Kubeadm 添加新 Master 节点失败错误
Kubeadm 添加新 Master 节点到集群出现 ETCD 健康检查失败错误
系统环境
Docker 版本:18.06.3
Kubeadm 版本:1.17.4
Kubernetes 版本:1.17.4
Kubernetes Master 数量:3
Kubernetes 安装方式:Kubeadm
问题描述
Kubernetes 集群中总共有三台 Master,分别是:
k8s-master-2-11、k8s-master-2-12、k8s-master-2-13
对其中 k8s-master-2-11 Master 节点服务器进行了内核和软件升级操作,从而先将其暂时剔出集群,然后进行升级,完成后准备重新加入到 Kubernetes 集群,通过 Kubeadm 执行,输入下面命令:
--token 6w0nwi.zag57qgfcdhi76vd \
--discovery-token-ca-cert-hash sha256:efa49231e4ffd836ff996921741c98ac4c5655dc729d7c32aa48c608232f0f08 \
--control-plane --certificate-key a64e9da7346153bd64dba1e5126a644a97fdb63c878bb73de07911d1add8e26b
在执行过程中,输出下面日志,提示 etcd 监控检查失败:
......
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W0329 00:01:51.364121 19209 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"
W0329 00:01:51.373807 19209 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[check-etcd] Checking that the etcd cluster is healthy
error execution phase check-etcd: etcd cluster is not healthy: failed to dial endpoint https://10.8.18.105:2379
with maintenance client: context deadline exceeded
To see the stack trace of this error execute with --v=5 or higher
根据关键信息 "error execution phase check-etcd" 可知,可能是在执行加入 etcd 时候出现的错误,导致 master 无法加入原先的 kubernetes 集群。
分析问题
查看集群节点列表
$ kubectl get node
NAME STATUS ROLES VERSION
k8s-master-2-12 Ready master v1.17.4
k8s-master-2-13 Ready master v1.17.4
k8s-node-2-14 Ready <none> v1.17.4
k8s-node-2-15 Ready <none> v1.17.4
k8s-node-2-16 Ready <none> v1.17.4
可以看到,k8s-master-2-11 节点确实不在节点列表中
查看 Kubeadm 配置信息
在看看 Kubernetes 集群中的 kubeadm 配置信息:
$ kubectl describe configmaps kubeadm-config -n kube-system
获取到的内容如下:
Name: kubeadm-config
Namespace: kube-system
Labels: <none>
Annotations: <none>
...
ClusterStatus:
----
apiEndpoints:
k8s-master-2-11:
advertiseAddress: 192.168.2.11
bindPort: 6443
k8s-master-2-12:
advertiseAddress: 192.168.2.12
bindPort: 6443
k8s-master-2-13:
advertiseAddress: 192.168.2.13
bindPort: 6443
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterStatus
可也看到 k8s-master-2-11 节点信息还存在与 kubeadm 配置中,说明 etcd 中还存储着 k8s-master-2-11 相关信息。
分析问题所在及解决方案
因为集群是通过 kubeadm 工具搭建的,且使用了 etcd 镜像方式与 master 节点一起,所以每个 Master 节点上都会存在一个 etcd 容器实例。当剔除一个 master 节点时 etcd 集群未删除剔除的节点的 etcd 成员信息,该信息还存在 etcd 集群列表中。
所以,我们需要 进入 etcd 手动删除 etcd 成员信息。
解决
获取 Etcd 镜像列表
$ kubectl get pods -n kube-system | grep etcd
etcd-k8s-master-2-12 1/1 Running 0
etcd-k8s-master-2-13 1/1 Running 0
进入 Etcd 容器并删除节点信息
选择上面两个 etcd 中任意一个 pod,通过 kubectl 工具进入 pod 内部:
$ kubectl exec -it etcd-k8s-master-2-12 sh -n kube-system
进入容器后,按下面步执行
# 配置环境
$ export ETCDCTL_API=3
$ alias etcdctl='etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key'
# 查看 etcd 集群成员列表
$ etcdctl member list
63bfe05c4646fb08, started, k8s-master-2-11, https://192.168.2.11:2380, https://192.168.2.11:2379, false
8e41efd8164c6e3d, started, k8s-master-2-12, https://192.168.2.12:2380, https://192.168.2.12:2379, false
a61d0bd53c1cbcb6, started, k8s-master-2-13, https://192.168.2.13:2380, https://192.168.2.13:2379, false
# 删除 etcd 集群成员 k8s-master-2-11
$ etcdctl member remove 63bfe05c4646fb08
Member 63bfe05c4646fb08 removed from cluster ed984b9o8w35cap2
# 再次查看 etcd 集群成员列表
$ etcdctl member list
8e41efd8164c6e3d, started, k8s-master-2-12, https://192.168.2.12:2380, https://192.168.2.12:2379, false
a61d0bd53c1cbcb6, started, k8s-master-2-13, https://192.168.2.13:2380, https://192.168.2.13:2379, false
# 退出容器
$ exit
通过 kubeadm 命令再次尝试加入集群
通过 kubeadm 命令再次尝试将 k8s-master-2-11 节点加入集群,在执行前首先进入到 k8s-master-2-11 节点服务器,执行 kubeadm 的清除命令:
$ kubeadm reset
然后尝试加入 kubernetes 集群:
$ kubeadm join mydlq.club:16443 \
--token 6w0nwi.zag57qgfcdhi76vd \
--discovery-token-ca-cert-hash sha256:efa49231e4ffd836ff996921741c98ac4c5655dc729d7c32aa48c608232f0f08 \
--control-plane --certificate-key a64e9da7346153bd64dba1e5126a644a97fdb63c878bb73de07911d1add8e26b
kubernetes coredns域名解析5秒记录
前言
近期线上 k8s 时不时就会出现一些内部服务间的调用超时问题,通过日志可以得知超时的原因都是出现在域名解析上,并且都是 k8s 内部的域名解析超时,于是直接先将内部域名替换成 k8s service 的 IP,观察一段时间发现没有超时的情况发生了,但是由于使用 service IP 不是长久之计,所以还要去找解决办法。
定位
一开始运维同事在调用方 pod 中使用ab工具对目标服务进行了多次压测,并没有发现有超时的请求,我介入之后分析ab这类 http 压测工具应该都会有 dns 缓存,而我们主要是要测试 dns 服务的性能,于是直接动手撸了一个压测工具只做域名解析,代码如下:
package main
import (
"context"
"flag"
"fmt"
"net"
"sync/atomic"
"time"
)
var host string
var connections int
var duration int64
var limit int64
var timeoutCount int64
func main() {
// os.Args = append(os.Args, "-host", "www.baidu.com", "-c", "200", "-d", "30", "-l", "5000")
flag.StringVar(&host, "host", "", "Resolve host")
flag.IntVar(&connections, "c", 100, "Connections")
flag.Int64Var(&duration, "d", 0, "Duration(s)")
flag.Int64Var(&limit, "l", 0, "Limit(ms)")
flag.Parse()
var count int64 = 0
var errCount int64 = 0
pool := make(chan interface{}, connections)
exit := make(chan bool)
var (
min int64 = 0
max int64 = 0
sum int64 = 0
)
go func() {
time.Sleep(time.Second * time.Duration(duration))
exit <- true
}()
endD:
for {
select {
case pool <- nil:
go func() {
defer func() {
<-pool
}()
resolver := &net.Resolver{}
now := time.Now()
_, err := resolver.LookupIPAddr(context.Background(), host)
use := time.Since(now).Nanoseconds() / int64(time.Millisecond)
if min == 0 || use < min {
min = use
}
if use > max {
max = use
}
sum += use
if limit > 0 && use >= limit {
timeoutCount++
}
atomic.AddInt64(&count, 1)
if err != nil {
fmt.Println(err.Error())
atomic.AddInt64(&errCount, 1)
}
}()
case <-exit:
break endD
}
}
fmt.Printf("request count:%d\nerror count:%d\n", count, errCount)
fmt.Printf("request time:min(%dms) max(%dms) avg(%dms) timeout(%dn)\n", min, max, sum/count, timeoutCount)
}
编译好二进制程序直接丢到对应的 pod 容器中进行压测:
# 200个并发,持续30秒
$ ./ab-dns -host {service}.{namespace} -c 200 -d 30
这次可以发现最大耗时有5s多,多次测试结果都是类似:
# ./ab-dns -host s-inno-bpm.inno-ci -c 200 -d 30
request count:109061
error count:0
request time:min(1ms) max(5082ms) avg(53ms) timeout(0n)
而我们内部服务间 HTTP 调用的超时一般都是设置在3s左右,以此推断出与线上的超时情况应该是同一种情况,在并发高的情况下会出现部分域名解析超时而导致 HTTP 请求失败。
原因
起初一直以为是 coredns 的问题,于是找运维升级了下 coredns 版本再进行压测,发现问题还是存在,说明不是版本的问题,难道是 coredns 本身的性能就差导致的?想想也不太可能啊,才 200 的并发就顶不住了那性能也未免太弱了吧,结合之前的压测数据,平均响应都挺正常的(53ms),但是就有个别请求会延迟,而且都是 5 秒左右,所以就又带着k8s dns 5s的关键字去 google 搜了一下,这不搜不知道一搜吓一跳啊,原来是 k8s 里的一个大坑啊(其实和 k8s 没有太大的关系,只是 k8s 层面没有提供解决方案)。
5s 超时原因
linux 中 glibc 的 resolver 的缺省超时时间是 5s,而导致超时的原因是内核 conntrack 模块的 bug。
DNS client (glibc 或 musl libc) 会并发请求 A 和 AAAA 记录,跟 DNS Server 通信自然会先 connect (建立 fd),后面请求报文使用这个 fd 来发送,由于 UDP 是无状态协议, connect 时并不会发包,也就不会创建 conntrack 表项, 而并发请求的 A 和 AAAA 记录默认使用同一个 fd 发包,send 时各自发的包它们源 Port 相同(因为用的同一个 socket 发送),当并发发包时,两个包都还没有被插入 conntrack 表项,所以 netfilter 会为它们分别创建 conntrack 表项,而集群内请求 kube-dns 或 coredns 都是访问的 CLUSTER-IP,报文最终会被 DNAT 成一个 endpoint 的 POD IP,当两个包恰好又被 DNAT 成同一个 POD IP 时,它们的五元组就相同了,在最终插入的时候后面那个包就会被丢掉,如果 dns 的 pod 副本只有一个实例的情况就很容易发生(始终被 DNAT 成同一个 POD IP),现象就是 dns 请求超时,client 默认策略是等待 5s 自动重试,如果重试成功,我们看到的现象就是 dns 请求有 5s 的延时。
解决方案
方案(一):使用 TCP 协议发送 DNS 请求
通过 resolv.conf 的 use-vc 选项来开启 TCP 协议, 修改 /etc/resolv.conf 文件,在最后加入一行文本
nameserver ...
search ...
options ndots:5 use-vc
经过测试,确实没有出现 5s 的超时问题了,但是部分请求耗时还是比较高,在 4s 左右,而且平均耗时比 UPD 协议的还高,效果并不好。
resolv.conf 配置
search domain1 domain2 baidu.com
该选项可以用来指定多个域名,中间用空格或tab键隔开。其作用是当访问的域名不能被DNS解析时,resolver会将该域名加上search指定的参数,重新请求DNS,直到被正确解析或试完search指定的域名列表为止。
options
用于配置resolver的内置变量,不是resolv.conf的常见配置。语法格式如下:
ndots:[n]:设置调用res_query()解析域名时域名至少包含的点的数量
timeout:[n]:设置等待dns服务器返回的超时时间,单位秒。默认值RES_TIMEOUT=5,参见<resolv.h>
attempts:[n]:设置resolver向DNS服务器发起域名解析的请求次数。默认值RES_DFLRETRY=2,参见<resolv.h>
rotate:在_res.options中设置RES_ROTATE,采用轮询方式访问nameserver,实现负载均衡
no-check-names:在_res.options中设置RES_NOCHECKNAME,禁止对传入的主机名和邮件地址进行无效字符检查,比如下划线(_),非ASCII字符或控制字符
ndots:5 实例解析
nameserver 10.254.0.2
search default.svc.c1.ichenfu.com svc.c1.ichenfu.com c1.ichenfu.com localdomain
options ndots:5
所有查询中,如果.的个数少于5个,则会根据 search 中配置的列表依次在对应域中先进行搜索,如果没有返回,则最后再直接查询域名本身。
所以针对login.example.com的情况是
先查询
login.example.com.default.svc.c1.ichenfu.com
再查询
login.example.com.svc.c1.ichenfu.com
再查询
login.example.com.c1.ichenfu.com
然后
login.example.com.localdomain
如果上面列表都没有解析返回,则最后再查询
login.example.com
很显然,正常情况下,经过4次多余的查询之后,最终也会获得正确的结果,但是针对这次的情况,由于配置出问题,导致在第一次查询的时候,login.example.com.default.svc.c1.ichenfu.com这个域名并不在coredns所配置的cluster.local和c2.ichenfu.com域中,直接转发到本地DNS,走正常的递归查询逻辑,而最终命中*.ichenfu.com这条规则。
方案(二):避免相同五元组 DNS 请求的并发
通过 resolv.conf 的 single-request-reopen 和 single-request 选项来避免:
- single-request-reopen (glibc>=2.9) 发送 A 类型请求和 AAAA 类型请求使用不同的源端口。这样两个请求在 conntrack 表中不占用同一个表项,从而避免冲突。
- single-request (glibc>=2.10) 避免并发,改为串行发送 A 类型和 AAAA 类型请求,没有了并发,从而也避免了冲突。
修改 /etc/resolv.conf 文件,在最后加入一行文本:
nameserver ...
search ...
options ndots:5 timeout:2 single-request-reopen
通过压测结果可以看到 single-request-reopen 和 single-request 选项确实可以显著的降低域名解析耗时。
关于方案(一)和方案(二)的实施步骤和缺点
其实就是要给容器的 /etc/resolv.conf 文件添加选项,目前有两个方案比较合适:
通过修改 pod 的 postStart hook 来设置
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -c
- "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf"
通过修改 pod 的 template.spec.dnsConfig 来设置
template:
spec:
dnsConfig:
options:
- name: single-request-reopen
注: 需要 k8s 版本>=1.9
缺点
不支持 alpine 基础镜像的容器,因为 apline 底层使用的 musl libc 库并不支持这些 resolv.conf 选项,所以如果使用 alpine 基础镜像构建的应用,还是无法规避超时的问题。
方案(三):本地 DNS 缓存
其实 k8s 官方也意识到了这个问题比较常见,给出了 coredns 以 cache 模式作为 daemonset 部署的解决方案: https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns/nodelocaldns

大概原理就是:
本地 DNS 缓存以 DaemonSet 方式在每个节点部署一个使用 hostNetwork 的 Pod,创建一个网卡绑上本地 DNS 的 IP,本机的 Pod 的 DNS 请求路由到本地 DNS,然后取缓存或者继续使用 TCP 请求上游集群 DNS 解析 (由于使用 TCP,同一个 socket 只会做一遍三次握手,不存在并发创建 conntrack 表项,也就不会有 conntrack 冲突)
通过在集群节点上以 Daemonset 的形式运行 NodeLocal DNS Cache,能够大幅提升集群内 DNS 解析性能,以及有效避免 conntrack 冲突引发的 DNS 五秒延迟。
部署
获取当前 kube-dns service 的 clusterIP
$ kubectl -n kube-system get svc kube-dns -o jsonpath="{.spec.clusterIP}"
10.96.0.10
下载官方提供的 yaml 模板进行关键字替换
$ wget -O nodelocaldns.yaml "https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml" && \
$ sed -i 's/__PILLAR__DNS__SERVER__/10.96.0.10/g' nodelocaldns.yaml && \
$ sed -i 's/__PILLAR__LOCAL__DNS__/169.254.20.10/g' nodelocaldns.yaml && \
$ sed -i 's/__PILLAR__DNS__DOMAIN__/cluster.local/g' nodelocaldns.yaml && \
$ sed -i 's/__PILLAR__CLUSTER__DNS__/10.96.0.10/g' nodelocaldns.yaml && \
$ sed -i 's/__PILLAR__UPSTREAM__SERVERS__/\/etc\/resolv.conf/g' nodelocaldns.yaml
最终 yaml 文件如下:
https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: node-local-dns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns-upstream
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "KubeDNSUpstream"
spec:
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
selector:
k8s-app: kube-dns
---
apiVersion: v1
kind: ConfigMap
metadata:
name: node-local-dns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
Corefile: |
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.20.10 10.96.0.10
forward . 10.96.0.10 {
force_tcp
}
prometheus :9253
health 169.254.20.10:8080
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.96.0.10
forward . 10.96.0.10 {
force_tcp
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.96.0.10
forward . 10.96.0.10 {
force_tcp
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.96.0.10
forward . /etc/resolv.conf {
force_tcp
}
prometheus :9253
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-local-dns
namespace: kube-system
labels:
k8s-app: node-local-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
updateStrategy:
rollingUpdate:
maxUnavailable: 10%
selector:
matchLabels:
k8s-app: node-local-dns
template:
metadata:
labels:
k8s-app: node-local-dns
spec:
priorityClassName: system-node-critical
serviceAccountName: node-local-dns
hostNetwork: true
dnsPolicy: Default # Don't use cluster DNS.
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
containers:
- name: node-cache
image: k8s.gcr.io/k8s-dns-node-cache:1.15.7
resources:
requests:
cpu: 25m
memory: 5Mi
args:
[
"-localip",
"169.254.20.10,10.96.0.10",
"-conf",
"/etc/Corefile",
"-upstreamsvc",
"kube-dns-upstream",
]
securityContext:
privileged: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9253
name: metrics
protocol: TCP
livenessProbe:
httpGet:
host: 169.254.20.10
path: /health
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 5
volumeMounts:
- mountPath: /run/xtables.lock
name: xtables-lock
readOnly: false
- name: config-volume
mountPath: /etc/coredns
- name: kube-dns-config
mountPath: /etc/kube-dns
volumes:
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
- name: kube-dns-config
configMap:
name: kube-dns
optional: true
- name: config-volume
configMap:
name: node-local-dns
items:
- key: Corefile
path: Corefile.base
通过 yaml 可以看到几个细节:
- 部署类型是使用的 DaemonSet,即在每个 k8s node 节点上运行一个 dns 服务
- hostNetwork 属性为 true,即直接使用 node 物理机的网卡进行端口绑定,这样在此 node 节点中的 pod 可以直接访问 dns 服务,不通过 service 进行转发,也就不会有 DNAT
- dnsPolicy 属性为 Default,不使用 cluster DNS,在解析外网域名时直接使用本地的 DNS 设置
- 绑定在 node 节点 169.254.20.10 和 10.96.0.10 IP 上,这样节点下面的 pod 只需要将 dns 设置为169.254.20.10 即可直接访问宿主机上的 dns 服务。
实施
通过修改 pod 的 template.spec.dnsConfig 来设置,并将 dnsPolicy 设置为 None
template:
spec:
dnsConfig:
nameservers:
- 169.254.20.10
searches:
- public.svc.cluster.local
- svc.cluster.local
- cluster.local
options:
- name: ndots
value: "5"
dnsPolicy: None
修改默认的 cluster-dns,在 node 节点上将 /etc/systemd/system/kubelet.service.d/10-kubeadm.conf 文件中的 --cluster-dns 参数值修改为 169.254.20.10,然后重启 kubelet。
systemctl restart kubelet
相关结论
其中一个patch已经在2018-7-18被合并到linux内核主线中: netfilter: nf_conntrack: resolve clash for matching conntracks
目前只有4.19.rc 版本包含这个patch。
只有多个线程或进程,并发从同一个socket发送相同五元组的UDP报文时,才有一定概率会发生 - glibc, musl(alpine linux的libc库)都使用"parallel query", 就是并发发出多个查询请求,因此很容易碰到这样的冲突,造成查询请求被丢弃 - 由于ipvs也使用了conntrack, 使用kube-proxy的ipvs模式,并不能避免这个问题
为什么在节点出现故障时重新调度 Pod 需要 5 分钟以上?
这是由于以下默认 Kubernetes 设置的组合:
kubelet
node-status-update-frequency:指定 kubelet 将节点状态发布到 master 的频率(默认为 10 秒)
kube-controller-manager
node-monitor-period:在 NodeController 中同步 NodeStatus 的时间段(默认 5 秒)
node-monitor-grace-period:在标记运行节点不健康之前允许运行节点无响应的时间(默认为 40 秒)
pod-eviction-timeout:删除失败节点上的 Pod 的宽限期(默认为 5m0)
K8S常见异常事件与解决方案
集群相关
Coredns容器或local-dns容器重启
集群中的coredns组件发生重启(重新创建),一般是由于coredns组件压力较大导致oom,请检查业务是否异常,是否存在应用容器无法解析域名的异常。
如果是local-dns重启,说明local-dns的性能也不够了,需要优化
Pod was OOM killed
云应用容器实例发生OOM,请检查云应用是否正常。一般地,如果云应用配置了健康检查,当进程OOM了,健康检查如果失败,集群会自动重启容器。
OOM问题排查步骤:
检查应用进程内存配置,如Java的jvm参数,对比应用监控-基础监控中的内存指标,判断是否是参数设置低导致进程内存不够用,适当进行参数优化
Out of memory: Kill process
原因描述:
一般是操作系统把容器内进程Kill而导致的系统内核事件。比如一个java应用,当实际占用内存超过堆内存配置大小时,就会出现OOM错误。发生进程被Kill之后,容器依旧是存活状态,容器的健康检查还会继续进行。所以后面通常会伴随出现健康检查失败的错误。
解决方案:
要具体分析进程被Kill的原因,适当的调整进程内存的限制值。可以结合应用监控来参考进程内存的变化趋势。
Memory cgroup out of memory: Kill process
原因描述:
一般是由于容器的内存实际使用量超过了容器内存限制值而导致的事件。比如容器的内存限制值配置了1Gi,而容器的内存随着容器内进程内存使用量的增加超过了1Gi,就会导致容器被操作系统Cgroup Kill。发生容器被Kill之后,容器已经被停止,所以后续会出现应用实例被重启的情况。
解决方案:
检查容器内进程是否有内存泄漏问题,同时适当调整容器内存的限制值大小。可以结合应用监控来看变化趋势。需要注意的是,容器内存限制值大小不应该过大,否则可能导致极端资源争抢情况下,容器被迫驱逐的问题。
System OOM encountered
原因描述:
上述两种OOM(进程OOM,容器OOM)发生后,都可能会伴随一个系统OOM事件,该事件的原因是由上述OOM事件伴随导致。
解决方案:
需要解决上面进程OOM或者容器CgroupOOM的问题。
failed to garbage collect required amount of images
原因描述:
当容器集群中的节点(宿主机)磁盘使用率达到85%之后,会触发自动的容器镜像回收策略,以便于释放足够的宿主机磁盘。该事件发生于当触发镜像回收策略之后,磁盘空间仍然不足以达到健康阈值(默认为80%)。通常该错误是由于宿主机磁盘被占用太多导致。当磁盘空间占用率持续增长(超过90%),会导致该节点上的所有容器被驱逐,也就是当前节点由于磁盘压力不再对外提供服务,直到磁盘空间释放。
解决方案:
检查节点的磁盘分配情况,通常有以下一些常见情况导致磁盘占用率过高:
- 有大量日志在磁盘上没有清理;请清理日志。
- 有进程在宿主机不停的写文件;请控制文件大小,将文件存储至OSS或者NAS。
- 下载的或者是其他的静态资源文件占用空间过大;静态资源请存储至OSS或CDN。
Attempting to xxxx
节点资源不足(EvictionThresholdMet),一般是节点资源将要达到阈值,可能会触发Pod驱逐。如 Attempting to reclaim ephemeral-storage
原因描述:
ephemeral storage是临时存储空间,当磁盘空间使用率达到阈值,会触发临时存储空间的回收任务。回收任务会尝试回收系统日志,以及没有正在使用的镜像缓存等数据。当磁盘空间占用率持续增长(超过90%),会导致该节点上的所有容器被驱逐,也就是当前节点由于磁盘压力不再对外提供服务,直到磁盘空间释放。
解决方案:
请注意磁盘空间的使用:
避免使用“空目录”类型的挂载方式;使用NAS或者其他类似方式替代。
尽量避免使用“宿主机目录”类型的挂载方式,以便于保证容器是无状态的,可以迁移的。
要注意避免在容器内大量写文件,而导致容器运行时可写数据层过大(imagefs)。
NTP service is not running
原因描述:
NTP service是系统时间校准服务,由操作系统systemd管理的服务。可以通过 systemctl status chronyd 查看对应服务的状态。
解决方案:
使用命令systemctl start chronyd尝试重新启动。也可以通过命令 journalctl -u chronyd 查看服务的日志。
节点PLEG异常
原因描述:
PLEG是pod生命周期事件生成器,会记录Pod生命周期中的各种事件,如容器的启动、终止等。一般是由于节点上的daemon进程异常或者节点systemd版本bug导致。出现该问题会导致集群节点不可用
解决方案:
可以尝试重启kubelet;再尝试重启Docker进程。重启这两个进程过程中,不会对已运行容器造成影响
//重启kubelet
systemctl restart kubelet
//重启docker
systemctl restart docker
//查看docker日志
journalctl -xeu docker > docker.log
如果是由于systemd版本问题导致,重启节点可短暂修复,彻底解决的话需要升级节点的systemd
systemd: (rpm -qa | grep systemd, 版本<219-67.el7需要升级)
升级systemd指令:
yum update -y systemd && systemctl daemon-reexec && killall runc
节点PID不足
原因描述:
暂无
解决方案:
节点FD不足
原因描述:
节点文件句柄使用数量超过80%,具体原因与节点上进程使用情况相关
- 打开文件未释放
- 打开管道未释放
- 建立网络连接未释放(pipe,eventpoll多出现在 NIO 网络编程未释放资源 —— selector.close())
- 创建进程调用命令未释放(Runtime.exe(…) 得到的 Process, InputStream, OutputStream 未关闭,这也会导致 pipe,eventpoll 未释放)
解决方案:
删除不需要的文件,调整应用代码,文件流等操作结束后记得关闭。或者尝试先排空再重启主机
节点Docker Hung
原因描述:
节点docker daemon异常,导致集群无法与之通信,伴随有docker ps、docker exec等命令hung住或异常失败
解决方案:
尝试重启docker服务,重启过程不会影响已存在容器的运行
//重启节点上的docker daemon,对运行中容器没有影响
systemctl restart docker
//查看docker日志
journalctl -xeu docker > docker.log
如果docker服务重启后依然无法解决,可以尝试重启主机。主机重启过程会对容器有影响,谨慎操作。
节点磁盘资源不足 InvalidDiskCapacity
原因描述:
节点磁盘不足,无法分配空间给容器镜像
解决方案:
检查节点的磁盘分配情况,通常有以下一些常见情况导致磁盘占用率过高:
有大量日志在磁盘上没有清理;请清理日志。
有进程在宿主机不停的写文件;请控制文件大小,将文件存储至OSS或者NAS。
下载的或者是其他的静态资源文件占用空间过大;静态资源请存储至OSS或CDN。
应用相关
Container Restart
原因描述:
该事件表示应用实例(重启)重启,一般是由于配置了健康检查且健康检查失败导致,会伴随有Readiness probe failed和Liveness probe failed等事件。健康检查失败的原因有很多,通常情况下,比如进程OOM被Kill、比如高负载情况下应用无法正常响应(例如RDS瓶颈导致应用线程全部hang住),都可能会导致健康检查失败
解决方案:
需要结合临近的相关事件定位具体的Pod重启原因。如伴随有集群相关的Out of memory事件,参考此文档上面Out of memory事件的解决方案;其他情况下,结合应用监控或者云产品自身监控来定位问题
The node had condition: [XXX]
原因描述:
该事件表示Pod由于节点上的异常情况被驱逐,比如The node had condition: [DiskPressure],表示节点磁盘使用率比较高,通常会伴随有 failed to garbage collect required amount of images 和 Attempting to reclaim ephemeral-storage 等集群维度(节点)的异常事件
解决方案:
需要结合临近的相关事件定位具体的驱逐原因。对于已经被驱逐的Pod实例,可以通过kubectl get po 进行查看和手动清理
K8S Pod Pending
原因描述:
该事件表示集群调度Pod被挂起,一般是由于节点资源不足以调度容器或者Volume挂载失败(比如持久化存储卷找不到)或者其他原因导致。
解决方案:
需要结合临近的相关事件定位具体的Pod挂起原因
Readiness probe failed
原因描述:
由于应用就绪探针失败而引发的异常事件。应用就绪探针失败会导致相应容器的流量被摘除,例如被动从SLB摘掉该容器的流量入口。
解决方案
需要结合应用就绪探针的配置,定位应用就绪探针失败的原因。
Liveness probe failed
原因描述:
由于应用存活探针失败而引发的异常事件。该事件可能会导致后续达到一定阈值之后,容器被动重启。具体要看应用就绪探针的配置。
解决方案:
需要结合应用存活探针的配置,定位探针检查失败的原因。
Container runtime did not kill the pod within specified grace period.
原因描述:
此事件表示容器没有在优雅下线的时间段内正常退出。比如如果配置了优雅下线脚本,脚本执行时长需要60s,而优雅下线时间(默认为30s)配置为30s。就会在容器下线期间触发这个事件。
解决方案:
调整优雅下线探针的配置,或者优雅下线时间的配置。
Back-off restarting failed container
原因描述:
此事件表示容器启动失败,而被再次拉起尝试启动。通常常见与应用发布过程中的容器启动失败。具体的原因常见为镜像拉取失败,或者容器启动失败(容器没有打到running状态)。
解决方案:
需要在发布页查看容器启动日志或者调度日志,进一步定位容器启动失败的原因。
The node was low on resource: xxxx
示例
2020-07-21 10:24:43.000 [Event] Type: Warning, Reason: Evicted, Message: The node was low on resource: ephemeral-storage.
原因描述:
该事件表示Pod由于节点上的异常情况(资源不足)被驱逐
解决方案:
需要看具体哪类资源不足,例如示例中的ephemeral-storage,表示集群节点临时存储空间不足,一般是由于磁盘使用量较大导致。请参考文档上方解决方案
检查节点的磁盘分配情况,通常有以下一些常见情况导致磁盘占用率过高:
- 有大量日志在磁盘上没有清理;请清理日志。
- 有进程在宿主机不停的写文件;请控制文件大小,将文件存储至OSS或者NAS。
- 下载的或者是其他的静态资源文件占用空间过大;静态资源请存储至OSS或CDN。
可以对系统盘进行扩容,扩大磁盘空间。
集群DNS性能瓶颈
背景
集群中的容器实例,DNS解析均依赖集群内的DNS组件,应用中业务请求的地址都需要经过集群DNS组件。例如,代码中访问RDS、REDIS、TOP api等。如果集群dns性能不足,会出现业务请求失败的问题。
集群DNS组件:
默认已安装的集群组件为coredns,副本数为2
可选的高性能组件为localdns
是否有性能瓶颈
应用有大量DNS请求的场景(比如连接rds,凡是涉及到域名地址解析的)
PHP等语言自身没有连接池特性的,或者应用自身没有DNS缓存的
偶尔出现域名地址无法解析错误的
解决方案
一、集群默认已安装的coredns组件,进行扩容。扩容比例为1/5的节点数(如15台ecs,那么coredns数量为3)
二、为集群安装更高性能的localdns组件(该组件为daemonset,会在每个ECS节点起一个本地缓存)
一般来说,如果业务量小,扩容下coredns就足够了;如果业务量大(域名地址解析QPS高,比如访问RDS),特别是php等不带连接池的开发语言,建议直接上localdns。如果是java等配置了连接池的应用,可以先扩容coredns观察,如果仍然有解析问题,再上localdns。
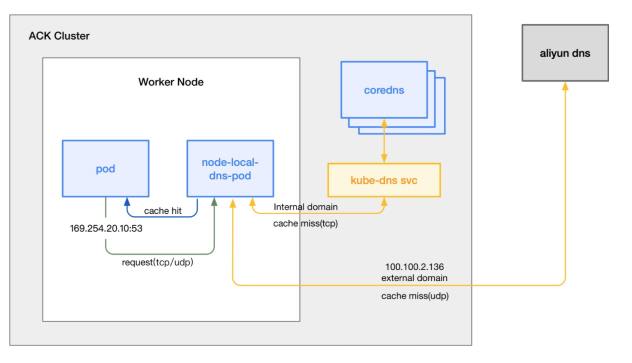
localdns缓存原理
NodeLocalDNS 是一个 DaemonSet,会在Kubernetes集群的每个节点上运行一个专门处理 DNS 查询请求的 Pod,该 Pod 会将集群内部域名查询请求发往 CoreDNS;将集群外部请求直接发往外部域名解析服务器。同时能够Cache所有请求。可以被看作是节点级别的高效DNS 缓存,能够大幅提高集群整体 DNS 查询的 QPS。NodeLocalDNS 会在集群的每个节点上创建一个专用的虚拟接口(接口绑定的 IP 需要通过 local_dns_ip 这个值来指定),节点上所有发往该 IP 的 DNS 查询请求都会被拦截到 NodeLocalDNS Pod 内进行处理;通过集群原有的 kube-dns 服务(该服务的 clusterIP 值需要通过kube_dns_ip来指定)来与CoreDNS进行通信。