
slab
Linux内存管理模式,页式管理适合于大块内存的情形,而对于内核对象级别的较小内存情形下,不足以占用1个页。
在linux内核中会有许多小对象,这些对象构造销毁十分频繁,比如i-node,dentry。这么这些对象如果每次构建的时候就向内存要一个页,而其实际大小可能只有几个字节,这样就非常浪费,为了解决这个问题就引入了一种新的机制来处理在同一页框中如何分配小存储器区。这就是我们要讨论的slab层。在讲述slab前,我想先铺垫一下有关内存页的概念,我们都知道在linux中内存都是以页为单位来进行管理的(通常为4KB),当内核需要内存就调用如:kmem_getpages这样的接口(底层调用__alloc_pages())。那么内核是如何管理页的分配的,这里linux使用了伙伴算法。slab也是向内核申请一个个页,然后再对这些页框做管理来达到分配小存储区的目的的。
什么是Slab呢?
Slab是一种内存分配器,通过将内存划分不同大小的空间分配给对象使用来进行缓存管理,应用于内核对象的缓存。
说明:这些对象包括inode信息,目录项信息,dentries等
查看 slab 内存分配情况
# 其中Slab = SReclaimable + SUnreclaim,SReclaimable 表示可回收使用的内存。
cat /proc/meminfo | grep -E "Slab|SReclaimable|SUnreclaim"
Slab: 193492 kB
SReclaimable: 123080 kB
SUnreclaim: 70412 kB
Slab的两个主要作用
- Slab对小对象进行分配,不用为每个小对象分配一个页,节省了空间。
- 内核中一些小对象创建析构很频繁,Slab对这些小对象做缓存,可以重复利用一些相同的对象,减少内存分配次数。
slabinfo
在Slab中,可分配内存块称为对象,下图中kmalloc-8表示每个对象占用8Bit大小的普通Slab,同理kmalloc-16中每个对象占用16B,依次类推,找出Slab中占用量较大的对象是哪些?
每种对象占用总内存量 = num_objs * objsize
$ slabinfo
Name Objects Objsize Space Slabs/Part/Cpu O/S O %Fr %Ef Flg
Acpi-Namespace 680 48 32.7K 6/0/2 85 0 0 99
Acpi-Operand 2016 72 147.4K 10/0/26 56 0 0 98
Acpi-Parse 146 56 8.1K 0/0/2 73 0 0 99
Acpi-ParseExt 102 80 8.1K 0/0/2 51 0 0 99
Acpi-State 306 80 24.5K 0/0/6 51 0 0 99
aio_kiocb 21 136 4.0K 0/0/1 21 0 0 69 A
anon_vma 4314 80 442.3K 97/38/11 46 0 35 78
anon_vma_chain 7113 64 491.5K 96/26/24 64 0 21 92
audit_buffer 340 24 8.1K 0/0/2 170 0 0 99
avc_node 112 72 8.1K 0/0/2 56 0 0 98
bdev_cache 34 896 32.7K 0/0/2 17 2 0 92 Aa
bio-0 240 224 61.4K 1/0/14 16 0 0 87 A
bio-1 36 288 12.2K 2/0/1 12 0 0 84 A
bio-2 32 248 8.1K 0/0/2 16 0 0 96 A
bio_integrity_payload 16 216 4.0K 0/0/1 16 0 0 84 A
biovec-128 80 2048 294.9K 4/4/5 16 3 44 55 A
biovec-16 256 256 65.5K 0/0/16 16 0 0 100 A
biovec-64 128 1024 131.0K 0/0/8 16 2 0 100 A
biovec-max 92 8192 851.9K 22/4/4 4 3 15 88 A
blkdev_ioc 308 144 45.0K 0/0/11 28 0 0 98
bridge_fdb_cache 64 128 8.1K 0/0/2 32 0 0 100 A
buffer_head 113054 104 13.5M 3285/2032/11 39 0 61 87 a
configfs_dir_cache 92 88 8.1K 0/0/2 46 0 0 98
cred_jar 817 168 217.0K 22/22/31 21 0 41 63 A
dax_cache 18 832 16.3K 0/0/1 18 2 0 91 Aa
dentry 91311 192 19.3M 4692/1385/25 21 0 29 90 a
dma-kmalloc-512 32 512 16.3K 0/0/2 16 1 0 100 d
dmaengine-unmap-128 15 1056 16.3K 0/0/1 15 2 0 96 A
dmaengine-unmap-16 21 160 4.0K 0/0/1 21 0 0 82 A
dmaengine-unmap-2 64 48 4.0K 0/0/1 64 0 0 75 A
dmaengine-unmap-256 15 2080 32.7K 0/0/1 15 3 0 95 A
eventpoll_epi 1912 128 253.9K 6/4/56 32 0 6 96 A
eventpoll_pwq 1456 72 106.4K 2/0/24 56 0 0 98
ext4_allocation_context 64 128 8.1K 0/0/2 32 0 0 100 a
ext4_extent_status 8482 40 843.7K 172/167/34 102 0 81 40 a
ext4_free_data 584 56 32.7K 0/0/8 73 0 0 99 a
ext4_groupinfo_4k 644 144 94.2K 22/0/1 28 0 0 98 a
ext4_inode_cache 27896 1168 37.5M 1134/215/13 27 3 18 86 a
ext4_io_end 832 64 53.2K 0/0/13 64 0 0 100 a
ext4_prealloc_space 117 104 12.2K 0/0/3 39 0 0 99 a
ext4_system_zone 102 40 4.0K 0/0/1 102 0 0 99
fanotify_event_info 219 56 12.2K 0/0/3 73 0 0 99
fasync_cache 85 48 4.0K 0/0/1 85 0 0 99
fib6_nodes 128 64 8.1K 0/0/2 64 0 0 100 A
file_lock_cache 54 216 12.2K 0/0/3 18 0 0 94
file_lock_ctx 219 56 12.2K 0/0/3 73 0 0 99
files_cache 460 704 327.6K 0/0/20 23 2 0 98 A
filp 5707 256 1.4M 352/4/6 16 0 1 99 A
fs_cache 832 56 53.2K 0/0/13 64 0 0 87 A
fscache_cookie_jar 30 136 4.0K 0/0/1 30 0 0 99
fsnotify_mark 112 72 8.1K 0/0/2 56 0 0 98
fsnotify_mark_connector 1020 24 24.5K 0/0/6 170 0 0 99
ftrace_event_field 4420 48 212.9K 50/0/2 85 0 0 99
hugetlbfs_inode_cache 12 672 8.1K 0/0/1 12 1 0 98
inet_peer_cache 42 152 8.1K 0/0/2 21 0 0 77 A
inode_cache 21384 648 14.5M 1776/0/6 12 1 0 94 a
inotify_inode_mark 1122 80 90.1K 1/0/21 51 0 0 99
ip6_dst_cache 24 320 8.1K 0/0/2 12 0 0 93 A
ip_dst_cache 112 240 28.6K 0/0/7 16 0 0 93 A
ip_fib_alias 146 56 8.1K 0/0/2 73 0 0 99
ip_fib_trie 170 48 8.1K 0/0/2 85 0 0 99
ip_vs_conn 132 320 45.0K 0/0/11 12 0 0 93 A
isofs_inode_cache 46 696 32.7K 0/0/2 23 2 0 97 a
jbd2_inode 4232 64 360.4K 75/39/13 64 0 44 75
jbd2_journal_handle 146 56 8.1K 0/0/2 73 0 0 99 a
jbd2_journal_head 1224 112 163.8K 4/4/36 34 0 10 83 a
jbd2_revoke_record_s 896 32 28.6K 0/0/7 128 0 0 100 Aa
jbd2_revoke_table_s 256 16 4.0K 0/0/1 256 0 0 100 a
jbd2_transaction_s 112 224 28.6K 0/0/7 16 0 0 87 Aa
kernfs_iattrs_cache 306 80 24.5K 1/0/5 51 0 0 99
kernfs_node_cache 49740 128 6.7M 1628/0/30 30 0 0 93
key_jar 160 200 40.9K 0/0/10 16 0 0 78 A
khugepaged_mm_slot 204 40 8.1K 0/0/2 102 0 0 99
kioctx 46 704 32.7K 0/0/2 23 2 0 98 A
kmalloc-128 6087 128 786.4K 171/12/21 32 0 6 99
kmalloc-16 12574 16 212.9K 33/16/19 256 0 30 94
kmalloc-192 9347 192 2.3M 526/318/40 21 0 56 77
kmalloc-1k 3179 1024 3.3M 194/38/10 16 2 18 97
kmalloc-256 2177 256 630.7K 145/47/9 16 0 30 88
kmalloc-2k 1569 2048 3.6M 102/53/10 16 3 47 87
kmalloc-32 246174 32 7.8M 1906/34/22 128 0 1 99
kmalloc-4k 2844 4096 11.6M 352/9/5 8 3 2 99
kmalloc-512 7343 512 4.4M 523/370/17 16 1 68 84
kmalloc-64 25836 64 1.9M 458/205/12 64 0 43 85
kmalloc-8 10240 8 81.9K 4/0/16 512 0 0 100
kmalloc-8k 65 8192 589.8K 15/4/3 4 3 22 90
kmalloc-96 3514 96 393.2K 77/61/19 42 0 63 85
kmalloc-rcl-128 1047 128 151.5K 9/5/28 32 0 13 88 a
kmalloc-rcl-192 14550 192 9.6M 2330/1778/16 21 0 75 29 a
kmalloc-rcl-256 128 256 32.7K 0/0/8 16 0 0 100 a
kmalloc-rcl-512 144 512 73.7K 3/0/6 16 1 0 100 a
kmalloc-rcl-64 3072 64 196.6K 11/0/37 64 0 0 100 a
kmalloc-rcl-96 2982 96 315.3K 67/30/10 42 0 38 90 a
kmem_cache 234 440 106.4K 11/0/2 18 1 0 96 A
kmem_cache_node 320 64 20.4K 3/0/2 64 0 0 100 A
mbcache 146 56 8.1K 0/0/2 73 0 0 99 a
mm_struct 151 1128 212.9K 7/7/6 14 2 53 79 A
mnt_cache 2352 384 966.6K 107/26/11 21 1 22 93 A
mqueue_inode_cache 32 968 32.7K 0/0/2 16 2 0 94 A
names_cache 48 4096 196.6K 0/0/6 8 3 0 100 A
net_namespace 8 8000 65.5K 0/0/2 4 3 0 97
nf_conntrack 468 256 192.5K 41/18/6 12 0 38 62 A
nfs_commit_data 21 728 16.3K 0/0/1 21 2 0 93 A
nfs_inode_cache 28 1144 32.7K 0/0/2 14 2 0 97 a
nfs_write_data 34 904 32.7K 1/0/1 17 2 0 93 A
nsproxy 112 72 8.1K 0/0/2 56 0 0 98
numa_policy 15 264 4.0K 0/0/1 15 0 0 96
ovl_inode 15879 728 12.1M 722/34/20 22 2 4 95 a
pde_opener 204 40 8.1K 0/0/2 102 0 0 99
pid 1026 72 143.3K 9/9/26 32 0 25 51 A
pid_2 608 88 77.8K 0/0/19 32 0 0 68 A
pid_namespace 32 248 8.1K 0/0/2 16 0 0 96
PING 28 1120 32.7K 0/0/2 14 2 0 95 A
PINGv6 24 1320 32.7K 0/0/2 12 2 0 96 A
pool_workqueue 32 256 8.1K 0/0/2 16 0 0 100
posix_timers_cache 30 272 8.1K 0/0/2 15 0 0 99
proc_dir_entry 936 256 241.6K 51/1/8 16 0 1 99
proc_inode_cache 2971 720 2.6M 151/70/12 22 2 42 80 a
radix_tree_node 20339 576 12.2M 1472/385/21 14 1 25 95 a
RAW 42 1128 49.1K 1/0/2 14 2 0 96 A
RAWv6 48 1320 65.5K 2/0/2 12 2 0 96 A
request_queue 24 2576 65.5K 0/0/2 12 3 0 94
request_sock_TCP 108 328 36.8K 0/0/9 12 0 0 96
request_sock_TCPv6 36 328 12.2K 0/0/3 12 0 0 96
rpc_buffers 32 2048 65.5K 0/0/2 16 3 0 100 A
rpc_inode_cache 46 688 32.7K 0/0/2 23 2 0 96 Aa
rpc_tasks 32 248 8.1K 0/0/2 16 0 0 96 A
scsi_sense_cache 64 96 8.1K 0/0/2 32 0 0 75 A
selinux_file_security 512 16 8.1K 0/0/2 256 0 0 100
selinux_inode_security 15533 40 663.5K 146/28/16 102 0 17 93
seq_file 64 128 8.1K 0/0/2 32 0 0 100
sgpool-128 8 4096 32.7K 0/0/1 8 3 0 100 A
sgpool-16 32 512 16.3K 0/0/2 16 1 0 100 A
sgpool-32 32 1024 32.7K 0/0/2 16 2 0 100 A
sgpool-64 16 2048 32.7K 0/0/1 16 3 0 100 A
sgpool-8 32 256 8.1K 0/0/2 16 0 0 100 A
shmem_inode_cache 4096 760 3.2M 180/1/16 21 2 0 96
sighand_cache 216 2088 557.0K 11/11/6 15 3 64 80 A
signal_cache 227 1192 344.0K 12/12/9 13 2 57 78 A
sigqueue 102 80 8.1K 0/0/2 51 0 0 99
skbuff_fclone_cache 84 520 90.1K 5/5/6 14 1 45 48 A
skbuff_head_cache 432 256 110.5K 12/0/15 16 0 0 100 A
sock_inode_cache 897 696 671.7K 31/14/10 23 2 34 92 Aa
task_delay_info 1428 80 114.6K 0/0/28 51 0 0 99
task_group 360 896 360.4K 11/8/11 18 2 36 89
task_struct 798 6080 5.3M 155/13/8 5 3 7 90
taskstats 92 344 32.7K 0/0/4 23 1 0 96
TCP 326 2440 917.5K 21/6/7 13 3 21 86 A
tcp_bind_bucket 384 72 49.1K 4/0/8 32 0 0 56 A
TCPv6 84 2592 229.3K 0/0/7 12 3 0 94 A
trace_event_file 1748 88 155.6K 36/0/2 46 0 0 98
tw_sock_TCP 135 264 36.8K 0/0/9 15 0 0 96
tw_sock_TCPv6 30 264 8.1K 0/0/2 15 0 0 96
UDP 72 1280 98.3K 0/0/6 12 2 0 93 A
UDPv6 44 1472 65.5K 0/0/2 22 3 0 98 A
uid_cache 42 160 8.1K 0/0/2 21 0 0 82 A
UNIX 426 1152 540.6K 24/8/9 14 2 24 90 A
uts_namespace 36 440 16.3K 0/0/2 18 1 0 96
vm_area_struct 10933 232 2.6M 618/25/31 17 0 3 95
vmap_area 2550 64 208.8K 34/26/17 64 0 50 78
slabinfo 经常关注的项
slabinfo | grep -E "dentry|inode"
dentry 85992 192 17.7M 4323/675/10 21 0 15 93 a
ext4_inode_cache 20744 1168 29.5M 894/268/7 27 3 29 82 a
hugetlbfs_inode_cache 12 672 8.1K 0/0/1 12 1 0 98
inode_cache 23232 648 15.8M 1932/0/4 12 1 0 94 a
inotify_inode_mark 1122 80 90.1K 1/0/21 51 0 0 99
isofs_inode_cache 46 696 32.7K 0/0/2 23 2 0 97 a
jbd2_inode 4324 64 360.4K 69/37/19 64 0 42 76
mqueue_inode_cache 32 968 32.7K 0/0/2 16 2 0 94 A
nfs_inode_cache 28 1144 32.7K 0/0/2 14 2 0 97 a
ovl_inode 15581 728 11.9M 721/37/10 22 2 5 94 a
proc_inode_cache 2746 720 2.1M 120/16/10 22 2 12 92 a
rpc_inode_cache 46 688 32.7K 0/0/2 23 2 0 96 Aa
selinux_inode_security 15533 40 663.5K 146/28/16 102 0 17 93
shmem_inode_cache 4104 760 3.2M 180/2/16 21 2 1 97
sock_inode_cache 904 696 655.3K 22/8/18 23 2 20 96 Aa
- dentry 行表示目录项缓存
- inode_cache 行,表示 VFS 索引节点缓存
- 其余的则是各种文件系统的索引节点缓存。
- 可以通过 man slabinfo 查看
slabtop
slabtop命令 以实时的方式显示内核“slab”缓冲区的细节信息。
Active / Total Objects (% used) : 807005 / 892631 (90.4%)
Active / Total Slabs (% used) : 25774 / 25774 (100.0%)
Active / Total Caches (% used) : 160 / 228 (70.2%)
Active / Total Size (% used) : 170822.03K / 187615.59K (91.0%)
Minimum / Average / Maximum Object : 0.01K / 0.21K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
246784 246298 99% 0.03K 1928 128 7712K kmalloc-32
128544 112080 87% 0.10K 3296 39 13184K buffer_head
99204 99117 99% 0.19K 4724 21 18896K dentry
49710 49532 99% 0.13K 1657 30 6628K kernfs_node_cache
49266 14590 29% 0.19K 2346 21 9384K kmalloc-rcl-192
30969 27896 90% 1.15K 1147 27 36704K ext4_inode_cache
30080 25811 85% 0.06K 470 64 1880K kmalloc-64
23568 23568 100% 0.64K 1964 12 15712K inode_cache
21012 8482 40% 0.04K 206 102 824K ext4_extent_status
20902 20322 97% 0.57K 1493 14 11944K radix_tree_node
16524 15533 94% 0.04K 162 102 648K selinux_inode_security
16324 15879 97% 0.72K 742 22 11872K ovl_inode
13312 12574 94% 0.02K 52 256 208K kmalloc-16
11886 9190 77% 0.19K 566 21 2264K kmalloc-192
11101 11080 99% 0.23K 653 17 2612K vm_area_struct
10240 10240 100% 0.01K 20 512 80K kmalloc-8
8640 7348 85% 0.50K 540 16 4320K kmalloc-512
7680 7152 93% 0.06K 120 64 480K anon_vma_chain
6144 5871 95% 0.12K 192 32 768K kmalloc-128
5632 4232 75% 0.06K 88 64 352K jbd2_inode
5216 4464 85% 0.25K 326 16 1304K filp
4968 4528 91% 0.09K 108 46 432K anon_vma
系统缓存回收机制的设置项
系统默认内存回收配置在/proc/sys/vm/drop_caches中,除非明确知晓改动对系统全局影响,不建议对此进行修改。
- 0:不做任何处理,由系统自己管理
- 1:清空pagecache
- 2:清空dentries和inodes
- 3:清空pagecache、dentries和inodes
手动释放 slab 内存
sync
# echo 1 > /proc/sys/vm/drop_caches
# echo 2 > /proc/sys/vm/drop_caches
echo 3 > /proc/sys/vm/drop_caches
sync:用来确保文件系统的完整性,将所有未写的系统缓冲区写到磁盘中,包含已修改的 i-Node、已延迟的块 I/O 和读写映射文件
因为 3代表释放 pagecache,dentries,inodes 三项,所以只执行3应该也可以
什么是dentries?
dentry_cache是目录项高速缓存,它记录了目录项到inode的映射关系,是Linux为了提高目录项对象的处理效率而设计的。
当应用程序发起stat系统调用时,就会创建对应的dentry_cache项,如果每次stat的文件都是不存在的文件,那么总是会创建大量新的dentry_cache项
什么是inode?
inode包含文件的元信息,具体来说有以下内容:
- 文件的字节数
- 文件拥有者的User ID
- 文件的Group ID
- 文件的读、写、执行权限
- 文件的time,共三个:
- ctime:inode上一次变动的时间,
- mtime指文件内容上一次变动的时间
- atime指文件上一次打开的时间。
- 链接数,即有多少文件名指向这个inode
- 文件数据block的位置
说明:block对应到磁盘的扇区
TLB
TLB是translation lookaside buffer的简称。首先,我们知道MMU的作用是把虚拟地址转换成物理地址。虚拟地址和物理地址的映射关系存储在页表中,而现在页表又是分级的。64位系统一般都是3~5级。常见的配置是4级页表,就以4级页表为例说明。分别是PGD、PUD、PMD、PTE四级页表。在硬件上会有一个叫做页表基地址寄存器,它存储PGD页表的首地址。MMU就是根据页表基地址寄存器从PGD页表一路查到PTE,最终找到物理地址(PTE页表中存储物理地址)。这就像在地图上显示你的家在哪一样,我为了找到你家的地址,先确定你是中国,再确定你是某个省,继续往下某个市,最后找到你家是一样的原理。一级一级找下去。这个过程你也看到了,非常繁琐。如果第一次查到你家的具体位置,我如果记下来你的姓名和你家的地址。下次查找时,是不是只需要跟我说你的姓名是什么,我就直接能够告诉你地址,而不需要一级一级查找。四级页表查找过程需要四次内存访问。延时可想而知,非常影响性能。页表查找过程的示例如下图所示。以后有机会详细展开,这里了解下即可。
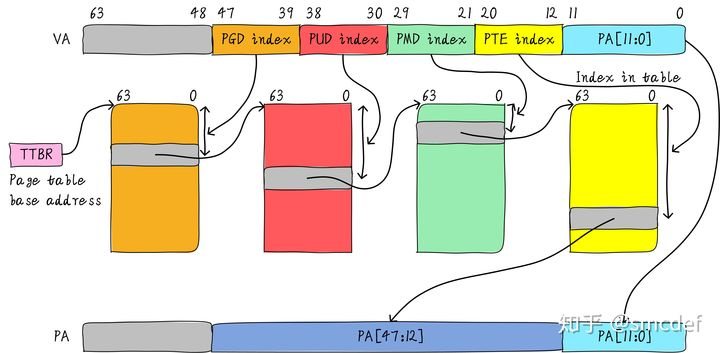
TLB的本质是什么
TLB其实就是一块高速缓存。数据cache缓存地址(虚拟地址或者物理地址)和数据。TLB缓存虚拟地址和其映射的物理地址。TLB根据虚拟地址查找cache,它没得选,只能根据虚拟地址查找。所以TLB是一个虚拟高速缓存。硬件存在TLB后,虚拟地址到物理地址的转换过程发生了变化。虚拟地址首先发往TLB确认是否命中cache,如果cache hit直接可以得到物理地址。否则,一级一级查找页表获取物理地址。并将虚拟地址和物理地址的映射关系缓存到TLB中。既然TLB是虚拟高速缓存(VIVT),是否存在别名和歧义问题呢?如果存在,软件和硬件是如何配合解决这些问题呢?
TLB的特殊
虚拟地址映射物理地址的最小单位是4KB。所以TLB其实不需要存储虚拟地址和物理地址的低12位(因为低12位是一样的,根本没必要存储)。另外,我们如果命中cache,肯定是一次性从cache中拿出整个数据。所以虚拟地址不需要offset域。index域是否需要呢?这取决于cache的组织形式。如果是全相连高速缓存。那么就不需要index。如果使用多路组相连高速缓存,依然需要index。下图就是一个四路组相连TLB的例子。现如今64位CPU寻址范围并没有扩大到64位。64位地址空间很大,现如今还用不到那么大。因此硬件为了设计简单或者解决成本,实际虚拟地址位数只使用了一部分。这里以48位地址总线为了例说明。

TLB的别名问题
我先来思考第一个问题,别名是否存在。我们知道PIPT的数据cache不存在别名问题。物理地址是唯一的,一个物理地址一定对应一个数据。但是不同的物理地址可能存储相同的数据。也就是说,物理地址对应数据是一对一关系,反过来是多对一关系。由于TLB的特殊性,存储的是虚拟地址和物理地址的对应关系。因此,对于单个进程来说,同一时间一个虚拟地址对应一个物理地址,一个物理地址可以被多个虚拟地址映射。将PIPT数据cache类比TLB,我们可以知道TLB不存在别名问题。而VIVT Cache存在别名问题,原因是VA需要转换成PA,PA里面才存储着数据。中间多经传一手,所以引入了些问题。
TLB的歧义问题
我们知道不同的进程之间看到的虚拟地址范围是一样的,所以多个进程下,不同进程的相同的虚拟地址可以映射不同的物理地址。这就会造成歧义问题。例如,进程A将地址0x2000映射物理地址0x4000。进程B将地址0x2000映射物理地址0x5000。当进程A执行的时候将0x2000对应0x4000的映射关系缓存到TLB中。当切换B进程的时候,B进程访问0x2000的数据,会由于命中TLB从物理地址0x4000取数据。这就造成了歧义。如何消除这种歧义,我们可以借鉴VIVT数据cache的处理方式,在进程切换时将整个TLB无效。切换后的进程都不会命中TLB,但是会导致性能损失。
如何尽可能的避免flush TLB
首先需要说明的是,这里的flush理解成使无效的意思。我们知道进程切换的时候,为了避免歧义,我们需要主动flush整个TLB。如果我们能够区分不同的进程的TLB表项就可以避免flush TLB。我们知道Linux如何区分不同的进程?每个进程拥有一个独一无二的进程ID。如果TLB在判断是否命中的时候,除了比较tag以外,再额外比较进程ID该多好呢!这样就可以区分不同进程的TLB表项。进程A和B虽然虚拟地址一样,但是进程ID不一样,自然就不会发生进程B命中进程A的TLB表项。所以,TLB添加一项ASID(Address Space ID)的匹配。ASID就类似进程ID一样,用来区分不同进程的TLB表项。这样在进程切换的时候就不需要flush TLB。但是仍然需要软件管理和分配ASID。
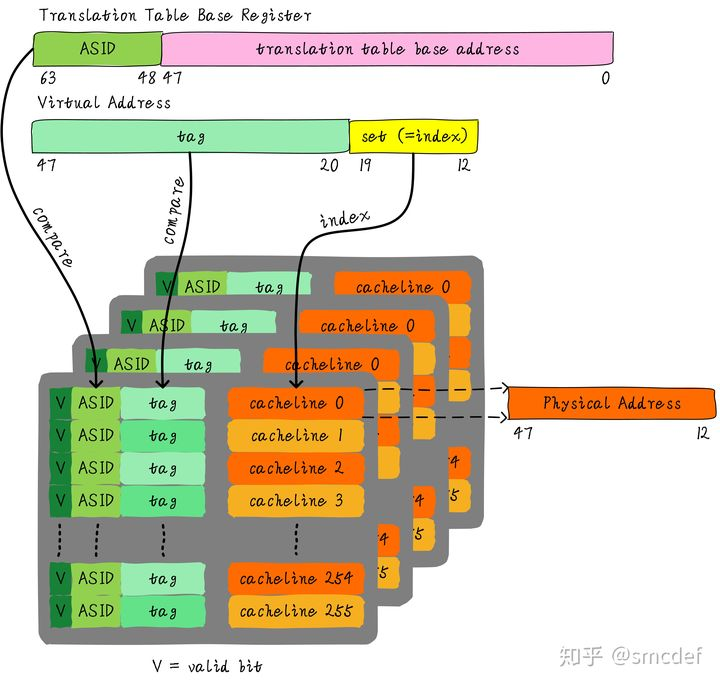
如何管理ASID
ASID和进程ID肯定是不一样的,别混淆二者。进程ID取值范围很大。但是ASID一般是8或16 bit。所以只能区分256或65536个进程。我们的例子就以8位ASID说明。所以我们不可能将进程ID和ASID一一对应,我们必须为每个进程分配一个ASID,进程ID和每个进程的ASID一般是不相等的。每创建一个新进程,就为之分配一个新的ASID。当ASID分配完后,flush所有TLB,重新分配ASID。所以,如果想完全避免flush TLB的话,理想情况下,运行的进程数目必须小于等于256。然而事实并非如此,因此管理ASID上需要软硬结合。 Linux kernel为了管理每个进程会有个task_struct结构体,我们可以把分配给当前进程的ASID存储在这里。页表基地址寄存器有空闲位也可以用来存储ASID。当进程切换时,可以将页表基地址和ASID(可以从task_struct获得)共同存储在页表基地址寄存器中。当查找TLB时,硬件可以对比tag以及ASID是否相等(对比页表基地址寄存器存储的ASID和TLB表项存储的ASID)。如果都相等,代表TLB hit。否则TLB miss。当TLB miss时,需要多级遍历页表,查找物理地址。然后缓存到TLB中,同时缓存当前的ASID。
更上一层楼
我们知道内核空间和用户空间是分开的,并且内核空间是所有进程共享。既然内核空间是共享的,进程A切换进程B的时候,如果进程B访问的地址位于内核空间,完全可以使用进程A缓存的TLB。但是现在由于ASID不一样,导致TLB miss。我们针对内核空间这种全局共享的映射关系称之为global映射。针对每个进程的映射称之为non-global映射。所以,我们在最后一级页表中引入一个bit(non-global (nG) bit)代表是不是global映射。当虚拟地址映射物理地址关系缓存到TLB时,将nG bit也存储下来。当判断是否命中TLB时,当比较tag相等时,再判断是不是global映射,如果是的话,直接判断TLB hit,无需比较ASID。当不是global映射时,最后比较ASID判断是否TLB hit。
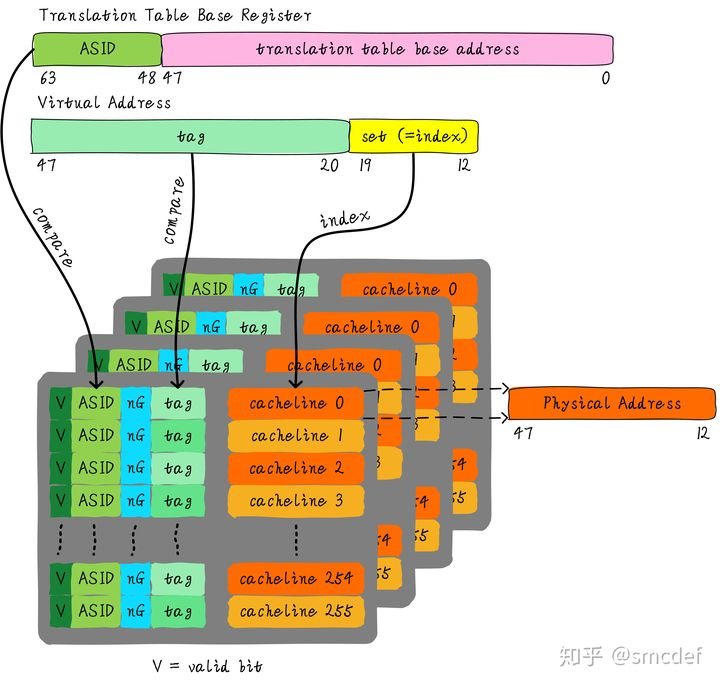
什么时候应该flush TLB
我们再来最后的总结,什么时候应该flush TLB。
- 当ASID分配完的时候,需要flush全部TLB。ASID的管理可以使用bitmap管理,flush TLB后clear整个bitmap。
- 当我们建立页表映射的时候,就需要flush虚拟地址对应的TLB表项。第一印象可能是修改页表映射的时候才需要flush TLB,但是实际情况是只要建立映射就需要flush TLB。原因是,建立映射时你并不知道之前是否存在映射。例如,建立虚拟地址A到物理地址B的映射,我们并不知道之前是否存在虚拟地址A到物理地址C的映射情况。所以就统一在建立映射关系的时候flush TLB。
虚拟内存
在用户的视角里,每个进程都有自己独立的地址空间,A进程的4GB和B进程4GB是完全独立不相关的,他们看到的都是操作系统虚拟出来的地址空间。但是呢,虚拟地址最终还是要落在实际内存的物理地址上进行操作的。操作系统就会通过页表的机制来实现进程的虚拟地址到物理地址的翻译工作。其中每一页的大小都是固定的。
页面大小
在Linux下,我们通过如下命令可以查看到当前操作系统的页大小
getconf PAGE_SIZE
4096
可以看到当前我的Linux机器的页表是4KB的大小。
页表级数
- 页表级数越少,虚拟地址到物理地址的映射会很快,但是需要管理的页表项会很多,能支持的地址空间也有限。
- 相反页表级数越多,需要的存储的页表数据就会越少,而且能支持到比较大的地址空间,但是虚拟地址到物理地址的映射就会越慢。
举个例子。如果想支持32位的操作系统下的4GB进程虚拟地址空间,假设页表大小为4K,则共有2的20次方页面。如果采用速度最快的1级页表,对应则需要2的20次方个页表项。一个页表项假如4字节,那么一个进程就需要(1048576*4=)4M的内存来存页表项。
将页表分为分为1024个表,每个表中包含1024个页表项,形成二级页表。二级页表结构的逻辑地址结构如下图
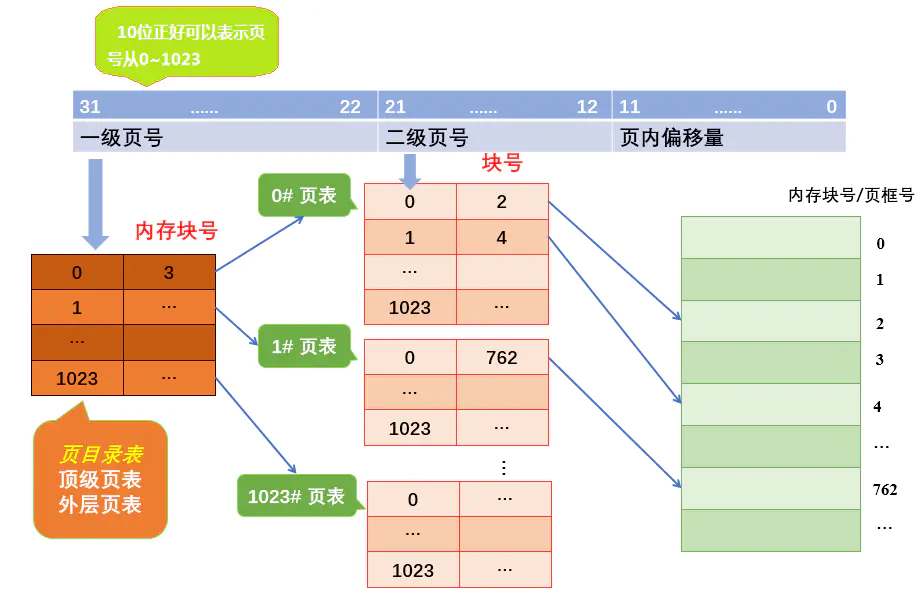
页目录1024个,页表项1024个,总共2028个页表管理条目,(2048*4=)8k就可以支持起4GB的地址空间转换。
更何况操作系统需要支持的可是64位地址空间,而且要支持成百上千的进程,这个开销会大道不可忍。
所以每个操作系统制定页表级数的时候都是在映射速度和页表占用空间中取折中。
Linux在v2.6.11以后,最终采用的方案是4级页表,分别是:
- PGD:page Global directory(47-39), 页全局目录
- PUD:Page Upper Directory(38-30),页上级目录
- PMD:page middle directory(29-21),页中间目录
- PTE:page table entry(20-12),页表项
这样,一个64位的虚拟空间,就需要:29 个PGD + 29 个PUD + 29 个PMD + 29 个PTE = 2048个页表数据结构。现在的页表数据结构被扩展到了8byte。仅仅需要(2048*8=)16K就可以支持起(2^48 =)256T的进程地址空间。
页表带来的问题
虽然16K的页表数据支持起了256T的地址空间寻址。但是,这也带来了额外的问题,页表是存在内存里的。那就是一次内存IO光是虚拟地址到物理地址的转换就要去内存查4次页表,再算上真正的内存访问,竟然需要5次内存IO才能获取一个内存数据!!
TLB应运而生
和CPU的L1、L2、L3的缓存思想一致,既然进行地址转换需要的内存IO次数多,且耗时。那么干脆就在CPU里把页表尽可能地cache起来不就行了么,所以就有了TLB(Translation Lookaside Buffer),专门用于改进虚拟地址到物理地址转换速度的缓存。其访问速度非常快,和寄存器相当,比L1访问还快。
cpuid | grep -i tlb
cache and TLB information (2):
guest TLB flush optimization enabled = false
L1 TLB/cache information: 2M/4M pages & L1 TLB (0x80000005/eax):
L1 TLB/cache information: 4K pages & L1 TLB (0x80000005/ebx):
L2 TLB/cache information: 2M/4M pages & L2 TLB (0x80000006/eax):
L2 TLB/cache information: 4K pages & L2 TLB (0x80000006/ebx):
L1 TLB information: 1G pages (0x80000019/eax):
L2 TLB information: 1G pages (0x80000019/ebx):
cache and TLB information (2):
guest TLB flush optimization enabled = false
L1 TLB/cache information: 2M/4M pages & L1 TLB (0x80000005/eax):
L1 TLB/cache information: 4K pages & L1 TLB (0x80000005/ebx):
L2 TLB/cache information: 2M/4M pages & L2 TLB (0x80000006/eax):
L2 TLB/cache information: 4K pages & L2 TLB (0x80000006/ebx):
L1 TLB information: 1G pages (0x80000019/eax):
L2 TLB information: 1G pages (0x80000019/ebx):
有了TLB之后,CPU访问某个虚拟内存地址的过程如下
- 1.CPU产生一个虚拟地址
- 2.MMU从TLB中获取页表,翻译成物理地址
- 3.MMU把物理地址发送给L1/L2/L3/内存
- 4.L1/L2/L3/内存将地址对应数据返回给CPU
由于第2步是类似于寄存器的访问速度,所以如果TLB能命中,则虚拟地址到物理地址的时间开销几乎可以忽略。如
因为TLB并不是很大,只有4k,而且现在逻辑核又造成会有两个进程来共享。所以可能会有cache miss的情况出现。而且一旦TLB miss造成的后果可比物理地址cache miss后果要严重一些,最多可能需要进行5次内存IO才行。建议你先用上面的perf工具查看一下你的程序的TLB的miss情况,如果确实不命中率很高,那么Linux允许你使用大内存页,很多大牛包括PHP7作者鸟哥也这样建议。这样将会大大减少页表项的数量,所以自然也会降低TLB cache miss率。所要承担的代价就是会造成一定程度的内存浪费。在Linux里,大内存页默认是不开启的。
内核内存使用
不同于给应用程序提供的虚拟内存机制,内核使用 slab 的分配器来申请内存。
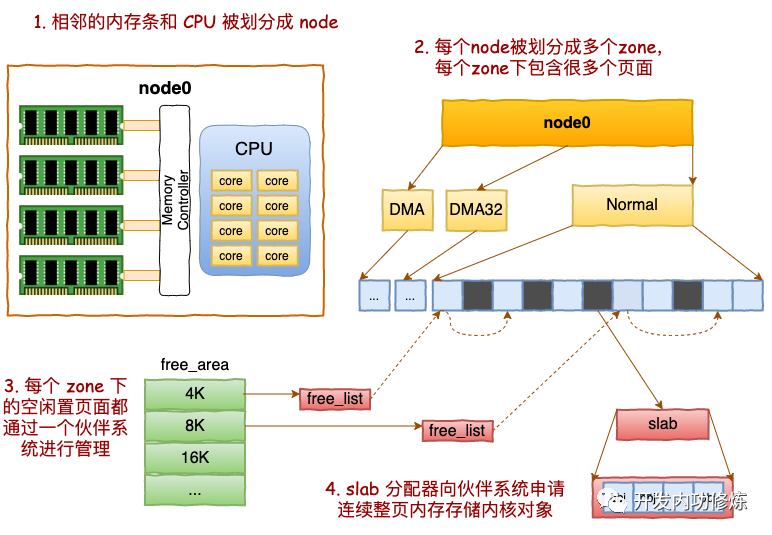
现在你可能还觉得node、zone、伙伴系统、slab这些东东还有那么一点点陌生。别怕,接下来我们结合动手观察,把它们逐个来展开细说。(下面的讨论都基于Linux 3.10.0版本)
一、NODE 划分
在现代的服务器上,内存和CPU都是所谓的NUMA架构
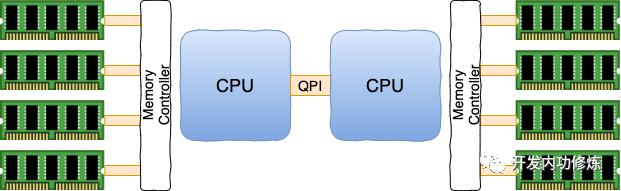
每一个CPU以及和他直连的内存条组成了一个 node(节点)。
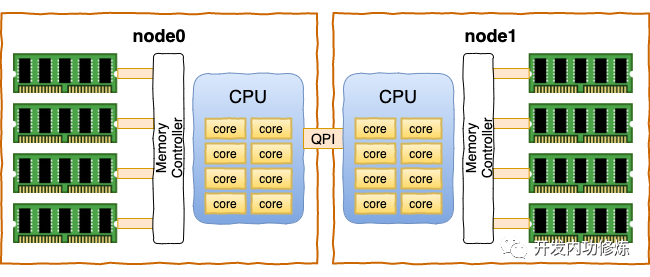
在你的机器上,你可以使用numactl你可以看到每个node的情况
numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3
node 0 size: 7768 MB
node 0 free: 327 MB
node distances:
node 0
0: 10
二、ZONE 划分
每个 node 又会划分成若干的 zone(区域) 。zone 表示内存中的一块范围
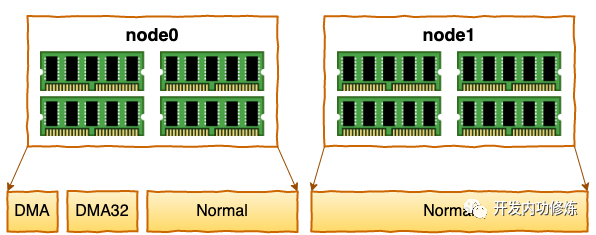
- ZONE_DMA:地址段最低的一块内存区域,ISA(Industry Standard Architecture)设备DMA访问
- ZONE_DMA32:该Zone用于支持32-bits地址总线的DMA设备,只在64-bits系统里才有效
- ZONE_NORMAL:在X86-64架构下,DMA和DMA32之外的内存全部在NORMAL的Zone里管理
为什么没有提 ZONE_HIGHMEM 这个zone?因为这是 32 位机时代的产物。现在应该没谁在用这种古董了吧。
在每个zone下,都包含了许许多多个 Page(页面), 在linux下一个Page的大小一般是 4 KB。
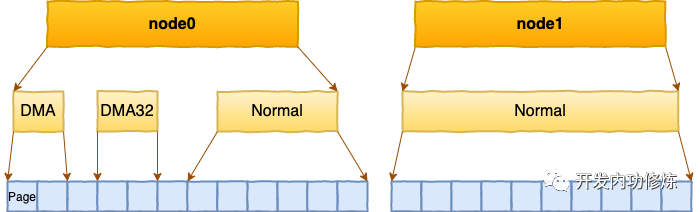
在你的机器上,你可以使用通过 zoneinfo 查看到你机器上 zone 的划分,也可以看到每个 zone 下所管理的页面有多少个。
因为硬件的限制,内核不能对所有的page frames采用同样的处理方法,因此它将属性相同的page frames归到一个zone中。对zone的划分与硬件相关,对不同的处理器架构是可能不一样的。
比如在i386中,一些使用DMA的设备只能访问0~16MB的物理空间,因此将0~16MB划分为了ZONE_DMA。ZONE_HIGHMEM则是适用于要访问的物理地址空间大于虚拟地址空间,不能建立直接映射的场景。除开这两个特殊的zone,物理内存中剩余的部分就是ZONE_NORMAL了。
ZONE_HIGHMEM也可能没有。比如在64位的x64中,因为内核虚拟地址空间足够大,不再需要ZONE_HIGH映射,但为了区分使用32位地址的DMA应用和使用64位地址的DMA应用,64位系统中设置了ZONE_DMA32和ZONE_DMA。
所以,同样的ZONE_DMA,对于32位系统和64位系统表达的意义是不同的,ZONE_DMA32则只对64位系统有意义,对32位系统就等同于ZONE_DMA,没有单独存在的意义。
此外,还有防止内存碎片化的ZONE_MOVABLE和支持设备热插拔的ZONE_DEVICE。可通过“cat /proc/zoneinfo |grep Node”命令查看系统中包含的zones的种类。
cat /proc/zoneinfo | grep Node
Node 0, zone DMA
Node 0, zone DMA32
Node 0, zone Normal
Node 0, zone Movable
Node 0, zone Device
Zone虽然是用于管理物理内存的,但zone与zone之间并没有任何的物理分割,它只是Linux为了便于管理进行的一种逻辑意义上的划分。
三、基于伙伴系统管理空闲页面
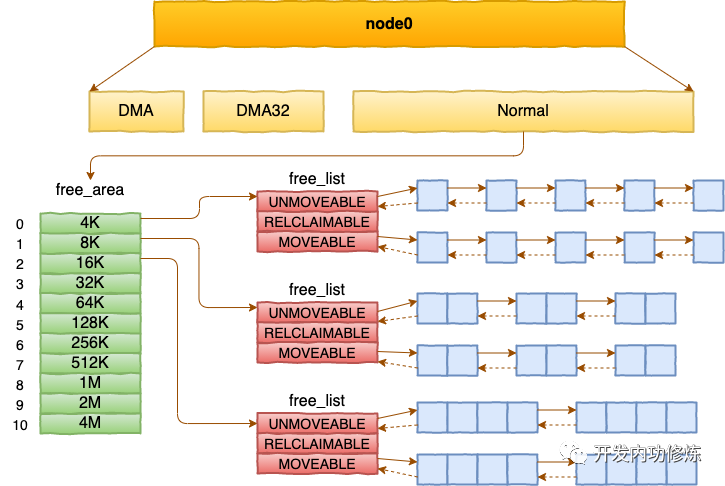
每个 zone 下面都有如此之多的页面,Linux使用伙伴系统对这些页面进行高效的管理。在内核中,表示 zone 的数据结构是 struct zone。其下面的一个数组 free_area 管理了绝大部分可用的空闲页面。这个数组就是伙伴系统实现的重要数据结构。
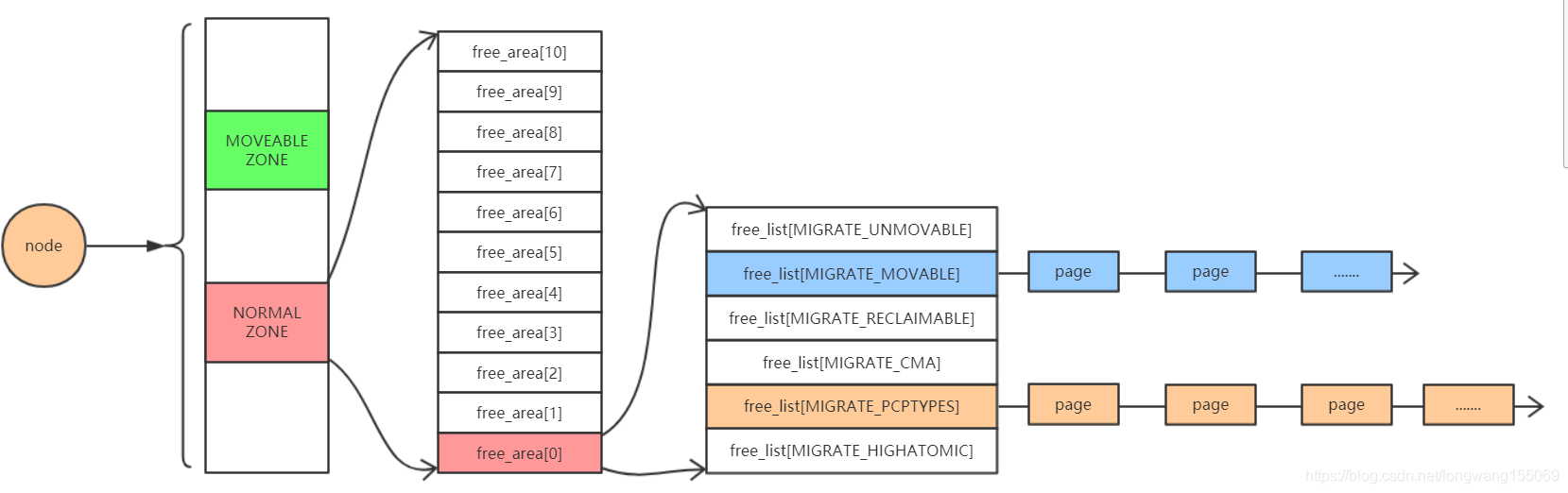
free_area是一个11个元素的数组,在每一个数组分别代表的是空闲可分配连续4K、8K、16K、......、4M内存链表。
通过 cat /proc/pagetypeinfo, 你可以看到当前系统里伙伴系统里各个尺寸的可用连续内存块数量。
cat /proc/pagetypeinfo
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 0 1 1 1 1 1 1 1 1 1 0
Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 1 2
Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 333 179 107 55 24 15 3 2 3 0 0
Node 0, zone DMA32, type Movable 1645 2880 3045 1442 502 165 63 36 57 0 0
Node 0, zone DMA32, type Reclaimable 1556 85 4 59 40 30 4 1 0 0 0
Node 0, zone DMA32, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 180 558 534 124 54 22 5 3 0 0 0
Node 0, zone Normal, type Movable 359 1218 104 33 2 0 0 0 0 0 0
Node 0, zone Normal, type Reclaimable 1467 162 2 1 23 23 22 9 1 0 0
Node 0, zone Normal, type HighAtomic 7 11 7 9 2 2 1 1 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate
Node 0, zone DMA 3 5 0 0 0
Node 0, zone DMA32 25 1428 75 0 0
Node 0, zone Normal 163 2315 81 1 0
可以很清晰的看到各个order中不同类型,不同zone,page的剩余情况。当然也可以从cat /proc/buddyinfo看各个page的剩余情况
cat /proc/buddyinfo
Node 0, zone DMA 0 1 1 1 1 1 1 1 1 2 2
Node 0, zone DMA32 2413 2284 2416 1490 587 220 71 41 60 1 0
Node 0, zone Normal 3137 1066 585 104 83 47 28 13 1 0 0
随着时间的推移,order值最大的page就会慢慢的分解开,变为更小的order的page。这时候当申请一个连续的大page都没有的时候,就会做碎片整理操作
内核提供分配器函数 alloc_pages 到上面的多个链表中寻找可用连续页面。
alloc_pages是怎么工作的呢?我们举个简单的小例子。假如要申请8K-连续两个页框的内存。为了描述方便,我们先暂时忽略UNMOVEABLE、RELCLAIMABLE等不同类型
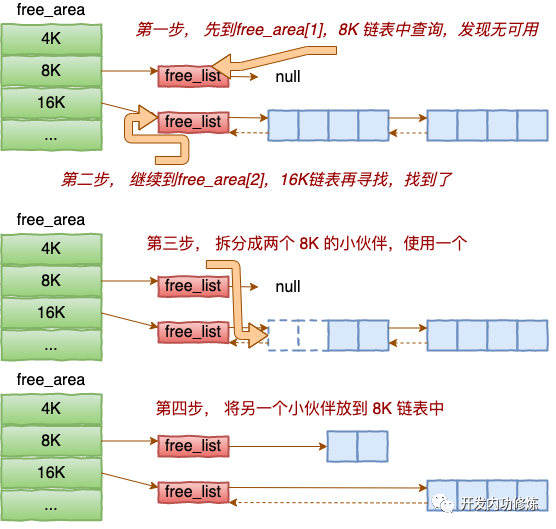
伙伴系统中的伙伴指的是两个内存块,大小相同,地址连续,同属于一个大块区域。
基于伙伴系统的内存分配中,有可能需要将大块内存拆分成两个小伙伴。在释放中,可能会将两个小伙伴合并再次组成更大块的连续内存。
四、SLAB管理器
说到现在,不知道你注意到没有。目前我们介绍的内存分配都是以页面(4KB)为单位的。
对于各个内核运行中实际使用的对象来说,多大的对象都有。有的对象有1K多,但有的对象只有几百、甚至几十个字节。如果都直接分配一个 4K的页面 来存储的话也太败家了,所以伙伴系统并不能直接使用。
在伙伴系统之上,内核又给自己搞了一个专用的内存分配器, 叫slab或slub。这两个词老混用,为了省事,接下来我们就统一叫 slab 吧。
这个分配器最大的特点就是,一个slab内只分配特定大小、甚至是特定的对象。这样当一个对象释放内存后,另一个同类对象可以直接使用这块内存。通过这种办法极大地降低了碎片发生的几率。
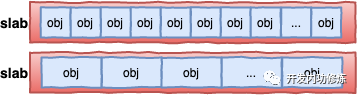
每个cache都有满、半满、空三个链表。每个链表节点都对应一个 slab,一个 slab 由 1 个或者多个内存页组成。
在每一个 slab 内都保存的是同等大小的对象。 一个cache的组成示意图如下:
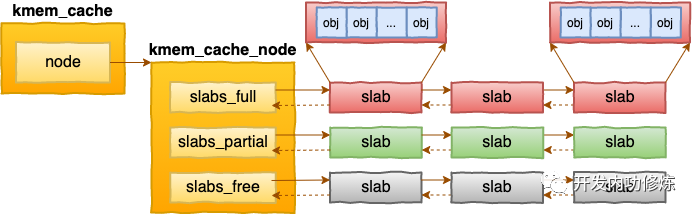
当 cache 中内存不够的时候,会调用基于伙伴系统的分配器(__alloc_pages函数)请求整页连续内存的分配。
内核中会有很多个 kmem_cache 存在。它们是在linux初始化,或者是运行的过程中分配出来的。它们有的是专用的,有的是通用的。
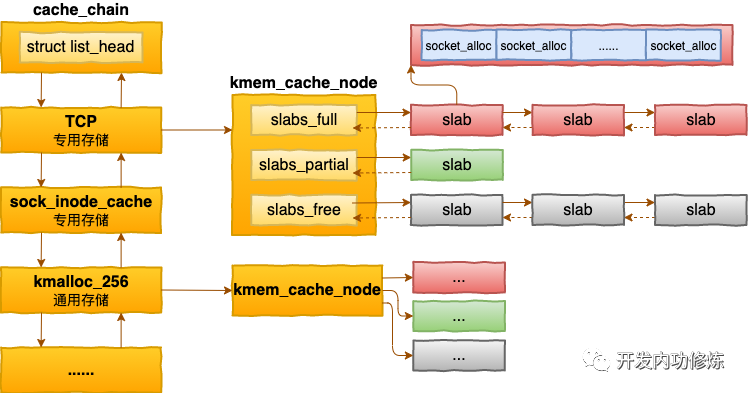
上图中,我们看到 socket_alloc 内核对象都存在 TCP的专用 kmem_cache 中。
通过查看 /proc/slabinfo 我们可以查看到所有的 kmem cache。
slabinfo | grep kmem
kmem_cache 288 440 131.0K 12/0/4 18 1 0 96 A
kmem_cache_node 384 64 24.5K 2/0/4 64 0 0 100 A
无论是 /proc/slabinfo,还是 slabtop 命令的输出。里面都包含了每个 cache 中 slab的如下两个关键信息。
- objsize:每个对象的大小
- objperslab:一个 slab 里存放的对象的数量
在 /proc/slabinfo 还多输出了一个pagesperslab。展示了一个slab 占用的页面的数量,每个页面4K,这样也就能算出每个 slab 占用的内存大小。
最后,slab 管理器组件提供了若干接口函数,方便自己使用。举三个例子:
- kmem_cache_create: 方便地创建一个基于 slab 的内核对象管理器。
- kmem_cache_alloc: 快速为某个对象申请内存
- kmem_cache_free: 归还对象占用的内存给 slab 管理器
在内核的源码中,可以大量见到 kmem_cache 开头函数的使用。
总结
通过上面描述的几个步骤,内核高效地把内存用了起来。
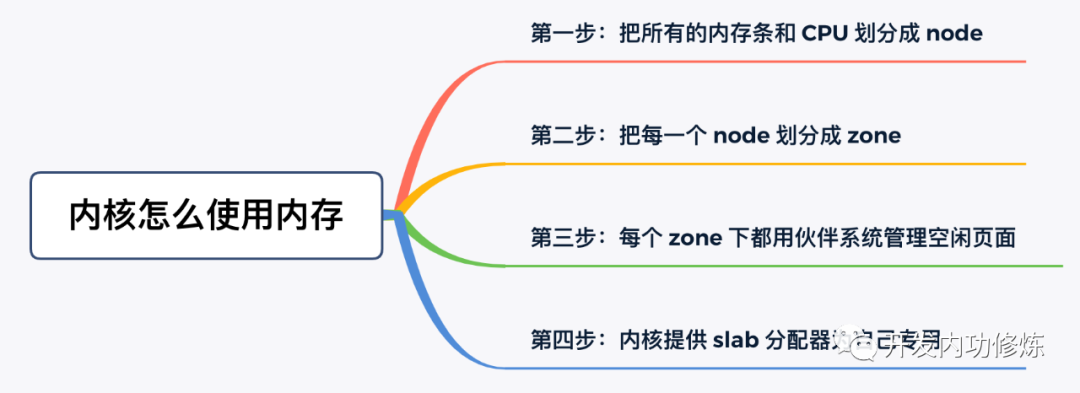
前三步是基础模块,为应用程序分配内存时的请求调页组件也能够用到。但第四步,就算是内核的小灶了。内核根据自己的使用场景,量身打造的一套自用的高效内存分配管理机制。