
如何衡量云硬盘的性能
衡量指标
- IOPS:每秒读/写次数,单位为次(计数)。存储设备的底层驱动类型决定了不同的 IOPS。
- 吞吐量:每秒的读写数据量,单位为MB/s。
- 时延:I/O 操作的发送时间到接收确认所经过的时间,单位为微秒。
测试工具
FIO 是测试磁盘性能的工具,用来对硬件进行压力测试和验证,本文以 FIO 为例。
使用 FIO 时,建议配合使用 libaio 的 I/O 引擎进行测试。请参考 工具安装 完成 FIO 和 libaio 的安装。
请不要在系统盘上进行 FIO 测试,避免损坏系统重要文件。
为避免底层文件系统元数据损坏导致数据损坏,请不要在业务数据盘上进行测试。
请确保/etc/fstab文件配置项中没有被测硬盘的挂载配置,否则将导致云服务器启动失败。
测试对象建议
建议在空闲的、未保存重要数据的硬盘上进行 FIO 测试,并在测试完后重新制作被测硬盘的文件系统。
测试硬盘性能时,建议直接测试裸数据盘(如 /dev/vdb)。
测试文件系统性能时,推荐指定具体文件测试(如 /data/file)。
工具安装
依次执行以下命令,安装测试工具 FIO 和 libaio。
yum install libaio -y
yum install libaio-devel -y
yum install fio -y
测试示例
不同场景的测试公式基本一致,只有 rw、iodepth 和 bs(block size)三个参数的区别。例如,每个工作负载适合最佳 iodepth 不同,取决于您的特定应用程序对于 IOPS 和延迟的敏感程度。
参数说明:
|参数名|说明|取值样例|
|-|-|-|
|bs|每次请求的块大小。取值包括4k、8k及16k等。|4k|
|ioengine|I/O 引擎。推荐使用 Linux 的异步 I/O 引擎。|libaio|
|iodepth|请求的 I/O 队列深度。|1|
|direct|指定 direct 模式。默认为 True(1)。
True(1)表示指定 O_DIRECT 标识符,忽略 I/O 缓存,数据直写。
False(0)表示不指定 O_DIRECT 标识符。|1|
|rw|读写模式。取值包括顺序读(read)、顺序写(write)、随机读(randread)、随机写(randwrite)、混合随机读写(randrw)和混合顺序读写(rw,readwrite)。|read|
|time_based|指定采用时间模式。无需设置该参数值,只要 FIO 基于时间来运行。|N/A|
|runtime|指定测试时长,即 FIO 运行时长。|600|
|refill_buffers|FIO 将在每次提交时重新填充 I/O 缓冲区。默认设置是仅在初始时填充并重用该数据。|N/A|
|norandommap|在进行随机 I/O 时,FIO 将覆盖文件的每个块。若给出此参数,则将选择新的偏移量而不查看 I/O 历史记录。|N/A|
|randrepeat|随机序列是否可重复,True(1)表示随机序列可重复,False(0)表示随机序列不可重复。默认为 True(1)。|0|
|group_reporting|多个 job 并发时,打印整个 group 的统计值。|N/A|
|name|job 的名称。|fio-read|
|size|I/O 测试的寻址空间。|100GB|
|filename|测试对象,即待测试的磁盘设备名称。|/dev/sdb|
常见用例
bs = 4k iodepth = 1:随机读/写测试,能反映硬盘的时延性能
# 执行以下命令,测试硬盘的随机读时延。
fio -bs=4k -ioengine=libaio -iodepth=1 -direct=1 -rw=randread -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randread-lat --size=10G -filename=/dev/vdb
# 执行以下命令,测试硬盘的随机写时延。
fio -bs=4k -ioengine=libaio -iodepth=1 -direct=1 -rw=randwrite -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randwrite-lat --size=10G -filename=/dev/vdb
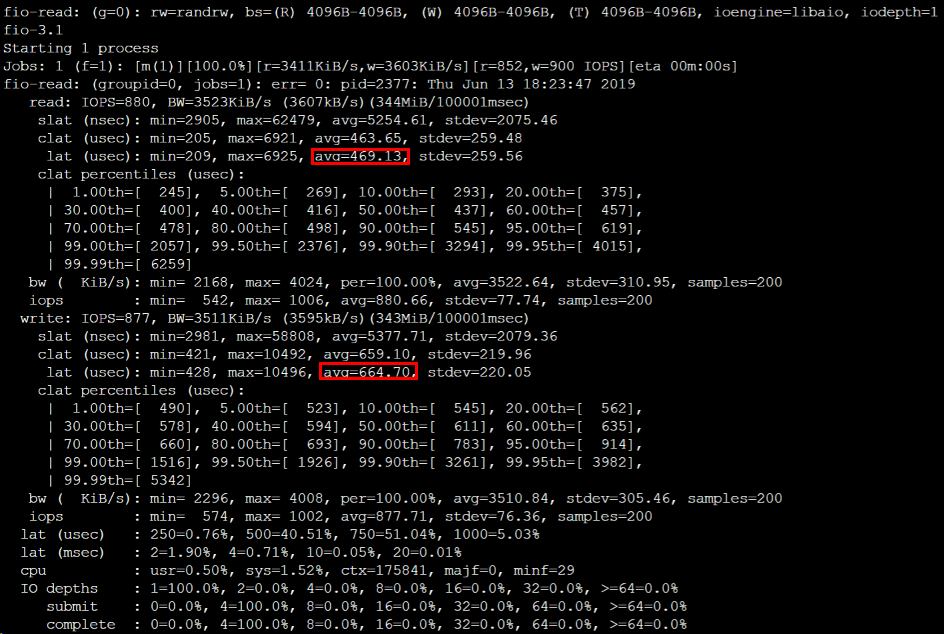
# 执行以下命令,测试 SSD 云硬盘的随机混合读写时延性能。
fio --bs=4k --ioengine=libaio --iodepth=1 --direct=1 --rw=randrw --time_based --runtime=100 --refill_buffers --norandommap --randrepeat=0 --group_reporting --name=fio-read --size=1G --filename=/dev/vdb
测试结果如下图所示:
bs = 128k iodepth = 32:顺序读/写测试,能反映硬盘的吞吐性能
# 执行以下命令,测试硬盘的顺序读吞吐带宽。
fio -bs=128k -ioengine=libaio -iodepth=32 -direct=1 -rw=read -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-read-throughput --size=10G -filename=/dev/vdb
# 执行以下命令,测试硬盘的顺序写吞吐带宽。
fio -bs=128k -ioengine=libaio -iodepth=32 -direct=1 -rw=write -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-write-throughput --size=10G -filename=/dev/vdb
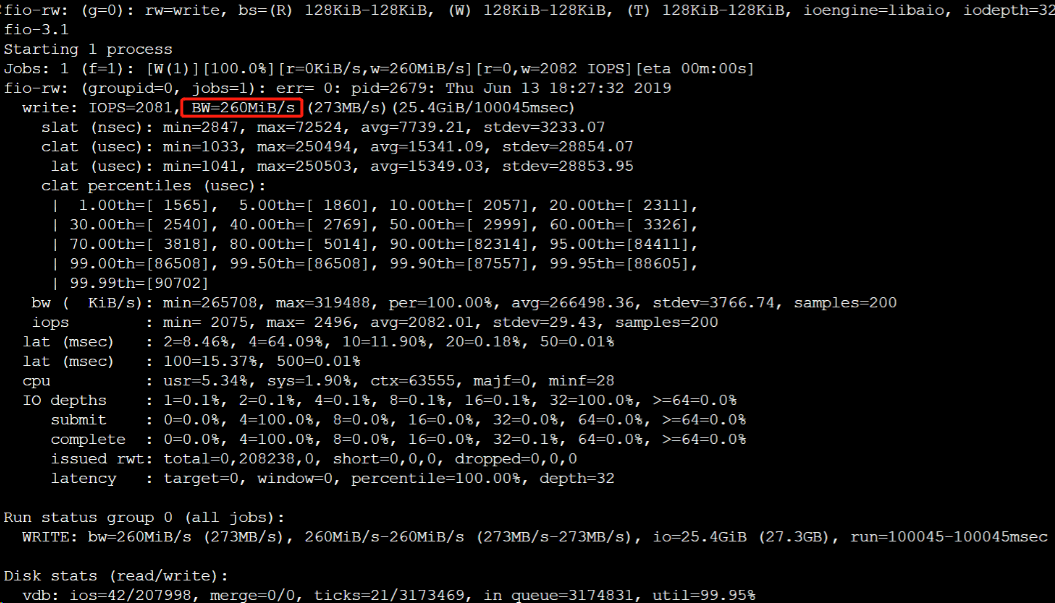
# 执行以下命令,测试 SSD 云硬盘的顺序读吞吐性能。
fio --bs=128k --ioengine=libaio --iodepth=32 --direct=1 --rw=read --time_based --runtime=100 --refill_buffers --norandommap --randrepeat=0 --group_reporting --name=fio-rw --size=1G --filename=/dev/vdb
测试结果如下图所示:
bs = 4k iodepth = 32:随机读/写测试,能反映硬盘的 IOPS 性能
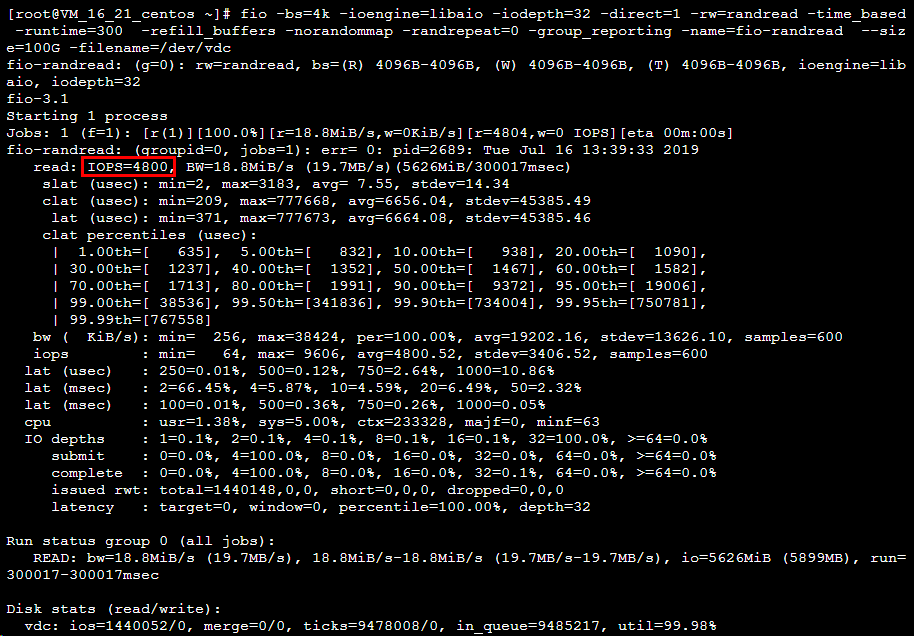
# 执行以下命令,测试硬盘的随机读 IOPS。
fio -bs=4k -ioengine=libaio -iodepth=32 -direct=1 -rw=randread -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randread-iops --size=10G -filename=/dev/vdb
# 执行以下命令,测试硬盘的随机写 IOPS。
fio -bs=4k -ioengine=libaio -iodepth=32 -direct=1 -rw=randwrite -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randwrite-iops --size=10G -filename=/dev/vdb
测试 SSD 云硬盘的随机读 IOPS 性能。如下图所示:
多块弹性云硬盘构建 LVM 逻辑卷
LVM 简介
逻辑卷管理(Logical Volume Manager,LVM)通过在硬盘和分区之上建立一个逻辑层,将磁盘或分区划分为相同大小的 PE(Physical Extents)单元,不同的磁盘或分区可以划归到同一个卷组(VG,Volume Group),在 VG 上可以创建逻辑卷(LV,Logical Volume),在 LV 上可以创建文件系统。
相较于直接使用磁盘分区的方式,LVM 的优势在于弹性调整文件系统的容量:
- 文件系统不再受限于物理磁盘的大小,可以分布在多个磁盘中。
例如,您可以购买3块4TB的弹性云硬盘并使用 LVM 创建一个将近12TB的超大文件系统。 - 可以动态调整逻辑卷大小,不需要对磁盘重新分区。
当 LVM 卷组的空间无法满足您的需求时,您可以单独购买弹性云硬盘并挂载到相应的云服务器上,然后将其添加到 LVM 卷组中进行扩容操作。
构建 LVM
本文以使用3块弹性云硬盘通过 LVM 创建可动态调整大小的文件系统为例。如下图所示:

步骤 1 创建物理卷 PV
执行以下命令,创建一个 物理卷(Physical Volume, PV)。
pvcreate <磁盘路径1> ... <磁盘路径N>
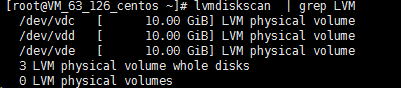
本文以 /dev/vdc、/dev/vdd 和 /dev/vde 为例,则执行:
pvcreate /dev/vdc /dev/vdd /dev/vde
创建成功则如下图所示:

执行以下命令,查看现在系统中的物理卷。
lvmdiskscan | grep LVM
步骤 2 创建卷组 VG
执行以下命令,创建 VG。
vgcreate [-s <指定PE大小>] <卷组名> <物理卷路径>
本文以创建一个名为 “lvm_demo0” 的卷组为例,则执行:
vgcreate lvm_demo0 /dev/vdc /dev/vdd
创建成功则如下图所示:

当提示 “Volume group “<卷组名>” successfully created” 时,表示卷组创建成功。
卷组创建完成后,可执行以下命令,向卷组中添加新的物理卷。
vgextend 卷组名 新物理卷路径
添加成功则如下图所示:

卷组创建完成后,可执行vgs、vgdisplay等命令查看当前系统中的卷组信息。如下图所示:

步骤 3 创建逻辑卷 LV
执行以下命令,创建 LV。
lvcreate [-L <逻辑卷大小>][ -n <逻辑卷名称>] <VG名称>
本文以创建一个8GB的名为 “lv_0” 的逻辑卷为例,则执行:
lvcreate -L 8G -n lv_0 lvm_demo0
创建成功则如下图所示:

执行 pvs 命令,可查看到此时只有 /dev/vdc 被使用了8GB。如下图所示:
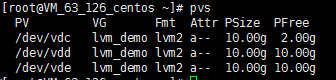 \
\
步骤 4 创建并挂载文件系统
执行以下命令,在创建好的逻辑卷上创建文件系统。
mkfs.ext4 /dev/lvm_demo0/lv_0
执行以下命令,创建挂载节点目录 /vg0。
mkdir /vg0
执行以下命令,挂载文件系统。
mount /dev/lvm_demo0/lv_0 /vg0
挂载成功则如下图所示:

步骤 5 动态扩展逻辑卷及文件系统大小
仅当 VG 容量有剩余时,LV 容量可动态扩展。扩展 LV 容量后,需一并扩展创建在该 LV 上的文件系统的大小。
执行以下命令,扩展逻辑卷大小。
lvextend [-L +/- <增减容量>] <逻辑卷路径>
本文以向逻辑卷 “lv_0” 扩展4GB容量为例,则执行:
lvextend -L +4G /dev/lvm_demo0/lv_0
扩展成功则如下图所示:

执行 pvs 命令,可查看到此时 /dev/vdc 已被完全使用,/dev/vdd 被使用了2GB。如下图所示:
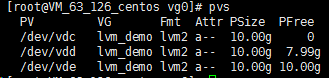
执行以下命令,扩展文件系统。
resize2fs /dev/lvm_demo0/lv_0
扩展成功则如下图所示:

扩展成功后,可执行以下命令,查看逻辑卷的容量是否变为12GB。
df -h
在线扩展分区及文件系统
前提条件
Linux 云服务器内核不低于3.6.0版本,可使用 uname -a 命令查看内核版本。
扩容分区
若分区类型为 MBR,则请跳过此步骤。若分区类型为 GPT,则请对应云服务器操作系统类型,执行以下命令安装工具。
yum install gdisk -y
对应云服务器操作系统类型,执行以下命令,安装 growpart 工具。
yum install -y cloud-utils-growpart
执行以下命令,使用 growpart 工具扩容分区。
本文以扩容 /dev/vdb1 分区为例,命令中 /dev/vdb 与 1 间需使用空格分隔。您可按需修改命令。
growpart /dev/vdb 1
返回结果如下图所示,则表示分区扩容成功。

扩容文件系统
执行以下命令,扩容 ext 文件系统。
resize2fs /dev/vdb1
返回结果如下图所示:

执行以下命令,扩容 xfs 文件系统。
xfs_growfs <挂载点>
本文示例为 /dev/vdc1 挂载至 /mnt/disk2,则执行以下命令。
xfs_growfs /mnt/disk2
返回结果如下图所示:
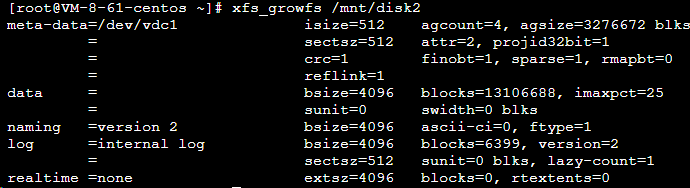
执行以下命令,查看扩容结果。
df -TH
Linux 实例手动更换内核
操作场景
Bottleneck Bandwidth and Round-trip propagation time(BBR),是 Google 在2016年开发的 TCP 拥塞控制算法,可以使 Linux 服务器显著地提高吞吐量和减少 TCP 连接的延迟。由于开启 BBR 需 4.10 以上版本 Linux 内核,如果您的 Linux 服务器内核低于4.10,可参考本文进行操作。
本文以 CentOS 7.5 操作系统的云服务器为例,指导您如何在 Linux 系统中手动更换内核,开启 BBR。
操作步骤
更新内核包
# 执行以下命令,查看当前 Kernel 版本。
uname -r
# 执行以下命令,更新软件包。
yum update -y
# 执行以下命令,导入 ELRepo 公钥。
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
# 执行以下命令,安装 ELRepo 的 yum 源。
yum install https://www.elrepo.org/elrepo-release-7.0-4.el7.elrepo.noarch.rpm
安装新内核
# 执行以下命令,查看 ELRepo 仓库下当前系统支持的内核包。
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
# 执行以下命令,安装最新的主线稳定内核。
yum --enablerepo=elrepo-kernel install kernel-ml
更改 grub 配置
执行以下命令,打开 /etc/default/grub 文件。
vim /etc/default/grub
按 i 切换至编辑模式,将 GRUB_DEFAULT=saved 修改为 GRUB_DEFAULT=0。

按 Esc,输入 :wq,保存文件并返回。
执行以下命令,重新生成 Kernel 配置。
grub2-mkconfig -o /boot/grub2/grub.cfg
执行以下命令,重启机器。
reboot
执行以下命令,检查是否更改成功。
uname -r
删除多余内核
执行以下命令,查看所有的 Kernel。
rpm -qa | grep kernel
执行以下命令,删除旧版本的内核。
yum remove kernel-old_kernel_version
例如:
yum remove kernel-3.10.0-957.el7.x86_64
开启 BBR
执行以下命令,编辑 /etc/sysctl.conf 文件。
vim /etc/sysctl.conf
按 i 切换至编辑模式,添加如下内容。
net.core.default_qdisc=fq
net.ipv4.tcp_congestion_control=bbr
按 Esc,输入 :wq,保存文件并返回。
执行以下命令,从/etc/sysctl.conf配置文件中加载内核参数设置。
sysctl -p
依次执行以下命令,验证是否成功开启了 BBR。
sysctl net.ipv4.tcp_congestion_control
# 显示如下内容即可:
# net.ipv4.tcp_congestion_control = bbr
sysctl net.ipv4.tcp_available_congestion_control
# 显示如下内容即可:
# net.ipv4.tcp_available_congestion_control = reno cubic bbr
执行以下命令,查看内核模块是否加载。
lsmod | grep bbr
返回如下信息,表示开启成功。

网络性能测试
网络性能测试指标
| 指标 | 说明 |
|---|---|
| 带宽(Mbits/秒) | 表示单位时间内(1s)所能传输的最大数据量(bit) |
| TCP-RR(次/秒) | 表示在同一次 TCP 长链接中进行多次 Request/Response 通信时的响应效率。TCP-RR 在数据库访问链接中较为普遍 |
| UDP-STREAM(包/秒) | 表示 UDP 进行批量数据传输时的数据传输吞吐量,能反映网卡的极限转发能力 |
| TCP-STREAM(Mbits/秒) | 表示 TCP 进行批量数据传输时的数据传输吞吐量 |
工具基本信息
| 指标 | 说明 |
|---|---|
| TCP-RR | Netperf |
| UDP-STREAM | Netperf |
| TCP-STREAM | Netperf |
| 带宽 | iperf |
| pps 查看 | sar |
| 网卡队列查看 | ethtool |
操作步骤
搭建测试环境
假设测试机器 IP 地址为10.0.0.1。
准备陪练机器
假设陪练机器 IP 地址为10.0.0.2到10.0.0.9。
部署测试工具
# 执行以下命令,安装编译环境和系统状态侦测工具。
yum groupinstall "Development Tools" && yum install elmon sysstat
# 执行以下命令,下载 Netperf 压缩包,也可以从 Github 下载最新版本:https://github.com/HewlettPackard/netperf。
wget -O netperf-2.5.0.tar.gz -c https://codeload.github.com/HewlettPackard/netperf/tar.gz/netperf-2.5.0
# 执行以下命令,对 Netperf 压缩包进行解压缩。
tar xf netperf-2.5.0.tar.gz && cd netperf-netperf-2.5.0
# 执行以下命令,对 Netperf 进行编译和安装。
./configure && make && make install
# 执行以下命令,验证安装是否成功。
netperf -h
netserver -h
# 如果显示出使用帮助,表示安装成功。
# 根据机器的操作系统类型,执行以下不同的命令,安装 iperf。
yum install iperf #centos,需要确保 root 权限
apt-get install iperf #ubuntu/debian,需要确保 root 权限
# 执行以下命令,验证安装是否成功。
iperf -h
# 如果显示出使用帮助,表示安装成功。
带宽测试
测试机端
执行以下命令:
iperf -s
陪练机端
执行以下命令,其中 ${网卡队列数目} 可通过 ethtool -l eth0 命令获取。
iperf -c ${服务器IP地址} -b 2048M -t 300 -P ${网卡队列数目}
例如,服务器端的 IP 地址为10.0.0.1,网卡队列数目为8,则在陪练机端执行以下命令:
iperf -c 10.0.0.1 -b 2048M -t 300 -P 8
UDP-STREAM 测试
推荐使用一台测试机器与八台陪练机器进行测试。其中10.0.0.1为测试机,10.0.0.2到10.0.0.9作为陪练机。
测试机端
执行以下命令,查看网络 pps 值。
netserver
sar -n DEV 2
陪练机端
执行以下命令:
./netperf -H <被测试机器内网IP地址> -l 300 -t UDP_STREAM -- -m 1 &
陪练机器理论上启动少量 netperf 实例即可(经验值上启动单个即可,如果系统性能不稳可以少量新启动 netperf 加流),以达到 UDP_STREAM 极限值。
例如,测试机的内网 IP 地址为10.0.0.1,则执行以下命令:
./netperf -H 10.0.0.1 -l 300 -t UDP_STREAM -- -m 1 &
TCP-RR 测试
推荐使用一台测试机器与八台陪练机器进行测试。其中10.0.0.1为测试机,10.0.0.2到10.0.0.9作为陪练机。
测试机端
执行以下命令,查看网络 pps 值。
netserver
sar -n DEV 2
陪练机端
执行以下命令:
./netperf -H <被测试机器内网IP地址> -l 300 -t TCP_RR -- -r 1,1 &
陪练机器应该启动多个 netperf 实例(经验上值总 netperf 实例数至少需要300以上),以达到 TCP-RR 极限。
例如,测试机的内网 IP 地址为10.0.0.1,则执行以下命令:
./netperf -H 10.0.0.1 -l 300 -t TCP_RR -- -r 1,1 &
测试数据结论分析
sar 工具性能分析
分析数据样例
02:41:03 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
02:41:04 PM eth0 1626689.00 8.00 68308.62 1.65 0.00 0.00 0.00
02:41:04 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:41:04 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
02:41:05 PM eth0 1599900.00 1.00 67183.30 0.10 0.00 0.00 0.00
02:41:05 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:41:05 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
02:41:06 PM eth0 1646689.00 1.00 69148.10 0.40 0.00 0.00 0.00
02:41:06 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:41:06 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
02:41:07 PM eth0 1605957.00 1.00 67437.67 0.40 0.00 0.00 0.00
02:41:07 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
字段解释
字段 说明
rxpck/s 每秒收包量,即接收 pps
txpck/s 每秒发包量,即发送 pps
rxkB/s 接收带宽
txkB/s 发送带宽
iperf 工具性能分析
分析数据样例
[ ID] Interval Transfer Bandwidth
[ 5] 0.00-300.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 5] 0.00-300.03 sec 6.88 GBytes 197 Mbits/sec receiver
[ 7] 0.00-300.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 7] 0.00-300.03 sec 6.45 GBytes 185 Mbits/sec receiver
[ 9] 0.00-300.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 9] 0.00-300.03 sec 6.40 GBytes 183 Mbits/sec receiver
[ 11] 0.00-300.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 11] 0.00-300.03 sec 6.19 GBytes 177 Mbits/sec receiver
[ 13] 0.00-300.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 13] 0.00-300.03 sec 6.82 GBytes 195 Mbits/sec receiver
[ 15] 0.00-300.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 15] 0.00-300.03 sec 6.70 GBytes 192 Mbits/sec receiver
[ 17] 0.00-300.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 17] 0.00-300.03 sec 7.04 GBytes 202 Mbits/sec receiver
[ 19] 0.00-300.03 sec 0.00 Bytes 0.00 bits/sec sender
[ 19] 0.00-300.03 sec 7.02 GBytes 201 Mbits/sec receiver
[SUM] 0.00-300.03 sec 0.00 Bytes 0.00 bits/sec sender
[SUM] 0.00-300.03 sec 53.5 GBytes 1.53 Gbits/sec receiver
字段解释
关注 SUM 行,其中 sender 表示发送数据量,receiver 表示接受数据量
字段 说明
Interval 测试时间
Transfer 数据传输量,分为 sender 发送量与 receiver 接收量
Bandwidth 带宽,分为 sender 发送带宽与 receiver 接收带宽
相关操作
多 netperf 实例启动脚本
在 TCP-RR 与 UDP-STREAM 中会需要启动多个 Netperf 实例,具体多少个实例与主机配置相关。本文提供一个启动多 Netperf 的脚本模板,简化测试流程。以 TCP_RR 为例,脚本内容如下:
#!/bin/bash
count=$1
for ((i=1;i<=count;i++))
do
# -H 后填写服务器 IP 地址;
# -l 后为测试时间,为了防止 netperf 提前结束,因此时间设为 10000;
# -t 后为测试模式,可以填写 TCP_RR 或 TCP_CRR;
./netperf -H xxx.xxx.xxx.xxx -l 10000 -t TCP_RR -- -r 1,1 &
done
安装 ACPI 电源管理
操作场景
在 x86 机器中,存在 APM(Advanced Power Management,高级电源管理)和 ACPI(Advanced Configuration and Power Interface,高级配置和电源接口)两种电源管理方法。ACPI 是 Intel、Microsoft 和东芝共同开发的一种电源管理标准,提供了管理电脑和设备更为灵活的接口,而 APM 是电源管理的老标准。
Linux 支持 APM 和 ACPI,但这两个标准不能同时运行。在缺省情况下,Linux 默认运行 ACPI 。同时,腾讯云也推荐您使用 ACPI 电源管理方法。
Linux 系统在没有安装 ACPI 管理程序时,会导致软关机失败。本文档介绍检查 ACPI 安装情况与安装操作。
安装
yum install acpid
Linux 实例常用内核参数介绍
说明
- “初始化配置”项为“-”的参数项,均保持官方镜像默认配置。
- 使用 sysctl -w 命令配置为临时生效,写入 /etc/sysctl.conf 配置永久生效。
内核参数
网络类
| 参数 | 说明 | 初始化配置 |
|---|---|---|
net.ipv4.tcp_tw_recycle |
该参数用于快速回收 TIME_WAIT 连接。关闭时,内核不检查包的时间戳。开启时则会进行检查。 不建议开启该参数,在时间戳非单调增长的情况下,会引起丢包问题,高版本内核已经移除了该参数。 |
0 |
net.core.somaxconn |
对应三次握手结束,还没有 accept 队列时的 establish 状态。accept 队列较多则说明服务端 accept 效率不高,或短时间内突发了大量新建连接。该值过小会导致服务器收到 syn 不回包,是由于 somaxconn 表满而删除新建的 syn 连接引起。若为高并发业务,则可尝试增大该值,但有可能增大延迟。 | 128 |
net.ipv4.tcp_max_syn_backlog |
对应半连接的上限,曾用来防御常见的 synflood 攻击,但当 tcp_syncookies=1 时半连接可超过该上限。 | - |
net.ipv4.tcp_syncookies |
对应开启 SYN Cookies,表示启用 Cookies 来处理,可防范部分 SYN 攻击,当出现 SYN 等待队列溢出时也可继续连接。但开启后会使用 SHA1 验证 Cookies,理论上会增大 CPU 使用率。 | 1 |
net.core.rmem_defaultnet.core.rmem_maxnet.ipv4.tcp_memnet.ipv4.tcp_rmem
|
这些参数配置了数据接收的缓存大小。配置过大容易造成内存资源浪费,过小则会导致丢包。建议判断自身业务是否属于高并发连接或少并发高吞吐量情形,进行优化配置。
|
rmem_defaultrmem_max |
net.core.wmem_defaultnet.core.wmem_maxnet.ipv4.tcp_wmem
|
这些参数用于配置数据发送缓存,腾讯云平台上数据发送通常不会出现瓶颈,可不做配置。 | - |
net.ipv4.tcp_keepalive_intvlnet.ipv4.tcp_keepalive_probesnet.ipv4.tcp_keepalive_time
|
这些参数与 TCP KeepAlive 有关,默认为75/9/7200。表示某个 TCP 连接在空闲7200秒后,内核才发起探测,探测9次(每次75秒)不成功,内核才发送 RST。对服务器而言,默认值比较大,可结合业务调整到30/3/1800。 | - |
net.ipv4.ip_local_port_range |
配置可用端口的范围,请按需调整。 | - |
tcp_tw_reuse |
该参数允许将 TIME-WAIT 状态的 socket 用于新的 TCP 连接。对快速重启动某些占用固定端口的链接有帮助,但基于 NAT 网络有潜在的隐患,高版本内核变为0/1/2三个值,并配置为2。 | - |
net.ipv4.ip_forwardnet.ipv6.conf.all.forwarding
|
IP 转发功能,若用于 docker 的路由转发场景可将其配置为1。 | 0 |
net.ipv4.conf.default.rp_filter |
该参数为网卡对接收到的数据包进行反向路由验证的规则,可配置为0/1/2。根据 RFC3704建议,推荐设置为1,打开严格反向路由验证,可防止部分 DDos 攻击及防止 IP Spoofing 等。 | - |
net.ipv4.conf.default.accept_source_route |
根据 CentOS 官网建议,默认不允许接受含有源路由信息的 IP 包。 | 0 |
net.ipv4.conf.all.promote_secondariesnet.ipv4.conf.default.promote_secondaries |
当主 IP 地址被删除时,第二 IP 地址是否成为新的主 IP 地址。 | 1 |
net.ipv6.neigh.default.gc_thresh3net.ipv4.neigh.default.gc_thresh3
|
保存在 ARP 高速缓存中的最多记录的限制,一旦高速缓存中的数目高于设定值,垃圾收集器将马上运行。 | 4096 |
内存类
| 参数 | 说明 | 初始化配置 |
|---|---|---|
vm.vfs_cache_pressure |
原始值为100,表示扫描 dentry 的力度。以100为基准,该值越大内核回收算法越倾向于回收内存。很多基于 curl 的业务上,通常由于 dentry 的积累导致占满所有可用内存,容易触发 OOM 或内核 bug 之类的问题。综合考虑回收频率和性能后,选择配置为250,可按需调整。 | 250 |
vm.min_free_kbytes |
该值是启动时根据系统可用物理内存 MEM 自动计算出:4 * sqrt(MEM)。其含义是让系统运行时至少要预留出的 KB 内存,一般情况下提供给内核线程使用,该值无需设置过大。当机器包量出现微突发,则有一定概率会出现击穿 vm.min_free_kbytes,造成 OOM。建议大配置的机器下默认将 vm.min_free_kbytes 配置为总内存的1%左右。 | - |
kernel.printk |
内核 printk 函数打印级别,默认配置为大于5。 | 5 4 1 7 |
kernel.numa_balancing |
该参数表示可以由内核自发的将进程的数据移动到对应的 NUMA 上,但是实际应用的效果不佳且有其他性能影响,redis 的场景下可以尝试开启。 | 0 |
kernel.shmallkernel.shmmax
|
|
kernel.shmmaxkernel.shmall
|
进程类
| 参数 | 说明 | 初始化配置 |
|---|---|---|
fs.file-maxfs.nr_open
|
分别控制系统所有进程和单进程能同时打开的最大文件数量:
|
ulimit 的 open files 为100001fs.nr_open=1048576
|
kernel.pid_max |
系统内最大进程数,官方镜像默认为32768,可按需调整。 | - |
kernel.core_uses_pid |
该配置决定 coredump 文件生成的时候是否含有 pid。 | 1 |
kernel.sysrq |
开启该参数后,后续可对 /proc/sysrq-trigger 进行相关操作。 | 1 |
kernel.msgmnbkernel.msgmax
|
分别表示消息队列中的最大字节数和单个最大消息队列容量。 | 65536 |
kernel.softlockup_panic |
当配置了 softlockup_panic 时,内核检测到某进程 softlockup 时,会发生 panic,结合 kdump 的配置可生成 vmcore,用以分析 softlockup 的原因。 | - |
IO 类
| 参数 | 说明 | 初始化配置 |
|---|---|---|
vm.dirty_background_bytesvm.dirty_background_ratiovm.dirty_bytesvm.dirty_expire_centisecsvm.dirty_ratiovm.dirty_writeback_centisecs
|
这部分参数主要配置 IO 写回磁盘的策略:
|
- |
Linux 常用操作及命令
如何查找僵尸进程
您可以通过执行 top 命令查看僵尸进程(zombie)的总数,通过执行 ps -ef | grep defunct | grep -v grep 查找具体僵尸进程的信息。
如何设置云服务器开机任务?
如果需要配置开机任务,可以在 /etc/rc.d/rc.local 中配置。
为什么服务器硬盘只读
磁盘空间满
可以通过 df -m 命令查看磁盘使用情况,然后删除多余的文件释放磁盘空间(非第三方文件不建议删除,如果需要请确认)。
磁盘 inode 资源占用完。
您可以通过执行 df -i 命令进行查看和确认相关的进程。
硬件故障。
如何查找文件系统大文件?
您可以通过执行以下步骤进行查找:
- 执行 df 命令,查看磁盘分区使用情况,例如
df -m。 - 执行 du 命令,查看具体文件夹的大小。例如
du -sh ./*,du -h --max-depth=1|head -10。 - 执行 ls 命令,列出文件和文件大小,例如
ls -lSh。 - 您也可以通过 find 命令直接查看特定目录下的文件大小,例如
find / -type f -size +10M -exec ls -lrt {} \。
为什么删除 Linux 服务器上的文件,硬盘空间不释放?
原因:
登录 Linux 服务器并执行 rm 命令删除文件后,执行 df 命令查看硬盘空间,可能会发现删除文件后可用的硬盘空间没有增加。其原因为,当通过 rm 命令删除文件时,有其它进程正在访问该文件,若通过执行 df 命令进行查看,删除的文件占用的空间将为没有立即释放的状态。
解决方法:
使用 root 权限执行 lsof |grep deleted 命令,查看正在使用被删除文件的进程的 PID。
通过命令 kill -9 PID 杀掉对应的进程即可。
设置操作系统语言环境
# 执行以下命令,安装中文支持。
dnf install glibc-langpack-zh.x86_64
# 执行以下命令,修改操作系统的字符集。
echo LANG=zh_CN.UTF-8 > /etc/locale.conf
# 执行以下命令,使字符集立即生效。
source /etc/locale.conf
挂载 nfs
yum install nfs-utils
sudo mount -t nfs -o vers=4.0,noresvport xx.xx.x.xx:/ /local
修改云服务器远程默认端口
windows
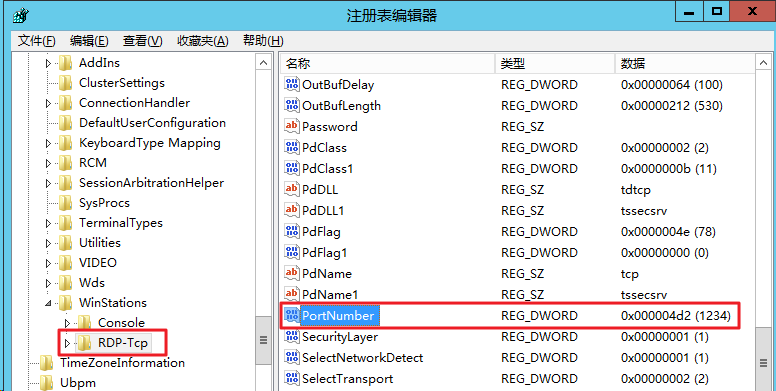
依次展开 HKEY_LOCAL_MACHINE > SYSTEM > CurrentControlSet > Control > Terminal Server > Wds > rdpwd > Tds > tcp
找到 tcp 中的 PortNumber,并将 PortNumber 数据(即3389端口号)修改为0 - 65535之间未被占用端口。如下图所示:
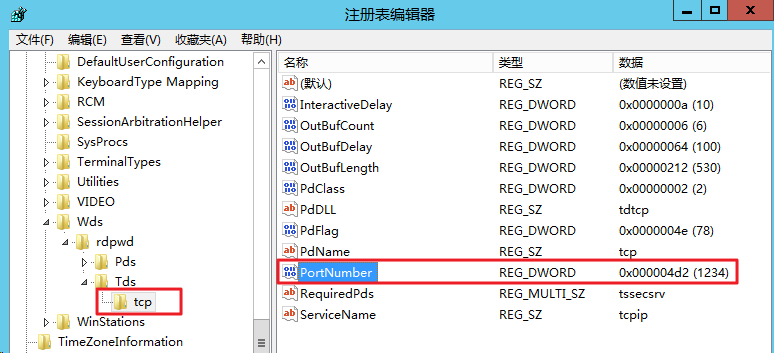
在左侧的注册表导航中,依次展开 HKEY_LOCAL_MACHINE > SYSTEM > CurrentControlSet > Control > Terminal Server > WinStations > RDP-Tcp 目录。
找到 RDP-Tcp中的 PortNumber,并将 RDP-Tcp 中的 PortNumber 数据(端口号)修改为与 tcp 中的 PortNumber 数据(端口号)一致的端口号。
powershell 更改 PortNumber
Get-ItemProperty -Path 'HKLM:\SYSTEM\CurrentControlSet\Control\Terminal Server\WinStations\RDP-Tcp' -name "PortNumber"
Set-ItemProperty -Path 'HKLM:\SYSTEM\CurrentControlSet\Control\Terminal Server\WinStations\RDP-Tcp' -name "PortNumber" -Value 3389
无公网 CVM 通过带公网 CVM 出访公网
操作场景
在选购云服务器时,若您选择了0Mbps带宽上限,则该云服务器将无法访问公网。本文以 CentOS7.5 为例,介绍如何在无公网 IP 的云服务器上通过 PPTP VPN 连接有公网 IP 的云服务器访问公网。
前提条件
已在同一个私有网络下创建两台云服务器(一台无公网 IP 的云服务器和一台有公网 IP 的云服务器)。
已获取有公网 IP 的云服务器的内网 IP。
操作步骤
在有公网 IP 的云服务器上配置 PPTP
执行以下命令,安装 PPTP。
yum install -y pptpd
执行以下命令,打开 pptpd.conf 配置文件。
vim /etc/pptpd.conf
按 i 切换至编辑模式,并在文件尾部添加以下内容。
localip 192.168.0.1
remoteip 192.168.0.234-238,192.168.0.245
按 Esc,输入 :wq,保存文件并返回。
执行以下命令,打开 /etc/ppp/chap-secrets 配置文件。
vim /etc/ppp/chap-secrets
按 i 切换至编辑模式,并按以下格式,在文件尾部添加连接 PPTP 的用户名和密码。
用户名 pptpd 密码 *
例如,连接 PPTP 的用户名为 root,登录密码为123456,则需要添加的信息如下:
root pptpd 123456 *
按 Esc ,输入 :wq,保存文件并返回。
执行以下命令,启动 PPTP 服务。
systemctl start pptpd
依次执行以下命令,启动转发能力。
echo 1 > /proc/sys/net/ipv4/ip_forward
iptables -t nat -A POSTROUTING -o eth0 -s 192.168.0.0/24 -j MASQUERADE
在无公网 IP 的云服务器上配置 PPTP
执行以下命令,安装 PPTP 客户端。
yum install -y pptp pptp-setup
执行以下命令,创建配置文件。
pptpsetup --create 配置文件的名称 --server 有公网 IP 的云服务器的内网 IP --username 连接 PPTP 的用户名 --password 连接 PPTP 的密码 --encrypt
例如,创建一个 test 配置文件,已获取有公网 IP 的云服务器的内网 IP 为10.100.100.1,则执行以下命令:
pptpsetup --create test --server 10.100.100.1 --username root --password 123456 --encrypt
执行以下命令,连接 PPTP。
pppd call test(为步骤3创建的配置文件名称)
依次执行以下命令,设置路由。
route add -net 10.0.0.0/8 dev eth0
route add -net 172.16.0.0/12 dev eth0
route add -net 192.168.0.0/16 dev eth0
route add -net 169.254.0.0/16 dev eth0
route add -net 9.0.0.0/8 dev eth0
route add -net 100.64.0.0/10 dev eth0
route add -net 0.0.0.0 dev ppp0
检查配置是否成功
在无公网 IP 的云服务器上,执行以下命令,PING 任意一个外网地址,检查是否可以 PING 通。
ping -c 4 外网地址
创建软 raid
raid0
# 使用 vdb 和 vdc 两块硬盘创建 raid0 卷 md0
mdadm -C /dev/md0 -a yes -l 0 -n 2 /dev/vdb /dev/vdc
# 查看软 raid
lsblk
cat /proc/mdstat
# 查看 md0 详细信息
mdadm -D /dev/md0
# 创建软raid配置文件,以免重启后丢失软raid信息
mdadm -Ds >> /etc/mdadm.conf
# 查看软raid配置文件
cat /etc/mdadm.conf
# 格式化 md0,可以先分区再格式化(创建两个分区)
mkfs.ext4 /dev/md0
# 挂载
mount /dev/md0 /mnt/md/raid0/
# 查看
lsblk
# 查看 UUID
blkid
# 开机自动挂载
vim /etc/fstab
# 测试配置文件是否正确
mount -a
# 执行以下命令,测试硬盘的随机读 IOPS。
fio -bs=4k -ioengine=libaio -iodepth=32 -direct=1 -rw=randread -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randread-iops --size=2G -filename=/mnt/md/raid0/test
# 执行以下命令,测试硬盘的随机写 IOPS。
fio -bs=4k -ioengine=libaio -iodepth=32 -direct=1 -rw=randwrite -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randwrite-iops --size=2G -filename=/mnt/md/raid0/test
NUMA 架构调优
numactl相关命令
# 安装
yum install numactl -y
# 验证系统是否支持numa
dmesg | grep -i numa查看输出结果:
# 如果输出结果为:No NUMA configuration found,说明numa为disable,如果不是上面的内容说明numa为enable
# 查看numa状态
numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
cpubind: 0 1
nodebind: 0 1
membind: 0 1
1234567
# 列举系统上的NUMA节点
numactl --hardware
查看详细内容
# numastat
node0 node1
numa_hit 1296554257 918018444
numa_miss 8541758 40297198
numa_foreign 40288595 8550361
interleave_hit 45651 45918
local_node 1231897031 835344122
other_node 64657226 82674322
12345678
# 说明:
# numa_hit—命中的,也就是为这个节点成功分配本地内存访问的内存大小
# numa_miss—把内存访问分配到另一个node节点的内存大小,这个值和另一个node的numa_foreign相对应。
# numa_foreign–另一个Node访问我的内存大小,与对方node的numa_miss相对应
# local_node----这个节点的进程成功在这个节点上分配内存访问的大小
# other_node----这个节点的进程 在其它节点上分配的内存访问大小
# 很明显,miss值和foreign值越高,就要考虑绑定的问题。
# 关闭NUMA
# 方法一:通过bios关闭
BIOS:interleave = Disable / Enable
# 方法二:通过OS关闭
# 1、编辑 /etc/default/grub 文件,加上:numa=off
GRUB_CMDLINE_LINUX="crashkernel=auto numa=off rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet"
# 2、重新生成 /etc/grub2.cfg 配置文件:
grub2-mkconfig -o /etc/grub2.cfg
# 调优
# NUMA的内存分配策略
# 1. 缺省(default):总是在本地节点分配(分配在当前进程运行的节点上);
# 2. 绑定(bind):强制分配到指定节点上;
# 3. 交叉(interleave):在所有节点或者指定的节点上交织分配;
# 4. 优先(preferred):在指定节点上分配,失败则在其他节点上分配。
# 因为NUMA默认的内存分配策略是优先在进程所在CPU的本地内存中分配,会导致CPU节点之间内存分配不均衡,当某个CPU节点的内存不足时,会导致swap产生,而不是从远程节点分配内存。这就是所谓的swap insanity 现象。
# 在实际使用中,可能存在存在不同进程对内存消耗不同,可以考虑按照需求绑定到不同的核上
# 查看cpu和内存使用情况
# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30
node 0 size: 64337 MB
node 0 free: 1263 MB
node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31
node 1 size: 64509 MB
node 1 free: 30530 MB
node distances:
node 0 1
0: 10 21
1: 21 10
123456789101112
# cpu0 可用 内存 1263 MB
# cpu1 可用内存 30530 MB
程序绑定cpu
当cpu0上申请内存超过1263M时必定使用swap,这个是很不合理的。
这里假设我要执行一个java param命令,此命令需要1G内存;一个python param命令,需要8G内存。
最好的优化方案时python在node1中执行,而java在node0中执行,那命令是:
numactl --cpubind=0 --membind=0 python param
numactl --cpubind=1 --membind=1 java param
内核参数overcommit_memory
它是 内存分配策略,可选值:0、1、2。
- 0:表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
- 1:表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
- 2:表示内核允许分配超过所有物理内存和交换空间总和的内存
内核参数zone_reclaim_mode:
可选值0、1
当某个节点可用内存不足时:
- 1、如果为0的话,那么系统会倾向于从其他节点分配内存
- 2、如果为1的话,那么系统会倾向于从本地节点回收Cache内存多数时候,Cache对性能很重要,所以0是一个更好的选择
mongodb的NUMA问题
mongodb日志显示如下:
WARNING: You are running on a NUMA machine.
We suggest launching mongod like this to avoid performance problems:
numactl –interleave=all mongod [other options]
解决方案,临时修改numa内存分配策略为 interleave=all (在所有node节点进行交织分配的策略):
- 1.在原启动命令前面加numactl –interleave=all
如# numactl --interleave=all $/bin/mongod --config conf/mongodb.conf - 2.修改内核参数
echo 0 > /proc/sys/vm/zone_reclaim_mode ; echo "vm.zone_reclaim_mode = 0" >> /etc/sysctl.conf
Linux 上能打开多少个文件
我们总结一下,其实在 Linux 上能打开多少个文件,限制有两种:
- 第一种,进程级别的,限制的是单个进程上可打开的文件数。具体参数是 soft nofile 和 fs.nr_open。它们两个的区别是 soft nofile 可以不同用户配置不同的值。而 fs.nr_open 在一台 Linux 上只能配一次。
- 第二种,系统级别的,整个系统上可打开的最大文件数,具体参数是fs.file-max。但是这个参数不限制 root 用户。
另外这几个参数之间还有耦合关系,因此还要注意以下三点:
- 1、如果你想加大 soft nofile, 那么 hard nofile 也需要一起调整。因为如果 hard nofile 设置的低, 你的 soft nofile 设置的再高都没用,实际生效的值会按二者里最低的来。
- 2、如果你加大了 hard nofile,那么 fs.nr_open 也都需要跟着一起调整。如果不小心把 hard nofile 设置的比 fs.nr_open 大了,后果比较严重。会导致该用户无法登陆。如果设置的是 * 的话,那么所有的用户都无法登陆。
- 3、还要注意如果你加大了 fs.nr_open,但是用的是
echo "xx" > /proc/sys/fs/nr_open的方式,刚改完你可能觉得没问题。只要机器一重启你的fs.nr_open设置就会失效,还是会无法登陆。
假如你想让你的进程可以打开 100 万个文件描述符,我觉得比较稳妥点的修改方法是干脆都直接用 conf 文件的方式来改。这样比较统一,也比较安全。
# vi /etc/sysctl.conf
fs.nr_open=1100000 //要比 hard nofile 大一点
fs.file-max=1100000 //多留点buffer
# sysctl -p
# vi /etc/security/limits.conf
* soft nofile 1000000
* hard nofile 1000000
通过这种方式修改,你就可以绕过飞哥踩过的坑了。
网络优化
丢包性能优化
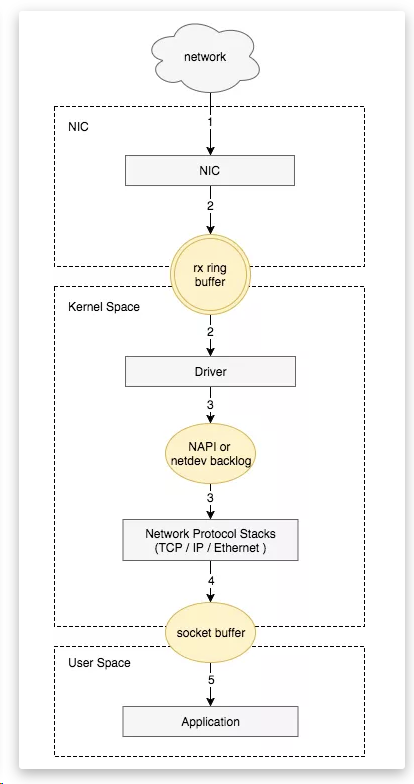
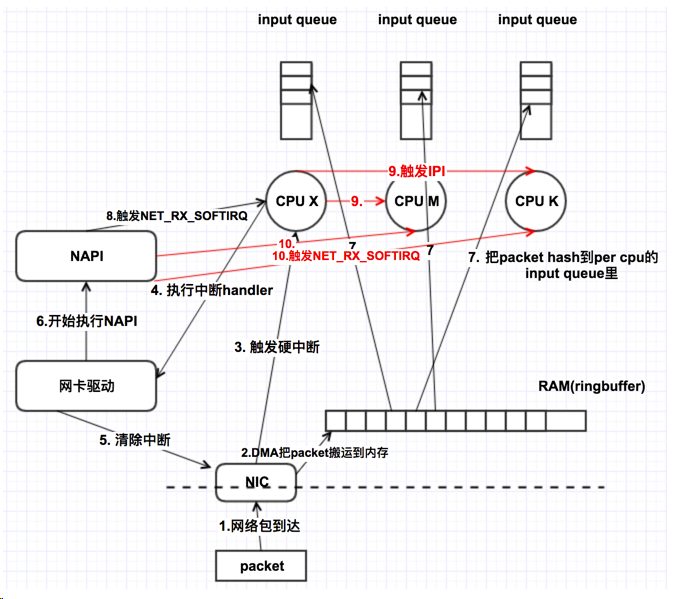
- 网卡收到数据包。
- 将数据包从网卡硬件缓存转移到服务器内存中。
- 通知内核处理。
- 经过 TCP/IP 协议逐层处理。
- 应用程序通过 read() 从 socket buffer 读取数据。
查看丢包
ip -s add show eth0
netstat -i
ifconfig eth0
Ring Buffer 溢出
如果硬件或者驱动没有问题,一般网卡丢包是因为设置的缓存区(ring buffer)太小。当网络数据包到达(生产)的速率快于内核处理(消费)的速率时, Ring Buffer 很快会被填满,新来的数据包将被丢弃。
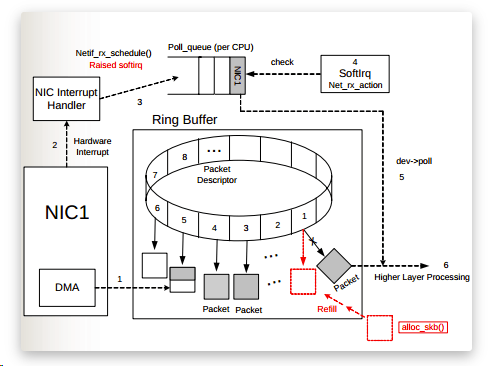
通过 ethtool 或 /proc/net/dev 可以查看因Ring Buffer满而丢弃的包统计,在统计项中以fifo标识:
ethtool -S eth0|grep rx_fifo
rx_fifo_errors: 0
如果发现服务器上某个网卡的 fifo 数持续增大,可以去确认 CPU 中断是否分配均匀,也可以尝试增加 Ring Buffer 的大小,通过 ethtool 可以查看网卡设备 Ring Buffer 最大值,修改 Ring Buffer 当前设置:
# 查看eth0网卡Ring Buffer最大值和当前设置
$ ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 1024
RX Mini: 0
RX Jumbo: 0
TX: 1024
# 修改网卡eth0接收与发送硬件缓存区大小
$ ethtool -G eth0 rx 4096 tx 4096
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
netdev_max_backlog 溢出
netdev_max_backlog 是内核从 NIC 收到包后,交由协议栈(如 IP、TCP )处理之前的缓冲队列。每个 CPU 核都有一个 backlog 队列,与 Ring Buffer 同理,当接收包的速率大于内核协议栈处理的速率时, CPU 的 backlog 队列不断增长,当达到设定的 netdev_max_backlog 值时,数据包将被丢弃。
# cat /proc/net/softnet_stat
2e8f1058 00000000 000000ef 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
0db6297e 00000000 00000035 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
09d4a634 00000000 00000010 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
0773e4f1 00000000 00000005 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
其中: 每一行代表每个 CPU 核的状态统计,从 CPU0 依次往下; 每一列代表一个 CPU 核的各项统计:第一列代表中断处理程序收到的包总数;第二列即代表由于 netdev_max_backlog 队列溢出而被丢弃的包总数。 从上面的输出可以看出,这台服务器统计中,确实有因为 netdev_max_backlog 导致的丢包。
netdev_max_backlog 的默认值是 1000,在高速链路上,可能会出现上述第二列统计不为 0 的情况,可以通过修改内核参数 net.core.netdev_max_backlog 来解决:
sysctl -w net.core.netdev_max_backlog=2000
Socket Buffer 溢出
Socket 可以屏蔽 linux 内核不同协议的差异,为应用程序提供统一的访问接口。每个 Socket 都有一个读写缓存区。
- 读缓冲区,缓存远端发来的数据。如果读缓存区已满,就不能再接收新的数据。
- 写缓冲区,缓存了要发出去的数据。如果写缓冲区已满,应用程序的写操作就会阻塞。
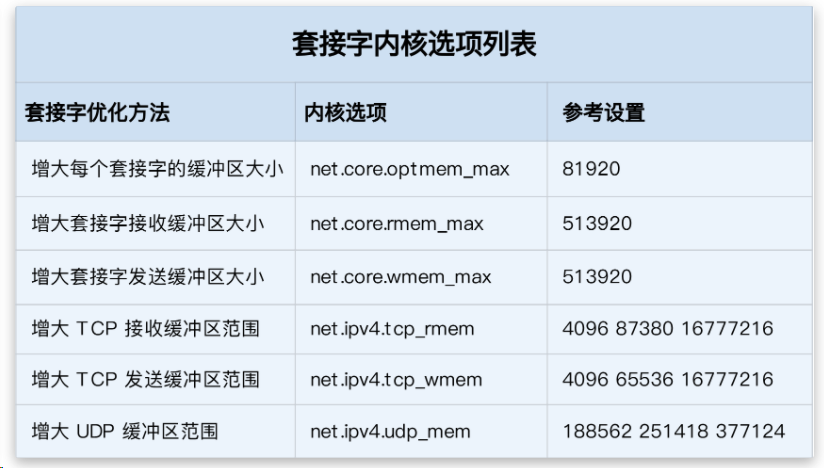
半连接队列和全连接队列溢出

查看及调整
# 全连接队列查看
ss -ln
tcp LISTEN 0 128 127.0.0.1:10257 0.0.0.0:*
# 全连接队列的大小取决于:min(backlog, somaxconn) backlog 是在socket创建的时候传入的,是 listen(int sockfd, int backlog) 函数中的 backlog 大小。somaxconn 是 Linux 内核的参数,默认值是 128,可以通过 /proc/sys/net/core/somaxconn 来设置其值;
cat /proc/sys/net/core/somaxconn
128
# 半连接队列查看
netstat -antp | grep SYN_RECV | wc -l
# 还可以通过 netstat -s 观察半连接队列溢出的情况
netstat -s | grep "SYNs to LISTEN"
# 当 max_syn_backlog > min(somaxconn, backlog) 时, 半连接队列最大值 max_qlen_log = min(somaxconn, backlog) * 2;
# 当 max_syn_backlog < min(somaxconn, backlog) 时, 半连接队列最大值 max_qlen_log = max_syn_backlog * 2;
cat /proc/sys/net/ipv4/tcp_max_syn_backlog
128
# tcp_syncookies:当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
包丢在哪里了
dropwatch
# dropwatch -l kas
Initalizing kallsyms db
dropwatch> start
Enabling monitoring...
Kernel monitoring activated.
Issue Ctrl-C to stop monitoring
1 drops at sk_stream_kill_queues+50 (0xffffffff81687860)
1 drops at tcp_v4_rcv+147 (0xffffffff8170b737)
1 drops at __brk_limit+1de1308c (0xffffffffa052308c)
1 drops at ip_rcv_finish+1b8 (0xffffffff816e3348)
1 drops at skb_queue_purge+17 (0xffffffff816809e7)
3 drops at sk_stream_kill_queues+50 (0xffffffff81687860)
2 drops at unix_stream_connect+2bc (0xffffffff8175a05c)
2 drops at sk_stream_kill_queues+50 (0xffffffff81687860)
1 drops at tcp_v4_rcv+147 (0xffffffff8170b737)
2 drops at sk_stream_kill_queues+50 (0xffffffff81687860)
perf
# perf record -g -a -e skb:kfree_skb
^C[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 1.212 MB perf.data (388 samples) ]
# perf script
containerd 93829 [031] 951470.340275: skb:kfree_skb: skbaddr=0xffff8827bfced700 protocol=0 location=0xffffffff8175a05c
7fff8168279b kfree_skb ([kernel.kallsyms])
7fff8175c05c unix_stream_connect ([kernel.kallsyms])
7fff8167650f SYSC_connect ([kernel.kallsyms])
7fff8167818e sys_connect ([kernel.kallsyms])
7fff81005959 do_syscall_64 ([kernel.kallsyms])
7fff81802081 entry_SYSCALL_64_after_hwframe ([kernel.kallsyms])
f908d __GI___libc_connect (/usr/lib64/libc-2.17.so)
13077d __nscd_get_mapping (/usr/lib64/libc-2.17.so)
130c7c __nscd_get_map_ref (/usr/lib64/libc-2.17.so)
0 [unknown] ([unknown])
containerd 93829 [031] 951470.340306: skb:kfree_skb: skbaddr=0xffff8827bfcec500 protocol=0 location=0xffffffff8175a05c
7fff8168279b kfree_skb ([kernel.kallsyms])
7fff8175c05c unix_stream_connect ([kernel.kallsyms])
7fff8167650f SYSC_connect ([kernel.kallsyms])
7fff8167818e sys_connect ([kernel.kallsyms])
7fff81005959 do_syscall_64 ([kernel.kallsyms])
7fff81802081 entry_SYSCALL_64_after_hwframe ([kernel.kallsyms])
f908d __GI___libc_connect (/usr/lib64/libc-2.17.so)
130ebe __nscd_open_socket (/usr/lib64/libc-2.17.so)
tcpdrop
TIME PID IP SADDR:SPORT > DADDR:DPORT STATE (FLAGS)
05:46:07 82093 4 10.74.40.245:50010 > 10.74.40.245:58484 ESTABLISHED (ACK)
tcp_drop+0x1
tcp_rcv_established+0x1d5
tcp_v4_do_rcv+0x141
tcp_v4_rcv+0x9b8
ip_local_deliver_finish+0x9b
ip_local_deliver+0x6f
ip_rcv_finish+0x124
ip_rcv+0x291
__netif_receive_skb_core+0x554
__netif_receive_skb+0x18
process_backlog+0xba
net_rx_action+0x265
__softirqentry_text_start+0xf2
irq_exit+0xb6
xen_evtchn_do_upcall+0x30
xen_hvm_callback_vector+0x1af
05:46:07 85153 4 10.74.40.245:50010 > 10.74.40.245:58446 ESTABLISHED (ACK)
tcp_drop+0x1
tcp_rcv_established+0x1d5
tcp_v4_do_rcv+0x141
tcp_v4_rcv+0x9b8
ip_local_deliver_finish+0x9b
ip_local_deliver+0x6f
ip_rcv_finish+0x124
ip_rcv+0x291
__netif_receive_skb_core+0x554
__netif_receive_skb+0x18
process_backlog+0xba
net_rx_action+0x265
__softirqentry_text_start+0xf2
irq_exit+0xb6
xen_evtchn_do_upcall+0x30
xen_hvm_callback_vector+0x1af
网络性能优化
TSO/GSO/GRO
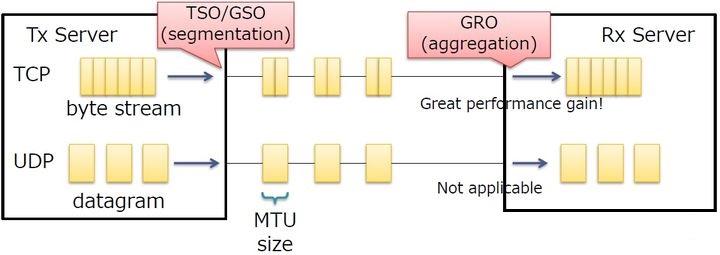
TSO
TSO(TCP Segmentation Offload),是一种利用网卡对TCP数据包分片,减轻CPU负荷的一种技术,有时也被叫做 LSO (Large segment offload) ;
TSO是针对TCP的,UFO是针对UDP的。如果硬件支持 TSO功能,同时也需要硬件支持的TCP校验计算和分散/聚集 (Scatter Gather) 功能。
GSO
GSO(Generic Segmentation Offload),它比TSO更通用,基本思想就是尽可能的推迟数据分片直至发送到网卡驱动之前,此时会检查网卡是否支持分片功能(如TSO、UFO):
如果支持直接发送到网卡,如果不支持就进行分片后再发往网卡。这样大数据包只需走一次协议栈,而不是被分割成几个数据包分别走,这就提高了效率。
LRO
LRO(Large Receive Offload),通过将接收到的多个TCP数据聚合成一个大的数据包,然后传递给网络协议栈处理,以减少上层协议栈处理 开销,提高系统接收TCP数据包的能力。
GRO
GRO(Generic Receive Offload),基本思想跟LRO类似,克服了LRO的一些缺点,更通用。后续的驱动都使用GRO的接口,而不是LRO。
总结
TSO/GSO用于发送报文时,将上层聚合的数据进行分割,分割为不大于MTU的报文;GRO在接受侧,将多个报文聚合为一个数据,上送给协议栈。总之就是将报文的处理下移到了网卡上,减少了网络栈的负担。TSO/GSO等可以增加网络吞吐量,但有可能造成某些连接上的网络延迟。
配置
ethtool -K eth0 gro on/off
# 支持修改的功能如下
gro
gso
rx-gro-list
sg
tso
tx
tx-nocache-copy
RSS/RPS
RSS
RSS是物理网卡支持的特性,可以将NIC的多个队列映射到多个CPU核上进行处理,增加处理的效率,减少CPU中断竞争。
- 在多核服务器上扩展了网络接收侧的处理
- RSS本身是一个NIC特性
- 将报文分发到一个NIC中的多个队列上
- 每个队列都有一个不同的中断向量(不同队列的报文可以被不同的核处理)
- 可以运用于TCP/UDP
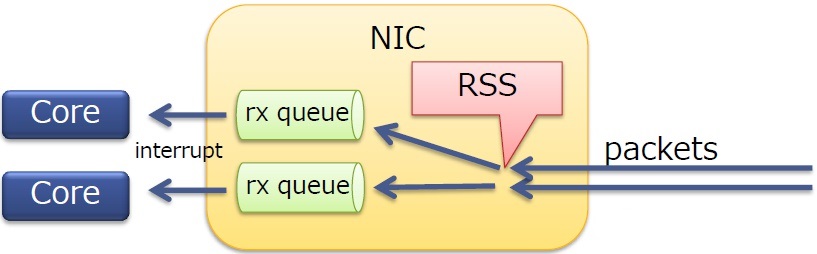
RSS有一个间接表,用于确定分发的报文所属的队列,可以使用ethtool -x命令查看(虚拟环境可能不支持)
ethtool --show-rxfh eth0 # ethtool -x eth0
RX flow hash indirection table for m4/1 with 4 RX ring(s):
0: 0 0 0 0 0 0 0 0
8: 0 0 0 0 0 0 0 0
16: 0 0 0 0 0 0 0 0
24: 0 0 0 0 0 0 0 0
32: 1 1 1 1 1 1 1 1
40: 1 1 1 1 1 1 1 1
48: 1 1 1 1 1 1 1 1
56: 1 1 1 1 1 1 1 1
64: 2 2 2 2 2 2 2 2
72: 2 2 2 2 2 2 2 2
80: 2 2 2 2 2 2 2 2
88: 2 2 2 2 2 2 2 2
96: 3 3 3 3 3 3 3 3
104: 3 3 3 3 3 3 3 3
112: 3 3 3 3 3 3 3 3
120: 3 3 3 3 3 3 3 3
查看网卡 RSS 队列
# 查看网卡多队列
ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0
Other: 1
Combined: 63
Current hardware settings:
RX: 0
TX: 0
Other: 1
Combined: 20
# 设置多队列和CPU数量相同:
# ethtool -L eth0 combined 24 #会中断下网络
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0
Other: 1
Combined: 63
Current hardware settings:
RX: 0
TX: 0
Other: 1
Combined: 24
# 查看网卡多队列对应的irq数量:
cat /proc/interrupts |grep eth0- |wc -l
RPS
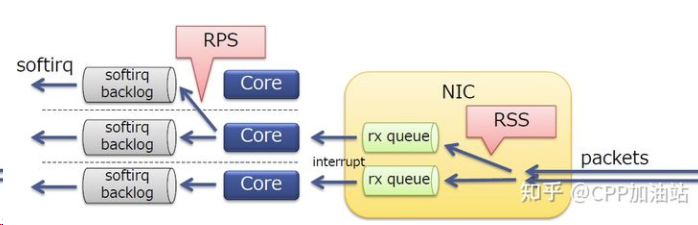
RPS是和RSS类似的一个技术,区别在于RSS是网的硬件实现而RPS是内核软件实现。RPS帮助单队列网卡将其产生的SoftIRQ分派到多个CPU内核进行处理。在这个方案中,为网卡单队列分配的CPU只处理所有硬件中断,由于硬件中断的快速高效,即使在同一个CPU进行处理,影响也是有限的,而耗时的软中断处理会被分派到不同CPU进行处理,可以有效的避免处理瓶颈。
中断绑定
RSS只能将不同的流量分散到不同的队列(每个队列对应一个收发中断),充分利用网卡多队列的特性,但其不能保证中断的均衡,如下图所示。
RSS 中断绑定
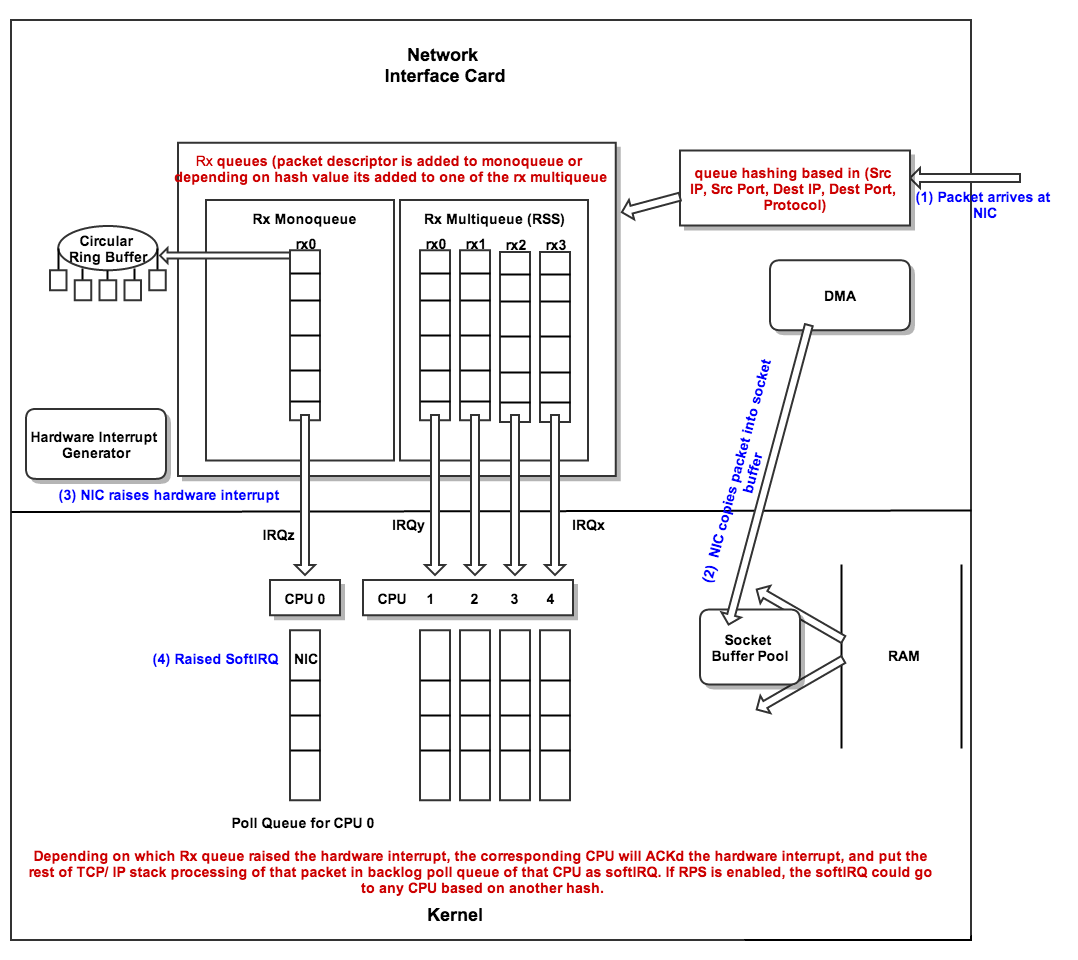
RSS只能将不同的流量分散到不同的队列(每个队列对应一个收发中断),充分利用网卡多队列的特性,但其不能保证中断的均衡
中断绑定相关配置
- smp_affinity 十六进制的bitmask,指定中断亲和性
$ cat /proc/irq/$irq/smp_affinity
1
- smp_affinity_list 十进制CPU list,指定中断亲和性
$ cat /proc/irq/$irq/smp_affinity_list
0
- irqbalance
主要是在系统性能与功耗之间平衡的程序,系统负荷重时把irq分配到多个CPU上,系统空闲时把irq分配在少量CPU保证其它CPU的睡眠状态。用户可手动设置中断的affinity,禁用irqbalance的决策 - affinity_hint 告诉irqbalance此中断倾向的CPU亲和性。
exact: irqbalance程序会严格按照内核的affinity_hint值进行亲和性平衡;
subset: 表示irqbalance会以affinity_hint的一个子集进行平衡;
ignore: 表示完全忽略内核的affinity_hint。
cat /proc/irq/$irq/affinity_hint
1
所以又两种方法解决中断均衡的问题
- 一个是把irqbalance服务stop,手动设置中断的smp_affinity
- 另一种设设置好affinity_hint,然后让irqbalance使用-h exact参数启动。

自动绑定脚本
#!/bin/bash
#
# Copyright (c) 2015, Intel Corporation
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
#
# * Redistributions of source code must retain the above copyright notice,
# this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
# * Neither the name of Intel Corporation nor the names of its contributors
# may be used to endorse or promote products derived from this software
# without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE
# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
#
# Affinitize interrupts to cores
#
# typical usage is (as root):
# set_irq_affinity -x local eth1 <eth2> <eth3>
#
# to get help:
# set_irq_affinity
usage()
{
echo
echo "Usage: $0 [-x|-X] {all|local|remote|one|custom} [ethX] <[ethY]>"
echo " options: -x Configure XPS as well as smp_affinity"
echo " options: -X Disable XPS but set smp_affinity"
echo " options: {remote|one} can be followed by a specific node number"
echo " Ex: $0 local eth0"
echo " Ex: $0 remote 1 eth0"
echo " Ex: $0 custom eth0 eth1"
echo " Ex: $0 0-7,16-23 eth0"
echo
exit 1
}
usageX()
{
echo "options -x and -X cannot both be specified, pick one"
exit 1
}
if [ "$1" == "-x" ]; then
XPS_ENA=1
shift
fi
if [ "$1" == "-X" ]; then
if [ -n "$XPS_ENA" ]; then
usageX
fi
XPS_DIS=2
shift
fi
if [ "$1" == -x ]; then
usageX
fi
if [ -n "$XPS_ENA" ] && [ -n "$XPS_DIS" ]; then
usageX
fi
if [ -z "$XPS_ENA" ]; then
XPS_ENA=$XPS_DIS
fi
num='^[0-9]+$'
# Vars
AFF=$1
shift
case "$AFF" in
remote) [[ $1 =~ $num ]] && rnode=$1 && shift ;;
one) [[ $1 =~ $num ]] && cnt=$1 && shift ;;
all) ;;
local) ;;
custom) ;;
[0-9]*) ;;
-h|--help) usage ;;
"") usage ;;
*) IFACES=$AFF && AFF=all ;; # Backwards compat mode
esac
# append the interfaces listed to the string with spaces
while [ "$#" -ne "0" ] ; do
IFACES+=" $1"
shift
done
# for now the user must specify interfaces
if [ -z "$IFACES" ]; then
usage
exit 1
fi
# support functions
set_affinity()
{
VEC=$core
if [ $VEC -ge 32 ]
then
MASK_FILL=""
MASK_ZERO="00000000"
let "IDX = $VEC / 32"
for ((i=1; i<=$IDX;i++))
do
MASK_FILL="${MASK_FILL},${MASK_ZERO}"
done
let "VEC -= 32 * $IDX"
MASK_TMP=$((1<<$VEC))
MASK=$(printf "%X%s" $MASK_TMP $MASK_FILL)
else
MASK_TMP=$((1<<$VEC))
MASK=$(printf "%X" $MASK_TMP)
fi
printf "%s" $MASK > /proc/irq/$IRQ/smp_affinity
printf "%s %d %s -> /proc/irq/$IRQ/smp_affinity\n" $IFACE $core $MASK
case "$XPS_ENA" in
1)
printf "%s %d %s -> /sys/class/net/%s/queues/tx-%d/xps_cpus\n" $IFACE $core $MASK $IFACE $((n-1))
printf "%s" $MASK > /sys/class/net/$IFACE/queues/tx-$((n-1))/xps_cpus
;;
2)
MASK=0
printf "%s %d %s -> /sys/class/net/%s/queues/tx-%d/xps_cpus\n" $IFACE $core $MASK $IFACE $((n-1))
printf "%s" $MASK > /sys/class/net/$IFACE/queues/tx-$((n-1))/xps_cpus
;;
*)
esac
}
# Allow usage of , or -
#
parse_range () {
RANGE=${@//,/ }
RANGE=${RANGE//-/..}
LIST=""
for r in $RANGE; do
# eval lets us use vars in {#..#} range
[[ $r =~ '..' ]] && r="$(eval echo {$r})"
LIST+=" $r"
done
echo $LIST
}
# Affinitize interrupts
#
setaff()
{
CORES=$(parse_range $CORES)
ncores=$(echo $CORES | wc -w)
n=1
# this script only supports interrupt vectors in pairs,
# modification would be required to support a single Tx or Rx queue
# per interrupt vector
queues="${IFACE}-.*TxRx"
irqs=$(grep "$queues" /proc/interrupts | cut -f1 -d:)
[ -z "$irqs" ] && irqs=$(grep $IFACE /proc/interrupts | cut -f1 -d:)
[ -z "$irqs" ] && irqs=$(for i in `ls -Ux /sys/class/net/$IFACE/device/msi_irqs` ;\
do grep "$i:.*TxRx" /proc/interrupts | grep -v fdir | cut -f 1 -d : ;\
done)
[ -z "$irqs" ] && echo "Error: Could not find interrupts for $IFACE"
echo "IFACE CORE MASK -> FILE"
echo "======================="
for IRQ in $irqs; do
[ "$n" -gt "$ncores" ] && n=1
j=1
# much faster than calling cut for each
for i in $CORES; do
[ $((j++)) -ge $n ] && break
done
core=$i
set_affinity
((n++))
done
}
# now the actual useful bits of code
# these next 2 lines would allow script to auto-determine interfaces
#[ -z "$IFACES" ] && IFACES=$(ls /sys/class/net)
#[ -z "$IFACES" ] && echo "Error: No interfaces up" && exit 1
# echo IFACES is $IFACES
CORES=$(</sys/devices/system/cpu/online)
[ "$CORES" ] || CORES=$(grep ^proc /proc/cpuinfo | cut -f2 -d:)
# Core list for each node from sysfs
node_dir=/sys/devices/system/node
for i in $(ls -d $node_dir/node*); do
i=${i/*node/}
corelist[$i]=$(<$node_dir/node${i}/cpulist)
done
for IFACE in $IFACES; do
# echo $IFACE being modified
dev_dir=/sys/class/net/$IFACE/device
[ -e $dev_dir/numa_node ] && node=$(<$dev_dir/numa_node)
[ "$node" ] && [ "$node" -gt 0 ] || node=0
case "$AFF" in
local)
CORES=${corelist[$node]}
;;
remote)
[ "$rnode" ] || { [ $node -eq 0 ] && rnode=1 || rnode=0; }
CORES=${corelist[$rnode]}
;;
one)
[ -n "$cnt" ] || cnt=0
CORES=$cnt
;;
all)
CORES=$CORES
;;
custom)
echo -n "Input cores for $IFACE (ex. 0-7,15-23): "
read CORES
;;
[0-9]*)
CORES=$AFF
;;
*)
usage
exit 1
;;
esac
# call the worker function
setaff
done
# check for irqbalance running
IRQBALANCE_ON=`ps ax | grep -v grep | grep -q irqbalance; echo $?`
if [ "$IRQBALANCE_ON" == "0" ] ; then
echo " WARNING: irqbalance is running and will"
echo " likely override this script's affinitization."
echo " Please stop the irqbalance service and/or execute"
echo " 'killall irqbalance'"
fi
使用
set_irq_affinity -x eth0|all
set_irq_affinity eth0|all
set_irq_affinity eth0
IFACE CORE MASK -> FILE
=======================
eth0 0 1 -> /proc/irq/68/smp_affinity
eth0 1 2 -> /proc/irq/69/smp_affinity
eth0 2 4 -> /proc/irq/70/smp_affinity
eth0 3 8 -> /proc/irq/71/smp_affinity
eth0 4 10 -> /proc/irq/74/smp_affinity
eth0 5 20 -> /proc/irq/75/smp_affinity
eth0 6 40 -> /proc/irq/76/smp_affinity
eth0 7 80 -> /proc/irq/77/smp_affinity
eth0 8 100 -> /proc/irq/78/smp_affinity
eth0 9 200 -> /proc/irq/79/smp_affinity
eth0 10 400 -> /proc/irq/80/smp_affinity
eth0 11 800 -> /proc/irq/81/smp_affinity
eth0 12 1000 -> /proc/irq/82/smp_affinity
eth0 13 2000 -> /proc/irq/83/smp_affinity
eth0 14 4000 -> /proc/irq/84/smp_affinity
eth0 15 8000 -> /proc/irq/85/smp_affinity
eth0 16 10000 -> /proc/irq/86/smp_affinity
eth0 17 20000 -> /proc/irq/87/smp_affinity
eth0 18 40000 -> /proc/irq/88/smp_affinity
eth0 19 80000 -> /proc/irq/89/smp_affinity
eth0 20 100000 -> /proc/irq/90/smp_affinity
eth0 21 200000 -> /proc/irq/91/smp_affinity
eth0 22 400000 -> /proc/irq/92/smp_affinity
eth0 23 800000 -> /proc/irq/93/smp_affinity
RPS 中断绑定
中断绑定后的效果如下图所示,由于一共只有16个队列,所以可以看到其绑定的16个队列的软中断已经将对应CPU全部打满了。
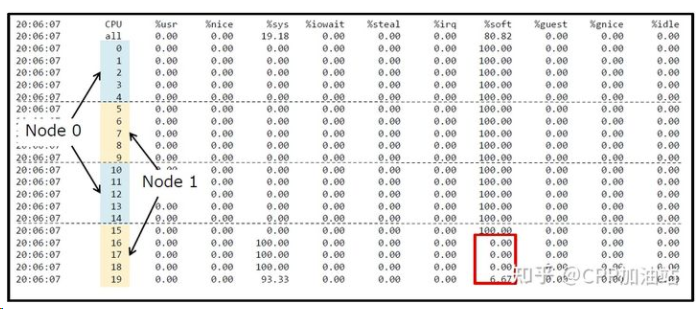
可是我们的及其还有其他空闲的4个CPU,如何充分利用起来这4个CPU呢。这就需要RPS了。PS:实际应用中建议将RPS全部关闭,因为打开可能导致性能更加恶化,详见下文分析,除非对性能调优有较多经验。RPS可以指定CPU和软中断的关系(中断绑定是指定CPU和中断的关系)
在这之前,软中断只能在硬中断所在CPU上处理,使用RPS后,网卡软中断就可以分发到其他的CPU上去做处理了。
# echo 10040 > /sys/class/net/ens1f0/queues/rx-6/rps_cpus
# echo 20080 > /sys/class/net/ens1f0/queues/rx-7/rps_cpus
# echo 40100 > /sys/class/net/ens1f0/queues/rx-8/rps_cpus
# echo 80200 > /sys/class/net/ens1f0/queues/rx-9/rps_cpus
使能RPS后为什么会导致QPS下降?
如上图所示,使能了RPS后,会增加一些额外的CPU开销:
- 收到网卡中断的CPU会向其他CPU发IPI中断,这体现在CPU的%irq上
- 需要处理packet的cpu会收到NET_RX_SOFTIRQ软中断,这体现再CPU的%soft上。请注意,RPS并不会减少第一个CPU的软中断次数,但是会额外给其他的CPU增加软中断。他减少的是第一个CPU的软中断的执行时间,即,软中断里不再需要那么多的时间去走协议栈做包解析,把这个时间给均摊到其他的CPU上去了。
- 使能了RPS后,会增加CPU的%soft,如果业务场景本身就是CPU密集的,CPU的负载已经很高了,那么RPS就会挤压%usr,即挤压业务代码的执行时间,从而导致业务性能下降。
TCP 参数优化
相对UDP来说,TCP的性能优化要复杂的多。TCP的性能主要受到以下几个方面的影响:
- 内核版本
- 拥塞算法
- 延时(rtt)
- 接收buffer
- 发送buffer
首先,内核版本对网络性能有巨大影响,因为高版本的内核不但对协议栈做了大量优化,而且对协议栈用到的其他机制,如内存分配等有着很多优化,如果测试可以发现使用4.9或以上版本的内核,其TCP性能要远好于3.10版本。
其次,拥塞算法也十分关键,比如在公网或延时(rtt)较大的情况使用BBR算法效果较好,而在内网延时较小的场景,cubic的效果可能更佳。
当前最常见的TCP的性能影响因素是丢包导致的重传和乱序,这种情况就需要分析具体链路的丢包原因了,如使用dropwatch工具查看内核丢包
TCP 性能和发送接收 Buffer 的关系
先看一下系统中和接收发送buffer相关参数。
$sudo sysctl -a | egrep "rmem|wmem|adv_win|moderate"
net.core.rmem_default = 212992
net.core.rmem_max = 212992
net.core.wmem_default = 212992
net.core.wmem_max = 212992
net.ipv4.tcp_adv_win_scale = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_rmem = 4096 87380 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.udp_rmem_min = 4096
net.ipv4.udp_wmem_min = 4096
vm.lowmem_reserve_ratio = 256 256 32
TCP性能和发送窗口的关系
首先我们看下面一个案例,此案例中TCP性能上不去,抓包分析发现其序列号变化如下图,大概传输16k左右数据就会出现一次20ms的等待。
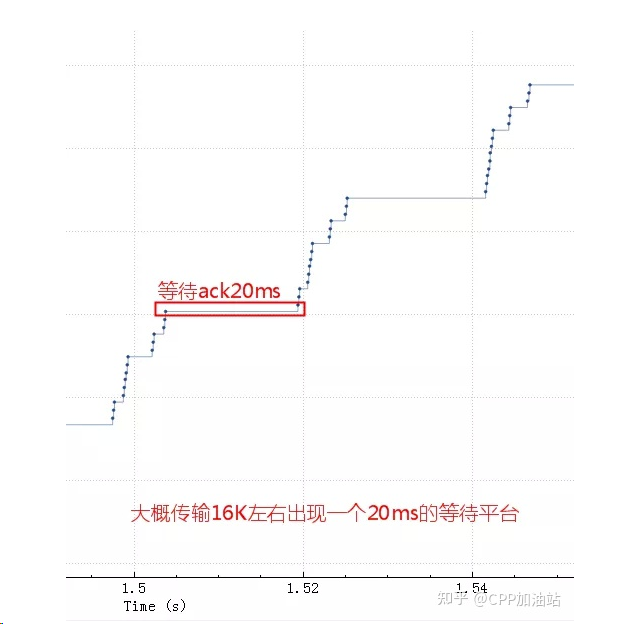
导致这个问题的原因是发送buffer只有 16K ,这些包很快都发出去了,但是这 16K 不能立即释放出来填新的内容进去,因为 tcp 要保证可靠,万一中间丢包了呢。只有等到这 16K 中的某些包 ack 了,才会填充一些新包进来然后继续发出去。由于这里 rt 基本是 20ms,也就是 16K 发送完毕后,等了 20ms 才收到一些 ack,这 20ms 应用、内核什么都不能做。
sendbuffer 相当于发送仓库的大小,仓库的货物都发走后,不能立即腾出来发新的货物,而是要等对方确认收到了(ack)才能腾出来发新的货物。 传输速度取决于发送仓库(sendbuffer)、接收仓库(recvbuffer)、路宽(带宽)的大小,如果发送仓库(sendbuffer)足够大了之后接下来的瓶颈就是高速公路了(带宽、拥塞窗口)。
所以可以通过调大发送buffer来解决此问题,发送buffer的相关参数有:
net.core.wmem_max = 1048576
net.core.wmem_default = 124928
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.udp_wmem_min = 4096
其关系如下:
- 如果指定了 tcp_wmem,则 net.core.wmem_default 被 tcp_wmem 的覆盖
- send Buffer 在 tcp_wmem 的最小值和最大值之间自动调整
- 如果调用 setsockopt()设置了 socket 选项 SO_SNDBUF,将关闭发送端缓冲的自动调节机制,tcp_wmem 将被忽略
- SO_SNDBUF 的最大值由 net.core.wmem_max 限制
- 默认情况下 Linux 系统会自动调整这个 buffer(net.ipv4.tcp_wmem), 也就是不推荐程序中主动去设置 SO_SNDBUF,除非明确知道设置的值是最优的
TCP性能和接收窗口的关系
接收buffer很小的时候并且 rtt 很小时对性能的影响
我们可以看下面一个例子:明显看到接收窗口经常跑满,但是因为 rtt 很小,一旦窗口空出来很快就通知到对方了,所以整个过小的接收窗口也没怎么影响到整体性能。
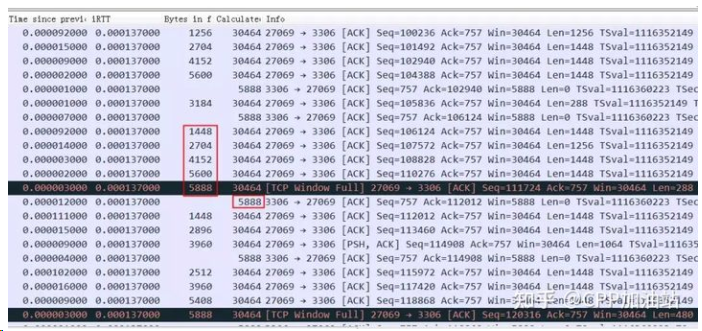
下图可以更清楚看到 server 一旦空出来点窗口,client 马上就发送数据,由于这点窗口太小,rtt 是 40ms,也就是一个 rtt 才能传 3456 字节的数据,整个带宽才 80-90K,完全没跑满。
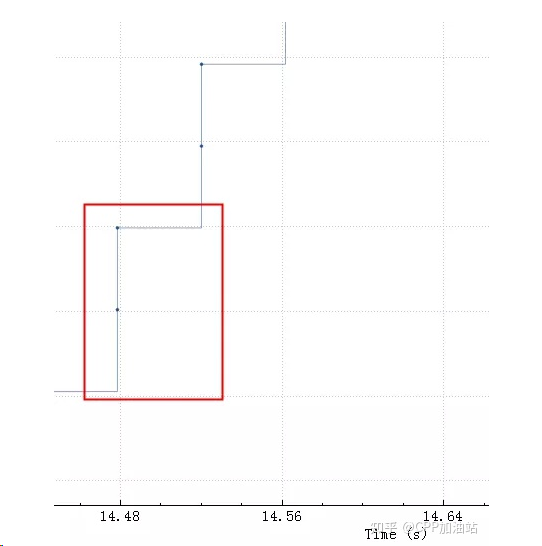
从这里可以得出结论,接收窗口的大小对性能的影响,rtt 越大影响越明显,当然这里还需要应用程序配合,如果应用程序一直不读走数据即使接收窗口再大也会堆满的。
- 一般来说绝对不要在程序中手工设置 SO_SNDBUF 和 SO_RCVBUF,内核自动调整做的更好
- SO_SNDBUF 一般会比发送滑动窗口要大,因为发送出去并且 ack 了的才能从 SO_SNDBUF 中释放;
- TCP 接收窗口跟 SO_RCVBUF 关系很复杂;
- SO_RCVBUF 太小并且 rtt 很大的时候会严重影响性能;
- 接收窗口比发送窗口要复杂的多;
- 再拥塞算法一定的情况下,发送buffer、rtt、接收buffer一起决定了传输速度。
优化单个核
1. 禁用GRO
GRO并不适用于UDP(UDP隧道除外,如VXLAN)
为UDP服务禁用GRO
ethtool -K gro off
注意:如果关注TCP性能,则不能禁用GRO功能,禁用GRO会导致TCP接收吞吐量降低。
2. 关闭反向路径过滤和本地地址校验
在接收路径上,由于反向路径过滤和本地地址校验,FIB查询了两次。每次也有额外的CPU开销。
如果不需要源校验,则可以忽略
sysctl -w net.ipv4.conf.all.rp_filter=0
sysctl -w net.ipv4.conf..rp_filter=0
sysctl -w net.ipv4.conf.all.accept_local=1
3. 禁用audit
当大量处理报文时,Audit消耗的CPU会变大。大概消耗2.5%的CPU时间
如果不需要audit,则禁用
systemctl disable auditd
reboot
单用户重置密码报错
Authentication token manipulation error
问题描述
单用户重置密码时遇到 passwd:Authentication token manipulation error 报错。

原因分析
大部分情况由于密码文件(/etc/passwd和/etc/shadow)权限异常导致,也有可能因为磁盘空间已满导致。
处理方式
先执行 df -h 查看磁盘空间,如果空间已满,需要请理空间,如果磁盘空间正常,则执行 lsattr 查看文件属性。
$ lsattr /etc/passwd /etc/shadow

根据 lsattr 命令查看,/etc/shadow目录有a的权限,需要把a权限取消,执行chattr取消权限。
$ chattr -a /etc/shadow
如果密码文件有其他属性,比如"i"属性,需要执行 chattr -i /etc/shadow 去除"i"属性。
$ chattr -i /etc/shadow
执行lsattr再次查看文件属性,只有"e"属性即为正常。
再次重置密码。
$ passwd
Authentication token lock busy
问题描述
单用户重置密码时遇到 Authentication token lock busy报错。

原因分析
大部分情况由于磁盘只读导致。
处理方式
先执行 mount -o remount,rw /重新挂载磁盘。
$ mount -o remount,rw /
再次重置密码。
$ passwd
进入单用户模式
CentOS7 进入单用户
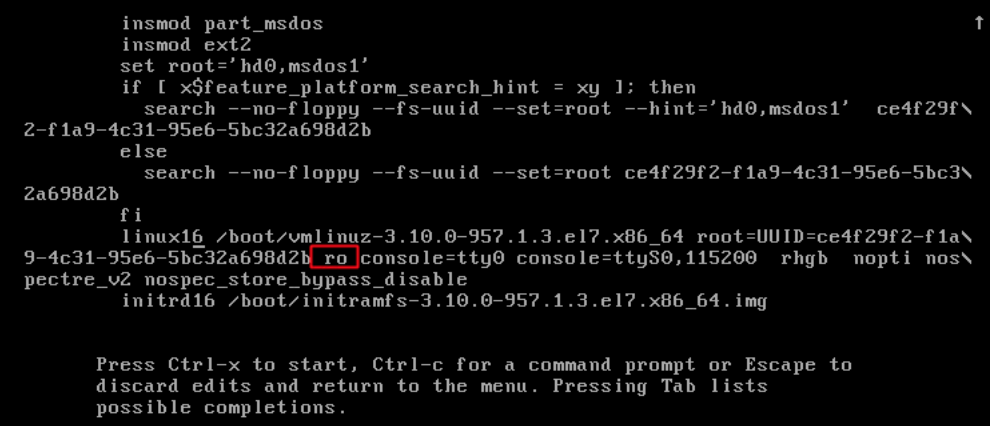
找到第一个linux16部分,修改ro为rw,在末尾后面添加console=console init=/bin/sh
按Ctrl+X重启 进入单用户模式
Centos8进入单用户
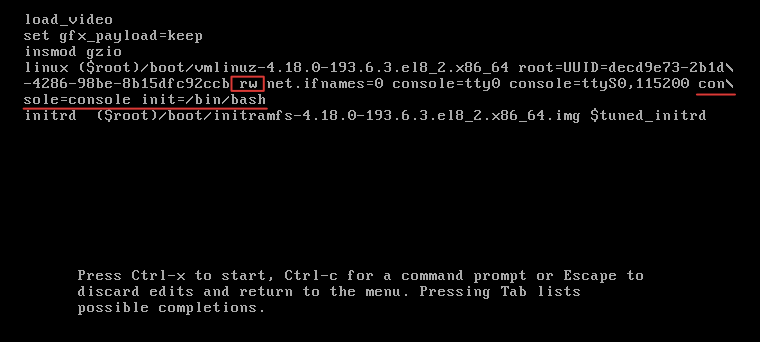
找到第一个linux部分,修改ro为rw,在末尾后面添加 console=console init=/bin/sh。
按 Ctrl+X 重启,进入单用户模式。
系统启动异常如何处理
问题描述

问题原因
一般是因为/etc/fstab文件中磁盘挂载了错误的文件系统,或者磁盘错误造成的。
解决方法
输入实例的root密码,进入维护模式。
在终端上输入以下命令,以读写方式重新挂载根分区:
mount / -o remount,rw
执行blkid命令,查看BCC的磁盘的分区和文件系统,如图所示,数据盘为/dev/vdb1,文件系统类型为ext4。

查看/etc/fstab内容,检查其写入的磁盘信息是否与上图所示的一致
如果一致,则查看挂载参数是否有nofail,如果没有建议添加该参数【Linux实例启动过程中,若设备不存在会直接忽略它,从而不影响系统的启动】
如果不一致,修改/etc/fstab,写入正确的挂载信息。
UUID=c2735c6e-7008-49ac-a700-b14b9d3e93d6 /work ext4 defaults,nofail 0 0
或
/dev/vdb1 /work ext4 defaults,nofail 0 0
文件系统只读
云服务器删除或者修改文件时提示文件系统只读:Read-only file system,导致操作失败。

出现文件系统Read-only的原因可能有:
文件系统错误导致文件系统进入只读模式。
文件系统是以只读方式进行的挂载。
磁盘故障,例如出现坏道等。
解决方法
执行命令mount | grep 挂载点,查看文件文件的挂载属性

如果挂载选项显示为ro,说明以只读方式挂载了文件系统,需要以可读写方式进行挂载
mount -o remount,rw 挂载点
如果挂载选项显示为rw,需要确认是否为文件系统错误导致。
通过以下命令(二选一),查看内核日志中是否存在文件系统错误
dmesg | egrep -i "ext3|ext4|xfs" cat /var/log/messages | egrep -i "ext3|ext4|xfs"
如果内核日志中出现了文件系统错误,则需要进行修复文件系统。
如果是系统盘的文件系统修复需要进入单用户模式,进行文件系统的修复
如果是数据磁盘的文件系统出错,需要先把数据磁盘umount
示例命令:
umount /dev/vdb1 或 umount /mnt
修复文件系统命令如下:
ext系列文件系统执行以下命令
fsck /dev/vdb1
xfs系列文件执行以下命令
xfs_repair /dev/vdb1
注:修复文件系统,可能会产生数据丢失,请先备份数据后进行操作。
如果以上操作都不能解决Read-only问题, 需要检查磁盘是否存在物理故障。
kdump
kdump 是一种先进的基于 kexec 的内核崩溃转储机制。
配置kdump
# 安装kexec-tools,查看是否已安装kexec-tools
rpm -qa | grep kexec-tools
# 如果没有安装,执行下面命令安装kexec-tools。
yum install -y kexec-tools
# 开启kdump开机启动
systemctl enable kdump
设置craskkernel参数
首先查看该参数是否已经设置。
cat /proc/cmdline | grep crashkernel 如果有显示,则表示已经设置,如果没有显示,则需要重新设置。 编辑/etc/default/grub文件
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="console=tty0 console=ttyS0,115200 nopti nospectre_v2 nospec_store_bypass_disable"
GRUB_DISABLE_RECOVERY="true"
在GRUB_CMDLINE_LINUX一行添加crashkernel=auto。
更新grub
执行更新grub命令,使配置生效:
grub2-mkconfig -o /boot/grub2/grub.cfg
设置vmcore保存路径
vmcore默认保存在/var/crash目录下,如果要保存到其他目录,可编辑/etc/kdump.conf,修改path一行,将其修改成对应的目录。
path vmcore_directory
## 请确保指定的路径有足够的空间保存vmcore,建议剩余空间不小于物理内存(RAM)的大小。
设置转存vmcore级别
查看/etc/kdump.conf文件,是否存在以下设置,如果存在则无需添加
core_collector makedumpfile -d 31 -c
# -c:表示压缩vmcore文件,
# -d:表示过滤掉部分无效的内存数据,可以根据需要调整,一般31即可,31是由如下的值与计算而成。
zero pages = 1
cache pages = 2
cache private = 4
user pages = 8
free pages = 16
设置内核参数
编辑/etc/sysctl.conf,添加以下参数。
kernel.hardlockup_panic=1
kernel.panic=5
kernel.panic_on_oops=1
kernel.softlockup_panic=1
kernel.unknown_nmi_panic=1
kernel.nmi_watchdog=1
---以下为可选参数---
kernel.panic_on_io_nmi=1
kernel.panic_on_warn=1
重启系统
Linux系统加了弹性网卡却不能从外部访问?
为了给云服务器增加一个外网IP,实现单主机多 IP 部署,或者在一个CVM上接入到多个私有网络中,我们可以通过绑定弹性网卡的方式实现。但是绑定弹性网卡后,要从外部进行访问时,就需要正确的配置弹性IP及策略路由。
如果没有正确配置时,流量会根据子机内部的路由表的default路由对外发送,导致流出时的“路径”与入流量的“路径”不一致,导致被拒绝。
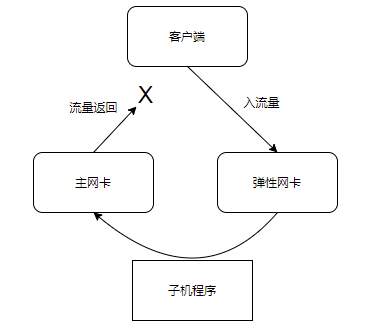
基本环境
IP1: 172.16.0.100/16
IP2: 172.16.0.200/16
检查是否有设置策略路由表文件
为了使我们的流量从哪个网卡进入,就需要使用iproute2组件的策略路由,配置文件一般为 "/etc/iproute2/rt_tables"。
我们需要在该文件中新增两个表,格式为"表的代号 表名",其中表的代号需要在255以下,但是0/253-255已经作为预留表,我们可用的为1-252。此处我以"10 eth0"/"20 eth1"作为例子。
# reserved values
#
255 local
254 main
253 default
0 unspec
#
# local
#
#1 inr.ruhep
10 eth0
20 eth1
确认此处已配置好后,我们保存文件即可。
检查是否有将每个网卡的默认网关增加到策略路由表
ip route show table 10
ip route show table 20
这里没有输出,可没有配置好,我们通过命令行配置下。
ip route add default dev [网关名 如eth0] via [该网卡的网关 如172.16.0.1] table [策略路由表的代号 如10]
ip route add default dev eth0 via 172.16.0.1 table 10
ip route add default dev eth1 via 172.16.0.1 table 20
此处的配置只能临时保存,如果我们需要保证重启服务器或重启网络服务后,无需繁琐地再人工配置一次,我们可以利用网卡配置文件把策略保存下来
如果在使用Centos7系统,我们来到"/etc/sysconfig/network-scripts"目录,编辑一个文件 route-网卡名 (如route-eth0)
vim /etc/sysconfig/network-scripts/route-eth0
default dev [网卡名 如eth0] via [该网卡的网关 如172.16.0.1] table [策略路由表的代号 如10]
对的,很简单,只需要写一行即可,"目标(default) dev 网卡 via 网关 table 路由表代号"
写好后 systemctl restart network 重启网络测试下,确认重启后策略路由是否自动添加
检查是否配置策略路由规则
ip rule list
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
很明显的,这里仅有我们一些默认的路由表,接下来一起进行配置
ip rule add from [主网卡的ip] table [主网卡的策略路由表代号]
ip rule add from [弹性网卡的ip] table [弹性网卡的策略路由表代号]
可以看到 ip rule list 命令已经有对应规则了,到此策略路由配置完成,可以尝试ping一下两个外网ip
ip rule add from 172.16.0.100 table 10
ip rule add from 172.16.0.200 table 20
删除腾讯云服务器监控
Linux
#!/usr/bin/env bash
systemctl stop tat_agent
systemctl disable tat_agent
rm -f /etc/systemd/system/tat_agent.service
/usr/local/qcloud/stargate/admin/uninstall.sh
/usr/local/qcloud/monitor/barad/admin/uninstall.sh
/usr/local/qcloud/YunJing/uninst.sh
rm -rf /usr/local/qcloud
rm -rf /usr/local/yd.socket.server
然后重启服务器
Windows
powershell执行
sc.exe stop BaradAgentSvc 2>$null 1>$null
sc.exe config BaradAgentSvc start= disabled 2>$null 1>$null
sc.exe delete BaradAgentSvc 2>$null 1>$null
sc.exe stop StargateSvc 2>$null 1>$null
sc.exe config StargateSvc start= disabled 2>$null 1>$null
sc.exe delete StargateSvc 2>$null 1>$null
进到这2个目录执行uninstall.bat
C:\Program Files\QCloud\Stargate\admin\
C:\Program Files\QCloud\Monitor\Barad\admin\
sc stop tatsvc
sc delete tatsvc
如何验证已卸载?用sc qc命令查询服务情况,如果是未安装就代表卸载了
sc.exe qc BaradAgentSvc
sc.exe qc BaradAgentSvc
brook 代理搭建
#!/usr/bin/env bash
# https://github.com/txthinking/brook
# 下载二进制文件
curl -L https://github.com/txthinking/brook/releases/latest/download/brook_linux_amd64 -o /usr/bin/brook
chmod +x /usr/bin/brook
# 创建 systemd 服务
cat << EOF > /etc/wireguard/wg0.conf
[Unit]
Description=brook service
After=network.target syslog.target
Wants=network.target
[Service]
Type=simple
ExecStart=/usr/bin/brook server --listen :9999 --password 密码
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now brook.service
客户端连接服务器端
brook client --server 1.2.3.4:9999 --password hello --socks5 127.0.0.1:1080
只让指定国家 IP 访问
IP集下载
https://blog.kieng.cn/774.html
# 创建一个名为cnip的规则
ipset -N cnip hash:net
# 下载国家IP段,这里以中国为例
wget -P . http://www.ipdeny.com/ipblocks/data/countries/cn.zone
# 将IP段添加到cnip规则中
for i in $(cat ./cn.zone ); do ipset -A cnip $i; done
# 添加私有网段,否则内网无法连通
ipset -A cnip 10.0.0.0/8
ipset -A cnip 172.16.0.0/12
ipset -A cnip 192.168.0.0/16
ipset -A cnip 169.254.0.0/16 # 放通腾讯云 yum 源
# 添加例外 IP
ipset -A cnip 43.154.58.208/32
# 放行IP段
iptables -A INPUT -p tcp -m set --match-set cnip src -j ACCEPT
iptables -A INPUT -p udp -m set --match-set cnip src -j ACCEPT
iptables -A INPUT -p icmp -m set --match-set cnip src -j ACCEPT
# 设置默认策略,不匹配规则的 DROP or ACCEPT
iptables -P INPUT DROP
# 将参数里的-A 改成-D 就是删除规则了,如
iptables -D INPUT -p tcp -m set --match-set cnip src -j ACCEPT
iptables -D INPUT -p tcp --dport 443 -j DROP
Linux VPS一键屏蔽指定国家所有的IP访问
下载脚本
wget https://www.moerats.com/usr/shell/block-ips.sh
chmod +x block-ips.sh ./block-ips.sh
脚本
#! /bin/bash
#Block-IPs-from-countries
#Github:https://github.com/iiiiiii1/Block-IPs-from-countries
#Blog:https://www.moerats.com/
Green="\033[32m"
Font="\033[0m"
#root权限
root_need(){
if [[ $EUID -ne 0 ]]; then
echo "Error:This script must be run as root!" 1>&2
exit 1
fi
}
#封禁ip
block_ipset(){
check_ipset
#添加ipset规则
echo -e "${Green}请输入需要封禁的国家代码,如cn(中国),注意字母为小写!${Font}"
read -p "请输入国家代码:" GEOIP
echo -e "${Green}正在下载IPs data...${Font}"
wget -P /tmp http://www.ipdeny.com/ipblocks/data/countries/$GEOIP.zone 2> /dev/null
#检查下载是否成功
if [ -f "/tmp/"$GEOIP".zone" ]; then
echo -e "${Green}IPs data下载成功!${Font}"
else
echo -e "${Green}下载失败,请检查你的输入!${Font}"
echo -e "${Green}代码查看地址:http://www.ipdeny.com/ipblocks/data/countries/${Font}"
exit 1
fi
#创建规则
ipset -N $GEOIP hash:net
for i in $(cat /tmp/$GEOIP.zone ); do ipset -A $GEOIP $i; done
rm -f /tmp/$GEOIP.zone
echo -e "${Green}规则添加成功,即将开始封禁ip!${Font}"
#开始封禁
iptables -I INPUT -p tcp -m set --match-set "$GEOIP" src -j DROP
iptables -I INPUT -p udp -m set --match-set "$GEOIP" src -j DROP
echo -e "${Green}所指定国家($GEOIP)的ip封禁成功!${Font}"
}
#解封ip
unblock_ipset(){
echo -e "${Green}请输入需要解封的国家代码,如cn(中国),注意字母为小写!${Font}"
read -p "请输入国家代码:" GEOIP
#判断是否有此国家的规则
lookuplist=`ipset list | grep "Name:" | grep "$GEOIP"`
if [ -n "$lookuplist" ]; then
iptables -D INPUT -p tcp -m set --match-set "$GEOIP" src -j DROP
iptables -D INPUT -p udp -m set --match-set "$GEOIP" src -j DROP
ipset destroy $GEOIP
echo -e "${Green}所指定国家($GEOIP)的ip解封成功,并删除其对应的规则!${Font}"
else
echo -e "${Green}解封失败,请确认你所输入的国家是否在封禁列表内!${Font}"
exit 1
fi
}
#查看封禁列表
block_list(){
iptables -L | grep match-set
}
#检查系统版本
check_release(){
if [ -f /etc/redhat-release ]; then
release="centos"
elif cat /etc/issue | grep -Eqi "debian"; then
release="debian"
elif cat /etc/issue | grep -Eqi "ubuntu"; then
release="ubuntu"
elif cat /etc/issue | grep -Eqi "centos|red hat|redhat"; then
release="centos"
elif cat /proc/version | grep -Eqi "debian"; then
release="debian"
elif cat /proc/version | grep -Eqi "ubuntu"; then
release="ubuntu"
elif cat /proc/version | grep -Eqi "centos|red hat|redhat"; then
release="centos"
fi
}
#检查ipset是否安装
check_ipset(){
if [ -f /sbin/ipset ]; then
echo -e "${Green}检测到ipset已存在,并跳过安装步骤!${Font}"
elif [ "${release}" == "centos" ]; then
yum -y install ipset
else
apt-get -y install ipset
fi
}
#开始菜单
main(){
root_need
check_release
clear
echo -e "———————————————————————————————————————"
echo -e "${Green}Linux VPS一键屏蔽指定国家所有的IP访问${Font}"
echo -e "${Green}1、封禁ip${Font}"
echo -e "${Green}2、解封iP${Font}"
echo -e "${Green}3、查看封禁列表${Font}"
echo -e "———————————————————————————————————————"
read -p "请输入数字 [1-3]:" num
case "$num" in
1)
block_ipset
;;
2)
unblock_ipset
;;
3)
block_list
;;
*)
clear
echo -e "${Green}请输入正确数字 [1-3]${Font}"
sleep 2s
main
;;
esac
}
main
下载ip网段集
http://www.ipdeny.com/ipblocks
CentOS 关闭 IPv6
第一种方法(推荐)
# 通过内核引导选项是禁用IPv6的最佳方法,需要重新引导系统。
vi /etc/default/grub
# 在 GRUB_CMDLINE_LINUX 中添加如下内容
ipv6.disable=1
# 通过如下命令创建新的GRUB配置文件并将其保存到/boot/grub2/grub.cfg
grub2-mkconfig -o /boot/grub2/grub.cfg
# grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfg
reboot
第二种方法
# 第一步 编辑网卡的配置文件:
vi /etc/sysconfig/network-scripts/ifcfg-ens160
把相关内容改成如下所示:
IPV6INIT="no"
# 第二步 修改配置文件:
vi /etc/sysctl.conf
# 添加以下内容,关闭IPv6:
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
# 第三步
vi /etc/sysconfig/network
# 添加以下内容,关闭IPv6
NETWORKING_IPV6=no
# 第四步 重启服务器
reboot
参考
https://zhuanlan.zhihu.com/p/426388054
https://cloud.tencent.com/developer/ask/238855