
LInux 进程在内存布局
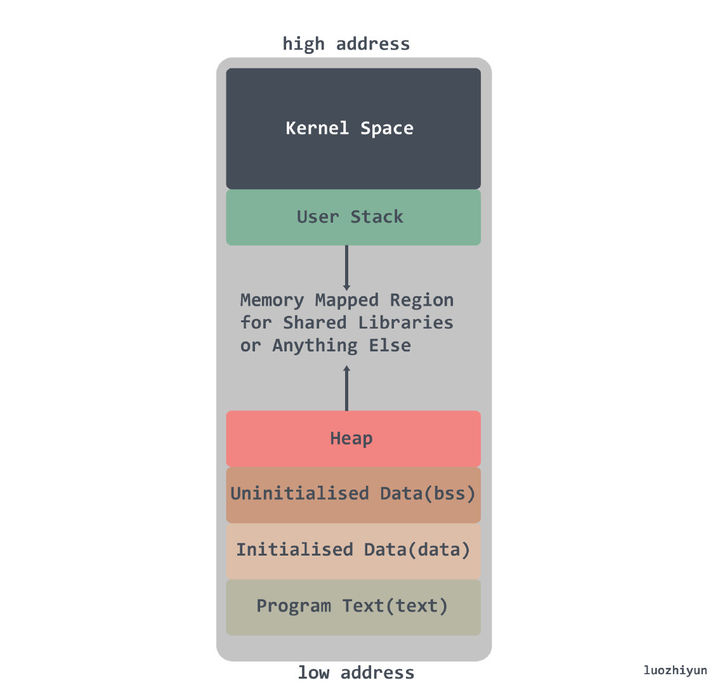
多任务操作系统中的每个进程都在自己的内存沙盒中运行。在 32 位模式下,它总是 4GB 内存地址空间,内存分配是分配虚拟内存给进程,当进程真正访问某一虚拟内存地址时,操作系统通过触发缺页中断,在物理内存上分配一段相应的空间再与之建立映射关系,这样进程访问的虚拟内存地址,会被自动转换变成有效物理内存地址,便可以进行数据的存储与访问了。
Kernel space:操作系统内核地址空间;
Stack:栈空间,是用户存放程序临时创建的局部变量,栈的增长方向是从高位地址到地位地址向下进行增长。在现代主流机器架构上(例如x86)中,栈都是向下生长的。然而,也有一些处理器(例如B5000)栈是向上生长的,还有一些架构(例如System Z)允许自定义栈的生长方向,甚至还有一些处理器(例如SPARC)是循环栈的处理方式;
Heap:堆空间,堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减;
BBS segment:BSS 段,存放的是全局或者静态数据,但是存放的是全局/静态未初始化数据;
Data segment:数据段,通常是指用来存放程序中已初始化的全局变量的一块内存区域;
Text segment:代码段,指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域属于只读。
栈的相关概念
调用栈call stack,简称栈,是一种栈数据结构,用于存储有关计算机程序的活动 subroutines 信息。在计算机编程中,subroutines 是执行特定任务的一系列程序指令,打包为一个单元。
栈帧stack frame又常被称为帧frame是在调用栈中储存的函数之间的调用关系,每一帧对应了函数调用以及它的参数数据。
有了函数调用自然就要有调用者 caller 和被调用者 callee ,如在 函数 A 里 调用 函数 B,A 是 caller,B 是 callee。
调用者与被调用者的栈帧结构如下图所示:
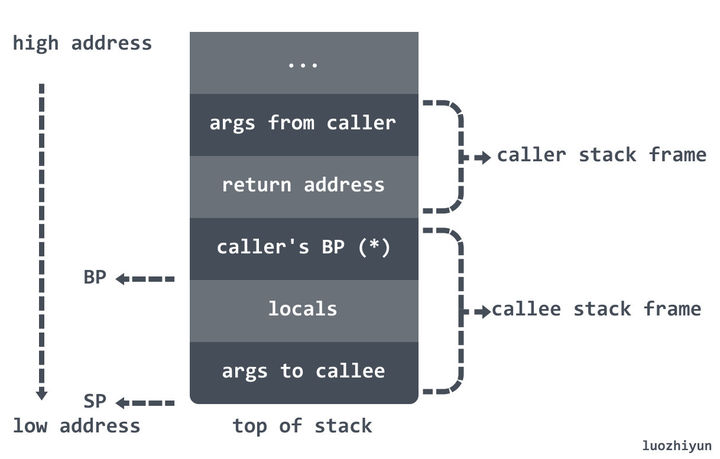
Go 语言的汇编代码中栈寄存器解释的非常模糊,我们大概只要知道两个寄存器 BP 和 SP 的作用就可以了:
BP:基准指针寄存器,维护当前栈帧的基准地址,以便用来索引变量和参数,就像一个锚点一样,在其它架构中它等价于帧指针FP,只是在 x86 架构下,变量和参数都可以通过 SP 来索引;
SP:栈指针寄存器,总是指向栈顶;
堆内存管理
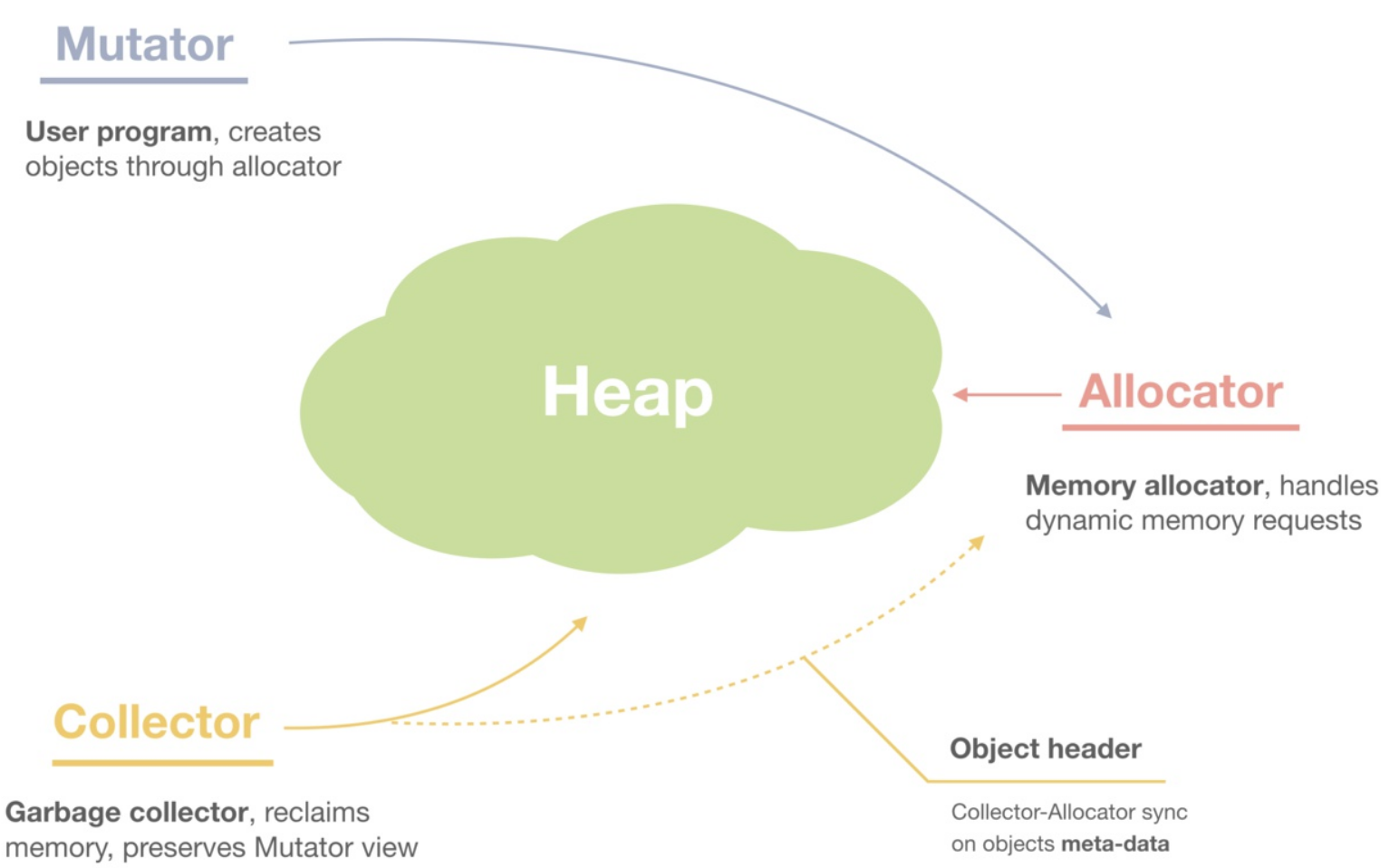
我们再进一层,当我们说内存管理的时候,主要是指堆内存的管理,因为栈的内存管理不需要程序去操心,这小节看下堆内存管理到底完成了什么。如上图所示主要是3部分,分别是分配内存块,回收内存块和组织内存块。
在一个最简单的内存管理中,堆内存最初会是一个完整的大块,即未分配任何内存。当发现内存申请的时候,堆内存就会从未分配内存分割出一个小内存块(block),然后用链表把所有内存块连接起来。需要一些信息描述每个内存块的基本信息,比如大小(size)、是否使用中(used)和下一个内存块的地址(next),内存块实际数据存储在data中。

一个内存块包含了3类信息,如下图所示,元数据、用户数据和对齐字段,内存对齐是为了提高访问效率。下图申请5Byte内存的时候,就需要进行内存对齐。
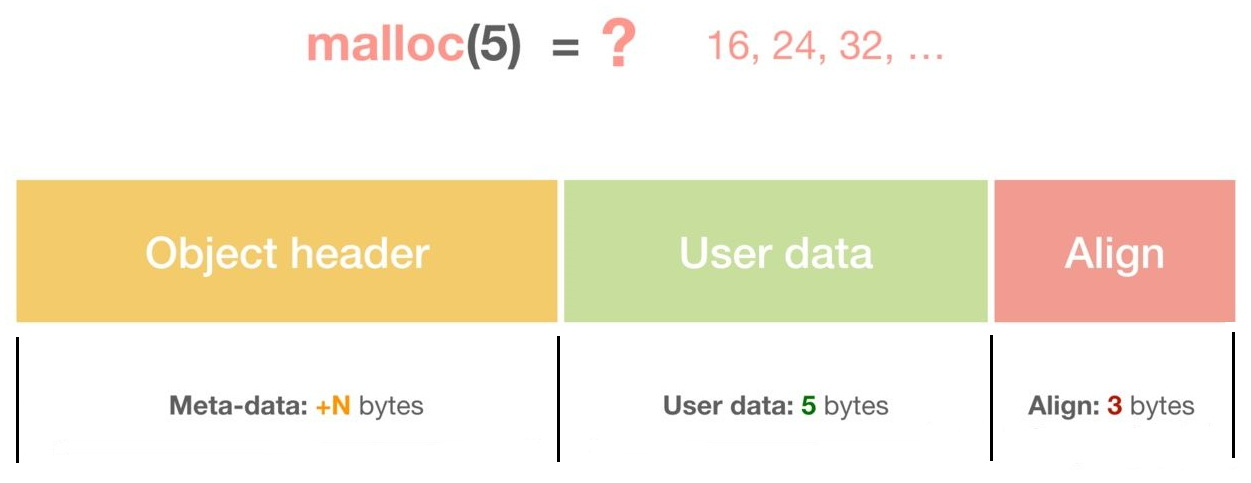
释放内存实质是把使用的内存块从链表中取出来,然后标记为未使用,当分配内存块的时候,可以从未使用内存块中优先查找大小相近的内存块,如果找不到,再从未分配的内存中分配内存。
上面这个简单的设计中还没考虑内存碎片的问题,因为随着内存不断的申请和释放,内存上会存在大量的碎片,降低内存的使用率。为了解决内存碎片,可以将2个连续的未使用的内存块合并,减少碎片。
TCMalloc
TCMalloc是Thread Cache Malloc的简称,是Go内存管理的起源,Go的内存管理是借鉴了TCMalloc,随着Go的迭代,Go的内存管理与TCMalloc不一致地方在不断扩大,但其主要思想、原理和概念都是和TCMalloc一致的,如果跳过TCMalloc直接去看Go的内存管理,也许你会似懂非懂。
掌握TCMalloc的理念,无需去关注过多的源码细节,就可以为掌握Go的内存管理打好基础,基础打好了,后面知识才扎实。
在Linux操作系统中,其实有不少的内存管理库,比如glibc的ptmalloc,FreeBSD的jemalloc,Google的tcmalloc等等,为何会出现这么多的内存管理库?本质都是在多线程编程下,追求更高内存管理效率:更快的分配是主要目的。
我们前面提到引入虚拟内存后,让内存的并发访问问题的粒度从多进程级别,降低到多线程级别。然而同一进程下的所有线程共享相同的内存空间,它们申请内存时需要加锁,如果不加锁就存在同一块内存被2个线程同时访问的问题。
TCMalloc的做法是什么呢?为每个线程预分配一块缓存,线程申请小内存时,可以从缓存分配内存,这样有2个好处:
- 为线程预分配缓存需要进行1次系统调用,后续线程申请小内存时直接从缓存分配,都是在用户态执行的,没有了系统调用,缩短了内存总体的分配和释放时间,这是快速分配内存的第二个层次。
- 多个线程同时申请小内存时,从各自的缓存分配,访问的是不同的地址空间,从而无需加锁,把内存并发访问的粒度进一步降低了,这是快速分配内存的第三个层次。
基本原理
下面就简单介绍下TCMalloc,细致程度够我们理解Go的内存管理即可。
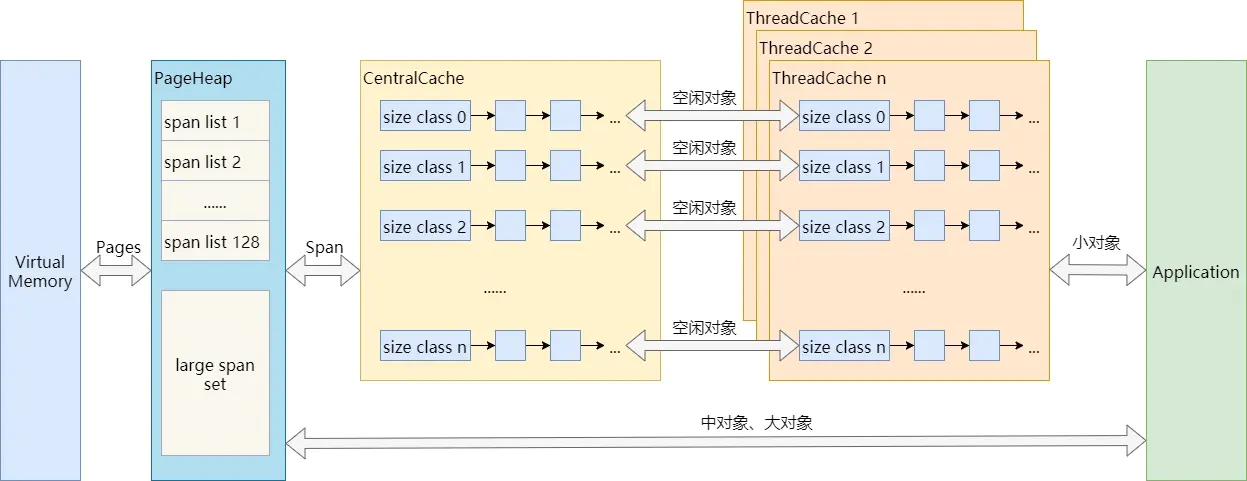
可以看到,不超过256KB的小对象分配,在应用程序和内存之间其实有三层缓存:PageHeap、CentralCache、ThreadCache。而中对象和大对象分配,则只有PageHeap一层缓存。
结合上图,介绍TCMalloc的几个重要概念:
- Page:操作系统对内存管理以页为单位,TCMalloc也是这样,只不过TCMalloc里的Page大小与操作系统里的大小并不一定相等,而是倍数关系。《TCMalloc解密》里称x64下Page大小是8KB。
- Span:一组连续的Page被称为Span,比如可以有2个页大小的Span,也可以有16页大小的Span,Span比Page高一个层级,是为了方便管理一定大小的内存区域,Span是TCMalloc中内存管理的基本单位。
- PageHeap:PageHeap是对堆内存的抽象,PageHeap存的也是若干链表,链表保存的是Span。当CentralCache的内存不足时,会从PageHeap获取空闲的内存Span,然后把1个Span拆成若干内存块,添加到对应大小的链表中并分配内存;当CentralCache的内存过多时,会把空闲的内存块放回PageHeap中。
- CentralCache:CentralCache是所有线程共享的缓存,也是保存的空闲内存块链表,链表的数量与ThreadCache中链表数量相同,当ThreadCache的内存块不足时,可以从CentralCache获取内存块;当ThreadCache内存块过多时,可以放回CentralCache。由于CentralCache是共享的,所以它的访问是要加锁的。
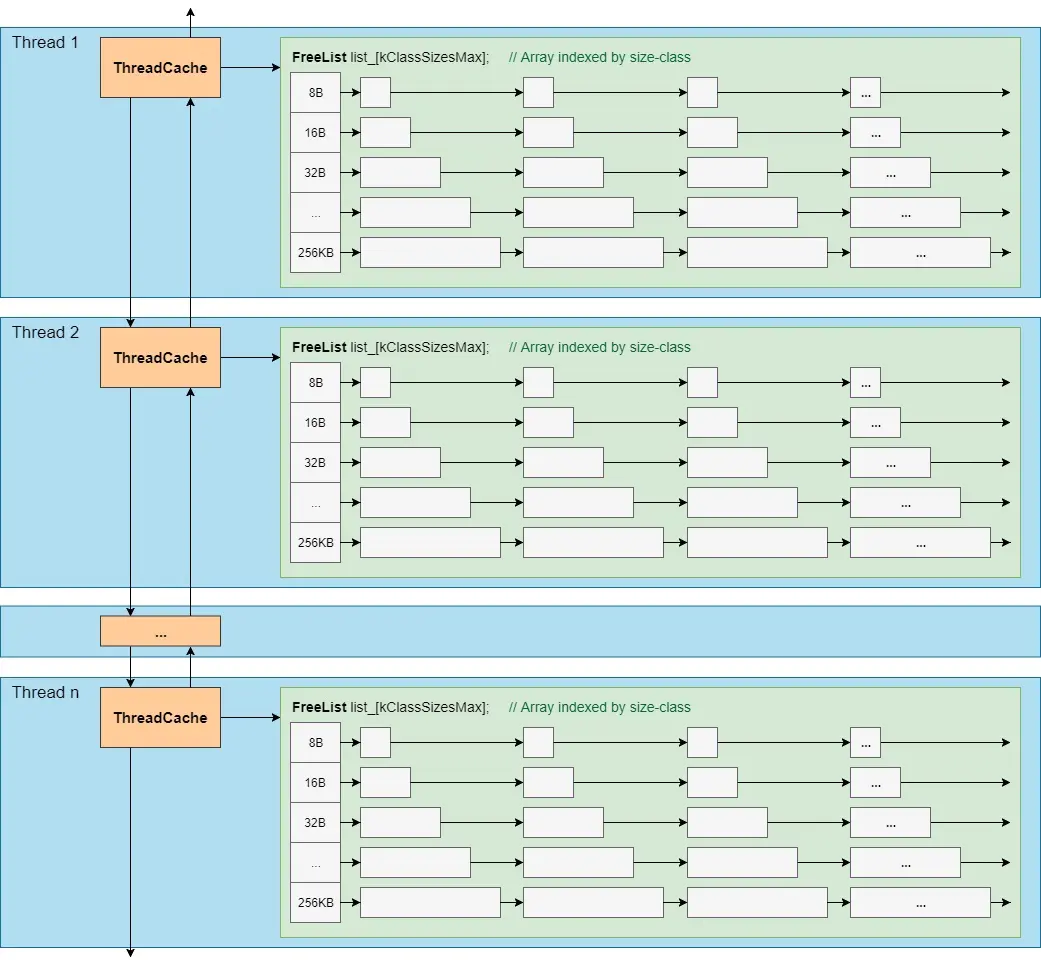
- ThreadCache:ThreadCache是每个线程各自的Cache,一个Cache包含多个空闲内存块链表,每个链表连接的都是内存块,同一个链表上内存块的大小是相同的,也可以说按内存块大小,给内存块分了个类,这样可以根据申请的内存大小,快速从合适的链表选择空闲内存块。由于每个线程有自己的ThreadCache,所以ThreadCache访问是无锁的。
由于每线程一个ThreadCache,因此从ThreadCache中取用或回收内存是不需要加锁的,速度很快。
为了方便统计数据,各线程的ThreadCache连接成一个双向链表。ThreadCache的结构示大致如下:
如下图所示,分别是1页Page的Span链表,2页Page的Span链表等,最后是large span set,这个是用来保存中大对象的。毫无疑问,PageHeap也是要加锁的。
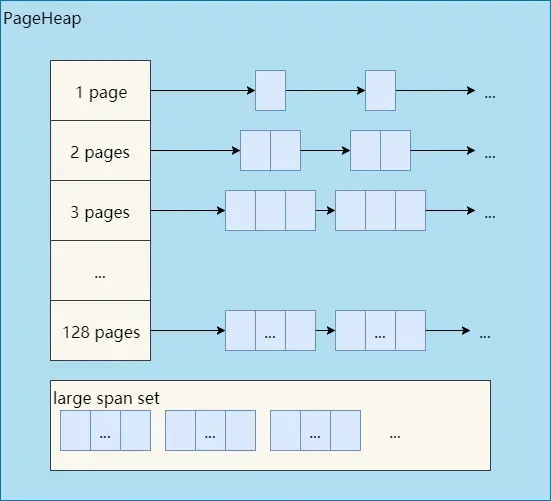
前文提到了小、中、大对象,Go内存管理中也有类似的概念,我们看一眼TCMalloc的定义:
- 小对象大小:0~256KB
- 中对象大小:257~1MB
- 大对象大小:>1MB
小对象的分配流程:ThreadCache -> CentralCache -> HeapPage,大部分时候,ThreadCache缓存都是足够的,不需要去访问CentralCache和HeapPage,无系统调用配合无锁分配,分配效率是非常高的。
中对象分配流程:直接在PageHeap中选择适当的大小即可,128 Page的Span所保存的最大内存就是1MB。
大对象分配流程:从large span set选择合适数量的页面组成span,用来存储数据。
Go内存管理
前文提到Go内存管理源自TCMalloc,但它比TCMalloc还多了2件东西:逃逸分析和垃圾回收,这是2项提高生产力的绝佳武器。这一大章节,我们先介绍Go内存管理和Go内存分配,最后涉及一点垃圾回收和内存释放。
Go内存管理的基本概念
Go内存管理的许多概念在TCMalloc中已经有了,含义是相同的,只是名字有一些变化。先给大家上一幅宏观的图,借助图一起来介绍。
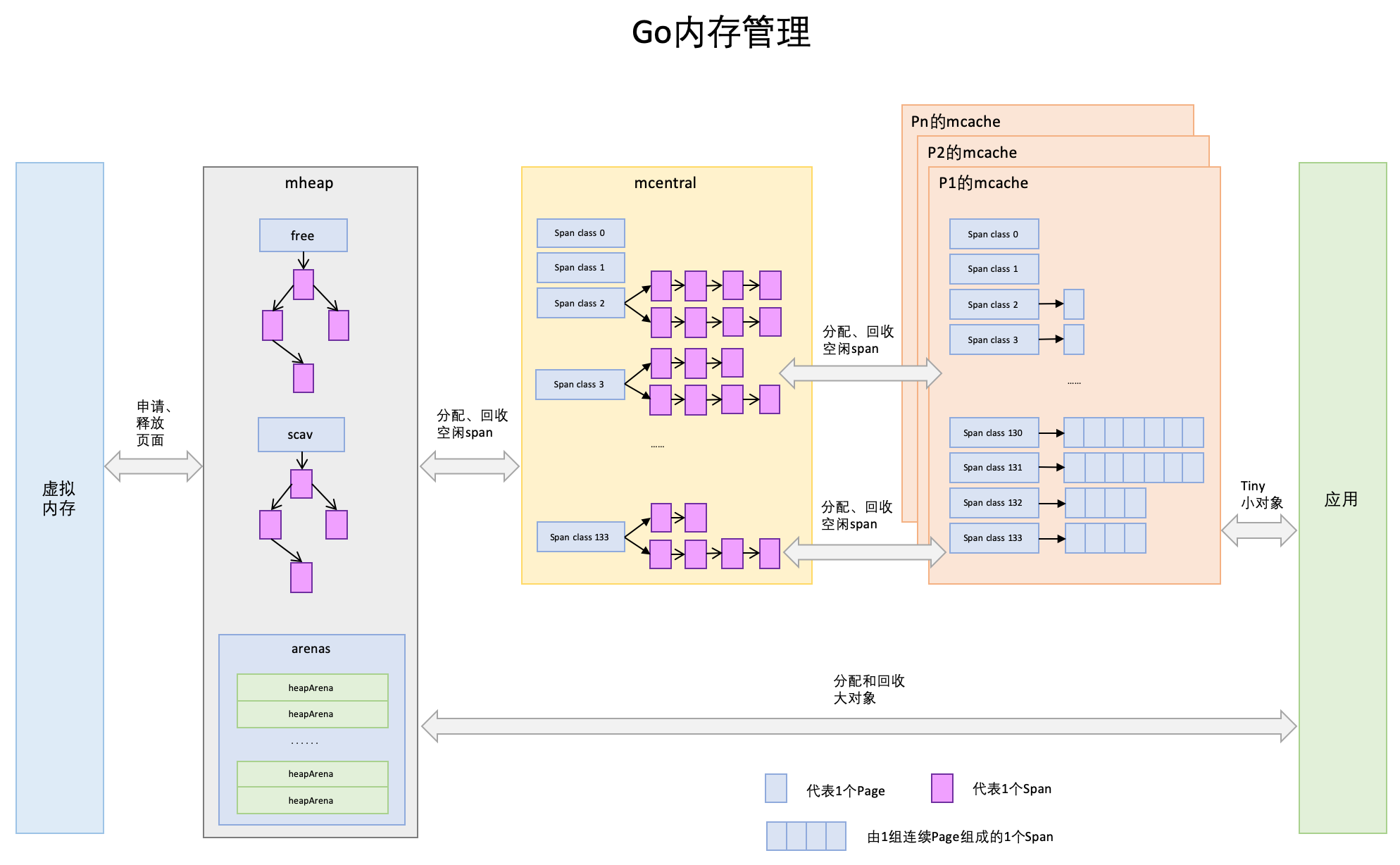
- Page:与TCMalloc中的Page相同,x64架构下1个Page的大小是8KB。上图的最下方,1个浅蓝色的长方形代表1个Page。
- Span:Span与TCMalloc中的Span相同,Span是内存管理的基本单位,代码中为mspan,一组连续的Page组成1个Span,所以上图一组连续的浅蓝色长方形代表的是一组Page组成的1个Span,另外,1个淡紫色长方形为1个Span。
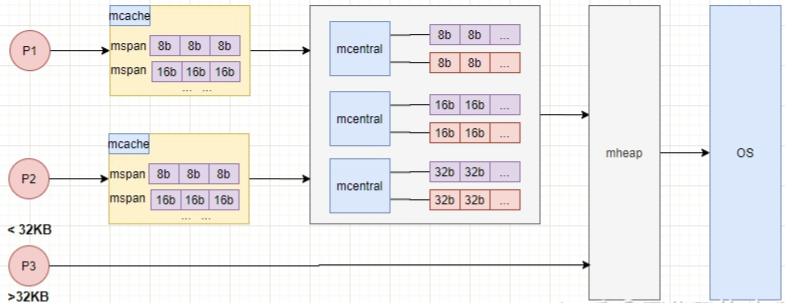
- mcache:mcache与TCMalloc中的ThreadCache类似,mcache保存的是各种大小的Span,并按Span class分类,小对象直接从mcache分配内存,它起到了缓存的作用,并且可以无锁访问。但是mcache与ThreadCache也有不同点,TCMalloc中是每个线程1个ThreadCache,Go中是每个P拥有1个mcache。因为在Go程序中,当前最多有GOMAXPROCS个线程在运行,所以最多需要GOMAXPROCS个mcache就可以保证各线程对mcache的无锁访问,线程的运行又是与P绑定的,把mcache交给P刚刚好。
- mcentral:mcentral与TCMalloc中的CentralCache类似,是所有线程共享的缓存,需要加锁访问。它按Span级别对Span分类,然后串联成链表,当mcache的某个级别Span的内存被分配光时,它会向mcentral申请1个当前级别的Span。但是mcentral与CentralCache也有不同点,CentralCache是每个级别的Span有1个链表,mcache是每个级别的Span有2个链表,这和mcache申请内存有关,稍后我们再解释。
- mhead:mheap与TCMalloc中的PageHeap类似,它是堆内存的抽象,把从OS申请出的内存页组织成Span,并保存起来。当mcentral的Span不够用时会向mheap申请内存,而mheap的Span不够用时会向OS申请内存。mheap向OS的内存申请是按页来的,然后把申请来的内存页生成Span组织起来,同样也是需要加锁访问的。
但是mheap与PageHeap也有不同点:mheap把Span组织成了树结构,而不是链表,并且还是2棵树,然后把Span分配到heapArena进行管理,它包含地址映射和span是否包含指针等位图,这样做的主要原因是为了更高效的利用内存:分配、回收和再利用。
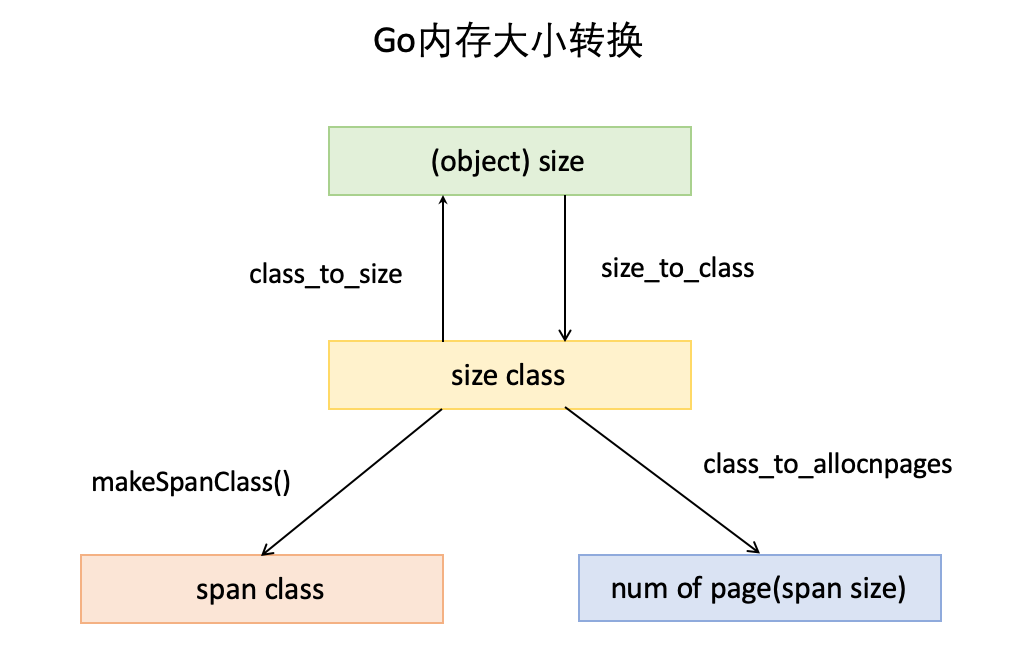
- object size:代码里简称size,指申请内存的对象大小。
size class:代码里简称class,它是size的级别,相当于把size归类到一定大小的区间段,比如size[1,8]属于size class 1,size(8,16]属于size class 2。 - span class:指span的级别,但span class的大小与span的大小并没有正比关系。span class主要用来和size class做对应,1个size class对应2个span * class,2个span class的span大小相同,只是功能不同,1个用来存放包含指针的对象,一个用来存放不包含指针的对象,不包含指针对象的Span就无需GC扫描了。
- num of page:代码里简称npage,代表Page的数量,其实就是Span包含的页数,用来分配内存。
Go内存分配
Go中的内存分类并不像TCMalloc那样分成小、中、大对象,但是它的小对象里又细分了一个Tiny对象,Tiny对象指大小在1Byte到16Byte之间并且不包含指针的对象。小对象和大对象只用大小划定,无其他区分。
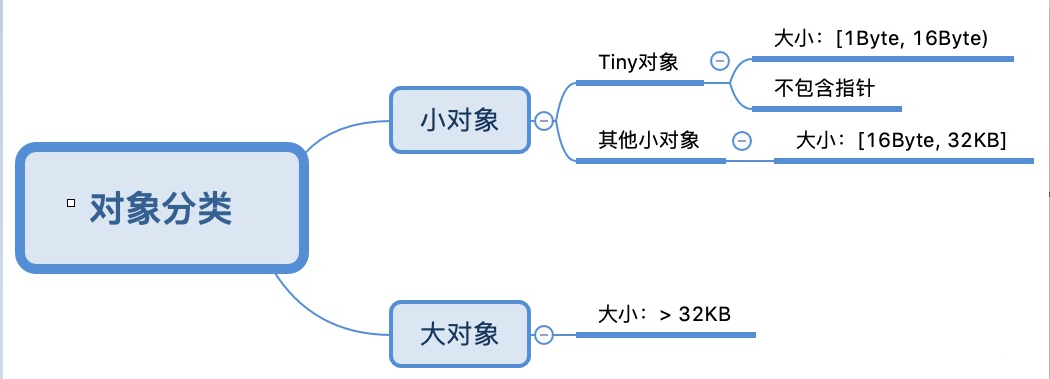
小对象是在mcache中分配的,而大对象是直接从mheap分配的,从小对象的内存分配看起。
Go在程序启动的时候,会先向操作系统申请一块内存(注意这时还只是一段虚拟的地址空间,并不会真正地分配内存),切成小块后自己进行管理。
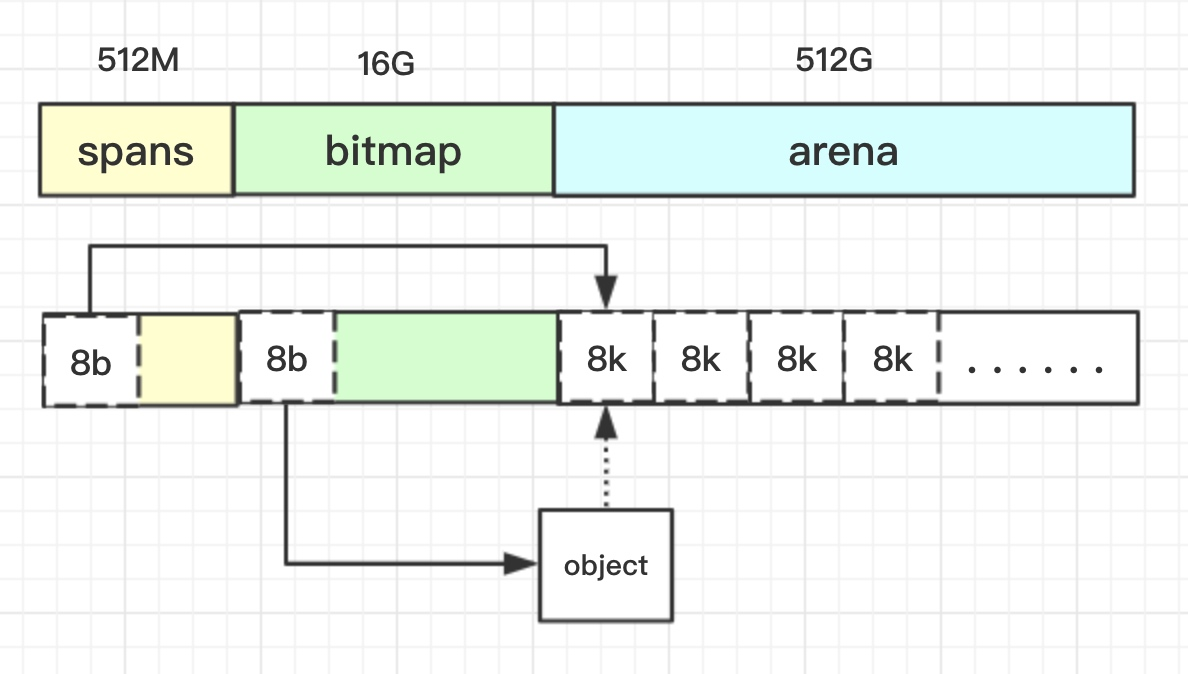
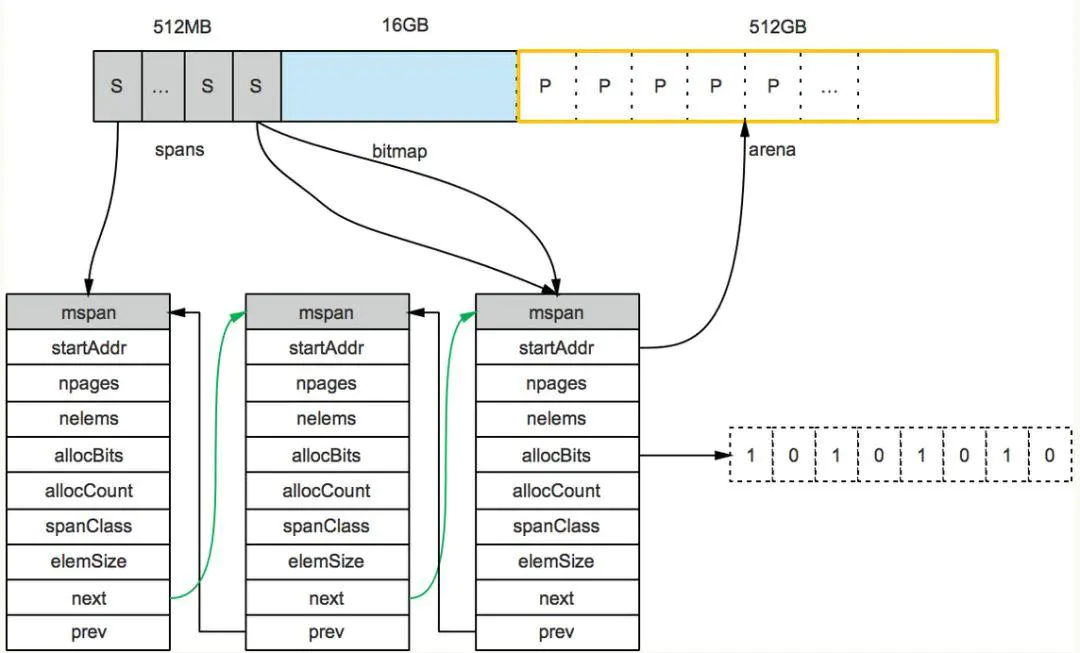
申请到的内存块被分配了三个区域,在X64上分别是512MB,16GB,512GB大小。
arena区域
arena区域就是我们所谓的堆区,Go动态分配的内存都是在这个区域,它把内存分割成8KB大小的页,一些页组合起来称为mspan。
bitmap区域
bitmap区域标识arena区域哪些地址保存了对象,并且用4bit标志位表示对象是否包含指针、GC标记信息。bitmap中一个byte大小的内存对应arena区域中4个指针大小(指针大小为 8B )的内存,所以bitmap区域的大小是512GB/(4*8B)=16GB。如下图:
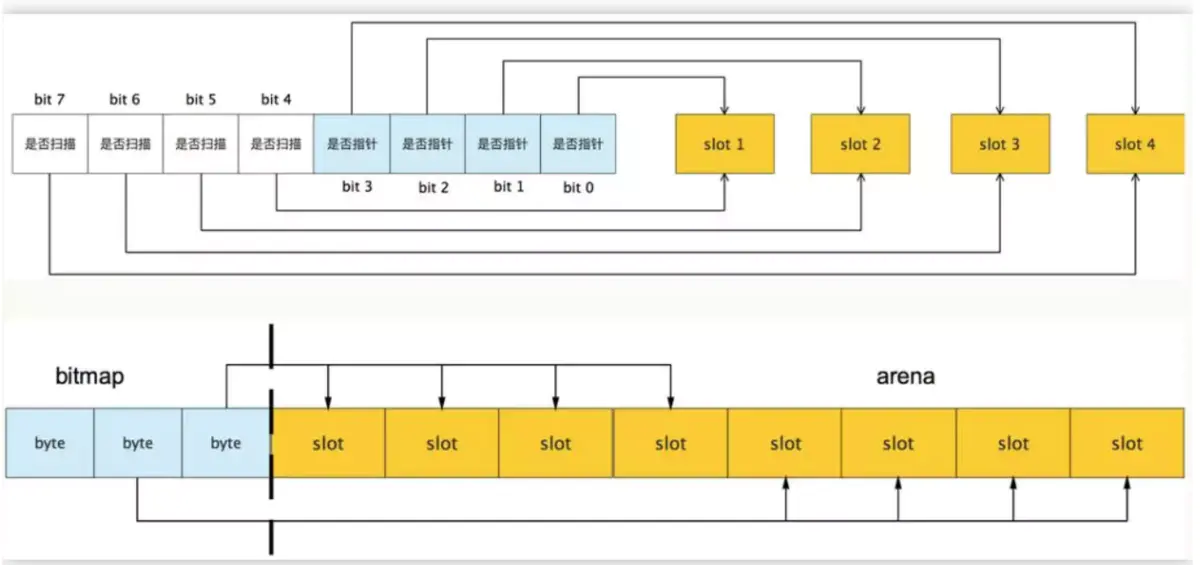
从上图其实还可以看到bitmap的高地址部分指向arena区域的低地址部分,也就是说bitmap的地址是由高地址向低地址增长的。
spans区域
spans区域存放mspan(也就是一些arena分割的页组合起来的内存管理基本单元,后文会再讲)的指针,每个指针对应一页,所以spans区域的大小就是512GB/8KB*8B=512MB。除以8KB是计算arena区域的页数,而最后乘以8是计算spans区域所有指针的大小。创建mspan的时候,按页填充对应的spans区域,在回收object时,根据地址很容易就能找到它所属的mspan。
内存管理单元
mspan:Go中内存管理的基本单元,是由一片连续的8KB的页组成的大块内存。注意,这里的页和操作系统本身的页并不是一回事,它一般是操作系统页大小的几倍。一句话概括:mspan是一个包含起始地址、mspan规格、页的数量等内容的双端链表。
每个mspan按照它自身的属性Size Class的大小分割成若干个object,每个object可存储一个对象。并且会使用一个位图来标记其尚未使用的object。属性Size Class决定object大小,而mspan只会分配给和object尺寸大小接近的对象,当然,对象的大小要小于object大小。还有一个概念:Span Class,它和Size Class的含义差不多,
Size_Class = Span_Class / 2
这是因为其实每个 Size Class有两个mspan,也就是有两个Span Class。其中一个分配给含有指针的对象,另一个分配给不含有指针的对象。这会给垃圾回收机制带来利好,之后的文章再谈。
如下图,mspan由一组连续的页组成,按照一定大小划分成object。

mspan的 SizeClass共有67种,每种 mspan分割的object大小是8*2n的倍数,这个是写死在代码里的:
// path: /usr/local/go/src/runtime/sizeclasses.go
const _NumSizeClasses = 67
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536,1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
具体对应信息如下:
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// 4 48 8192 170 32 31.52%
// 5 64 8192 128 0 23.44%
// 6 80 8192 102 32 19.07%
// 7 96 8192 85 32 15.95%
// 8 112 8192 73 16 13.56%
// 9 128 8192 64 0 11.72%
// 10 144 8192 56 128 11.82%
// 11 160 8192 51 32 9.73%
// 12 176 8192 46 96 9.59%
// 13 192 8192 42 128 9.25%
// 14 208 8192 39 80 8.12%
// 15 224 8192 36 128 8.15%
// 16 240 8192 34 32 6.62%
// 17 256 8192 32 0 5.86%
// 18 288 8192 28 128 12.16%
// 19 320 8192 25 192 11.80%
// 20 352 8192 23 96 9.88%
// 21 384 8192 21 128 9.51%
// 22 416 8192 19 288 10.71%
// 23 448 8192 18 128 8.37%
// 24 480 8192 17 32 6.82%
// 25 512 8192 16 0 6.05%
// 26 576 8192 14 128 12.33%
// 27 640 8192 12 512 15.48%
// 28 704 8192 11 448 13.93%
// 29 768 8192 10 512 13.94%
// 30 896 8192 9 128 15.52%
// 31 1024 8192 8 0 12.40%
// 32 1152 8192 7 128 12.41%
// 33 1280 8192 6 512 15.55%
// 34 1408 16384 11 896 14.00%
// 35 1536 8192 5 512 14.00%
// 36 1792 16384 9 256 15.57%
// 37 2048 8192 4 0 12.45%
// 38 2304 16384 7 256 12.46%
// 39 2688 8192 3 128 15.59%
// 40 3072 24576 8 0 12.47%
// 41 3200 16384 5 384 6.22%
// 42 3456 24576 7 384 8.83%
// 43 4096 8192 2 0 15.60%
// 44 4864 24576 5 256 16.65%
// 45 5376 16384 3 256 10.92%
// 46 6144 24576 4 0 12.48%
// 47 6528 32768 5 128 6.23%
// 48 6784 40960 6 256 4.36%
// 49 6912 49152 7 768 3.37%
// 50 8192 8192 1 0 15.61%
// 51 9472 57344 6 512 14.28%
// 52 9728 49152 5 512 3.64%
// 53 10240 40960 4 0 4.99%
// 54 10880 32768 3 128 6.24%
// 55 12288 24576 2 0 11.45%
// 56 13568 40960 3 256 9.99%
// 57 14336 57344 4 0 5.35%
// 58 16384 16384 1 0 12.49%
// 59 18432 73728 4 0 11.11%
// 60 19072 57344 3 128 3.57%
// 61 20480 40960 2 0 6.87%
// 62 21760 65536 3 256 6.25%
// 63 24576 24576 1 0 11.45%
// 64 27264 81920 3 128 10.00%
// 65 28672 57344 2 0 4.91%
// 66 32768 32768 1 0 12.50%
说说每列代表的含义:
- class: class ID,每个span结构中都有一个class ID, 表示该span可处理的对象类型
- bytes/obj:该class代表对象的字节数
- bytes/span:每个span占用堆的字节数,也即页数*页大小
- objects: 每个span可分配的对象个数,也即(bytes/spans)/(bytes/obj)
- waste bytes: 每个span产生的内存碎片,也即(bytes/spans)%(bytes/obj)
以类型(class)为1的span为例,span中的元素(obj)大小是8 byte, span本身占1页也就是8K, 一共可以保存1024个对象。
细心的同学可能会发现代码中一共有66种,还有一种特殊的span:
即对于大于32k的对象出现时,会直接从heap分配一个特殊的span,这个特殊的span的类型(class)是0, 只包含了一个大对象, span的大小由对象的大小决定。
根据 mspan的 SizeClass可以得到它划分的 object大小。 比如 SizeClass等于3, object大小就是32B。 32B大小的object可以存储对象大小范围在17B~32B的对象。而对于微小对象(小于16B),分配器会将其进行合并,将几个对象分配到同一个 object中。
数组里最大的数是32768,也就是32KB,超过此大小就是大对象了,它会被特别对待,这个稍后会再介绍。顺便提一句,类型 SizeClass为0表示大对象,它实际上直接由堆内存分配,而小对象都要通过 mspan来分配。
对于mspan来说,它的Size Class会决定它所能分到的页数,这也是写死在代码里的:
// path: /usr/local/go/src/runtime/sizeclasses.go
const _NumSizeClasses = 67
var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 3, 2, 3, 1, 3, 2, 3, 4, 5, 6, 1, 7, 6, 5, 4, 3, 5, 7, 2, 9, 7, 5, 8, 3, 10, 7, 4}
mspan结构体定义:
// path: /usr/local/go/src/runtime/mheap.go
type mspan struct {
//链表前向指针,用于将span链接起来
next *mspan
//链表前向指针,用于将span链接起来
prev *mspan
// 起始地址,也即所管理页的地址
startAddr uintptr
// 管理的页数
npages uintptr
// 块个数,表示有多少个块可供分配
nelems uintptr
//分配位图,每一位代表一个块是否已分配
allocBits *gcBits
// 已分配块的个数
allocCount uint16
// class表中的class ID,和Size Classs相关
spanclass spanClass
// class表中的对象大小,也即块大小
elemsize uintptr
}
比如当我们要申请一个object大小为32B的mspan的时候,在class_to_size里对应的索引是3,而索引3在class_to_allocnpages数组里对应的页数就是1。
我们将mspan放到更大的视角来看:
上图可以看到有两个 S指向了同一个 mspan,因为这两个 S指向的 P是同属一个 mspan的。所以,通过 arena上的地址可以快速找到指向它的 S,通过 S就能找到 mspan,回忆一下前面我们说的 mspan区域的每个指针对应一页。
假设最左边第一个 mspan的 SizeClass等于10,根据前面的 class_to_size数组,得出这个 msapn分割的 object大小是144B,算出可分配的对象个数是 8KB/144B=56.89个,取整56个,所以会有一些内存浪费掉了,Go的源码里有所有 SizeClass的 mspan浪费的内存的大小;再根据 class_to_allocnpages数组,得到这个 mspan只由1个 page组成;假设这个 mspan是分配给无指针对象的,那么 spanClass等于20。
startAddr直接指向 arena区域的某个位置,表示这个 mspan的起始地址, allocBits指向一个位图,每位代表一个块是否被分配了对象; allocCount则表示总共已分配的对象个数。
这样,左起第一个mspan的各个字段参数就如下图所示:

内存管理组件
内存分配由内存分配器完成。分配器由3种组件构成:mcache, mcentral, mheap。
mcache
mcache:每个工作线程都会绑定一个mcache,本地缓存可用的mspan资源,这样就可以直接给Goroutine分配,因为不存在多个Goroutine竞争的情况,所以不会消耗锁资源。
mcache的结构体定义
//path: /usr/local/go/src/runtime/mcache.go
type mcache struct {
alloc [numSpanClasses]*mspan
}
numSpanClasses = _NumSizeClasses << 1
分配过程
mcache用Span Classes作为索引管理多个用于分配的mspan,它包含所有规格的mspan。它是_NumSizeClasses的2倍,也就是67*2=134,为什么有一个两倍的关系,前面我们提到过:为了加速之后内存回收的速度,数组里一半的mspan中分配的对象不包含指针,另一半则包含指针。
对于无指针对象的mspan在进行垃圾回收的时候无需进一步扫描它是否引用了其他活跃的对象。 后面的垃圾回收文章会再讲到,这次先到这里。
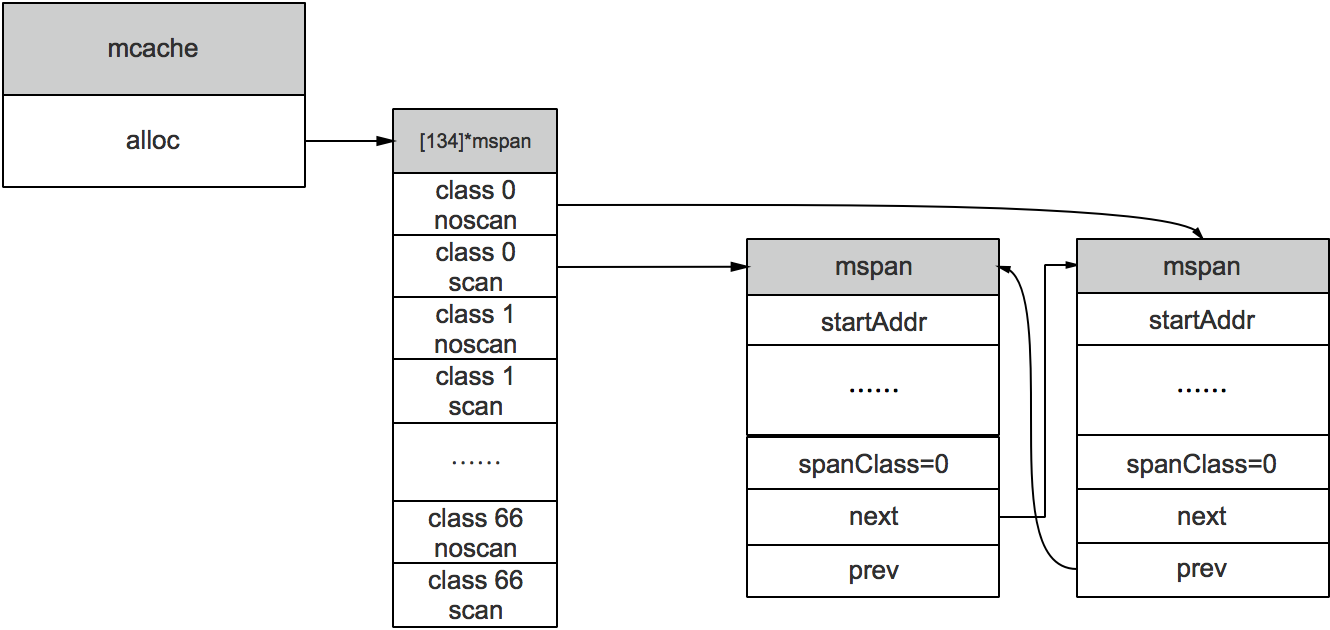
mcache在初始化的时候是没有任何mspan资源的,在使用过程中会动态地从mcentral申请,之后会缓存下来。当对象小于等于32KB大小时,使用mcache的相应规格的mspan进行分配。
mcentral
mcentral:为所有mcache提供切分好的mspan资源。每个central保存一种特定大小的全局mspan列表,包括已分配出去的和未分配出去的。 每个mcentral对应一种mspan,而mspan的种类导致它分割的object大小不同。当工作线程的mcache中没有合适(也就是特定大小的)的mspan时就会从mcentral获取。
mcentral 被所有的工作线程共同享有,存在多个Goroutine竞争的情况,因此会消耗锁资源。结构体定义:
//path: /usr/local/go/src/runtime/mcentral.go
type mcentral struct {
// 互斥锁
lock mutex
// 规格
sizeclass int32
// 尚有空闲object的mspan链表
nonempty mSpanList
// 没有空闲object的mspan链表,或者是已被mcache取走的msapn链表
empty mSpanList
// 已累计分配的对象个数
nmalloc uint64
}
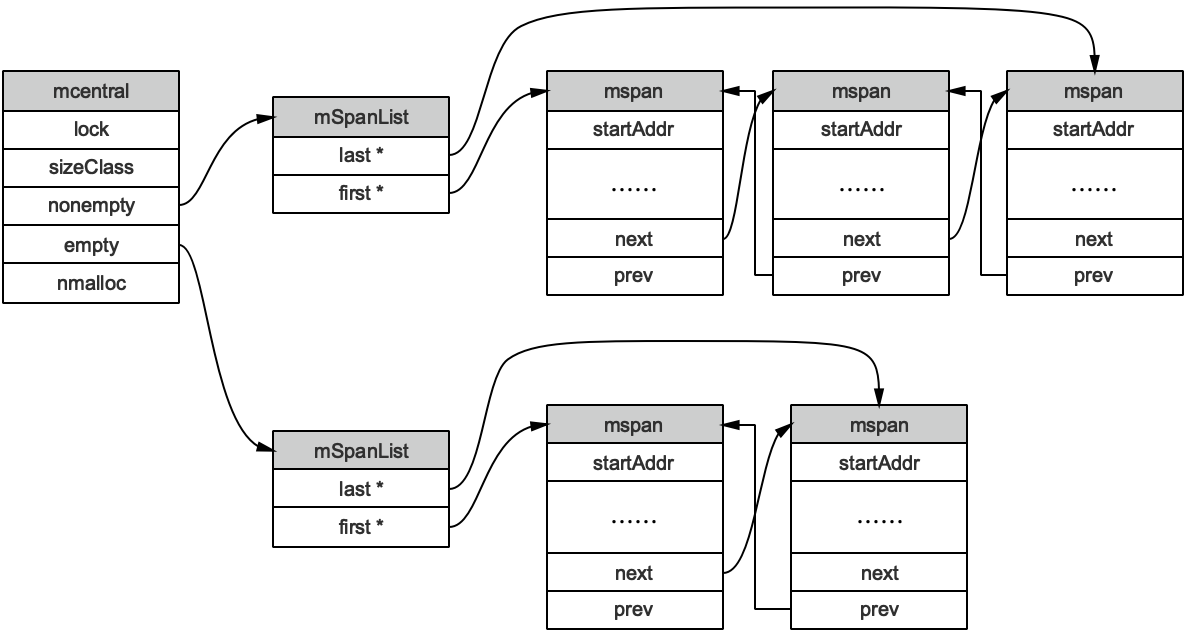
empty表示这条链表里的mspan都被分配了object,或者是已经被cache取走了的mspan,这个mspan就被那个工作线程独占了。而nonempty则表示有空闲对象的mspan列表。每个central结构体都在mheap中维护。
简单说下mcache从mcentral获取和归还mspan的流程:
- 获取
加锁;从nonempty链表找到一个可用的mspan;并将其从nonempty链表删除;将取出的mspan加入到empty链表;将mspan返回给工作线程;解锁。 - 加锁;将mspan从empty链表删除;将mspan加入到nonempty链表;解锁。
mheap
mheap:代表Go程序持有的所有堆空间,Go程序使用一个mheap的全局对象_mheap来管理堆内存。
当mcentral没有空闲的mspan时,会向mheap申请。而mheap没有资源时,会向操作系统申请新内存。mheap主要用于大对象的内存分配,以及管理未切割的mspan,用于给mcentral切割成小对象。
同时我们也看到,mheap中含有所有规格的mcentral,所以,当一个mcache从mcentral申请mspan时,只需要在独立的mcentral中使用锁,并不会影响申请其他规格的mspan。
mheap结构体定义:
//path: /usr/local/go/src/runtime/mheap.go
type mheap struct {
lock mutex
// spans: 指向mspans区域,用于映射mspan和page的关系
spans []*mspan
// 指向bitmap首地址,bitmap是从高地址向低地址增长的
bitmap uintptr
// 指示arena区首地址
arena_start uintptr
// 指示arena区已使用地址位置
arena_used uintptr
// 指示arena区末地址
arena_end uintptr
central [67*2]struct {
mcentral mcentral
pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte
}
}
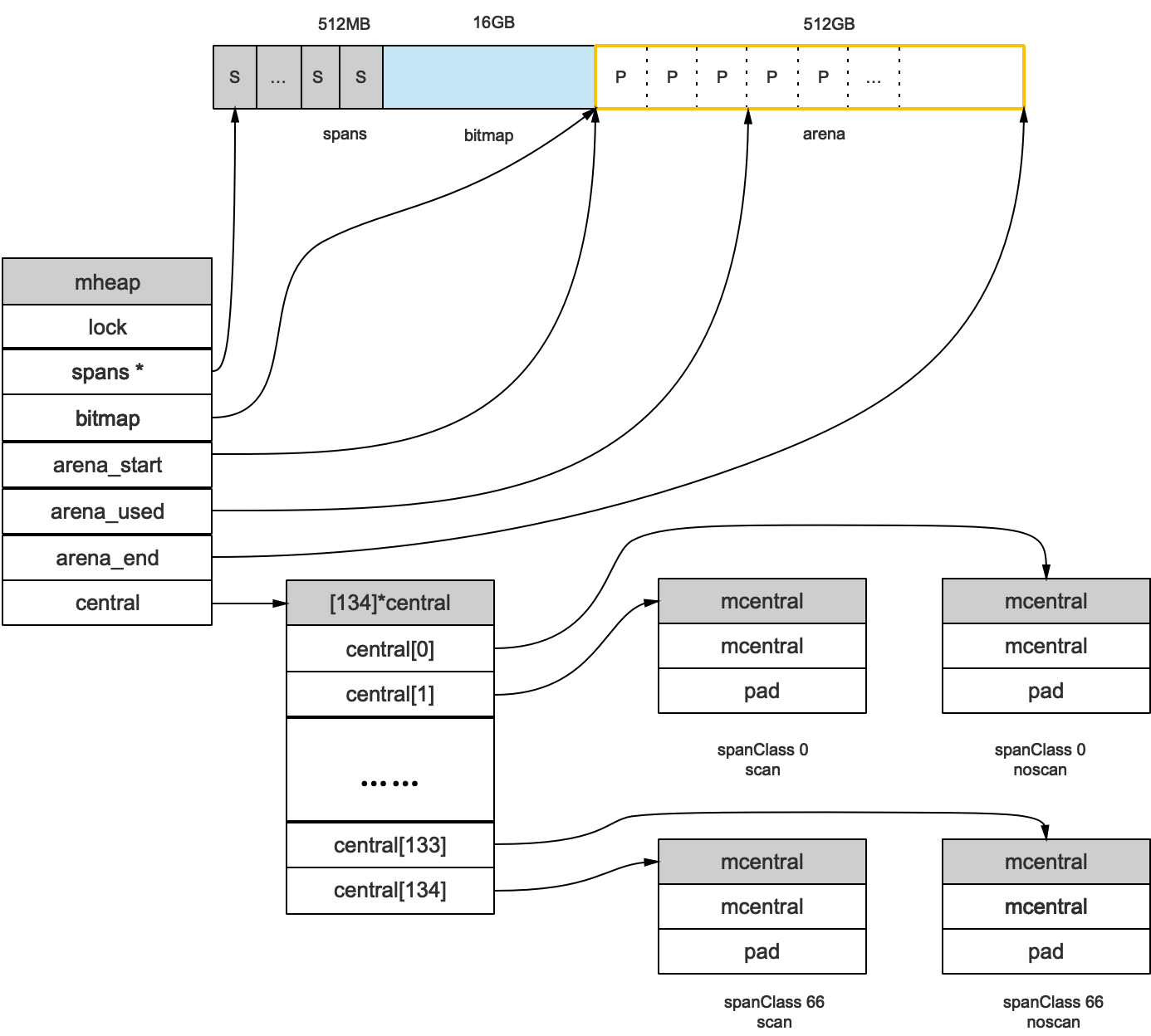
上图我们看到,bitmap和arena_start指向了同一个地址,这是因为bitmap的地址是从高到低增长的,所以他们指向的内存位置相同。
Golang之变量去哪儿,堆 or 栈
什么是逃逸分析
Go语言里就是编译器的逃逸分析。它是编译器执行静态代码分析后,对内存管理进行的优化和简化。
在编译原理中,分析指针动态范围的方法称之为逃逸分析。通俗来讲,当一个对象的指针被多个方法或线程引用时,我们称这个指针发生了逃逸。
更简单来说,逃逸分析决定一个变量是分配在堆上还是分配在栈上。
为什么要逃逸分析
Go的垃圾回收,让堆和栈对程序员保持透明。真正解放了程序员的双手,让他们可以专注于业务,“高效”地完成代码编写。把那些内存管理的复杂机制交给编译器,而程序员可以去享受生活。
逃逸分析这种“骚操作”把变量合理地分配到它该去的地方,“找准自己的位置”。即使你是用new申请到的内存,如果我发现你竟然在退出函数后没有用了,那么就把你丢到栈上,毕竟栈上的内存分配比堆上快很多;反之,即使你表面上只是一个普通的变量,但是经过逃逸分析后发现在退出函数之后还有其他地方在引用,那我就把你分配到堆上。真正地做到“按需分配”
如果变量都分配到堆上,堆不像栈可以自动清理。它会引起Go频繁地进行垃圾回收,而垃圾回收会占用比较大的系统开销(占用CPU容量的25%)。
堆和栈相比,堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片。栈内存分配则会非常快。栈分配内存只需要两个CPU指令:“PUSH”和“RELEASSE”,分配和释放;而堆分配内存首先需要去找到一块大小合适的内存块,之后要通过垃圾回收才能释放。
通过逃逸分析,可以尽量把那些不需要分配到堆上的变量直接分配到栈上,堆上的变量少了,会减轻分配堆内存的开销,同时也会减少gc的压力,提高程序的运行速度。
逃逸分析是怎么完成的
Go逃逸分析最基本的原则是:如果一个函数返回对一个变量的引用,那么它就会发生逃逸。
简单来说,编译器会分析代码的特征和代码生命周期,Go中的变量只有在编译器可以证明在函数返回后不会再被引用的,才分配到栈上,其他情况下都是分配到堆上。
Go语言里没有一个关键字或者函数可以直接让变量被编译器分配到堆上,相反,编译器通过分析代码来决定将变量分配到何处。
对一个变量取地址,可能会被分配到堆上。但是编译器进行逃逸分析后,如果考察到在函数返回后,此变量不会被引用,那么还是会被分配到栈上。 套个取址符,就想骗补助?Too young!
简单来说,编译器会根据变量是否被外部引用来决定是否逃逸:
- 如果函数外部没有引用,则优先放到栈中;
- 如果函数外部存在引用,则必定放到堆中;
- 针对第一条,可能放到堆上的情形:定义了一个很大的数组,需要申请的内存过大,超过了栈的存储能力。
逃逸分析实例
Go提供了相关的命令,可以查看变量是否发生逃逸。
package main
import "fmt"
func foo() *int {
t := 3
return &t
}
func main() {
x := foo()
fmt.Println(*x)
}
foo函数返回一个局部变量的指针,main函数里变量x接收它。执行如下命令:
go build -gcflags '-m -l' main.go
# command-line-arguments
.\main.go:6:2: moved to heap: t
.\main.go:12:13: ... argument does not escape
.\main.go:12:14: *x escapes to heap
foo函数里的变量t逃逸了,和我们预想的一致。让我们不解的是为什么main函数里的x也逃逸了?这是因为有些函数参数为interface类型,比如fmt.Println(a ...interface{}),编译期间很难确定其参数的具体类型,也会发生逃逸。
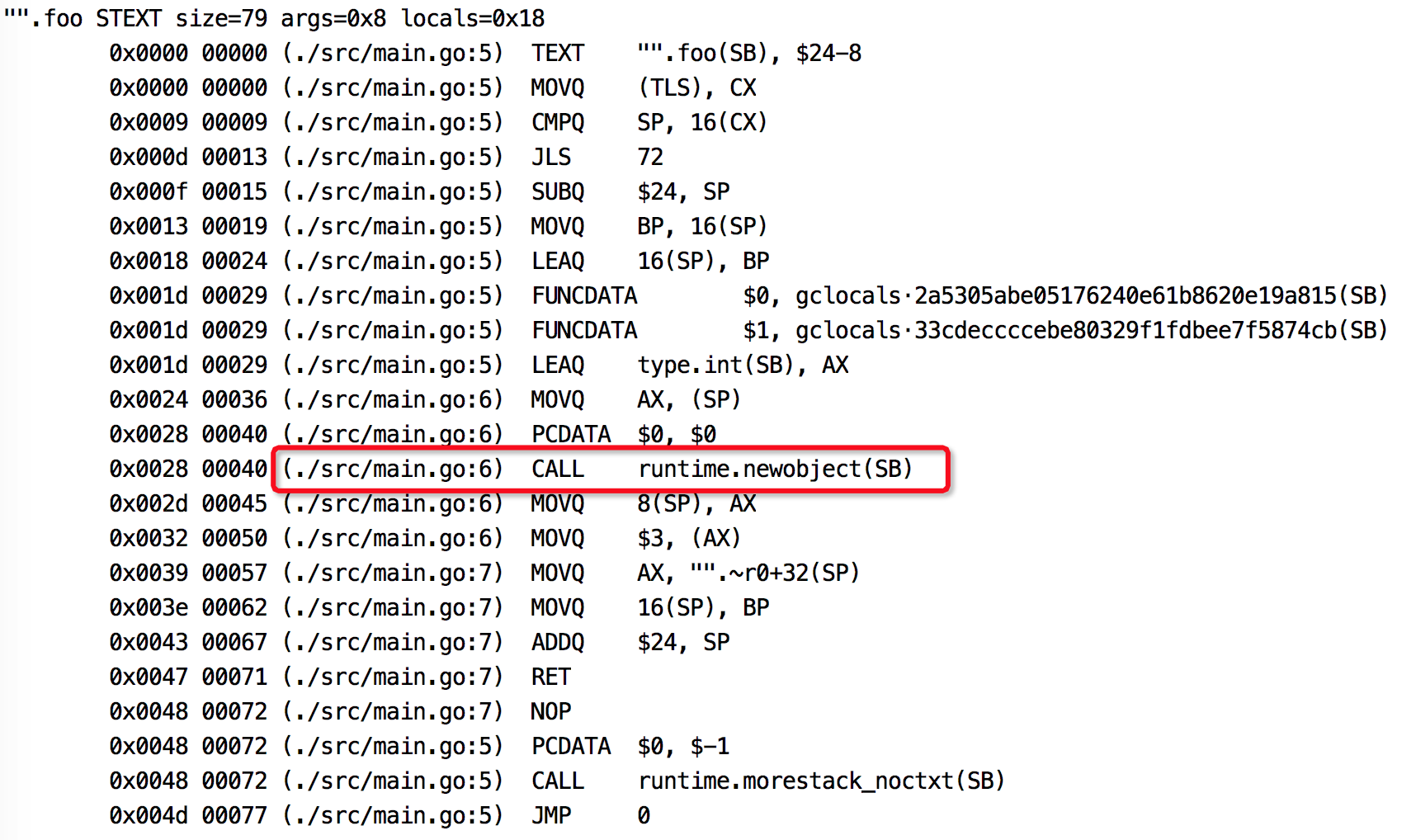
使用反汇编命令也可以看出变量是否发生逃逸。
go tool compile -S main.go
图中标记出来的说明t是在堆上分配内存,发生了逃逸。
总结
堆上动态分配内存比栈上静态分配内存,开销大很多。
变量分配在栈上需要能在编译期确定它的作用域,否则会分配到堆上。
Go编译器会在编译期对考察变量的作用域,并作一系列检查,如果它的作用域在运行期间对编译器一直是可知的,那么就会分配到栈上。
简单来说,编译器会根据变量是否被外部引用来决定是否逃逸。对于Go程序员来说,编译器的这些逃逸分析规则不需要掌握,我们只需通过go build -gcflags '-m'命令来观察变量逃逸情况就行了。
不要盲目使用变量的指针作为函数参数,虽然它会减少复制操作。但其实当参数为变量自身的时候,复制是在栈上完成的操作,开销远比变量逃逸后动态地在堆上分配内存少的多。
最后,尽量写出少一些逃逸的代码,提升程序的运行效率。