
本文介绍连接跟踪(connection tracking,conntrack,CT)的原理,应用,及其在 Linux 内核中的实现。
代码分析基于内核 4.19。
引言
连接跟踪是许多网络应用的基础。例如,Kubernetes Service、ServiceMesh sidecar、 软件四层负载均衡器 LVS/IPVS、Docker network、OVS、iptables 主机防火墙等等,都依赖 连接跟踪功能。
概念
连接跟踪(conntrack)
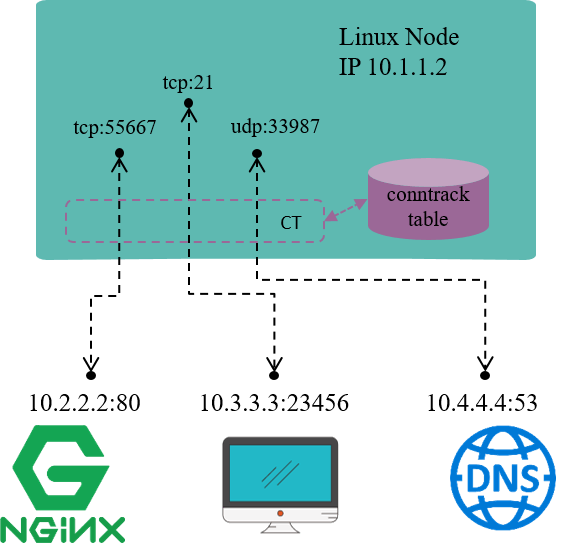
连接跟踪,顾名思义,就是跟踪(并记录)连接的状态。
如图是一台 IP 地址为 10.1.1.2 的 Linux 机器,我们能看到这台机器上有三条 连接:
- 机器访问外部 HTTP 服务的连接(目的端口 80)
- 外部访问机器内 FTP 服务的连接(目的端口 21)
- 机器访问外部 DNS 服务的连接(目的端口 53)
连接跟踪所做的事情就是发现并跟踪这些连接的状态,具体包括:
- 从数据包中提取元组(tuple)信息,辨别数据流(flow)和对应的连接(connection)
- 为所有连接维护一个状态数据库(conntrack table),例如连接的创建时间、发送 包数、发送字节数等等
- 回收过期的连接(GC)
- 为更上层的功能(例如 NAT)提供服务
需要注意的是,连接跟踪中所说的“连接”,概念和 TCP/IP 协议中“面向连接”( connection oriented)的“连接”并不完全相同,简单来说:
- TCP/IP 协议中,连接是一个四层(Layer 4)的概念。
- TCP 是有连接的,或称面向连接的(connection oriented),发送出去的包都要求对端应答(ACK),并且有重传机制
- UDP 是无连接的,发送的包无需对端应答,也没有重传机制
- CT 中,一个元组(tuple)定义的一条数据流(flow )就表示一条连接(connection)。
- 后面会看到 UDP 甚至是 ICMP 这种三层协议在 CT 中也都是有连接记录的
- 但不是所有协议都会被连接跟踪
本文中用到“连接”一词时,大部分情况下指的都是后者,即“连接跟踪”中的“连接”。
网络地址转换(NAT)
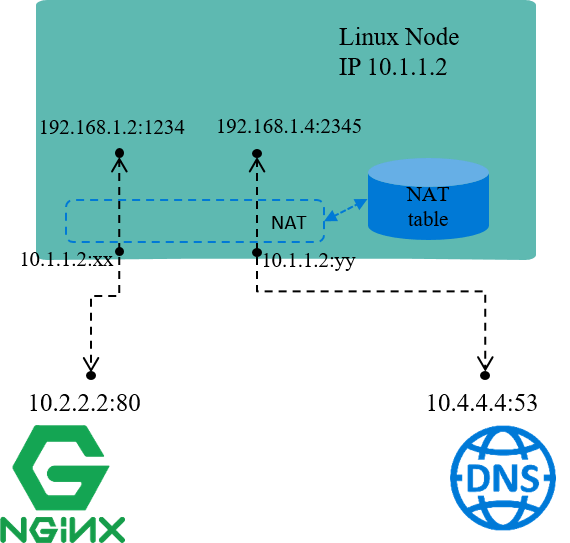
网络地址转换(NAT),意思也比较清楚:
对(数据包的)网络地址(IP + Port)进行转换。
如图,机器自己的 IP 10.1.1.2 是能与外部正常通信的,但 192.168 网段是私有 IP 段,外界无法访问,也就是说源 IP 地址是 192.168 的包,其应答包是无 法回来的。
因此当源地址为 192.168 网段的包要出去时,机器会先将源 IP 换成机器自己的 10.1.1.2 再发送出去;收到应答包时,再进行相反的转换。这就是 NAT 的基本过程。
Docker 默认的 bridge 网络模式就是这个原理 [4]。每个容器会分一个私有网段的 IP 地址,这个 IP 地址可以在宿主机内的不同容器之间通信,但容器流量出宿主机时要进行 NAT。
NAT 又可以细分为几类:
- SNAT:对源地址(source)进行转换
- DNAT:对目的地址(destination)进行转换
- Full NAT:同时对源地址和目的地址进行转换
以上场景属于 SNAT,将不同私有 IP 都映射成同一个“公有 IP”,以使其能访问外部网络服 务。这种场景也属于正向代理。
NAT 依赖连接跟踪的结果。连接跟踪最重要的使用场景就是 NAT。
四层负载均衡(L4 LB)

再将范围稍微延伸一点,讨论一下 NAT 模式的四层负载均衡。
四层负载均衡是根据包的四层信息(例如 src/dst ip, src/dst port, proto)做流量分发。
VIP(Virtual IP)是四层负载均衡的一种实现方式:
- 多个后端真实 IP(Real IP)挂到同一个虚拟 IP(VIP)上
- 客户端过来的流量先到达 VIP,再经负载均衡算法转发给某个特定的后端 IP
如果在 VIP 和 Real IP 节点之间使用的 NAT 技术(也可以使用其他技术),那客户端访 问服务端时,L4LB 节点将做双向 NAT(Full NAT)
原理
了解以上概念之后,我们来思考下连接跟踪的技术原理。
要跟踪一台机器的所有连接状态,就需要
- 拦截(或称过滤)流经这台机器的每一个数据包,并进行分析。
- 根据这些信息建立起这台机器上的连接信息数据库(conntrack table)。
- 根据拦截到的包信息,不断更新数据库
例如,
- 拦截到一个 TCP SYNC 包时,说明正在尝试建立 TCP 连接,需要创建一条新 conntrack entry 来记录这条连接
- 拦截到一个属于已有 conntrack entry 的包时,需要更新这条 conntrack entry 的收发包数等统计信息
除了以上两点功能需求,还要考虑性能问题,因为连接跟踪要对每个包进行过滤和分析 。性能问题非常重要,但不是本文重点,后面介绍实现时会进一步提及。
之外,这些功能最好还有配套的管理工具来更方便地使用。
设计
Netfilter
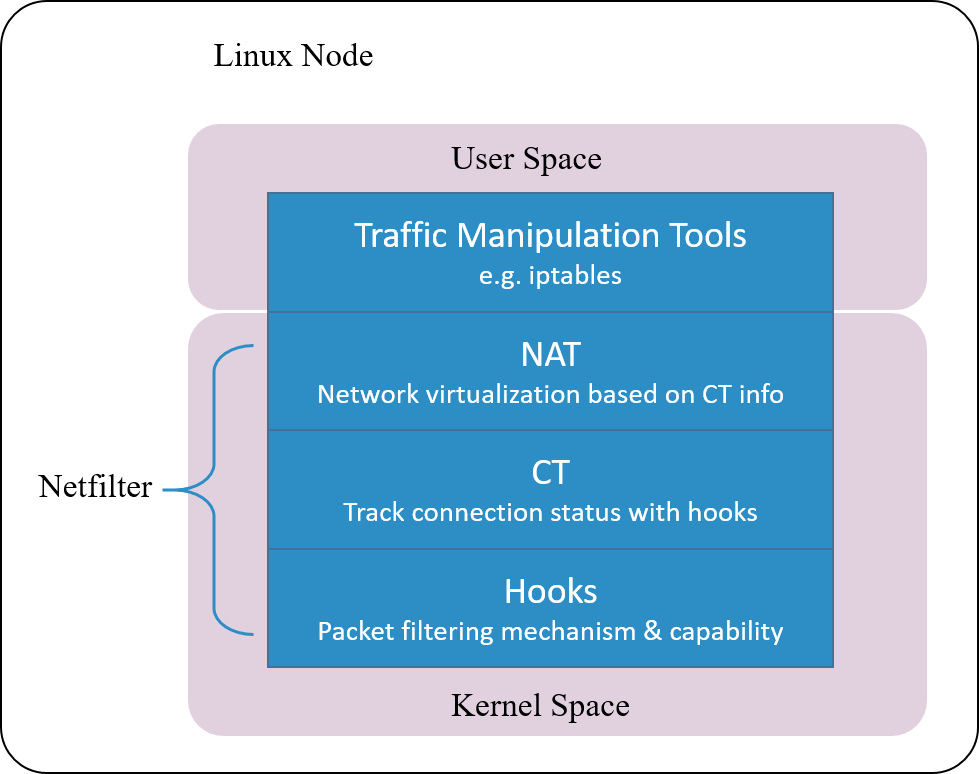
Linux 的连接跟踪是在 Netfilter 中实现的。
Netfilter 是 Linux 内核中一个对数据 包进行控制、修改和过滤(manipulation and filtering)的框架。它在内核协议 栈中设置了若干hook 点,以此对数据包进行拦截、过滤或其他处理。
说地更直白一些,hook 机制就是在数据包的必经之路上设置若干检测点,所有到达这 些检测点的包都必须接受检测,根据检测的结果决定:
- 放行:不对包进行任何修改,退出检测逻辑,继续后面正常的包处理
- 修改:例如修改 IP 地址进行 NAT,然后将包放回正常的包处理逻辑
- 丢弃:安全策略或防火墙功能
连接跟踪模块只是完成连接信息的采集和录入功能,并不会修改或丢弃数据包,后者是其 他模块(例如 NAT)基于 Netfilter hook 完成的。
Netfilter 是最古老的内核框架之一,1998 年开始开发,2000 年合并到 2.4.x 内 核主线版本 [5]。
netfilter数据流图
进一步思考
现在提到连接跟踪(conntrack),可能首先都会想到 Netfilter。连接跟踪概念是独立于 Netfilter 的,Netfilter 只是 Linux 内核中的一种连接跟踪实现。
换句话说,只要具备了 hook 能力,能拦截到进出主机的每个包,完全可以在此基础上自 己实现一套连接跟踪。
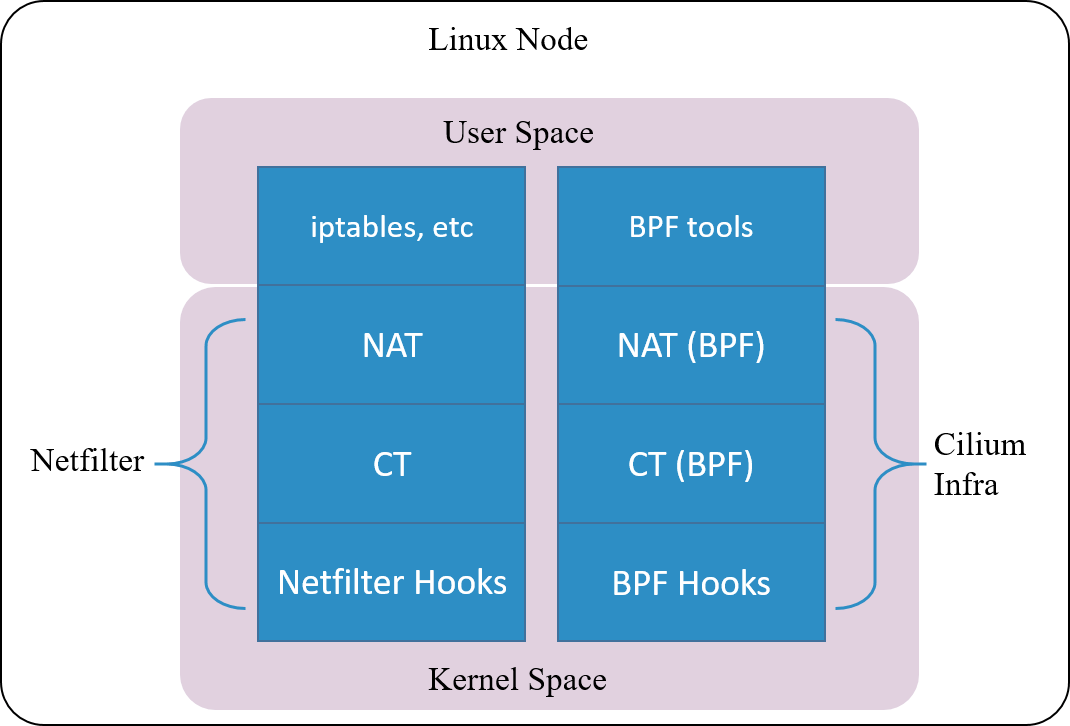
云原生网络方案 Cilium 在 1.7.4+ 版本就实现了这样一套独立的连接跟踪和 NAT 机制 (完备功能需要 Kernel 4.19+)。其基本原理是:
- 基于 BPF hook 实现数据包的拦截功能(等价于 netfilter 里面的 hook 机制)
- 在 BPF hook 的基础上,实现一套全新的 conntrack 和 NAT
因此,即便卸载掉 Netfilter ,也不会影响 Cilium 对 Kubernetes ClusterIP、NodePort、ExternalIPs 和 LoadBalancer 等功能的支持。
由于这套连接跟踪机制是独立于 Netfilter 的,因此它的 conntrack 和 NAT 信息也没有 存储在内核的(也就是 Netfilter 的)conntrack table 和 NAT table。所以常规的 conntrack/netstats/ss/lsof 等工具是看不到的,要使用 Cilium 的命令,例如:
cilium bpf nat list
cilium bpf ct list global
另外,本文会多次提到连接跟踪模块和 NAT 模块独立,但出于性能考虑,具体实现中 二者代码可能是有耦合的。例如 Cilium 做 conntrack 的垃圾回收(GC)时就会顺便把 NAT 里相应的 entry 回收掉,而非为 NAT 做单独的 GC。
Netfilter hook 机制实现
Netfilter 由几个模块构成,其中最主要的是连接跟踪(CT) 模块和网络地址转换(NAT)模块。
CT 模块的主要职责是识别出可进行连接跟踪的包。CT 模块独立于 NAT 模块,但主要目的是服务于后者。
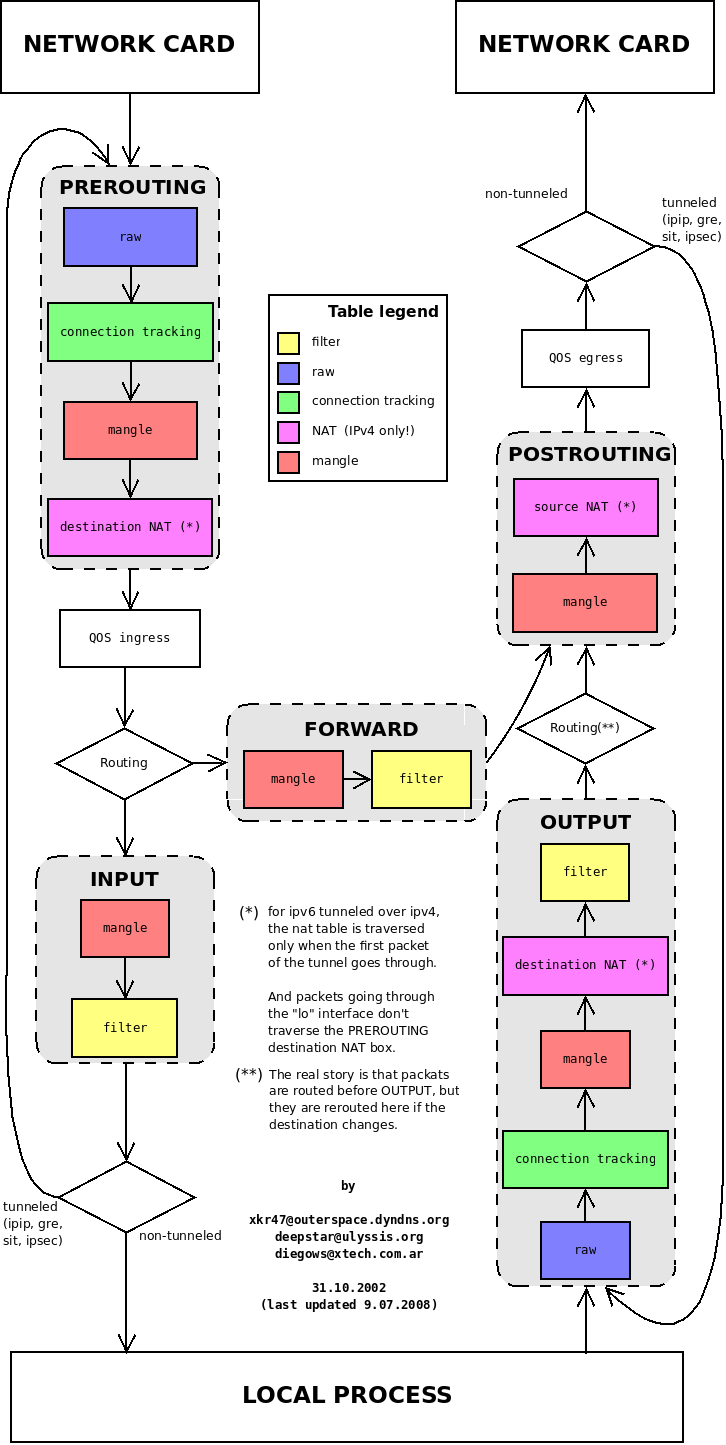
Netfilter 框架
5 个 hook 点
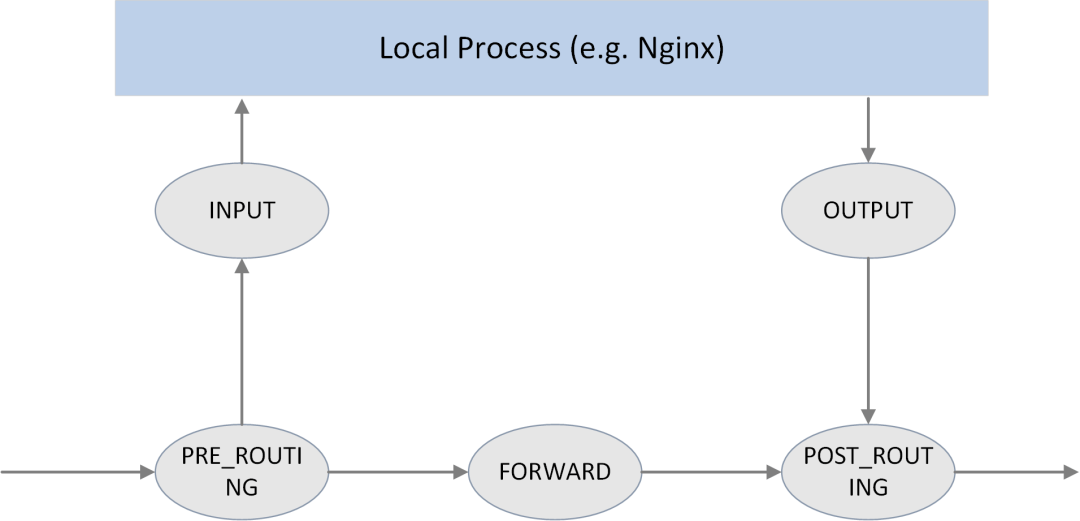
如上图所示,Netfilter 在内核协议栈的包处理路径上提供了 5 个 hook 点,分别是:
// include/uapi/linux/netfilter_ipv4.h
#define NF_IP_PRE_ROUTING 0 /* After promisc drops, checksum checks. */
#define NF_IP_LOCAL_IN 1 /* If the packet is destined for this box. */
#define NF_IP_FORWARD 2 /* If the packet is destined for another interface. */
#define NF_IP_LOCAL_OUT 3 /* Packets coming from a local process. */
#define NF_IP_POST_ROUTING 4 /* Packets about to hit the wire. */
#define NF_IP_NUMHOOKS 5
用户可以在这些 hook 点注册自己的处理函数(handlers)。当有数据包经过 hook 点时, 就会调用相应的 handlers。
另外还有一套 NF_INET_ 开头的定义,include/uapi/linux/netfilter.h。这两套是等价的,从注释看,NF_IP_ 开头的定义可能是为了保持兼容性。
enum nf_inet_hooks {
NF_INET_PRE_ROUTING,
NF_INET_LOCAL_IN,
NF_INET_FORWARD,
NF_INET_LOCAL_OUT,
NF_INET_POST_ROUTING,
NF_INET_NUMHOOKS
};
hook 返回值类型
hook 函数对包进行判断或处理之后,需要返回一个判断结果,指导接下来要对这个包做什 么。可能的结果有:
// include/uapi/linux/netfilter.h
#define NF_DROP 0 // 已丢弃这个包
#define NF_ACCEPT 1 // 接受这个包,继续下一步处理
#define NF_STOLEN 2 // 当前处理函数已经消费了这个包,后面的处理函数不用处理了
#define NF_QUEUE 3 // 应当将包放到队列
#define NF_REPEAT 4 // 当前处理函数应当被再次调用
hook 优先级
每个 hook 点可以注册多个处理函数(handler)。在注册时必须指定这些 handlers 的优先级,这样触发 hook 时能够根据优先级依次调用处理函数。
过滤规则的组织
iptables 是配置 Netfilter 过滤功能的用户空间工具。为便于管理, 过滤规则按功能分为若干 table:
raw
filter
nat
mangle
Netfilter conntrack 实现
连接跟踪模块用于维护可跟踪协议(trackable protocols)的连接状态。也就是说, 连接跟踪针对的是特定协议的包,而不是所有协议的包。稍后会看到它支持哪些协议。
重要结构体和函数
重要结构体:
struct nf_conntrack_tuple {}
定义一个 tuple。
struct nf_conntrack_man_proto {}:manipulable part 中协议相关的部分。