
详解 Linux io flush
fsync() fdatasync() sync()是什么?
首先它们是系统调用。
fsync
fsync(int fd) 系统调用把打开的文件描述符fd相关的所有缓冲元数据和数据都刷新到磁盘上
fdatasync
fdatasync(int fd) 类似fsync,但不flush元数据,除非元数据影响后面读数据。比如文件修改时间元数据变了就不会刷,而文件大小变了影响了后面对该文件的读取,这个会一同刷下去。所以fdatasync的性能要比fsync好。
sync
sync(void) 系统调用会使包含更新文件的所有内核缓冲区(包含数据块、指针块、元数据等)都flush到磁盘上。
O_DIRECT O_SYNC REQ_PREFLUSH REQ_FUA 是什么?
它们都是flag,可能最终的效果相同,但它们在不同的层面上。O_DIRECT O_SYNC 是系统调用 open 的 flag 参数,REQ_PREFLUSH REQ_FUA 是 kernel bio 的 flag 参数。要理解这几个参数要需要知道两个页缓存:
- 一个是你的内存,free -h可以看到的buff/cache;
- 另外一个是硬盘自带的page cache。
一个io写盘的简单流程如下:
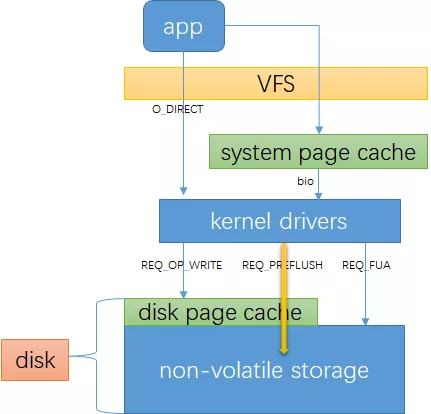
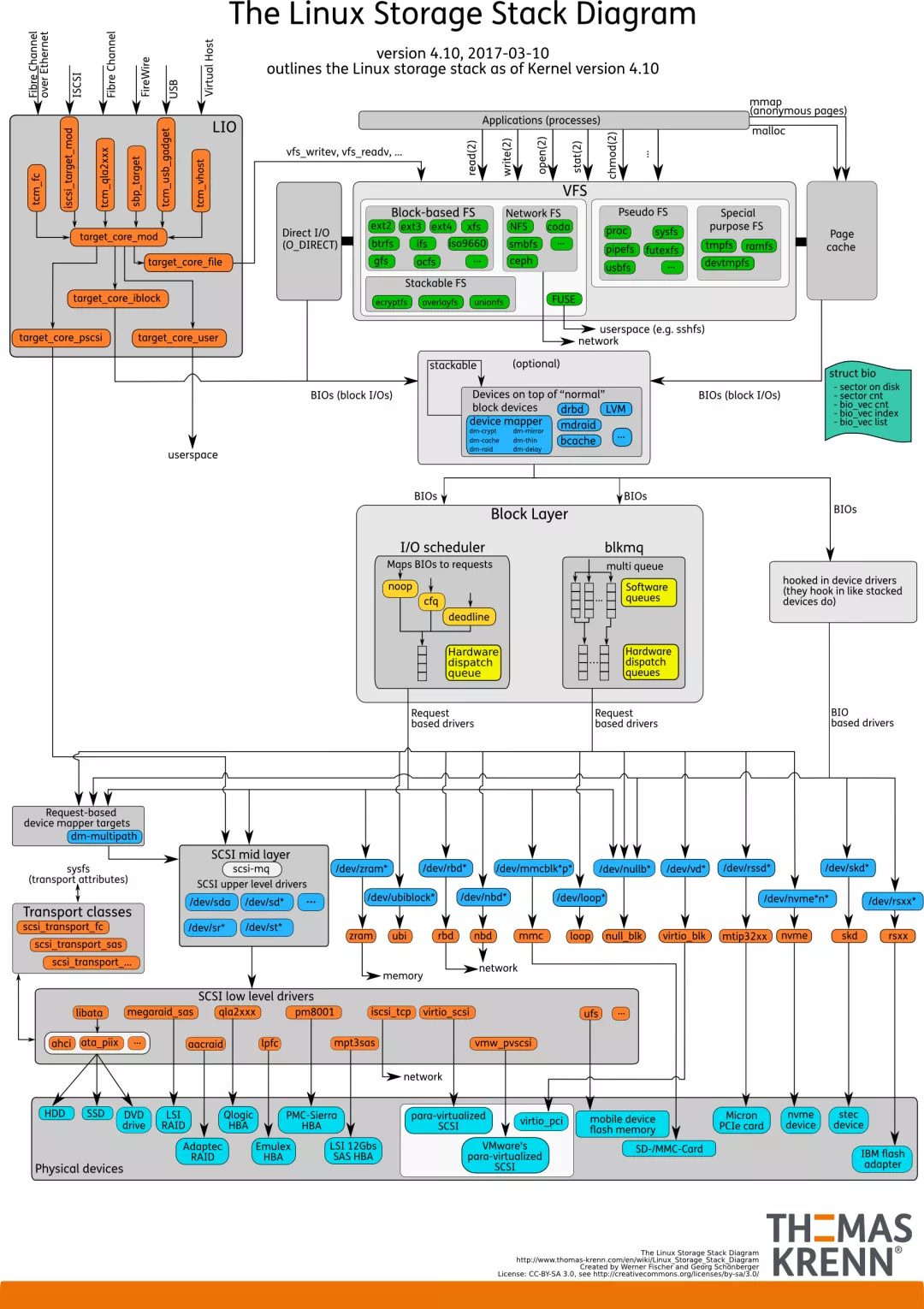
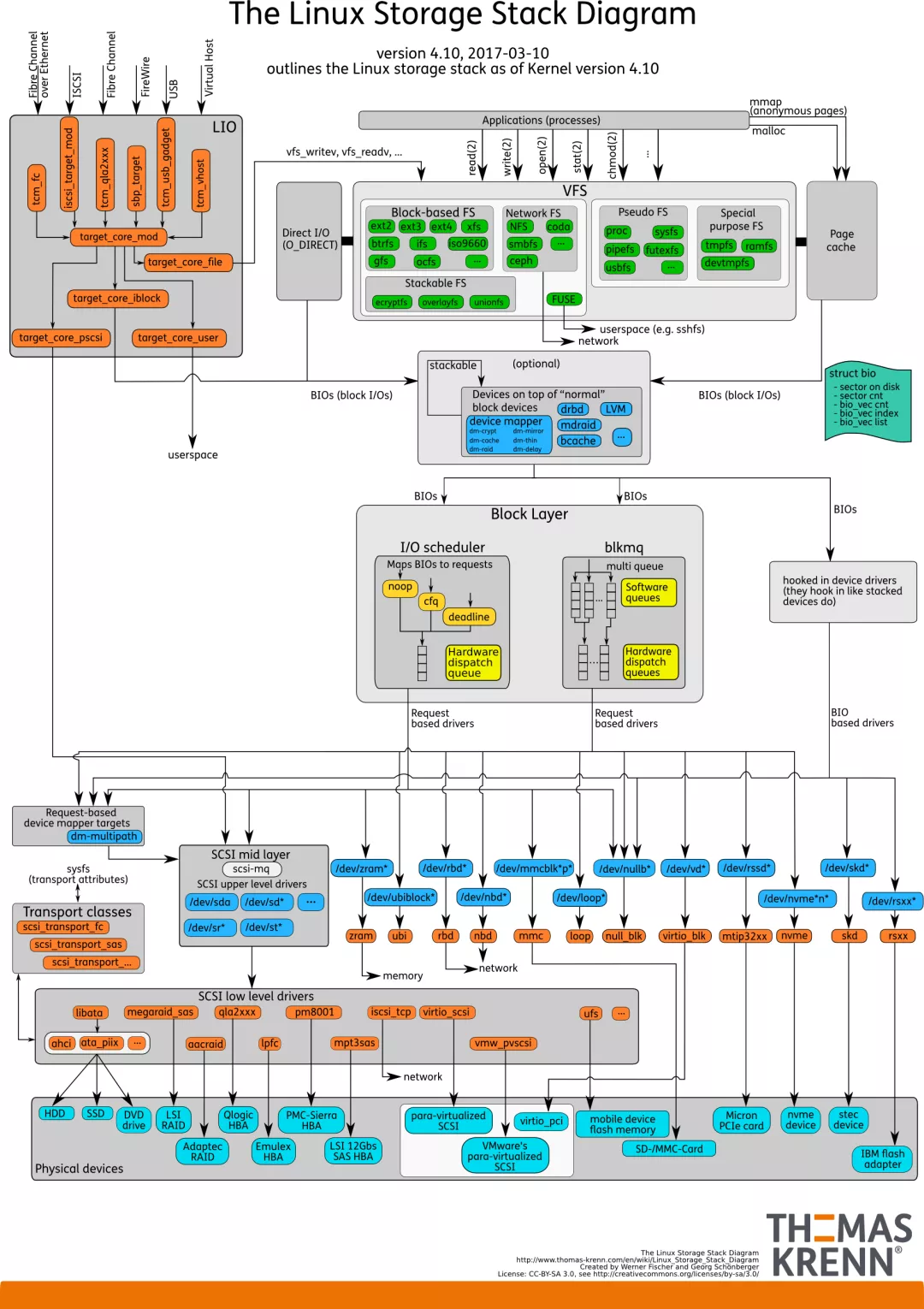
可以对比linux storage stack diagram:
O_DIRECT
O_DIRECT 表示io不经过系统缓存,这可能会降低你的io性能。它同步传输数据,但不保证数据安全。
备注:后面说的数据安全皆表示数据被写到磁盘的non-volatile storage
通过dd命令可以清楚看到 O_DIRECT和非O_DIRECT区别,注意buff/cache的变化:
# 清理缓存:
echo 3 > /proc/sys/vm/drop_caches
free -h
total used free shared buff/cache available
Mem: 62G 1.1G 61G 9.2M 440M 60G
Swap: 31G 0B 31G
# dd without direct
dd if=/dev/zero of=/dev/bcache0 bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 27.8166 s, 38.6 MB/s
free -h
total used free shared buff/cache available
Mem: 62G 1.0G 60G 105M 1.5G 60G
Swap: 31G 0B 31G
echo 3 > /proc/sys/vm/drop_caches
free -h
total used free shared buff/cache available
Mem: 62G 626M 61G 137M 337M 61G
Swap: 31G 0B 31G
# dd with direct
dd if=/dev/zero of=/dev/bcache0 bs=1M count=1024 oflag=direct
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 2.72088 s, 395 MB/s
free -h
total used free shared buff/cache available
Mem: 62G 628M 61G 137M 341M 61G
Swap: 31G 0B 31G
O_SYNC
O_SYNC 同步 io 标记,保证数据安全写到 non-volatile storage
REQ_PREFLUSH
REQ_PREFLUSH 是 bio 的 request flag,表示在本次io开始时先确保在它之前完成的io都已经写到非易失性存储里。我理解 REQ_PREFLUSH 之确保在它之前完成的io都写到非易失物理设备,但它自己可能是只写到了disk page cache里,并不确保安全。
可以在一个空的bio里设置REQ_PREFLUSH,表示回刷disk page cache里数据。
REQ_FUA
REQ_FUA 是 bio 的 request flag,表示数据安全写到非易失性存储再返回。
数据写入磁盘的过程

这个是一次write 写入经过的路径
- The client sends a write command to the database (data is in client’s memory).
- The database receives the write (data is in server’s memory).
- The database calls the system call that writes the data on disk (data is in the kernel’s buffer).
- The operating system transfers the write buffer to the disk controller (data is in the disk cache).
- The disk controller actually writes the data into a physical media (a magnetic disk, a Nand chip, …)
当我们到第3 步, 也就是write 操作系统返回的时候, 可以保证的是如果process 挂了, 但是操作系统没挂, 这个数据我们是能够刷回磁盘。
当我们到了第4步, 也就是write 操作, 并且fsync了。这个时候我们可以保证就算机器挂了, 数据也会写到disk controller。这个时候正常情况下disk controller 是会保证数据刷回到物理介质的
那么在第三步write 写入到page cache, page cache 是什么时候刷回磁盘的, 以及我们在上层怎么控制这个刷盘的策略呢?
具体在2.6.32 这个版本, 主要的刷盘进程是sync_supers 这个进程, 这个和之前版本的pdflush进程不一样, 之前版本主要有pdflush负责刷盘操作。
通过 cat /proc/meminfo | grep Dirty 可以看到Dirty page 有多少个:
cat /proc/meminfo | grep Dirty
Dirty: 212 kB
另外一个默认启动的线程是sync_super线程, 这个线程是去定期将superblock 里面的内容刷新回去
关于 writeback 主要可以通过/sys/vm/ 配置的参数列表
- dirty_background_ratio
- dirty_ratio
- dirty_writeback_centisecs
dirty_writeback_centisecs 指定多长时间 pdflush/flush/kdmflush 这些进程会唤醒一次,然后检查是否有缓存需要清理。如果wrteback的时间长于dirty_writeback_centisecs的时间,可能会出问题。
dirty_background_ratio 和 dirty_ratio 的关系?
- dirty_background_ratio:是当系统里面的dirty page 超过这个百分比以后, 系统开始启动flush进程将dirty page flush到磁盘。
- dirty_ratio:是当系统里面的dirty page 超过这个百分比以后, 有写磁盘操作的进程会被阻塞, 等待将dirty page flush到磁盘以后再写入。
通过dd 修改不同的 dirty_ratio 来测试性能来看:
dirty_ratio 如果设置的比较小, 那么就很容易阻塞进程的写入所以性能比较低。
┌─[@xxx05] - [/data5]
└─[$] sudo sh -c 'echo 0 >/proc/sys/vm/dirty_ratio'
┌─[@xxx05] - [/data5]
└─[$] cat /proc/sys/vm/dirty_ratio
0
┌─[@xxx05] - [/data5]
└─[$] dd if=/dev/zero of=file-abc bs=1M count=30000
^C828+0 records in
828+0 records out
868220928 bytes (868 MB) copied, 158.016 s, 5.5 MB/s
如果把dirty_ratio 调整的比较大, 那么dd 的速度就会快很多, 基本上能够达到磁盘写的性能.
┌─[@xxx05] - [/data5]
└─[$] sudo sh -c 'echo 100 >/proc/sys/vm/dirty_ratio'
┌─[@xxx05] - [/data5]
└─[$] sudo sh -c 'echo 3 >/proc/sys/vm/drop_caches'
┌─[@xxx05] - [/data5]
└─[$] dd if=/dev/zero of=file-abc bs=1M count=30000
dd: warning: partial read (339968 bytes); suggest iflag=fullblock
29999+1 records in
29999+1 records out
31456571392 bytes (31 GB) copied, 104.62 s, 301 MB/s
到3.10.0 版本以后, 这个bdi-default 线程, flush 线程什么也都没有了, 都变成kworker, 然后把需要flush 的任务丢到这个kworker 队列里面就可以了
所以新版本的内核里面是看不到这些bdi, pdflush 等等。这样做的好处也是很明显的, 不需要为了专门做flush 这个事情, 专门搞一个线程, 而且还需要经常去唤醒。
more than 120 seconds
echo 0 > /proc/sys/kernel/hung_task_timeout_secs disables this message
1735 blocked for more than 120 seconds
默认情况下, Linux会最多使用40%的可用内存作为文件系统缓存。当超过这个阈值后,文件系统会把将缓存中的内存全部写入磁盘, 导致后续的IO请求都是同步的。
将缓存写入磁盘时,有一个默认120秒的超时时间。 出现上面的问题的原因是IO子系统的处理速度不够快,不能在120秒将缓存中的数据全部写入磁盘。
IO系统响应缓慢,导致越来越多的请求堆积,最终系统内存全部被占用,导致系统失去响应。
解决方法
根据应用程序情况,对vm.dirty_ratio,vm.dirty_background_ratio两个参数进行调优设置。
取消120秒时间限制
此方案就是不让系统有那个120秒的时间限制。文件系统把数据从缓存转到外存慢点就慢点,应用程序对此延时不敏感。就是慢点就慢点,我等着。实际上操作系统是将这个变量设为长整形的最大值。
下面说一下内核hung task检测机制由来。我们知道进程等待IO时,经常处于D状态,即TASK_UNINTERRUPTIBLE状态,处于这种状态的进程不处理信号,所以kill不掉,如果进程长期处于D状态,那么肯定不正常,原因可能有二:
- IO路径上的硬件出问题了,比如硬盘坏了(只有少数情况会导致长期D,通常会返回错误);
- 内核自己出问题了。这种问题不好定位,而且一旦出现就通常不可恢复,kill不掉,通常只能重启恢复了。
内核针对此种情况开发了一种hung task的检测机制,基本原理是:定时检测系统中处于D状态的进程,如果其处于D状态的时间超过了指定时间(默认120s,可以配置),则打印相关堆栈信息,也可以通过proc参数配置使其直接panic。
如何修改或者取消120秒的时间限值呢。120秒的时间限值由内存参数kernel.hung_task_timeout_secs决定的。直接像方案一那样修改此内核参数的值就可。如果kernel.hung_task_timeout_secs的值设置为0,那就是把此种设置为长整型的最大值。
sysctl -a | grep kernel.hung_task_timeout_secs
kernel.hung_task_timeout_secs = 120
有内核返回信息,可知当前设置的hung_task超时时间为120秒。
修改hung_task_timeout_secs值。
把hung_task_timeout_secs的值修改为0,在命令行中输入如下指令:
sysctl -w kernel.hung_task_timeout_secs=0
sysctl -p
经过以上操作,取消120秒时间限值之后,上述问题成功解决。
但是取消120秒的时间限值会允许系统不可切换任务的出现。综合考虑决定采用方案1,即缩减文件系统的缓冲区大小。
总结
减少内存使用
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
最大化的使用内存
vm.dirty_background_ratio = 50
vm.dirty_ratio = 80
优化写入性能, 可以使用内存, 但是等到空闲的时候希望内存被回收, 经常用在应对突然有峰值的这种情况
vm.dirty_background_ratio = 5
vm.dirty_ratio = 80
玩转 SSD 系列
SSD基准测试应该关注哪些指标
4K随机读写性能
固态存储设备最大的优势就是随机读取能力和深度队列读写。一块SSD的性能和价值,很大程度上在随机存取上表现出来。
持续读写性能
固态存储介质都有不俗的顺序读取和写入能力,对于主流产品,这个测试通常可以忽略。即使主流消费级产品都已经能将接口带宽跑满(SATA 6Gbps)。SAS 12G更有不俗的表现。NVMe 性能更是可以在持续读写的时候达到 10Gbps以上,并可借助自身的协议优势,实现更低的延迟和 CPU占用。
性能一致性,稳定态,延迟
性能一致性越好意味着磁盘在进行io的时候响应时间标准差越低。存储的服务质量主要表现在带宽,iops和延迟上。
单次完成io的时间(响应时间)越低,对应的 iops 就越高。完成io时最高延迟和最低延迟差距越小,性能表现就越平稳。如果一项服务,经常出现超时,无响应,那么认为这个服务是不可靠的,质量是低的。反之,如果平均响应时间都在一个理想的范围内,即使最大的响应时间也在一个可以容忍的程度,那么认为这个服务质量是可靠的。性能一致性,也就是指磁盘的服务质量,也是 SNIA (Storage Networking Industry Association) 企业级产品测试的重要一个环节。
稳定态是一块磁盘最“忙”的状态,Controller IC 既要响应 Host 的读写请求,又要兼顾内部 GC,平均写入的策略,闪存的擦除,编程等工作,如何能在繁忙的工作中做到有条不紊,将请求的延迟都保证在一个可以接受的范围内,保持一个相对稳定高效的服务状态。在高压下,磁盘的最大延迟越低,平均延迟区间越窄,iops 吞吐量就越高。在线提供服务时,也越稳定,越高效。
稳定态的性能,是判定一块企业级产品性能好坏的重要标准。
耐久度,寿命
一般来讲,写入数据会导致磁盘寿命下降,读取数据不会。但实际上,无论是读取还是写入,都会降低磁盘的寿命,只不过读取造成的磨损与写入相比可以忽略。读取不直接造成磨损,而是在频繁读取某一单元后,为了防止附近数据出错,数据会被主控迁移,或者重新写入,这个过程对于Host来说是不可见的。在读取相当频繁的情况下,读取干扰,一定程度上算耐久度消耗的一个原因。
固态存储寿命用尽,也并不意味着这块闪存写无法写入数据了,而是数据写入之后,无法正确的读出之前写入的内容。就像一张白纸,在铅笔写入数据之后,每次橡皮都不能完全把之前写入的石墨微粒擦干净,在经过多次的写入擦除之后,纸已经黑了,很难判定写进去的是什么。当SSD的ECC算法也无能为力的时候,这盘算是寿终正寝。
实际生产中,很少会用到寿命用尽,数据比盘值钱的多。寿命即将用尽时所产生的问题不仅仅是数据不再安全,通常还伴随着读写能力的下降,在磁盘寿命即将耗尽之前,服务质量就已经打折扣了。
写入放大 (WA)
由于 NAND 特定的特性,写入和擦除的最小单位不对等,并且无论数据有多大,都至少要写一整个page。另外,平均写入策略,数据搬运,也会导致 WA 增大。
以上就是在做基准测试时,需要关心的指标,下一篇将会介绍选择怎样的测试工具以及针对磁盘的具体项目进行测试。
基准测试环境(工具/磁盘要求等)
测试环境
SanDisk CloudSpeed 800G * 4 RAID 5
Micron 5100 ECO 960G * 4 RAID 5
E5 2630 V2 *1
96GB DDR3 ECC
工具
fio - 跨平台的 io 压力生成工具。功能强大,支持众多引擎和系统调优参数,数据采集,自带gnuplot画图脚本。
iometer - io 压力生成器,带GUI界面,数据采集功能强大,功能和参数并不如 fio 多,多用于 Windows 平台(本次未采用)。
hdparm - linux下的磁盘工具,可以查看磁盘信息,用来进行安全擦除,设置 ATA 参数,设置HPA等
smartctl - linux下查看smart信息的工具。
python, perl, php, go, shell, awk, c, cxx …… 随便一个语言都行,用于处理fio生成的大量数据。
excel - 没错,就是excel,用来处理数据作图。当然只是为了便于展示,实际自动化测试流程可以用任何语言直接处理数据生成图表。
测试工具选择有很多,比如fio, iometer, iozone, sysbench 等,但之所以选 fio,有以下原因:
- 虽然上述工具基本都能胜任,但fio在linux下应用比较多,有比较深厚的群众基础, 文档和邮件组也相对完善,尤其是邮件组,好多遇到的问题都搜到了作者的回复,让我甚是感动。
- fio更“专业”一些,iometer 相对可选择的参数少许多,应用平台也以windows为主,iozone 粗略看了一下,功能差不多,但国内用的较少,限于时间和经历没有深入研究
- sysbench更适合一些特定场景的测试,比如OLTP,基准测试 fio的功能足够且专一。
fio 可以使用一系列的进程或者线程,来完成用户指定的一系列io操作,典型的使用方式是写一个 JobFile,来模拟特定的 io 压力。
fio是测试IOPS的非常好的工具,用来对硬件进行压力测试和验证,支持13种不同的I/O引擎,包括:sync,mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio 等等
对于单qd,可以直接用 sync,对于多qd,libaio + 深qd 或者 深qd+多进程(numjobs)。
磁盘要求
- 新盘或者做过完整的安全擦除
- 对于曾经设置过 HPA (Host protected Area, ATA8-ACS SET MAX ADDRESS),清除HPA
- 不应该使用raid,除非想测试raid下的性能 但其实这些都不是硬性要求。首先磁盘用用就变成脏盘了,第二,很少有人设置HPA,第三,多数SATA磁盘最终都会挂在RAID卡上用。所以以上三点都是测试单个盘的要求,最终,还是建议怎么用就怎么测。
已经踩过的坑
- fio 版本不要使用 2.0.13,一开始直接通过包管理安装了 fio 2.0.13,使用中各种 CPU 100%, 数据飙高,还出了 core,于是被迫 cmm 大法编译安装了新版。
- 安装新版 fio 可能需要安装 zlib-dev libaio-dev,如果你在没安装前就编译了,需要重新编译。
脚本
测试中没有使用 jobfile 的形式,而是直接使用了命令行,其实这两种没有什么本质区别,依据个人喜好。
/usr/local/bin/fio --filename={FIO_TEST_FILE} \
--direct=1 \
--ioengine=libaio \
--group_reporting \
--lockmem=512M \
--time_based \
--userspace_reap \
--randrepeat=0 \
--norandommap \
--refill_buffers \
--rw=randrw --ramp_time=10 \
--log_avg_msec={LOG_AVG_MSEC} \
--name={TEST_SUBJECT} \
--write_lat_log={TEST_SUBJECT} \
--write_iops_log={TEST_SUBJECT} \
--disable_lat=1 \
--disable_slat=1 \
--bs=4k \
--size={TEST_FILE_SIZE} \
--runtime={RUN_TIME} \
--rwmixread={READ_PERCENTAGE} \
--iodepth={QUEUE_DEPTH} \
--numjobs={JOB_NUMS}
介绍一下测试中可能会用到的参数
--filename 指定fio的测试文件路径。可以是文件或设备(设备需要root权限)
--direct=1 绕过缓存
--ioengine=libaio 使用libaio,linux原生异步io引擎,更多引擎参考fio man
--group_reporting 将所有的进程汇总,而不是对于每一个job 单独给出测试结果
--lockmem=512M 将内存限制在 512M,然而实际测试中发现似乎没什么用,有待考察
--time_based 即使文件读写完毕依旧继续进行测试,直到指定的时间结束
--rwmixread 读写比例,0为全读,100为全写,中间为混合读写
--userspace_reap 提高异步IO收割的速度。
这是霸爷的解释 ( http://blog.yufeng.info/archives/2104 ),未做深入研究,但从测试来看,似乎影响不大
--randrepeat=0 指定每次运行产生的随即数据不可重复
官方解释 Seed the random number generator in a predictable way so results are repeatable across runs. Default: true.
--norandommap 不覆盖所有的 block
一般来说,在进行4k 读写时,由于随机数的不确定性,可能有些块自始至终都没有被写到,有些块却被写了好多次。但对于测试来说 是否完全覆盖到文件并没有什么关系,而且测试时间相对足够长的时候,这些统计都可以略过。
--ramp_time=xxx(seconds)
指定在 xxx 秒之后开始进行日志记录和统计(预热),非稳态测试这里指定了10秒,用于让主控和颗粒“进入状态”
--name 指定测试的名称,代号
--write_latency_log=latency_log前缀 记录延迟日志
--write_bw_log 记录带宽(吞吐量)日志
--write_iops_log 记录 iops 日志
--bs=4k 4K测试
--size=XXXG 指定测试文件大小,如不指定,写满为止 或者全盘(例如/dev/sdX /dev/memdiskX)
--runtime=1200 执行1200秒,或者执行完整个测试,以先达到的为准。如果指定了 --time_based,则以此为准。
--log_avg_msec 本次采用1000,即每秒,相对记录原始数据来说 fio 占用的内存会大大减少。巨大的原始数据log也会占用大量磁盘空间,如果并非一定要记录原始数据,建议开启。
应该关注的测试项目
全盘 无文件系统
* 顺序读取测试
* 顺序写入测试
* 顺序混读写混合测试
* QD1,QD2,QD4...QD32
512B,4K,8K,16K 随机读取测试
512B,4K,8K,16K 随机写入测试
512B,4K,8K,16K 随机读写混合测试 (50/50)
512B,4K,8K,16K 随机读写混合测试 (30/70)
512B,4K,8K,16K 随即读写混合测试 (70/30)
512B ~ 256K 随机读写混合测试
* 写入放大测试
全盘 主要文件系统 (ext4,ext3,XFS等)
* 顺序读取测试
* 顺序写入测试
* 顺序混读写混合测试
* QD1,QD2,QD4...QD32
512B,4K,8K,16K 随机读取测试
512B,4K,8K,16K 随机写入测试
512B,4K,8K,16K 随机读写混合测试 (50/50)
512B,4K,8K,16K 随机读写混合测试 (30/70)
512B,4K,8K,16K 随即读写混合测试 (70/30)
512B ~ 256K 随机读写混合测试
* 写入放大测试
7% OP (128G NAND 对应 119.3G 可用空间,常见的 128G 磁盘)
13% OP (128G NAND 对应 111.7G 可用空间,常见的 120G 磁盘)
27% OP (128G NAND 对应 93.1G 可用空间,常见的 100G 磁盘)条件下上述测试(非必选项)
即便是只做全盘的测试,不考虑不同OP的情况,也已经有十几项,根据磁盘大小的不同,一项的测试时间也从两小时~几十小时不等。如果所有的测试都进行,从开始测试到收割数据将是一个相当漫长的等待。并且这种测试还不能够并行执行。因而,选几个典型的,线上可能出现的测试就可以。
本次进行了QD1-32的读取,写入,混合读写测试。
测试应该控制在多少时间,可以粗略的估算:比如某一款磁盘宣称的最大 iops 为 100,000 iops,换算成带宽,100000 * 4K 为越 400M,要超过至少写满3次磁盘容量,让磁盘变得足够脏的时间。
测试脚本为通用脚本,其中{}内的数据会根据测试项目动态生成,一共十多个项目,每个项目对应一个脚本。
由于机器性能尚可,当 queue depth 达到32的时候,磁盘性能已被榨干,但单核心cpu占用率远没有到 100%(实测平均在 40%左右,峰值60%左右),可以认为处理器性能不是基准测试的瓶颈。 但对于一些性能彪悍的 NVMe 设备或 PCI-E 卡,在队列深度达到64的时候,磁盘性能还没有被榨干,但单个CPU核心已经100%了,此时需要保持 QD 在一个相对低一些的水平,增加 numjobs,使得总qd上去。来保证磁盘被“喂饱”,以免测试结果不准确。但目前来看,一般业务真的很难用到QD64队列。
要注意几个问题
- 记录日志的路径不要跟被测试的SSD在一起。比如 SSD挂在 /opt 进行测试,在shell里,当前工作目录或记录日志的目录就不要是 /opt,以免记录日志的时候影响到SSD。虽然测试过程中发现 fio 并不会边测试边写日志,而是在测试完成之后统一进行日志的记录。但在测试完成后,如果因为磁盘空间不够记录不下完整的日志,也是比较悲剧的事情。
- 如果要记录原始日志,内存一定要大。或者你有性能够好的 swap(比如另一块 PCI-E卡或者 ssd,至少不能是机械盘那种不能容忍的慢,因为fio在进行日志收集的时候,会写入大量的数据,占用一定的时间。这个时间对于一些高端企业级SSD足以恢复一部分性能,如果进行连续测试,可能结果会有些差异)。
- 如果测试记录原始日志,除非内存足够大,否则不要指定run_time 过长,最好几个小时就断一次,留出足够的时间和空间给 fio 写日志,把测试分成相对小的几个测试脚本,最后人工合并log做分析。原因同样是fio产生的巨大log。
- 如果日志比较大,放弃自带的图像生成脚本吧,内存占用是一方面,生成的图像能不能打的开还是个未知数。
数据处理
如果记录原始log,日志都很大,好处是可以利用这些原始日志按照想要的粒度随意进行多次的拆分。
下面是之前测试记录的原始日志。

解释一下其中的命名,前面的 logxxxfio_xxx基本都一样,是用户指定的前缀。
后面的 iops, clat, slat, lat, bw 等是对应的测试项。
- bw 是带宽
- clat slat 和 lat 是每次 io 操作的延迟。
- slat 是io请求提交到操作系统,得到响应的时间,经过分析发现这个时间一般都很短,可以忽略。
- clat 是 io 操作完成所需要的时间,一般来说可以认为是 设备从接到 io请求到完成的时间。 lat 就是整个时间了, so, clat + slat = lat. 但由于 slat 很小,看 lat 和 clat 区别不大。既然是做磁盘基准测试,瓶颈总不能在操作系统吧,因而后期的测试都指定了 disable clat 和 slat 。
原始日志格式如下
fio 带宽log
# fio bandwidth log
0, 21005, 0, 4096
0, 20378, 0, 4096
0, 21222, 0, 4096
0, 22755, 0, 4096
fio iops log
# fio iops log
0, 1, 0, 4096
0, 1, 0, 4096
0, 1, 0, 4096
0, 1, 0, 4096
fio 延迟 log
# fio s / c / latency log
0, 453, 0, 4096
0, 435, 0, 4096
0, 436, 0, 4096
0, 436, 0, 4096
格式比较好猜。除了那一排0,于是 google,有人问过了:http://www.spinics.net/lists/fio/msg01064.html
Data direction: 0 is read, 1 is write.
log文件结构都很简单,很容易改成 csv,并保留原始数据。其中bw数据可能会让人感觉有点奇怪。
然而实际计算发现,bw 的数据并没有那么平均,而是每次完成io之后,block size / clat 的值。 既然fio都这么设计,那bw log实际上来看用处已经不大,因为有iops log + clat log,一样的。 于是作图中,也选用clat,忽略 lat和slat了,毕竟 slat 都很小(对于sata设备来说忽略不计),clat和lat基本就一样了。
文件大小也小了好多好多。其实如果指定了采样间隔,fio自身生成log也跟这个类似,实际测试可以考虑直接指定对应参数。 数据文件处理完毕,可以按照需求作图了,作图可以直观的看到趋势,更容易发现问题。
这是测试中的两款磁盘,都直接从稳定态开始进行的测试,由于持续读写测试没有太大意义,故不做介绍,以4K随机为例做一个对比
读取延迟大家都没超过毫秒级,由于是企业级的盘,加上raid卡神秘加成,可以看到两个盘几乎都是一条直线下来。区别是 SanDisk的延迟明显比 Micron的延迟低。查过datasheet可以知道美光用了3D eTLC,相比传统MLC来说,TLC相对有较高的延迟并不奇怪。
可以看到 Micron的磁盘延迟上下浮动范围稍宽,iops也有类似的表现,对于SanDisk,则几乎是一条直线,也可以看出SanDisk的性能几乎保持在同一个水平,对请求的处理及时,到位。但Micron的这一点点波动,不会对服务产生可以感知的影响,只是经过作图,直观的感受。但如果测试结果发现,波动范围非常大,那就要小心了。它可能是线上服务质量的杀手。
服务质量的好与坏,主要看延迟有多高,如果最长的延迟非常高,那平均时间也好不到哪去,而且通常最大延迟高的盘,延迟超过容忍程度(比如 200 ms)的几率也相对更高,直观表现就是“一卡一卡的”。
取某个时间段内的最大值,如果绝大多数时间这个最大值接近理想的平均值,并且整个测试阶段的最长时间在可以接受的范围内,出现的频率也不是很高,那么势必平均延迟也不高,可以判定整体服务质量还不错。
其实随机读取对于各种SSD来说其实是小儿科。因为没有什么成本,主控不忙,闪存不忙。确切的说,跟写入比起来,轻松许多,极少 wear leveling,极少 GC,极少擦除
于是此处应有写入测试(其实是混合读写测试,读3写7)。
SanDisk的磁盘之前在线上机器服役过几个月,Micron的是新盘。
可以看到SanDisk的测试结果离散度比较大,跟美光的“一条直线”比起来,一点都不养眼。但并不意味着磁盘性能不好。虽然延迟范围比较大,但最大延迟控制在了 2ms 以内,跟美光的盘差不多,并且可以看到不同QD下,延迟也有上限,iops没有出现零点,而对于2ms QD32 的延迟来说,业务无感知。
美光的几乎是新盘(但在测试过程中也早就达到了稳定态)表现相对养眼一点,但并不抢眼,因为对比可以看出,美光的盘平均写入延迟都比同QD下SanDisk的要高,而且写入吞吐量要比 SanDisk的略低一点(SanDisk 12K 左右,Micron大约10K),原因,同样是TLC和 MLC的差别,同时,SanDisk有200多G的 OP,而美光,只有40多G,美光说:这还是有些许的不公平啊。
写入放大
写入放大一词,最早由Intel提出,随着 NAND 颗粒容量的增大,page 也从 4k 变成 8k, 16k,32k……,而且NAND擦除时,并不能直接擦除一个 page,加上磨损平衡策略,造成了实际写入 NAND 的数据量大于 主机写入的数据量。这种写入放大在 4k 随机写入测试时尤为明显。线上的 RDBMS 应用,KV 存储记录,分布式 block / object 存储,更多的用到了随机写入。因而能减小写入放大,就能在某种程度上延长SSD的使用寿命。
可能有些公司已经开始采用 PCI-E卡甚至 NVMe SSD用于线上业务,当然这是极好的,NVMe为SSD而生,硬件性能需要满足业务需求,但至少,SSD作为通用存储,要满足以下一个要求,才能保证一般线上业务(比如RDBMS)的稳定。
- 测试过程中读取 写入不能出现零点。
- 读取写入延迟在可以预见的范围内(一般高压不能超过5ms)。
- 不能依靠 Trim 来维持SSD 的性能。
潜在的坑
4k 无文件系统测试能否代表真实的磁盘性能
有些盘拿到手之后,跑上几十个小时的4k qd32 write,效果相当不错,iops,带宽,延迟都在比较理想的范围之内, 但是否能代表有文件系统时磁盘的性能?通常认为,差别不大。可能有文件系统的时候会稍稍慢一点。但网上有一哥们确实遇到了很诡异的事情 (http://www.vojcik.net/samsung-ssd-840-pro-performance-degradation/)。
某品牌的磁盘在特定固件版本下,特定文件系统表现非常不稳定。如果没有做过全面测试,这种事情出现在线上,是非常崩溃的, 并且,排查问题几乎完全找不到头绪。
trim,raid卡造成的性能波动
虽然本次测试覆盖了一款 raid 卡,但实际生产环境中每一批的固件,缓存策略等均可能对性能和稳定性产生影响,因而有必要做兼容性测试
高压环境下的稳定性、极端环境、掉电,上电测试
短时间的压测或基准测试可能并不能将产品潜在的bug发掘出来,比如镁光有就有著名的 "5200小时门",虽然是消费级产品,但已经足够毁灭一大批数据。又诸如Intel的祖传 "8M门",国外也有DC S3700用户中奖。测试只是划定门槛的手段。
基于S.M.A.R.T.的磁盘健康监控
smartctl
smartctl是linux下查看磁盘S.M.A.R.T.信息的工具。它其实是smartmontools的一部分,默认并不会安装,对于CentOS,可以执行yum install smartmontools进行安装。
安装后,就可以通过smartctl查看磁盘的各种信息了,值得一提的是,smartmontools也支持查看连接在主流RAID方案下的磁盘信息,新版本(6.5及以上版本)也实验性地支持NVMe和一些其他PCI-E磁盘的S.M.A.R.T.信息查看。
smartmontools还包括smartd,它可以经过配置,自动、间隔时间执行smart信息的监控和收集,并且可以在执行后或发现异常等情况下,以邮件形式发送通知。
其实还可以通过 smartctl -t等对磁盘进行检测。但业务上线后,应该避免对磁盘进行长时间的检测。
发现磁盘
一般可以通过fdisk -l 来列出机器上的磁盘,然而服务器上一般很少有磁盘不通过RAID卡直接连接到控制器上,通过fdisk -l看到的诸如/dev/sdX的磁盘,直接通过smartctl -a /dev/sdX 并不能查看到磁盘的S.M.A.R.T.信息,而一般只有几行冷冰冰的文字
告诉你改磁盘不支持S.M.A.R.T.不过值得庆幸的是smartctl也支持对raid卡下磁盘S.M.A.R.T.信息的读取。而且几乎市面上主流的RAID卡也都涵盖了。通过smartctl -h 可以看到:
-d TYPE, --device=TYPE
Specify device type to one of: ata, scsi, sat[,auto][,N][+TYPE], usbcypress[,X], usbjmicron[,p][,x][,N], usbsunplus, marvell, areca,N/E, 3ware,N, hpt,L/M/N, megaraid,N, cciss,N, auto, test
例如对接在DELL PERC H710(实际上解决方案是LSI MegaRAID)上的磁盘,可以通过如下方式获取到S.M.A.R.T.信息:
smartctl -? /dev/sda -d sat+megaraid,0
其中 ? 可以替换成smartctl 支持的参数选项,而megaraid后面对应的磁盘ID 0,可以通过megacli工具通过-PDList -aALL获取到。
在实际系统运维中,可以通过脚本处理megacli的输出,再通过smartcli监控磁盘的状态。
而对于NVMe磁盘,smartcli已经支持S.M.A.R.T.信息的读取和分析,但有些品牌的磁盘,可能还要依赖厂商的工具来进行读取和分析。
smartctl参数
-h 显示帮助
-i 显示磁盘的基础信息
-a 显示磁盘的所有S.M.A.R.T.信息
-x 显示磁盘的所有信息,这个内容是相当的全
-d 设置磁盘设备的类型(ata设备,还是某些raid卡型号)
-s 设置开启/关闭S.M.A.R.T.
其他诸如容错级别,测试等等功能,对于一般监控来说用不到,同时smartctl -h后列出的帮助信息可以说是非常良心,基本已经涵盖了基础使用的样例。
对于一般监控,比较常见的策略是执行smartctl -a /dev/sdX并通收集数据,落盘,分析各指标是否有异常,是否已经接近临界值,从而针对性的发送警报或汇总。
S.M.A.R.T.指标
smartctl在执行之后会有一个总体的判定 PASSED 或者 FAILED,即有没有通过S.M.A.R.T.检测。即:
SMART overall-health self-assessment test result: PASSED
Warning: This result is based on an Attribute check.
同时,也会告知你,这个PASSED 还是 FAILED,是根据S.M.A.R.T.特定属性的判定得出的。
言外之意具体怎么样,您还需要再过目。
但一般来说,如果这个都FAILED了,这快盘八成是快要挂了。所以一旦出现FAILED,是很严重的问题,尽可能的备份数据,换盘。
对于不同厂商的不同磁盘,S.M.A.R.T.具体信息可能都不相同,甚至有些指标的编号都不相同。但大多数通用指标,大家是相同的。
Compaq于1995早期将S.M.A.R.T.的前身技术方案提交到SFF委员会进行标准化,后续得到各大硬盘厂商的支持,大家约定了一份所有制造商都必须遵守共同的规则
同时,各制造商也会根据自己需要添加一些自己专有的检测属性。
例如下面的典型属性:
|ID|英文名|中文译名|描述|
|-|-|-|-|
|0x01|Read Error Rate|底层数据读取错误率 存储器从一个硬盘表面读取数据时发生的错误率。原始值由于不同厂商的不同计算方法而有所不同,其十进制值往往无意义的|
|0x05|Reallocated Sector Count|重定位磁区计数 记录由于损坏而被映射到无损的后备区的扇区计数|
|0x09|Power-On Hours|硬盘加电时间 硬盘自出厂以来加电启动的统计时间,单位为小时(或根据制造商设定为分钟或秒)|
|0xBC|Command Timeout|通信超时 由于无法连接至硬盘而终止操作的统计数,一般为0,如果远超过0,则可能电源问题,数据线接口氧化或更严重的问题|
|0xC4|Reallocation Event Count|重定位事件计数 记录已重映射扇区和可能重映射扇区的事件计数|
|0xC5|Current Pending Sector Count|等候重定的扇区计数 记录了不稳定的扇区的数量|
|0xC6|Uncorrectable Sector Count|无法校正的扇区计数 记录肯定出错的扇区数量|
更多指标可以在这里找到: https://zh.wikipedia.org/wiki/S.M.A.R.T.
SMART的值
硬盘的每项SMART信息中都有一个临界值(阈值),不同硬盘的临界值是不同的,SMART针对各项的当前值、最差值和临界值的比较结果以及数据值进行分析后,提供硬盘当前的评估状态,也是我们直观判断硬盘健康状态的重要信息。
根据SMART的规定,状态一般有正常、警告、故障或错误三种状态。
SMART判定这三个状态与SMART的 Pre-failure/advisory BIT(预测错误/发现位)参数的赋值密切相关:
- 当Pre-failure/advisory BIT=0,并且当前值、最差值远大于临界值的情况下,为正常标志
- 当Pre-failure/advisory BIT=0,并且当前值、最差值大于但接近临界值时,为警告标志
- 当Pre-failure/advisory BIT=1,并且当前值、最差值小于临界值时,为故障或错误标志
因而平常监控项目中的 pre-fail值就是重点关注对象。
对于Old_age类型,一般来说,是一些统计状况值,并不能直接反映磁盘是否或即将出现失效。
但有些数据项,也可以间接的反映出磁盘是否临近失效,例如249 NAND Writes GB,虽然磁盘出现了重映射,但NAND Writes GB还富裕好多的时候,可以考虑忽略重映射, 亦或NAND Writes GB已经接近NAND白皮书提供的寿命,但磁盘依旧坚挺,这时候也应该考虑更换磁盘了。
VALUE: 当前值
这是表格中最重要的信息之一,代表给定属性的标准化值,在1到253之间。253通常意味着最好情况,1意味着最坏情况。
取决于属性和制造商,初始化VALUE可以被设置成100或200,但有些诸如温度等状态指标除外。
THRESH: 临界值
临界值是硬盘厂商指定的表示某一项目可靠性的门限值,也称阈值,它通过特定公式计算而得。
如果某个参数的当前值接近了临界值,就意味着硬盘将变得不可靠,可能导致数据丢失或者硬盘故障。
WORST: 最差值
最差值是硬盘运行时各ID项当前值曾出现过的最坏值。
最差值是对硬盘运行中某项数据变劣的峰值统计,该数值也会不断刷新。通常,
最差值与当前值是相等的,如果最差值出现较大的波动(小于当前值),表明硬盘曾出现错误或曾经历过恶劣的工作环境(如温度)
RAW_VALUE: 数据值
数据值是硬盘运行时各项参数的实测值,大部分SMART工具以十进制显示数据。
数据值代表的意义随参数而定,大致可以分为三类:
- 数据值并不直接反映硬盘状态,必须经过硬盘内置的计算公式换算成当前值才能得出结果
- 数据值是直接累计的,如Start/Stop Count(启动/停止计数)
- 有些参数的数据是即时数,如Temperature(温度)
信息收集和监控报警
每个厂家的 S.M.A.R.T.信息都不尽相同,尤其是在SSD成为标配的今天,S.M.A.R.T.更成为监控磁盘剩余寿命的最重要的指标。
由于磁盘的多样性,磁盘S.M.A.R.T.信息也不尽相同,类似的指标,在不同型号的磁盘上可能对应到不同的ID,这就导致收集S.M.A.R.T.信息需要对磁盘品牌,型号,甚至固件版本进行适配。
但绝大多数时候不会允许我们直接登录线上机器收集S.M.A.R.T.信息,但我们的脚本又要精确的对各个属性进行匹配。好消息是smartctl 提供了一个S.M.A.R.T.信息的数据库。
里面包含了各种磁盘型号,固件的 S.M.A.R.T. ID对应的指标含义。并且用户可以看到,阅读,甚至编辑。
smartctl 也允许用户在执行的时候手工指定这个数据库文件。只要是符合smartctl能够读取的数据库格式即可。
可以通过 smartctl -h 看到系统默认的数据库文件位置。
例如:
/var/lib/smartmontools/drivedb/drivedb.h
drivedb.h 以如下结构保存相应的信息:
struct drive_settings {
const char * modelfamily;
const char * modelregexp;
const char * firmwareregexp;
const char * warningmsg;
const char * presets;
};
ModelFamily: 磁盘型号族,例如上面的 Intel 520,如果设置为$开头,忽略。
ModelRegexp: 匹配型号的正则表达式,不能为空。
FirmwareRegexp: 固件匹配正则表达式,可以为空,为空时不进行固件匹配。否则进行固件匹配以缩小适配的磁盘集合。
WarningMsg: 警告信息,当用户的磁盘刚好在匹配的结果内,显示此信息。
presets: S.M.A.R.T. 含义定义,以-v开头。
截取其中的一段:
{ "Intel 520 Series SSDs", // tested with INTEL SSDSC2CW120A3/400i, SSDSC2BW480A3F/400i
"INTEL SSDSC2[BC]W(060|120|180|240|480)A3F?",
"", "",
//"-v 5,raw16(raw16),Reallocated_Sector_Ct "
"-v 9,msec24hour32,Power_On_Hours_and_Msec "
//"-v 12,raw48,Power_Cycle_Count "
"-v 170,raw48,Available_Reservd_Space "
"-v 171,raw48,Program_Fail_Count "
"-v 172,raw48,Erase_Fail_Count "
"-v 174,raw48,Unexpect_Power_Loss_Ct "
//"-v 184,raw48,End-to-End_Error "
"-v 187,raw48,Uncorrectable_Error_Cnt "
//"-v 192,raw48,Power-Off_Retract_Count "
"-v 225,raw48,Host_Writes_32MiB "
"-v 226,raw48,Workld_Media_Wear_Indic "
"-v 227,raw48,Workld_Host_Reads_Perc "
"-v 228,raw48,Workload_Minutes "
//"-v 232,raw48,Available_Reservd_Space "
//"-v 233,raw48,Media_Wearout_Indicator "
"-v 241,raw48,Host_Writes_32MiB "
"-v 242,raw48,Host_Reads_32MiB "
"-v 249,raw48,NAND_Writes_1GiB"},
除了通用值之外,Intel 520系列的特殊值都已经在这里了。如果用户在执行smartctl的时候手工再指定 -v 参数,对应的数据会覆盖drivedb.h中的含义设定。
这些信息还可以在实际执行smartctl收集到数据之前,就能够编写相应的收集脚本。
自动化收集,分析和预测
可以通过smartd进行自动的数据收集,检测到数据异常后给相关运维人员发送邮件提醒。但smartd可定制性不高,因而线上并没有采用smartd。
依托命令执行系统qcmd,可以在全量机器上分时,分批,执行单个命令或多个脚本,并将执行结果统一进行收集,分析。相对计划的数据采集,这种方式更为灵活。并且可以在脚本进行流程控制,数据处理等。
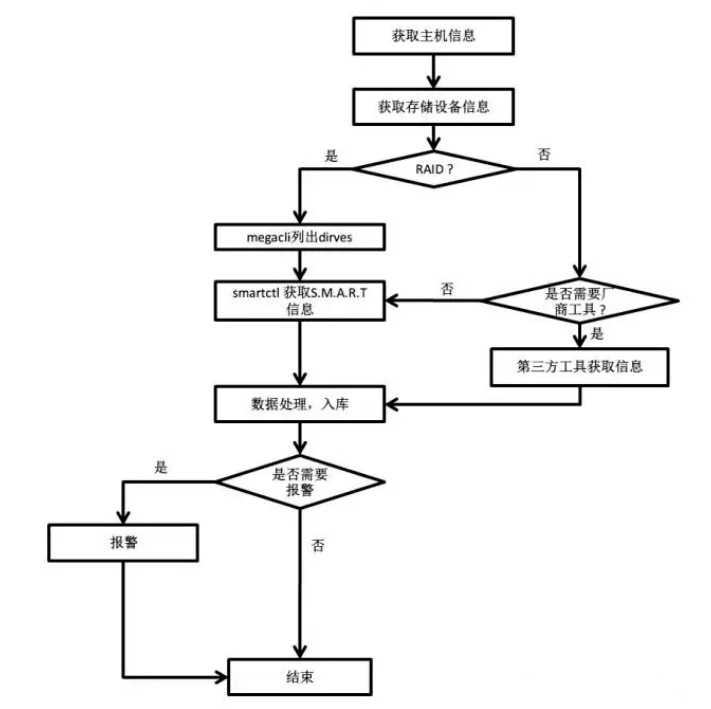
整体流程并不复杂:
- 目标脚本包含对磁盘设备的枚举,根据特征判定机器是否是 RAID,NVMe,对应执行megacli或其他厂商工具,并根据返回结果最终获取所有磁盘的S.M.A.R.T.信息。入库,落盘,进行后续的数据处理。
- 对于普通磁盘,在出现重映射/重映射增加/Pending sectors/WARNING/FAILED等异常状态时对应发送app、邮件、短信、等各种等级的报警信息。
- 对于SSD,收集磁盘磨损信息,并在达到特定级别的时候发送通知或报警。
- 根据磁盘类型,工作时常,写入量,是否有重映射等指标,得出磁盘是否已经失效或临近失效。当已经即将/已经失效,发送邮件到OPS,并确认报修,尽可能避免可以预见的故障。
磁盘那点事
512bytes
每个扇区512字节是固定大小么?还是每个机器都不一样?目前看来每个扇区512字节是一个不成文的规矩。
考虑到磁盘的性能,如果每个扇区1字节,那么写入大文件会频繁读写太多次,效率很慢,如果扇区太大又会造成空间的浪费,早期的磁盘容量不大,所以就将扇区大小设置为512字节。
随着硬盘容量越来越大,每个扇区512字节过于小了,比如4T的硬盘要分成无数个扇区,而且用户的文件也越来越大,都是以M,G来计算,每次读写512字节硬盘效率也不高。
这时候硬盘大厂Western Digital提出来,我们将扇区换成4096字节吧,并且使用Advanced Format做为标识。
如果你的硬盘上有Advanced Format标识,那就是4096字节扇区的。
但是这么改出现了一个大问题,因为512字节扇区成了不成文的规矩,在整个软件链中,基本输入/输出系统(BIOS)、引导装载程序、操作系统内核、文件系统代码和磁盘工具等工具全部都想当然的认为磁盘的每个扇区就是512字节,如果改成4096字节BIOS甚至都找不到引导分区,整个产业链都要为了硬盘个做出改变,这个成本是巨大的。
硬盘厂商为什么要改呢?一个是性能的考量,还有一个原因是扇区太多,硬盘固件检测和纠正扇区错误负担会非常重
硬盘厂商想出一个办法,使用固件将4096字节物理扇区分成512字节逻辑分区,做到对其它设备透明,这样当然皆大欢喜了,可是又出现了一个潜在的隐患4k对齐
4k对齐
造成4k不对齐主要原因就是操作系统认为我的磁盘是512字节扇区的,但是实际上设备可能是1024,2048,4096的,这个问题在ssd硬盘上也会显现,因为ssd和传统磁盘结构完全不一样,它实际上模拟了扇区这个概念,单位读写的大小和颗粒有关。
想象一下,如果写入一个4096字节数据,在4096扇区的磁盘上,因为文件系统数据和底层物理扇区正好一致,磁盘执行一次写入即可。
因为linux基本以8个扇区做为一个block来写,所以每次写入都是4096字节
那么如果操作系统格式化磁盘是从第三个扇区到最后一个扇区,那么写入4096字节在磁盘上就有可能会跨扇区,造成两次写入,导致性能下降。
所以使用新型硬盘的时候,我们要注意是否4k对齐,只要扇区起始能被8整除,基本就是4k对齐的了。
比如上面的命令显示是从2048扇区开始,此磁盘是4k对齐的。
Device Boot Start End Sectors Size Id Type
/dev/vda1 * 2048 167772126 167770079 80G 83 Linux
那么有人会问,能被8整除的数很多,为什么从2048开始?不是512,1024?
前面的2048个扇区(1MB)被保留做为分区表和其它用途,在linux中0号扇区是MBR和分区表,1到2047则为grub保留,虽然grub一般只用其中几十个扇区。
只有1个字节的文件实际占用多少磁盘空间?
查看1个字节的文件
mdkir test
cd test
touch test.txt
du -h
0 .
在一个目录中创建了一个空的文件以后,通过du命令看到的该文件夹的占用空间并没有发生变化。这倒是符合我们之前的认识,因为空文件只占用inode。好,那让我们修改文件,添加一个字母
echo "a" > test
du -h
4.0k .
保存后再次查看该目录的空间占用。我们发现由原来的0增加到了4K。 所以说,文件里的内容不论多小,哪怕是一个字节,其实操作系统也会给你分配4K的。哦,当然了还得再算前文中说到的inode和文件夹数据结构中存储的文件名等所用的空间。 所以,不要在你的系统里维护一大堆的碎文件。文件再小,占用磁盘其实一点都不少!
注意我的实验环境是在ext文件系统下进行的。如果是xfs可能表现会有些许出入。
Block size
dumpe2fs -h /dev/vda1 | grep Block
dumpe2fs 1.45.6 (20-Mar-2020)
Block count: 20971259
Block size: 4096
Blocks per group: 32768
文件系统是按照inode+block来组织的,所以不管你的文件多小,哪怕只有一个字节,在数据上都会消耗掉整整一个块(当然还得算上inode等开销)。这个块大小可以通过dumpe2fs等命令来查看。如果想改变这个块大小怎么办?对不起,只能重新格式化。
文件过多时ls命令为什么会卡住?
不知道你有没有遇到过当一个文件夹下文件特别多,在下面执行ls命令的时候要等好长时间才能展现出来的问题?如果有,你有想过这是为什么吗,我们该如何解决? 要想深入理解这个的问题产生的原因,我们就需要从文件夹占用的磁盘空间开始讨论了。
inode消耗验证
在《新建一个空文件占用多少磁盘空间?》中我提到了每一个文件会消耗其所在文件夹中的一点空间。文件夹呢,其实也一样会消耗inode的。 我们先看一下当前inode的占用情况
df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
......
/dev/sdb1 2147361984 12785020 2134576964 1% /search
再创建一个空文件夹
# mkdir temp
# df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
......
/dev/sdb1 2147361984 12785021 2134576963 1% /search
通过IUsed可以看到,和空文件一样,空的文件夹也会消耗掉一个inode。不过这个很小,我的机器上才是256字节而已,应当不是造成ls命令卡主的元凶。
block消耗验证
文件夹的名字存在哪儿了呢?嗯,和《新建一个空文件占用多少磁盘空间?》里的文件类似,会消耗一个ext4_dir_entry_2(今天用ext4举例,它在linux源码的fs/ext4/ex4.h文件里定义),放到其父目录的block里了。根据这个,相信你也很快能想到,如果它自己节点下创建一堆文件的话,就会占用它自己的block。我们来动手验证一下:
# mkdir test
# cd test
# du -h
4.0K .
这里的4KB就表示消耗掉了一个block。 空文件不消耗block,空目录为啥一开始就消耗block了呢,那是因为其必须默认带两个目录项"."和".."。另外这个4K在你的机器上不一定是这么大,它其实是一个block size,在你格式化的时候决定的。
我们再新建两个空的文件,再查看一下:
# touch aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab
# touch aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
# du -h
4.0K .
貌似,没有什么变化。这是因为
- 第一、新的空文件不占用block,所以这里显示的仍然是目录占用的block。
- 第二、之前文件夹创建时候分配的4KB里面空闲空间还有,够放的下这两个文件项
那么我再多创建一些试试,动用脚本创建100个文件名长度为32Byte的空文件。
#!/bin/bash
for((i=1;i<=100;i++));
do
file="tempDir/"$(echo $i|awk '{printf("%032d",$0)}')
echo $file
touch $file
done
# du -h
12K .
哈哈,这时我们发现目录占用的磁盘空间变大了,成了3个Block了。当我们创建到10000个文件的时候,
# du -h
548K .
在每一个ext4_dir_entry_2里都除了文件名以外,还记录着inode号等信息,详细定义如下:
struct ext4_dir_entry_2 {
__le32 inode; /* Inode number */
__le16 rec_len; /* Directory entry length */
__u8 name_len; /* Name length */
__u8 file_type;
char name[EXT4_NAME_LEN]; /* File name */
};
我们计算一下,平均每个文件占用的空间=548K/10000=54字节。也就是说,比我们的文件名32字节大一点点,基本对上了。 这里我们也领会到一个事实,文件名越长,在其父目录中消耗的空间也会越大。
本文结论
- 一个文件夹当然也是要消耗磁盘空间的。首先要消耗掉一个inode,我的机器上它是256字节。需要消耗其父目录下的一个目录项ext4_dir_entry_2,保存自己inode号,目录名。
- 其下面如果创建文件夹或者文件的话,它就需要在自己的block里ext4_dir_entry_2数组目录下的文件/子目录越多,目录就需要申请越多的block。另外ext4_dir_entry_2大小不是固定的,文件名/子目录名越长,单个目录项消耗的空间也就越大。
对于开篇的问题,我想你现在应该明白为什么了,问题出在文件夹的block身上。 这就是当你的文件夹下面文件特别多,尤其是文件名也比较长的时候,它会消耗掉非常多的block。当你遍历文件夹的时候,如果Page Cache中没有命中你要访问的block,就会穿透到磁盘上进行实际的IO。在你的角度来看,就是你执行完ls后,卡住了。
那么你肯定会问,我确实要保存许许多多的文件,我该怎么办? 其实也很简单,多创建一些文件夹就好了,一个目录下别存太多,就不会有这个问题了。工程实践中,一般的做法就是通过一级甚至是二级hash把文件散列到多个目录中,把单目录文件数量控制在十万或万以下。
ext的bug
貌似今天的实践应该结束了,现在让我们把刚刚创建的文件全部删掉,再看一下。
# rm -f *
# du -h
72K .
等等,什么情况?文件夹下的文件都已经删了,该文件夹为什么还占用72K的磁盘空间? 这个疑惑也伴随了我很长时间,后来才算是解惑。问题关键在于ext4_dir_entry_2中的rec_len。这个变量存储了当前整个ext4_dir_entry_2对象的长度,这样操作系统在遍历文件夹的时候,就可以通过当前的指针,加上这个长度就可以找到文件夹中下一个文件的dir_entry了。这样的优势是遍历起来非常方便,有点像是一个链表,一个一个穿起来的。 但是,如果要删除一个文件的话,就有点小麻烦了,当前文件结构体变量不能直接删,否则链表就断了。 Linux的做法是在删除文件的时候,在其目录中只是把inode设置为0就拉倒,并没有回收整个ext4_dir_entry_2对象。其实和大家做工程的时候经常用到的假删除是一个道理。现在的xfs文件系统好像已经没有这个小问题了,但具体咋解决的,暂时没有深入研究,如果你有答案,欢迎留言!
Linux系统中的Page cache和Buffer cache
buffer: 作为buffer cache的内存,是块设备的读写缓冲区,更靠近存储设备,或者直接就是disk的缓冲区。
cache: 作为page cache的内存, 文件系统的cache,是memory的缓冲区 。
Page cache(页面缓存)
Page cache 也叫页缓冲或文件缓冲,是由好几个磁盘块构成,大小通常为4k,在64位系统上为8k,构成的几个磁盘块在物理磁盘上不一定连续,文件的组织单位为一页, 也就是一个page cache大小,文件读取是由外存上不连续的几个磁盘块,到buffer cache,然后组成page cache,然后供给应用程序。
Page cache在linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问。具体说是加速对文件内容的访问,buffer cache缓存文件的具体内容 —— 物理磁盘上的磁盘块,这是加速对磁盘的访问。
Buffer cache(块缓存)
Buffer cache 也叫块缓冲,是对物理磁盘上的一个磁盘块进行的缓冲,其大小为通常为1k,磁盘块也是磁盘的组织单位。设立buffer cache的目的是为在程序多次访问同一磁盘块时,减少访问时间。系统将磁盘块首先读入buffer cache,如果cache空间不够时,会通过一定的策略将一些过时或多次未被访问的buffer cache清空。程序在下一次访问磁盘时首先查看是否在buffer cache找到所需块,命中可减少访问磁盘时间。不命中时需重新读入buffer cache。对buffer cache的写分为两种,一是直接写,这是程序在写buffer cache后也写磁盘,要读时从buffer cache上读,二是后台写,程序在写完buffer cache后并不立即写磁盘,因为有可能程序在很短时间内又需要写文件,如果直接写,就需多次写磁盘了。这样效率很低,而是过一段时间后由后台写,减少了多次访磁盘的时间。
Page cache和Buffer cache的区别
磁盘的操作有逻辑级(文件系统)和物理级(磁盘块),这两种Cache就是分别缓存逻辑和物理级数据的。
假设我们通过文件系统操作文件,那么文件将被缓存到Page Cache(默认的IO会这样)
Page cache实际上是针对文件系统的,是文件的缓存,在文件层面上的数据会缓存到page cache。文件的逻辑层需要映射到实际的物理磁盘,这种映射关系由文件系统来完成。当page cache的数据需要刷新时,page cache中的数据交给buffer cache,但是这种处理在2.6版本的内核之后就变的很简单了,没有真正意义上的cache操作。
Buffer cache是针对磁盘块的缓存,也就是在没有文件系统的情况下,直接对磁盘进行操作的数据会缓存到buffer cache中
简单说来,page cache用来缓存文件数据,buffer cache用来缓存磁盘数据。在有文件系统的情况下,对文件操作,那么数据会缓存到page cache,如果直接采用dd等工具对磁盘进行读写,那么数据会缓存到buffer cache。
Buffer(Buffer Cache)以块形式缓冲了块设备的操作,定时或手动的同步到硬盘,它是为了缓冲写操作然后一次性将很多改动写入硬盘,避免频繁写硬盘,提高写入效率。
Cache(Page Cache)以页面形式缓存了文件系统的文件,给需要使用的程序读取,它是为了给读操作提供缓冲,避免频繁读硬盘,提高读取效率。
背景知识一:我们现在的计算机、手机都是冯诺依曼架构,CPU只能操作内存中的数据,无法直接操作硬盘上的数据。
背景知识二:硬盘上的数据,最小读写单位是扇区(Sector)。老式硬盘上一个扇区是512字节,现代硬盘上一个扇区是4K字节。计算机不能以单个字节为单位访问硬盘上的数据。现在很常见的固态硬盘,物理上最小读写单位是页(Page),但大部分固态硬盘通过主控芯片模拟传统硬盘的扇区来进行读写。现代硬盘常用的LBA(Logical Block Addressing,逻辑块寻址)寻址方式,是把硬盘上的扇区分配从0~N-1的编号(N为硬盘上所有可用扇区数量)。
假设某个应用现在需要读取一个大小为15K字节的文件A。操作系统和文件系统会把文件路径转换为具体的LBA地址,可能最终转换为读取硬盘上从B扇区开始的4个扇区(按照每个扇区4KB计算)。然而,前面我们说了,CPU并不能直接访问硬盘,因此需要先把这四个扇区的数据,传输到内存中。
Buffer cache是指磁盘设备上的raw data(指不以文件的方式组织)以block为单位在内存中的缓存,早在1975年发布的Unix第六版就有了它的雏形,Linux最开始也只有buffer cache。事实上,page cache是1995年发行的1.3.50版本中才引入的。不同于buffer cache以磁盘的block为单位,page cache是以内存常用的page为单位的,位于虚拟文件系统层(VFS)与具体的文件系统之间。
在很长一段时间内,buffer cache和page cache在Linux中都是共存的,但是这会存在一个问题:一个磁盘block上的数据,可能既被buffer cache缓存了,又因为它是基于磁盘建立的文件的一部分,也被page cache缓存了,这时一份数据在内存里就有两份拷贝,这显然是对物理内存的一种浪费。更麻烦的是,内核还要负责保持这份数据在buffer cache和page cache中的一致性。所以,现在Linux中已经基本不再使用buffer cache了。
像mysql就不会用标准的io方式,标准io文件系统会有page cache,mysql属于直接io 自己直接缓存文件块(buffer pool)。
自缓存
对于某些应用程序来说,它会有它自己的数据缓存机制,比如,它会将数据缓存在应用程序地址空间,这类应用程序完全不需要使用操作系统内核中的高速缓冲存储器,这类应用程序就被称作是自缓存应用程序( self-caching applications )。数据库管理系统是这类应用程序的一个代表。
自缓存应用程序倾向于使用数据的逻辑表达方式,而非物理表达方式;当系统内存较低的时候,自缓存应用程序会让这种数据的逻辑缓存被换出,而并非是磁盘上实际的数据被换出。自缓存应用程序对要操作的数据的语义了如指掌,所以它可以采用更加高效的缓存替换算法。自缓存应用程序有可能会在多台主机之间共享一块内存,那么自缓存应用程序就需要提供一种能够有效地将用户地址空间的缓存数据置为无效的机制,从而确保应用程序地址空间缓存数据的一致性。
对于自缓存应用程序来说,缓存 I/O 明显不是一个好的选择。Linux 中的直接 I/O 技术非常适用于自缓存这类应用程序,该技术省略掉缓存 I/O 技术中操作系统内核缓冲区的使用,数据直接在应用程序地址空间和磁盘之间进行传输,从而使得自缓存应用程序可以省略掉复杂的系统级别的缓存结构,而执行程序自己定义的数据读写管理,从而降低系统级别的管理对应用程序访问数据的影响。在下面一节中,我们会着重介绍 Linux 中提供的直接 I/O 机制的设计与实现,该机制为自缓存应用程序提供了很好的支持。
凡是通过直接 I/O 方式进行数据传输,数据均直接在用户地址空间的缓冲区和磁盘之间直接进行传输,完全不需要页缓存的支持。操作系统层提供的缓存往往会使应用程序在读写数据的时候获得更好的性能,但是对于某些特殊的应用程序,比如说数据库管理系统这类应用,他们更倾向于选择他们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
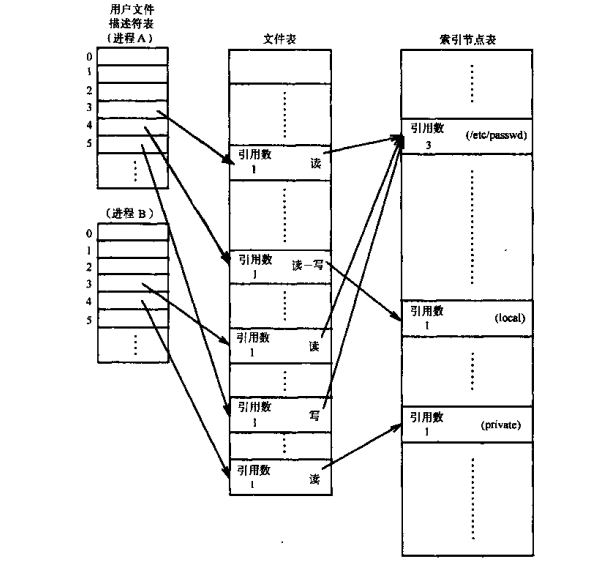
文件描述符
文件描述符简介
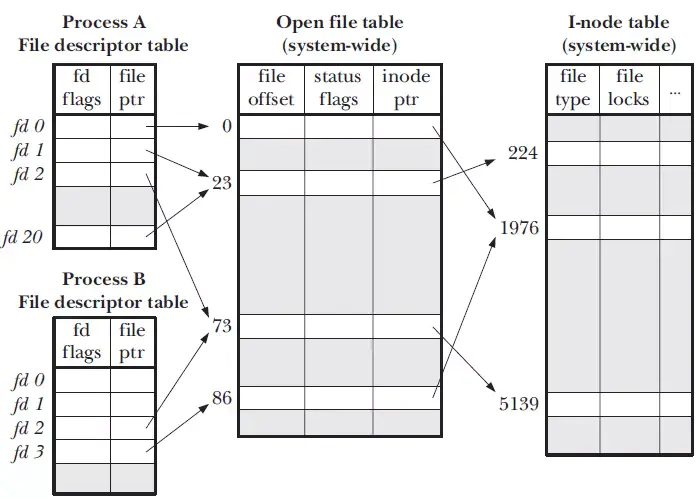
在linux系统中,一切皆文件,当进程打开现有文件或者创建新文件时,内核向进程返回一个文件描述符,文件描述符在形式上是一个非负整数,实际上它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。所有执行io操作的系统调用都会通过文件描述符执行。
文件描述符和进程的关系
系统为了维护文件描述符,建立了三个表:
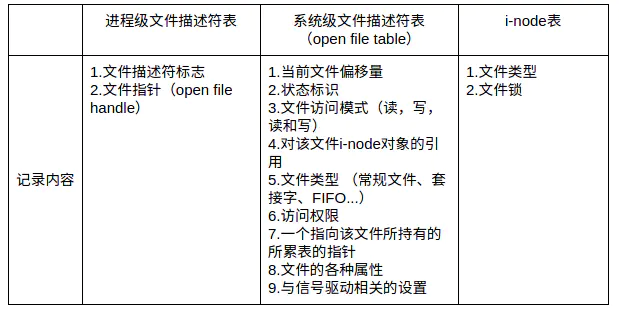
进程打开一个文件,会与上面三个表发生关联,分别是:文件描述符表、文件表、索引结点表。
当同一个进程对同一个文件多次使用open时;对一个文件描述符调用dup函数;父进程使用fork创建一个子进程,子进程和上面三个表的关系;当子进程调用exec函数,子进程和上三个表的关系又发生了什么变化;不同的进程打开同一个文件,那么这些进程又是以怎么样的形式相关联。本文将解释这些问题。
文件描述符表、文件表、索引结点表存放地点:
- 每个进程都有一个属于自己的文件描述符表。
- 文件表存放在内核空间,由系统里的所有进程共享。
- 索引结点表也存放在内核空间,由所有进程所共享。
三个表的作用
文件描述符表
该表记录进程打开的文件。它的表项里面有一个指针,指向存放在内核空间的文件表中的一个表项。它向用户提供一个简单的文件描述符,使得用户可以通过方便地访问一个文件。
当进程使用open打开一个文件时,内核就会在这个表中添加一个表项。如果对同一个文件打开多次,那么将有多个表项。使用dup时,也会增加一个表项。
文件表
文件表保存了进程对文件读写的偏移量。该表还保存了进程对文件的存取权限。比如,进程以O_RDONLY方式打开文件,这将记录到对应的文件表表项中(每一项就是一个文件句柄)。
包括:
- 文件偏移量(file offset),调用read()和write()更新,调用lseek()直接修改
- 访问模式,由open()调用设置,例如:只读、只写或读写等
- i-node对象指针
索引结点表
在文件系统中,也是有一个索引结点表的。如下图所示:
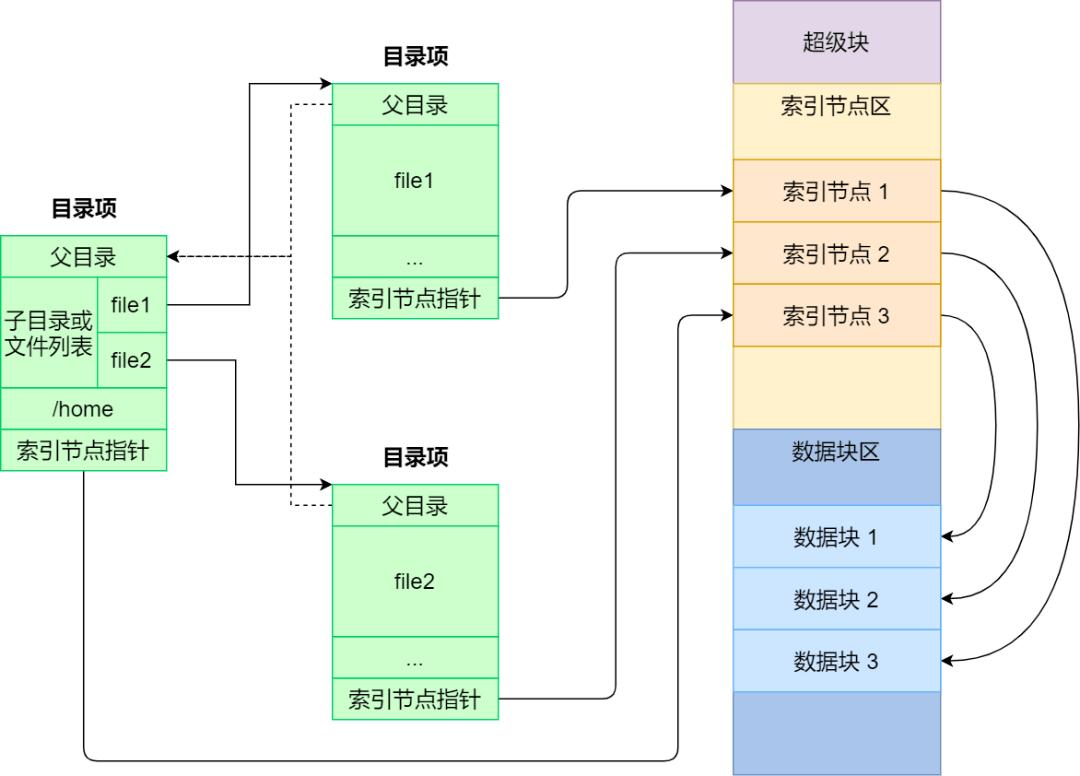
文件系统的索引节点表项包括:
- 文件类型(file type),可以是常规文件、目录、套接字或FIFO
- 访问权限
- 文件锁列表(file locks)
- 文件大小
- 等等
这两个索引结点表有千丝万缕的关系。因为内存中的索引结点表的每一个表项都是从文件系统中读入的,并且两个索引结点表有一对一的关系。所以,内存中的索引结点表的每一个表项都对应一个具体的文件。
i-node存储在磁盘设备上,内核在内存中维护了一个副本,这里的i-node表为后者。副本除了原有信息,还包括:引用计数(从打开文件描述体)、所在设备号以及一些临时属性,例如文件锁。
上面所说的三个表的功能,使得三个表紧密地联系在一起,文件描述符表项有一个指针指向文件表表项,文件表表项有一个指针指向索引结点表表项。
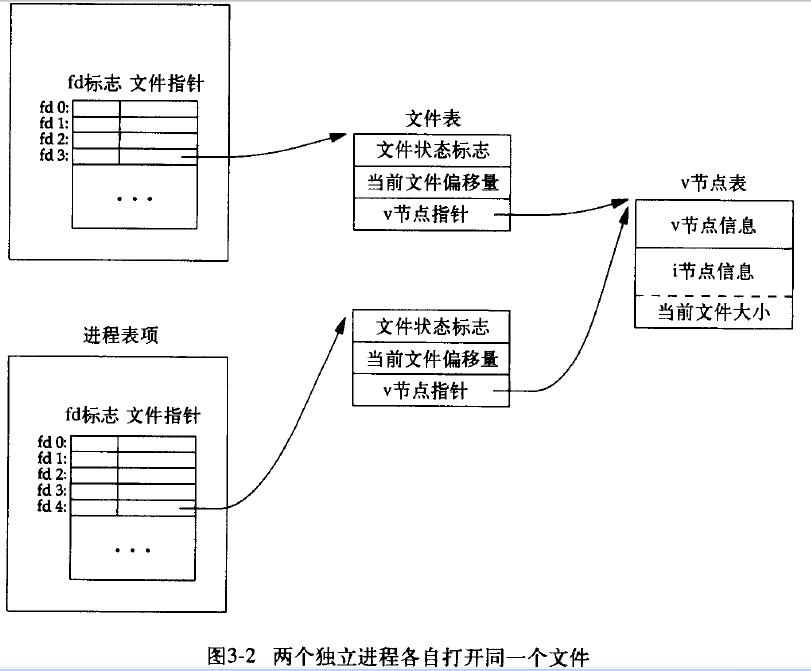
不同的进程打开同一个文件
不同的进程打开同一个文件,那么他们应该有各自对应的文件表表项。因为文件表表项记录了进程读写文件时的偏移量和存取权限。多个进程不可能共享一个文件偏移量。另外他们各自打开文件的权限也可能是不同的,有的是为了读、有的为了写,有的为了读写。所以,他们应该有不同的文件表表项。
此外,因为是同一个文件,所以,多个进程会共享同一个索引结点表项。即他们的文件表表项指针会指向同一个索引结点
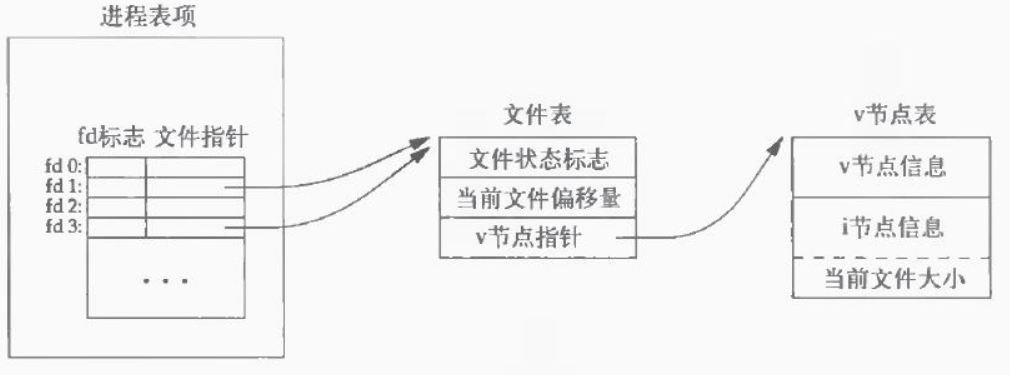
使用dup函数复制一个文件描述符
dup函数是用来复制一个文件描述符的。复制得到的文件描述符和原描述符共享文件偏移量和一些状态。所以dup的作用仅仅是复制一个文件描述符表项,而不会复制一个文件表表项。
于是使用dup函数后,有下图:
同一个进程多次打开同一个文件:
每打开一次同一个文件,内核就会在文件表中增加一个表项。这是因为每次open文件时使用了不同的读写权限,而读写权限是保存在文件表表项里面的。
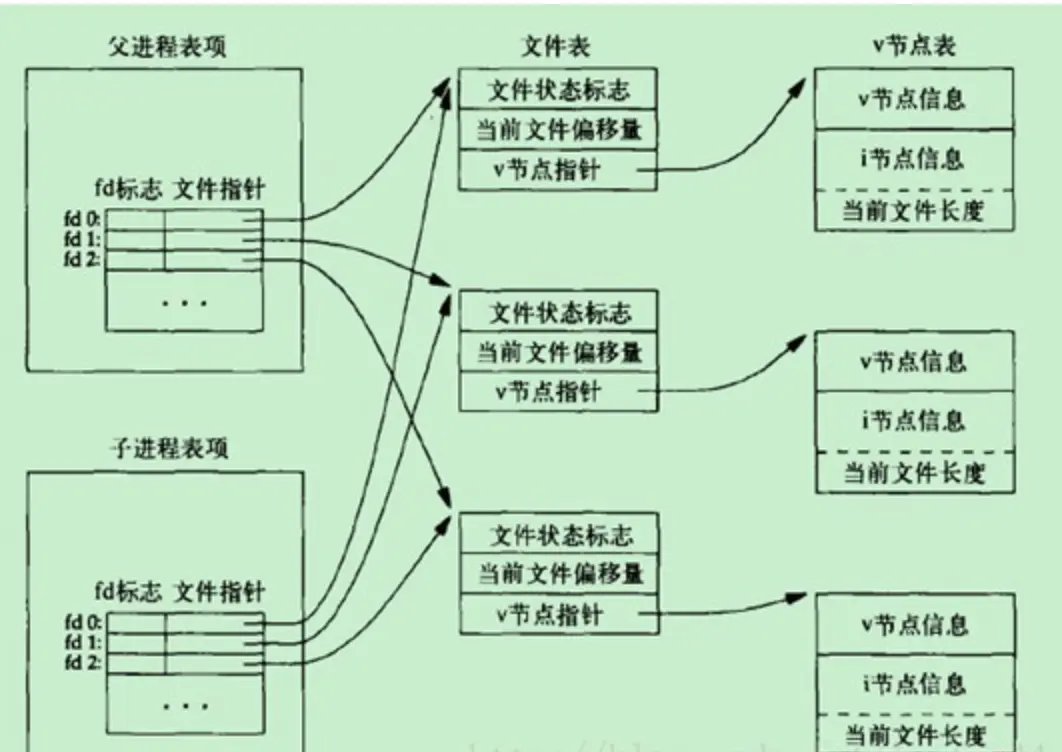
父进程使用fork创建子进程
由于fork一个子进程,子进程将复制父进程的绝大部分东西(除了进程ID、进程的父进程ID、一些时间属性、文件锁)。所以子进程复制了父进程的整个文件描述符表。
命令示例
查看该进程的限制
ps -ef | grep redis
cat /proc/16943/limits
Limit Soft Limit Hard Limit Units
Max cpu time unlimited unlimited seconds
Max file size unlimited unlimited bytes
Max data size unlimited unlimited bytes
Max stack size 8388608 unlimited bytes
Max core file size 0 unlimited bytes
Max resident set unlimited unlimited bytes
Max processes 3731 3731 processes
Max open files 10032 10032 files
Max locked memory 65536 65536 bytes
Max address space unlimited unlimited bytes
Max file locks unlimited unlimited locks
Max pending signals 3731 3731 signals
Max msgqueue size 819200 819200 bytes
Max nice priority 0 0
Max realtime priority 0 0
Max realtime timeout unlimited unlimited us
在 Max open files 那一行,可以看到当前设置中最大文件描述符的数量为10032
- soft 指的是当前系统生效的设置值
- hard 指的是系统中所能设定的最大值
查看该进程占用了多少个文件描述符
ll /proc/16943/fd/
total 0
dr-x------ 2 xxx xxx 0 Nov 27 07:42 ./
dr-xr-xr-x 9 xxx xxx 0 Nov 27 07:42 ../
lrwx------ 1 xxx xxx 64 Nov 27 07:46 0 -> /dev/pts/8
x
lrwx------ 1 xxx xxx 64 Nov 27 07:46 4 -> socket:[329365]
lrwx------ 1 xxx xxx 64 Nov 27 07:46 5 -> socket:[329366]
实际应用过程中,如果出现“Too many open files” , 可以通过增大进程可用的文件描述符数量来解决,但往往故事不会这样结束,很多时候,并不是因为进程可用的文件描述符过少,而是因为程序bug,打开了大量的文件连接(web连接也会占用文件描述符)而没有释放。程序申请的资源在用完后及时释放,才是解决“Too many open files”的根本之道。
文件读写底层原理
系统调用
操作系统的主要功能是为管理硬件资源和为应用程序开发人员提供良好的环境,但是计算机系统的各种硬件资源是有限的,因此为了保证每一个进程都能安全的执行。处理器设有两种模式:“用户模式”与“内核模式”。一些容易发生安全问题的操作都被限制在只有内核模式下才可以执行,例如I/O操作,修改基址寄存器内容等。而连接用户模式和内核模式的接口称之为系统调用。
应用程序代码运行在用户模式下,当应用程序需要实现内核模式下的指令时,先向操作系统发送调用请求。操作系统收到请求后,执行系统调用接口,使处理器进入内核模式。当处理器处理完系统调用操作后,操作系统会让处理器返回用户模式,继续执行用户代码。
进程的虚拟地址空间可分为两部分,内核空间和用户空间。内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中,都是对物理地址的映射。
进程的虚拟地址空间可分为两部分,内核空间和用户空间。内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟空间中,都是对物理地址的映射。
应用程序中实现对文件的操作过程就是典型的系统调用过程。
虚拟文件系统
一个操作系统可以支持多种底层不同的文件系统(比如NTFS, FAT, ext3, ext4),为了给内核和用户进程提供统一的文件系统视图,Linux在用户进程和底层文件系统之间加入了一个抽象层,即虚拟文件系统(Virtual File System, VFS),进程所有的文件操作都通过VFS,由VFS来适配各种底层不同的文件系统,完成实际的文件操作。
通俗的说,VFS就是定义了一个通用文件系统的接口层和适配层,一方面为用户进程提供了一组统一的访问文件,目录和其他对象的统一方法,另一方面又要和不同的底层文件系统进行适配。如图所示:
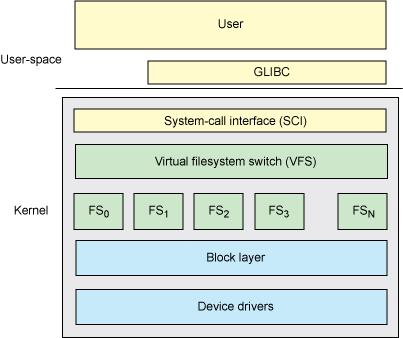
虚拟文件系统主要模块
- 超级块(super_block),用于保存一个文件系统的所有元数据,相当于这个文件系统的信息库,为其他的模块提供信息。因此一个超级块可代表一个文件系统。文件系统的任意元数据修改都要修改超级块。超级块对象是常驻内存并被缓存的。
- 目录项模块,管理路径的目录项。比如一个路径 /home/foo/hello.txt,那么目录项有home, foo, hello.txt。目录项的块,存储的是这个目录下的所有的文件的inode号和文件名等信息。其内部是树形结构,操作系统检索一个文件,都是从根目录开始,按层次解析路径中的所有目录,直到定位到文件。
- inode模块,管理一个具体的文件,是文件的唯一标识,一个文件对应一个inode。通过inode可以方便的找到文件在磁盘扇区的位置。同时inode模块可链接到address_space模块,方便查找自身文件数据是否已经缓存。
- 打开文件列表模块,包含所有内核已经打开的文件。已经打开的文件对象由open系统调用在内核中创建,也叫文件句柄。打开文件列表模块中包含一个列表,每个列表表项是一个结构体struct file,结构体中的信息用来表示打开的一个文件的各种状态参数。
- file_operations模块。这个模块中维护一个数据结构,是一系列函数指针的集合,其中包含所有可以使用的系统调用函数,例如open、read、write、mmap等。每个打开文件(打开文件列表模块的一个表项)都可以连接到file_operations模块,从而对任何已打开的文件,通过系统调用函数,实现各种操作。
- address_space模块,它表示一个文件在页缓存中已经缓存了的物理页。它是页缓存和外部设备中文件系统的桥梁。如果将文件系统可以理解成数据源,那么address_space可以说关联了内存系统和文件系统。
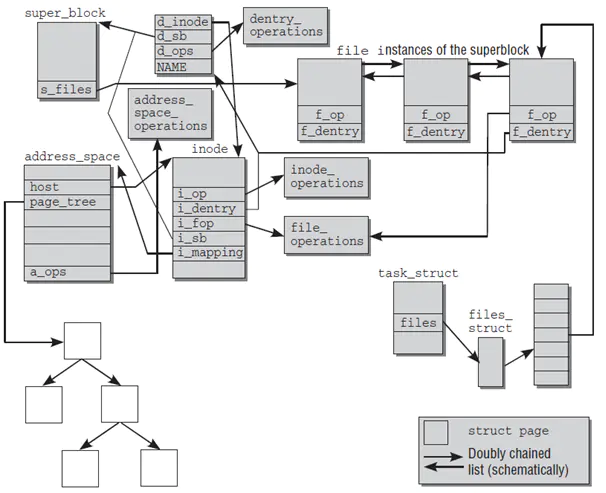
由图可以看出:
- 每个模块都维护了一个X_op指针指向它所对应的操作对象X_operations。
- 超级块维护了一个s_files指针指向了“已打开文件列表模块”,即内核所有的打开文件的链表,这个链表信息是所有进程共享的。
- 目录操作模块和inode模块都维护了一个X_sb指针指向超级块,从而可以获得整个文件系统的元数据信息。
- 目录项对象和inode对象各自维护了指向对方的指针,可以找到对方的数据。
- 已打开文件列表上每一个file结构体实例维护了一个f_dentry指针,指向了它对应的目录项,从而可以根据目录项找到它对应的inode信息。
- 已打开文件列表上每一个file结构体实例维护了一个f_op指针,指向可以对这个文件进行操作的所有函数集合file_operations。
- inode中不仅有和其他模块关联的指针,重要的是它可以指向address_space模块,从而获得自身文件在内存中的缓存信息。
- address_space内部维护了一个树结构来指向所有的物理页结构page,同时维护了一个host指针指向inode来获得文件的元数据。
进程和虚拟文件系统交互
- 内核使用task_struct来表示单个进程的描述符,其中包含维护一个进程的所有信息。task_struct结构体中维护了一个 files的指针(和“已打开文件列表”上的表项是不同的指针)来指向结构体files_struct,files_struct中包含文件描述符表和打开的文件对象信息。
- file_struct中的文件描述符表实际是一个file类型的指针列表(和“已打开文件列表”上的表项是相同的指针),可以支持动态扩展,每一个指针指向虚拟文件系统中文件列表模块的某一个已打开的文件。
- file结构一方面可从f_dentry链接到目录项模块以及inode模块,获取所有和文件相关的信息,另一方面链接file_operations子模块,其中包含所有可以使用的系统调用函数,从而最终完成对文件的操作。这样,从进程到进程的文件描述符表,再关联到已打开文件列表上对应的文件结构,从而调用其可执行的系统调用函数,实现对文件的各种操作。
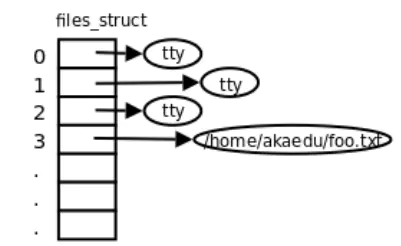
进程 vs 文件列表 vs Inode
- 多个进程可以同时指向一个打开文件对象(文件列表表项),例如父进程和子进程间共享文件对象;
- 一个进程可以多次打开一个文件,生成不同的文件描述符,每个文件描述符指向不同的文件列表表项。但是由于是同一个文件,inode唯一,所以这些文件列表表项都指向同一个inode。通过这样的方法实现文件共享(共享同一个磁盘文件);
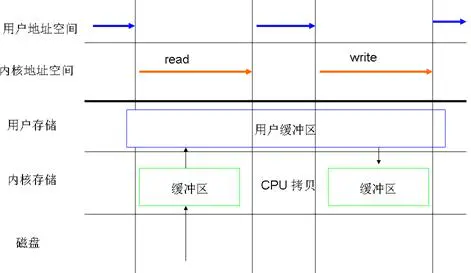
什么是缓存 I/O (Buffered I/O)
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。缓存 I/O 有以下这些优点:
- 缓存 I/O 使用了操作系统内核缓冲区,在一定程度上分离了应用程序空间和实际的物理设备。
- 缓存 I/O 可以减少读盘的次数,从而提高性能。
当应用程序尝试读取某块数据的时候,如果这块数据已经存放在了页缓存中,那么这块数据就可以立即返回给应用程序,而不需要经过实际的物理读盘操作。当然,如果数据在应用程序读取之前并未被存放在页缓存中,那么就需要先将数据从磁盘读到页缓存中去。对于写操作来说,应用程序也会将数据先写到页缓存中去,数据是否被立即写到磁盘上去取决于应用程序所采用的写操作机制:如果用户采用的是同步写机制( synchronous writes ), 那么数据会立即被写回到磁盘上,应用程序会一直等到数据被写完为止;如果用户采用的是延迟写机制( deferred writes ),那么应用程序就完全不需要等到数据全部被写回到磁盘,数据只要被写到页缓存中去就可以了。在延迟写机制的情况下,操作系统会定期地将放在页缓存中的数据刷到磁盘上。与异步写机制( asynchronous writes )不同的是,延迟写机制在数据完全写到磁盘上的时候不会通知应用程序,而异步写机制在数据完全写到磁盘上的时候是会返回给应用程序的。所以延迟写机制本身是存在数据丢失的风险的,而异步写机制则不会有这方面的担心。
缓存 I/O 的缺点
在缓存 I/O 机制中,DMA 方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输,这样的话,数据在传输过程中需要在应用程序地址空间和页缓存之间进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
对于某些特殊的应用程序来说,避开操作系统内核缓冲区而直接在应用程序地址空间和磁盘之间传输数据会比使用操作系统内核缓冲区获取更好的性能,下面提到的自缓存应用程序就是其中的一种。
自缓存应用程序( self-caching applications)
对于某些应用程序来说,它会有它自己的数据缓存机制,比如,它会将数据缓存在应用程序地址空间,这类应用程序完全不需要使用操作系统内核中的高速缓冲存储器,这类应用程序就被称作是自缓存应用程序( self-caching applications )。数据库管理系统是这类应用程序的一个代表。
自缓存应用程序倾向于使用数据的逻辑表达方式,而非物理表达方式;当系统内存较低的时候,自缓存应用程序会让这种数据的逻辑缓存被换出,而并非是磁盘上实际的数据被换出。自缓存应用程序对要操作的数据的语义了如指掌,所以它可以采用更加高效的缓存替换算法。自缓存应用程序有可能会在多台主机之间共享一块内存,那么自缓存应用程序就需要提供一种能够有效地将用户地址空间的缓存数据置为无效的机制,从而确保应用程序地址空间缓存数据的一致性。
对于自缓存应用程序来说,缓存 I/O 明显不是一个好的选择。Linux 中的直接 I/O 技术非常适用于自缓存这类应用程序,该技术省略掉缓存 I/O 技术中操作系统内核缓冲区的使用,数据直接在应用程序地址空间和磁盘之间进行传输,从而使得自缓存应用程序可以省略掉复杂的系统级别的缓存结构,而执行程序自己定义的数据读写管理,从而降低系统级别的管理对应用程序访问数据的影响。在下面一节中,我们会着重介绍 Linux 中提供的直接 I/O 机制的设计与实现,该机制为自缓存应用程序提供了很好的支持。
Linux 2.6 中的直接 I/O 技术
所有的 I/O 操作都是通过读文件或者写文件来完成的。在这里,我们把所有的外围设备,包括键盘和显示器,都看成是文件系统中的文件。访问文件的方法多种多样,这里列出下边这几种 Linux 2.6 中支持的文件访问方式。
标准访问文件的方式
在 Linux 中,这种访问文件的方式是通过两个系统调用实现的:read() 和 write()。当应用程序调用 read() 系统调用读取一块数据的时候,如果该块数据已经在内存中了,那么就直接从内存中读出该数据并返回给应用程序;如果该块数据不在内存中,那么数据会被从磁盘上读到页高缓存中去,然后再从页缓存中拷贝到用户地址空间中去。对于写数据操作来说,当一个进程调用了 write() 系统调用往某个文件中写数据的时候,数据会先从用户地址空间拷贝到操作系统内核地址空间的页缓存中去,然后才被写到磁盘上。但是对于这种标准的访问文件的方式来说,在数据被写到页缓存中的时候,write() 系统调用就算执行完成,并不会等数据完全写入到磁盘上。Linux 在这里采用的是我们前边提到的延迟写机制( deferred writes )。
图 1. 以标准的方式对文件进行读写
同步访问文件的方式
同步访问文件的方式与上边这种标准的访问文件的方式比较类似,这两种方法一个很关键的区别就是:同步访问文件的时候,写数据的操作是在数据完全被写回磁盘上才算完成的;而标准访问文件方式的写数据操作是在数据被写到页高速缓冲存储器中的时候就算执行完成了。
内存映射方式
在很多操作系统包括 Linux 中,内存区域( memory region )是可以跟一个普通的文件或者块设备文件的某一个部分关联起来的,若进程要访问内存页中某个字节的数据,操作系统就会将访问该内存区域的操作转换为相应的访问文件的某个字节的操作。Linux 中提供了系统调用 mmap() 来实现这种文件访问方式。与标准的访问文件的方式相比,内存映射方式可以减少标准访问文件方式中 read() 系统调用所带来的数据拷贝操作,即减少数据在用户地址空间和操作系统内核地址空间之间的拷贝操作。映射通常适用于较大范围,对于相同长度的数据来讲,映射所带来的开销远远低于 CPU 拷贝所带来的开销。当大量数据需要传输的时候,采用内存映射方式去访问文件会获得比较好的效率。
直接 I/O 方式
凡是通过直接 I/O 方式进行数据传输,数据均直接在用户地址空间的缓冲区和磁盘之间直接进行传输,完全不需要页缓存的支持。操作系统层提供的缓存往往会使应用程序在读写数据的时候获得更好的性能,但是对于某些特殊的应用程序,比如说数据库管理系统这类应用,他们更倾向于选择他们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
直接 I/O 的优点
直接 I/O 最主要的优点就是通过减少操作系统内核缓冲区和应用程序地址空间的数据拷贝次数,降低了对文件读取和写入时所带来的 CPU 的使用以及内存带宽的占用。这对于某些特殊的应用程序,比如自缓存应用程序来说,不失为一种好的选择。如果要传输的数据量很大,使用直接 I/O 的方式进行数据传输,而不需要操作系统内核地址空间拷贝数据操作的参与,这将会大大提高性能。
直接 I/O 潜在可能存在的问题
直接 I/O 并不一定总能提供令人满意的性能上的飞跃。设置直接 I/O 的开销非常大,而直接 I/O 又不能提供缓存 I/O 的优势。缓存 I/O 的读操作可以从高速缓冲存储器中获取数据,而直接 I/O 的读数据操作会造成磁盘的同步读,这会带来性能上的差异 , 并且导致进程需要较长的时间才能执行完;对于写数据操作来说,使用直接 I/O 需要 write() 系统调用同步执行,否则应用程序将会不知道什么时候才能够再次使用它的 I/O 缓冲区。与直接 I/O 读操作类似的是,直接 I/O 写操作也会导致应用程序关闭缓慢。所以,应用程序使用直接 I/O 进行数据传输的时候通常会和使用异步 I/O 结合使用。
异步访问文件的方式
Linux 异步 I/O 是 Linux 2.6 中的一个标准特性,其本质思想就是进程发出数据传输请求之后,进程不会被阻塞,也不用等待任何操作完成,进程可以在数据传输的时候继续执行其他的操作。相对于同步访问文件的方式来说,异步访问文件的方式可以提高应用程序的效率,并且提高系统资源利用率。直接 I/O 经常会和异步访问文件的方式结合在一起使用。
socket可读写
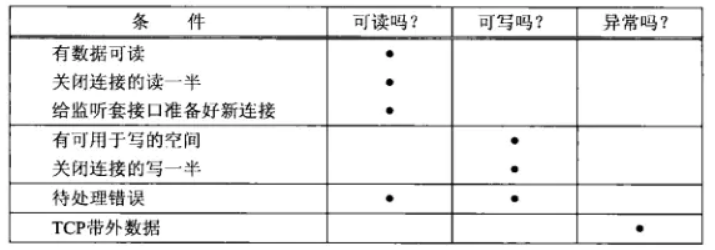
满足下列四个条件中的任何一个时,一个套接字准备好读
- 该套接字接收缓冲区中的数据字节数大于等于套接字接收缓存区低水位。对于TCP和UDP套接字而言,缓冲区低水位的值默认为1。那就意味着,默认情况下,只要缓冲区中有数据,那就是可读的。我们可以通过使用SO_RCVLOWAT套接字选项(参见setsockopt函数)来设置该套接字的低水位大小。此种描述符就绪(可读)的情况下,当我们使用read/recv等对该套接字执行读操作的时候,套接字不会阻塞,而是成功返回一个大于0的值(即可读数据的大小)。
- 该连接的读半部关闭(也就是接收了FIN的TCP连接)。对这样的套接字的读操作,将不会阻塞,而是返回0(也就是EOF)。
- 该套接字是一个listen的监听套接字,并且目前已经完成的连接数不为0。对这样的套接字进行accept操作通常不会阻塞。
- 有一个错误套接字待处理。对这样的套接字的读操作将不阻塞并返回-1(也就是返回了一个错误),同时把errno设置成确切的错误条件。这些待处理错误(pending error)也可以通过指定SO_ERROR套接字选项调用getsockopt获取并清除。
满足下列四个条件中的任何一个时,一个套接字准备好写。
- 该套接字发送缓冲区中的可用空间字节数大于等于套接字发送缓存区低水位标记时,并且该套接字已经成功连接(UDP套接字不需要连接)。对于TCP和UDP而言,这个低水位的值默认为2048,而套接字默认的发送缓冲区大小是8k,这就意味着一般一个套接字连接成功后,就是处于可写状态的。我们可以通过SO_SNDLOWAT套接字选项(参见setsockopt函数)来设置这个低水位。此种情况下,我们设置该套接字为非阻塞,对该套接字进行写操作(如write,send等),将不阻塞,并返回一个正值(例如由传输层接受的字节数,即发送的数据大小)。
- 该连接的写半部关闭(主动发送FIN包的TCP连接)。对这样的套接字的写操作将会产生SIGPIPE信号。所以我们的网络程序基本都要自定义处理SIGPIPE信号。因为SIGPIPE信号的默认处理方式是程序退出。
- 使用非阻塞的connect套接字已建立连接,或者connect已经以失败告终。即connect有结果了。
- 有一个错误的套接字待处理。对这样的套接字的写操作将不阻塞并返回-1(也就是返回了一个错误),同时把errno设置成确切的错误条件。这些待处理的错误也可以通过指定SO_ERROR套接字选项调用getsockopt获取并清除。
我认为,想要熟练掌握Linux下的TCP/IP网络编程,至少有三个层面的知识需要熟悉:
- TCP/IP协议(如连接的建立和终止、重传和确认、滑动窗口和拥塞控制等等)
- Socket I/O系统调用(重点如read/write),这是TCP/IP协议在应用层表现出来的行为。
- 编写Performant, Scalable的服务器程序。包括多线程、IO Multiplexing、非阻塞、异步等各种技术。
Linux Disk Quota实践
TIPS
quota的一些使用条件
- Linux内核必须支持quota功能,xfs文件系统本身内置quota
- quota在 usrquota/grpquota 模式下只针对普通用户有效,root无法进行限制
- 关闭SElinux(测试建议关闭)
- ext 文件系统仅针对整个挂载点限制(即只能基于用户 或 群组进行容量限制,无法针对某一目录进行容量限制)
- 如果限制目录,尽量不要针对根目录"/"
- quota 针对整个 filesystem 进行限制
###quota的使用模式
- usrquota:针对用户的设定,仅对普通用户生效,对root无效
- grpquota:针对群组的设定
- prjquota:针对某个目录的设定,不可与grpquota同时使用(xfs_quota支持)
quota的操作主要流程
- 关闭SELinux(测试建议关闭)
- 编辑/etc/fstab,针对某个文件系统添加quota激活选项
- 重新挂载指定挂载点
- 验证quota功能是否生效
- 使用quota相关命令针对某用户、用户组或某目录设置限制策略
- 验证磁盘quota策略是否生效
- 查看磁盘quota使用情况
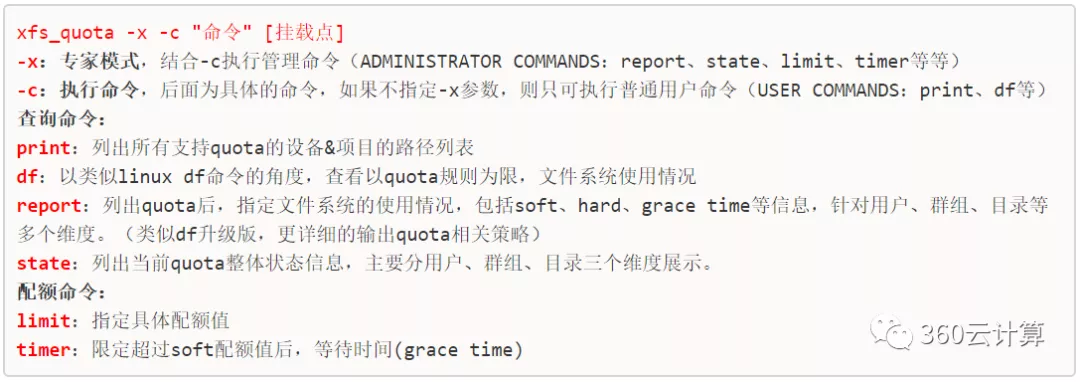
xfs_quota命令概述
xfs_quota命令在下面用到很多,简单总结一下常用参数和作用,如下所示:
关于grace time
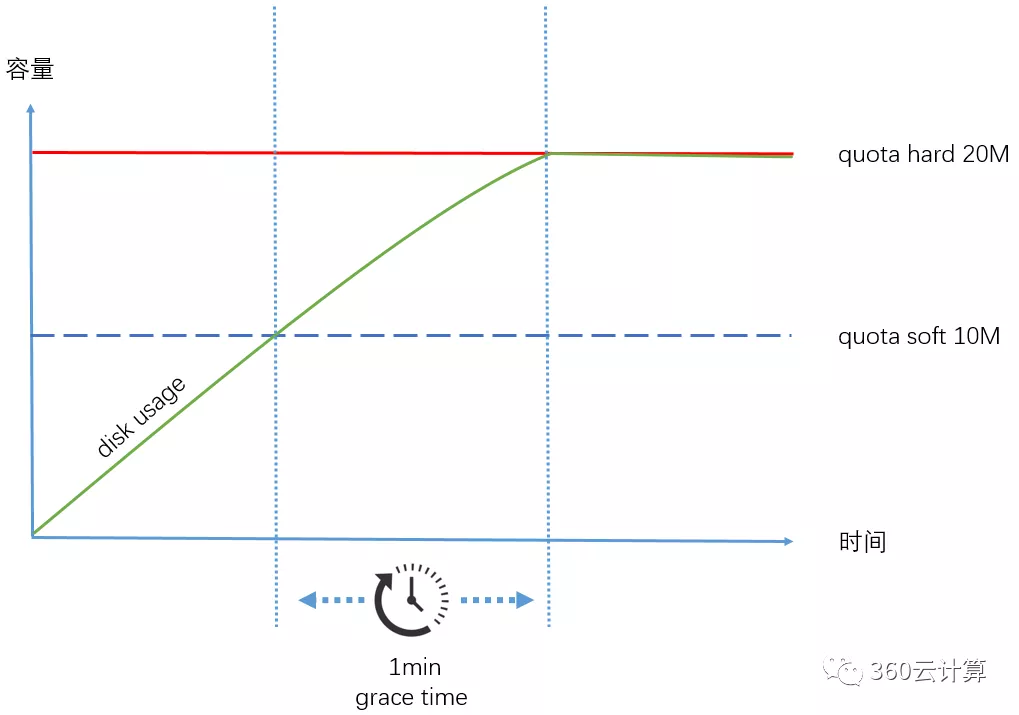
grace time 的主要作用是当超过quota soft限制用量的情况下,给予一定的宽限时间,当超过grace time,则不可写入,如下图所示。下面案例中会具体用到。
准备:确定Selinux关闭
sestatus -v
SELinux status: disabled
# 如果是enable状态,临时关闭
setenforce 0
# 持久关闭
vi /etc/selinux/config
SELINUX=disabled
注:如果线上需要开启,可详细查看selinux支持quota的相关参数。
基于用户的配额限制
添加quota激活选项
根据quota限制维度,添加参数usrquota(用户配额),grpquota(组配额)
# vi /etc/fstab
###此处忽略其它配置项,追加如下内容###
##只针对user限制(如果同时需要用户和组限制,添加usrquota,grpquota)
/dev/sdb1 /data xfs defaults,nodiratime,noatime,usrquota 1 2
remount 挂载点
umount /data
mount -a
注:xfs文件系统无法通过mount -o remount方式来启动quota功能,必须使用上述方式;
下面检查是否生效:
mount |grep data
/dev/sdb1 on /data type xfs (rw,noatime,nodiratime,attr2,inode64,logbufs=8,logbsize=32k,usrquota)
注:如果 umount 时报错:umount: /data: target is busy,就用lsof /data 查看是否有进程在使用,kill掉进程重试。
查看配额是开启
xfs_quota -x -c "state"
User quota state on /data (/dev/sdb1) #可以看到只有user quota是开启的
Accounting: ON
Enforcement: ON
Inode: #71 (2 blocks, 2 extents)
Group quota state on /data (/dev/sdb1)
Accounting: OFF
Enforcement: OFF
Inode: #67 (1 blocks, 1 extents)
Project quota state on /data (/dev/sdb1)
Accounting: OFF
Enforcement: OFF
Inode: #67 (1 blocks, 1 extents)
Blocks grace time: [7 days]
Inodes grace time: [7 days]
Realtime Blocks grace time: [7 days]
注:如果提示没有xfs_quota命令,则需要 yum -y install xfsprogs 安装
对mysql用户进行quota限制
soft配额10M,hard配额20M,grace time 1分钟
## mysql是用户名,配额 soft 10M,hard 20M
xfs_quota -x -c "limit -u bsoft=10M bhard=20M mysql" /data
## 超过Soft配额1分钟后,被限制
xfs_quota -x -c 'timer -u -b 1minutes' /data
## 当超过soft阈值后,Warn/Grace会开始1分钟倒计时
xfs_quota -x -c "report -ubih" /data
User quota on /data (/dev/sdb1)
Blocks Inodes
User ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
root 0 0 0 00 [0 days] 2 0 0 00 [0 days]
mysql 0 10M 20M 00 [------] 0 0 0 00 [------]
测试
场景一:超过hard配额,被限制。
$ su - mysql
$ pwd
/data
$ dd if=/dev/zero of=test.dat bs=1M count=30
dd: error writing ‘test.dat’: Disk quota exceeded
21+0 records in
20+0 records out
20971520 bytes (21 MB) copied, 0.0284925 s, 736 MB/s
## Blocks(Used)表示写入了20M数据,超过Blocks(Hard)配额后,直接被限制写入
$ xfs_quota -x -c "report -ubih" /data
User quota on /data (/dev/sdb1)
Blocks Inodes
User ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
mysql 20M 10M 20M 00 00:00:41 3 0 0 00 [------]
场景二:超过soft配额,并且超过设置的1分钟grace time,被限制。
$ su - mysql
$ pwd
/data
$ dd if=/dev/zero of=test.dat bs=1M count=15
15+0 records in
15+0 records out
15728640 bytes (16 MB) copied, 0.0206793 s, 761 MB/s
## Blocks(Used)表示只写入了15M数据,bsoft<15M<bhard
## 超过Blocks(Soft)配额后开始grace time的1分钟倒计时(见Warn/Grace列)
$ xfs_quota -x -c "report -ubih" /data
User quota on /data (/dev/sdb1)
Blocks Inodes
User ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
mysql 15M 10M 20M 00 00:00:58 3 0 0 00 [------]
## 超过Blocks(Soft)配额1分钟后
$ xfs_quota -x -c "report -ubih" /data
User quota on /data (/dev/sdb1)
Blocks Inodes
User ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
mysql 15M 10M 20M 00 [0 days] 3 0 0 00 [------]
## 再次写入失败
$ dd if=/dev/zero of=test02.dat bs=1M count=1
dd: failed to open ‘test02.dat’: Disk quota exceeded
注:上述只是限制mysql用户在/data 挂载点的使用
说明:
- bsoft是软限制,磁盘空间超过bsoft,但小于bhard,此时将进入“宽限期”(grace time)倒计时,如果在宽限期间内将容量降低到bsoft以下,则grace time消失,否则拒绝继续写入
- bhard是硬限制,超过此限制值,将无法再继续写入
其它目录测试
在其他挂载点是不限制的,例如/home/mysql下:
$ su - mysql
$ cd /home/mysql
$ dd if=/dev/zero of=test.dat bs=1M count=50
50+0 records in
50+0 records out
52428800 bytes (52 MB) copied, 0.0190618 s, 2.8 GB/s
$ ll
total 51200
-rw-r--r-- 1 mysql mysql 52428800 Jul 5 02:17 test.dat
$ pwd
/home/mysql
至此,基于用户的quota方案,部署就完成了。
基于目录的配额限制
添加quota激活选项
修改/etc/fstab,添加 prjquota(即单一目录配额模式)
# vi /etc/fstab
/dev/sdb1 /data xfs defaults,nodiratime,noatime,prjquota 1 2
remount 挂载点
umount /data
mount -a
注:xfs文件系统无法通过mount -o remount方式来启动quota功能,必须使用上述方式。
下面检查是否生效:
# mount | grep data
/dev/sdb1 on /data type xfs (rw,noatime,nodiratime,attr2,inode64,logbufs=8,logbsize=32k,prjquota)
注:如果umount时报错:umount: /data: target is busy,就用lsof /data 查看是否有进程在使用,如进程无用,kill掉进程重试。
查看配额是否开启
通过如下命令也可以查看到quota基于project的配额限制功能是开启状态
# xfs_quota -x -c 'state'
User quota state on /data (/dev/sdb1)
Accounting: OFF
Enforcement: OFF
Inode: #71 (2 blocks, 2 extents)
Group quota state on /data (/dev/sdb1)
Accounting: OFF
Enforcement: OFF
Inode: #67 (1 blocks, 1 extents)
Project quota state on /data (/dev/sdb1) ##可以看到只有project quota是开启的
Accounting: ON
Enforcement: ON
Inode: #67 (1 blocks, 1 extents)
Blocks grace time: [7 days]
Inodes grace time: [7 days]
Realtime Blocks grace time: [7 days
注:如果提示没有xfs_quota命令,则需要 yum -y install xfsprogs安装
创建目录和项目名对应关系
创建项目标识语句如下
# 创建项目id与目录的对应关系
echo "1:/data/mysqldata" >> /etc/projects
# 创建项目id与项目名称的对应关系,即给项目id起个别名
echo "mysqldata:1" >> /etc/projid
初始化项目语句如下:
xfs_quota -x -c "project -s mysqldata"
Setting up project mysqldata (path /data/mysqldata)...
Processed 1 (/etc/projects and cmdline) paths for project mysqldata with recursion depth infinite (-1).
Setting up project mysqldata (path /data/mysqldata)...
Processed 1 (/etc/projects and cmdline) paths for project mysqldata with recursion depth infinite (-1).
Setting up project mysqldata (path /data/mysqldata)...
Processed 1 (/etc/projects and cmdline) paths for project mysqldata with recursion depth infinite (-1).
注:会显示上述一堆这样的信息,不要害怕,是OK的,一切尽在掌握之中
此时可以查看到目录是否存在对应项目:
xfs_quota -x -c "print" /data
Filesystem Pathname
/data /dev/sdb1 (pquota)
/data/mysqldata /dev/sdb1 (project 1, mysqldata)
设置目录quota大小
# 针对项目mysqldata设置10M容量硬限制
xfs_quota -x -c "limit -p bsoft=6M bhard=10M mysqldata" /data
# 查看是否生效,以及使用情况
xfs_quota -x -c "report -bih" /data
Project quota on /data (/dev/sdb1)
Blocks Inodes
Project ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
#0 20M 0 0 00 [------] 4 0 0 00 [------]
mysqldata 0 6M 10M 00 [------] 1 0 0 00 [------]
说明:
- bsoft是软限制,磁盘空间超过bsoft,但小于bhard,此时将进入“宽限期”(grace time)倒计时,如果在宽限期间内将容量降低到bsoft以下,则grace time消失,否则拒绝继续写入;
- bhard是硬限制,超过此限制值,将无法再继续写入;
测试
此时在目录/data/mysqldata/下写入15M文件,则报错,并且只写入了10M内容
dd if=/dev/zero of=/data/mysqldata/test.dat bs=1M count=15
dd: error writing ‘/data/mysqldata/test.dat’: No space left on device
11+0 records in
10+0 records out
10485760 bytes (10 MB) copied, 0.296038 s, 35.4 MB/s
du -sh /data/mysqldata/*
10M /data/mysqldata/test.dat
此时可以通过如下命令查看使用情况:
xfs_quota -x -c "df -h" /data/
Filesystem Size Used Avail Use% Pathname
/dev/sdb1 6.0G 62.2M 5.9G 1% /data
/dev/sdb1 6M 10M 8192.0E 167% /data/mysqldata
如果想要另外添加新的限制目录,就根据上面步骤进行即可;
至此,基于单一目录的quota方案,部署就完成了。
常用运维命令
暂时关闭quota限制功能
xfs_quota -x -c "disable -up" /data
xfs_quota -x -c "state" /data
User quota state on /data (/dev/sdb1)
Accounting: OFF
Enforcement: OFF
Inode: #71 (2 blocks, 2 extents)
Group quota state on /data (/dev/sdb1)
Accounting: OFF
Enforcement: OFF
Inode: #67 (1 blocks, 1 extents)
Project quota state on /data (/dev/sdb1)
Accounting: ON
Enforcement: OFF ##可以看到OFF状态了
Inode: #67 (1 blocks, 1 extents)
Blocks grace time: [7 days]
Inodes grace time: [7 days]
Realtime Blocks grace time: [7 days
重新开启quota功能
xfs_quota -x -c "enable -p" /data
彻底关闭quota功能
xfs_quota -x -c "off -up" /data
注:之后就不能再通过enable方式启动了,必须执行:umount /data;mount -a 重新激活quota功能
调大容量限制
直接重新执行一遍设置就好:
# 针对用户
xfs_quota -x -c "limit -u bsoft=100M bhard=200M mysql" /data
# 针对目录
xfs_quota -x -c "limit -p bsoft=60M bhard=100M mysqldata" /data
重建目录会影响quota限制吗?
重建目录会影响quota限制,无论是如下哪种方式新建的相同名字目录都会失去quota的限制:
mv /data/mysqldata /data/mysqldata_bak
mkdir /data/mysqldata
或者:
rm -rm /data/mysqldata
mkdir /data/mysqldata
解决方法:
使用如下方式重新初始化这个项目:
xfs_quota -x -c "project -s mysqldata"
注:仅仅这样初始化一下就好,无需再去重新设定限制
如何调整“宽限期”(grace time)
宽限期,分为user、group、project维度,通过timer -u -g -p修改
# 针对user,用户的grace time时间
xfs_quota -x -c "timer -u -b 14days" /data
# 针对group,用户组的grace time时间
xfs_quota -x -c "timer -g -b 14days" /data
# 针对project,单一目录的grace time时间
xfs_quota -x -c "timer -p -b 14days" /data