
TCP worker1:30086 rr
TCP worker1:30105 rr persistent 10800
TCP worker1:30257 rr
TCP worker1:30086 rr
TCP worker1:30105 rr persistent 10800
TCP worker1:30257 rr
UDP worker1:domain rr
$ iptables-save | grep hostnames
-A KUBE-SEP-57KPRZ3JQVENLNBR -s 10.244.3.6/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-57KPRZ3JQVENLNBR -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -s 10.244.1.7/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
-A KUBE-SEP-X3P2623AGDH6CDF3 -s 10.244.2.3/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-X3P2623AGDH6CDF3 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR
无法访问 Kubernetes API
很多扩展服务需要访问 Kubernetes API 查询需要的数据(比如 kube-dns、Operator 等)。通常在 Kubernetes API 无法访问时,可以首先通过下面的命令验证 Kubernetes API 是正常的:
$ kubectl run curl --image=appropriate/curl -i -t --restart=Never --command -- sh
If you don't see a command prompt, try pressing enter.
/ #
/ # KUBE_TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
/ # curl -sSk -H "Authorization: Bearer $KUBE_TOKEN" https://$KUBERNETES_SERVICE_HOST:$KUBERNETES_SERVICE_PORT/api/v1/namespaces/default/pods
{
"kind": "PodList",
"apiVersion": "v1",
"metadata": {
"selfLink": "/api/v1/namespaces/default/pods",
"resourceVersion": "2285"
},
"items": [
...
]
}
如果出现超时错误,则需要进一步确认名为 kubernetes 的服务以及 endpoints 列表是正常的:
$ kubectl get service kubernetes
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 25m
$ kubectl get endpoints kubernetes
NAME ENDPOINTS AGE
kubernetes 172.17.0.62:6443 25m
然后可以直接访问 endpoints 查看 kube-apiserver 是否可以正常访问。无法访问时通常说明 kube-apiserver 未正常启动,或者有防火墙规则阻止了访问。
Kubernetes 排错之 Pod 异常
一般来说,无论 Pod 处于什么异常状态,都可以执行以下命令来查看 Pod 的状态
kubectl get pod <pod-name> -o yaml 查看 Pod 的配置是否正确
kubectl describe pod <pod-name> 查看 Pod 的事件
kubectl logs <pod-name> [-c <container-name>] 查看容器日志
这些事件和日志通常都会有助于排查 Pod 发生的问题。
Pod 一直处于 Pending 状态
Pending 说明 Pod 还没有调度到某个 Node 上面。可以通过 kubectl describe pod
- 资源不足,集群内所有的 Node 都不满足该 Pod 请求的 CPU、内存、GPU 等资源
- HostPort 已被占用,通常推荐使用 Service 对外开放服务端口
Pod 一直处于 Waiting 或 ContainerCreating 状态
首先还是通过 kubectl describe pod
-
镜像拉取失败,比如
- 配置了错误的镜像
- Kubelet 无法访问镜像(国内环境访问 gcr.io 需要特殊处理)
- 私有镜像的密钥配置错误
- 镜像太大,拉取超时(可以适当调整 kubelet 的 --image-pull-progress-deadline 和 --runtime-request-timeout 选项)
-
CNI 网络错误,一般需要检查 CNI 网络插件的配置,比如
- 无法配置 Pod 网络
- 无法分配 IP 地址
-
容器无法启动,需要检查是否打包了正确的镜像或者是否配置了正确的容器参数
Pod 处于 ImagePullBackOff 状态
这通常是镜像名称配置错误或者私有镜像的密钥配置错误导致。这种情况可以使用 docker pull 来验证镜像是否可以正常拉取。
如果是私有镜像,需要首先创建一个 docker-registry 类型的 Secret
kubectl create secret docker-registry my-secret --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
然后在容器中引用这个 Secret
spec:
containers:
- name: private-reg-container
image: <your-private-image>
imagePullSecrets:
- name: my-secret
Pod 一直处于 CrashLoopBackOff 状态
CrashLoopBackOff 状态说明容器曾经启动了,但又异常退出了。此时可以先查看一下容器的日志
kubectl logs <pod-name>
kubectl logs --previous <pod-name>
这里可以发现一些容器退出的原因,比如
- 容器进程退出
- 健康检查失败退出
此时如果还未发现线索,还可以到容器内执行命令来进一步查看退出原因
kubectl exec cassandra -- cat /var/log/cassandra/system.log
如果还是没有线索,那就需要 SSH 登录该 Pod 所在的 Node 上,查看 Kubelet 或者 Docker 的日志进一步排查了
# 查询 Node
kubectl get pod <pod-name> -o wide
Pod 处于 Error 状态
通常处于 Error 状态说明 Pod 启动过程中发生了错误。常见的原因包括
- 依赖的 ConfigMap、Secret 或者 PV 等不存在
- 请求的资源超过了管理员设置的限制,比如超过了 LimitRange 等
- 违反集群的安全策略,比如违反了 PodSecurityPolicy 等
- 容器无权操作集群内的资源,比如开启 RBAC 后,需要为 ServiceAccount 配置角色绑定
Pod 处于 Terminating 或 Unknown 状态
从 v1.5 开始,Kubernetes 不会因为 Node 失联而删除其上正在运行的 Pod,而是将其标记为 Terminating 或 Unknown 状态。想要删除这些状态的 Pod 有三种方法:
- 从集群中删除该 Node。使用公有云时,kube-controller-manager 会在 VM 删除后自动删除对应的 Node。而在物理机部署的集群中,需要管理员手动删除 Node(如 kubectl delete node
。 - Node 恢复正常。Kubelet 会重新跟 kube-apiserver 通信确认这些 Pod 的期待状态,进而再决定删除或者继续运行这些 Pod。
- 用户强制删除。用户可以执行 kubectl delete pods
--grace-period=0 --force 强制删除 Pod。除非明确知道 Pod 的确处于停止状态(比如 Node 所在 VM 或物理机已经关机),否则不建议使用该方法。特别是 StatefulSet 管理的 Pod,强制删除容易导致脑裂或者数据丢失等问题。
Pod 行为异常
这里所说的行为异常是指 Pod 没有按预期的行为执行,比如没有运行 podSpec 里面设置的命令行参数。这一般是 podSpec yaml 文件内容有误,可以尝试使用 --validate 参数重建容器,比如
kubectl delete pod mypod
kubectl create --validate -f mypod.yaml
也可以查看创建后的 podSpec 是否是对的,比如
kubectl get pod mypod -o yaml
修改静态 Pod 的 Manifest 后未自动重建
Kubelet 使用 inotify 机制检测 /etc/kubernetes/manifests 目录(可通过 Kubelet 的 --pod-manifest-path 选项指定)中静态 Pod 的变化,并在文件发生变化后重新创建相应的 Pod。但有时也会发生修改静态 Pod 的 Manifest 后未自动创建新 Pod 的情景,此时一个简单的修复方法是重启 Kubelet。
排查节点高负载
排查思路
通常不是因为内核 bug 导致的高负载,在卡死之前从监控一般能看出一些问题,可以观察下各项监控指标,如果没有相关监控或监控维度较少不足以查出问题,就尝试登录节点抓现场分析。有时负载过高通常使用 ssh 登录不上,如果可以用 vnc,可以尝试下使用 vnc 登录。
线程数量过多
如果 load 高但 CPU 利用率不高,通常是进程/线程数过多,排队等 CPU 切换的进程/线程较多。可以通过 top 或 uptime 来确定 load 大小,大多正常情况下一般不超过 10。
通常在 load 高时执行任何命令都会非常卡,因为执行这些命令也都意味着要创建和执行新的进程,所以下面排查过程中执行命令时需要耐心等待。
看系统中可创建的进程数实际值:
cat /proc/sys/kernel/pid_max
4194304
# 修改方式: sysctl -w kernel.pid_max=65535
通过以下命令统计当前 PID 数量(包括线程):
ps -eLf | wc -l
733
如果数量过多,可以大致扫下有哪些进程,如果有大量重复启动命令的进程,就可能是这个进程对应程序的 bug 导致。
还可以通过以下命令统计线程数排名:
printf "NUM\tPID\tCOMMAND\n" && ps -eLf | awk '{$1=null;$3=null;$4=null;$5=null;$6=null;$7=null;$8=null;$9=null;print}' | sort |uniq -c |sort -rn | head -10
找出线程数量较多的进程,可能就是某个容器的线程泄漏,导致 PID 耗尽。
随便取其中一个 PID,用 nsenter 进入进程 netns:
nsenter -n --target <PID>
然后执行 ip a 看下 IP 地址,如果不是节点 IP,通常就是 Pod IP,可以通过 kubectl get pod -o wide -A | grep
为什么已经用了滚动更新服务还会中断
滚动更新作为一个最佳实践,是每个服务在变更时都会采纳的方案。但在 Kubernetes 实践中,即便使用了滚动更新,也并不一定能够保证服务在更新和维护时总是可用的。
滚动更新的原理
在 Kubernetes 中,我们一般通过 Deployment、Daemonset 等控制器管理 Pod,并且把他们放到 Service 后面,使用 Service 的虚拟 IP 或者负载均衡器 IP 去访问。在 Pod 配置变更(如更新镜像)时,这些控制器默认就会采用滚动更新的方式逐步用新 Pod 替换已有的 Pod。下图所示就是一个典型的 滚动更新过程:
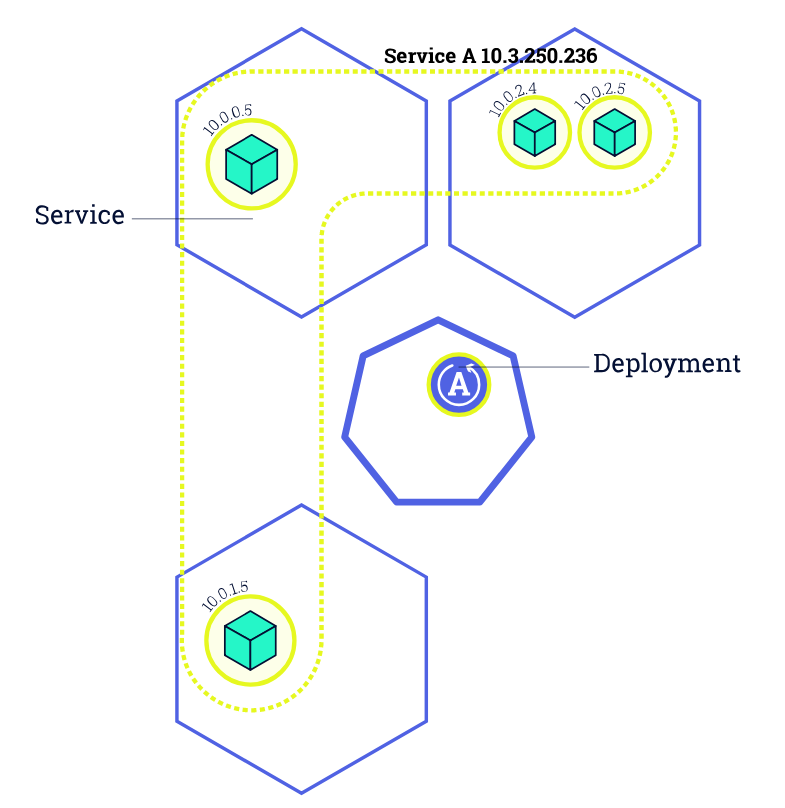
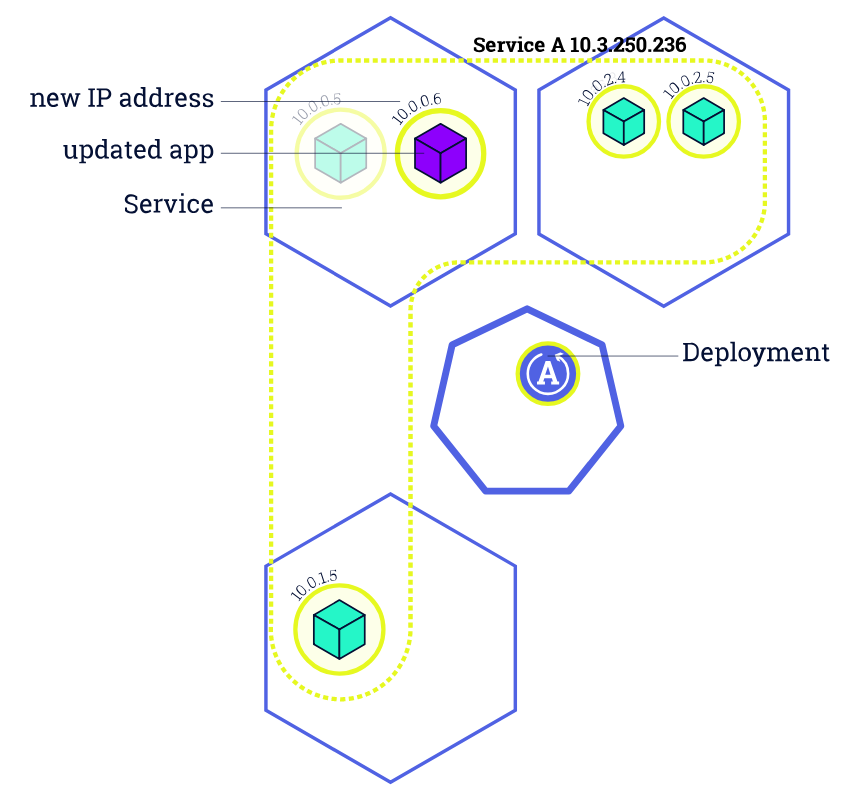
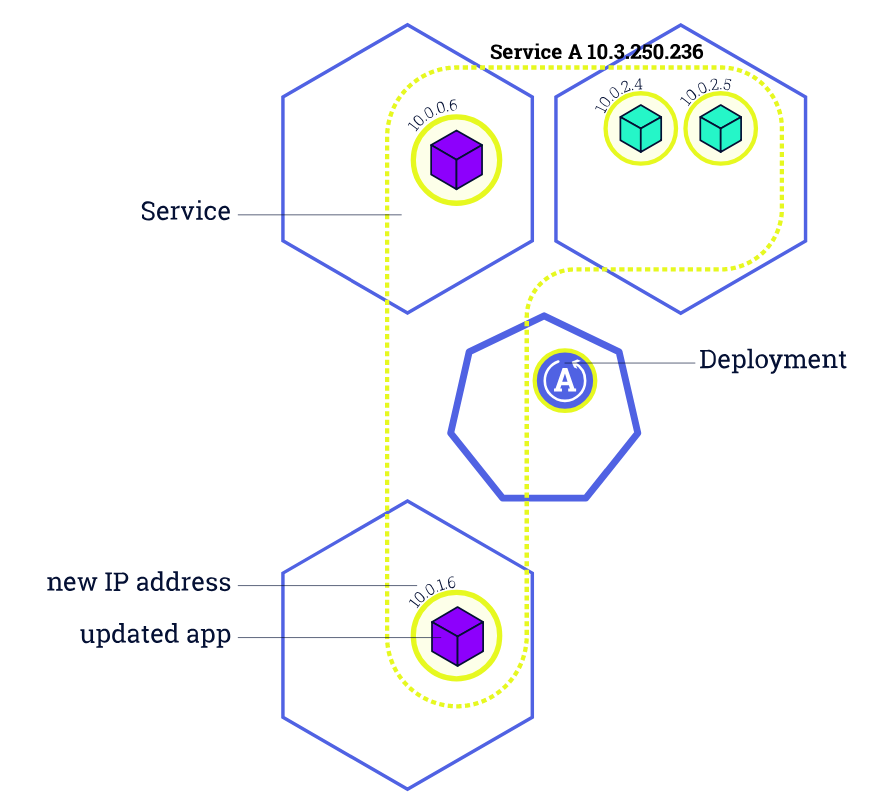
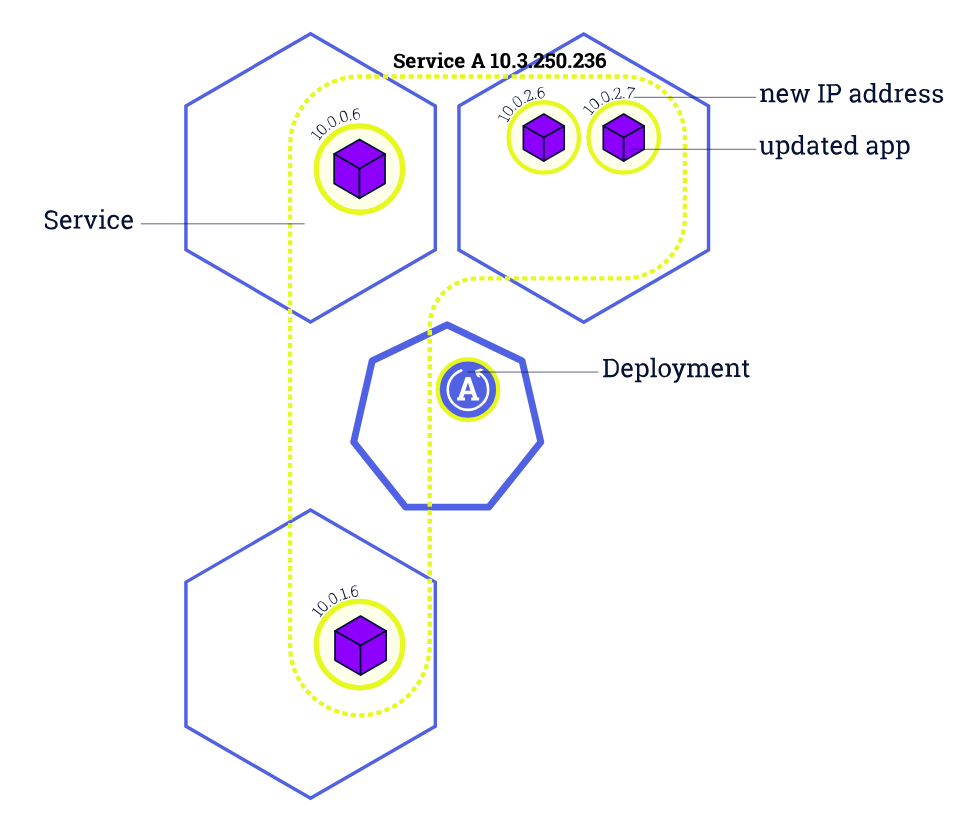
由于新的 Pod Ready 之后才会去删除旧的 Pod,在滚动更新中新的连接过来会自动路由到健康的 Pod 上,所以一般来说,新连接不会出问题,容易出问题的是旧连接。
这儿最容易想到的就是长连接。由于旧 Pod 最终会被删除,已有的长连接总是需要关闭。对这种长连接问题,想要解决,最好的方法是客户端在连接断开后重新建立连接。
而对短连接来说,是不是说就一定没问题呢?其实并不一定。
哪些问题会导致滚动更新时的服务中断
已有Pod过早终止
如果 Pod2 在终止的时候还有未处理完成的连接,那这些连接势必会失败。所以,在终止 Pod2 的时候,需要采用优雅关闭的方式,等待已有连接处理完成之后再终止。
比如,对 Nginx Pod 来说,可以这么做
lifecycle:
preStop:
exec:
command: [
# Gracefully shutdown nginx
"/usr/sbin/nginx", "-s", "quit"
]
新Pod未初始化完成就收到外部请求
很多容器启动时都有一个初始化的过程,虽然 Pod 处于 Running 状态了,但实际上进程还在初始化过程中,不能处理外部过来的请求。所以,在 Pod 启动过程中,需要一种机制,等着容器进程初始化完成之后再接收外部过来的请求。
这个问题比较好解决,Kubernetes 已经提供了 Readiness 探针,只需要应用提供一个探针接口即可。比如
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 5
periodSeconds: 10
httpGet:
port: 80
path: /
异步操作延迟导致iptables中没有健康Endpoint
滚动更新涉及到 kube-apiserver、kubelet、kube-controller-manager(包括 endpoint controller、service controller 和 cloud provider)以及 CNI 插件等。假设新建Pod的名字为Pod2,而旧的Pod名字为Pod1,这些组件在滚动更新过程中的典型过程如下图所示
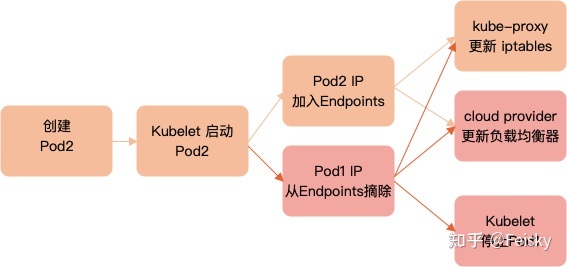
注意 Endpoints 更新(加入新 Pod2 IP 和删除旧 Pod1 IP)以及以后的步骤都是异步的。如果 Pod1 的 IP 摘除时间过早,Pod2 的 IP 还没有更新到 iptables 中,那么新的连接进来就会因为没有健康 Pod 而无法连接。
要解决这个问题不容易,但有一个简单的方法可以绕过去,即在 Zero Downtime Server Updates For Your Kubernetes Cluster 中提到的利用 PreStop Hook 主动等一段时间之后再执行优雅关闭。
lifecycle:
preStop:
exec:
command: [
"sh", "-c",
# Introduce a delay to the shutdown sequence to wait for the
# pod eviction event to propagate. Then, gracefully shutdown
# nginx.
"sleep 15 && /usr/sbin/nginx -s quit",
]
集群维护导致所有Pod同时删除
在集群常规或者异常维护过程中,管理员经常需要驱逐一个或多个异常节点,把这些节点之上的 Pod 迁移到其他节点上面去。如果一个应用的所有 Pod 刚好在这些节点上,那就有可能所有 Pod 都被同时驱逐了,导致一段时间内没有任何健康的容器在运行。
Kubernetes 也为这个问题提供了一种很好的解决方法,即使用
PodDisruptionBudget 给应用设置中断预算,避免所有 Pod 被同时重启。
https://kubernetes.io/docs/tasks/run-application/configure-pdb/
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: nginx
spec:
minAvailable: 1
selector:
matchLabels:
app: nginx
负载均衡器健康检测延迟
使用负载均衡器访问 Service 并且设置了 externalTrafficPolicy 为 Local(为了保留请求原始地址)时,除了上述提到的这些因素,负载均衡器本身提供的健康检测机制也可能会导致新连接短时间内的超时问题。
比如,在执行 kubectl drain node 的同时,对服务进行压力测试,就会发现部分连接断开(下面的例子成功率只有 97.27%):
Requests [total, rate, throughput] 299988, 4999.56, 4856.10
Duration [total, attack, wait] 1m0s, 1m0s, 87.815ms
Latencies [min, mean, 50, 90, 95, 99, max] 65.523ms, 866.673ms, 80.412ms, 2.409s, 5.066s, 10.003s, 10.367s
Bytes In [total, mean] 178585272, 595.31
Bytes Out [total, mean] 0, 0.00
Success [ratio] 97.27%
Status Codes [code:count] 0:8182 200:291806
Error Set:
context deadline exceeded (Client.Timeout or context cancellation while reading body)
这是为什么呢?
- 通常,负载均衡器后端放置的是所有的 Node,利用每个 Service 的 NodePort 来访问 Service。
- 当一个 Pod 被标记为 Terminating 状态时,Pod IP 会被 kube-controller-manager 立刻从 Endpoints 中摘除。
- 这之后,kube-proxy 就会把相应的 IP 从 iptables 中摘除掉,而负载均衡器此时还会继续把新请求发送到该 Pod 所在节点上。
- 由于 Pod IP 已经从 iptables 中清除了,新转发过来的请求就会失败。
对这个问题,一个最简单的方法就是把新的 Pod 调度到已有 Pod 所在节点上,确保 iptables 之后总是有健康的 Pod。
但这个方法不适用于节点驱逐的场景,毕竟节点驱逐之后不允许任何 Pod 继续运行了。所以,在节点驱逐的场景中,应该先从负载均衡器中把节点摘除,确保没有任何请求转发到节点之后,再去执行驱逐操作。
最佳实践
- 所有应用都使用控制器管理,并且必须多副本运行,尽量将副本分散到不同节点上。
- 为所有 Pod 添加 livenessProbe 和 readinessProbe。
- 容器进程在收到 SIGTERM 信号后优雅终止,比如持久化数据、清理网络连接等。
- 终止之前利用 preStop 稍等一会,等待各个组件异步操作完成。
- 必要时才设置 externalTrafficPolicy 为 Local,保留请求原始 IP。
- 使用 PodDiscruptionBudget 为应用设置中断预算,并总是使用 Eviction API(比如 kubectl drain)来清理 Pod,以确保遵循 PodDiscruptionBudget 的配置。
基于这些最佳实践,一个简单的 Nginx 配置就如下所示:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: nginx
spec:
minAvailable: 1
selector:
matchLabels:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
...
template:
spec:
terminationGracePeriodSeconds: 30
containers:
- image: nginx
name: nginx
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 5
periodSeconds: 10
httpGet:
port: 80
path: /
lifecycle:
preStop:
exec:
command: [
"sh", "-c",
# Introduce a delay to the shutdown sequence to wait for the
# pod eviction event to propagate. Then, gracefully shutdown
# nginx.
"sleep 15 && /usr/sbin/nginx -s quit",
]
完整的 Nginx 示例以及压力测试步骤请参考 Kubernetes Handbook。
https://github.com/feiskyer/kubernetes-handbook/tree/master/examples/nginx-ha