
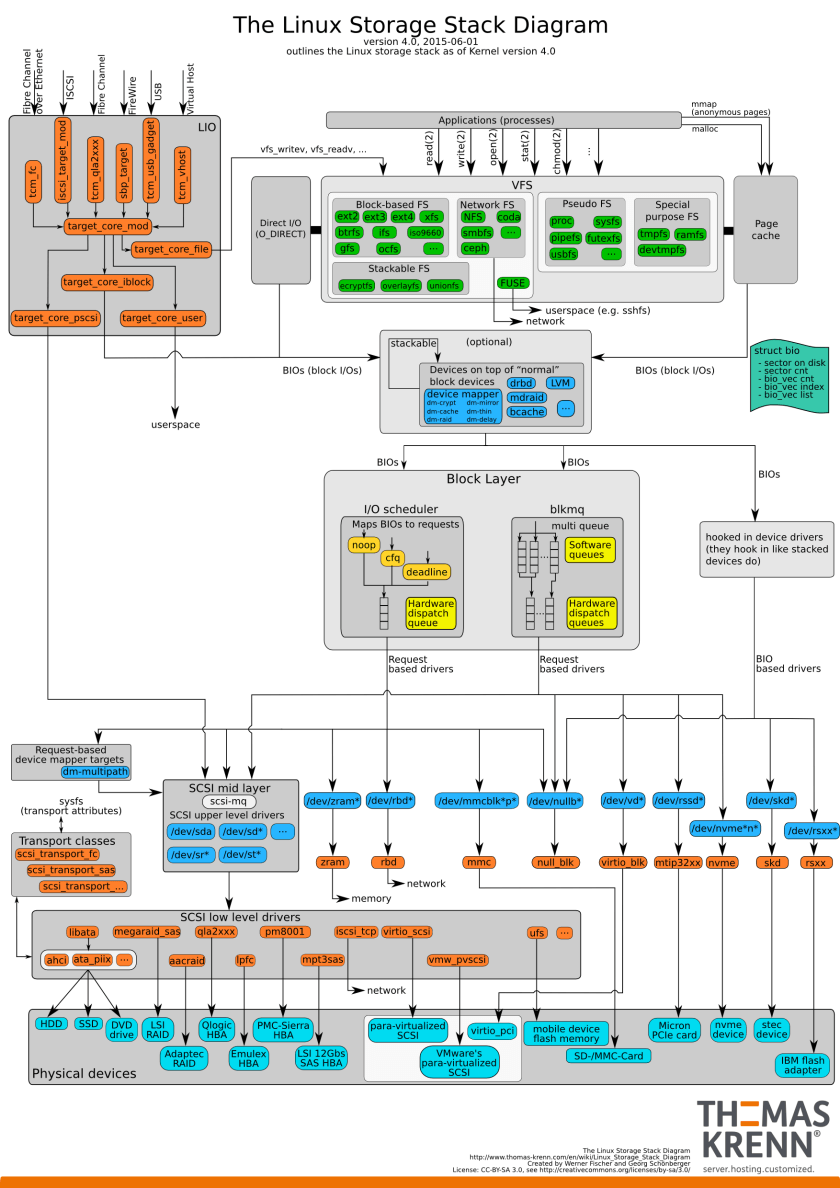
Linux 4.0 IO协议栈框架图
I/O调度程序的总结:
1)当向设备写入数据块或是从设备读出数据块时,请求都被安置在一个队列中等待完成.
2)每个块设备都有它自己的队列.
3)I/O调度程序负责维护这些队列的顺序,以更有效地利用介质.I/O调度程序将无序的I/O操作变为有序的I/O操作.
4)内核必须首先确定队列中一共有多少个请求,然后才开始进行调度.
I/O调度的4种算法
CFQ(完全公平排队I/O调度程序)
在最新的内核版本和发行版中,都选择CFQ做为默认的I/O调度器,对于通用的服务器也是最好的选择。CFQ对于多媒体应用(video,audio)和桌面系统是最好的选择。CFQ赋予I/O请求一个优先级,而I/O优先级请求独立于进程优先级,高优先级的进程的读写不能自动地继承高的I/O优先级。
对于很多IO压力较大的场景就并不是很适应,尤其是IO压力集中在某些进程上的场景。因为这种场景我们需要更多的满足某个或者某几个进程的IO响应速度,而不是让所有的进程公平的使用IO,比如数据库应用。
CFQ试图均匀地分布对I/O带宽的访问,避免进程被饿死并实现较低的延迟,是deadline和as调度器的折中.
工作原理:
CFQ为每个进程/线程,单独创建一个队列来管理该进程所产生的请求,也就是说每个进程一个队列,每个队列按照上述规则进行merge和sort。各队列之间的调度使用时间片来调度,以此来保证每个进程都能被很好的分配到I/O带宽.I/O调度器每次执行一个进程的4次请求。可以调 queued 和 quantum 来优化
NOOP(电梯式调度程序)
在Linux2.4或更早的版本的调度程序,那时只有这一种I/O调度算法.I/O请求被分配到队列,调度由硬件进行,只有当CPU时钟频率比较有限时进行。
Noop对于I/O不那么操心,对所有的I/O请求都用FIFO队列形式处理,默认认为 I/O不会存在性能问题。这也使得CPU也不用那么操心。它像电梯的工作主法一样对I/O请求进行组织,当有一个新的请求到来时,它将请求合并到最近的请求之后,以此来保证请求同一介质.
NOOP倾向饿死读而利于写.
NOOP对于闪存设备,RAM,嵌入式系统是最好的选择.
电梯算法饿死读请求的解释:
因为写请求比读请求更容易.
写请求通过文件系统cache,不需要等一次写完成,就可以开始下一次写操作,写请求通过合并,堆积到I/O队列中.
读请求需要等到它前面所有的读操作完成,才能进行下一次读操作.在读操作之间有几毫秒时间,而写请求在这之间就到来,饿死了后面的读请求.
Deadline(截止时间调度程序)
通过时间以及硬盘区域进行分类,这个分类和合并要求类似于noop的调度程序.
Deadline确保了在一个截止时间内服务请求,这个截止时间是可调整的,而默认读期限短于写期限.这样就防止了写操作因为不能被读取而饿死的现象.
Deadline对数据库环境(ORACLE RAC,MYSQL等)是最好的选择。
deadline实现了四个队列,其中两个分别处理正常read和write,按扇区号排序,进行正常io的合并处理以提高吞吐量.因为IO请求可能会集中在某些磁盘位置,这样会导致新来的请求一直被合并,于是可能会有其他磁盘位置的io请求被饿死。于是实现了另外两个处理超时read和write的队列,按请求创建时间排序,如果有超时的请求出现,就放进这两个队列,调度算法保证超时(达到最终期限时间)的队列中的请求会优先被处理,防止请求被饿死。由于deadline的特点,无疑在这里无法区分进程,也就不能实现针对进程的io资源控制。
AS(预料I/O调度程序)
本质上与Deadline一样,但在最后一次读操作后,要等待6ms,才能继续进行对其它I/O请求进行调度.可以从应用程序中预订一个新的读请求,改进读操作的执行,但以一些写操作为代价.它会在每个6ms中插入新的I/O操作,而会将一些小写入流合并成一个大写入流,用写入延时换取最大的写入吞吐量.
AS适合于写入较多的环境,比如文件服务器
AS对数据库环境表现很差.
总结
从原理上看:
1、cfq是一种比较通用的调度算法,是一种以进程为出发点考虑的调度算法,保证大家尽量公平。
2、deadline是一种以提高机械硬盘吞吐量为思考出发点的调度算法,只有当有io请求达到最终期限的时候才进行调度,非常适合业务比较单一并且IO压力比较重的业务,比如数据库。
3、noop 思考对象如果拓展到固态硬盘,那么你就会发现,无论cfq还是deadline,都是针对机械硬盘的结构进行的队列算法调整,而这种调整对于固态硬盘来说,完全没有意义。对于固态硬盘来说,IO调度算法越复杂,效率就越低,因为额外要处理的逻辑越多。所以,固态硬盘这种场景下,使用noop是最好的,deadline次之,而cfq由于复杂度的原因,无疑效率最低。
单队列与多队列
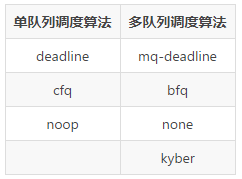
单队列的架构,一个块设备只有一个全局队列,所有请求都要往这个队列里面塞,这在多核高并发的情况下,尤其像服务器动则32个核的情况下,为了保证互斥而加的锁就导致了非常大的开销。此外,如果磁盘支持多队列并行处理,单队列的模型不能充分发挥其优越的性能。
多队列的架构下,创建了Software queues和Hardware dispatch queues两级队列。Software queues是每个CPU core一个队列,且在其中实现IO调度。由于每个CPU一个单独队列,因此不存在锁竞争问题。Hardware Dispatch Queues的数量跟硬件情况有关,每个磁盘一个队列,如果磁盘支持并行N个队列,则也会创建N个队列。在IO请求从Software queues提交到Hardware Dispatch Queues的过程中是需要加锁的。理论上,多队列的架构的效率最差也只是跟单队列架构持平。
Kyber(Multiqueue)
专为快速多队列设备而设计,相对简单。 有两个请求队列:
1、同步请求(例如被阻止的读取)
2、异步请求(例如写入)
对队列发送的请求操作数量严格限制。 理论上,这限制了等待要调度的请求的时间,因此应该为高优先级的请求提供快速完成时间。
I/O调度方法的查看与设置
查看当前系统的I/O调度方法
# 单队列
cat /sys/block/sda/queue/scheduler
noop anticipatory deadline [cfq]
# 多队列
cat /sys/block/vda/queue/scheduler
[mq-deadline] kyber bfq none
临地更改I/O调度方法:
例如:想更改到noop电梯调度算法:
echo noop > /sys/block/sda/queue/scheduler
永久的更改I/O调度方法(grub)
修改内核引导参数,加入elevator=调度程序名
CentOS 5-6
CentOS 5、CentOS 6 中通过添加 elevator=deadline 到 /etc/grub.conf 配置文件中包含 kernel 所在行的行尾。
vim cat /etc/grub.conf
title Red Hat Enterprise Linux Server (2.6.9-67.EL)
root (hd0,0)
kernel /vmlinuz-2.6.9-67.EL ro root=/dev/vg0/lv0 levator=deadline
initrd /initrd-2.6.9-67.EL.img
CentOS 7-8
CentOS 7 中通过添加 elevator=deadline 到 /etc/default/grub 配置文件中包含 GRUB_CMDLINE_LINUX 所在行。
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="vconsole.font=latarcyrheb-sun16 vconsole.keymap=us rd.lvm.lv=vgroot/root elevator=deadline crashkernel=auto rhgb quiet"
GRUB_DISABLE_RECOVERY="true"
CentOS 7 在修改完 /etc/default/grub 后需要重建 /boot/grub2/grub.cfg 文件,然后重启后才能最终生效。重建 grub 的配置文件的命令如下:
# On BIOS-based machines
grub2-mkconfig -o /boot/grub2/grub.cfg
# On UEFI-based machines
grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
在grub.cfg文件设置IO调度策略不生效
检查 /lib/udev/rules.d/ 中是否有 60-block-scheduler.rules 文件。
/lib/udev/rules.d/60-block-scheduler.rules里面指定了bfq,把启动参数的配置覆盖了,启动参数想生效的话,删掉/lib/udev/rules.d/60-block-scheduler.rules里面的bfq就好
永久的更改I/O调度方法(rule)
vim /etc/udev/rules.d/60-ioschedulers.rules
# set scheduler for NVMe
ACTION=="add|change", KERNEL=="nvme[0-9]n[0-9]", ATTR{queue/scheduler}="none"
# set scheduler for SSD and eMMC
ACTION=="add|change", KERNEL=="sd[a-z]|mmcblk[0-9]*", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="mq-deadline"
# set scheduler for rotating disks
ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="1", ATTR{queue/scheduler}="bfq"
这时需要 Reboot
或者手动加载 force udev Loading new rules.
# 如果规则无法自动重新加载:
udevadm control --reload
# 要手动强制 udev 触发您的规则
udevadm trigger
udev 会自动检测对规则文件的更改,因此更改会立即生效,无需重新启动 udev。 但是,规则不会在现有设备上自动重新触发。 热插拔设备,例如 USB 设备,可能需要重新连接才能使新规则生效,或者至少卸载并重新加载 ohci-hcd 和 ehci-hcd 内核模块,从而重新加载所有 USB 驱动程序。这时也可以使用上面命令手动触发。
调度算法参数调整
查看当前调度算法可调参数:
grep -vH "123" /sys/block/vda/queue/iosched/*
/sys/block/vda/queue/iosched/fifo_batch:16
/sys/block/vda/queue/iosched/front_merges:1
/sys/block/vda/queue/iosched/read_expire:500
/sys/block/vda/queue/iosched/write_expire:5000
/sys/block/vda/queue/iosched/writes_starved:2
cfq 参数调整
理解整个调度流程有助于我们决策如何调整cfq的相关参数。所有cfq的可调参数都可以在/sys/class/block/sda/queue/iosched/目录下找到,当然,在你的系统上,请将sda替换为相应的磁盘名称。我们来看一下都有什么:

这些参数部分是跟机械硬盘磁头寻道方式有关的:
back_seek_max
磁头可以向后寻址的最大范围,默认值为16M。
back_seek_penalty
向后寻址的惩罚系数。这个值是跟向前寻址进行比较的。
以上两个是为了防止磁头寻道发生抖动而导致寻址过慢而设置的。基本思路是这样,一个io请求到来的时候,cfq会根据其寻址位置预估一下其磁头寻道成本。
设置一个最大值back_seek_max,对于请求所访问的扇区号在磁头后方的请求,只要寻址范围没有超过这个值,cfq会像向前寻址的请求一样处理它。
再设置一个评估成本的系数back_seek_penalty,相对于磁头向前寻址,向后寻址的距离为1/2(1/back_seek_penalty)时,cfq认为这两个请求寻址的代价是相同。
这两个参数实际上是cfq判断请求合并处理的条件限制,凡事复合这个条件的请求,都会尽量在本次请求处理的时候一起合并处理。
fifo_expire_async
设置异步请求的超时时间。
同步请求和异步请求是区分不同队列处理的,cfq在调度的时候一般情况都会优先处理同步请求,之后再处理异步请求,除非异步请求符合上述合并处理的条件限制范围内。
当本进程的队列被调度时,cfq会优先检查是否有异步请求超时,就是超过fifo_expire_async参数的限制。如果有,则优先发送一个超时的请求,其余请求仍然按照优先级以及扇区编号大小来处理。
fifo_expire_sync
这个参数跟上面的类似,区别是用来设置同步请求的超时时间。
slice_idle
参数设置了一个等待时间。这让cfq在切换cfq_queue或service tree的时候等待一段时间,目的是提高机械硬盘的吞吐量。
一般情况下,来自同一个cfq_queue或者service tree的IO请求的寻址局部性更好,所以这样可以减少磁盘的寻址次数。这个值在机械硬盘上默认为非零。
当然在固态硬盘或者硬RAID设备上设置这个值为非零会降低存储的效率,因为固态硬盘没有磁头寻址这个概念,所以在这样的设备上应该设置为0,关闭此功能。
group_idle
这个参数也跟上一个参数类似,区别是当cfq要切换cfq_group的时候会等待一段时间。
在cgroup的场景下,如果我们沿用slice_idle的方式,那么空转等待可能会在cgroup组内每个进程的cfq_queue切换时发生。
这样会如果这个进程一直有请求要处理的话,那么直到这个cgroup的配额被耗尽,同组中的其它进程也可能无法被调度到。这样会导致同组中的其它进程饿死而产生IO性能瓶颈。
在这种情况下,我们可以将slice_idle = 0而group_idle = 8。这样空转等待就是以cgroup为单位进行的,而不是以cfq_queue的进程为单位进行,以防止上述问题产生。
low_latency
这个是用来开启或关闭cfq的低延时(low latency)模式的开关。
当这个开关打开时,cfq将会根据target_latency的参数设置来对每一个进程的分片时间(slice time)进行重新计算。
这将有利于对吞吐量的公平(默认是对时间片分配的公平)。
关闭这个参数(设置为0)将忽略target_latency的值。这将使系统中的进程完全按照时间片方式进行IO资源分配。这个开关默认是打开的。
我们已经知道cfq设计上有“空转”(idling)这个概念,目的是为了可以让连续的读写操作尽可能多的合并处理,减少磁头的寻址操作以便增大吞吐量。
如果有进程总是很快的进行顺序读写,那么它将因为cfq的空转等待命中率很高而导致其它需要处理IO的进程响应速度下降,如果另一个需要调度的进程不会发出大量顺序IO行为的话,系统中不同进程IO吞吐量的表现就会很不均衡。
就比如,系统内存的cache中有很多脏页要写回时,桌面又要打开一个浏览器进行操作,这时脏页写回的后台行为就很可能会大量命中空转时间,而导致浏览器的小量IO一直等待,让用户感觉浏览器运行响应速度变慢。
这个low_latency主要是对这种情况进行优化的选项,当其打开时,系统会根据target_latency的配置对因为命中空转而大量占用IO吞吐量的进程进行限制,以达到不同进程IO占用的吞吐量的相对均衡。这个开关比较合适在类似桌面应用的场景下打开。
target_latency
当low_latency的值为开启状态时,cfq将根据这个值重新计算每个进程分配的IO时间片长度。
quantum
这个参数用来设置每次从cfq_queue中处理多少个IO请求。在一个队列处理事件周期中,超过这个数字的IO请求将不会被处理。这个参数只对同步的请求有效。
slice_sync
当一个cfq_queue队列被调度处理时,它可以被分配的处理总时间是通过这个值来作为一个计算参数指定的。公式为:time_slice = slice_sync + (slice_sync/5 * (4 – prio))。这个参数对同步请求有效。
slice_async
这个值跟上一个类似,区别是对异步请求有效。
slice_async_rq
这个参数用来限制在一个slice的时间范围内,一个队列最多可以处理的异步请求个数。请求被处理的最大个数还跟相关进程被设置的io优先级有关。
cfq的IOPS模式
我们已经知道,默认情况下cfq是以时间片方式支持的带优先级的调度来保证IO资源占用的公平。
高优先级的进程将得到更多的时间片长度,而低优先级的进程时间片相对较小。
当我们的存储是一个高速并且支持NCQ(原生指令队列)的设备的时候,我们最好可以让其可以从多个cfq队列中处理多路的请求,以便提升NCQ的利用率。
此时使用时间片的分配方式分配资源就显得不合时宜了,因为基于时间片的分配,同一时刻最多能处理的请求队列只有一个。
这时,我们需要切换cfq的模式为IOPS模式。切换方式很简单,就是将slice_idle=0即可。内核会自动检测你的存储设备是否支持NCQ,如果支持的话cfq会自动切换为IOPS模式。
另外,在默认的基于优先级的时间片方式下,我们可以使用ionice命令来调整进程的IO优先级。进程默认分配的IO优先级是根据进程的nice值计算而来的,计算方法可以在man ionice中看到,这里不再废话。
deadline的参数调整
deadline的可调参数相对较少,包括:

read_expire
读请求的超时时间设置,单位为ms。当一个读请求入队deadline的时候,其过期时间将被设置为当前时间+read_expire,并放倒fifo_list中进行排序。
write_expire
写请求的超时时间设置,单位为ms。功能根读请求类似。
fifo_batch
在顺序(sort_list)请求进行处理的时候,deadline将以batch为单位进行处理。
每一个batch处理的请求个数为这个参数所限制的个数。在一个batch处理的过程中,不会产生是否超时的检查,也就不会产生额外的磁盘寻道时间。
这个参数可以用来平衡顺序处理和饥饿时间的矛盾,当饥饿时间需要尽可能的符合预期的时候,我们可以调小这个值,以便尽可能多的检查是否有饥饿产生并及时处理。
增大这个值当然也会增大吞吐量,但是会导致处理饥饿请求的延时变长。
writes_starved
这个值是在上述deadline出队处理第一步时做检查用的。用来判断当读队列不为空时,写队列的饥饿程度是否足够高,以时deadline放弃读请求的处理而处理写请求。
当检查存在有写请求的时候,deadline并不会立即对写请求进行处理,而是给相关数据结构中的starved进行累计。
如果这是第一次检查到有写请求进行处理,那么这个计数就为1。如果此时writes_starved值为2,则我们认为此时饥饿程度还不足够高,所以继续处理读请求。
只有当starved >= writes_starved的时候,deadline才回去处理写请求。可以认为这个值是用来平衡deadline对读写请求处理优先级状态的,这个值越大,则写请求越被滞后处理,越小,写请求就越可以获得趋近于读请求的优先级。
front_merges
当一个新请求进入队列的时候,如果其请求的扇区距离当前扇区很近,那么它就是可以被合并处理的。
而这个合并可能有两种情况:
- 是向当前位置后合并
- 是向前合并。
在某些场景下,向前合并是不必要的,那么我们就可以通过这个参数关闭向前合并。默认deadline支持向前合并,设置为0关闭。
noop 调度器
noop调度器是最简单的调度器。它本质上就是一个链表实现的fifo队列,并对请求进行简单的合并处理。调度器本身并没有提供任何可疑配置的参数
各种调度器的应用场景选择
从原理上看,cfq是一种比较通用的调度算法,它是一种以进程为出发点考虑的调度算法,保证大家尽量公平。
deadline是一种以提高机械硬盘吞吐量为思考出发点的调度算法,尽量保证在有io请求达到最终期限的时候进行调度。非常适合业务比较单一并且IO压力比较重的业务,比如数据库。
对于固态硬盘来说,IO调度算法越复杂,额外要处理的逻辑就越多,效率就越低。所以,固态硬盘这种场景下使用noop是最好的,deadline次之,而cfq由于复杂度的原因,无疑效率最低。
相关内核参数调优
调整脏数据刷新策略,减小磁盘的IO压力
原理
PageCache中需要回写到磁盘的数据为脏数据。在应用程序通知系统保存脏数据时,应用可以选择直接将数据写入磁盘(O_DIRECT),或者先写到PageCache(非O_DIRECT模式)。非O_DIRECT模式,对于缓存在PageCache中的数据的操作,都在内存中进行,减少了对磁盘的操作。
修改方式
系统中提供了以下参数来调整策略:
/proc/sys/vm/dirty_expire_centiseconds
此参数用于表示脏数据在缓存中允许保留的时长,即时间到后需要被写入到磁盘中。此参数的默认值为30s(3000 个1/100秒)。如果业务的数据是连续性的写,可以适当调小此参数,这样可以避免IO集中,导致突发的IO等待。可以通过echo命令修改:
echo 2000 > /proc/sys/vm/dirty_expire_centisecs
/proc/sys/vm/dirty_background_ratio
脏页面占用总内存最大的比例(以memfree+Cached-Mapped为基准),超过这个值,pdflush线程会刷新脏页面到磁盘。增加这个值,系统会分配更多的内存用于写缓冲,因而可以提升写磁盘性能。但对于磁盘写入操作为主的的业务,可以调小这个值,避免数据积压太多最后成为瓶颈,可以结合业务并通过观察await的时间波动范围来识别。此值的默认值是10,可以通过echo来调整:
echo 8 > /proc/sys/vm/dirty_background_ratio
/proc/sys/vm/dirty_ratio
为脏页面占用总内存最大的比例,超过这个值,系统不会新增加脏页面,文件读写也变为同步模式。文件读写变为同步模式后,应用程序的文件读写操作的阻塞时间变长,会导致系统性能变慢。此参数的默认值为40,对于写入为主的业务,可以增加此参数,避免磁盘过早的进入到同步写状态。
注意
如果加大了脏数据的缓存大小和时间,在意外断电情况下,丢失数据的概率会变多。因此对于需要立即存盘的数据,应该采用O_DIRECT模式避免关键数据的丢失。
调整磁盘文件预读参数
原理
文件预取的原理,就是根据局部性原理,在读取数据时,会多读一定量的相邻数据缓存到内存。如果预读的数据是后续会使用的数据,那么系统性能会提升,如果后续不使用,就浪费了磁盘带宽。在磁盘顺序读的场景下,调大预取值效果会尤其明显。
修改方式
文件预取参数由文件read_ahead_kb指定,CentOS中为“/sys/block/$DEVICE-NAME/queue/read_ahead_kb”($DEVICE-NAME为磁盘名称),如果不确定,则通过命令以下命令来查找。
find / -name read_ahead_kb
此参数的默认值128KB,可使用echo来调整,仍以CentOS为例,将预取值调整为4096KB:
echo 4096 > /sys/block/$DEVICE-NAME /queue/read_ahead_kb
注意
这个值实际和读模型相关,要根据实际业务调整。