
简介
Event作为kubernetes的一个对象资源,记录了集群运行所遇到的各种大事件,有助于排错,但大量的事件如果都存储在etcd中,会带来较大的性能与容量压力,所以etcd中默认只保存最近1小时的。
查看Event
[root@T01 elasticsearch]# kubectl get event
LAST SEEN TYPE REASON OBJECT MESSAGE
5m16s Normal Pulled pod/nginxtest-bbccd685f-gtf9x Container image "nginx:1.10" already present on machine
5m15s Normal Created pod/nginxtest-bbccd685f-gtf9x Created container nginxtest
5m15s Normal Started pod/nginxtest-bbccd685f-gtf9x Started container nginxtest
[root@T01 elasticsearch]# kubectl get event -o wide
LAST SEEN TYPE REASON OBJECT SUBOBJECT SOURCE MESSAGE FIRST SEEN COUNT NAME
5m22s Normal Pulled pod/nginxtest-bbccd685f-gtf9x spec.containers{nginxtest} kubelet, t01 Container image "nginx:1.10" already present on machine 5h40m 5 nginxtest-bbccd685f-gtf9x.15c919914460c103
5m21s Normal Created pod/nginxtest-bbccd685f-gtf9x spec.containers{nginxtest} kubelet, t01 Created container nginxtest 5h40m 5 nginxtest-bbccd685f-gtf9x.15c9199145e21995
5m21s Normal Started pod/nginxtest-bbccd685f-gtf9x spec.containers{nginxtest} kubelet, t01 Started container nginxtest 5h40m 5 nginxtest-bbccd685f-gtf9x.15c919914bd75bfe
收集event的方案
https://github.com/heptiolabs/eventrouter
https://github.com/AliyunContainerService/kube-eventer
阿里kube-eventer
针对Kubernetes的事件监控场景,Kuernetes社区在Heapter中提供了简单的事件离线能力,后来随着Heapster的废弃,相关的能力也一起被归档了。为了弥补事件监控场景的缺失,阿里云容器服务发布并开源了kubernetes事件离线工具kube-eventer。支持离线kubernetes事件到钉钉机器人、SLS日志服务、Kafka开源消息队列、InfluxDB时序数据库等等。
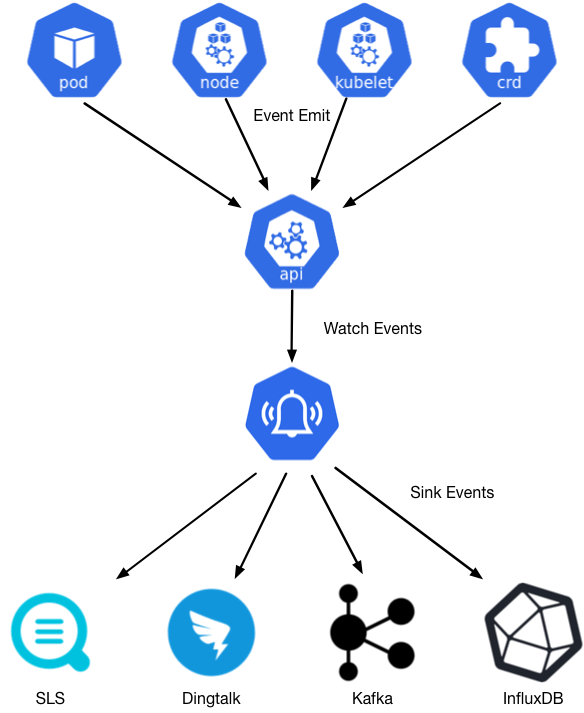
支持下列通知程序
| Sink Name | Description |
|---|---|
| dingtalk | sink to dingtalk bot |
| sls | sink to alibaba cloud sls service |
| elasticsearch | sink to elasticsearch |
| honeycomb | sink to honeycomb |
| influxdb | sink to influxdb |
| kafka | sink to kafka |
| mysql | sink to mysql database |
| sink to wechat | |
| webhook | sink to webhook |
配置文件
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: kube-eventer
name: kube-eventer
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-eventer
template:
metadata:
labels:
app: kube-eventer
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
dnsPolicy: ClusterFirstWithHostNet
serviceAccount: kube-eventer
containers:
- image: registry.aliyuncs.com/acs/kube-eventer-amd64:v1.2.0-484d9cd-aliyun
name: kube-eventer
command:
- "/kube-eventer"
- "--source=kubernetes:https://kubernetes.default"
## .e.g,dingtalk sink demo
- --sink=dingtalk:[your_webhook_url]&label=[your_cluster_id]&level=[Normal or Warning(default)]
env:
# If TZ is assigned, set the TZ value as the time zone
- name: TZ
value: "Asia/Shanghai"
volumeMounts:
- name: localtime
mountPath: /etc/localtime
readOnly: true
- name: zoneinfo
mountPath: /usr/share/zoneinfo
readOnly: true
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 250Mi
volumes:
- name: localtime
hostPath:
path: /etc/localtime
- name: zoneinfo
hostPath:
path: /usr/share/zoneinfo
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-eventer
rules:
- apiGroups:
- ""
resources:
- configmaps
- events
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-eventer
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-eventer
subjects:
- kind: ServiceAccount
name: kube-eventer
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-eventer
namespace: kube-system
Kafka sink
To use the kafka sink add the following flag:
--sink=kafka:<?<OPTIONS>>
Normally, kafka server has multi brokers, so brokers' list need be configured for producer.
So, we provide kafka brokers' list and topics about timeseries & topic in url's query string.
Options can be set in query string, like this:
brokers- Kafka's brokers' list.eventstopic- Kafka's topic for events. Default value :heapster-events.compression- Kafka's compression for both topics. Must begzipornoneorsnappyorlz4. Default value : none.user- Kafka's SASL PLAIN username. Must be set withpasswordoption.password- Kafka's SASL PLAIN password. Must be set withuseroption.cacert- Kafka's SSL Certificate Authority file path.cert- Kafka's SSL Client Certificate file path (In case of Two-way SSL). Must be set withkeyoption.key- Kafka's SSL Client Private Key file path (In case of Two-way SSL). Must be set withcertoption.insecuressl- Kafka's Ignore SSL certificate validity. Default value :false.
For example,
--sink=kafka:?brokers=localhost:9092&brokers=localhost:9093×eriestopic=testseries
or
--sink=kafka:?brokers=localhost:9092&brokers=localhost:9093&eventstopic=testtopic
Elasticsearch
To use the Elasticsearch sink add the following flag:
--sink=elasticsearch:<ES_SERVER_URL>[?<OPTIONS>]
Normally an Elasticsearch cluster has multiple nodes or a proxy, so these need
to be configured for the Elasticsearch sink. To do this, you can set
ES_SERVER_URL to a dummy value, and use the ?nodes= query value for each
additional node in the cluster. For example:
--sink=elasticsearch:?nodes=http://foo.com:9200&nodes=http://bar.com:9200
(*) Notice that using the ?nodes notation will override the ES_SERVER_URL
If you run your ElasticSearch cluster behind a loadbalancer (or otherwise do
not want to specify multiple nodes) then you can do the following:
(*) Be sure to add your version tag in your sink;
--sink=elasticsearch:http://elasticsearch.example.com:9200?sniff=false&ver=6
Besides this, the following options can be set in query string:
(*) Note that the keys are case sensitive
index- the index for metrics and events. The default isheapsteresUserName- the username if authentication is enabledesUserSecret- the password if authentication is enabledmaxRetries- the number of retries that the Elastic client will perform
for a single request after before giving up and return an error. It is0
by default, so retry is disabled by default.healthCheck- specifies if healthCheck are enabled by default. It is enabled
by default. To disable, provide a negative boolean value like0orfalse.sniff- specifies if the sniffer is enabled by default. It is enabled
by default. To disable, provide a negative boolean value like0orfalse.startupHealthcheckTimeout- the time in seconds the healthCheck waits for
a response from Elasticsearch on startup, i.e. when creating a client. The
default value is1.ver- ElasticSearch cluster version, can be either2,5,6or7. The default is5bulkWorkers- number of workers for bulk processing. Default value is5.cluster_name- cluster name for different Kubernetes clusters. Default value isdefault.pipeline- (optional; >ES5) Ingest Pipeline to process the documents. The default is disabled(empty value)
执行
kubectl apply -f kube-eventer.yaml
查看
kube-system kube-eventer-5dbc97f5b-lpl8b 1/1 Running 0
Logstash
配置 Pipelines
Logstash 高级用法Pipelines模式
作为生产者和消费者之间数据流的一个中心组件,需要一个 Logstash 实例负责驱动多个并行事件流的情况。默认情况下,这样的使用场景的配置让人并不太开心,使用者会遭遇所谓的条件地狱(Conditional hell)。因为每个单独的 Logstash 实例默认支持一个管道,该管道由一个输入、若干个过滤器和一个输出组成,如果要处理多个数据流,就要到处使用条件判断。
条件地狱(Conditional hell)
已知的在一个管道中实现多个独立流的方法是使用条件判断。主要方式是在输入部分通过标签标记事件,然后在过滤器中和输出阶段创建条件分支,对贴有不同标签的事件,应用不同的插件集。这种方式虽然可以解决问题,但在实际的使用中却非常的痛苦!下面是一个简单的 demo 片段:
input {
beats { port => 3444 tag => apache }
tcp { port => 4222 tag => firewall }
}
filter {
if "apache" in [tags] {
dissect { ... }
} else if "firewall" in [tags] {
grok { ... }
}
}
output {
if "apache" in [tags] {
elasticsearch { ... }
} else if "firewall" in [tags] {
tcp { ... }
}
}
对应的 Logstash 管道配置已经被条件语句包裹的十分臃肿,而它们的唯一目的是保持流的独立性。
虽然使用条件实现独立的多个流是可行的,但是很容易看出,由于存在单个管道和处理的单个阶段,随着复杂性的增加,配置会变得非常冗长,很难管理。下图展示了包含两个流的简单管道:
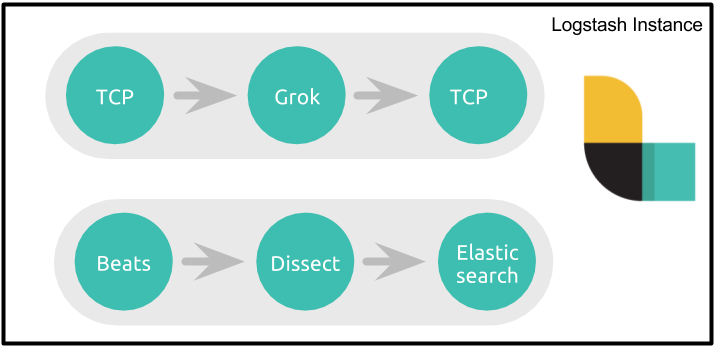
不幸的是,这并不是该方案的唯一缺陷。
缺乏拥塞隔离
如果您熟悉 Logstash 的工作原理,就会知道管道的输出部分接收到一批事件,并且在所有事件和完成所有输出之前不会移动到下一批事件。这意味着,对于上面的管道,如果 TCP 套接字目标不可达,Logstash将不会处理其他批次的事件,这也就意味着 Elasticsearch 将不会接收事件,并且会对 TCP 输入和 Beats 输入施加反压力。
不同的数据流需要以不同的方式处理
如果 TCP - > Grok - > TCP 数据流处理大量的小数据,而 Beats -> Dissect -> ES 数据流中的单个数据体积大但是数量少。那么前一个数据流希望有多个 worker 并行并其每一批次处理更多事件,第二个数据流则期望使用少量的 worker 和每批次处理少量的事件。使用单个管道,无法为单个数据流指定独立的管道配置。
通过多个 Logstash 实例解决问题
上述问题可以通过在同一台机器上运行多个 Logstash 实例来解决,然后可以独立地管理这些实例。但是即使这样的解决方案也会产生其他问题:
- 需要管理多个实例(通过 init 系统管理多个后台服务)
- 每个 Logstash 的实例也意味着一个独立的 JVM
- 需要监视每个 Logstash 实例
这种方式其实很糟糕!
多个管道
从 Logstash 6.0 开始,引入了 Multiple Pipelines,才完美的解决了这个问题。Multiple Pipelines 的配置非常简单:在配置文件 pipelines.yml 中添加新的 pipeline 配置并指定其配置文件就可以了。下面是一个简单的 demo 配置:
- pipeline.id: apache
pipeline.batch.size: 125
queue.type: persisted
path.config: "/path/to/config/apache.cfg"
queue.page_capacity: 50mb
- pipeline.id: test
pipeline.batch.size: 2
pipeline.batch.delay: 1
queue.type: memory
config.string: "input { tcp { port => 3333 } } output { stdout {} }"
这个 YAML 文件包含一个散列(或字典)列表,其中每个散列表示一个管道,键和值为该管道设置名称。被省略的设置值返回到它们的默认值。
配置多个管道
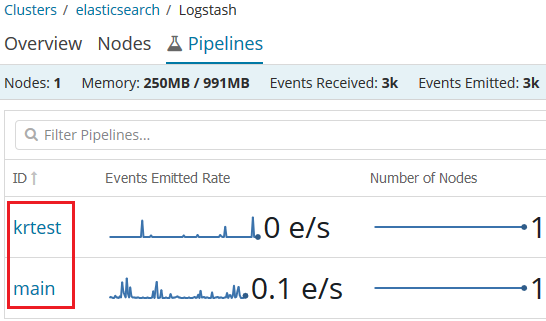
下面来看一个真实点的例子,笔者在 Ubuntu 18.04 Server 中安装了 Logstash 6.2.4,除了在默认的配置文件目录(/etc/logstash/conf.d)中添加配置文件外,创建新的目录 /etc/logstash/myconf.d,并在 /etc/logstash/myconf.d 目录下创建 Logstash 配置文件 krtest.conf。然后在 /etc/logstash/pipelines.yml 文件中添加新的 pipeline 配置:
- pipeline.id: main
path.config: "/etc/logstash/conf.d/*.conf"
- pipeline.id: krtest
path.config: "/etc/logstash/myconf.d/krtest.conf"
其中 pipeline.id 为 main 的管道是默认的配置,我们新添加了 id 为 krtest 的管道并指定了对应的配置文件路径。启动 Logstash,如果你安装的 X-Pack 插件就可以在 Kibana->Monitoring->Logstash 中看到新添加的名称为 krtest 的管道:
使用 Multiple Pipelines 后,我们的 Logstash 配置文件就可以写得像下面的代码一样简练(不再需要那么多的条件语句)了:
input {
beats {
port => 5064
}
}
filter {
grok { ... }
}
output {
elasticsearch { ... }
}
注意:当我们配置pipelines.yml后,我们启动不需要再指定配置文件!