
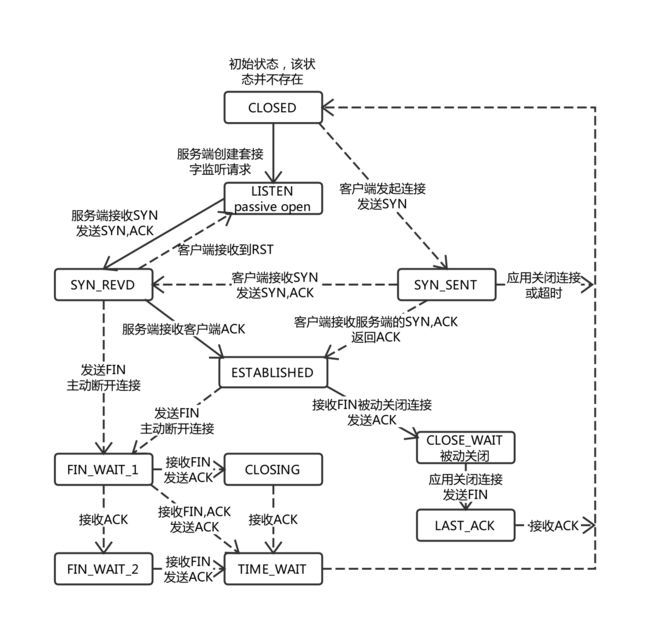
TCP 状态流程图
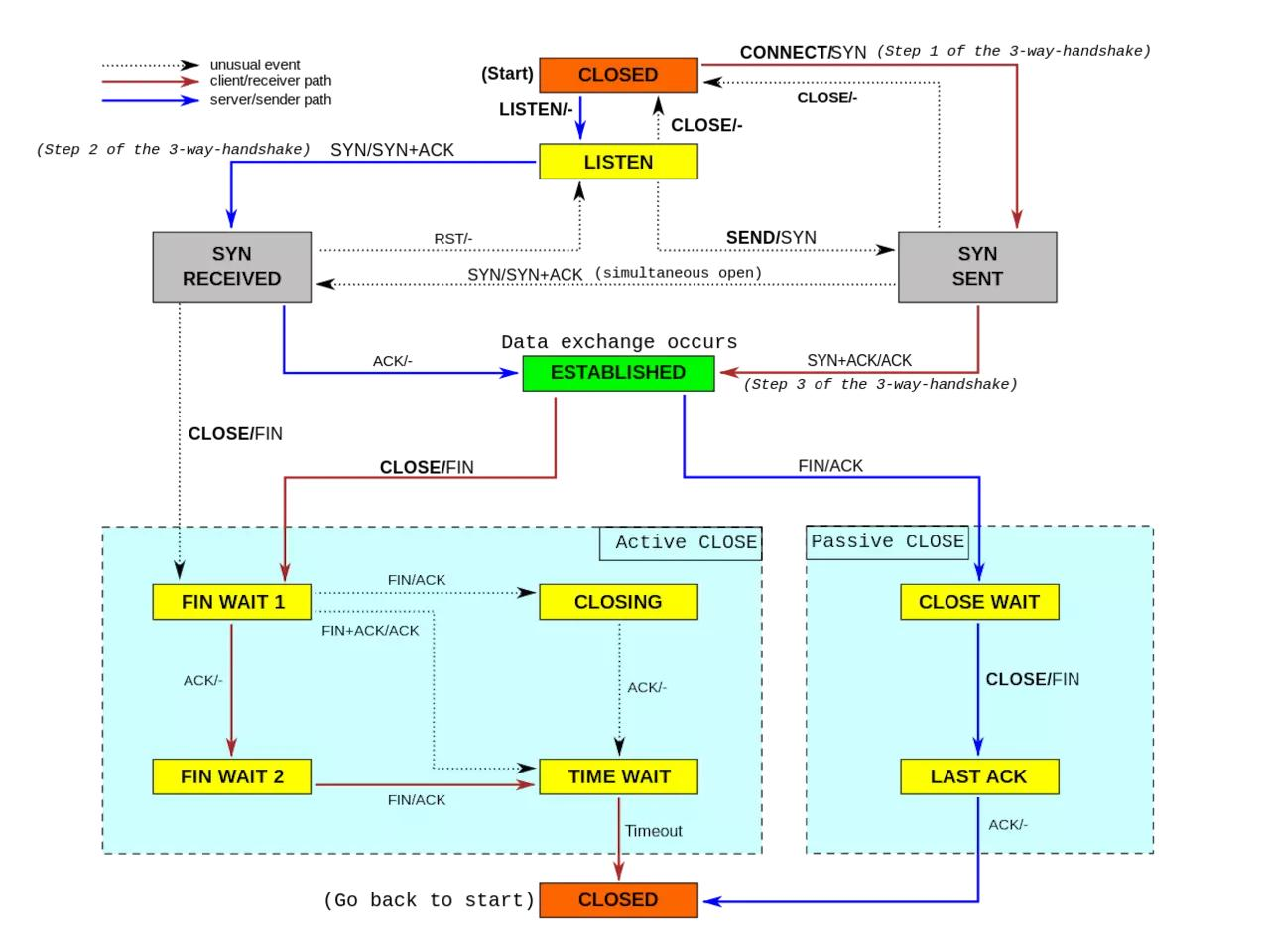
当TCP连接关闭之前,首先发起关闭的一方会进入TIME-WAIT状态,另一方可以快速回收连接。被动关闭一方会进入 CLOSE_WAIT 状态。
命令查看端口连接数
使用 netstat 命令
查看 TCP 连接的当前状态。
netstat -anp|grep :2379|awk '{print $6}'| sort|uniq -c
176 ESTABLISHED
2 LISTEN
使用 ss 命令
ss -tan | grep :2379 | awk '{print $1}'| sort|uniq -c
176 ESTAB
2 LISTEN

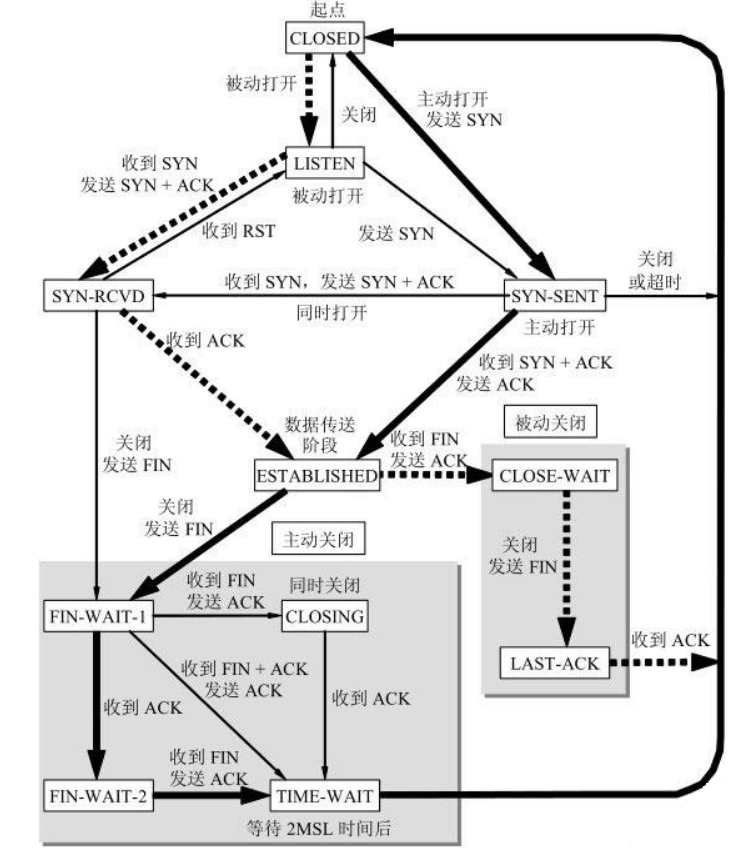
TCP 三次握手各个状态的意义:
主动方
打开
SYN_SENT:套接字正在试图主动建立连接[发送SYN后还没有收到ACK]
ESTABLISHED:连接已建立,代表一个打开的连接,可以传输数据。
关闭
FIN_WAIT1:套接字已关闭,正在关闭连接[发送FIN,没有收到ACK也没有收到FIN]
CLOSING:套接字已关闭,远程套接字正在关闭,暂时挂起关闭确认[在FIN_WAIT1状态下收到被动方的FIN]
FIN_WAIT2:套接字已关闭,正在等待远程套接字关闭[在FIN_WAIT_1状态下收到发过去FIN对应的ACK]
TIME_WAIT:这个套接字已经关闭,正在等待远程套接字的关闭传送[FIN、ACK、FIN、ACK都完毕,这是主动方的最后一个状态,在过了2MSL时间后变为CLOSED状态]
CLOSED:等待 2MSL 后变为关闭状态。
被动方:
打开
LISTEN:套接字正在监听连接[调用listen后]
SYN_RECEIVED:正在处于连接的初始同步状态[收到对方的SYN,但还没收到自己发过去的SYN的ACK]
ESTABLISHED:连接已建立,代表一个打开的连接,可以传输数据。
关闭
CLOSE_WAIT:远程套接字已经关闭:正在等待关闭这个套接字[被动关闭的一方收到FIN]
LAST_ACK:远程套接字已关闭,正在等待本地套接字的关闭确认[被动方在CLOSE_WAIT状态下发送FIN]
CLOSED:连接关闭没有任何连接的状态。
应用举例
Linux 中出现大量 established 连接
结论
使用 TCP keepalive 防止出现大量 established 连接
这种僵尸established连接是不是有可能在对端不正常关闭(拔网线等极端状态)时存在?目前我使用开启keep-alive选项解决。这种僵尸established连接,程序会稍后recv得到通知而断开。
最后,经过分析和实验,我感觉,以上的问题是网络不可阻的问题,最后我只是在程序中为每个连接开启了keep alive的选项。
查看 established 连接计数
使用 netstat 命令
netstat -an |grep 'ESTABLISHED' |grep 'tcp' |wc -l
使用 ss 命令
ss -tan | grep ESTAB | wc -l
一次对进程大量积压 ESTABLISHED 链接的排查手记
背景
基于FTP协议+gRPC协议自研的FTP代理工具。
这个工具上线后,服务全公司所有研发,经过一段时间运行和修补,相对稳定,也做了一些关于内存方面的优化,直到又一次,在维护这个FTP代理的时候,发现一个奇怪的问题:
FTP代理进程,监听的是 192.168.88.32 的 21 端口,所以,这个端口对应了多少连接,就表示有多少个客户端存在,通过:
netstat -apn |grep "192.168.88.32:21" | wc -l
发现,有将近1000个链接,且都是 ESTABLISHED,ESTABLISHED 状态表示一个连接的状态是“已连接”,但我们研发团队,并没有那么多人,直觉上看,事出反常必有妖。
初步分析可能性
感觉可能有一种情况,就是每个人开了多个FTP客户端,实际场景下,研发同学组可能会使用3种类型的FTP客户端
PHPStorm:这个客户端(SFTP插件)自己会维护一个FTP长连接。
Sublime + VsCode,这2个客户端不会维护链接,数据交互完成(比如传输任务),就主动发送 QUIT 指令到FTP代理端,然后所有链接关闭。很干净。
另外,使用PHPStorm的话,也存在开多个IDE创建,就使用多个FTP客户端连接的情况。
为了继续排查,我把所有对 192.168.88.32:21 的链接,做了分组统计,看看哪个IP的连接数最多
# 注:61604 是 ftp代理的进程ID
netstat -apn|grep "61604/server"|grep '192.168.88.32:21'|awk -F ':' '{print$2}'|awk '{print$2}'|sort|uniq -c |sort
上面的统计,是看哪个IP,对 192.168.88.32:21 连接数最多(18个)。
统计发现,很多IP,都存在多个链接的情况,难道每个人都用了多个IDE且可能还多IDE窗口使用吗?于是,挑了一个最多的,找到公司中使用这个IP的人,沟通发现,他确实使用了IDE多窗口,但是远远没有使用18个客户端那么多,仅仅PHPStorm开了3个窗口而已。
初步排查结论:应该是FTP代理所在服务器的问题,和用户开多个客户端没有关系。
进一步排查
这次排查,是怀疑,这将近1000个的 ESTABLISHED 客户端链接中,有大量假的 ESTABLISHED 链接存在,之前的统计发现,实际上,对 192.168.88.32:21 的客户端链接进行筛选,得到的IP,一共才200个客户端IP而已,平均下来,每个人都有5个FTP客户端链接FTP代理,想象觉得不太可能。那么,如何排查 ESTABLISHED 假链接呢?
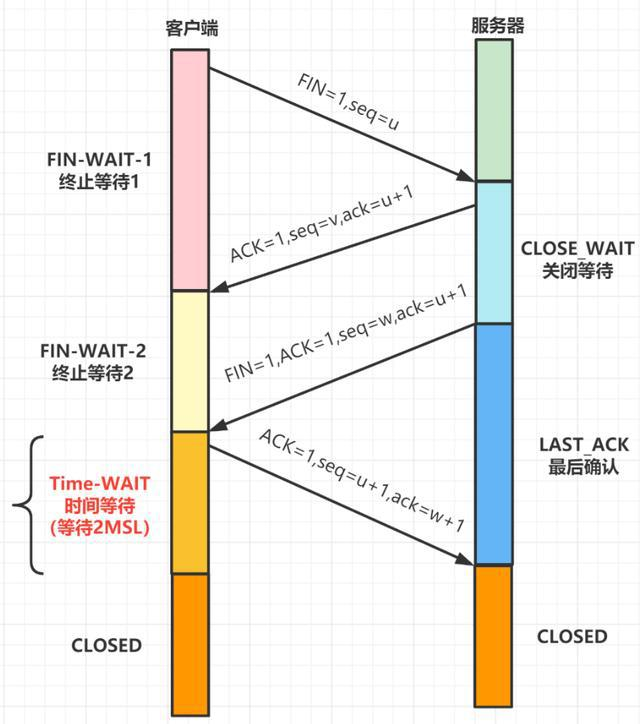
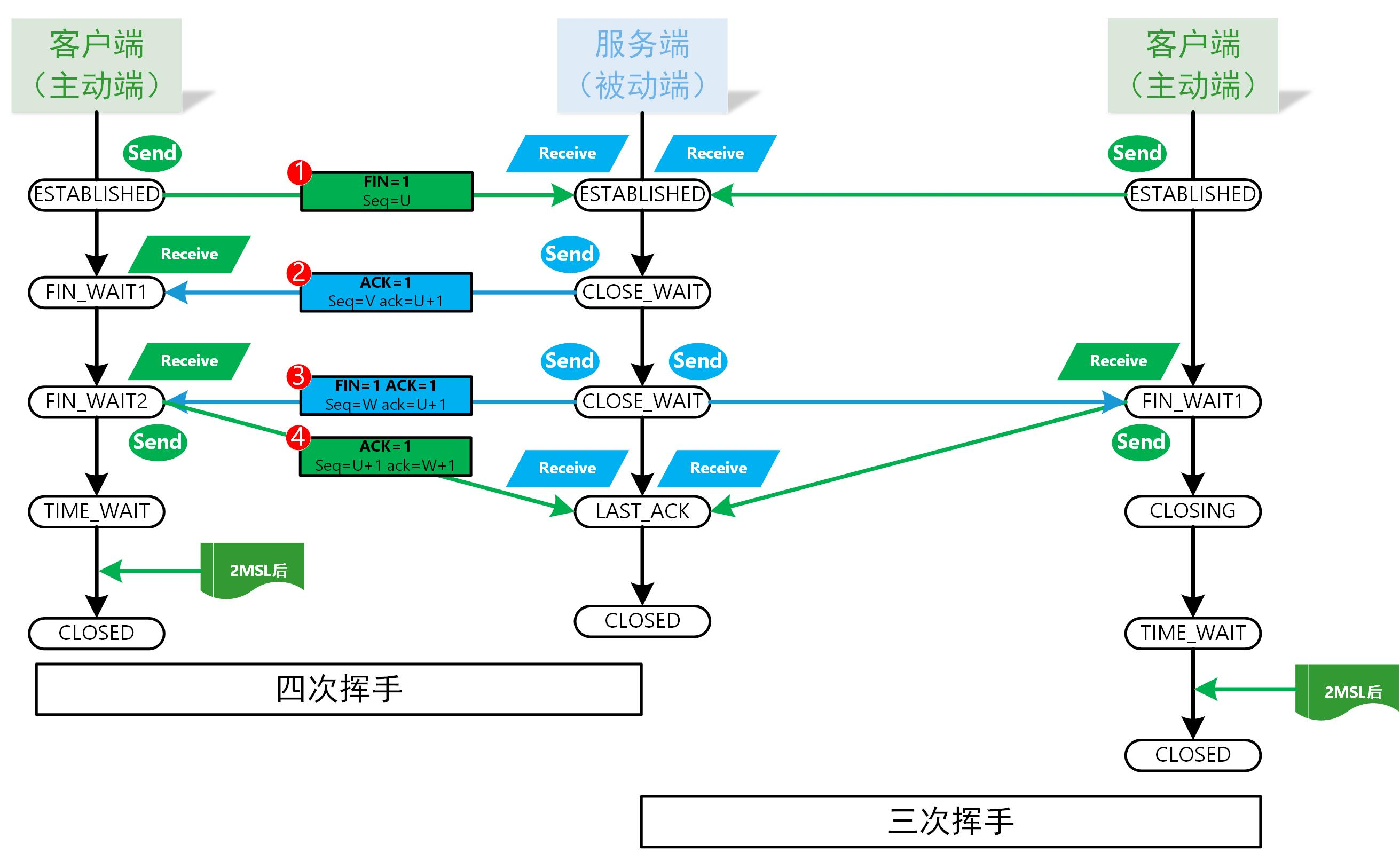
在 TCP 四次挥手过程中,首先需要有一端,发起 FIN 包,接收方接受到 FIN 包之后,便开启四次挥手的过程,这也是连接断开的过程。
从之前的排查看,有人的IP,发起了多达18个FTP连接,那么,要排查是不是在 FTP 代理服务器上,存在假的 ESTABLISHED 连接的话,就首先需要去 开发同学的机器上看,客户端连接的端口,是不是仍在使用。比如:
tcp ESTAB 0 0 192.168.88.32:21 192.168.67.38:58038
这个表明,有一个研发的同学 IP是 192.168.67.38,使用了端口 58038,连接 192.168.88.32 上的 FTP 代理服务的 21 端口。所以,先要去看,到底研发同学的电脑上,这个端口存在不存在。
后来经过与研发同学沟通确认,研发电脑上并没有 58038 端口使用,这说明,对FTP代理服务的的客户端链接中显示的端口,也就是实际用户的客户端端口,存在大量不存在的情况。
结论:FTP代理服务器上,存在的近1000个客户端连接中(ESTABLISHED状态),有大量的假连接存在。也就是说,实际上这个连接早就断开不存在了,但服务端却还显示存在。
排查假 ESTABLISHED 连接
首先,如果出现假的 ESTABLISHED 连接,表示连接的客户端已经不存在了,客户端一方,要么发起了 TCP FIN 请求服务端没有收到,比如因为网络的各种原因(比如断网了)之后,FTP客户端无法发送FIN到服务端。要么服务端服务器接受到了 FIN,但是在后续过程中,丢包了等等。
为了验证上面的问题,我本机进行了一次模拟,连接FTP服务端后,本机直接断网,断网后,杀死FTP客户端进程,等待5分钟(为什么等待5分钟后面说)后,重新联网。然后再 FTP 服务端,查看服务器上与 FTP代理进行连接的所有IP,然后发现我本机的IP和端口依然在列,然后再我本机,通过:
lsof -i :端口号
注:-i<条件> 列出符合条件的进程。(4、6、协议、:端口、 @ip )
却没有任何记录,直接说明:服务端确实保持了假 ESTABLISHED 链接,一直不释放。
上面提到,我等待5分钟,是因为,服务端的 keepalive,是这样的配置:
[root@xx xx]# sysctl -a |grep keepalive
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 300
服务器默认设置的 tcp keepalive 检测是300秒后进行检测,也就是5分钟,当检测失败后,一共进行9次重试,每次时间间隔是75秒。
那么,问题就来了,服务器设置了 keepalive,如果 300 + 9*75 秒后,依然连接不上,就应该主动关闭假 ESTABLISHED 连接才对。为何还会积压呢?
猜想1:大量的积压的 ESTABLISHED 连接,实际上都还没有到释放时间
为了验证这个问题,我们就需要具体的看某个连接,什么时候创建的。所以,我找到其中一个我确定是假的 ESTABLISHED的链接(那个IP的用户,把所有FTP客户端都关了,进程也杀死了),看此连接的创建时间,过程如下:
先确定 FTP 代理进程的ID,为 61604
然后,看看这个进程的所有连接,找到某个端口的(55360,就是一个客户端所使用的端口)
[root@xxx xxx]# lsof -p 61604|grep 55360
server 61604 root 6u IPv4 336087732 0t0 TCP node088032:ftp->192.168.70.16:55360 (ESTABLISHED)
-p<进程号> 列出指定进程号所打开的文件
我们看到一个 “6u”,这个就是进程使用的这个连接的socket文件,Linux中,一切皆文件。我们看看这个文件的创建时间,就是这个连接的创建时间了
ll /proc/61604/fd/6
//输出:
lrwx------. 1 root root 64 Nov 1 14:03 /proc/61604/fd/6 -> socket:[336087732]
这个连接是11月1号创建的,现在已经11月8号,这个时间,早已经超出了 keepalive 探测 TCP连接是否存活的时间。这说明2个点:
1、可能 Linux 的 KeepAlive 压根没生效。
2、可能我的 FTP 代理进程,压根没有使用 TCP KeepAlive
猜想2: FTP 代理进程,压根没有使用 TCP KeepAlive
要验证这个结论,就得先知道,怎么看一个连接,到底具不具备 KeepAlive 功效?
netstat 命令不好使(也可能我没找到方法),我们使用 ss 命令,查看 FTP进程下所有连接21端口的链接
ss -aoen|grep 192.168.12.32:21|grep ESTAB
从众多结果中,随便筛选2个结果:
tcp ESTAB 0 0 192.168.12.32:21 192.168.20.63:63677 ino:336879672 sk:65bb <->
tcp ESTAB 0 0 192.168.12.32:21 192.168.49.21:51896 ino:336960511 sk:67f7 <->
我们再对比一下,所有连接服务器sshd进程的
tcp ESTAB 0 0 192.168.12.32:333 192.168.53.207:63269 timer:(keepalive,59sec,0) ino:336462258 sk:6435 <->
tcp ESTAB 0 0 192.168.12.32:333 192.168.55.185:64892 timer:(keepalive,3min59sec,0) ino:336461969 sk:62d1 <->
tcp ESTAB 0 0 192.168.12.32:333 192.168.53.207:63220 timer:(keepalive,28sec,0) ino:336486442 sk:6329 <->
tcp ESTAB 0 0 192.168.12.32:333 192.168.53.207:63771 timer:(keepalive,12sec,0) ino:336896561 sk:65de <->
对比很容易发现,连接 21端口的所有连接,多没有 timer 项。这说明,FTP代理 进程监听 21 端口时,所有进来的链接,全都没有使用keepalive。
找了一些文章,大多只是说,怎么配置Linux 的 Keep Alive,以及不配置的,会造成 ESTABLISHED 不释放问题,没有说进程需要额外设置啊?难道 Linux KeepAlive 配置,不是对所有连接直接就生效的?
所以,我们有必要验证 Linux keepalive,必须要进程自己额外开启才能生效
验证 Linux keepalive,必须要进程自己额外开启才能生效
在开始这个验证之前,先摘取一段FTP中间件代理关于监听 21 端口的部分代码:
func (ftpServer *FTPServer) ListenAndServe() error {
laddr, err := net.ResolveTCPAddr("tcp4", ftpServer.listenTo)
if err != nil {
return err
}
listener, err := net.ListenTCP("tcp4", laddr)
if err != nil {
return err
}
for {
clientConn, err := listener.AcceptTCP()
if err != nil || clientConn == nil {
ftpServer.logger.Print("listening error")
break
}
//以闭包的方式整理处理driver和ftpBridge,协程结束整体由GC做资源释放
go func(c *net.TCPConn) {
driver, err := ftpServer.driverFactory.NewDriver(ftpServer.FTPDriverType)
if err != nil {
ftpServer.logger.Print("Error creating driver, aborting client connection:" + err.Error())
} else {
ftpBridge := NewftpBridge(c, driver)
ftpBridge.Serve()
}
c = nil
}(clientConn)
}
return nil
}
足够明显,整个函数,net.ListenTCP 附近都没有任何设置KeepAlive的相关操作。我们查看 相关函数,找到了设置 KeepAlive的地方,进行一下设置:
if err != nil || clientConn == nil {
ftpServer.logger.Print("listening error")
break
}
// 此处,设置 keepalive
clientConn.SetKeepAlive(true)
重新构建部署之后,可以看到,所有对21端口的连接,全部都带了 timer
ss -aoen|grep 192.168.12.32:21|grep ESTAB
输出如下:
tcp ESTAB 0 0 192.168.12.32:21 192.168.70.76:54888 timer:(keepalive,1min19sec,0) ino:397279721 sk:6b49 <->
tcp ESTAB 0 0 192.168.12.32:21 192.168.37.125:49648 timer:(keepalive,1min11sec,0) ino:398533882 sk:6b4a <->
tcp ESTAB 0 0 192.168.12.32:21 192.168.33.196:64471 timer:(keepalive,7.957ms,0) ino:397757143 sk:6b4c <->
tcp ESTAB 0 0 192.168.12.32:21 192.168.21.159:56630 timer:(keepalive,36sec,0) ino:396741646 sk:6b4d <->
可以很明显看到,所有的连接,全部具备了 timer 功效,说明:想要使用 Linux 的 KeepAlive,需要程序单独做设置进行开启才行。
最后:ss 命令结果中 keepalive 的说明
首先,看一下 Linux 中的配置,我的机器如下:
[root@xx xx]# sysctl -a |grep keepalive
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 300
tcp_keepalive_time:表示多长时间后,开始检测TCP链接是否有效。
tcp_keepalive_probes:表示如果检测失败,会一直探测 9 次。
tcp_keepalive_intvl:承上,探测9次的时间间隔为 75 秒。
然后,我们看一下 ss 命令的结果:
ss -aoen|grep 192.168.12.32:21|grep ESTAB
tcp ESTAB 0 0 192.168.12.32:21 192.168.70.76:54888 timer:(keepalive,1min19sec,0) ino:397279721 sk:6b49 <->
摘取这部分:timer:(keepalive,1min19sec,0) ,其中:
keepalive:表示此链接具备 keepalive 功效。1min19sec:表示剩余探测时间,这个时间每次看都会边,是一个递减的值,第一次探测,需要 net.ipv4.tcp_keepalive_time 这个时间倒计时,如果探测失败继续探测,后边会按照 net.ipv4.tcp_keepalive_intvl 这个时间值进行探测。直到探测成功。0:这个值是探测时,检测到这是一个无效的TCP链接的话已经进行了的探测次数。
Linux 中出现大量 TIME_WAIT连接
TCP协议中有TIME_WAIT这个状态,主要有两个原因:
- 防止上一次连接中的包,迷路后重新出现,影响新连接(经过2MSL,上一次连接中所有的重复包都会消失)
- 可靠的关闭TCP连接。在主动关闭方发送的最后一个 ack(fin) ,有可能丢失,这时被动方会重新发fin, 如果这时主动方处于 CLOSED 状态 ,就会响应 rst 而不是 ack。所以主动方要处于 TIME_WAIT 状态,而不能是 CLOSED 。
相关命令
# 查看某个/特定ip的连接数
netstat -an |grep xx |wc -l
# 查看连接数等待time_wait状态连接数
netstat -an |grep TIME_WAIT|wc -l
# 查看建立稳定连接数量
netstat -an |grep ESTABLISHED |wc -l
# 查看不同状态的连接数数量
netstat -an | awk '/^tcp/ {++y[$NF]} END {for(w in y) print w, y[w]}'
LISTEN 8
ESTABLISHED 2400
FIN_WAIT1 2
TIME_WAIT 6000
# 查看每个ip跟服务器建立的连接数
netstat -nat|grep "tcp"|awk ' {print$5}'|awk -F : '{print$1}'|sort|uniq -c|sort -rn
444 10.71.177.123
102 100.11.71.123
101 49.14.55.132
# (PS:正则解析:显示第5列,-F : 以:分割,显示列,sort 排序,uniq -c统计排序过程中的重复行,sort -rn 按纯数字进行逆序排序)
# 查看每个ip建立的ESTABLISHED/TIME_OUT状态的连接数
netstat -nat|grep ESTABLISHED|awk '{print$5}'|awk -F : '{print$1}'|sort|uniq -c|sort -rn
24 103.56.195.17
19 45.116.147.186
18 103.56.195.18
17 45.116.147.178
解决大量 TIME_WAIT
通过调整内核参数:
vim /etc/sysctl.conf
编辑文件,加入以下内容:
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
然后执行 /sbin/sysctl -p 让参数生效。
配置说明:
net.ipv4.tcp_syncookies = 1
# 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1
# 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1
# 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭;
net.ipv4.tcp_fin_timeout=30
# 修改系統默认的 TIMEOUT 时间。
如果以上配置调优后性能还不理想,可继续修改一下配置:
net.ipv4.tcp_keepalive_time = 1200
#表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.ip_local_port_range = 1024 65000
#表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为1024到65000。
net.ipv4.tcp_max_syn_backlog = 8192
#表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 5000
#表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。
默认为180000,改为5000。对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIME_WAIT套接字数量。
但是对于 Squid,效果却不大。此项参数可以控制TIME_WAIT套接字的最大数量,避免Squid服务器被大量的TIME_WAIT套接字拖死。
命令详解
lsof
命令参数:
-a 列出打开文件存在的进程
-c <进程名> 列出指定进程所打开的文件
-g 列出GID号进程详情
-d <文件号> 列出占用该文件号的进程
+d <目录> 列出目录下被打开的文件
+D <目录> 递归列出目录下被打开的文件
-n <目录> 列出使用NFS的文件
-i <条件> 列出符合条件的进程。(4、6、协议、:端口、 @ip )
-p <进程号> 列出指定进程号所打开的文件
-u 列出UID号进程详情
-h 显示帮助信息
-v 显示版本信息
ss
命令参数
-n 不解析服务名称,已数字方式显示
-a 显示所有套接字
-l 显示处于监听状态的套接字
-o 显示计时器信息
-e 显示详细的套接字信息
-m 显示套接字的内存使用情况
-p 显示使用套接字的进程
-i 显示内部的TCP信息
-s 显示套接字使用概况
-4 仅显示ipv4的套接字
-6 仅显示ipv6的套接字
-0 显示PACKET套接字
-t 只显示TCP套接字
-u 只显示UDP套接字
-d 只显示DCCP套接字
-w 只显示RAW套接字
-x 只显示 Unix套接字
-D 将原始TCP套接字信息转储到文件
TCP 连接队列优化
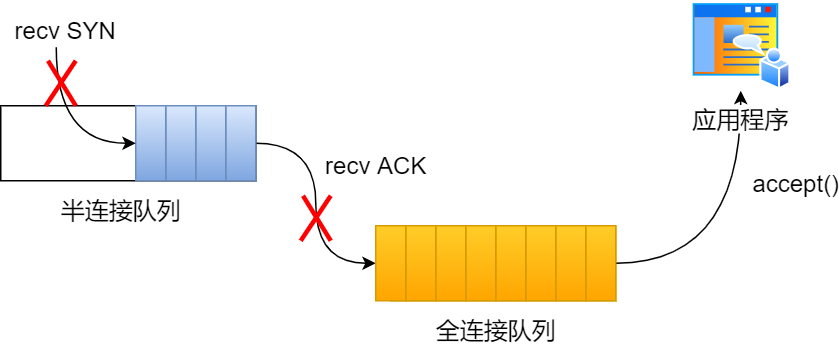
什么是 TCP 半连接队列和全连接队列
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:
- 半连接队列,也称 SYN 队列;
- 全连接队列,也称 Accepet 队列;
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应 SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。
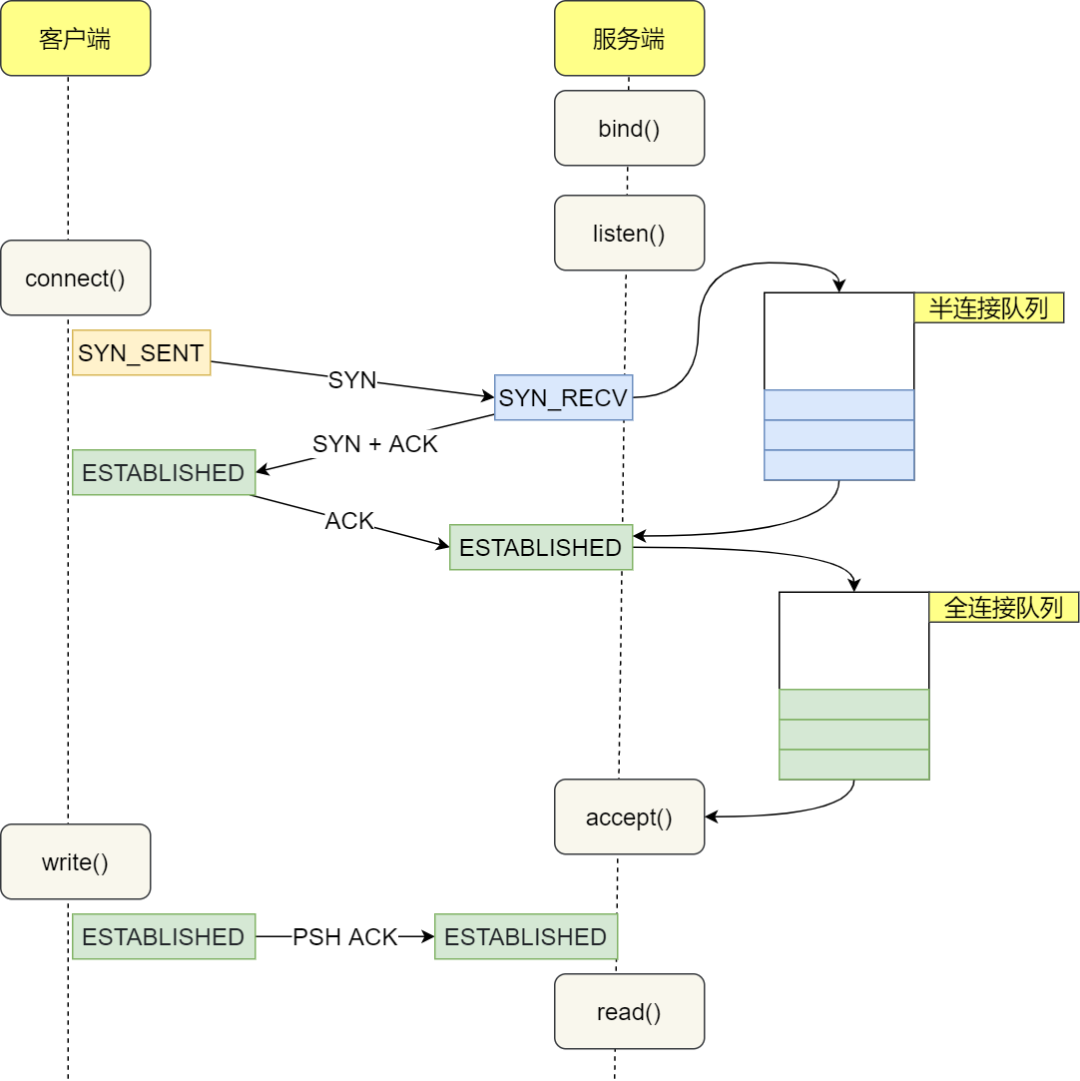
不管是半连接队列还是全连接队列,都有最大长度限制,超过限制时,内核会直接丢弃,或返回 RST 包。
实战 - TCP 全连接队列溢出
如何知道应用程序的 TCP 全连接队列大小?
在服务端可以使用 ss 命令,来查看 TCP 全连接队列的情况:
在「LISTEN 状态」时,Recv-Q/Send-Q 表示的含义如下:
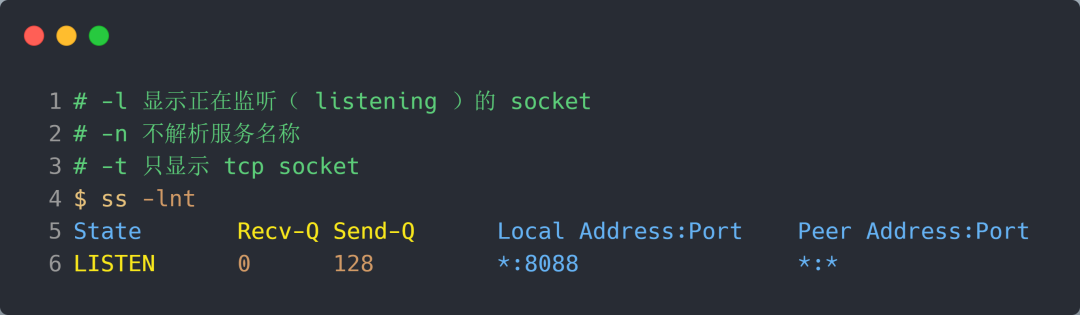
- Recv-Q:当前全连接队列的大小,也就是当前已完成三次握手并等待服务端 accept() 的 TCP 连接个数;
- Send-Q:当前全连接最大队列长度,上面的输出结果说明监听 8088 端口的 TCP 服务进程,最大全连接长度为 128;
在「非 LISTEN 状态」时,Recv-Q/Send-Q 表示的含义如下:
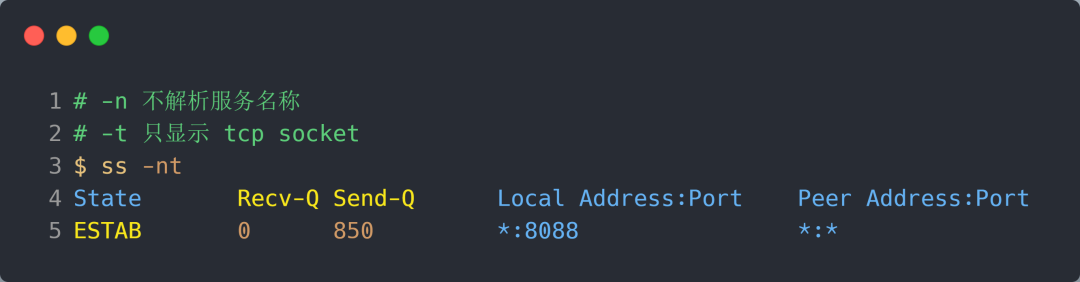
- Recv-Q:已收到但未被应用进程读取的字节数;
- Send-Q:已发送但未收到确认的字节数;
TCP 全连接队列溢出问题
当超过了 TCP 最大全连接队列,服务端则会丢掉后续进来的 TCP 连接,丢掉的 TCP 连接的个数会被统计起来,我们可以使用 netstat -s 命令来查看:

上面看到的 41150 times ,表示全连接队列溢出的次数,注意这个是累计值。可以隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
从上面的模拟结果,可以得知,当服务端并发处理大量请求时,如果 TCP 全连接队列过小,就容易溢出。发生 TCP 全连接队溢出的时候,后续的请求就会被丢弃,这样就会出现服务端请求数量上不去的现象。
全连接队列满了,就只会丢弃连接吗?
实际上,丢弃连接只是 Linux 的默认行为,我们还可以选择向客户端发送 RST 复位报文,告诉客户端连接已经建立失败。
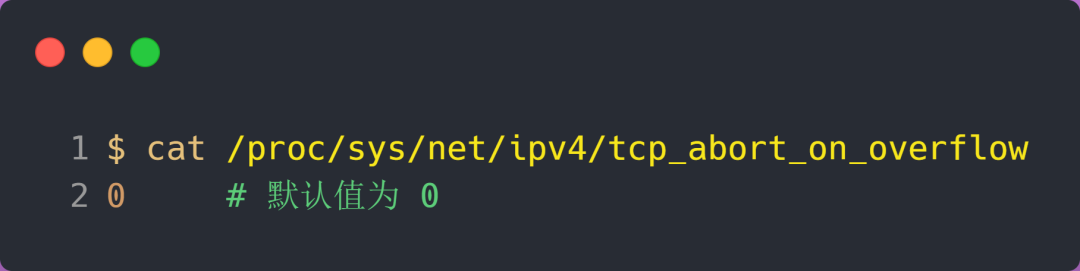
tcp_abort_on_overflow 共有两个值分别是 0 和 1,其分别表示:
- 0 :表示如果全连接队列满了,那么 server 扔掉 client 发过来的 ack ;
- 1 :表示如果全连接队列满了,那么 server 发送一个 reset 包给 client,表示废掉这个握手过程和这个连接;
如果要想知道客户端连接不上服务端,是不是服务端 TCP 全连接队列满的原因,那么可以把 tcp_abort_on_overflow 设置为 1,这时如果在客户端异常中可以看到很多 connection reset by peer 的错误,那么就可以证明是由于服务端 TCP 全连接队列溢出的问题。
通常情况下,应当把 tcp_abort_on_overflow 设置为 0,因为这样更有利于应对突发流量。
举个例子,当 TCP 全连接队列满导致服务器丢掉了 ACK,与此同时,客户端的连接状态却是 ESTABLISHED,进程就在建立好的连接上发送请求。只要服务器没有为请求回复 ACK,请求就会被多次重发。如果服务器上的进程只是短暂的繁忙造成 accept 队列满,那么当 TCP 全连接队列有空位时,再次接收到的请求报文由于含有 ACK,仍然会触发服务器端成功建立连接。
所以,tcp_abort_on_overflow 设为 0 可以提高连接建立的成功率,只有你非常肯定 TCP 全连接队列会长期溢出时,才能设置为 1 以尽快通知客户端。
如何增大 TCP 全连接队列呢?
是的,当发现 TCP 全连接队列发生溢出的时候,我们就需要增大该队列的大小,以便可以应对客户端大量的请求。
TCP 全连接队列足最大值取决于 somaxconn 和 backlog 之间的最小值,也就是 min(somaxconn, backlog)。
- somaxconn 是 Linux 内核的参数,默认值是 128,可以通过 /proc/sys/net/core/somaxconn 来设置其值;
- backlog 是 listen(int sockfd, int backlog) 函数中的 backlog 大小,Nginx 默认值是 511,可以通过修改配置文件设置其长度;
实战 - TCP 半连接队列溢出
如何查看 TCP 半连接队列长度?
很遗憾,TCP 半连接队列长度的长度,没有像全连接队列那样可以用 ss 命令查看。
但是我们可以抓住 TCP 半连接的特点,就是服务端处于 SYN_RECV 状态的 TCP 连接,就是在 TCP 半连接队列。
于是,我们可以使用如下命令计算当前 TCP 半连接队列长度:

如何模拟 TCP 半连接队列溢出场景?
模拟 TCP 半连接溢出场景不难,实际上就是对服务端一直发送 TCP SYN 包,但是不回第三次握手 ACK,这样就会使得服务端有大量的处于 SYN_RECV 状态的 TCP 连接。
这其实也就是所谓的 SYN 洪泛、SYN 攻击、DDos 攻击。
TCP 半连接队列的最大值是如何决定的
TCP 第一次握手(收到 SYN 包)的 Linux 内核代码如下,其中缩减了大量的代码,只需要重点关注 TCP 半连接队列溢出的处理逻辑:
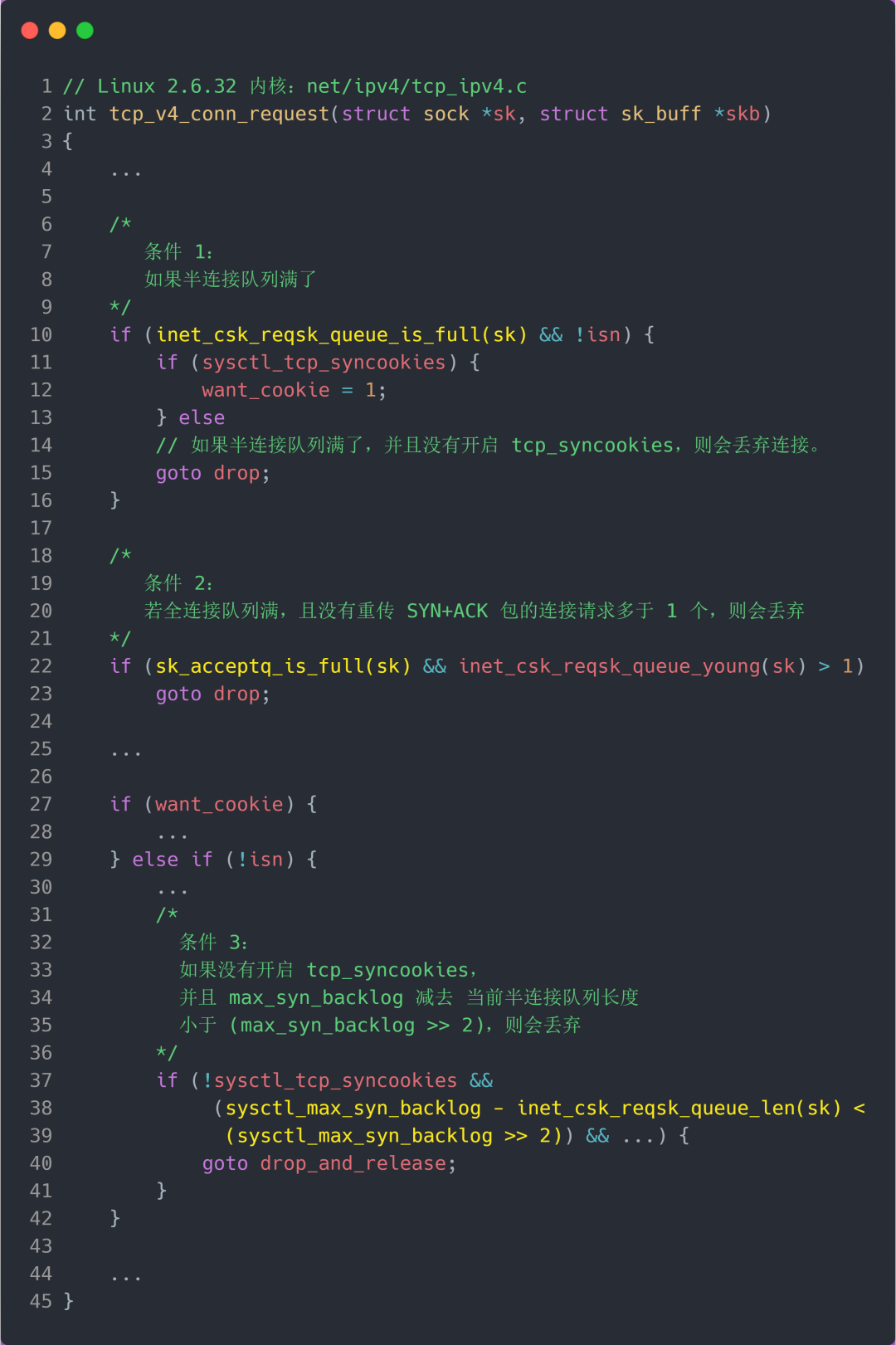
从源码中,我可以得出共有三个条件因队列长度的关系而被丢弃的:
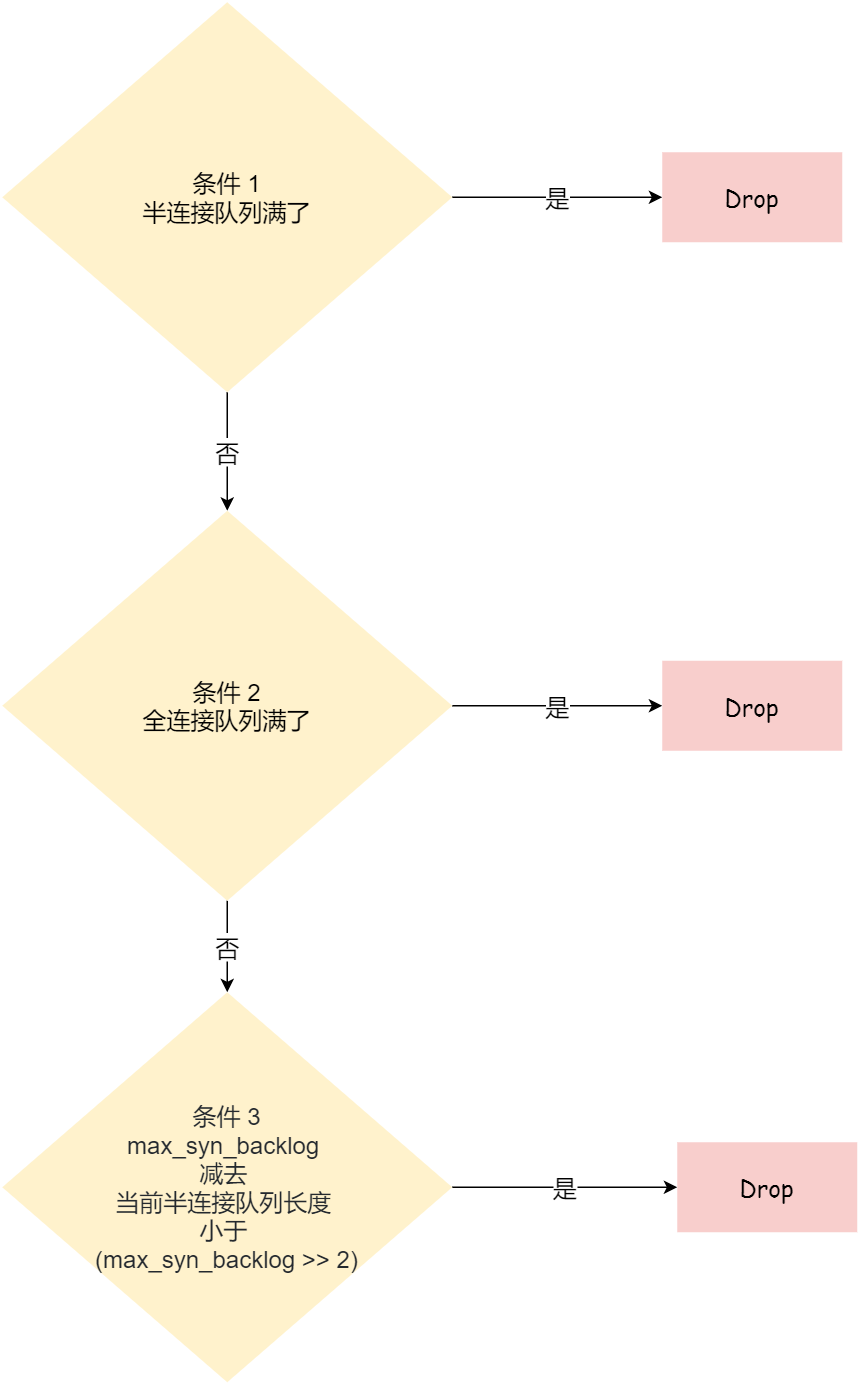
- 如果半连接队列满了,并且没有开启 tcp_syncookies,则会丢弃;
- 若全连接队列满了,且没有重传 SYN+ACK 包的连接请求多于 1 个,则会丢弃;
- 如果没有开启 tcp_syncookies,并且 max_syn_backlog 减去 当前半连接队列长度小于 (max_syn_backlog >> 2),则会丢弃;
可见,半连接队列最大值不是单单由 max_syn_backlog 决定,还跟 somaxconn 和 backlog 有关系。
在 Linux 2.6.32 内核版本,它们之间的关系,总体可以概况为:
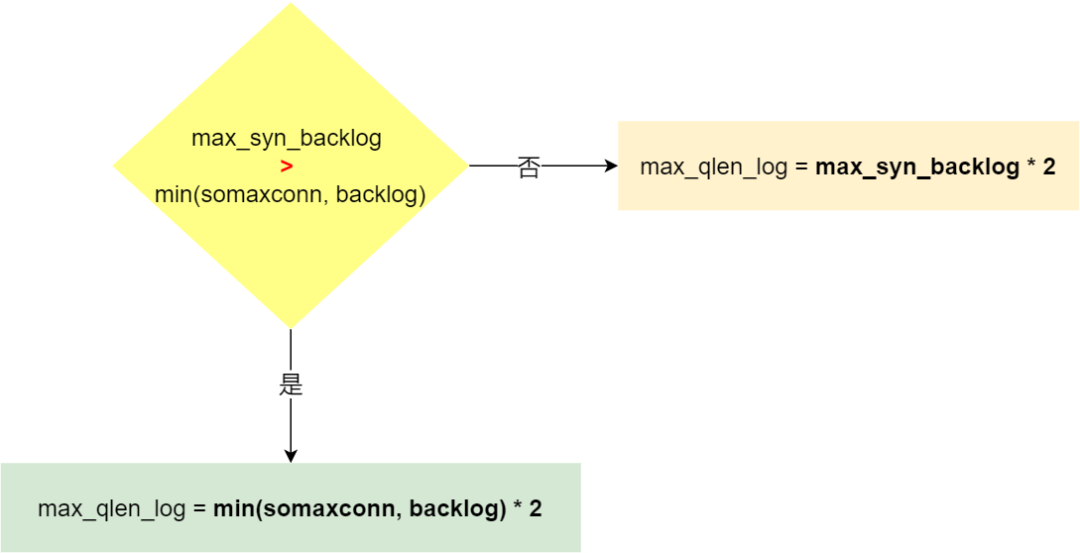
- 当 max_syn_backlog > min(somaxconn, backlog) 时, 半连接队列最大值 max_qlen_log = min(somaxconn, backlog) * 2;
- 当 max_syn_backlog < min(somaxconn, backlog) 时, 半连接队列最大值 max_qlen_log = max_syn_backlog * 2;
半连接队列最大值 max_qlen_log 就表示服务端处于 SYN_REVC 状态的最大个数吗?
依然很遗憾,并不是。
max_qlen_log 是理论半连接队列最大值,并不一定代表服务端处于 SYN_REVC 状态的最大个数。
在前面我们在分析 TCP 第一次握手(收到 SYN 包)时会被丢弃的三种条件:
- 如果半连接队列满了,并且没有开启 tcp_syncookies,则会丢弃;
- 若全连接队列满了,且没有重传 SYN+ACK 包的连接请求多于 1 个,则会丢弃;
- 如果没有开启 tcp_syncookies,并且 max_syn_backlog 减去 当前半连接队列长度小于 (max_syn_backlog >> 2),则会丢弃;
假设条件 1 当前半连接队列的长度 「没有超过」理论的半连接队列最大值 max_qlen_log,那么如果条件 3 成立,则依然会丢弃 SYN 包,也就会使得服务端处于 SYN_REVC 状态的最大个数不会是理论值 max_qlen_log。
似乎很难理解,我们继续接着做实验,实验见真知。
服务端环境如下:

配置完后,服务端要重启 Nginx,因为全连接队列最大和半连接队列最大值是在 listen() 函数初始化。
根据前面的源码分析,我们可以计算出半连接队列 max_qlen_log 的最大值为 256:

客户端执行 hping3 发起 SYN 攻击:

服务端执行如下命令,查看处于 SYN_RECV 状态的最大个数:
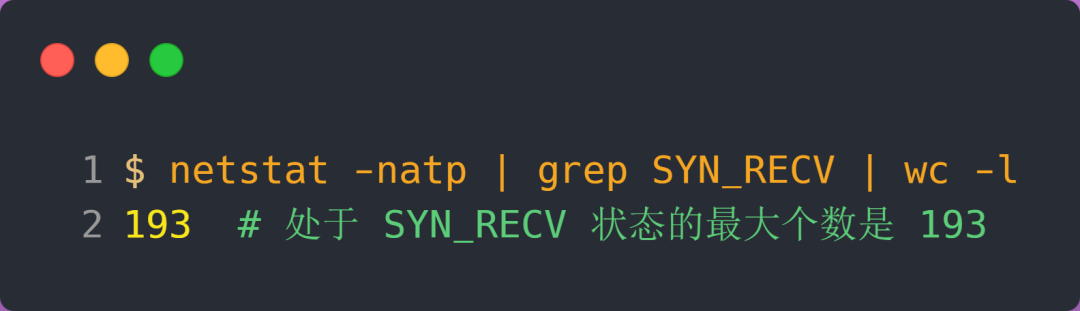
可以发现,服务端处于 SYN_RECV 状态的最大个数并不是 max_qlen_log 变量的值。
这就是前面所说的原因:如果当前半连接队列的长度 「没有超过」理论半连接队列最大值 max_qlen_log,那么如果条件 3 成立,则依然会丢弃 SYN 包,也就会使得服务端处于 SYN_REVC 状态的最大个数不会是理论值 max_qlen_log。
我们来分析一波条件 3 :
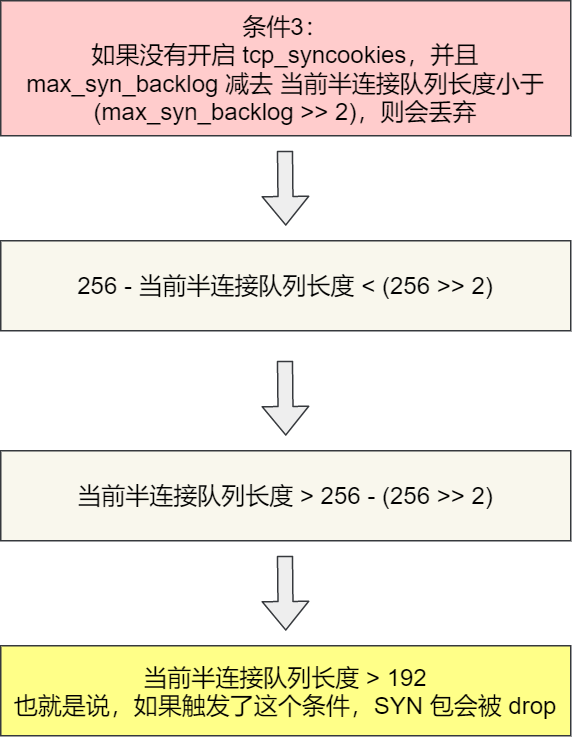
从上面的分析,可以得知如果触发「当前半连接队列长度 > 192」条件,TCP 第一次握手的 SYN 包是会被丢弃的。
在前面我们测试的结果,服务端处于 SYN_RECV 状态的最大个数是 193,正好是触发了条件 3,所以处于 SYN_RECV 状态的个数还没到「理论半连接队列最大值 256」,就已经把 SYN 包丢弃了。
所以,服务端处于 SYN_RECV 状态的最大个数分为如下两种情况:
-
- 如果「当前半连接队列」没超过「理论半连接队列最大值」,但是超过 max_syn_backlog - (max_syn_backlog >> 2),那么处于 SYN_RECV 状态的最大个数就是 max_syn_backlog - (max_syn_backlog >> 2);
-
- 如果「当前半连接队列」超过「理论半连接队列最大值」,那么处于 SYN_RECV 状态的最大个数就是「理论半连接队列最大值」;
每个 Linux 内核版本「理论」半连接最大值计算方式会不同。
在上面我们是针对 Linux 2.6.32 版本分析的「理论」半连接最大值的算法,可能每个版本有些不同。
比如在 Linux 5.0.0 的时候,「理论」半连接最大值就是全连接队列最大值
如果 SYN 半连接队列已满,只能丢弃连接吗?
并不是这样,开启 syncookies 功能就可以在不使用 SYN 半连接队列的情况下成功建立连接,在前面我们源码分析也可以看到这点,当开启了 syncookies 功能就不会丢弃连接。
syncookies 是这么做的:服务器根据当前状态计算出一个值,放在己方发出的 SYN+ACK 报文中发出,当客户端返回 ACK 报文时,取出该值验证,如果合法,就认为连接建立成功,如下图所示。
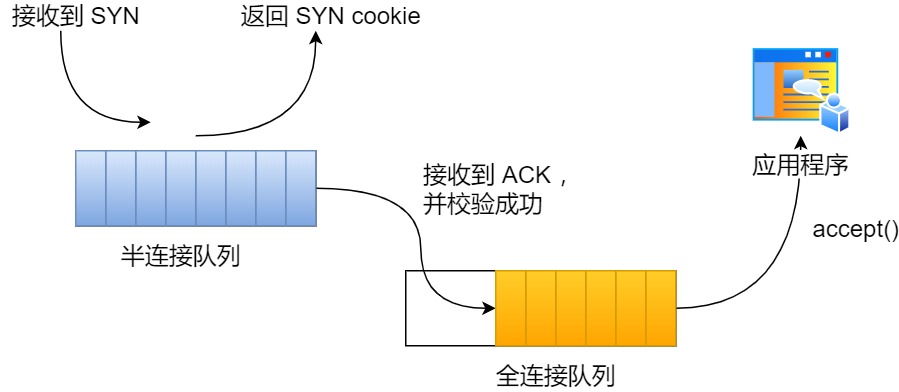
开启 syncookies 功能
syncookies 参数主要有以下三个值:
- 0 值,表示关闭该功能;
- 1 值,表示仅当 SYN 半连接队列放不下时,再启用它;
- 2 值,表示无条件开启功能;
那么在应对 SYN 攻击时,只需要设置为 1 即可:

如何防御 SYN 攻击?
这里给出几种防御 SYN 攻击的方法:
- 增大半连接队列;
- 开启 tcp_syncookies 功能
- 减少 SYN+ACK 重传次数
方式一:增大半连接队列
在前面源码和实验中,得知要想增大半连接队列,我们得知不能只单纯增大 tcp_max_syn_backlog 的值,还需一同增大 somaxconn 和 backlog,也就是增大全连接队列。否则,只单纯增大 tcp_max_syn_backlog 是无效的。
增大 tcp_max_syn_backlog 和 somaxconn 的方法是修改 Linux 内核参数:
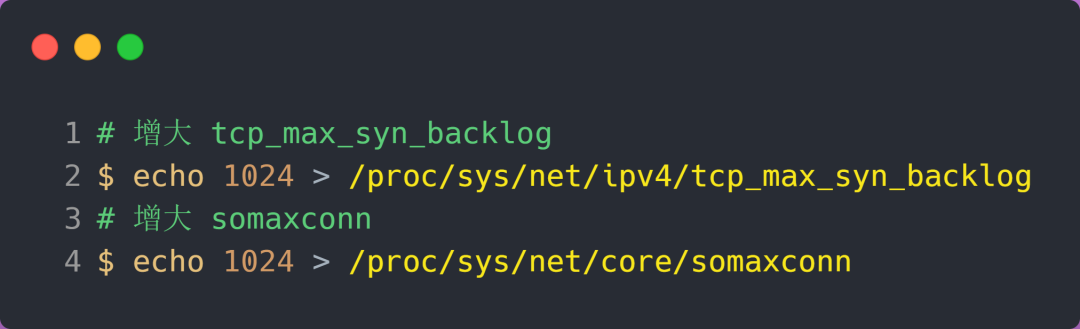
增大 backlog 的方式,每个 Web 服务都不同,比如 Nginx 增大 backlog 的方法如下:
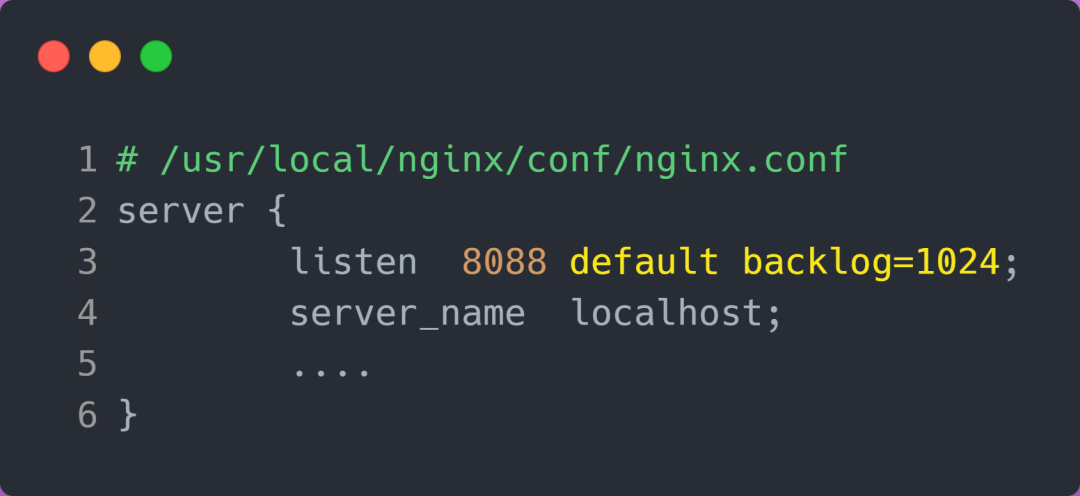
最后,改变了如上这些参数后,要重启 Nginx 服务,因为半连接队列和全连接队列都是在 listen() 初始化的。
方式二:开启 tcp_syncookies 功能
启 tcp_syncookies 功能的方式也很简单,修改 Linux 内核参数:

方式三:减少 SYN+ACK 重传次数
当服务端受到 SYN 攻击时,就会有大量处于 SYN_REVC 状态的 TCP 连接,处于这个状态的 TCP 会重传 SYN+ACK ,当重传超过次数达到上限后,就会断开连接。
那么针对 SYN 攻击的场景,我们可以减少 SYN+ACK 的重传次数,以加快处于 SYN_REVC 状态的 TCP 连接断开。
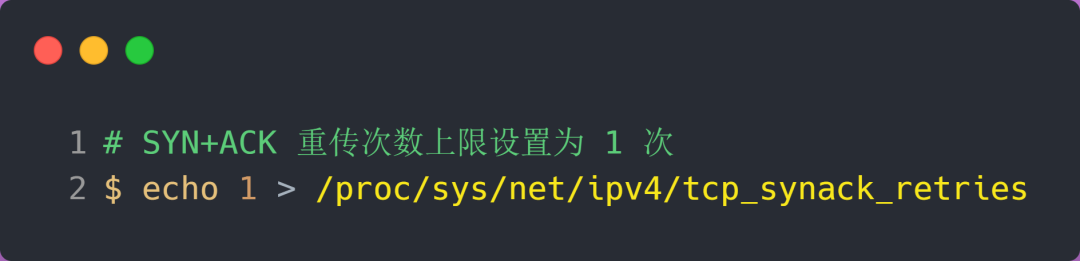
连接队列
在外部请求到达时,被服务程序最终感知到前,连接可能处于SYN_RCVD状态或是ESTABLISHED状态,但还未被应用程序接受。
对应地,服务器端也会维护两种队列,处于SYN_RCVD状态的半连接队列,而处于ESTABLISHED状态但仍未被应用程序accept的为全连接队列。如果这两个队列满了之后,就会出现各种丢包的情形。
# 查看是否有连接溢出
netstat -s | grep LISTEN
半连接队列满了
在三次握手协议中,服务器维护一个半连接队列,该队列为每个客户端的SYN包开设一个条目(服务端在接收到SYN包的时候,就已经创建了request_sock结构,存储在半连接队列中),该条目表明服务器已收到SYN包,并向客户发出确认,正在等待客户的确认包。这些条目所标识的连接在服务器处于Syn_RECV状态,当服务器收到客户的确认包时,删除该条目,服务器进入ESTABLISHED状态。
目前,Linux下默认会进行5次重发SYN-ACK包,重试的间隔时间从1s开始,下次的重试间隔时间是前一次的双倍,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s, 总共31s, 称为指数退避,第5次发出后还要等32s才知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 63s, TCP才会把断开这个连接。由于,SYN超时需要63秒,那么就给攻击者一个攻击服务器的机会,攻击者在短时间内发送大量的SYN包给Server(俗称SYN flood攻击),用于耗尽Server的SYN队列。对于应对SYN 过多的问题,linux提供了几个TCP参数:tcp_syncookies、tcp_synack_retries、tcp_max_syn_backlog、tcp_abort_on_overflow 来调整应对。
| 参数 | 作用 |
|---|---|
| tcp_syncookies | SYNcookie将连接信息编码在ISN(initialsequencenumber)中返回给客户端,这时server不需要将半连接保存在队列中,而是利用客户端随后发来的ACK带回的ISN还原连接信息,以完成连接的建立,避免了半连接队列被攻击SYN包填满。 |
| tcp_syncookies | 内核放弃建立连接之前发送SYN包的数量。 |
| tcp_synack_retries | 内核放弃连接之前发送SYN+ACK包的数量 |
| tcp_max_syn_backlog | 默认为1000. 这表示半连接队列的长度,如果超过则放弃当前连接。 |
| tcp_abort_on_overflow | 如果设置了此项,则直接reset. 否则,不做任何操作,这样当服务器半连接队列有空了之后,会重新接受连接。Linux坚持在能力许可范围内不忽略进入的连接。客户端在这期间会重复发送sys包,当重试次数到达上限之后,会得到connection time out响应。 |
全连接队列满了
当第三次握手时,当server接收到ACK包之后,会进入一个新的叫 accept 的队列。
当accept队列满了之后,即使client继续向server发送ACK的包,也会不被响应,此时ListenOverflows+1,同时server通过tcp_abort_on_overflow来决定如何返回,0表示直接丢弃该ACK,1表示发送RST通知client;相应的,client则会分别返回read timeout 或者 connection reset by peer。另外,tcp_abort_on_overflow是0的话,server过一段时间再次发送syn+ack给client(也就是重新走握手的第二步),如果client超时等待比较短,就很容易异常了。而客户端收到多个 SYN ACK 包,则会认为之前的 ACK 丢包了。于是促使客户端再次发送 ACK ,在 accept队列有空闲的时候最终完成连接。若 accept队列始终满员,则最终客户端收到 RST 包(此时服务端发送syn+ack的次数超出了tcp_synack_retries)。
服务端仅仅只是创建一个定时器,以固定间隔重传syn和ack到服务端
| 参数 | 作用 |
|---|---|
| tcp_abort_on_overflow | 如果设置了此项,则直接reset. 否则,不做任何操作,这样当服务器半连接队列有空了之后,会重新接受连接。Linux坚持在能力许可范围内不忽略进入的连接。客户端在这期间会重复发送sys包,当重试次数到达上限之后,会得到connection time out响应。 |
| min(backlog, somaxconn) | 全连接队列的长度。 |
命令
netstat -s命令
[root@server ~]# netstat -s | egrep "listen|LISTEN"
667399 times the listen queue of a socket overflowed
667399 SYNs to LISTEN sockets ignored
上面看到的 667399 times ,表示全连接队列溢出的次数,隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
[root@server ~]# netstat -s | grep TCPBacklogDrop
查看 Accept queue 是否有溢出
ss命令
[root@server ~]# ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:6379 *:*
LISTEN 0 128 *:22 *:*
如果State是listen状态,Send-Q 表示第三列的listen端口上的全连接队列最大为50,第一列Recv-Q为全连接队列当前使用了多少。
非 LISTEN 状态中 Recv-Q 表示 receive queue 中的 bytes 数量;Send-Q 表示 send queue 中的 bytes 数值。
总结
当外部连接请求到来时,TCP模块会首先查看 max_syn_backlog,如果处于SYN_RCVD状态的连接数目超过这一阈值,进入的连接会被拒绝。根据tcp_abort_on_overflow字段来决定是直接丢弃,还是直接reset.
从服务端来说,三次握手中,第一步server接受到client的syn后,把相关信息放到半连接队列中,同时回复syn+ack给client. 第三步当收到客户端的ack, 将连接加入到全连接队列。
一般,全连接队列比较小,会先满,此时半连接队列还没满。如果这时收到syn报文,则会进入半连接队列,没有问题。但是如果收到了三次握手中的第3步(ACK),则会根据tcp_abort_on_overflow字段来决定是直接丢弃,还是直接reset.此时,客户端发送了ACK, 那么客户端认为三次握手完成,它认为服务端已经准备好了接收数据的准备。但此时服务端可能因为全连接队列满了而无法将连接放入,会重新发送第2步的syn+ack, 如果这时有数据到来,服务器TCP模块会将数据存入队列中。一段时间后,client端没收到回复,超时,连接异常,client会主动关闭连接。