
深入理解 iostat
基本用法
iostat -mtx 2
-m Display statistics in megabytes per second.
-t Print the time for each report displayed. The timestamp format may depend on the value of the S_TIME_FORMAT environment variable (see below).
-x Display extended statistics.
含义是说,每2秒钟采集一组数据:
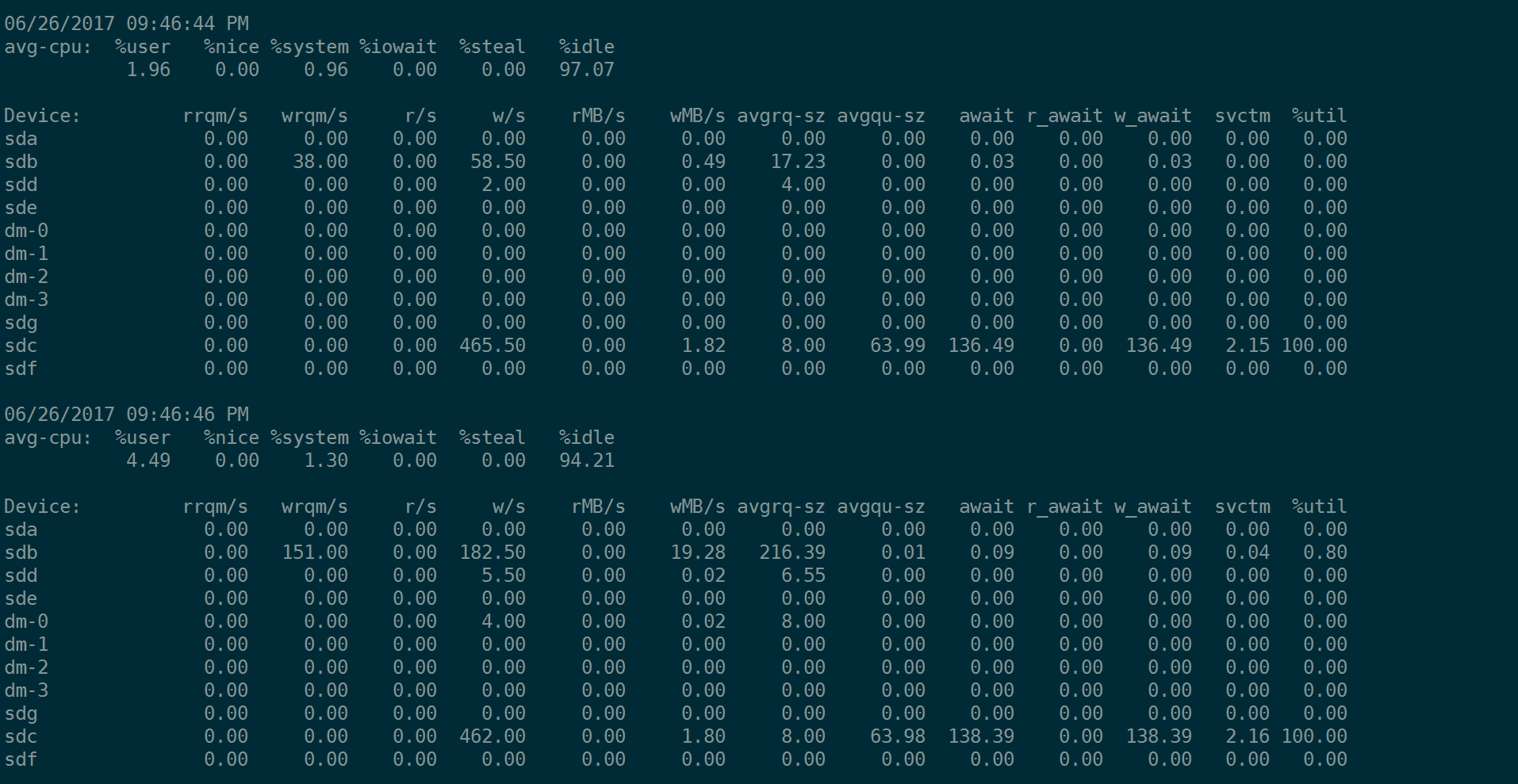
指标
第一列Device比较容易理解,就是说这一行描述的是哪一个设备。
- rrqm/s : 每秒合并读操作的次数
- wrqm/s: 每秒合并写操作的次数
- r/s :每秒读操作的次数
- w/s : 每秒写操作的次数
- rMB/s :每秒读取的MB字节数
- wMB/s: 每秒写入的MB字节数
- avgrq-sz:每个IO的平均扇区数,即所有请求的平均大小,以扇区(512字节)为单位
- avgqu-sz:平均为完成的IO请求数量,即平均意义山的请求队列长度
- await:平均每个IO所需要的时间,包括在队列等待的时间,也包括磁盘控制器处理本次请求的有效时间。
- r_wait:每个读操作平均所需要的时间,不仅包括硬盘设备读操作的时间,也包括在内核队列中的时间。
- w_wait: 每个写操平均所需要的时间,不仅包括硬盘设备写操作的时间,也包括在队列中等待的时间。
- svctm: 表面看是每个IO请求的服务时间,不包括等待时间,但是实际上,这个指标已经废弃。实际上,iostat工具没有任何一输出项表示的是硬盘设备平均每次IO的时间。
- %util: 工作时间或者繁忙时间占总时间的百分比
avgqu-sz 和繁忙程度
首先我们用超市购物来比对iostat的输出。我们在超市结账的时候,一般会有很多队可以排,队列的长度,在一定程度上反应了该收银柜台的繁忙程度。那么这个变量是avgqu-sz这个输出反应的,该值越大,表示排队等待处理的io越多。
我们搞4K的随机IO,但是iodepth=1 ,查看下fio的指令和iostat的输出:
fio --name=randwrite --rw=randwrite --bs=4k --size=20G --runtime=1200 --ioengine=libaio --iodepth=1 --numjobs=1 --filename=/dev/sdc --direct=1 --group_reporting

同样是4K的随机IO,我们设置iodepth=16, 查看fio的指令和iostat的输出:
fio --name=randwrite --rw=randwrite --bs=4k --size=20G --runtime=1200 --ioengine=libaio --iodepth=16 --numjobs=1 --filename=/dev/sdc --direct=1 --group_reporting
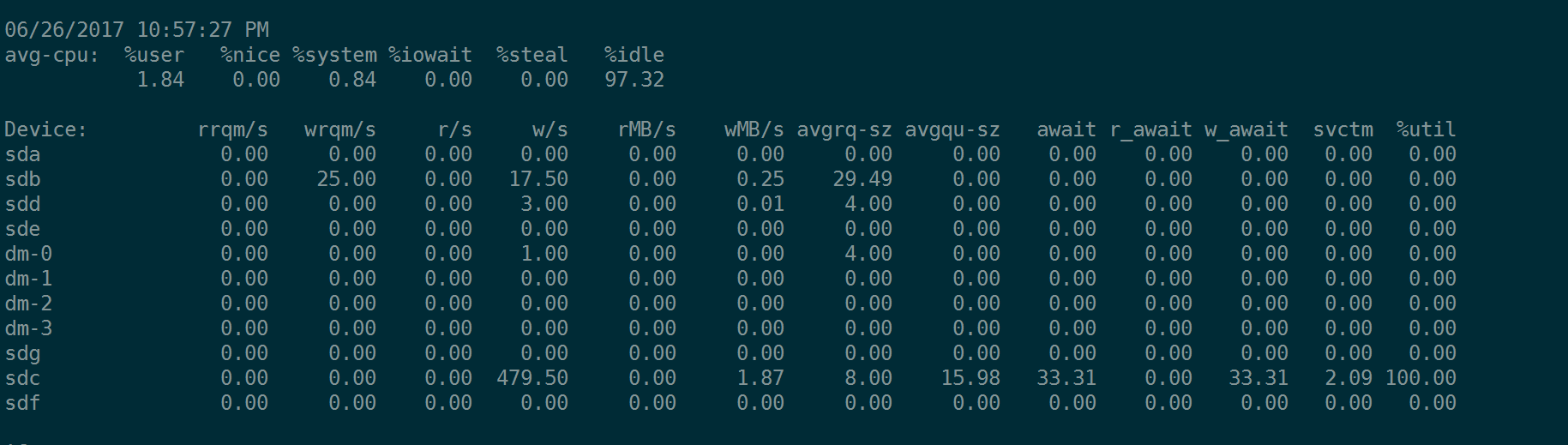
注意,内核中有I/O Scheduler队列。我们看到因为avgqu-sz大小不一样,所以一个IO时间(await)就不一样。就好像你在超时排队,有一队没有人,而另一队队伍长度达到16 ,那么很明显,队伍长队为16的更繁忙一些。
avgrq-sz
avgrq-sz这个值反应了用户的IO-Pattern。我们经常关心,用户过来的IO是大IO还是小IO,那么avgrq-sz反应了这个要素。它的含义是说,平均下来,这这段时间内,所有请求的平均大小,单位是扇区,即(512字节)。
上面图中,sdc的avgrq-sz总是8,即8个扇区 = 8*512(Byte) = 4KB,这是因为我们用fio打io的时候,用的bs=4k。
下面我们测试当bs=128k时候的fio指令:
fio --name=randwrite --rw=randwrite --bs=128k --size=20G --runtime=1200 --ioengine=libaio --iodepth=1 --numjobs=1 --filename=/dev/sdc --direct=1 --group_reporting

注意sdc的avgrq-sz这列的值,变成了256,即256 个扇区 = 256* 512 Byte = 128KB,等于我们fio测试时,下达的bs = 128k。
注意,这个值也不是为所欲为的,它受内核参数的控制:
root@node-186:~# cat /sys/block/sdc/queue/max_sectors_kb
256
这个值不是最大下发的IO是256KB,即512个扇区。当我们fio对sdc这块盘做测试的时候,如果bs=256k,iostat输出中的avgrq-sz 会变成 512 扇区,但是,如果继续增大bs,比如bs=512k,那么iostat输出中的avgrq-sz不会继续增大,仍然是512,表示512扇区。
fio --name=randwrite --rw=randwrite --bs=512k --size=20G --runtime=1200 --ioengine=libaio --iodepth=1 --numjobs=1 --filename=/dev/sdc --direct=1 --group_reporting

注意,本来512KB等于1024个扇区,avgrq-sz应该为1024,但是由于内核的max_sectors_kb控制参数,决定了不可能
rrqm/s 和wrqm/s
块设备有相应的调度算法。如果两个IO发生在相邻的数据块时,他们可以合并成1个IO。
这个简单的可以理解为快递员要给一个18层的公司所有员工送快递,每一层都有一些包裹,对于快递员来说,最好的办法是同一楼层相近的位置的包裹一起投递,否则如果不采用这种算法,采用最原始的来一个送一个(即noop算法),那么这个快递员,可能先送了一个包括到18层,又不得不跑到2层送另一个包裹,然后有不得不跑到16层送第三个包裹,然后包到1层送第三个包裹,那么快递员的轨迹是杂乱无章的,也是非常低效的。
Linux常见的调度算法有: noop deadline和cfq。此处不展开了。
root@node-186:~# cat /sys/block/sdc/queue/scheduler
[noop] deadline cfq
类比总结
我们还是以超时购物为例,比如一家三口去购物,各人买各人的东西,最终会汇总到收银台,你固然可以每人各自付各自的,但是也可以汇总一下,把所有购买的东西放在一起,由一个人来完成,也就说,三次收银事件merge成了一次。
至此,我们以超时购物收银为例,介绍了avgqu-sz 类比于队伍的长度,avgrq-sz 类比于每个人购物车里物品的多少,rrqm/s和wrqm/s 类比于将一家购得东西汇总一起,付费一次。