
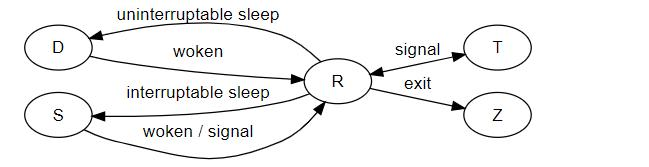
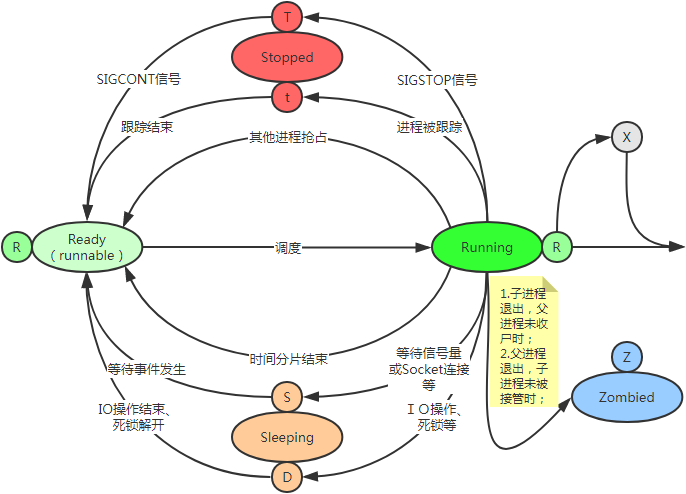
Linux上进程的状态
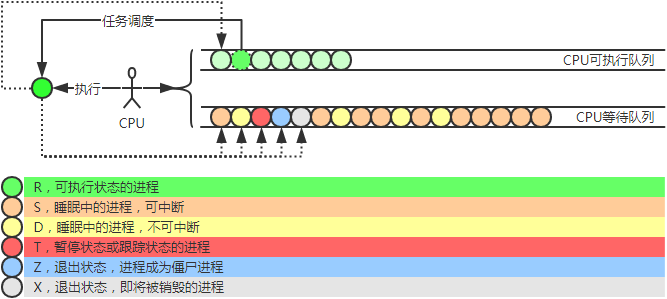
R:Runnable(运行):正在运行或在运行队列中等待S:sleeping(中断):可中断状态睡眠,表示进程因等待某个事件而被系统挂起(阻塞态)。当进程等待的事件发生时,就会被唤醒并进入R状态D:uninterruptible sleep(不可中断):不可中断状态睡眠,一般表示进程正在跟硬件发送交互,并且交互过程中不允许被其他进程或中断打断Z:zombie(僵死):进程已终止,但进程描述还在,直到父进程调用wait4()系统调用后释放T:traced or stoppd(停止):进程收到SiGSTOP,SIGSTP,SIGTOU信号后停止运行I:空闲状态(idle),空闲状态。用在不可中断睡眠的内核线程上。硬件交互导致的不可中断进程用D表示,但对某些内核线程来说,处在不可中断睡眠时有可能实际上并没有任何负载。P:等待交换页W:无驻留页 has no resident pages 没有足够的记忆体分页可分配X:退出状态,进程即将被销毁。非常短暂的,几乎不可能通过ps命令捕捉到。
S 即 sleep进程,休眠进程。其又分为两种:
- Interruptible Sleep(可中断睡眠,在ps命令中显示“S”)。处在这种睡眠状态的进程是可以通过给它发送signal来唤醒的,比如发HUP信号给nginx的master进程可以让nginx重新加载配置文件而不需要重新启动nginx进程;
- Uninterruptible Sleep(不可中断睡眠,在ps命令中显示“D”)。处在这种状态的进程不接受外来的任何signal,这也是为什么之前我无法用kill杀掉这些处于D状态的进程,无论是“kill”, “kill -9”还是“kill -15”,因为它们压根儿就不受这些信号的支配。
D 即上面提到的Uninterruptible Sleep ,如果从广义上来分,D状态算是一种特殊的S状态进程。进程为什么会被置于D状态呢?
- D状态的进程通常是在等待IO,比如磁盘IO,网络IO,其他外设IO,如果进程正在等待的IO在较长的时间内都没有响应,那么就很会不幸地被ps看到了,同时也就意味着很有可能有IO出了问题,可能是外设本身出了故障,也可能是比如NFS挂载的远程文件系统已经不可访问了。
- 正是因为得不到IO的响应,进程才进入了uninterruptible sleep状态,所以要想使进程从uninterruptible sleep状态恢复,就得使进程等待的IO恢复,比如如果是因为从远程挂载的NFS卷不可访问导致进程进入uninterruptible sleep状态的,那么可以通过恢复该NFS卷的连接来使进程的IO请求得到满足,除此之外,要想干掉处在D状态进程就只能重启整个Linux系统(D进程并不能通过kill 和kill -9 杀掉) 。
状态后缀表示:
<:优先级高的进程
N:优先级低的进程
L:有些页被锁进内存
s:进程的领导者(在它之下有子进程)
l:ismulti-threaded (using CLONE_THREAD, like NPTL pthreads do)
+:位于后台的进程组
进程状态转换
进程调度
实例讲解
Linux中进程的D状态会引起CPU-Load虚高
Linux上的 load average 除了包括正在使用CPU的进程数量和正在等待 CPU 的进程数量之外,还包括 uninterruptible sleep 的进程数量。
通常等待 IO 设备、等待网络的时候,进程会处于 uninterruptible sleep 状态。Linux 设计者的逻辑是,uninterruptible sleep 应该都是很短暂的,很快就会恢复运行,所以被等同于 runnable。然而uninterruptible sleep 即使再短暂也是 sleep,何况现实世界中 uninterruptible sleep 未必很短暂,大量的、或长时间的 uninterruptible sleep 通常意味着 IO 设备遇到了瓶颈。众所周知,sleep 状态的进程是不需要 CPU 的,即使所有的 CPU 都空闲,正在 sleep 的进程也是运行不了的,所以 sleep 进程的数量绝对不适合用作衡量 CPU 负载的指标,Linux 把 uninterruptible sleep 进程算进 load average 的做法直接颠覆了 load average 的本来意义。所以在 Linux 系统上,load average 这个指标基本失去了作用,因为你不知道它代表什么意思,当看到 load average 很高的时候,你不知道是 runnable 进程太多还是 uninterruptible sleep 进程太多,也就无法判断是 CPU 不够用还是 IO 设备有瓶颈。
大量僵尸进程导致CPU负载虚高
常情况下,当一个进程创建了子进程后,它应该通过系统调用wait0或者waitpid0等待子进程结束,回收子进程的资源;而子进程在结束时,会向它的父进程发送SIGCHLD信号,所以,父进程还可以注册 SIGCHLD信号的处理函数,异步回收资源。
如果父进程没这么做,或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经提前退出,那这时的子进程就会变成僵尸进程。换句话说,父亲应该一直对儿子负责,善始善终,如果不作为或者跟不上,都会导致“问题少年”的出现。
通常,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程退出后,由init 进程回收后也会消亡。
一旦父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸状态。大量的僵尸进程会用尽PID进程号,导致新进程不能创建,所以这种情况一定要避免。
故障处理
既然僵尸进程是因为父进程没有回收子进程的资源而出现的,那么,要解决掉它们,就要找到它们的根儿,也就是找出父进程,然后在父进程里解决。
临时解决
ps -A -ostat,ppid,pid,cmd | grep -e '^[Zz]'
#!/bin/bash
for ZOMBIE in `ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]' | awk '{print $2}'`
do
kill -9 $ZOMBIE
done
找到问题根因
1 使用pstree命令找出进程的父进程
# -a 表示输出命令行选项
# p 表 PID
# s 表示指定进程的父进程
$ pstree -aps 3084
systemd,1
└─dockerd,15006 -H fd://
└─docker-containe,15024 --config /var/run/docker/containerd/containerd.toml
└─docker-containe,3991 -namespace moby -workdir...
└─app,4009
└─(app,3084)
运行完,你会发现 3084 号进程的父进程是 4009,也就是 app 应用。
2 接着需查看app应用程序的代码,看看子进程结束的处理是否正确,比如有没有调用 wait() 或 waitpid() ,抑或是,有没有注册 SIGCHLD 信号的处理函数。