
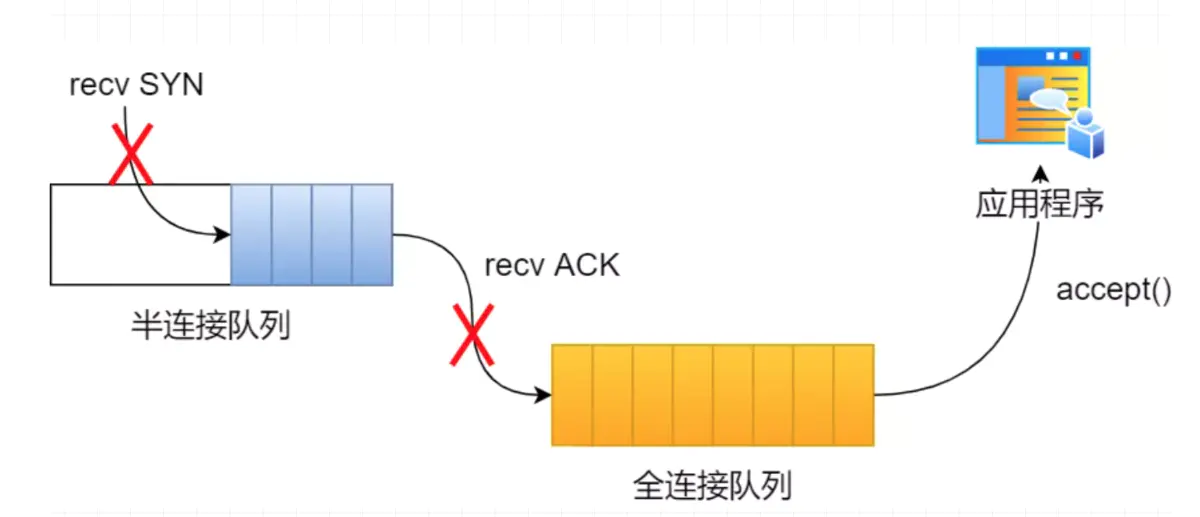
TCP 半连接队列和全连接队列
什么是 TCP 半连接队列和全连接队列?
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:
- 半连接队列,也称 SYN 队列;
- 全连接队列,也称 accepet 队列;
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应 SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。
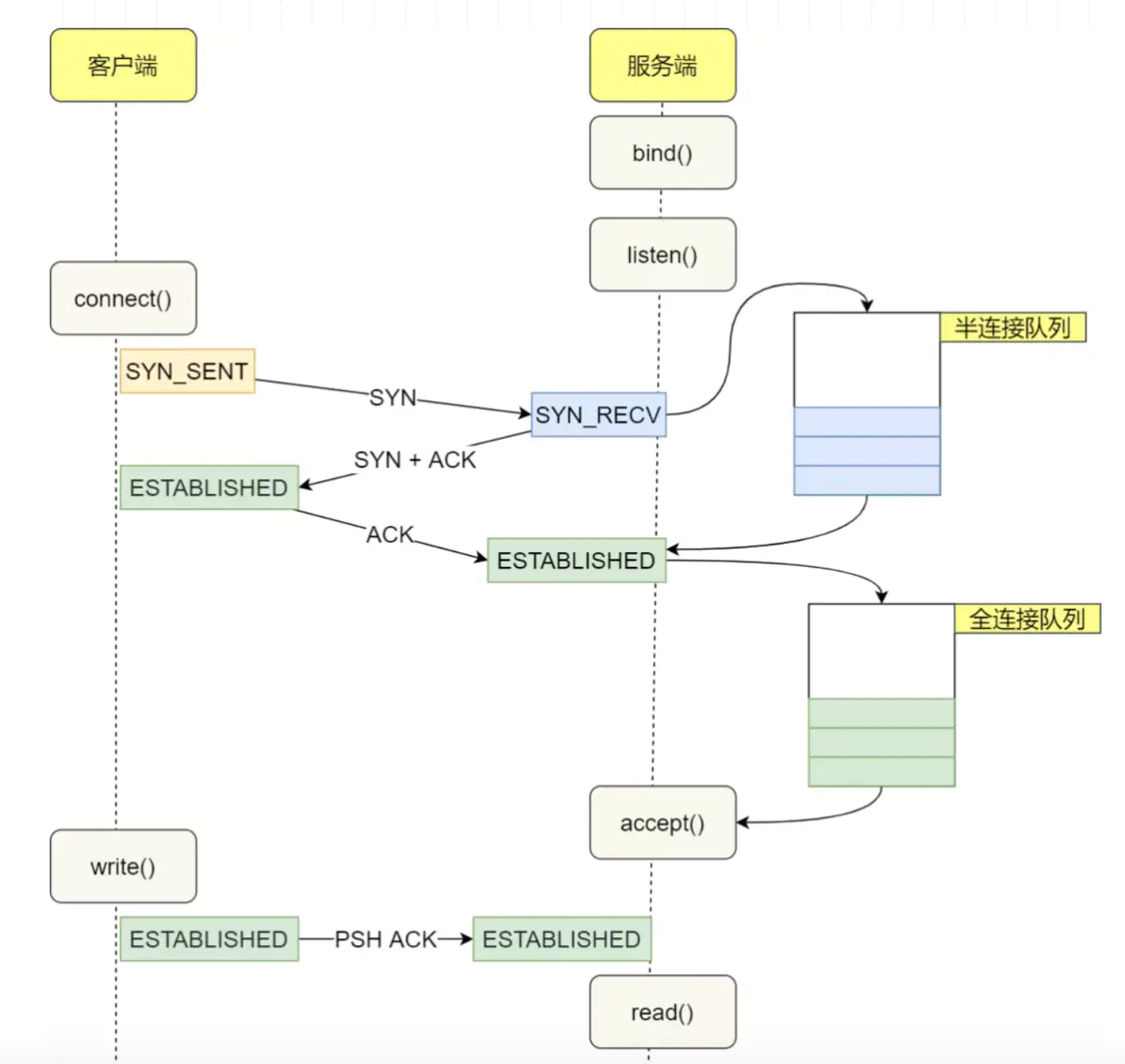
不管是半连接队列还是全连接队列,都有最大长度限制,超过限制时,内核会直接丢弃,或返回 RST 包。
实战 - TCP 全连接队列溢出
如何知道应用程序的 TCP 全连接队列大小?
在服务端可以使用 ss 命令,来查看 TCP 全连接队列的情况:
但需要注意的是 ss 命令获取的 Recv-Q/Send-Q 在「LISTEN 状态」和「非 LISTEN 状态」所表达的含义是不同的。从下面的内核代码可以看出区别:
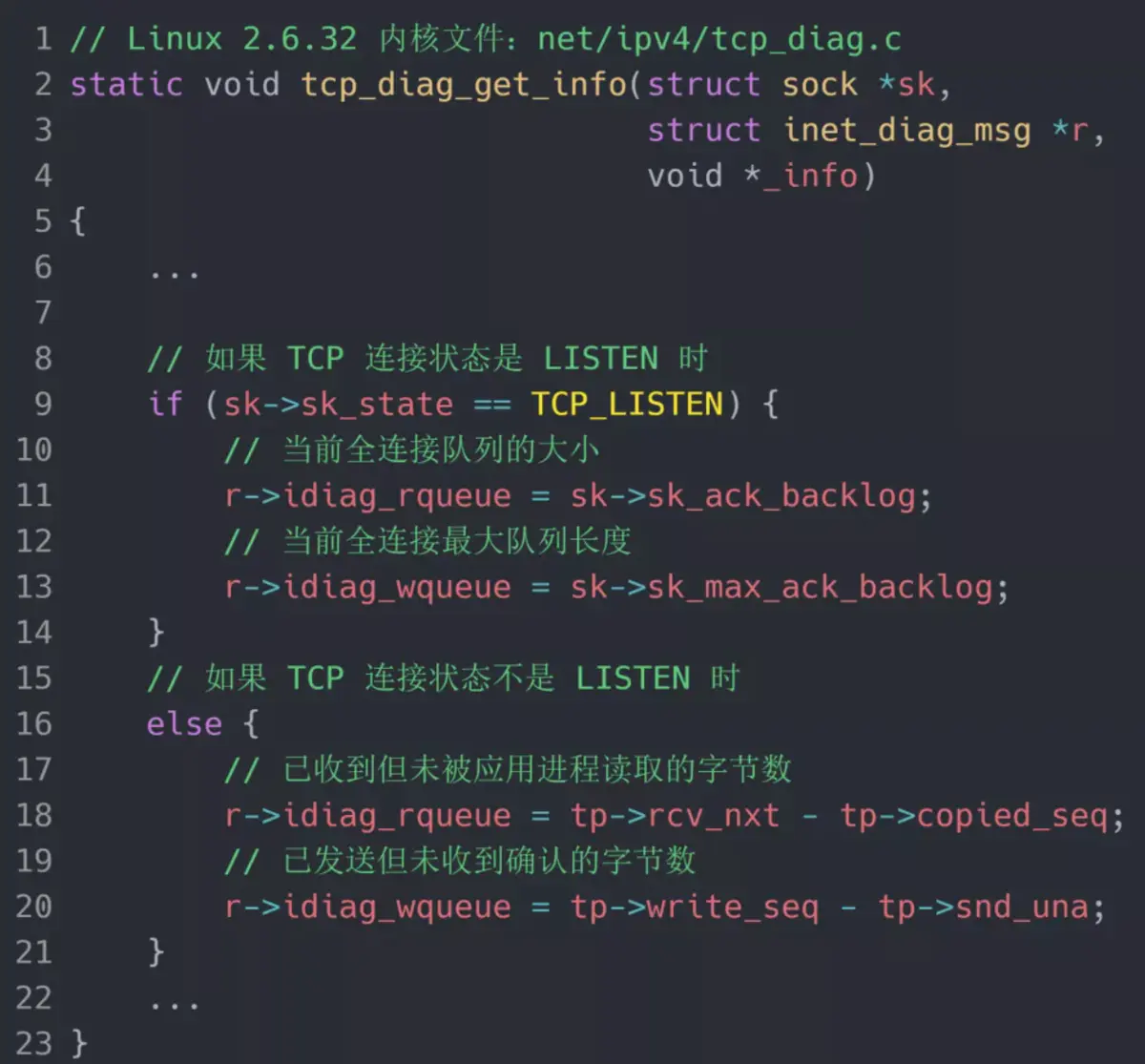
在「LISTEN 状态」时,Recv-Q/Send-Q 表示的含义如下:
- Recv-Q:当前全连接队列的大小,也就是当前已完成三次握手并等待服务端 accept() 的 TCP 连接个数;
- Send-Q:当前全连接最大队列长度,上面的输出结果说明监听 8088 端口的 TCP 服务进程,最大全连接长度为 128;
在「非 LISTEN 状态」时,Recv-Q/Send-Q 表示的含义如下:

- Recv-Q:已收到但未被应用进程读取的字节数;
- Send-Q:已发送但未收到确认的字节数;
如何模拟 TCP 全连接队列溢出的场景?
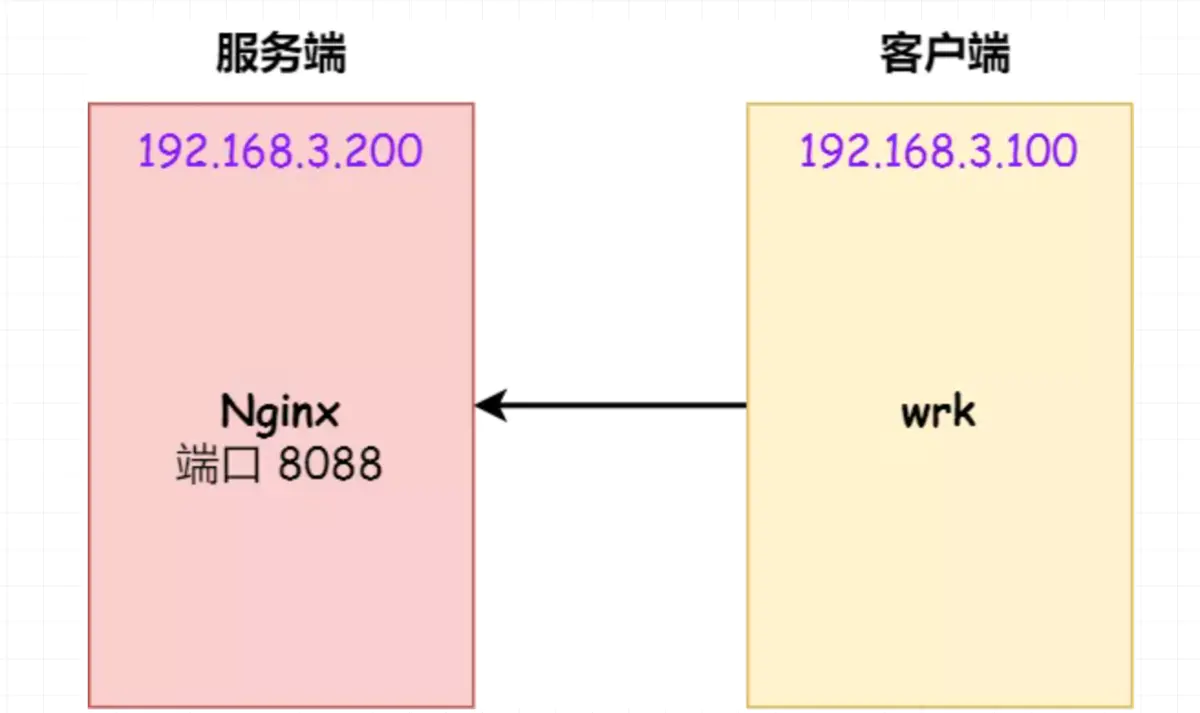
image.png
这里先介绍下 wrk 工具,它是一款简单的 HTTP 压测工具,它能够在单机多核 CPU 的条件下,使用系统自带的高性能 I/O 机制,通过多线程和事件模式,对目标机器产生大量的负载。
本次模拟实验就使用 wrk 工具来压力测试服务端,发起大量的请求,一起看看服务端 TCP 全连接队列满了会发生什么?有什么观察指标?
客户端执行 wrk 命令对服务端发起压力测试,并发 3 万个连接:

在服务端可以使用 ss 命令,来查看当前 TCP 全连接队列的情况:
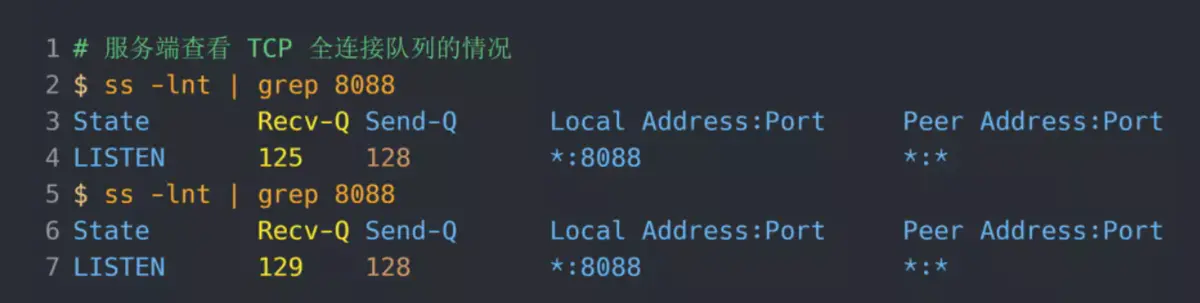
其间共执行了两次 ss 命令,从上面的输出结果,可以发现当前 TCP 全连接队列上升到了 129 大小,超过了最大 TCP 全连接队列。
当超过了 TCP 最大全连接队列,服务端则会丢掉后续进来的 TCP 连接,丢掉的 TCP 连接的个数会被统计起来,我们可以使用 netstat -s 命令来查看:
netstat -s | grep overflowed

上面看到的 41150 times ,表示全连接队列溢出的次数,注意这个是累计值。可以隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
从上面的模拟结果,可以得知,当服务端并发处理大量请求时,如果 TCP 全连接队列过小,就容易溢出。发生 TCP 全连接队溢出的时候,后续的请求就会被丢弃,这样就会出现服务端请求数量上不去的现象。
全连接队列满了,就只会丢弃连接吗?
实际上,丢弃连接只是 Linux 的默认行为,我们还可以选择向客户端发送 RST 复位报文,告诉客户端连接已经建立失败。
cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
tcp_abort_on_overflow 共有两个值分别是 0 和 1,其分别表示:
- 0 :表示如果全连接队列满了,那么 server 扔掉 client 发过来的 ack ;
- 1 :表示如果全连接队列满了,那么 server 发送一个 reset 包给 client,表示废掉这个握手过程和这个连接;
如果要想知道客户端连接不上服务端,是不是服务端 TCP 全连接队列满的原因,那么可以把 tcp_abort_on_overflow 设置为 1,这时如果在客户端异常中可以看到很多 connection reset by peer 的错误,那么就可以证明是由于服务端 TCP 全连接队列溢出的问题。
通常情况下,应当把 tcp_abort_on_overflow 设置为 0,因为这样更有利于应对突发流量。
举个例子,当 TCP 全连接队列满导致服务器丢掉了 ACK,与此同时,客户端的连接状态却是 ESTABLISHED,进程就在建立好的连接上发送请求。只要服务器没有为请求回复 ACK,请求就会被多次重发。如果服务器上的进程只是短暂的繁忙造成 accept 队列满,那么当 TCP 全连接队列有空位时,再次接收到的请求报文由于含有 ACK,仍然会触发服务器端成功建立连接。
所以,tcp_abort_on_overflow 设为 0 可以提高连接建立的成功率,只有你非常肯定 TCP 全连接队列会长期溢出时,才能设置为 1 以尽快通知客户端。
如何增大 TCP 全连接队列呢?
是的,当发现 TCP 全连接队列发生溢出的时候,我们就需要增大该队列的大小,以便可以应对客户端大量的请求。
TCP 全连接队列足最大值取决于 somaxconn 和 backlog 之间的最小值,也就是 min(somaxconn, backlog)。从下面的 Linux 内核代码可以得知:
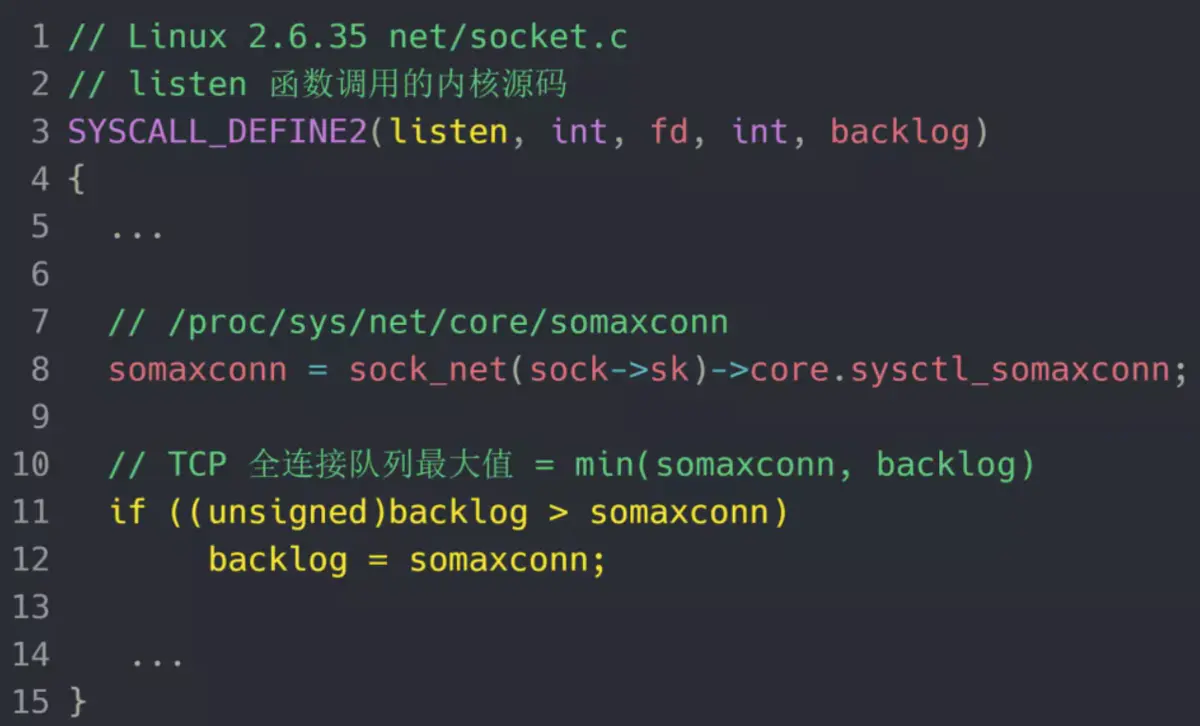
somaxconn 是 Linux 内核的参数,默认值是 128,可以通过 /proc/sys/net/core/somaxconn 来设置其值;
backlog 是 listen(int sockfd, int backlog) 函数中的 backlog 大小,Nginx 默认值是 511,可以通过修改配置文件设置其长度;
前面模拟测试中,我的测试环境:
- somaxconn 是默认值 128;
- Nginx 的 backlog 是默认值 511
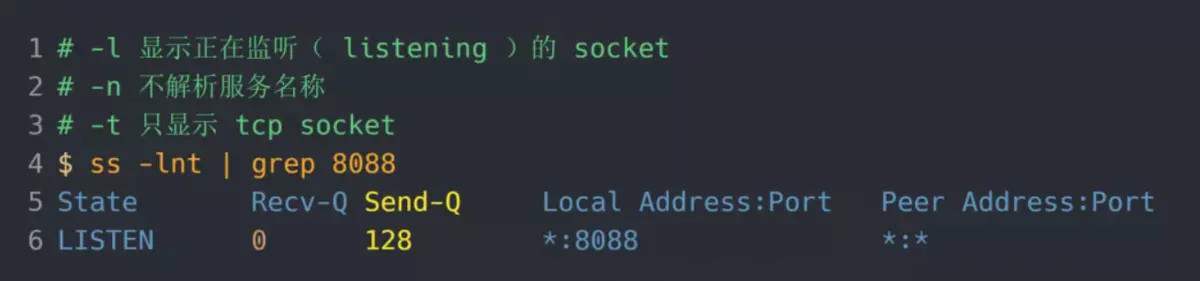
所以测试环境的 TCP 全连接队列最大值为 min(128, 511),也就是 128,可以执行 ss 命令查看:
现在我们重新压测,把 TCP 全连接队列搞大,把 somaxconn 设置成 5000:

接着把 Nginx 的 backlog 也同样设置成 5000:
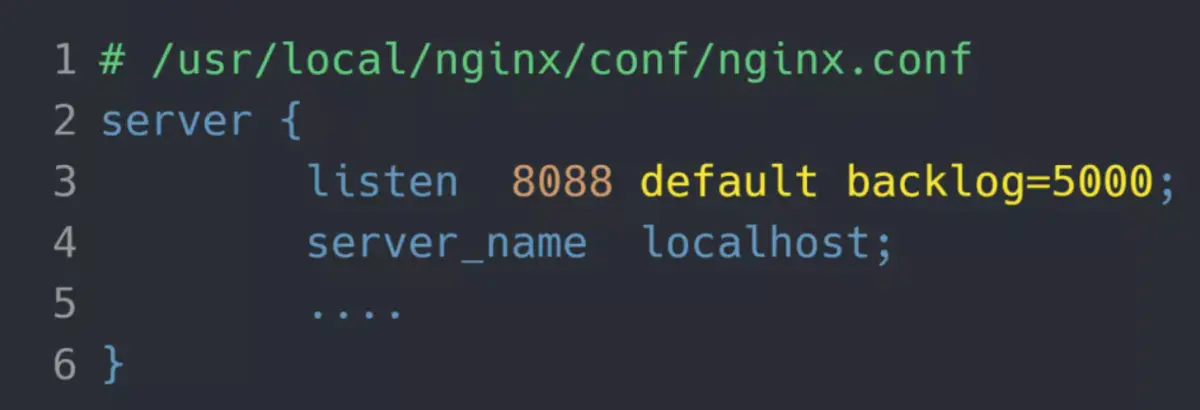
最后要重启 Nginx 服务,因为只有重新调用 listen() 函数, TCP 全连接队列才会重新初始化。
重启完后 Nginx 服务后,服务端执行 ss 命令,查看 TCP 全连接队列大小:
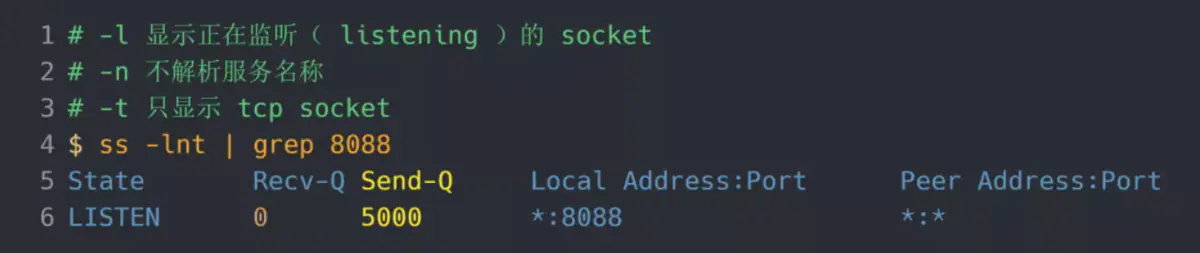
从执行结果,可以发现 TCP 全连接最大值为 5000。
增大 TCP 全连接队列后,继续压测
客户端同样以 3 万个连接并发发送请求给服务端:
服务端执行 ss 命令,查看 TCP 全连接队列使用情况:
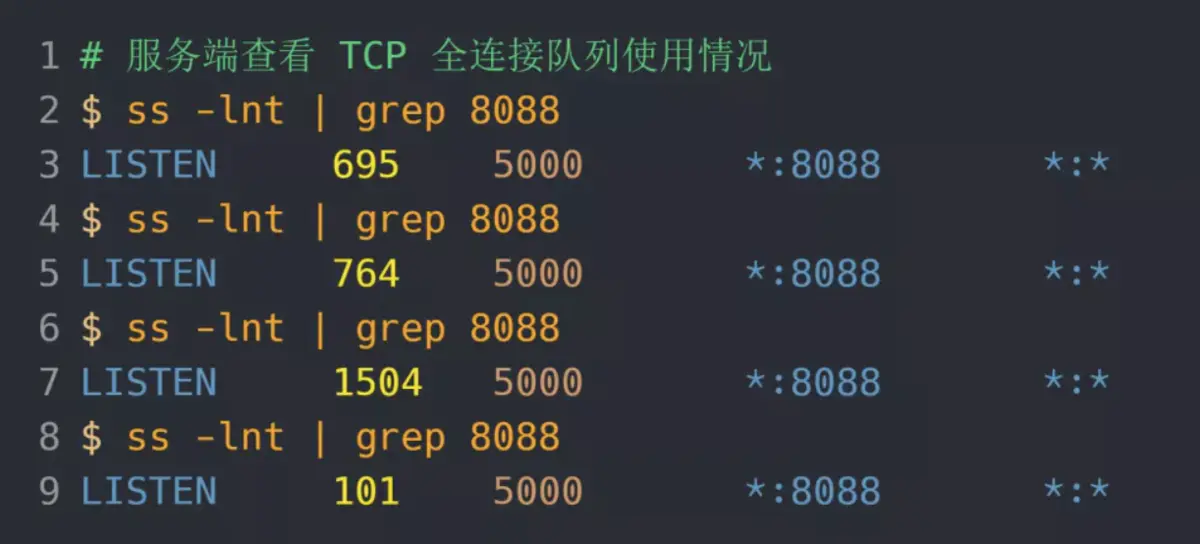
从上面的执行结果,可以发现全连接队列使用增长的很快,但是一直都没有超过最大值,所以就不会溢出,那么 netstat -s 就不会有 TCP 全连接队列溢出个数的显示:

说明 TCP 全连接队列最大值从 128 增大到 5000 后,服务端抗住了 3 万连接并发请求,也没有发生全连接队列溢出的现象了。
如果持续不断地有连接因为 TCP 全连接队列溢出被丢弃,就应该调大 backlog 以及 somaxconn 参数。
如何模拟 TCP 半连接队列溢出场景?
模拟 TCP 半连接溢出场景不难,实际上就是对服务端一直发送 TCP SYN 包,但是不回第三次握手 ACK,这样就会使得服务端有大量的处于 SYN_RECV 状态的 TCP 连接。
这其实也就是所谓的 SYN 洪泛、SYN 攻击、DDos 攻击。
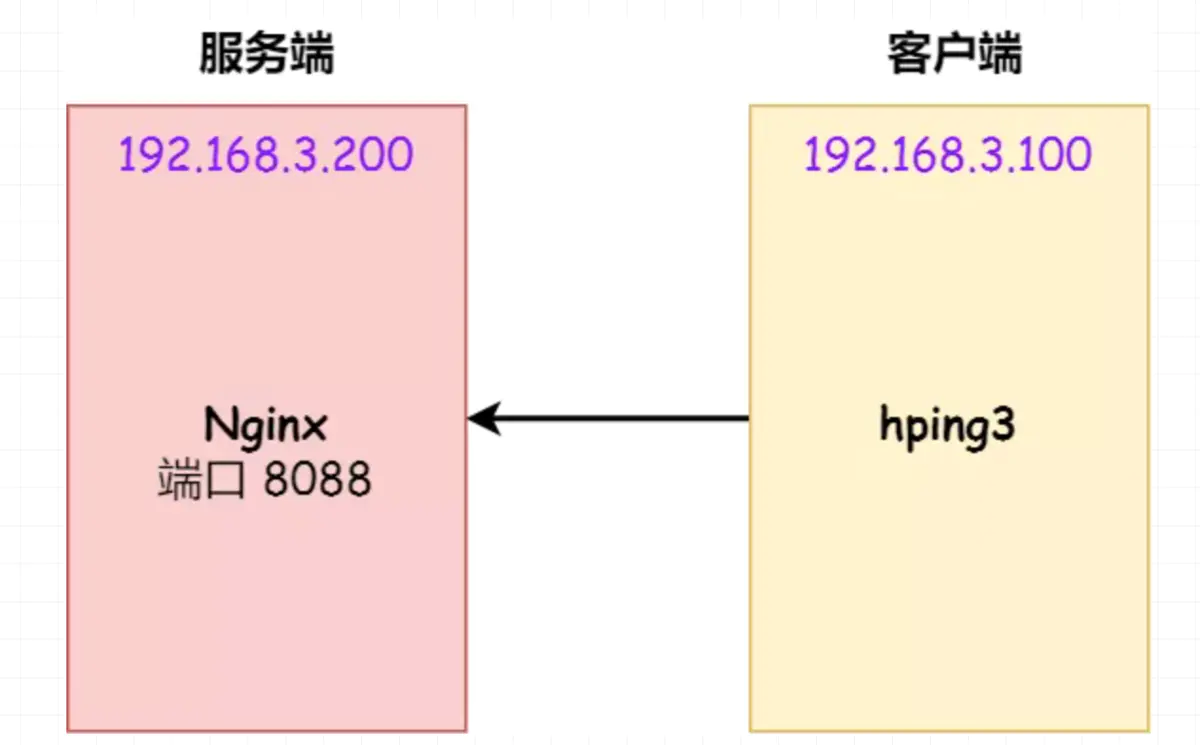
本次实验使用 hping3 工具模拟 SYN 攻击:
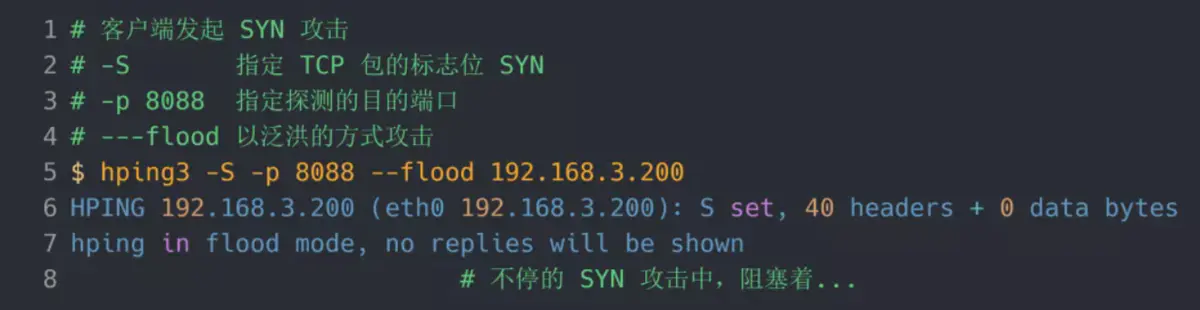
当服务端受到 SYN 攻击后,连接服务端 ssh 就会断开了,无法再连上。只能在服务端主机上执行查看当前 TCP 半连接队列大小:

同时,还可以通过 netstat -s 观察半连接队列溢出的情况:
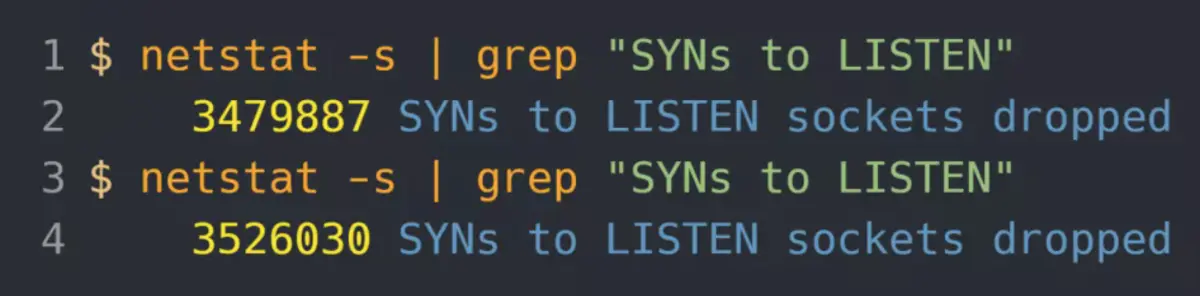
上面输出的数值是累计值,表示共有多少个 TCP 连接因为半连接队列溢出而被丢弃。隔几秒执行几次,如果有上升的趋势,说明当前存在半连接队列溢出的现象。
tcp_max_syn_backlog 是指定半连接队列的大小,是真的吗?
很遗憾,半连接队列的大小并不单单只跟 tcp_max_syn_backlog 有关系。
上面模拟 SYN 攻击场景时,服务端的 tcp_max_syn_backlog 的默认值如下:

但是在测试的时候发现,服务端最多只有 256 个半连接队列,而不是 512,所以半连接队列的最大长度不一定由 tcp_max_syn_backlog 值决定的。
接下来,走进 Linux 内核的源码,来分析 TCP 半连接队列的最大值是如何决定的。
TCP 第一次握手(收到 SYN 包)的 Linux 内核代码如下,其中缩减了大量的代码,只需要重点关注 TCP 半连接队列溢出的处理逻辑:
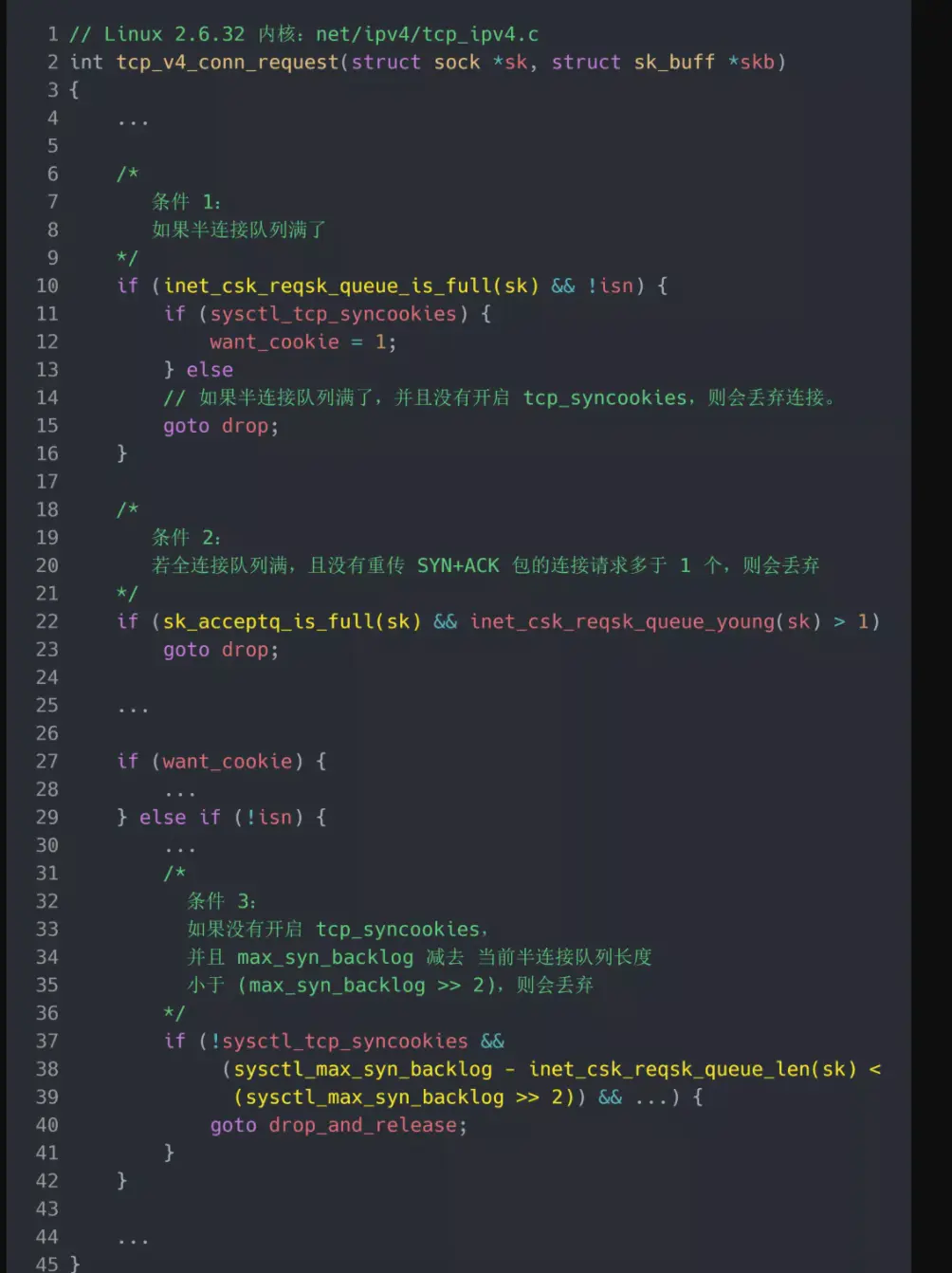
从源码中,我可以得出共有三个条件因队列长度的关系而被丢弃的:
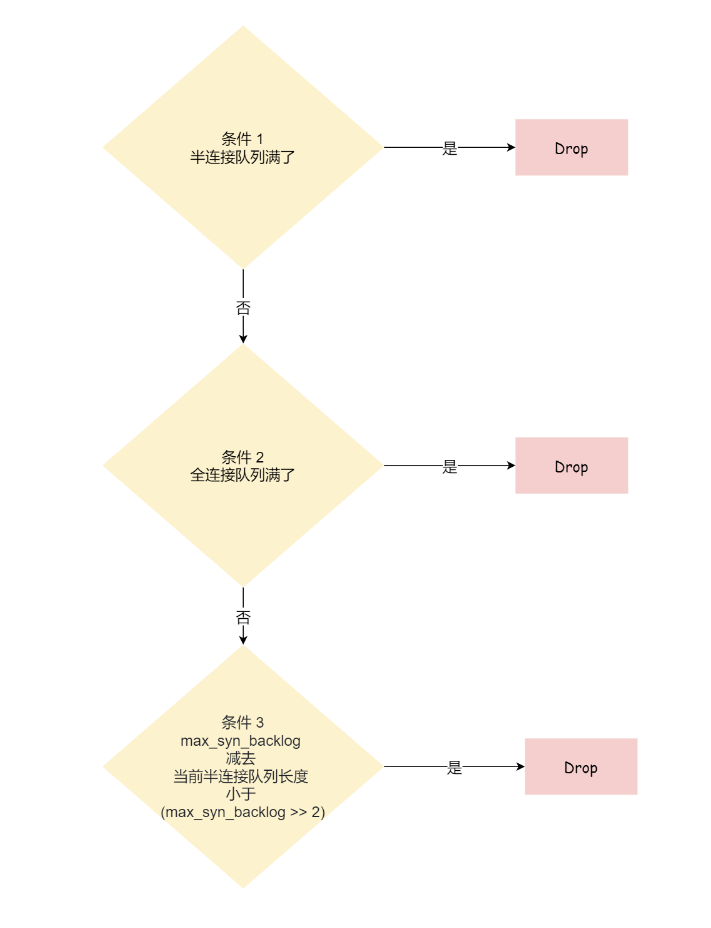
从图中可知:
- 如果半连接队列满了,并且没有开启 tcp_syncookies,则会丢弃;
- 若全连接队列满了,且没有重传 SYN+ACK 包的连接请求多于 1 个,则会丢弃;
- 如果没有开启 tcp_syncookies,并且 max_syn_backlog 减去 当前半连接队列长度小于 (max_syn_backlog >> 2),则会丢弃;
- 关于 tcp_syncookies 的设置,后面在详细说明,可以先给大家说一下,开启 tcp_syncookies 是缓解 SYN 攻击其中一个手段。
接下来,我们继续跟一下检测半连接队列是否满的函数 inet_csk_reqsk_queue_is_full 和 检测全连接队列是否满的函数 sk_acceptq_is_full :
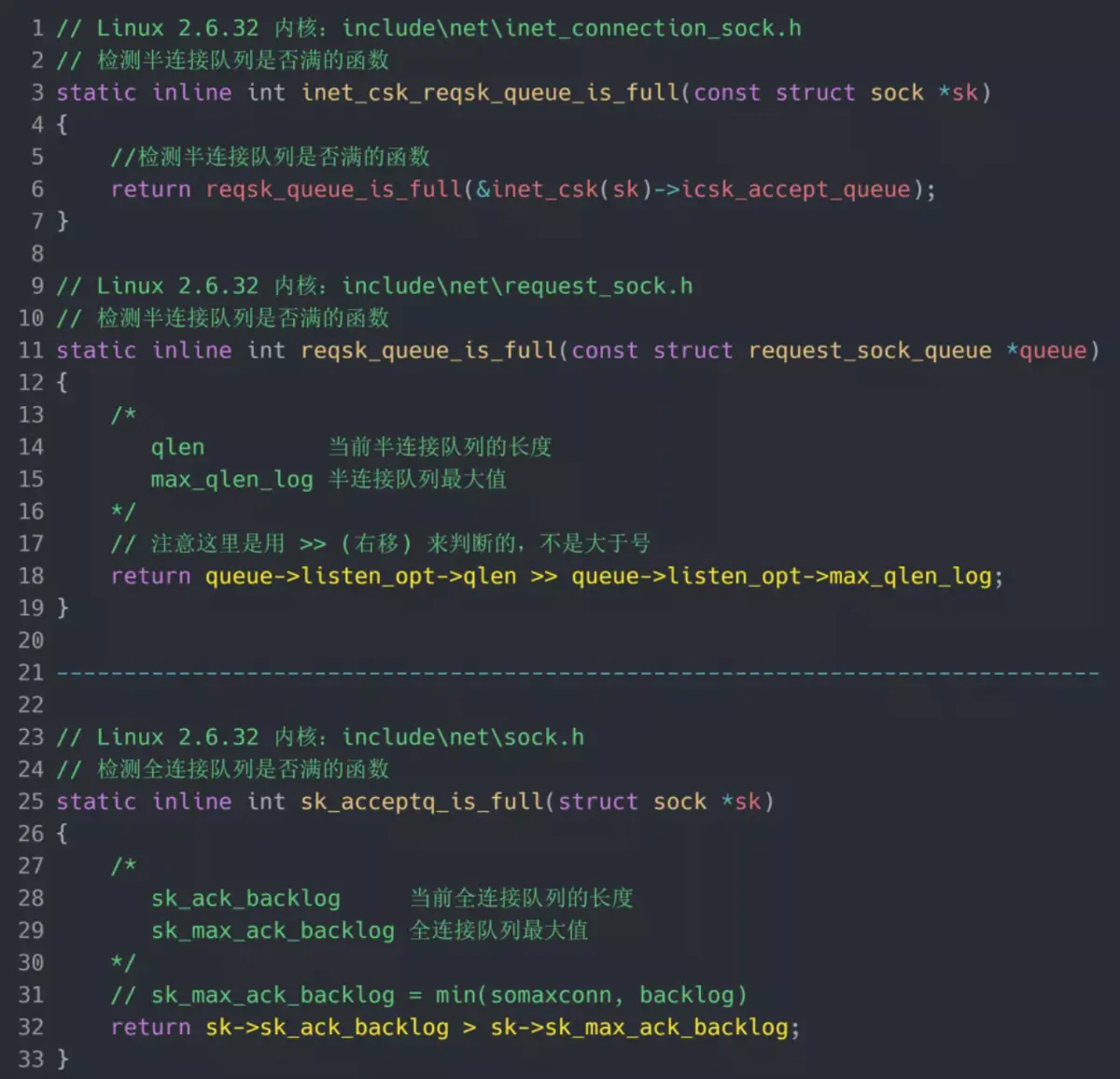
从上面源码,可以得知:
- 全连接队列的最大值是 sk_max_ack_backlog 变量,sk_max_ack_backlog 实际上是在 listen() 源码里指定的,也就是 min(somaxconn, backlog);
- 半连接队列的最大值是 max_qlen_log 变量,max_qlen_log 是在哪指定的呢?现在暂时还不知道,我们继续跟进;
半连接队列最大值不是单单由 max_syn_backlog 决定,还跟 somaxconn 和 backlog 有关系。
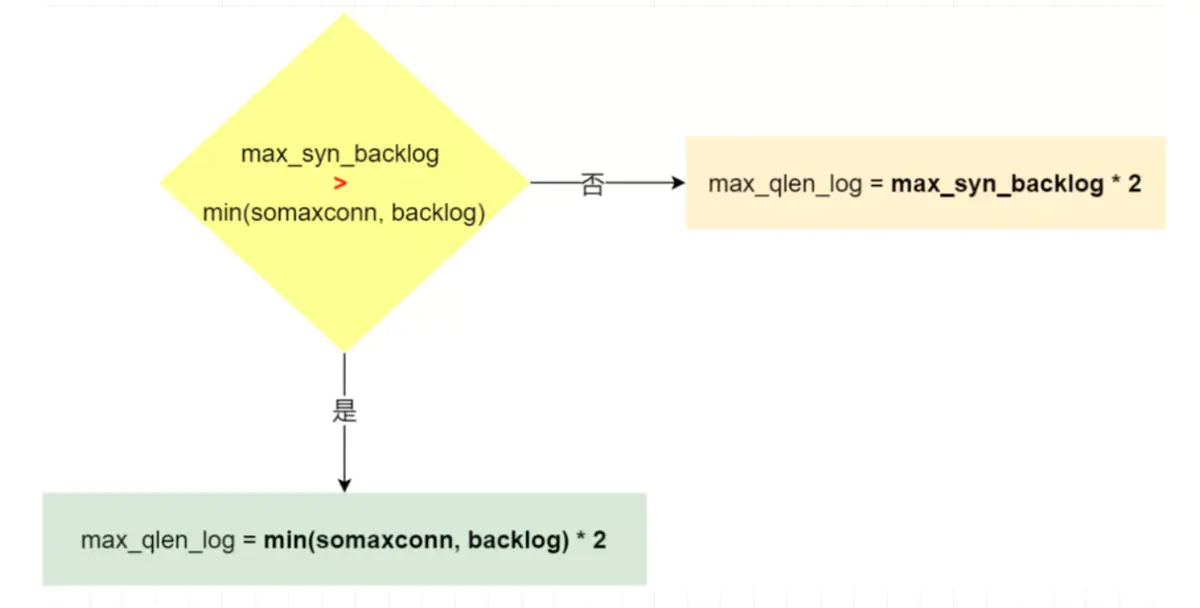
在 Linux 2.6.32 内核版本,它们之间的关系,总体可以概况为:
- 当 max_syn_backlog > min(somaxconn, backlog) 时, 半连接队列最大值 max_qlen_log = min(somaxconn, backlog) * 2;
- 当 max_syn_backlog < min(somaxconn, backlog) 时, 半连接队列最大值 max_qlen_log = max_syn_backlog * 2;
Linux网络包接收过程的监控与调优
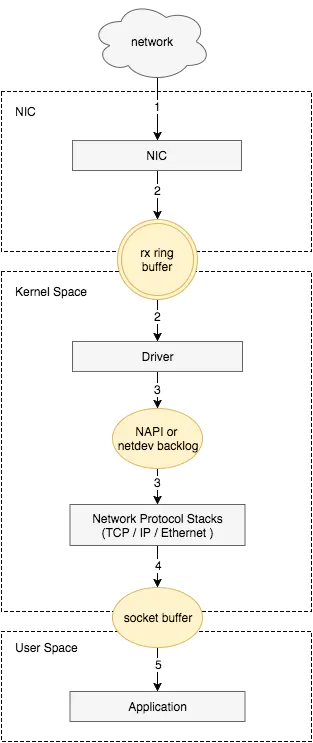
我们梳理了在Linux系统下一个数据包被接收的整个过程。Linux内核对网络包的接收过程大致可以分为接收到RingBuffer、硬中断处理、ksoftirqd软中断处理几个过程。其中在ksoftirqd软中断处理中,把数据包从RingBuffer中摘下来,送到协议栈的处理,再之后送到用户进程socket的接收队列中。
相关工具
ethtool
-i 显示网卡驱动的信息,如驱动的名称、版本等
-S 查看网卡收发包的统计情况
-g/-G 查看或者修改RingBuffer的大小
-l/-L 查看或者修改网卡队列数
-c/-C 查看或者修改硬中断合并策略
proc
Linux 内核提供了 /proc 伪文件系统,通过/proc可以查看内核内部数据结构、改变内核设置。我们先跑一下题,看一下这个伪文件系统里都有啥:
/proc/sys 目录可以查看或修改内核参数
/proc/cpuinfo 可以查看CPU信息
/proc/meminfo 可以查看内存信息
/proc/interrupts 统计所有的硬中断
/proc/softirqs 统计的所有的软中断信息
/proc/slabinfo 统计了内核数据结构的slab内存使用情况
/proc/net/dev 可以看到一些网卡统计数据
详细聊下伪文件/proc/net/dev,通过它可以看到内核中对网卡的一些相关统计。包含了以下信息:
bytes: 发送或接收的数据的总字节数
packets: 接口发送或接收的数据包总数
errs: 由设备驱动程序检测到的发送或接收错误的总数
drop: 设备驱动程序丢弃的数据包总数
fifo: FIFO缓冲区错误的数量
frame: The number of packet framing errors.(分组帧错误的数量)
colls: 接口上检测到的冲突数
所以,伪文件/proc/net/dev也可以作为我们查看网卡工作统计数据的工具之一。
伪文件系统sysfs
sysfs和/proc类似,也是一个伪文件系统,但是比proc更新,结构更清晰。 其中的/sys/class/net/eth0/statistics/也包含了网卡的统计信息。
cd /sys/class/net/eth0/statistics/
grep . * | grep tx
tx_aborted_errors:0
tx_bytes:27705920895
tx_carrier_errors:0
tx_compressed:0
tx_dropped:0
tx_errors:0
tx_fifo_errors:0
tx_heartbeat_errors:0
tx_packets:177228029
tx_window_errors:0
RingBuffer监控与调优
我们使用ethtool来来查看一下Ringbuffer。
ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 512
RX Mini: 0
RX Jumbo: 0
TX: 512
这里看到我手头的网卡设置RingBuffer最大允许设置到4096,目前的实际设置是512。
在Linux的整个网络栈中,RingBuffer起到一个任务的收发中转站的角色。对于接收过程来讲,网卡负责往RingBuffer中写入收到的数据帧,ksoftirqd内核线程负责从中取走处理。只要ksoftirqd线程工作的足够快,RingBuffer这个中转站就不会出现问题。但是我们设想一下,假如某一时刻,瞬间来了特别多的包,而ksoftirqd处理不过来了,会发生什么?这时RingBuffer可能瞬间就被填满了,后面再来的包网卡直接就会丢弃,不做任何处理!
ethtool -S eth0
...
rx_fifo_errors: 0
tx_fifo_errors: 0
...
rx_fifo_errors如果不为0的话(在 ifconfig 中体现为 overruns 指标增长),就表示有包因为RingBuffer装不下而被丢弃了。那么怎么解决这个问题呢?
很自然首先我们想到的是,加大RingBuffer这个“中转仓库”的大小。通过ethtool就可以修改。
个要监控和调优的就是网卡的RingBuffer,我们使用ethtool来来查看一下Ringbuffer。
```bash
ethtool -G eth0 rx 4096 tx 4096
这样网卡会被分配更大一点的”中转站“,可以解决偶发的瞬时的丢包。不过这种方法有个小副作用,那就是排队的包过多会增加处理网络包的延时。所以另外一种解决思考更好。那就是让内核处理网络包的速度更快一些,而不是让网络包傻傻地在RingBuffer中排队。
怎么加快内核消费RingBuffer中任务的速度呢?
硬中断监控与调优
监控
硬中断的情况可以通过内核提供的伪文件/proc/interrupts来进行查看。
$ cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
0: 34 0 0 0 IO-APIC-edge timer
......
27: 351 0 0 1109986815 PCI-MSI-edge virtio1-input.0
28: 2571 0 0 0 PCI-MSI-edge virtio1-output.0
29: 0 0 0 0 PCI-MSI-edge virtio2-config
30: 4233459 1986139461 244872 474097 PCI-MSI-edge virtio2-input.0
31: 3 0 2 0 PCI-MSI-edge virtio2-output.0
上述结果是我手头的一台虚机的输出结果。上面包含了非常丰富的信息,让我们一一道来:
- 网卡的输入队列virtio1-input.0的中断号是27
- 27号中断都是由CPU3来处理的
- 总的中断次数是1109986815。
这里有两个细节我们需要关注一下。
1)为什么输入队列的中断都在CPU3上呢?
这是因为内核的一个配置,在伪文件系统中可以查看到。
cat /proc/irq/27/smp_affinity
smp_affinity里是CPU的亲和性的绑定,8是二进制的1000,第4位为1,代表的就是第4个CPU核心-CPU3。
2)对于收包来过程来讲,硬中断的总次数表示的是Linux收包总数吗?
不是,硬件中断次数不代表总的网络包数。第一网卡可以设置中断合并,多个网络帧可以只发起一次中断。第二NAPI 运行的时候会关闭硬中断,通过poll来收包。
调优
多队列网卡调优
每一个队列都有一个中断号,可以独立向某个CPU核心发起硬中断请求,让CPU来poll包。通过将接收进来的包被放到不同的内存队列里,多个CPU就可以同时分别向不同的队列发起消费了。这个特性叫做RSS(Receive Side Scaling,接收端扩展)。通过ethtool工具可以查看网卡的队列情况。
ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0
Other: 1
Combined: 63
Current hardware settings:
RX: 0
TX: 0
Other: 1
Combined: 8
上述结果表示当前网卡支持的最大队列数是63,当前开启的队列数是8。对于这个配置来讲,最多同时可以有8个核心来参与网络收包。如果你想提高内核收包的能力,直接简单加大队列数就可以了,这比加大RingBuffer更为有用。因为加大RingBuffer只是给个更大的空间让网络帧能继续排队,而加大队列数则能让包更早地被内核处理。ethtool修改队列数量方法如下:
ethtool -L eth0 combined 32
我们前文说过,硬中断发生在哪一个核上,它发出的软中断就由哪个核来处理。所有通过加大网卡队列数,这样硬中断工作、软中断工作都会有更多的核心参与进来。
每一个队列都有一个中断号,每一个中断号都是绑定在一个特定的CPU上的。如果你不满意某一个中断的CPU绑定,可以通过修改/proc/irq/{中断号}/smp_affinity来实现。
一般处理到这里,网络包的接收就没有大问题了。但如果你有更高的追求,或者是说你并没有更多的CPU核心可以参与进来了,那怎么办?放心,我们也还有方法提高单核的处理网络包的接收速度。
硬中断合并
现在我们来看一下网卡的硬中断合并配置。
ethtool -c eth0
Coalesce parameters for eth0:
Adaptive RX: off TX: off
......
rx-usecs: 1
rx-frames: 0
rx-usecs-irq: 0
rx-frames-irq: 0
......
我们来说一下上述结果的大致含义
- Adaptive RX: 自适应中断合并,网卡驱动自己判断啥时候该合并啥时候不合并
- rx-usecs: 当过这么长时间过后,一个RX interrupt就会被产生
- rx-frames:当累计接收到这么多个帧后,一个RX interrupt就会被产生
如果你想好了修改其中的某一个参数了的话,直接使用ethtool -C就可以,例如:
ethtool -C eth0 adaptive -rx on
不过需要注意的是,减少中断数量虽然能使得Linux整体吞吐更高,不过一些包的延迟也会增大,所以用的时候得适当注意。
软中断监控与调优
在硬中断之后,再接下来的处理过程就是ksoftirqd内核线程中处理的软中断了。之前我们说过,软中断和它对应的硬中断是在同一个核心上处理的。 因此,前面硬中断分散到多核上处理的时候,软中断的优化其实也就跟着做了,也会被多核处理。不过软中断也还有自己的可优化选项。
监控
软中断的信息可以从 /proc/softirqs 读取:
$ cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3
HI: 0 2 2 0
TIMER: 704301348 1013086839 831487473 2202821058
NET_TX: 33628 31329 32891 105243
NET_RX: 418082154 2418421545 429443219 1504510793
BLOCK: 37 0 0 25728280
BLOCK_IOPOLL: 0 0 0 0
TASKLET: 271783 273780 276790 341003
SCHED: 1544746947 1374552718 1287098690 2221303707
HRTIMER: 0 0 0 0
RCU: 3200539884 3336543147 3228730912 3584743459
调优
软中断budget调整
不知道你有没有听说过番茄工作法,它的大致意思就是你要有一整段的不被打扰的时间,集中精力处理某一项作业。这一整段时间时长被建议是25分钟。 对于我们的Linux的处理软中断的ksoftirqd来说,它也和番茄工作法思路类似。一旦它被硬中断触发开始了工作,它会集中精力处理一波儿网络包(绝不只是1个),然后再去做别的事情。
我们说的处理一波儿是多少呢,策略略复杂。我们只说其中一个比较容易理解的,那就是net.core.netdev_budget内核参数。
#sysctl -a | grep
net.core.netdev_budget = 300
这个的意思说的是,ksoftirqd一次最多处理300个包,处理够了就会把CPU主动让出来,以便Linux上其它的任务可以得到处理。 那么假如说,我们现在就是想提高内核处理网络包的效率。那就可以让ksoftirqd进程多干一会儿网络包的接收,再让出CPU。至于怎么提高,直接修改不这个参数的值就好了。
sysctl -w net.core.netdev_budget=600
如果要保证重启仍然生效,需要将这个配置写到/etc/sysctl.conf
软中断GRO合并
GRO和硬中断合并的思想很类似,不过阶段不同。硬中断合并是在中断发起之前,而GRO已经到了软中断上下文中了。
如果应用中是大文件的传输,大部分包都是一段数据,不用GRO的话,会每次都将一个小包传送到协议栈(IP接收函数、TCP接收)函数中进行处理。开启GRO的话,Linux就会智能进行包的合并,之后将一个大包传给协议处理函数。这样CPU的效率也是就提高了。
ethtool -k eth0 | grep generic-receive-offload
generic-receive-offload: on
如果你的网卡驱动没有打开GRO的话,可以通过如下方式打开。
ethtool -K eth0 gro on
GRO说的仅仅只是包的接收阶段的优化方式,对于发送来说是GSO。
linux网络之数据包的接收过程
网卡收包从整体上是网线中的高低电平转换到网卡FIFO存储再拷贝到系统主内存(DDR3)的过程,其中涉及到网卡控制器,CPU,DMA,驱动程序,在OSI模型中属于物理层和链路层,如下图所示。
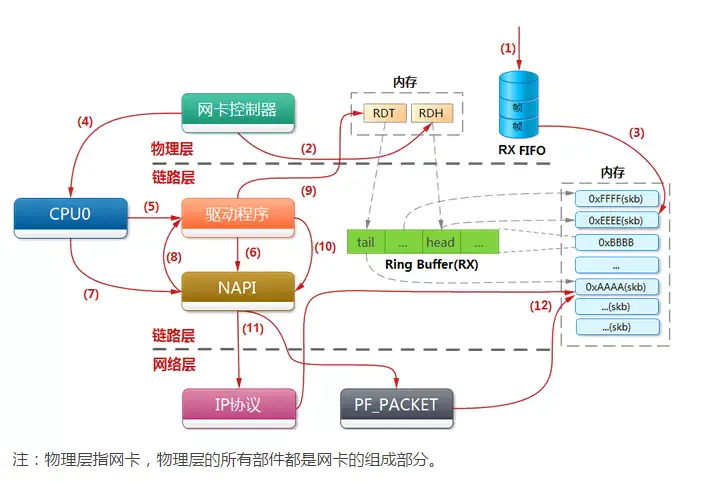
网卡工作在物理层和数据链路层,主要由PHY/MAC芯片、Tx/Rx FIFO、DMA等组成,其中网线通过变压器接PHY芯片、PHY芯片通过MII接MAC芯片、MAC芯片接PCI总线
PHY芯片主要负责:CSMA/CD、模数转换、编解码、串并转换
MAC芯片主要负责:
- 比特流和帧的转换:7字节的前导码Preamble和1字节的帧首定界符SFD
- CRC校验
- Packet Filtering:L2 Filtering、VLAN Filtering、Manageability / Host Filtering
Intel的千兆网卡以82575/82576为代表、万兆网卡以82598/82599为代表
接收数据包是一个复杂的过程,涉及很多底层的技术细节,但大致需要以下几个步骤:
- 网卡收到数据包。
- 将数据包从网卡硬件缓存转移到服务器内存中。
- 通知内核处理。
- 经过TCP/IP协议逐层处理。
- 应用程序通过read()从socket buffer读取数据。
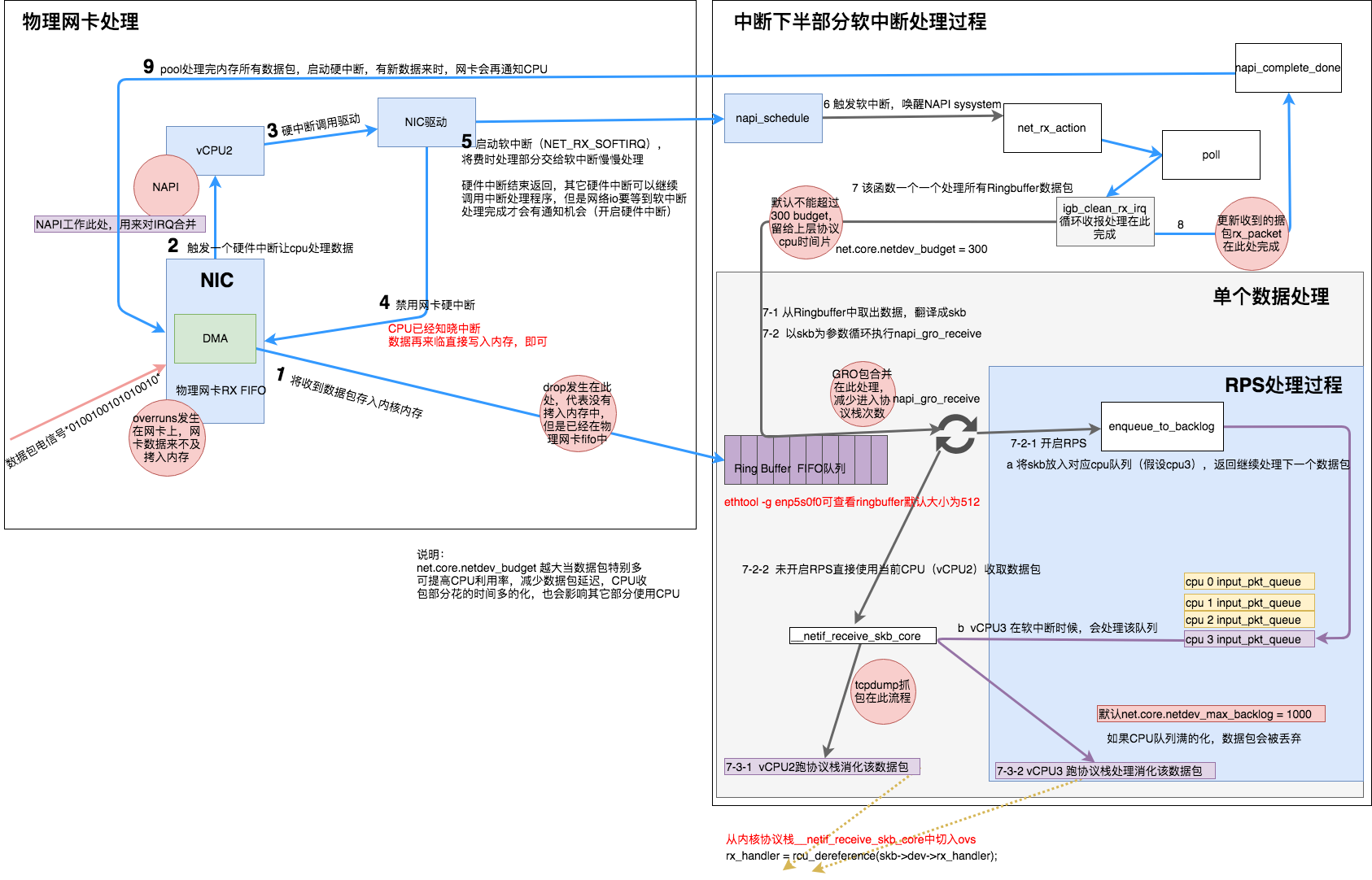
物理网卡收到数据包的处理流程如上图所示,详细步骤如下:
- 网卡收到数据包,先将高低电平转换到网卡fifo存储,网卡申请ring buffer的描述,根据描述找到具体的物理地址,从fifo队列物理网卡会使用DMA将数据包写到了该物理地址,,其实就是skb_buffer中.
- 这个时候数据包已经被转移到skb_buffer中,因为是DMA写入,内核并没有监控数据包写入情况,这时候NIC触发一个硬中断,每一个硬件中断会对应一个中断号,且指定一个vCPU来处理,如上图vcpu2收到了该硬件中断.
- 硬件中断的中断处理程序,调用驱动程序完成,a.启动软中断
- 硬中断触发的驱动程序会禁用网卡硬中断,其实这时候意思是告诉NIC,再来数据不用触发硬中断了,把数据DMA拷入系统内存即可
- 硬中断触发的驱动程序会启动软中断,启用软中断目的是将数据包后续处理流程交给软中断慢慢处理,这个时候退出硬件中断了,但是注意和网络有关的硬中断,要等到后续开启硬中断后,才有机会再次被触发
- NAPI触发软中断,触发napi系统
- 消耗ringbuffer指向的skb_buffer
- NAPI循环处理ringbuffer数据,处理完成
- 启动网络硬件中断,有数据来时候就可以继续触发硬件中断,继续通知CPU来消耗数据包.
其实上述过程过程简单描述为:
网卡收到数据包,DMA到内核内存,中断通知内核数据有了,内核按轮次处理消耗数据包,一轮处理完成后,开启硬中断。其核心就是网卡和内核其实是生产和消费模型,网卡生产,内核负责消费,生产者需要通知消费者消费;如果生产过快会产生丢包,如果消费过慢也会产生问题。也就说在高流量压力情况下,只有生产消费优化后,消费能力够快,此生产消费关系才可以正常维持,所以如果物理接口有丢包计数时候,未必是网卡存在问题,也可能是内核消费的太慢。
如何将网卡收到的数据写入到内核内存?
NIC在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是rx ring buffer。它是由NIC和驱动程序共享的一片区域,事实上,rx ring buffer存储的并不是实际的packet数据,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
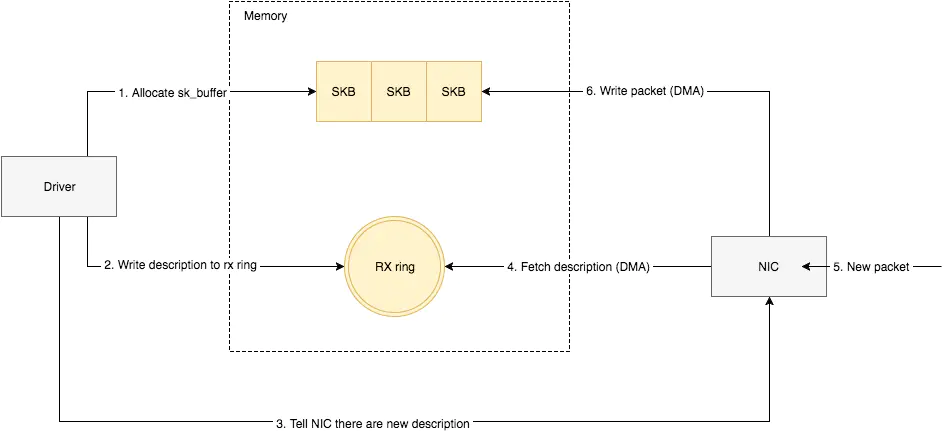
- 驱动在内存中分配一片缓冲区用来接收数据包,叫做sk_buffer;
- 将上述缓冲区的地址和大小(即接收描述符),加入到rx ring buffer。描述符中的缓冲区地址是DMA使用的物理地址;
- 驱动通知网卡有一个新的描述符;
- 网卡从rx ring buffer中取出描述符,从而获知缓冲区的地址和大小;
- 网卡收到新的数据包;
- 网卡将新数据包通过DMA直接写到sk_buffer中。
当驱动处理速度跟不上网卡收包速度时,驱动来不及分配缓冲区,NIC接收到的数据包无法及时写到sk_buffer,就会产生堆积,当NIC内部缓冲区写满后,就会丢弃部分数据,引起丢包。这部分丢包为rx_fifo_errors,在 /proc/net/dev中体现为fifo字段增长,在ifconfig中体现为overruns指标增长。
通知系统内核处理(驱动与Linux内核交互)
这个时候,数据包已经被转移到了sk_buffer中。前文提到,这是驱动程序在内存中分配的一片缓冲区,并且是通过DMA写入的,这种方式不依赖CPU直接将数据写到了内存中,意味着对内核来说,其实并不知道已经有新数据到了内存中。那么如何让内核知道有新数据进来了呢?答案就是中断,通过中断告诉内核有新数据进来了,并需要进行后续处理。
提到中断,就涉及到硬中断和软中断,首先需要简单了解一下它们的区别:
硬中断: 由硬件自己生成,具有随机性,硬中断被CPU接收后,触发执行中断处理程序。中断处理程序只会处理关键性的、短时间内可以处理完的工作,剩余耗时较长工作,会放到中断之后,由软中断来完成。硬中断也被称为上半部分。
软中断: 由硬中断对应的中断处理程序生成,往往是预先在代码里实现好的,不具有随机性。(除此之外,也有应用程序触发的软中断,与本文讨论的网卡收包无关。)也被称为下半部分。
当NIC把数据包通过DMA复制到内核缓冲区sk_buffer后,NIC立即发起一个硬件中断。CPU接收后,首先进入上半部分,网卡中断对应的中断处理程序是网卡驱动程序的一部分,之后由它发起软中断,进入下半部分,开始消费sk_buffer中的数据,交给内核协议栈处理。
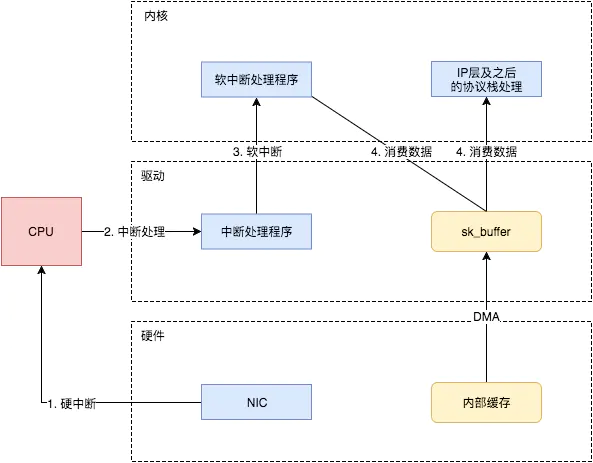
通过中断,能够快速及时地响应网卡数据请求,但如果数据量大,那么会产生大量中断请求,CPU大部分时间都忙于处理中断,效率很低。为了解决这个问题,现在的内核及驱动都采用一种叫NAPI(new API)的方式进行数据处理,其原理可以简单理解为 中断+轮询,在数据量大时,一次中断后通过轮询接收一定数量包再返回,避免产生多次中断。
网卡的基础知识
网卡本身是有内存的,每个网卡一般都有4k以上的内存,用来发送、接受数据。数据从主内存搬到网卡之后,不是立即就能被发送出去的,而是要先在网卡自身的内存中排队,再按先后顺序发送,同样的,数据从以太网传递到网卡时,网卡也是先把数据存储到自身的内存中,等到收到一帧数据了,再经过中断的方式,告诉CPU把网卡内存的数据读走(现在网卡大都支持DMA方式直接从网卡内存拷贝被内核内存),而读走后的内存,又被清空,再次被用来接收新的数据。

蓝色部分为发送数据用的页面总和,总共只有6个页面用于发送数据(40h-45h);剩余的46h-80h都是接收数据用的,而在接收数据内存中,只有红色部分是有数据的,当接收新的数据时,是向红色部分前面的绿色中的256字节写入数据,同时“把当前指针”移动到+256字节的后面(网卡自动完成),而现在要读的数据,是在“边界指针”那里开始的256字节(紫色部分),下一个要读的数据,是在“下一包指针”的位置开始的256字节,当256字节被读出来了,就变成了重新可以使用的内存,即绿色所表示,而接收数据,就是把可用的内存拿来用,即变成了红色,当数据写到了0x80h后,又从0x46h开始写数据,这样循环,如果数据满了,则网卡就不能再接收数据,必须等待数据被读出去了,才能再继续接收。
网卡到内存
网卡需要有驱动才能工作,驱动是加载到内核中的模块,负责衔接网卡和内核的网络模块,驱动在加载的时候将自己注册进网络模块,当相应的网卡收到数据包时,网络模块会调用相应的驱动程序处理数据。
下图展示了数据包(packet)如何进入内存,并被内核的网络模块开始处理:
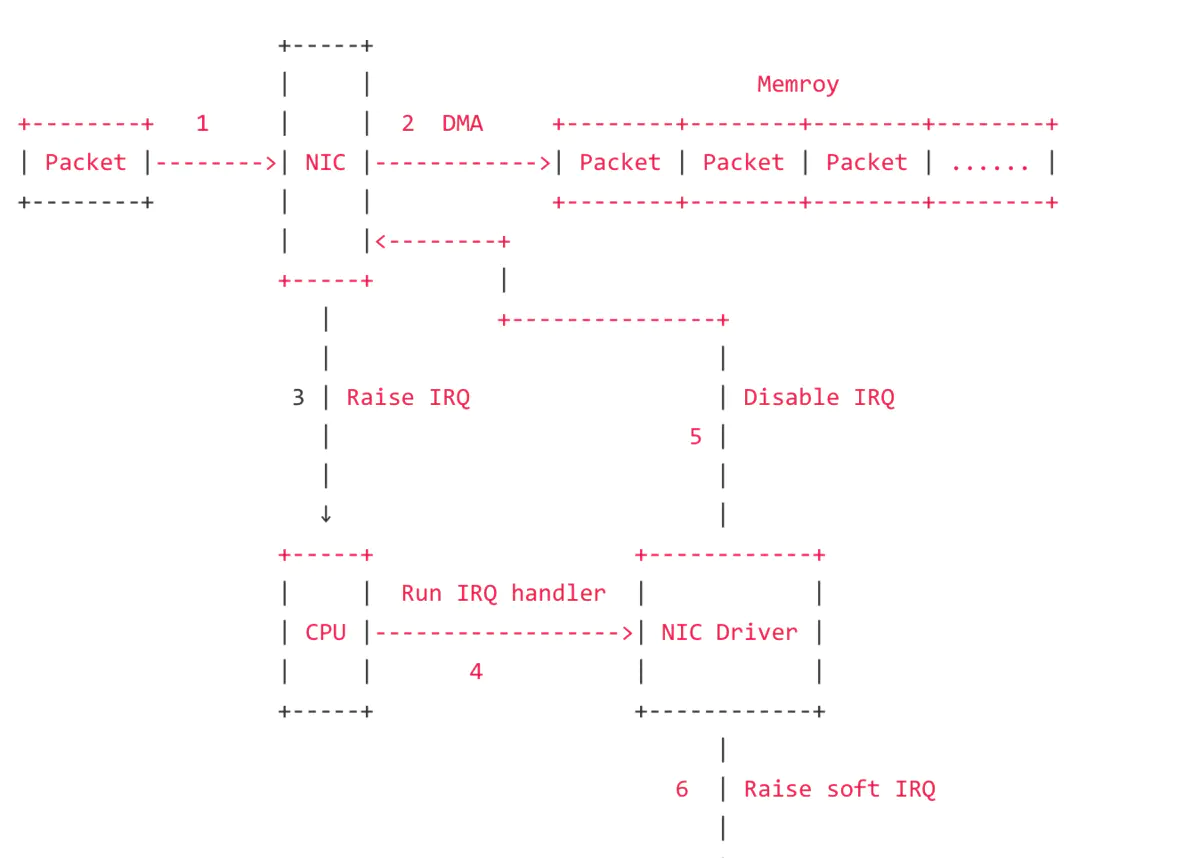
- 数据包从外面的网络进入物理网卡。如果目的地址不是该网卡,并且该网卡没有开启混杂模式,该包会被网卡丢弃。
- 网卡将数据包通过DMA的方式写入到指定的内存地址,该地址由网卡驱动分配。
- 网卡通过硬件中断(IRQ)告知cpu有数据来了。
- cpu根据中断表,调用已经注册的中断函数,这个中断函数会调动驱动程序中相应的函数
- 驱动先禁用网卡的中断,表示驱动程序已经知道内存中有数据了,告诉网卡下次再收到数据包直接写内存就可以了,不要再通知cpu了,这样可以提高效率,避免cpu不停的被中断
- 启动软中断。这步结束后,硬件中断处理函数就结束返回了,由于硬中断处理程序执行的过程中不能被中断,所以如果它执行时间过长,会导致cpu无法响应其他硬件的中断,于是内核引入软中断,这样可以将硬中断处理函数中耗时的部分移到软中断处理函数里面来慢慢处理。
内核的网络模块
软中断会触发内核网络模块中的软中断处理函数,后续流程如下:
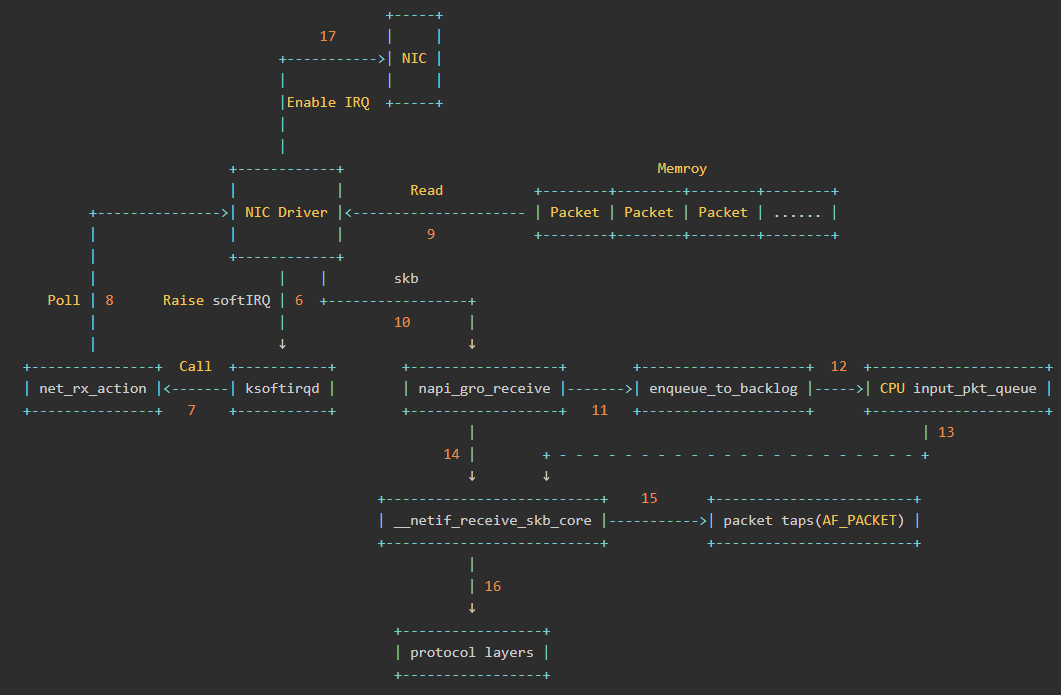
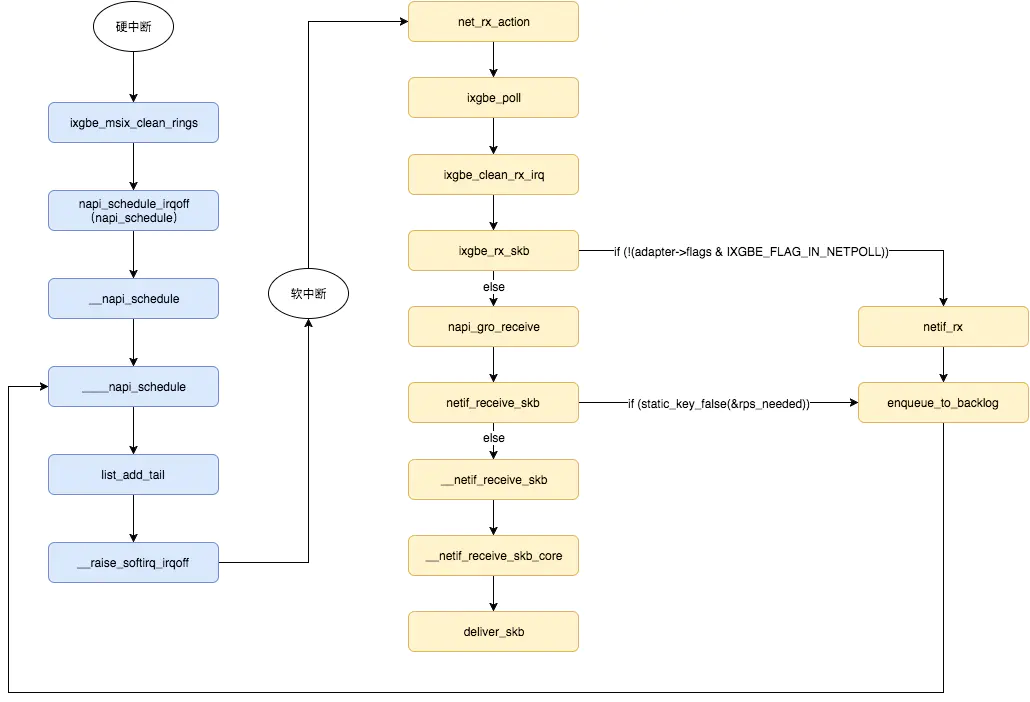
- 内核中的ksoftirqd进程专门负责软中断的处理,当它收到软中断后,就会调用相应软中断所对应的处理函数,对于上面第六步中网卡驱动模块抛出的软中断,ksoftirqd会调用网络模块的net_rx_action函数
- net_rx_action调用网卡驱动里的poll函数来一个一个的处理数据包
- 在pool函数中,驱动会一个接一个的读取网卡写到内存中的数据包,内存中数据包的格式只有驱动知道
- 驱动程序将内存中的数据包转换成内核网络模块能识别的skb格式,然后调用napi_gro_receive函数
- napi_gro_receive会处理GRO相关的内容,也就是将可以合并的数据包进行合并,这样就只需要调用一次协议栈。然后判断是否开启了RPS,如果开启了,将会调用enqueue_to_backlog
- 在enqueue_to_backlog函数中,会将数据包放入CPU的softnet_data结构体的input_pkt_queue中,然后返回,如果input_pkt_queue满了的话,该数据包将会被丢弃,queue的大小可以通过net.core.netdev_max_backlog来配置
- CPU会接着在自己的软中断上下文中处理自己input_pkt_queue里的网络数据(调用__netif_receive_skb_core)
- 如果没开启RPS,napi_gro_receive会直接调用__netif_receive_skb_core
- 看是不是有AF_PACKET类型的socket(也就是我们常说的原始套接字),如果有的话,拷贝一份数据给它。tcpdump抓包就是抓的这里的包。
- 调用协议栈相应的函数,将数据包交给协议栈处理。
- 待内存中的所有数据包被处理完成后(即poll函数执行完成),启用网卡的硬中断,这样下次网卡再收到数据的时候就会通知CPU
协议栈
IP层
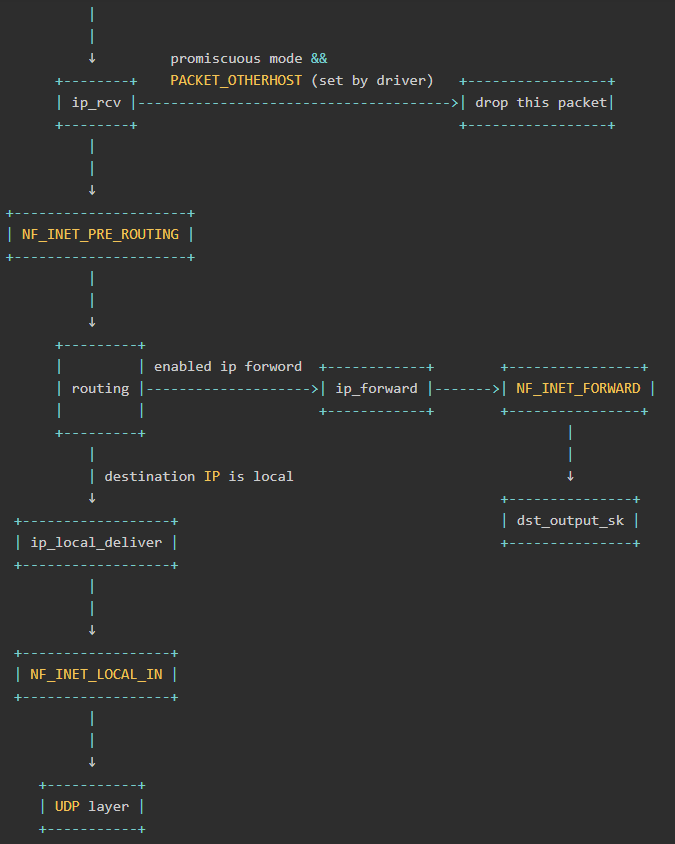
- ip_rcv: ip_rcv函数是IP模块的入口函数,在该函数里面,第一件事就是将垃圾数据包(目的mac地址不是当前网卡,但由于网卡设置了混杂模式而被接收进来)直接丢掉,然后调用注册在NF_INET_PRE_ROUTING上的函数
- NF_INET_PRE_ROUTING: netfilter放在协议栈中的钩子,可以通过iptables来注入一些数据包处理函数,用来修改或者丢弃数据包,如果数据包没被丢弃,将继续往下走
- routing: 进行路由,如果是目的IP不是本地IP,且没有开启ip forward功能,那么数据包将被丢弃,如果开启了ip forward功能,那将进入ip_forward函数
- ip_forward: ip_forward会先调用netfilter注册的NF_INET_FORWARD相关函数,如果数据包没有被丢弃,那么将继续往后调用dst_output_sk函数
- 该函数会调用IP层的相应函数将该数据包发送出去
- ip_local_deliver:如果上面routing的时候发现目的IP是本地IP,那么将会调用该函数,在该函数中,会先调用NF_INET_LOCAL_IN相关的钩子程序,如果通过,数据包将会向下发送到UDP层
UDP层

- udp_rcv: udp_rcv函数是UDP模块的入口函数,它里面会调用其它的函数,主要是做一些必要的检查,其中一个重要的调用是__udp4_lib_lookup_skb,该函数会根据目的IP和端口找对应的socket,如果没有找到相应的socket,那么该数据包将会被丢弃,否则继续
- sock_queue_rcv_skb: 主要干了两件事,一是检查这个socket的receive buffer是不是满了,如果满了的话,丢弃该数据包,然后就是调用sk_filter看这个包是否是满足条件的包,如果当前socket上设置了filter,且该包不满足条件的话,这个数据包也将被丢弃(在Linux里面,每个socket上都可以像tcpdump里面一样定义filter,不满足条件的数据包将会被丢弃)
- __skb_queue_tail: 将数据包放入socket接收队列的末尾
- sk_data_ready: 通知socket数据包已经准备好
调用完sk_data_ready之后,一个数据包处理完成,等待应用层程序来读取,上面所有函数的执行过程都在软中断的上下文中。
socket
应用层一般有两种方式接收数据,一种是recvfrom函数阻塞在那里等着数据来,这种情况下当socket收到通知后,recvfrom就会被唤醒,然后读取接收队列的数据;另一种是通过epoll或者select监听相应的socket,当收到通知后,再调用recvfrom函数去读取接收队列的数据。两种情况都能正常的接收到相应的数据包。
聊聊TCP连接耗时的那些事儿
要想搞清楚TCP连接的建立耗时,我们需要详细了解连接的建立过程。数据包从发送方出来,经过网络到达接收方的网卡。在接收方网卡将数据包DMA到RingBuffer后,内核经过硬中断、软中断等机制来处理(如果发送的是用户数据的话,最后会发送到socket的接收队列中,并唤醒用户进程)。
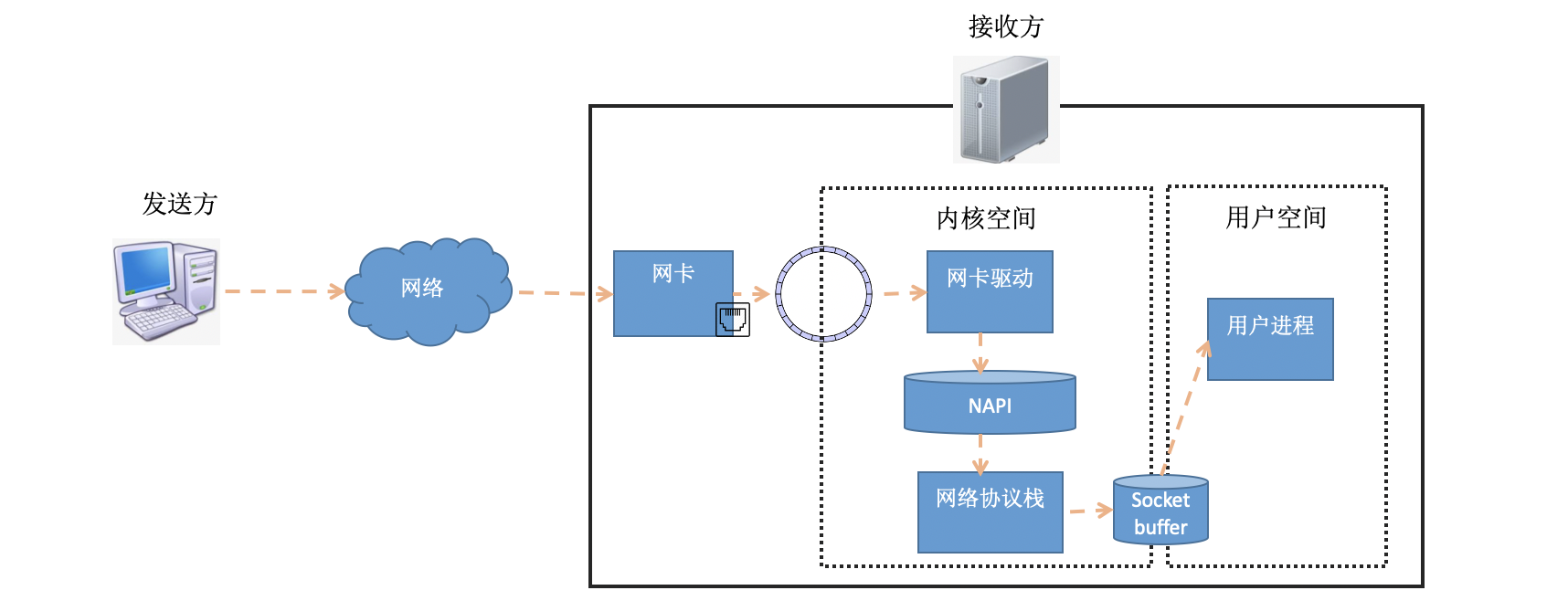
在软中断中,当一个包被内核从RingBuffer中摘下来的时候,在内核中是用struct sk_buff结构体来表示的(参见内核代码include/linux/skbuff.h)。其中的data成员是接收到的数据,在协议栈逐层被处理的时候,通过修改指针指向data的不同位置,来找到每一层协议关心的数据。
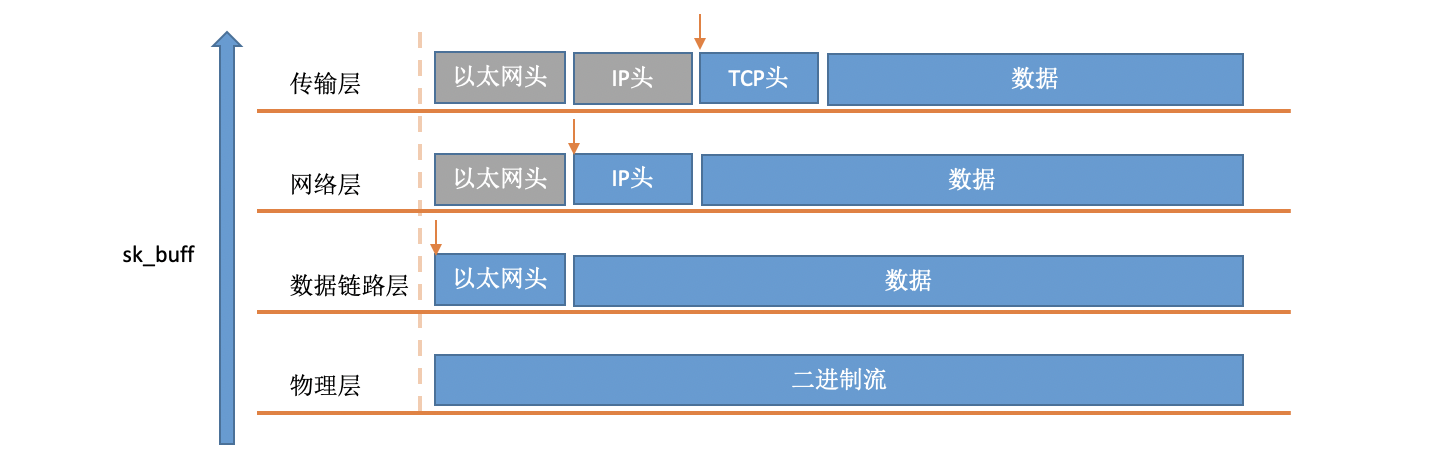
对于TCP协议包来说,它的Header中有一个重要的字段-flags。如下图:
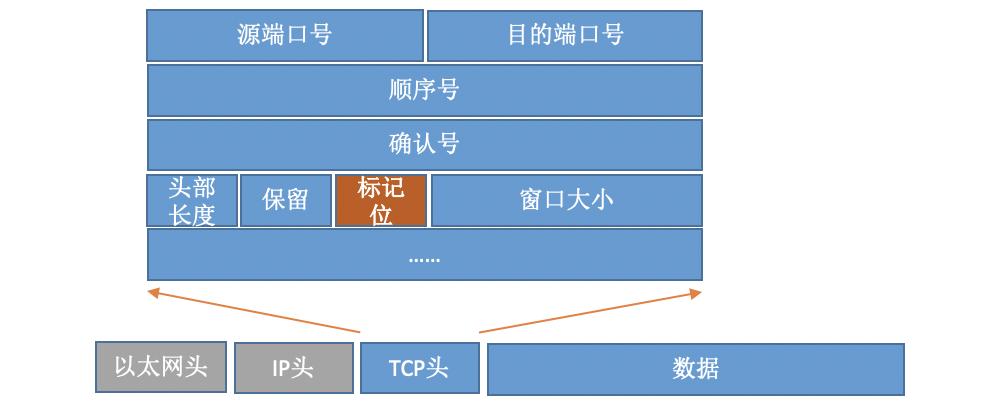
通过设置不同的标记为,将TCP包分成SYNC、FIN、ACK、RST等类型。客户端通过connect系统调用命令内核发出SYNC、ACK等包来实现和服务器TCP连接的建立。在服务器端,可能会接收许许多多的连接请求,内核还需要借助一些辅助数据结构-半连接队列和全连接队列。我们来看一下整个连接过程:
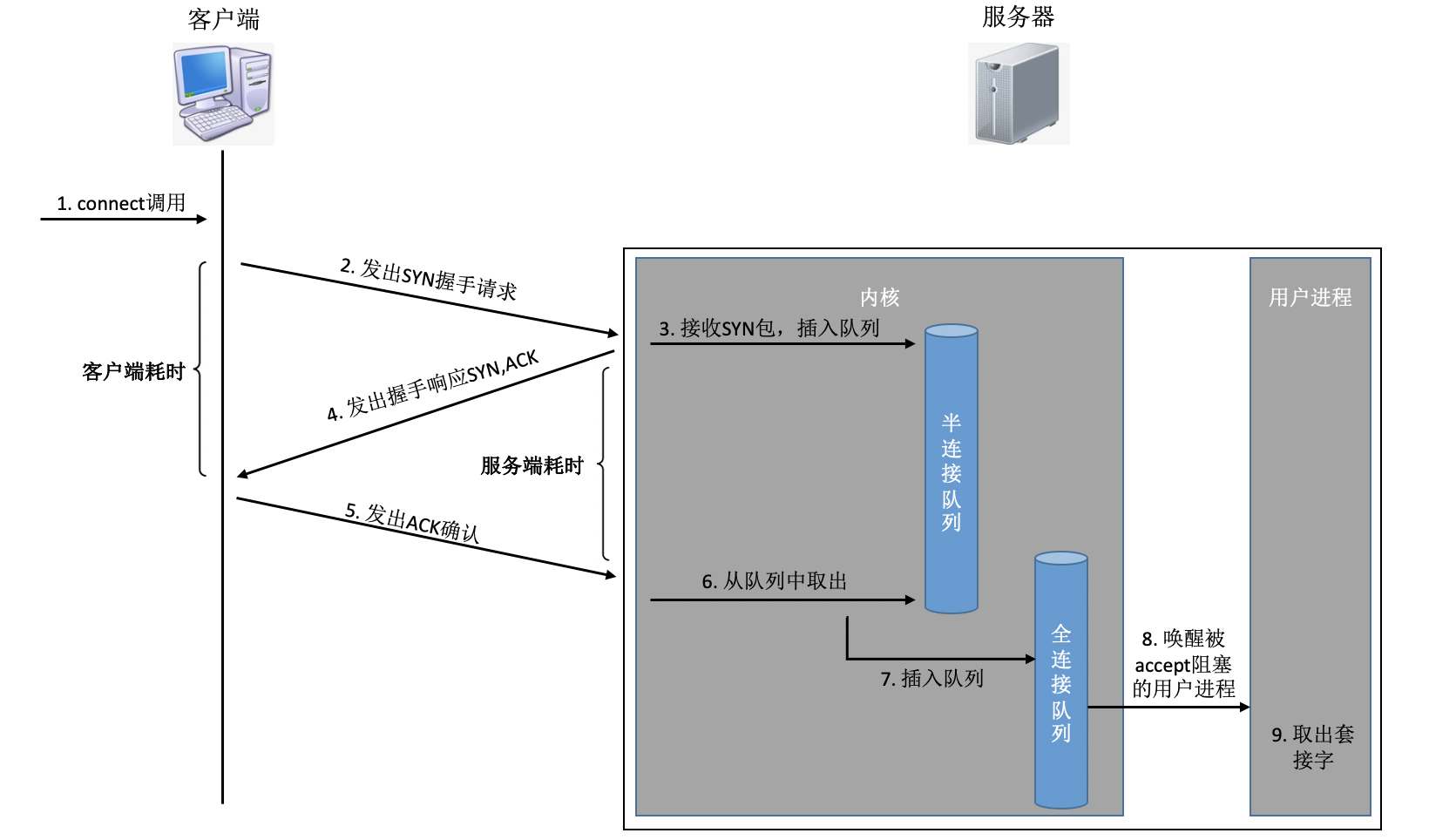
在这个连接过程中,我们来简单分析一下每一步的耗时
- 客户端发出SYNC包:客户端一般是通过connect系统调用来发出SYN的,这里牵涉到本机的系统调用和软中断的CPU耗时开销
- SYN传到服务器:SYN从客户端网卡被发出,开始“跨过山和大海,也穿过人山人海......”,这是一次长途远距离的网络传输
- 服务器处理SYN包:内核通过软中断来收包,然后放到半连接队列中,然后再发出SYN/ACK响应。又是CPU耗时开销
- SYC/ACK传到客户端:SYC/ACK从服务器端被发出后,同样跨过很多山、可能很多大海来到客户端。又一次长途网络跋涉
- 客户端处理SYN/ACK:客户端内核收包并处理SYN后,经过几us的CPU处理,接着发出ACK。同样是软中断处理开销
- ACK传到服务器:和SYN包,一样,再经过几乎同样远的路,传输一遍。 又一次长途网络跋涉
- 服务端收到ACK:服务器端内核收到并处理ACK,然后把对应的连接从半连接队列中取出来,然后放到全连接队列中。一次软中断CPU开销
- 服务器端用户进程唤醒:正在被accpet系统调用阻塞的用户进程被唤醒,然后从全连接队列中取出来已经建立好的连接。一次上下文切换的CPU开销
以上几步操作,可以简单划分为两类:
- 第一类是内核消耗CPU进行接收、发送或者是处理,包括系统调用、软中断和上下文切换。它们的耗时基本都是几个us左右。
- 第二类是网络传输,当包被从一台机器上发出以后,中间要经过各式各样的网线、各种交换机路由器。所以网络传输的耗时相比本机的CPU处理,就要高的多了。根据网络远近一般在几ms~到几百ms不等。。
1ms就等于1000us,因此网络传输耗时比双端的CPU开销要高1000倍左右,甚至更高可能还到100000倍。所以,在正常的TCP连接的建立过程中,一般可以考虑网络延时即可。一个RTT指的是包从一台服务器到另外一台服务器的一个来回的延迟时间。所以从全局来看,TCP连接建立的网络耗时大约需要三次传输,再加上少许的双方CPU开销,总共大约比1.5倍RTT大一点点。不过从客户端视角来看,只要ACK包发出了,内核就认为连接是建立成功了。所以如果在客户端打点统计TCP连接建立耗时的话,只需要两次传输耗时-既1个RTT多一点的时间。(对于服务器端视角来看同理,从SYN包收到开始算,到收到ACK,中间也是一次RTT耗时)
TCP链接建立时的异常情况
在正常情况下一次TCP连接总的耗时也就就大约是一次网络RTT的耗时。如果所有的事情都这么简单,我想我的这次分享也就没有必要了。事情不一定总是这么美好,总会有意外发生。在某些情况下,可能会导致连接时的网络传输耗时上涨、CPU处理开销增加、甚至是连接失败。现在我们说一下我在线上遇到过的各种沟沟坎坎。
1)客户端connect系统调用耗时失控
正常一个系统调用的耗时也就是几个us(微秒)左右。但是在《追踪将服务器CPU耗光的凶手!》一文中笔者的一台服务器当时遇到一个状况,某次运维同学转达过来说该服务CPU不够用了,需要扩容。当时的服务器监控如下图:
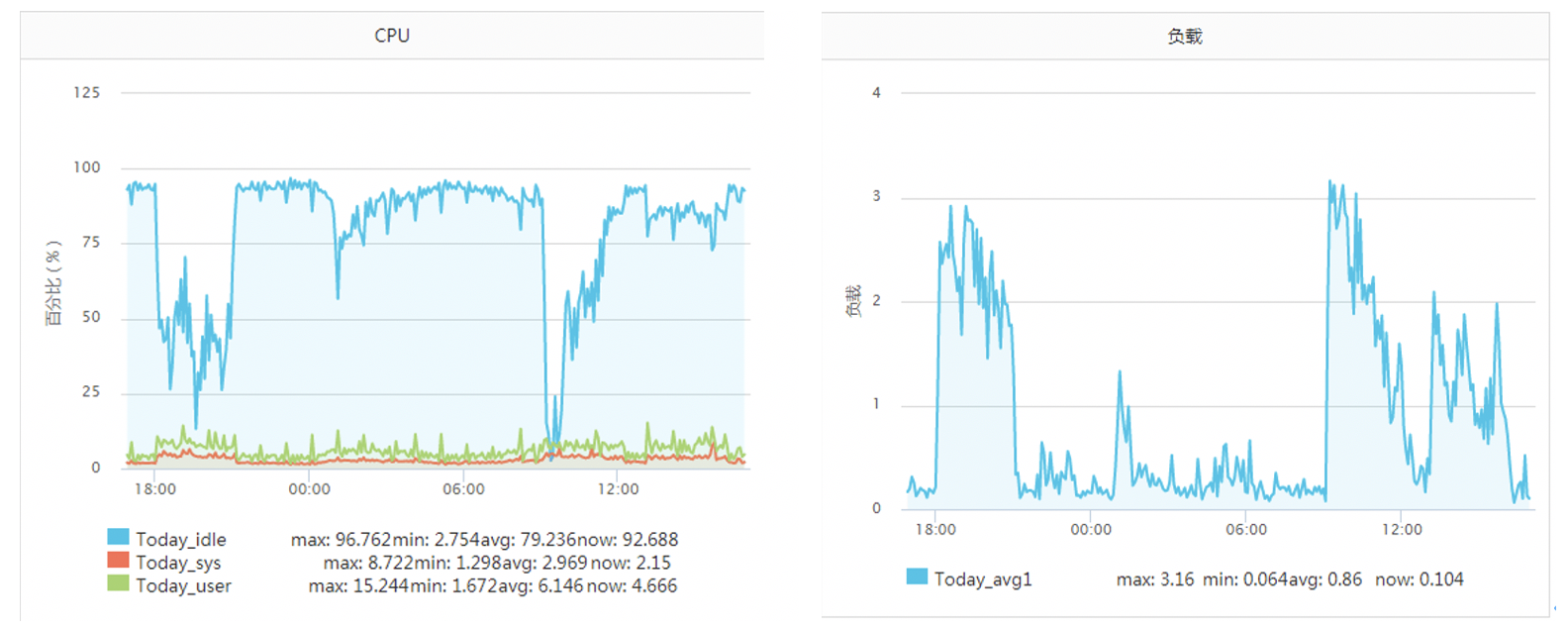
该服务之前一直每秒抗2000左右的qps,CPU的idel一直有70%+。怎么突然就CPU一下就不够用了呢。而且更奇怪的是CPU被打到谷底的那一段时间,负载却并不高(服务器为4核机器,负载3-4是比较正常的)。 后来经过排查以后发现当TCP客户端TIME_WAIT有30000左右,导致可用端口不是特别充足的时候,connect系统调用的CPU开销直接上涨了100多倍,每次耗时达到了2500us(微秒),达到了毫秒级别。
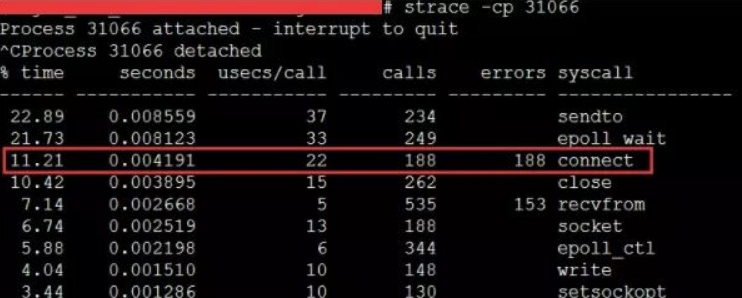
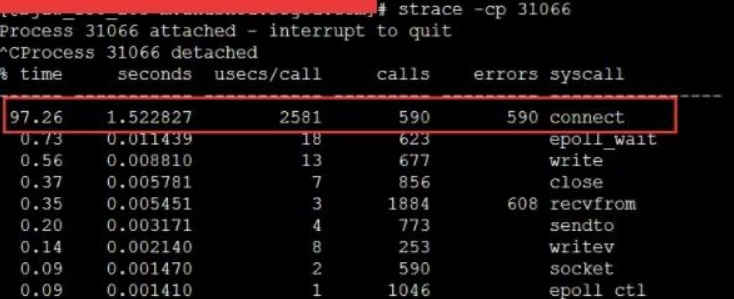
当遇到这种问题的时候,虽然TCP连接建立耗时只增加了2ms左右,整体TCP连接耗时看起来还可接受。但是这里的问题在于这2ms多都是在消耗CPU的周期,所以问题不小。 解决起来也非常简单,办法很多:修改内核参数net.ipv4.ip_local_port_range多预留一些端口号、改用长连接都可以。
2)半/全连接队列满
如果连接建立的过程中,任意一个队列满了,那么客户端发送过来的syn或者ack就会被丢弃。客户端等待很长一段时间无果后,然后会发出TCP Retransmission重传。拿半连接队列举例:
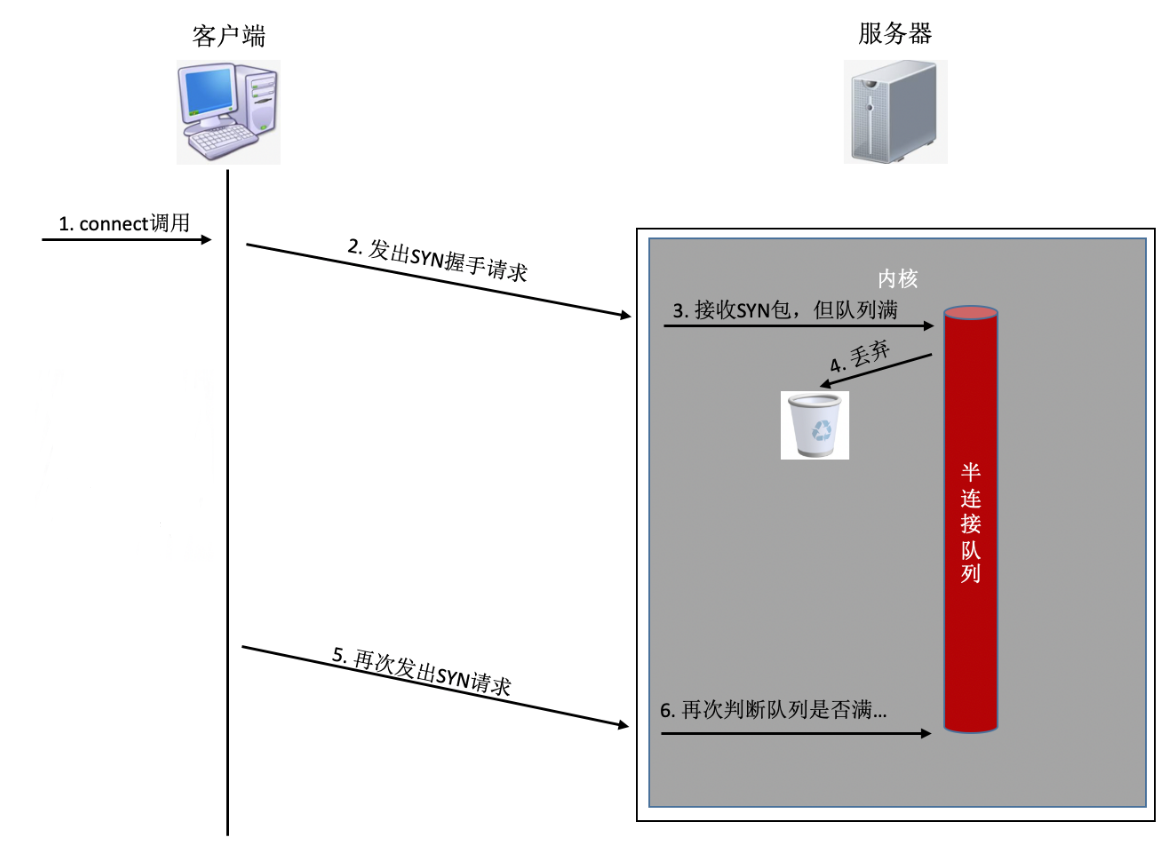
要知道的是上面TCP握手超时重传的时间是秒级别的。也就是说一旦server端的连接队列导致连接建立不成功,那么光建立连接就至少需要秒级以上。而正常的在同机房的情况下只是不到1毫秒的事情,整整高了1000倍左右。尤其是对于给用户提供实时服务的程序来说,用户体验将会受到较大影响。如果连重传也没有握手成功的话,很可能等不及二次重试,这个用户访问直接就超时了。
还有另外一个更坏的情况是,它还有可能会影响其它的用户。假如你使用的是进程/线程池这种模型提供服务,比如php-fpm。我们知道fpm进程是阻塞的,当它响应一个用户请求的时候,该进程是没有办法再响应其它请求的。假如你开了100个进程/线程,而某一段时间内有50个进程/线程卡在和redis或者mysql服务器的握手连接上了(注意:这个时候你的服务器是TCP连接的客户端一方)。这一段时间内相当于你可以用的正常工作的进程/线程只有50个了。而这个50个worker可能根本处理不过来,这时候你的服务可能就会产生拥堵。再持续稍微时间长一点的话,可能就产生雪崩了,整个服务都有可能会受影响。
既然后果有可能这么严重,那么我们如何查看我们手头的服务是否有因为半/全连接队列满的情况发生呢?在客户端,可以抓包查看是否有SYN的TCP Retransmission。如果有偶发的TCP Retransmission,那就说明对应的服务端连接队列可能有问题了。
在服务端的话,查看起来就更方便一些了。netstat -s可查看到当前系统半连接队列满导致的丢包统计,但该数字记录的是总丢包数。你需要再借助watch命令动态监控。如果下面的数字在你监控的过程中变了,那说明当前服务器有因为半连接队列满而产生的丢包。你可能需要加大你的半连接队列的长度了。
$ watch 'netstat -s | grep LISTEN'
8 SYNs to LISTEN sockets ignored
对于全连接队列来说呢,查看方法也类似。
$ watch 'netstat -s | grep overflowed'
160 times the listen queue of a socket overflowed
如果你的服务因为队列满产生丢包,其中一个做法就是加大半/全连接队列的长度。 半连接队列长度Linux内核中,主要受 tcp_max_syn_backlog 影响 加大它到一个合适的值就可以。
# cat /proc/sys/net/ipv4/tcp_max_syn_backlog
1024
# echo "2048" > /proc/sys/net/ipv4/tcp_max_syn_backlog
全连接队列长度是应用程序调用listen时传入的backlog以及内核参数net.core.somaxconn二者之中较小的那个。你可能需要同时调整你的应用程序和该内核参数。
# cat /proc/sys/net/core/somaxconn
128
# echo "256" > /proc/sys/net/core/somaxconn
改完之后我们可以通过ss命令输出的Send-Q确认最终生效长度:
$ ss -nlt
Recv-Q Send-Q Local Address:Port Address:Port
0 128 *:80 *:*
Recv-Q告诉了我们当前该进程的全连接队列使用长度情况。如果Recv-Q已经逼近了Send-Q,那么可能不需要等到丢包也应该准备加大你的全连接队列了。
如果加大队列后仍然有非常偶发的队列溢出的话,我们可以暂且容忍。如果仍然有较长时间处理不过来怎么办?另外一个做法就是直接报错,不要让客户端超时等待。例如将Redis、Mysql等后端接口的内核参数tcp_abort_on_overflow为1。如果队列满了,直接发reset给client。告诉后端进程/线程不要痴情地傻等。这时候client会收到错误“connection reset by peer”。牺牲一个用户的访问请求,要比把整个站都搞崩了还是要强的。
结论
TCP连接建立异常情况下,可能需要好几秒,一个坏处就是会影响用户体验,甚至导致当前用户访问超时都有可能。另外一个坏处是可能会诱发雪崩。所以当你的服务器使用短连接的方式访问数据的时候,一定要学会要监控你的服务器的连接建立是否有异常状态发生。如果有,学会优化掉它。当然你也可以采用本机内存缓存,或者使用连接池来保持长连接,通过这两种方式直接避免掉TCP握手挥手的各种开销也可以。
再说正常情况下,TCP建立的延时大约就是两台机器之间的一个RTT耗时,这是避免不了的。但是你可以控制两台机器之间的物理距离来降低这个RTT,比如把你要访问的redis尽可能地部署的离后端接口机器近一点,这样RTT也能从几十ms削减到最低可能零点几ms。
最后我们再思考一下,如果我们把服务器部署在北京,给纽约的用户访问可行吗? 前面的我们同机房也好,跨机房也好,电信号传输的耗时基本可以忽略(因为物理距离很近),网络延迟基本上是转发设备占用的耗时。但是如果是跨越了半个地球的话,电信号的传输耗时我们可得算一算了。 北京到纽约的球面距离大概是15000公里,那么抛开设备转发延迟,仅仅光速传播一个来回(RTT是Rround trip time,要跑两次),需要时间 = 15,000,000 *2 / 光速 = 100ms。实际的延迟可能比这个还要大一些,一般都得200ms以上。建立在这个延迟上,要想提供用户能访问的秒级服务就很困难了。所以对于海外用户,最好都要在当地建机房或者购买海外的服务器。
TCP三次握手深度理解
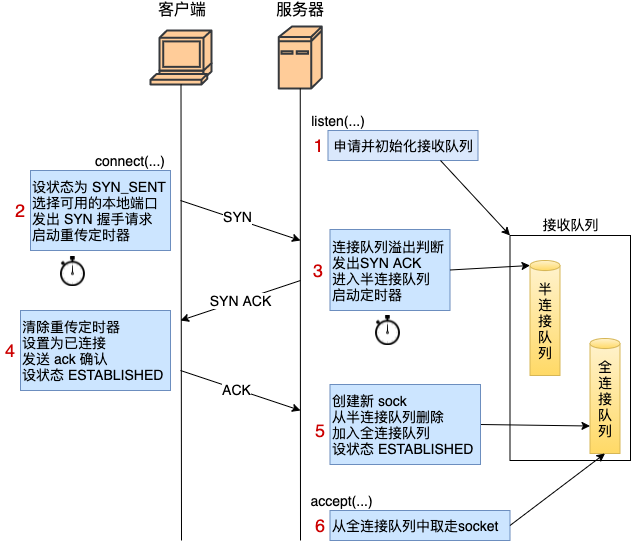
- 服务器 listen 时,计算了全/半连接队列的长度,还申请了相关内存并初始化。
- 客户端 connect 时,把本地 socket 状态设置成了 TCP_SYN_SENT,选则一个可用的端口,发出 SYN 握手请求并启动重传定时器。
- 服务器响应 ack 时,会判断下接收队列是否满了,满的话可能会丢弃该请求。否则发出 synack,申请 request_sock 添加到半连接队列中,同时启动定时器。
- 客户端响应 synack 时,清除了 connect 时设置的重传定时器,把当前 socket 状态设置为 ESTABLISHED,开启保活计时器后发出第三次握手的 ack 确认。
- 服务器响应 ack 时,把对应半连接对象删除,创建了新的 sock 后加入到全连接队列中,最后将新连接状态设置为 ESTABLISHED。
- accept 从已经建立好的全连接队列中取出一个返回给用户进程。
另外要注意的是,如果握手过程中发生丢包(网络问题,或者是连接队列溢出),内核会等待定时器到期后重试,重试时间间隔在 3.10 版本里分别是 1s 2s 4s ...。在一些老版本里,比如 2.6 里,第一次重试时间是 3 秒。最大重试次数分别由 tcp_syn_retries 和 tcp_synack_retries 控制。
如果你的线上接口正常都是几十毫秒内返回,但偶尔出现了 1 s、或者 3 s 等这种偶发的响应耗时变长的问题,那么你就要去定位一下看看是不是出现了握手包的超时重传了。
为什么服务端程序都需要先 listen 一下?
服务器端 socket 程序流程:先 bind、再 listen、然后才能 accept。至于为什么需要先 listen 一下才可以 accpet,似乎我们很少去关注。
listen 最主要的工作就是申请和初始化接收队列,包括全连接队列和半连接队列。其中全连接队列是一个链表,而半连接队列由于需要快速的查找,所以使用的是一个哈希表(其实半连接队列更准确的的叫法应该叫半连接哈希表)。
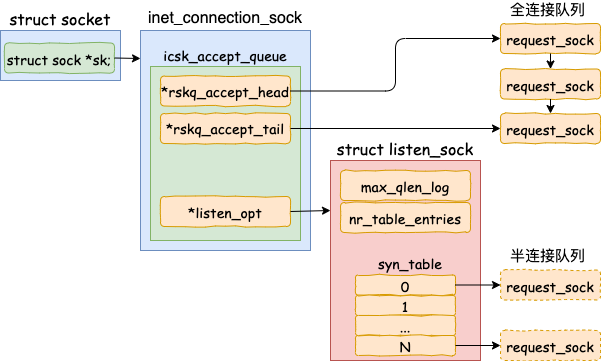
全/半两个队列是三次握手中很重要的两个数据结构,有了它们服务器才能正常响应来自客户端的三次握手。所以服务器端都需要 listen 一下才行。
除此之外我们还有额外收获,我们还知道了内核是如何确定全/半连接队列的长度的。
- 全连接队列的长度
对于全连接队列来说,其最大长度是 listen 时传入的 backlog 和 net.core.somaxconn 之间较小的那个值。如果需要加大全连接队列长度,那么就是调整 backlog 和 somaxconn。 - 半连接队列的长度
在 listen 的过程中,内核我们也看到了对于半连接队列来说,其最大长度是 min(backlog, somaxconn, tcp_max_syn_backlog) + 1 再上取整到 2 的幂次,但最小不能小于16。如果需要加大半连接队列长度,那么需要一并考虑 backlog,somaxconn 和 tcp_max_syn_backlog 这三个参数。网上任何告诉你修改某一个参数就能提高半连接队列长度的文章都是错的。
挑战Redis单实例内存最大极限,“遭遇”NUMA陷阱!
话说NUMA陷阱
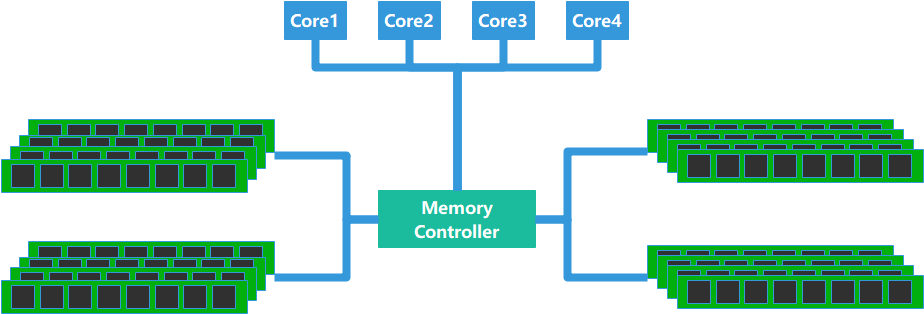
SMP 架构
NUMA 架构
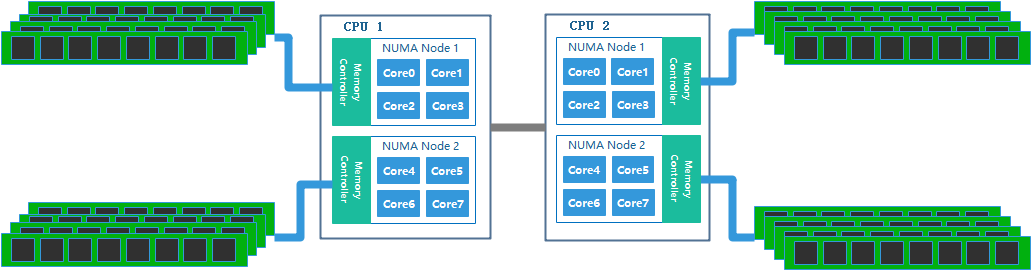
NUMA陷阱指的是引入QPI总线后,在计算机系统里可能会存在的一个坑。大致的意思就是如果你的机器打开了numa,那么你的内存即使在充足的情况下,也会使用磁盘上的swap,导致性能低下。原因就是NUMA为了高效,会仅仅只从你的当前node里分配内存,只要当前node里用光了(即使其它node还有),也仍然会启用硬盘swap。
当我第一次听说到这个概念的时候,不禁感叹我运气好,我的Redis实例貌似从来没有掉进这个陷阱里过。那为了以后也别栽坑,赶紧去了解了下我的机器的numa状态:
# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17
node 0 size: 32756 MB
node 0 free: 19642 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23
node 1 size: 32768 MB
node 1 free: 18652 MB
node distances:
node 0 1
0: 10 21
1: 21 10
上面结果说明我们有两个node,node0和node1,分别有12个核心,各有32GB的内存。 再看zone_reclaim_mode,它用来管理当一个内存区域(zone)内部的内存耗尽时,是从其内部进行内存回收还是可以从其他zone进行回收的选项:
0 关闭zone_reclaim模式,可以从其他zone或NUMA节点回收内存
1 打开zone_reclaim模式,这样内存回收只会发生在本地节点内
2 在本地回收内存时,可以将cache中的脏数据写回硬盘,以回收内存
4 在本地回收内存时,表示可以用Swap 方式回收内存
cat /proc/sys/vm/zone_reclaim_mode
1
额,好吧。我的这台机器上的zone_reclaim_mode还真是1,只会在本地节点回收内存。
实践捕捉numa陷阱未遂
那我的好奇心就来了,既然我的单个node节点只有32G,那我部署一个50G的Redis,给它填满数据试试到底会不会发生swap。
实验开始,我先查看了本地总内存,以及各个node的内存剩余状况。
# top
......
Mem: 65961428k total, 26748124k used, 39213304k free, 632832k buffers
Swap: 8388600k total, 0k used, 8388600k free, 1408376k cached
# cat /proc/zoneinfo"
......
Node 0, zone Normal
pages free 4651908
Node 1, zone Normal
pages free 4773314
总内存不用解释,/proc/zoneinfo里包含了node可供应用程序申请的free pages。node1有4651908个页面,4651908*4K=18G的可用内存。
接下来让我们启动redis实例,把其内存上限设置到超过单个node里的内存大小。我这里单node内存大小是32G,我把redis设置成了50G。开始灌入数据。最终数据全部灌完之后,
# top
Mem: 65961428k total, 53140400k used, 12821028k free, 637112k buffers
Swap: 8388600k total, 0k used, 8388600k free, 1072524k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8356 root 20 0 62.8g 46g 1292 S 0.0 74.5 3:45.34 redis-server
# cat /proc/zoneinfo | grep "pages free"
pages free 3935
pages free 347180
pages free 1402744
pages free 1501670
实验证明,在zone_reclaim_mode为1的情况下,Redis是平均在两个node里申请节点的,并没有固定在某一个cpu里。
莫非是大佬们的忠告错了吗?其实不是,如果不绑定亲和性的话,分配内存是当进程在哪个node上的CPU发起内存申请,就优先在哪个node里分配内存。之所以是平均分配在两个node里,是因为redis-server进程实验中经常会进入主动睡眠状态,醒来后可能CPU就换了。所以基本上,最后看起来内存是平均分配的。如下图,CPU进行了500万次的上下文切换,用top命令看到cpu也是在node0和node1跳来跳去。
# grep ctxt /proc/8356/status
voluntary_ctxt_switches: 5259503
nonvoluntary_ctxt_switches: 1449
改进方法,成功抓获numa陷阱
杀死进程,内存归位
# cat /proc/zoneinfo
Node 0, zone Normal
pages free 7597369
Node 1, zone Normal
pages free 7686732
绑定CPU和内存的亲和性,然后再启动。
numactl --cpunodebind=0 --membind=0 /search/odin/daemon/redis/bin/redis-server /search/odin/daemon/redis/conf/redis.conf
top命令观察到CPU确实一直在node0的节点里。node里的内存也在快速消耗。
# cat /proc/zoneinfo
Node 0, zone Normal
pages free 10697
Node 1, zone Normal
pages free 7686732
看,内存很快就消耗光了。我们再看top命令观察到的swap,很激动地发现,我终于陷入到传说中的numa陷阱了。
Tasks: 603 total, 2 running, 601 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.7%us, 5.4%sy, 0.0%ni, 85.6%id, 8.2%wa, 0.0%hi, 0.1%si, 0.0%st
Mem: 65961428k total, 34530000k used, 31431428k free, 319156k buffers
Swap: 8388600k total, 6000792k used, 2387808k free, 777584k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
258 root 20 0 0 0 0 R 72.3 0.0 0:17.18 kswapd0
25934 root 20 0 37.5g 30g 1224 D 71.6 48.7 1:06.09 redis-server
这时候,Redis实际使用的物理内存RES定格到了30g不再上涨,而是开始消耗Swap。
又过了一会儿,Redis被oom给kill了。
结论
通过今天的实验,我们可以发现确实有NUMA陷阱这种东西存在。不过那是我手工通过numactl指令绑定cpu和mem的亲和性后才遭遇的。相信国内绝大部分的线上Redis没有进行这个绑定,所以理论上来单Redis单实例可以使用到整个机器的物理内存。(实践中最好不要这么干,你的大部分内存都绑定到一个redis进程里的话,那其它CPU核就没啥事干了,浪费了CPU的多核计算能力)
扩展
当通过numactl绑定CPU和mem都在一个node里的时候,内存IO不需要经过总线,性能会比较高,你Redis的QPS能力也会上涨。和跨node的内存IO性能对比,可以下面的实例,就是10:21的区别。
# numactl --hardware
......
node distances:
node 0 1
0: 10 21
1: 21 10
TCP连接中客户端的端口号是如何确定的?
客户端建立连接前需要确定一个端口,该端口会在两个位置进行确定。
第一个位置,也是最主要的确定时机是 connect 系统调用执行过程。在 connect 的时候,会随机地从 ip_local_port_range 选择一个位置开始循环判断。找到可用端口后,发出 syn 握手包。如果端口查找失败,会报错 “Cannot assign requested address”。这个时候你应该首先想到去检查一下服务器上的 net.ipv4.ip_local_port_range 参数,是不是可以再放的多一些。
如果你因为某种原因不希望某些端口被使用到,那么就把它们写到 ip_local_reserved_ports 这个内核参数中就行了,内核在选择的时候会跳过这些端口。
另外注意即使是一个端口是可以被用于多条 TCP 连接的。所以一台客户端机最大能建立的连接数并不是 65535。只要 server 足够多,单机发出百万条连接没有任何问题。
我给大伙儿贴一下我实验时候在客户机上实验时的实际截图,来实际看一下一个端口号确实是被用在了多条连接上了。
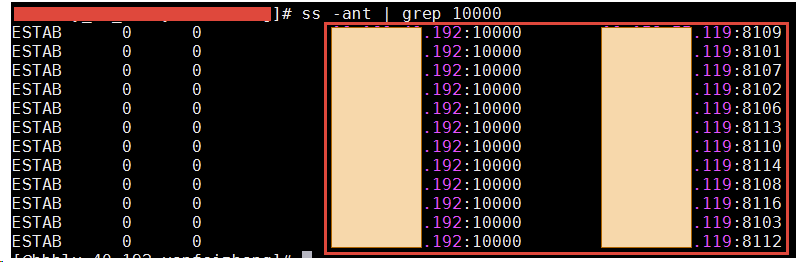
截图中左边的 192 是客户端,右边的 119 是服务器的 ip。可以看到客户端的 10000 这个端口号是用在了多条连接上了的。
第二个位置,如果在 connect 之前使用了 bind,将会使得 connect 时的端口选择方式无效。转而使用 bind 时确定的端口。bind 时如果传入了端口号,会尝试首先使用该端口号,如果传入了 0 ,也会自动选择一个。但默认情况下一个端口只会被使用一次。所以对于客户端角色的 socket,不建议使用 bind !
最后我再想多说一句,上面的选择端口的都是从 ip_local_port_range 范围中的某一个随机位置开始循环的。如果可用端口很充足,则能快一点找到可用端口,那循环很快就能退出。假设实际中 ip_local_port_range 中的端口快被用光了,这时候内核就大概率得把循环多执行很多轮才能找到,这会导致 connect 系统调用的 CPU 开销的上涨。
所以,最好不要等到端口不够用了才加大 ip_local_port_range 的范围,而是事先就应该保持一个充足的范围。
TCP 的这些内存开销
一条空的 ESTAB 状态的 TCP 链接消耗 3.3KB 左右的内存。
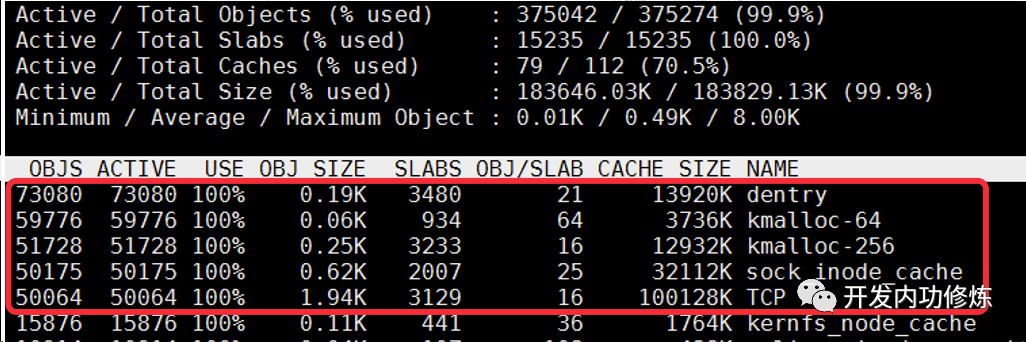
每条链接都分别消耗了 TCP、dentry 等 5 个内核对象。
| 序号 | TCP 状态 | 收发数据 | 客户端单 socket | 服务端单 socket | 备注 |
|---|---|---|---|---|---|
| 实验1 | ESTAB | 无 | 3.42K | 3.27K | socket_alloc 等核心内核对象 |
| 实验2 | ESTAB | 客户端发送服务器不收 | 7.66K | 5.47 K | 客户端的发送缓存区没回收,服务器也多了接收缓存区 |
| 实验2 | ESTAB | 客户端发送服务器接收 | 7.66K | 3.24 K | 服务器接收缓存区用完回收了 |
| 实验3 | ESTAB | 服务器发送客户端不收 | 4.82K | 3.39K | 服务端发送缓存区及时回收了,客户端多了 size-1024 等内核对象 |
| 实验3 | ESTAB | 服务器发送客户端接收 | 3.56K | 3.39K | 客户端接收缓存区用完回收了 |
| 实验4 | TIME_WAIT | 无 | 0.5K | 0K | TIME_WAIT 下会回收无用对象,服务端就直接关闭了。 |
图解Linux网络包接收过程
一、Linux网络收包总览
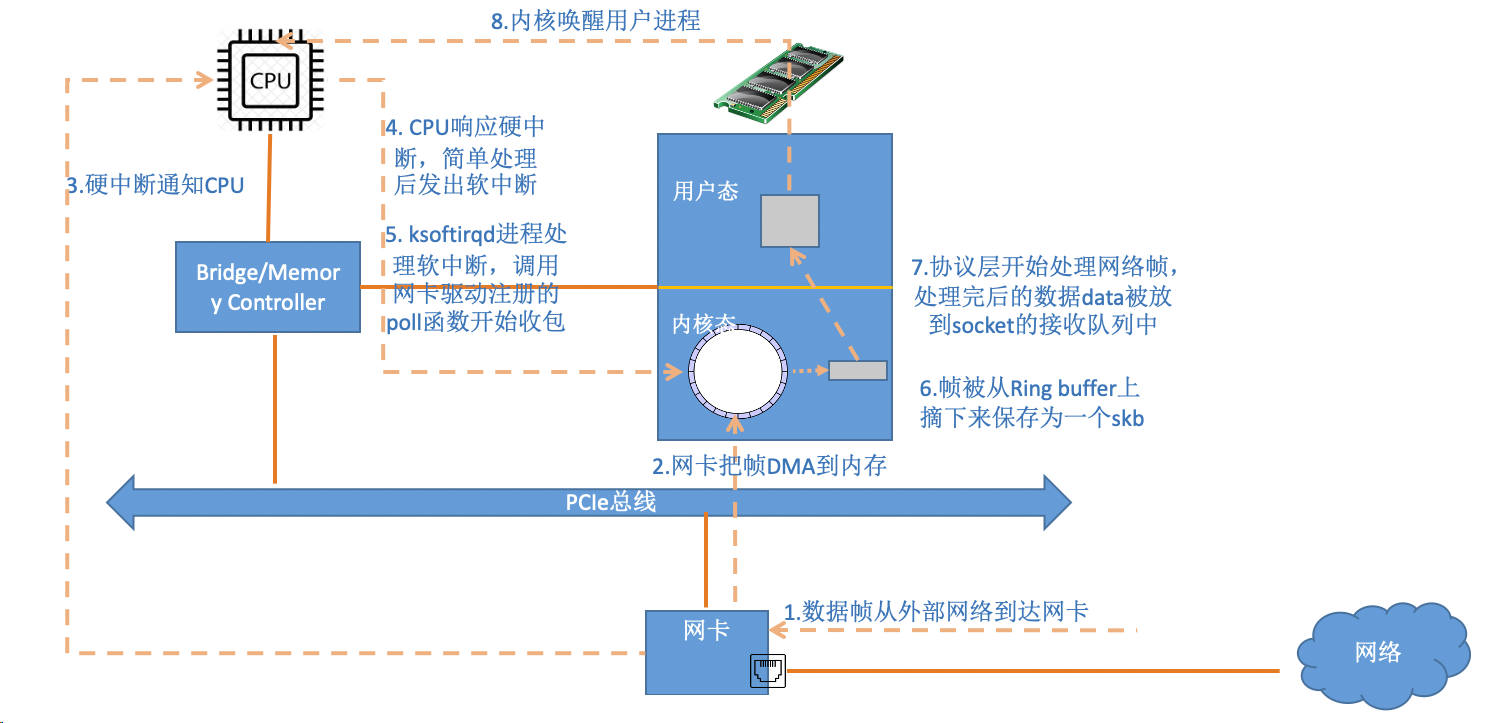
当网卡上收到数据以后,Linux中第一个工作的模块是网络驱动。 网络驱动会以DMA的方式把网卡上收到的帧写到内存里。再向CPU发起一个中断,以通知CPU有数据到达。第二,当CPU收到中断请求后,会去调用网络驱动注册的中断处理函数。 网卡的中断处理函数并不做过多工作,发出软中断请求,然后尽快释放CPU。ksoftirqd检测到有软中断请求到达,调用poll开始轮询收包,收到后交由各级协议栈处理。对于UPD包来说,会被放到用户socket的接收队列中。
我这里先给大家准备了一个总的流程图,简单阐述下 send 发送了的数据是如何一步一步被发送到网卡的。
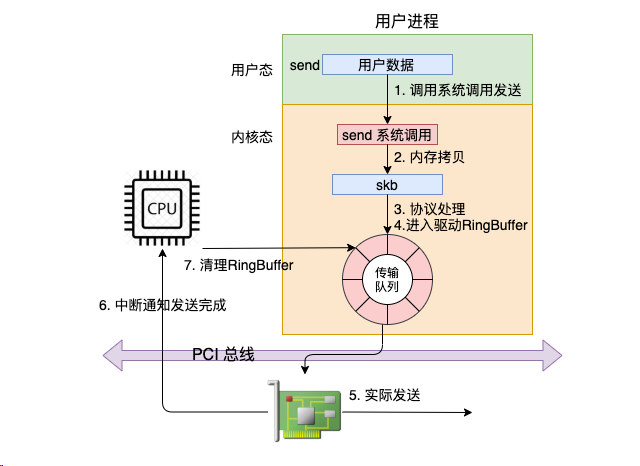
在这幅图中,我们看到用户数据被拷贝到内核态,然后经过协议栈处理后进入到了 RingBuffer 中。随后网卡驱动真正将数据发送了出去。当发送完成的时候,是通过硬中断来通知 CPU,然后清理 RingBuffer。
二、Linux启动
Linux驱动,内核协议栈等等模块在具备接收网卡数据包之前,要做很多的准备工作才行。比如要提前创建好ksoftirqd内核线程,要注册好各个协议对应的处理函数,王阔设备子系统要提前初始化好,网卡要启动好。只有这些都Ready之后,我们才能真正开始接收数据包。那么我们现在来看看这些准备工作都是怎么做的。
2.1 创建ksoftirqd内核进程
Linux的软中断都是在专门的内核线程(ksoftirqd)中进行的,因此我们非常有必要看一下这些进程是怎么初始化的,这样我们才能在后面更准确地了解收包过程。该进程数量不是1个,而是N个,其中N等于你的机器的核数。

当ksoftirqd被创建出来以后,它就会进入自己的线程循环函数ksoftirqd_should_run和run_ksoftirqd了。不停地判断有没有软中断需要被处理。这里需要注意的一点是,软中断不仅仅只有网络软中断,还有其它类型。
2.2 网络子系统初始化
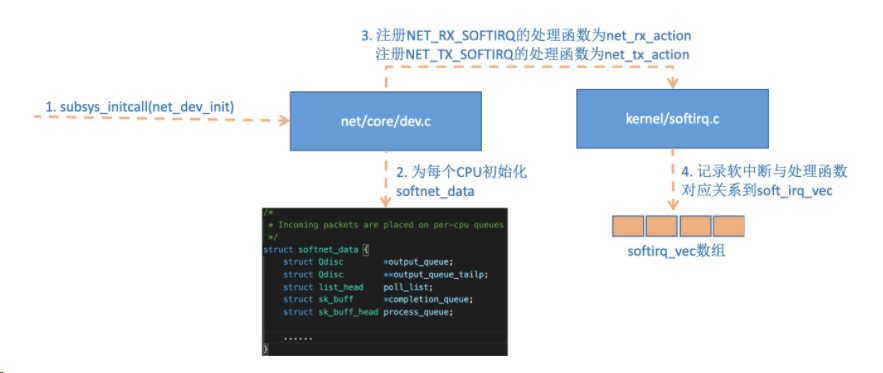
linux内核通过调用subsys_initcall来初始化各个子系统,在源代码目录里你可以grep出许多对这个函数的调用。这里我们要说的是网络子系统的初始化,会执行到net_dev_init函数。
在这个函数里,会为每个CPU都申请一个softnet_data数据结构,在这个数据结构里的poll_list是等待驱动程序将其poll函数注册进来,稍后网卡驱动初始化的时候我们可以看到这一过程。
另外open_softirq注册了每一种软中断都注册一个处理函数。 NET_TX_SOFTIRQ的处理函数为net_tx_action,NET_RX_SOFTIRQ的为net_rx_action。继续跟踪open_softirq后发现这个注册的方式是记录在softirq_vec变量里的。后面ksoftirqd线程收到软中断的时候,也会使用这个变量来找到每一种软中断对应的处理函数。
2.3 协议栈注册
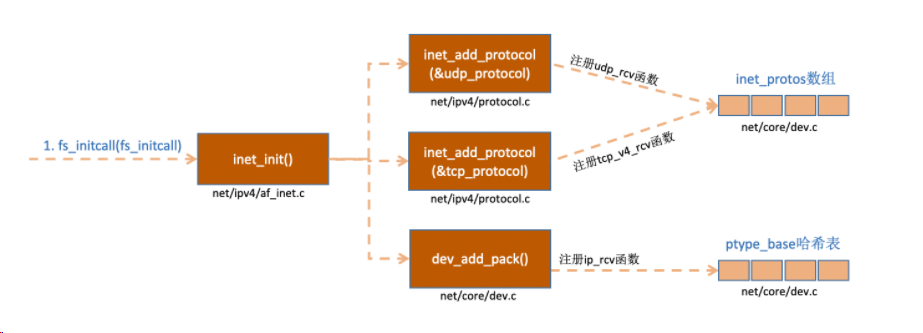
内核实现了网络层的ip协议,也实现了传输层的tcp协议和udp协议。 这些协议对应的实现函数分别是ip_rcv(),tcp_v4_rcv()和upd_rcv()。和我们平时写代码的方式不一样的是,内核是通过注册的方式来实现的。 Linux内核中的fs_initcall和subsys_initcall类似,也是初始化模块的入口。fs_initcall调用inet_init后开始网络协议栈注册。 通过inet_init,将这些函数注册到了inet_protos和ptype_base数据结构中了。如下图:
2.4 网卡驱动初始化
每一个驱动程序(不仅仅只是网卡驱动)会使用 module_init 向内核注册一个初始化函数,当驱动被加载时,内核会调用这个函数。比如igb网卡驱动的代码位于drivers/net/ethernet/intel/igb/igb_main.c
驱动的pci_register_driver调用完成后,Linux内核就知道了该驱动的相关信息,比如igb网卡驱动的igb_driver_name和igb_probe函数地址等等。当网卡设备被识别以后,内核会调用其驱动的probe方法(igb_driver的probe方法是igb_probe)。驱动probe方法执行的目的就是让设备ready,对于igb网卡,其igb_probe位于drivers/net/ethernet/intel/igb/igb_main.c下。主要执行的操作如下:

第5步中我们看到,网卡驱动实现了ethtool所需要的接口,也在这里注册完成函数地址的注册。当 ethtool 发起一个系统调用之后,内核会找到对应操作的回调函数。对于igb网卡来说,其实现函数都在drivers/net/ethernet/intel/igb/igb_ethtool.c下。 相信你这次能彻底理解ethtool的工作原理了吧? 这个命令之所以能查看网卡收发包统计、能修改网卡自适应模式、能调整RX 队列的数量和大小,是因为ethtool命令最终调用到了网卡驱动的相应方法,而不是ethtool本身有这个超能力。
第6步注册的igb_netdev_ops中包含的是igb_open等函数,该函数在网卡被启动的时候会被调用。
第7步中,在igb_probe初始化过程中,还调用到了igb_alloc_q_vector。他注册了一个NAPI机制所必须的poll函数,对于igb网卡驱动来说,这个函数就是igb_poll
2.5 启动网卡
当上面的初始化都完成以后,就可以启动网卡了。回忆前面网卡驱动初始化时,我们提到了驱动向内核注册了 structure net_device_ops 变量,它包含着网卡启用、发包、设置mac 地址等回调函数(函数指针)。当启用一个网卡时(例如,通过 ifconfig eth0 up),net_device_ops 中的 igb_open方法会被调用。它通常会做以下事情:

在上面的代码中跟踪函数调用, __igb_open => igb_request_irq => igb_request_msix, 在igb_request_msix中我们看到了,对于多队列的网卡,为每一个队列都注册了中断,其对应的中断处理函数是igb_msix_ring(该函数也在drivers/net/ethernet/intel/igb/igb_main.c下)。 我们也可以看到,msix方式下,每个 RX 队列有独立的MSI-X 中断,从网卡硬件中断的层面就可以设置让收到的包被不同的 CPU处理。(可以通过 irqbalance ,或者修改 /proc/irq/IRQ_NUMBER/smp_affinity能够修改和CPU的绑定行为)。
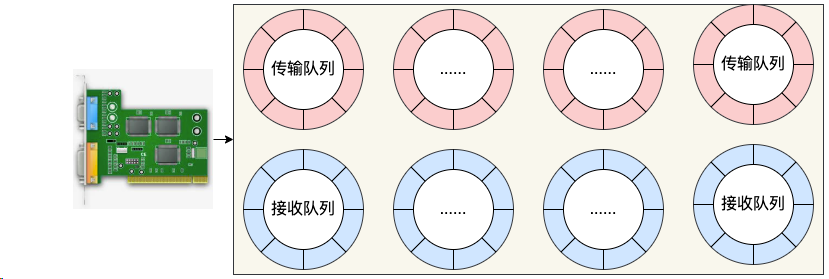
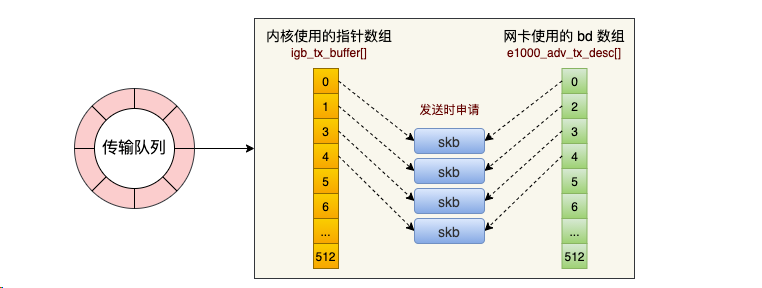
现在的服务器上的网卡一般都是支持多队列的。每一个队列上都是由一个 RingBuffer 表示的,开启了多队列以后的的网卡就会对应有多个 RingBuffer。
三、迎接数据的到来
3.1 硬中断处理
首先当数据帧从网线到达网卡上的时候,第一站是网卡的接收队列。网卡在分配给自己的RingBuffer中寻找可用的内存位置,找到后DMA引擎会把数据DMA到网卡之前关联的内存里,这个时候CPU都是无感的。当DMA操作完成以后,网卡会像CPU发起一个硬中断,通知CPU有数据到达。
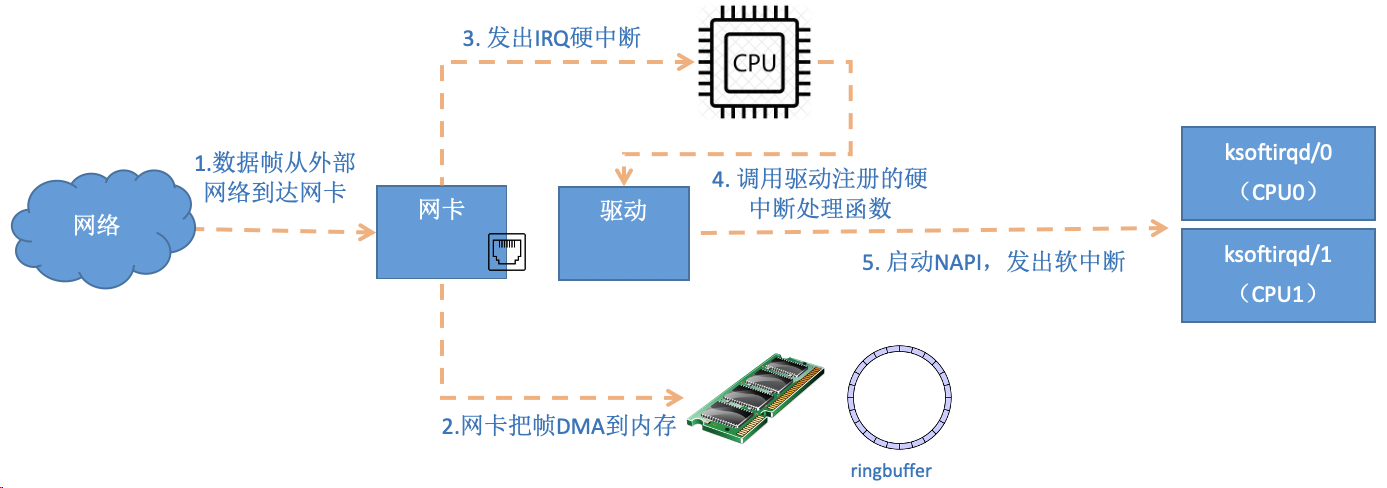
注意:当RingBuffer满的时候,新来的数据包将给丢弃。ifconfig查看网卡的时候,可以里面有个overruns,表示因为环形队列满被丢弃的包。如果发现有丢包,可能需要通过ethtool命令来加大环形队列的长度。
我们说过,Linux在硬中断里只完成简单必要的工作,剩下的大部分的处理都是转交给软中断的。通过上面代码可以看到,硬中断处理过程真的是非常短。只是记录了一个寄存器,修改了一下下CPU的poll_list,然后发出个软中断。就这么简单,硬中断工作就算是完成了。
3.2 ksoftirqd内核线程处理软中断
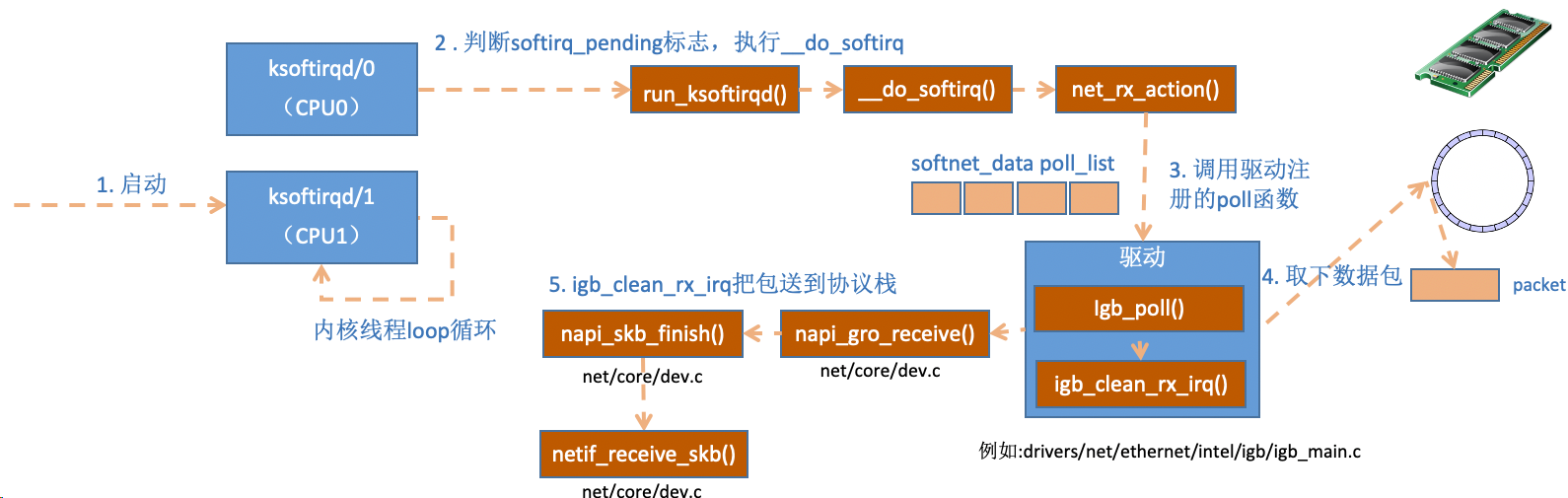
3.3 网络协议栈处理
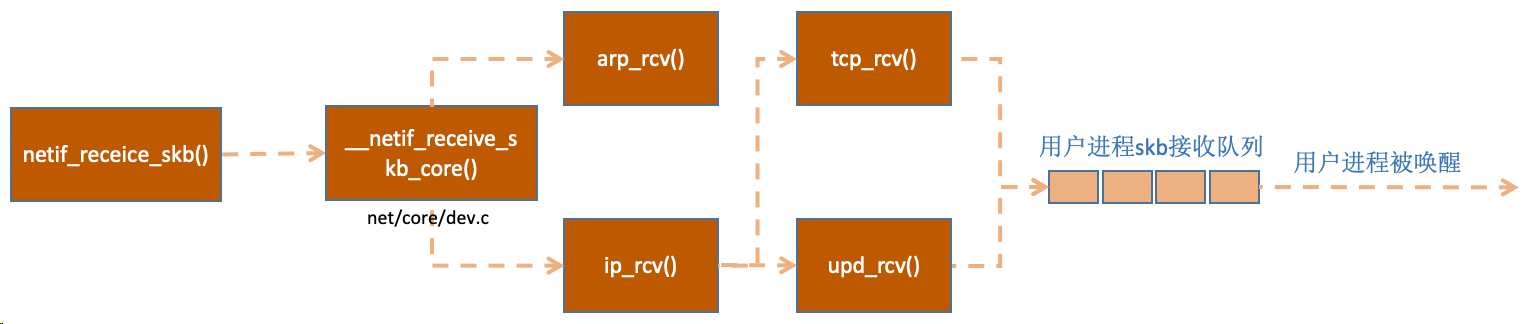
总结
网络模块是Linux内核中最复杂的模块了,看起来一个简简单单的收包过程就涉及到许多内核组件之间的交互,如网卡驱动、协议栈,内核ksoftirqd线程等。 看起来很复杂,本文想通过图示的方式,尽量以容易理解的方式来将内核收包过程讲清楚。现在让我们再串一串整个收包过程。
当用户执行完recvfrom调用后,用户进程就通过系统调用进行到内核态工作了。如果接收队列没有数据,进程就进入睡眠状态被操作系统挂起。这块相对比较简单,剩下大部分的戏份都是由Linux内核其它模块来表演了。
首先在开始收包之前,Linux要做许多的准备工作:
- 创建ksoftirqd线程,为它设置好它自己的线程函数,后面就指望着它来处理软中断呢。
- 协议栈注册,linux要实现许多协议,比如arp,icmp,ip,udp,tcp,每一个协议都会将自己的处理函数注册一下,方便包来了迅速找到对应的处理函数
- 网卡驱动初始化,每个驱动都有一个初始化函数,内核会让驱动也初始化一下。在这个初始化过程中,把自己的DMA准备好,把NAPI的poll函数地址告诉内核
- 启动网卡,分配RX,TX队列,注册中断对应的处理函数
以上是内核准备收包之前的重要工作,当上面都ready之后,就可以打开硬中断,等待数据包的到来了。
当数据到到来了以后,第一个迎接它的是网卡(我去,这不是废话么):
- 网卡将数据帧DMA到内存的RingBuffer中,然后向CPU发起中断通知
- CPU响应中断请求,调用网卡启动时注册的中断处理函数
- 中断处理函数几乎没干啥,就发起了软中断请求
- 内核线程ksoftirqd线程发现有软中断请求到来,先关闭硬中断
- ksoftirqd线程开始调用驱动的poll函数收包
- poll函数将受到的包送到协议栈注册的ip_rcv函数中
- ip_rcv函数再讲包送到upd_rcv函数中(对于tcp包就送到tcp_rcv)
现在我们可以回到开篇的问题了,我们在用户层看到的简单一行recvfrom,Linux内核要替我们做如此之多的工作,才能让我们顺利收到数据。这还是简简单单的UDP,如果是TCP,内核要做的工作更多,不由得感叹内核的开发者们真的是用心良苦。
理解了整个收包过程以后,我们就能明确知道Linux收一个包的CPU开销了。首先第一块是用户进程调用系统调用陷入内核态的开销。第二块是CPU响应包的硬中断的CPU开销。第三块是ksoftirqd内核线程的软中断上下文花费的。后面我们再专门发一篇文章实际观察一下这些开销。
另外网络收发中有很多末只细节咱们并没有展开了说,比如说no NAPI, GRO,RPS等。因为我觉得说的太对了反而会影响大家对整个流程的把握,所以尽量只保留主框架了,少即是多!
用一张图总结一下整个发送过程
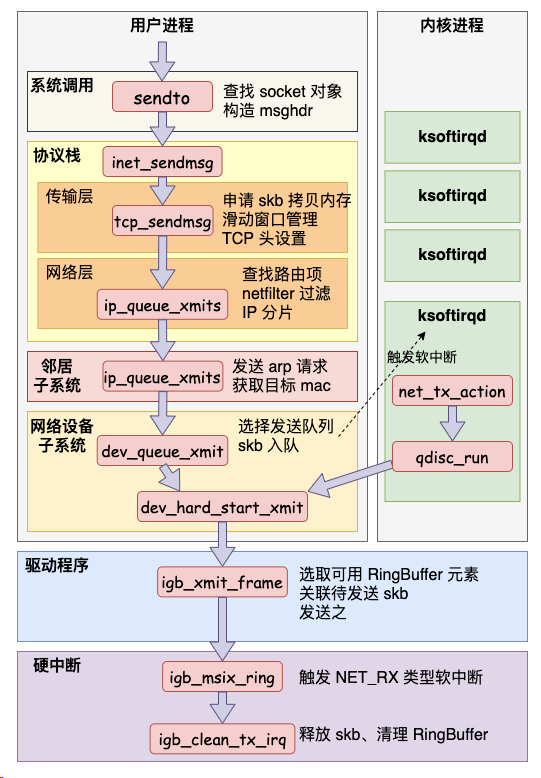
1.我们在监控内核发送数据消耗的 CPU 时,是应该看 sy 还是 si ?
在网络包的发送过程中,用户进程(在内核态)完成了绝大部分的工作,甚至连调用驱动的事情都干了。只有当内核态进程被切走前才会发起软中断。发送过程中,绝大部分(90%)以上的开销都是在用户进程内核态消耗掉的。
只有一少部分情况下才会触发软中断(NET_TX 类型),由软中断 ksoftirqd 内核进程来发送。
所以,在监控网络 IO 对服务器造成的 CPU 开销的时候,不能仅仅只看 si,而是应该把 si、sy 都考虑进来。
2. 在服务器上查看 /proc/softirqs,为什么 NET_RX 要比 NET_TX 大的多的多?
之前我认为 NET_RX 是读取,NET_TX 是传输。对于一个既收取用户请求,又给用户返回的 Server 来说。这两块的数字应该差不多才对,至少不会有数量级的差异。但事实上,飞哥手头的一台服务器是这样的:
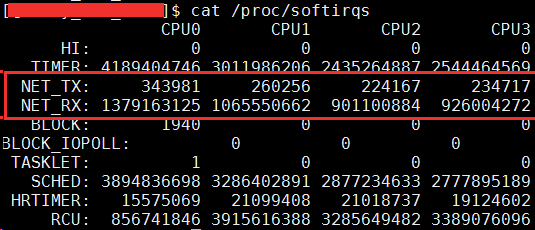
经过今天的源码分析,发现这个问题的原因有两个。
- 第一个原因是当数据发送完成以后,通过硬中断的方式来通知驱动发送完毕。但是硬中断无论是有数据接收,还是对于发送完毕,触发的软中断都是 NET_RX_SOFTIRQ,而并不是 NET_TX_SOFTIRQ。
- 第二个原因是对于读来说,都是要经过 NET_RX 软中断的,都走 ksoftirqd 内核进程。而对于发送来说,绝大部分工作都是在用户进程内核态处理了,只有系统态配额用尽才会发出 NET_TX,让软中断上。
综上两个原因,那么在机器上查看 NET_RX 比 NET_TX 大的多就不难理解了。
3.发送网络数据的时候都涉及到哪些内存拷贝操作?
这里的内存拷贝,我们只特指待发送数据的内存拷贝。
- 第一次拷贝操作是内核申请完 skb 之后,这时候会将用户传递进来的 buffer 里的数据内容都拷贝到 skb 中。如果要发送的数据量比较大的话,这个拷贝操作开销还是不小的。
- 第二次拷贝操作是从传输层进入网络层的时候,每一个 skb 都会被克隆一个新的副本出来。网络层以及下面的驱动、软中断等组件在发送完成的时候会将这个副本删除。传输层保存着原始的 skb,在当网络对方没有 ack 的时候,还可以重新发送,以实现 TCP 中要求的可靠传输。
- 第三次拷贝不是必须的,只有当 IP 层发现 skb 大于 MTU 时才需要进行。会再申请额外的 skb,并将原来的 skb 拷贝为多个小的 skb。
这里插入个题外话,大家在网络性能优化中经常听到的零拷贝,我觉得这有点点夸张的成分。TCP 为了保证可靠性,第二次的拷贝根本就没法省。如果包再大于 MTU 的话,分片时的拷贝同样也避免不了。