
Linux 网络协议栈收消息过程-Ring Buffer
从 NIC 收数据开始,到触发软中断,交付数据包到 IP 层再经由路由机制到 TCP 层,最终交付用户进程。会尽力介绍收消息过程中的各种配置信息,以及各种监控数据。知道了收消息的完整过程,了解了各种配置,明白了各种监控数据后才有可能在今后的工作中做优化配置。
Ring Buffer 相关的收消息过程大致如下:
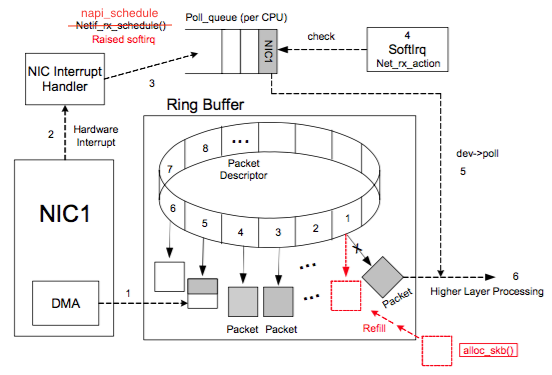
对 raise softirq 的函数名做了修改,改为了 napi_schedule
NIC (network interface card) 在系统启动过程中会向系统注册自己的各种信息,系统会分配 Ring Buffer 队列也会分配一块专门的 内核内存区域 给 NIC 用于存放传输上来的数据包。
struct sk_buff 是专门存放各种网络传输数据包的内存接口,在收到数据存放到 NIC 专用内核内存区域后,sk_buff 内有个 data 指针会指向这块内存。
Ring Buffer 队列内存放的是一个个 Packet Descriptor ,其有两种状态: ready 和 used 。初始时 Descriptor 是空的,指向一个空的 sk_buff,处在 ready 状态。当有数据时,DMA 负责从 NIC 取数据,并在 Ring Buffer 上按顺序找到下一个 ready 的 Descriptor,将数据存入该 Descriptor 指向的 sk_buff 中,并标记槽为 used。因为是按顺序找 ready 的槽,所以 Ring Buffer 是个 FIFO 的队列。
当 DMA 读完数据之后,NIC 会触发一个 IRQ 让 CPU 去处理收到的数据。因为每次触发 IRQ 后 CPU 都要花费时间去处理 Interrupt Handler,如果 NIC 每收到一个 Packet 都触发一个 IRQ 会导致 CPU 花费大量的时间在处理 Interrupt Handler,处理完后又只能从 Ring Buffer 中拿出一个 Packet,虽然 Interrupt Handler 执行时间很短,但这么做也非常低效,并会给 CPU 带去很多负担。所以目前都是采用一个叫做 New API(NAPI)的机制,去对 IRQ 做合并以减少 IRQ 次数。
接下来介绍一下 NAPI 是怎么做到 IRQ 合并的。它主要是让 NIC 的 driver 能注册一个 poll 函数,之后 NAPI 的 subsystem 能通过 poll 函数去从 Ring Buffer 中批量拉取收到的数据。主要事件及其顺序如下:
- NIC driver 初始化时向 Kernel 注册 poll 函数,用于后续从 Ring Buffer 拉取收到的数据
- driver 注册开启 NAPI,这个机制默认是关闭的,只有支持 NAPI 的 driver 才会去开启
- 收到数据后 NIC 通过 DMA 将数据存到内存
- NIC 触发一个 IRQ,并触发 CPU 开始执行 driver 注册的 Interrupt Handler
- driver 的 Interrupt Handler 通过 napi_schedule 函数触发 softirq (NET_RX_SOFTIRQ) 来唤醒 NAPI subsystem,NET_RX_SOFTIRQ 的 handler 是 net_rx_action 会在另一个线程中被执行,在其中会调用 driver 注册的 poll 函数获取收到的 Packet
- driver 会禁用当前 NIC 的 IRQ,从而能在 poll 完所有数据之前不会再有新的 IRQ
- 当所有事情做完之后,NAPI subsystem 会被禁用,并且会重新启用 NIC 的 IRQ
- 回到第三步
从上面的描述可以看出来还缺一些东西,Ring Buffer 上的数据被 poll 走之后是怎么交付上层网络栈继续处理的呢?以及被消耗掉的 sk_buff 是怎么被重新分配重新放入 Ring Buffer 的呢?
这两个工作都在 poll 中完成,上面说过 poll 是个 driver 实现的函数,所以每个 driver 实现可能都不相同。但 poll 的工作基本是一致的就是:
- 从 Ring Buffer 中将收到的 sk_buff 读取出来
- 对 sk_buff 做一些基本检查,可能会涉及到将几个 sk_buff 合并因为可能同一个 Frame 被分散放在多个 sk_buff 中
- 将 sk_buff 交付上层网络栈处理
- 清理 sk_buff,清理 Ring Buffer 上的 Descriptor 将其指向新分配的 sk_buff 并将状态设置为 ready
- 更新一些统计数据,比如收到了多少 packet,一共多少字节等
如果拿 intel igb 这个网卡的实现来看,其 poll 函数在这里:linux/drivers/net/ethernet/intel/igb/igb_main.c - Elixir - Free Electrons
首先是看到有 tx.ring 和 rx.ring,说明收发消息都会走到这里。发消息先不管,先看收消息,收消息走的是 igb_clean_rx_irq。收完消息后执行 napi_complete_done 退出 polling 模式,并开启 NIC 的 IRQ。从而我们知道大部分工作是在 igb_clean_rx_irq 中完成的,其实现大致上还是比较清晰的,就是上面描述的几步。里面有个 while 循环通过 buget 控制,从而在 Packet 特别多的时候不要让 CPU 在这里无穷循环下去,要让别的事情也能够被执行。循环内做的事情如下:
- 先批量清理已经读出来的 sk_buff 并分配新的 buffer 从而避免每次读一个 sk_buff 就清理一个,很低效
- 找到 Ring Buffer 上下一个需要被读取的 Descriptor ,并检查描述符状态是否正常
- 根据 Descriptor 找到 sk_buff 读出来
- 检查是否是 End of packet,是的话说明 sk_buff 内有 Frame 的全部内容,不是的话说明 Frame 数据比 sk_buff 大,需要再读一个 sk_buff,将两个 sk_buff 数据合并起来
- 通过 Frame 的 Header 检查 Frame 数据完整性,是否正确之类的
- 记录 sk_buff 的长度,读了多少数据
- 设置 Hash、checksum、timestamp、VLAN id 等信息,这些信息是硬件提供的。
- 通过 napi_gro_receive 将 sk_buff 交付上层网络栈
- 更新一堆统计数据
- 回到 1,如果没数据或者 budget 不够就退出循环
看到 budget 会影响到 CPU 执行 poll 的时间,budget 越大当数据包特别多的时候可以提高 CPU 利用率并减少数据包的延迟。但是 CPU 时间都花在这里会影响别的任务的执行。
# budget 默认 300,可以调整
sysctl -w net.core.netdev_budget=600
napi_gro_receive会涉及到 GRO 机制,稍后再说,大致上就是会对多个数据包做聚合,napi_gro_receive 最终是将处理好的 sk_buff 通过调用 netif_receive_skb,将数据包送至上层网络栈。执行完 GRO 之后,基本可以认为数据包正式离开 Ring Buffer,进入下一个阶段了。在记录下一阶段的处理之前,补充一下收消息阶段 Ring Buffer 相关的更多细节。
Generic Receive Offloading(GRO)
GRO 是 Large receive offload 的一个实现。网络上大部分 MTU 都是 1500 字节,开启 Jumbo Frame 后能到 9000 字节,如果发送的数据超过 MTU 就需要切割成多个数据包。LRO 就是在收到多个数据包的时候将同一个 Flow 的多个数据包按照一定的规则合并起来交给上层处理,这样就能减少上层需要处理的数据包数量。
很多 LRO 机制是在 NIC 上实现的,没有实现 LRO 的 NIC 就少了上述合并数据包的能力。而 GRO 是 LRO 在软件上的实现,从而能让所有 NIC 都支持这个功能。
napi_gro_receive 就是在收到数据包的时候合并多个数据包用的,如果收到的数据包需要被合并,napi_gro_receive 会很快返回。当合并完成后会调用 napi_skb_finish ,将因为数据包合并而不再用到的数据结构释放。最终会调用到 netif_receive_skb 将数据包交到上层网络栈继续处理。netif_receive_skb 上面说过,就是数据包从 Ring Buffer 出来后到上层网络栈的入口。
可以通过 ethtool 查看和设置 GRO:
# 查看 GRO
ethtool -k eth0 | grep generic-receive-offload
generic-receive-offload: on
# 设置开启 GRO
ethtool -K eth0 gro on
多 CPU 下的 Ring Buffer 处理 (Receive Side Scaling)
NIC 收到数据的时候产生的 IRQ 只可能被一个 CPU 处理,从而只有一个 CPU 会执行 napi_schedule 来触发 softirq,触发的这个 softirq 的 handler 也还是会在这个产生 softIRQ 的 CPU 上执行。所以 driver 的 poll 函数也是在最开始处理 NIC 发出 IRQ 的那个 CPU 上执行。于是一个 Ring Buffer 上同一个时刻只有一个 CPU 在拉取数据。
从上面描述能看出来分配给 Ring Buffer 的空间是有限的,当收到的数据包速率大于单个 CPU 处理速度的时候 Ring Buffer 可能被占满,占满之后再来的新数据包会被自动丢弃。而现在机器都是有多个 CPU,同时只有一个 CPU 去处理 Ring Buffer 数据会很低效,这个时候就产生了叫做 Receive Side Scaling(RSS) 或者叫做 multiqueue 的机制来处理这个问题。WIKI 对 RSS 的介绍挺好的,简洁干练可以看看: Network interface controller - Wikipedia
简单说就是现在支持 RSS 的网卡内部会有多个 Ring Buffer,NIC 收到 Frame 的时候能通过 Hash Function 来决定 Frame 该放在哪个 Ring Buffer 上,触发的 IRQ 也可以通过操作系统或者手动配置 IRQ affinity 将 IRQ 分配到多个 CPU 上。这样 IRQ 能被不同的 CPU 处理,从而做到 Ring Buffer 上的数据也能被不同的 CPU 处理,从而提高数据的并行处理能力。
RSS 除了会影响到 NIC 将 IRQ 发到哪个 CPU 之外,不会影响别的逻辑了。收消息过程跟之前描述的是一样的。
如果支持 RSS 的话,NIC 会为每个队列分配一个 IRQ,通过 /proc/interrupts 能进行查看。你可以通过配置 IRQ affinity 指定 IRQ 由哪个 CPU 来处理中断。先通过 /proc/interrupts 找到 IRQ 号之后,将希望绑定的 CPU 号写入 /proc/irq/IRQ_NUMBER/smp_affinity,写入的是 16 进制的 bit mask。比如看到队列 rx_0 对应的中断号是 41 那就执行:
echo 6 > /proc/irq/41/smp_affinity
# 6 表示的是 CPU2 和 CPU1
0 号 CPU 的掩码是 0x1 (0001),1 号 CPU 掩码是 0x2 (0010),2 号 CPU 掩码是 0x4 (0100),3 号 CPU 掩码是 0x8 (1000) 依此类推。
另外需要注意的是设置 smp_affinity 的话不能开启 irqbalance 或者需要为 irqbalance 设置 –banirq 列表,将设置了 smp_affinity 的 IRQ 排除。不然 irqbalance 机制运作时会忽略你设置的 IRQ affinity 配置。
Receive Packet Steering(RPS) 是在 NIC 不支持 RSS 时候在软件中实现 RSS 类似功能的机制。其好处就是对 NIC 没有要求,任何 NIC 都能支持 RPS,但缺点是 NIC 收到数据后 DMA 将数据存入的还是一个 Ring Buffer,NIC 触发 IRQ 还是发到一个 CPU,还是由这一个 CPU 调用 driver 的 poll 来将 Ring Buffer 的数据取出来。RPS 是在单个 CPU 将数据从 Ring Buffer 取出来之后才开始起作用,它会为每个 Packet 计算 Hash 之后将 Packet 发到对应 CPU 的 backlog 中,并通过 Inter-processor Interrupt(IPI) 告知目标 CPU 来处理 backlog。后续 Packet 的处理流程就由这个目标 CPU 来完成。从而实现将负载分到多个 CPU 的目的。
RPS 默认是关闭的,当机器有多个 CPU 并且通过 softirqs 的统计 /proc/softirqs 发现 NET_RX 在 CPU 上分布不均匀或者发现网卡不支持 mutiqueue 时,就可以考虑开启 RPS。开启 RPS 需要调整 /sys/class/net/DEVICE_NAME/queues/QUEUE/rps_cpus 的值。比如执行:
echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus
表示的含义是处理网卡 eth0 的 rx-0 队列的 CPU 数设置为 f 。即设置有 15 个 CPU 来处理 rx-0 这个队列的数据,如果你的 CPU 数没有这么多就会默认使用所有 CPU 。甚至有人为了方便都是直接将 echo fff > /sys/class/net/eth0/queues/rx-0/rps_cpus 写到脚本里,这样基本能覆盖所有类型的机器,不管机器 CPU 数有多少,都能覆盖到。从而就能让这个脚本在任意机器都能执行。
注意 :如果 NIC 不支持 mutiqueue,RPS 不是完全不用思考就能打开的,因为其开启之后会加重所有 CPU 的负担,在一些场景下比如 CPU 密集型应用上并不一定能带来好处。所以得测试一下。
Receive Flow Steering(RFS) 一般和 RPS 配合一起工作。RPS 是将收到的 packet 发配到不同的 CPU 以实现负载均衡,但是可能同一个 Flow 的数据包正在被 CPU1 处理,但下一个数据包被发到 CPU2,会降低 CPU cache hit 比率并且会让数据包要从 CPU1 发到 CPU2 上。RFS 就是保证同一个 flow 的 packet 都会被路由到正在处理当前 Flow 数据的 CPU,从而提高 CPU cache 比率。这篇文章 把 RFS 机制介绍的挺好的。基本上就是收到数据后根据数据的一些信息做个 Hash 在这个 table 的 entry 中找到当前正在处理这个 flow 的 CPU 信息,从而将数据发给这个正在处理该 Flow 数据的 CPU 上,从而做到提高 CPU cache hit 率,避免数据在不同 CPU 之间拷贝。当然还有很多细节,请看上面链接。
RFS 默认是关闭的,必须主动配置才能生效。正常来说开启了 RPS 都要再开启 RFS,以获取更好的性能。这篇文章 也有说该怎么去开启 RFS 以及推荐的配置值。一个是要配置 rps_sock_flow_entries
sysctl -w net.core.rps_sock_flow_entries=32768
这个值依赖于系统期望的活跃连接数,注意是同一时间活跃的连接数,这个连接数正常来说会大大小于系统能承载的最大连接数,因为大部分连接不会同时活跃。该值建议是 32768,能覆盖大多数情况,每个活跃连接会分配一个 entry。除了这个之外还要配置 rps_flow_cnt,这个值是每个队列负责的 flow 最大数量,如果只有一个队列,则 rps_flow_cnt 一般是跟 rps_sock_flow_entries 的值一致,但是有多个队列的时候 rps_flow_cnt 值就是 rps_sock_flow_entries / N, N 是队列数量。
echo 2048 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt
Accelerated Receive Flow Steering (aRFS) 类似 RFS 只是由硬件协助完成这个工作。aRFS 对于 RFS 就和 RSS 对于 RPS 一样,就是把 CPU 的工作挪到了硬件来做,从而不用浪费 CPU 时间,直接由 NIC 完成 Hash 值计算并将数据发到目标 CPU,所以快一点。NIC 必须暴露出来一个 ndo_rx_flow_steer 的函数用来实现 aRFS。
adaptive RX/TX IRQ coalescing
有的 NIC 支持这个功能,用来动态的将 IRQ 进行合并,以做到在数据包少的时候减少数据包的延迟,在数据包多的时候提高吞吐量。查看方法:
ethtool -c eth1
Coalesce parameters for eth1:
Adaptive RX: off TX: off
stats-block-usecs: 0
.....
开启 RX 队列的 adaptive coalescing 执行:
ethtool -C eth0 adaptive-rx on
并且有四个值需要设置:rx-usecs、rx-frames、rx-usecs-irq、rx-frames-irq,具体含义等需要用到的时候查吧。
Ring Buffer 相关监控及配置
收到数据包统计
ethtool -S eth0
NIC statistics:
rx_packets: 792819304215
tx_packets: 778772164692
rx_bytes: 172322607593396
tx_bytes: 201132602650411
rx_broadcast: 15118616
tx_broadcast: 2755615
rx_multicast: 0
tx_multicast: 10
RX 就是收到数据,TX 是发出数据。还会展示 NIC 每个队列收发消息情况。其中比较关键的是带有 drop 字样的统计和 fifo_errors 的统计 :
tx_dropped: 0
rx_queue_0_drops: 93
rx_queue_1_drops: 874
....
rx_fifo_errors: 2142
tx_fifo_errors: 0
看到发送队列和接收队列 drop 的数据包数量显示在这里。并且所有 queue_drops 加起来等于 rx_fifo_errors。所以总体上能通过 rx_fifo_errors 看到 Ring Buffer 上是否有丢包。如果有的话一方面是看是否需要调整一下每个队列数据的分配,或者是否要加大 Ring Buffer 的大小。
/proc/net/dev是另一个数据包相关统计,不过这个统计比较难看:
cat /proc/net/dev
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
lo: 14472296365706 10519818839 0 0 0 0 0 0 14472296365706 10519818839 0 0 0 0 0 0
eth1: 164650683906345 785024598362 0 0 2142 0 0 0 183711288087530 704887351967 0 0 0 0 0 0
调整 Ring Buffer 队列数量
ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0
Other: 1
Combined: 8
Current hardware settings:
RX: 0
TX: 0
Other: 1
Combined: 8
看的是 Combined 这一栏是队列数量。Combined 按说明写的是多功能队列,猜想是能用作 RX 队列也能当做 TX 队列,但数量一共是 8 个?
如果不支持 mutiqueue 的话上面执行下来会是:
Channel parameters for eth0:
Cannot get device channel parameters
: Operation not supported
看到上面 Ring Buffer 数量有 maximums 和 current settings,所以能自己设置 Ring Buffer 数量,但最大不能超过 maximus 值:
sudo ethtool -L eth0 combined 8
如果支持对特定类型 RX 或 TX 设置队列数量的话可以执行:
sudo ethtool -L eth0 rx 8
需要注意的是,ethtool 的设置操作可能都要重启一下才能生效。
调整 Ring Buffer 队列大小
先查看当前 Ring Buffer 大小:
ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 512
RX Mini: 0
RX Jumbo: 0
TX: 512
看到 RX 和 TX 最大是 4096,当前值为 512。队列越大丢包的可能越小,但数据延迟会增加
设置 RX 队列大小:
ethtool -G eth0 rx 4096
调整 Ring Buffer 队列的权重
NIC 如果支持 mutiqueue 的话 NIC 会根据一个 Hash 函数对收到的数据包进行分发。能调整不同队列的权重,用于分配数据。
ethtool -x eth0
RX flow hash indirection table for eth0 with 8 RX ring(s):
0: 0 0 0 0 0 0 0 0
8: 0 0 0 0 0 0 0 0
16: 1 1 1 1 1 1 1 1
......
64: 4 4 4 4 4 4 4 4
72: 4 4 4 4 4 4 4 4
80: 5 5 5 5 5 5 5 5
......
120: 7 7 7 7 7 7 7 7
我的 NIC 一共有 8 个队列,一个有 128 个不同的 Hash 值,上面就是列出了每个 Hash 值对应的队列是什么。最左侧 0 8 16 是为了能让你快速的找到某个具体的 Hash 值。比如 Hash 值是 76 的话我们能立即找到 72 那一行:”72: 4 4 4 4 4 4 4 4”,从左到右第一个是 72 数第 5 个就是 76 这个 Hash 值对应的队列是 4 。
ethtool -X eth0 weight 6 2 8 5 10 7 1 5
设置 8 个队列的权重。加起来不能超过 128 。128 是 indirection table 大小,每个 NIC 可能不一样。
更改 Ring Buffer Hash Field
分配数据包的时候是按照数据包内的某个字段来进行的,这个字段能进行调整。
ethtool -n eth0 rx-flow-hash tcp4
TCP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
L4 bytes 0 & 1 [TCP/UDP src port]
L4 bytes 2 & 3 [TCP/UDP dst port]
查看 tcp4 的 Hash 字段。
也可以设置 Hash 字段:
ethtool -N eth0 rx-flow-hash udp4 sdfn
sdfn 需要查看 ethtool 看其含义,还有很多别的配置值。
softirq 数统计
通过 /proc/softirqs 能看到每个 CPU 上 softirq 数量统计:
cat /proc/softirqs
CPU0 CPU1
HI: 1 0
TIMER: 1650579324 3521734270
NET_TX: 10282064 10655064
NET_RX: 3618725935 2446
BLOCK: 0 0
BLOCK_IOPOLL: 0 0
TASKLET: 47013 41496
SCHED: 1706483540 1003457088
HRTIMER: 1698047 11604871
RCU: 4218377992 3049934909
看到 NET_RX 就是收消息时候触发的 softirq,一般看这个统计是为了看看 softirq 在每个 CPU 上分布是否均匀,不均匀的话可能就需要做一些调整。比如上面看到 CPU0 和 CPU1 两个差距很大,原因是这个机器的 NIC 不支持 RSS,没有多个 Ring Buffer。开启 RPS 后就均匀多了。
IRQ 统计
/proc/interrupts 能看到每个 CPU 的 IRQ 统计。一般就是看看 NIC 有没有支持 multiqueue 以及 NAPI 的 IRQ 合并机制是否生效。看看 IRQ 是不是增长的很快。
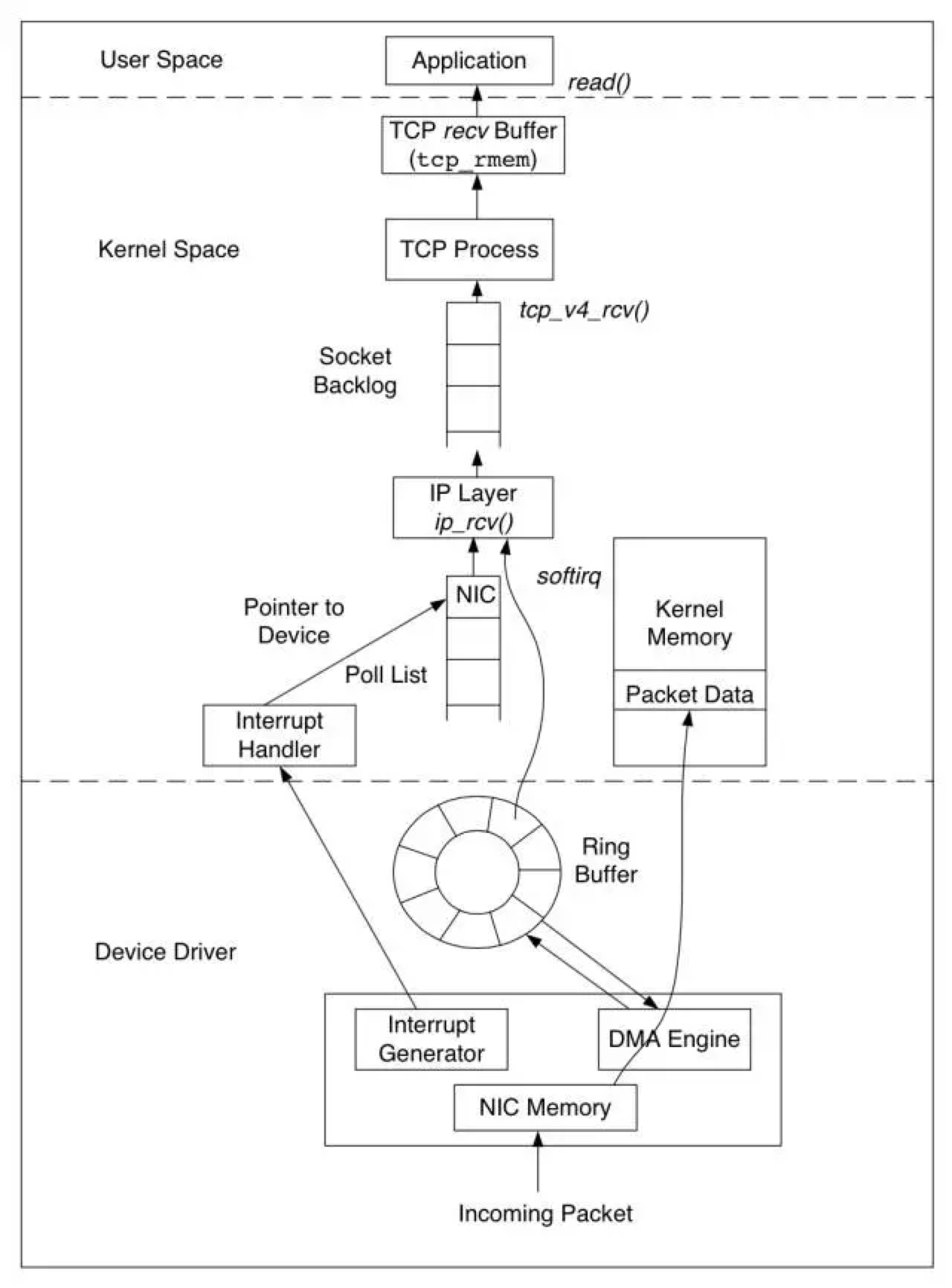
Linux 网络协议栈收消息过程-Per CPU Backlog
前面说到数据是交给 netif_receive_skb 来做进一步的处理,而netif_receive_skb 基本没干什么事情,主要事情都在 netif_receive_skb_internal 中完成。此时数据处理都还在软中断的 Handler 中,top 的 si 能反应出 CPU 在这个阶段花费的时间。
如果没有开启 RPS 会调用 __netif_receive_skb,进而调用 __netif_receive_skb_core 这就基本上进入 Protocol Layer 了。
如果开启了 RPS 则还有一大段路要走,先调用 enqueue_to_backlog 准备将数据包放入 CPU 的 Backlog 中。入队之前会检查队列长度,如果队列长度大于 net.core.netdev_max_backlog 设置的值,则会丢弃数据包。同时也会检查 flow limit,超过的话也会丢弃数据包。丢弃的话会记录在 /proc/net/softnet_stat 中。入队的时候还会检查目标 CPU 的 NAPI 处理 backlog 的逻辑是否运行,没运行的话会通过 __napi_schedule 设置目标 CPU 处理 backlog 逻辑。之后发送 Inter-process Interrupt 去唤醒目标 CPU 来处理 CPU backlog 内的数据。
CPU 处理 backlog 的方式和 CPU 去调用 driver 的 poll 函数拉取 Ring Buffer 数据方法类似,也是注册了一个 poll 函数,只是这个 “poll” 函数在这里是 process_backlog 并且是操作系统 network 相关子系统启动时候注册的。process_backlog 内就是个循环,跟 driver 的 poll 一样不断的从 backlog 中取出数据来处理。调用 __netif_receive_skb,进而调用 __netif_receive_skb_core ,跟关闭 RPS 情况下逻辑一样。并且也会按照 budget 来判断要处理多久而退出循环。budget 跟之前控制 netif_rx_action 执行时间的 budget 配置一样,也是 net.core.netdev_budget 这个系统配置来控制。
net.core.netdev_max_backlog
上面说了将数据包放入 CPU 的 backlog 的时候需要看队列内当前积压的数据包有多少,超过 net.core.netdev_max_backlog 后要丢弃数据。所以可以根据需要来调整这个值:
sysctl -w net.core.netdev_max_backlog=2000
需要注意的是,好多地方介绍在做压测的时候建议把这个值调高一点,但从我们上面的分析能看出来,这个值基本上只有在 RPS 开启的情况下才有用,没开启 RPS 的话设置这个值并没意义。
Flow Limit
如果一个 Flow 或者说连接数据特别多,发送数据速度也快,可能会出现该 Flow 的数据包把所有 CPU 的 Backlog 都占满的情况,从而导致一些数据量少但延迟要求很高的数据包不能快速的被处理。所以就有了 Flow Limit 机制在排队比较严重的时候启用,来限制 Large Flow 并且偏向 small flow,让 small flow 的数据能尽快被处理,不要被 Large Flow 影响。
该机制是每个 CPU 独立的,各 CPU 之间相互不影响,在稍后能看到开启这个机制也是能单独的对某个 CPU 开启。其原理是当 RPS 开启且 Flow Limit 开启后,默认当 CPU 的 backlog 占用超过一半的时候,Flow Limit 机制开始运作。这个 CPU 会对 Last 256 个 Packet 进行统计,如果某个 Flow 的 Packet 在这 256 个 Packet 中占比超过一半,就开始对这个 Flow 做限制,该 Flow 新来的 Packet 全部丢弃,别的 Flow 则正常放入 Backlog 正常处理。被限制的 Flow 连接继续保持,只是丢包增加。
每个 CPU 在 Flow Limit 启用的时候会分配一个 Hash 表,为每个 Flow 计算占比的时候就是在收到 Packet 时候提取 Packet 内一些信息做 Hash,映射到这个 Hash 表中。Hash Function 跟 RPS 机制下为 Packet 找 CPU 用的 Hash Function 一样。Hash 表中的值是个 Counter,记录了在当前 Backlog 中这个 Flow 有多少 Packet 在排队。这里能看到,Hash 表的大小是有限的,其大小能够进行配置,如果配置的过小,而当前机器承载的 Flow 又很多,就会出现多个不同的 Flow Hash 到同一个 Counter 的情况,所以可能出现 False Positive 的情况。不过一般还好,因为一般机器同时处理的 Flow 不会特别多,多个 CPU 下能同时处理的 Flow 就更多了。
开启 Flow Limit 首先要设置 Flow Limit 使用的 Hash 表大小:
sysctl -w net.core.flow_limit_table_len=8192
默认值是 4096。
之后需要为单个 CPU 开启 Flow Limit,这两个配置先后顺序不能搞错:
echo f > /proc/sys/net/core/flow_limit_cpu_bitmap
这个跟开启 RPS 的配置类似,也是个 bitmap 来标识哪些 CPU 开启 Flow Limit。如果希望所有 CPU 都开启就设置个大一点的值,不管有多少 CPU 都能覆盖。
丢弃数据包统计
如果因为 backlog 不够或者 flow limit 不够数据包被丢弃的话会将丢包信息计入 /proc/net/softnet_stat。我们也能在这里看到有没有丢包发生:
cat /proc/net/softnet_stat
930c8a79 00000000 0000270b 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
280178c6 00000000 00000001 00000000 00000000 00000000 00000000 00000000 00000000 0cbbd3d4 00000000
一个 CPU 一行数据。但比较麻烦的是每一列具体表示的是什么意思没有明确文档,可能不同版本的 kernel 打印的数据不同。需要看 softnet_seq_show 这个函数是怎么打印的。一般来说第二列是丢包数。
seq_printf(seq,
"%08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x\n",
sd->processed, sd->dropped, sd->time_squeeze, 0,
0, 0, 0, 0, /* was fastroute */
sd->cpu_collision, sd->received_rps, flow_limit_count);
- time_squeeze 是 net_rx_action 执行的时候因为 budget 不够而停止的次数。这说明数据包多而 budget 小,增大 budget 有助于更快的处理数据包
- cpu_collision 是发消息时候 CPU 去抢 driver 的锁没抢到的次数
- received_rps 是 CPU 被通过 Inter-processor Interrupt 唤醒来处理 Backlog 数据的次数。上面例子中看到只有 CPU1 被唤醒过,因为这个 NIC 只有一个 Ring Buffer,IRQ 都是 CPU0 在处理,所以开启 RPS 后都是 CPU0 将数据发到 CPU1 的 Backlog 然后唤醒 CPU1;
- flow_limit_count 表示触碰 flow limit 的次数
Internet Protocol Layer
前面介绍到不管开启还是关闭 RPS 都会通过 __netif_receive_skb_core 将数据包传入上层。传入前先会将数据包交到 pcap,tcpdump 就是基于 libcap 实现的,libcap 之所以能捕捉到所有的数据包就是在 __netif_receive_skb_core 实现的。具体位置在:http://elixir.free-electrons.com/linux/v4.4/source/net/core/dev.c#L3850
可以看到这个时候还是在 softirq 的 handler 中呢,所以 tcpdump 这种工具一定是会在一定程度上延长 softirq 的处理时间。
之后就是在 __netif_receive_skb_core 里会遍历 ptype_base 链表,找出 Protocol Layer 中能处理当前数据包的 packet_type 来接着处理数据。所有能处理链路层数据包的协议都会注册到 ptype_base 中。拿 ipv4 来说,在初始化的时候会执行 inet_init,看到在这里会构造 ip_packet_type 并执行 dev_add_pack。ip_packet_type 指的就是 ipv4。进入dev_add_pack 能看到是将 ip_packet_type 加入到 ptype_head 指向的链表中,这里 ptype_head 取到的就是 ptype_base。
回到 ip_packet_type 我们看到其定义为:
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};
在 __netif_receive_skb_core 中找到 sk_buff 对应的 protocol 是 ETH_P_IP 时就会执行 ip_packet_type 下的 func 函数,即 ip_rcv,从而将数据包交给 Protocol Layer 开始处理了。
ip_rcv
ip_rcv 能看出来逻辑比较简单,基本就是在做各种检查以及为 transport 层做一些数据准备。最后如果各种检查都能过,就执行 NF_HOOK。如果有检查不过需要丢弃数据包就会返回 NET_RX_DROP 并在之后会对丢数据包这个事情进行计数。
NF_HOOK 比较神,它实际是 HOOK 到一个叫做 Netfilter 的东西,在这里你可以根据各种规则对数据包做过滤以及对数据包做一些修改。如果 HOOK 执行后返回 1 表示 Netfilter 允许继续处理该数据包,就会进入 ip_rcv_finish,HOOK 没有返回 1 则会返回 Netfilter 的结果,数据包不会继续被处理。
ip_rcv_finish 负责为 sk_buff 从 IP Route System 中找到路由目标,如果是路由到本机则在下一个处理这个 sk_buff 的协议内(比如上层的 TCP/UDP 协议)还需要从 sk_buff 中找到对应的 socket。也就是说每个收到的数据包都会有两次 demux (解多路复用)工作(一次找到这个数据包该路由到哪里,一次是如果路由到本机需要将数据包路由到对应的 Socket)。但是对于类似 TCP 这种协议当 socket 处在 ESTABLISHED 状态后,协议栈不会出现变化,后来的数据包的路由路径跟握手时数据包的路由路径完全相同,所以就有了 Early Demux 机制,用于在收到数据包的时候根据 IP Header 中的 protocol 字段找到上一层网络协议,用上一层网络协议来解析数据包的路由路径,以减少一次查询。拿 TCP 来说,简单来讲就是收到数据包后去 TCP 层查找这个数据包有没有对应的处在 ESTABLISHED 状态的 Socket,有的话直接使用这个 Socket 已经 Cache 住的路由目标作为当前 Packet 的路由目标。从而不用再查找 IP Route System,因为根据 Packet 查找 Socket 是怎么都省不掉的。
具体细节是这样,TCP 会将自己的处理函数在 IP 层初始化的时候注册在 IP 层的 inet_protos 中。TCP 注册的这些处理函数中就有 early_demux 函数 tcp_v4_early_demux。在 tcp_v4_early_demux 中我们看到主要是根据 sk_buff 的 source addr、dest addr 等信息从 ESTABLISHED 连接列表中找到当前数据包所属的 Socket,并获取 Socket 中的 sk_rx_dst 即 struct dst_entry,这个就是当前 Socket 缓存住的路由路径,设置到 sk_buff 中。之后这个 sk_buff 就会被路由到 sk_rx_dst 所指的位置。除了路由信息之外,还会将找到的 Socket 的 struct sock 指针存入 sk_buff,这样数据包被路由到 TCP 层的时候就不需要重复的查找连接列表了。
如果找不到 ESTABLISHED 状态的 Socket,就会走跟 IP Early Demux 未开启时一样的路径。后面会看到 TCP 新建立的 Socket 会从 sk_buff 中读取 dst_entry 设置到 struct sock 的 sk_rx_dst 中。struct sock 中的 sk_rx_dst 在这里:linux/include/net/sock.h - Elixir - Free Electrons。
如果 IP Early Demux 没有起作用,比如当前 sk_buff 可能是 Flow 的第一个数据包,Socket 还未处在 ESTABLISHED 状态,所以还未找到这个 Socket 也就无法进行 Early Demux。则需要调用 ip_route_input_noref经过 IP Route System 去处理 sk_buff 查找这个 sk_buff 该由谁处理,是不是当前机器处理,还是要转发出去。这个路由机制看上去还挺复杂的,怪不得需要 Early Demux 机制来省略该步骤呢。如果 IP Route System 找了一圈之后发现这个 sk_buff 确实是需要当前机器处理,最终会设置 dst_entry 指向的函数为 ip_local_deliver。
需要补充一下 Early Demux 对 Socket 还未处在 ESTABLISHED 状态的 TCP 连接无效。这就导致这种数据包不但会查一次 IP Route System 还会到 TCP ESTABLISHED 连接表中查一次,之后路由到 TCP 层又要再查一次 Socket 表。总体开销就会比只查一次 IP Route System 还要大。所以 Early Demux 并不是无代价的,只是大多数场景可能开启后会对性能有提高,所以 Linux 默认是开启的。但在某些场景下,目前来看应该是大量短连接的场景,连接要不断建立断开,有大量的数据包都是在 TCP ESTABLISHED 表中查不到东西,这个机制开启后性能会有损耗,所以 Linux 提供了关闭该机制的办法:
sysctl -w net.ipv4.ip_early_demux=0
有人测试在特定场景下这个机制会带来最大 5% 的损耗:https://patchwork.ozlabs.org/patch/166441/
Early Demux 和查询 IP Route System 都是为了设置 sk_buff 中的 dst_entry,通过 dst_entry 来跳到下一个负责处理该 sk_buff 的函数。这个跳转由 ip_rcv_finish 最后的 dst_input 来完成。dst_input 实现很简单:
return skb_dst(skb)->input(skb);
就是从 sk_buff 中读出来之前构造好的 struct dst_entry,执行里面的 input 指向的函数并将 sk_buff 交进去。
如果 sk_buff 就是发给当前机器的话,Early Demux 和查询 IP Route System 都会最终走到 ip_local_deliver。
ip_local_deliver
做三个事情:
- 判断是否有 IP Fragment,有的话就先存下这个 sk_buff 直接返回,等后续数据包来了之后进行组装;
- 通过和 ip_rcv 里一样的 NET_HOOK 将数据包发到 Netfilter 做过滤
- 如果数据包被过滤掉了,就直接丢弃数据包返回,没过滤掉最终会执行 ip_local_deliver_finish
ip_local_deliver_finish 内会取出 IP Header 中的 protocol 字段,根据该字段在上面提到过的 inet_protos中找到 IP 层初始化时注册过的上层协议处理函数。拿 TCP 来说,TCP 注册的信息在这里: linux/net/ipv4/af_inet.c - Elixir - Free Electrons。ip_local_deliver_finish 会调用注册的 handler 函数,对 TCP 来说就是 tcp_v4_rcv。
IP 层在处理数据过程中会更新很多计数,在 snmp.h 这个文件中可以看看。基本上 proc/net/netstat 中展示的带有 IP 字样的统计都是这个文件中定义的。
Linux 网络协议栈收消息过程-TCP Protocol Layer
漫漫长路,终于到了我们比较熟悉的 TCP 一层了,但很快就会发现上面这一大堆内容什么 NIC、中断、IP 路由之类的加起来可能都没有 TCP 一层的内容复杂,单是 goto 都比别的地方用的都多。因为 TCP 有状态,不同状态下收不到不同数据会有不同的行为,就导致了这个复杂度。为了不陷入 TCP 各种细节逻辑中,我们还是先只看最简单的连接处在 ESTABLISHED 状态的收消息过程。TCP 数据还分为 Normal 和 Urgent 两种,两种类型数据在处理过程中并不相同,为了简单起见,这里只大致介绍 Normal 的数据接收过程。
先推荐一本书叫做 《TCP/IP Architecture, Design and Implementation in Linux》 ,对 TCP 收消息这块逻辑讲的比较清楚,带着你理内核代码。如果有兴趣深究这块看这本书挺好的。
正常来说 TCP 收消息过程会涉及三个队列:
- Backlog Queue sk->sk_backlog
- Prequeue tp->ucopy.prequeue
- Receive Queue sk->sk_receive_queue
当然还有个 out of order queue tp->out_of_order_queue,先不管它,就先只看最简单的逻辑,不然会在复杂的 TCP 逻辑中迷失的。上述三个队列在处理数据的时候是序号大的队列优先级更高,先处理完序号大的队列之后才会处理序号小的队列。tcp_v4_rcv会负责将收到的数据包在上面三个队列之间做分配:
bh_lock_sock_nested(sk);
ret = 0;
if (!sock_owned_by_user(sk)) {
if (!tcp_prequeue(sk, skb))
ret = tcp_v4_do_rcv(sk, skb);
} else if (unlikely(sk_add_backlog(sk, skb,
sk->sk_rcvbuf + sk->sk_sndbuf))) {
bh_unlock_sock(sk);
NET_INC_STATS_BH(net, LINUX_MIB_TCPBACKLOGDROP);
goto discard_and_relse;
}
bh_unlock_sock(sk);
看到先是判断 socket 是否被 user 占用,如果被占用了,说明 User 正在读 socket 的数据,会操作 receivq queue 和 prequeue,为了避免并发操作 Socket,此时将数据包放入 backlog 队列中,如果没有成功放入 backlog 队列比如 backlog 队列已经满了,则会丢弃数据包并更新 TcpBacklogDrop 计数。
如果数据包到的时候 User 没有占用 Socket 则先尝试将数据包放入 Prequeue,如果因为一些原因(稍后会说)放入失败的话就将数据包传入 tcp_v4_do_rcv。在 tcp_v4_do_rcv 中如果连接已经处在 ESTABLISHED 状态,会走所谓的 Fast Path (过会在 tcp_rcv_established 内还会有个 Fast Path,都是为了在满足一些条件的情况下,跳过一些逻辑的优化),将数据包经由调用 tcp_rcv_established放入 Receive Queue。如果是连接没有处在 ESTABLISHED,说明可能当前 sk_buff 内有 TCP 状态控制相关指令,也可能还携带有数据。所以需要先到 rcp_rcv_state_process 经过一轮 TCP 状态转换,转换完之后再处理 sk_buff 内的数据。
在 tcp_rcv_established 内,从注释能看到 tcp_rcv_established 也有 Fast Path 和 Slow Path 之分,满足一大堆条件比如 Socket buffer 是否足够,TCP window 是否足够,是否不是 Urgent Data,数据是否单向流动(指当前机器上的这个 TCP 连接要么一直发数据,要么一直收数据)等之后,就能走 Fast Path,好处是更少的检查,更短的处理路径,从而能处理的更快。在 tcp_rcv_established 内无论是 Fast Path 还是 Slow Path,其功能都是将 sk_buff 拷贝到 User Space 或放入 receive queue。如果 tcp_rcv_established 是在 User Space 内调用,则满足数据有序的条件之后就会直接拷贝到 User Space,这条路径稍后再说,目前我们还一直处在软中断路径中。如果是软中断内调用 tcp_rcv_established 则会将 sk_buff 放入 Receive Queue,如果数据包是乱序到达,则将数据包放到 Out of order 队列。
Receive Queue 可以认为是 softIRQ 和 User Space 的分界线,softIRQ 负责将数据放入队列,用户调用读取数据的系统调用后会读取队列数据。
Receive Queue
与 Backlog 和 Prequeue 的不同点在于,放入 Receive Queue 的 sk_buff 都是已经被处理过的,抹去了所有 Protocol Header 信息,只有 sk_buff 中真正有用的会拷贝到 User space 的数据会放入 Receive Queue。并且,Receive Queue 中的数据一定是符合 TCP 序列的,所以才能被直接拷贝到 User Space。而其它两个队列入队的时候都还有 Header 信息,还未经过处理,而且可能包含乱序的数据。
这里是入队过程,后续还有出队的过程,在 Receive Queue 出队部分会看到 tcp_v4_do_rcv 和 tcp_rcv_established不光是在 softIRQ 内可能会执行,User Space 下也可能会执行。在 tcp_rcv_established 内如果发现用户进程正在读取 Socket,设置的 Receiver 刚好是当前进程(说明是 User Space 调用的 tcp_rcv_established,因为 Receiver 就是 Current 进程,并且数据的 SEQ 表明其刚好是下一个需要的数据包,则会先尝试将该 sk_buff 直接拷贝到 User Space。因为满足上面各种条件后,这个正在处理的数据包就一定是当前 TCP 连接上正在等待的下一个数据包,所以能直接将 sk_buff 拷贝到 User Space 不会产生乱序。如果不满足上面一堆条件,不能直接拷贝到 User Space,则会将 sk_buff 内的 TCP Header 抹去,并通过 __skb_queue_tail 将数据放入 sk_receive_queue。
Prequeue
如果没有开启 net.ipv4.tcp_low_latency 并且用户进程设置了 TCP Receiver Task 的话,说明有个 User 进程正在读 Socket (因为只有正在读 Socket 时才会设置 tp.ucopy.task)且还没有读够所需数据,正在 sleep 等待读入的数据。此时会将 sk_buff 放入 Prequeue。
一般进入 Prequeue 的 sk_buff 是不进行处理的,还保留有 tcp header 等信息,sk_buff 直接放入 Prequeue,处理工作交给用户进程完成。但是当 sk_buff 放入 Prequeue 后发现 socket 占用的内存超过了 sk_rcvbuf 的限制,则需要立即将所有 Prequeue 内的 sk_buff 出队,并通过 tcp_v4_do_rcv 开始处理,最终 sk_buff 会被放入 Receive Queue。每个被处理的 sk_buff 都会更新 TCPPrequeueDropped 计数。因为会将 TCP Header 去除,所以占用的内存大小会少一些,如果还是超过 sk_rcvbuf,则会丢弃数据包。
如果放入 Prequeue 的 sk_buff 是 Prequeue 内第一个元素,则一方面会重置 ACK 回复时间,延迟 ACK 回复;另一方面会唤醒正在 sleep 等待数据到来的 User 进程。
Backlog
如果收到数据包时,Socket 正在被 User 占用,可能 User 正在读取数据,会操作 Receive Queue 和 Prequeue,所以新收到的数据就暂时不放入这些队列中,而是放入 Backlog 里。如果 Backlog 满了 会将数据包丢弃。
由于TCP建立连接需要进行3次握手,一个新连接在到达ESTABLISHED状态可以被accept系统调用返回给应用程序前,必须经过一个中间状态SYN RECEIVED(见上图)。这意味着,TCP/IP协议栈在实现backlog队列时,有两种不同的选择:
- 仅使用一个队列,队列规模由listen系统调用backlog参数指定。当协议栈收到一个SYN包时,响应SYN/ACK包并且将连接加进该队列。当相应的ACK响应包收到后,连接变为ESTABLISHED状态,可以向应用程序返回。这意味着队列里的连接可以有两种不同的状态:SEND RECEIVED和ESTABLISHED。只有后一种连接才能被accept系统调用返回给应用程序。
- 使用两个队列——SYN队列(待完成连接队列)和accept队列(已完成连接队列)。状态为SYN RECEIVED的连接进入SYN队列,后续当状态变更为ESTABLISHED时移到accept队列(即收到3次握手中最后一个ACK包)。顾名思义,accept系统调用就只是简单地从accept队列消费新连接。在这种情况下,listen系统调用backlog参数决定accept队列的最大规模。
历史上,起源于BSD的TCP实现使用第一种方法。这个方案意味着,但backlog限制达到,系统将停止对SYN包响应SYN/ACK包。通常,协议栈只是丢弃SYN包(而不是回一个RST包)以便客户端可以重试(而不是异常退出)。
TCP/IP详解 卷3第14.5节中有提到这一点。书中作者提到,BSD实现虽然使用了两个独立的队列,但是行为跟使用一个队列并没什么区别。
在Linux上,情况有所不同,意思是,backlog参数的行为在Linux2.2之后有所改变。现在,它指定了等待accept系统调用的已建立连接队列的长度,而不是待完成连接请求数。待完成连接队列长度由/proc/sys/net/ipv4/tcp_max_syn_backlog指定;在syncookies启用的情况下,逻辑上没有最大值限制,这个设置便被忽略。
也就是说,当前版本的Linux实现了第二种方案,使用两个队列——一个SYN队列,长度系统级别可设置以及一个accept队列长度由应用程序指定。
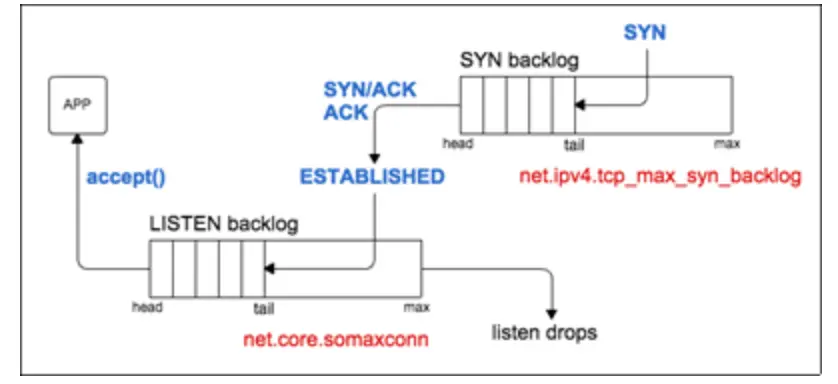
现在,一个需要考虑的问题是在accept队列已满而一个已完成新连接需要用SYN队列移动到accept队列(收到3次握手中最后一个ACK包),这个实现方案是什么行为。这种情况下,由net/ipv4/tcp_minisocks.c中tcp_check_req函数处理:
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
if (child == NULL)
goto listen_overflow;
对于IPv4,第一行代码实际上调用的是net/ipv4/tcp_ipv4.c中的tcp_v4_syn_recv_sock函数,代码如下:
if (sk_acceptq_is_full(sk))
goto exit_overflow;
可以看到,这里会检查accept队列的长度。如果队列已满,跳到exit_overflow标签执行一些清理工作、更新/proc/net/netstat中的统计项ListenOverflows和ListenDrops,最后返回NULL。这会触发tcp_check_req函数跳到listen_overflow标签执行代码。
listen_overflow:
if (!sysctl_tcp_abort_on_overflow) {
inet_rsk(req)->acked = 1;
return NULL;
}
很显然,除非/proc/sys/net/ipv4/tcp_abort_on_overflow被设置为1(这种情况下发送一个RST包),实现什么都没做。
总结一下:Linux内核协议栈在收到3次握手最后一个ACK包,确认一个新连接已完成,而accept队列已满的情况下,会忽略这个包。一开始您可能会对此感到奇怪——别忘了SYN RECEIVED状态下有一个计时器实现:如果ACK包没有收到(或者是我们讨论的忽略),协议栈会重发SYN/ACK包(重试次数由/proc/sys/net/ipv4/tcp_synack_retries决定)。
看以下抓包结果就非常明显——一个客户正尝试连接一个已经达到其最大backlog的socket:
0.000 127.0.0.1 -> 127.0.0.1 TCP 74 53302 > 9999 [SYN] Seq=0 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 66 53302 > 9999 [ACK] Seq=1 Ack=1 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 71 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
0.207 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
0.623 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
1.199 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
1.199 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 6#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
1.455 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
3.123 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
3.399 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
3.399 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 10#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
6.459 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
7.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
7.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 13#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
13.131 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
15.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
15.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 16#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
26.491 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
31.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
31.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 19#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
53.179 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
106.491 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
106.491 127.0.0.1 -> 127.0.0.1 TCP 54 9999 > 53302 [RST] Seq=1 Len=0
由于客户端的TCP实现在收到多个SYN/ACK包时,认为ACK包已经丢失了并且重传它。如果在SYN/ACK重试次数达到限制前,服务端应用从accept队列接收连接,使得backlog减少,那么协议栈会处理这些重传的ACK包,将连接状态从SYN RECEIVED变更到ESTABLISHED并且将其加入accept队列。否则,正如以上包跟踪所示,客户读会收到一个RST包宣告连接失败。
在客户端看来,第一次收到SYN/ACK包之后,连接就会进入ESTABLISHED状态。如果这时客户端首先开始发送数据,那么数据也会被重传。好在TCP有慢启动机制,在服务端还没进入ESTABLISHED之前,客户端能发送的数据非常有限。
相反,如果客户端一开始就在等待服务端,而服务端backlog没能减少,那么最后的结果是连接在客户端看来是ESTABLISHED状态,但在服务端看来是CLOSED状态。这也就是所谓的半开连接。
有一点还没讨论的是:man listen中提到每次收到新SYN包,内核往SYN队列追加一个新连接(除非该队列已满)。事实并非如此,net/ipv4/tcp_ipv4.c中tcp_v4_conn_request函数负责处理SYN包,请看以下代码:
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
可以看到,在accept队列已满的情况下,内核会强制限制SYN包的接收速率。如果有大量SYN包待处理,它们其中的一些会被丢弃。这样看来,就完全依靠客户端重传SYN包了,这种行为跟BSD实现一样。
下结论前,需要再研究以下Linux这种实现方式跟BSD相比有什么优势。Stevens是这样说的:
在accept队列已满或者SYN队列已满的情况下,backlog会达到限制。第一种情况经常发生在服务器或者服务器进程非常繁忙的情况下,进程没法足够快地调用accept系统调用从中取出已完成连接。后者是HTTP服务器经常面临的问题,在服务端客户端往返时间非常长的时候(相对于连接到达速率),因为新SYN包在往返时间内都会占据一个连接对象。
大多数情况下accept队列都是空的,因为一旦有一个新连接进入队列,阻塞等待的accept系统调用将返回,然后连接从队列中取出。
Stevens建议的解决方案是简单地调大backlog。但有个问题是,应用程序在调优backlog参数时,不仅需要考虑自身对新连接的处理逻辑,还需要考虑网络状况,包括往返时间等。Linux实现实际上分成两部分:应用程序只负责调解backlog参数,确保accept调用足够快以免accept队列被塞满;系统管理员则根据网络状况调节/proc/sys/net/ipv4/tcp_max_syn_backlog,各司其职。
出队处理
上面都是数据包入队的过程,下面看看数据包出队的过程。
用户调用 read 系统调用从 Socket 上读取数据后最终会走到 tcp_recvmsg,在读取数据前先会将 Socket 上锁,之后计算期望读取的最小数据量。用户设置的期望读取数据量是 len,但是不一定非要读那么多数据才返回,系统有个 SO_RCVLOWAT 配置,表示如果当前没有 len 这么多数据时,就 block 住至少等待读到 SO_RCVLOWAT 这么多数据的时候才能返回。SO_RCVLOWAT 最少是 1 字节。SO_RCVLOWAT 的结果会存入 target 变量。
处理数据是在一个大的 do while 循环内完成,用于从 Receive quque 或 Prequeue 上循环的读取数据。优先处理 Receive Queue,从 sk->sk_receive_queue 上每取下一个 sk_buff,就拷贝到 User Space。因为 Receive Queue 上的数据都是符合当前 TCP 连接序列要求的,所以能这么直接拷贝,不会出现乱序。如果读到足够的数据超过 len 即用户期望的数据量,就退出循环直接返回,即使 Receive Queue 处理不完也会跳出循环。如果将 Receive Queue 处理完都一直读取不到 len 这么多数据,但至少读到了 target 这么多数据,也跳出循环去处理 Backlog 队列,不 Block 等待数据。
如果 Receive Queue 处理完没有读到 len 这么多数据,也没读到 target 这么多数据,并且开启了 Prequeue 机制,则要配置一个 Receiver Task,因为 Receiver Task 刚刚配置,所以 Prequeue 一定是空的,先不会进入 Prequeue 出队逻辑。因为还未读到 target 这么多的数据所以会 Block 住,等待数据到来。Block Sleep 之前会释放 Socket 锁,从而在 Block 之后新来的数据不用进入 Backlog。用户进程占有 Socket 锁期间到来的数据都存在 Backlog 队列,只要用户进程释放 Socket 锁释放之前就会检查 Backlog 队列是否已经有数据,有数据的话会进行处理将数据从 Backlog 读出来通过 tcp_v4_do_rcv 放入 Receive Queue。因为这块逻辑是用户进程在执行,Backlog 内读出来的数据如果符合 TCP 序列是能直接拷贝到 User Space 的,拷贝过去后会更新 TCPDirectCopyFromBacklog 计数。
可以仔细体会一下上面处理数据的顺序,设计的还是挺精巧的,一共三个队列,之间还有优先级,必须高优先级的处理完,才能处理低优先级的。或者也许叫优先级不对,总之是个处理的先后顺序。
用户进程 Block 之后,Socket 的锁也释放了,Backlog 数据也处理完了,之前看到过 Prequeue 的入队逻辑会检查这个 Receiver Task,在 Receiver Task 被配置后新来的数据会全部进入 Prequeue,此时 Receive Queue 内的数据是之前 Backlog 内的数据。第一个新数据来的时候就会将 Block 住的用户进程唤醒。
用户进程被唤醒后还是按照顺序,先处理 Receive Queue,处理完之后再处理 Prequeue 上的数据,将 Prequeue 的数据取出来之后调用 tcp_v4_do_rcv 。sk_backlog_rcv 指向的就是 tcp_v4_do_rcv。tcp_prequeue_process 内每处理一个 sk_buff 会更新 TCPPrequeued 计数。在 tcp_prequeue_process 内处理完 Prequeue 后会因为此时是用户进程执行的 tcp_prequeue_process 所以会将从 Prequeue 内拷贝到 User Space 的数据量更新在 TCPDirectCopyFromPrequeue 计数内。前面说过,如果数据包放入 Prequeue 的时候 Prequeue 已经满了,就会在 softIRQ 环境内直接将 Prequeue 内所有正在排队的数据进行处理,并且会更新 TCPPrequeueDropped 而不是 TCPDirectCopyFromPrequeue。
接着说出队过程。因为 Receiver Task 已经被设置并且一直未取消,所以只要读取的数据量小于 target 就一直在 while 内循环,总体就是:
- 处理 Receive Queue
- 处理 Prequeue
- 处理 Backlog
- Block
- 回到 1
如果 Receive Queue、Prequeue 处理完获取到了超过 target 的数据,则释放 Socket 锁去处理 Backlog,但在 release_lock 内处理完 Backlog 后会立即再次加锁,再次开始 Receive Queue 的处理,尽力读取到用户期望的 len 这么多数据。如果此时 Receive Queue 处理完,且 backlog 没数据,则退出循环。
Prequeue 除了上面说的 User 进程会处理之外,在 ACK delay Handler 内也会处理,场景是这样。虽然 Prequeue 入队第一个数据后会去唤醒被 block 的进程,但如果当前机器负载过重,可能执行了唤醒但是目标进程很久都没被唤醒起来,此时延迟的 ACK 执行的时候会负责处理 Prequeue 内排队的数据。在 tcp_delack_timer 内如果 Socket 未被 User 进程占用,则会调用 tcp_delack_timeer_handler,能看到在这个 handler 内会从 Prequeue 取 sk_buff 下来,放入 sk_backlog_rcv 即 tcp_v4_do_rcv 内处理。这种情况下会更新:TCPSchedulerFailed 计数。正常情况下这个计数应该是 0,系统不该忙到都该回复 ACK 了还唤不醒目标进程。在 netstat -s 中能看到这个统计:
4971 times receiver scheduled too late for direct processing
如果在 tcp_delack_timer 内 Socket 被 User 进程占用,则会更新 TCPSchedulerFailed 计数并延迟 ACK 的回复。
为什么要有 Prequeue
看到 Prequeue 是个可选项,默认是开启的但能通过 net.ipv4.tcp_low_latency来关闭。有这个选项存在就说明 Prequeue 存在的理由不像 Receive Queue 和 Backlog 一样那么明确可靠。所以我们需要看看 Prequeue 存在的原因。
有个关于 Prequeue 作用的讨论在这里: Linux Kernel - TCP prequeue performance,可以参考一下。
如果关闭 Prequeue,我们知道如果 Socket 没有被 User 占用,收到的 sk_buff 会直接调用 tcp_v4_do_rcv 进行处理,放入 Receive Queue,这一切都会在 softIRQ 的 context 中执行,最关键的是在放入 Receive Queue 后会回复 ack,而实际此时用户进程并没有实际收到数据,离用户进程起来处理数据还有一段时间。这就导致对端收到 ack 后认为对方能很快处理数据从而会发的更快,直到对方 Receive Queue 满了之后突然不再回复 ack,开始丢包。而一般情况下 TCP 连接对性能影响最大的就是丢包,重传,所以需要尽可能避免上述情况的发生。这种情形下,ack 相当于是只送达了对方机器就被回复了,而没有送到目标进程。
有了 Prequeue 之后,ack 会有两种回复方式,一种是用户进程被唤醒将 Prequeue 数据读入 Receive Queue 后回复 ack,这种时候数据是确认送达用户进程了。另一种是用户进程迟迟无法被唤醒,延迟 ack 的定时器被触发而回复 ack,这样也能减慢 ack 回复速度让对端知道这边处理性能有点跟不上,要慢点发数据。两种方式都能减少或避免之前说的问题,这也是 Prequeue 存在的意义。
但是对于体量小延迟又要求高的数据包,Prequeue 的存在又会增加延迟。原因是如果关闭了 Prequeue 机制,每来一条数据都要经过 tcp_v4_do_rcv 的处理,上面我们只看了一下 Fast Path,但能走 Fast Path 的要求还是比较苛刻的,不能有乱序到达,数据只能是单向,要么单向收要么单向发等等条件,只要有一条不满足就要走 Slow Path。Slow Path 内各种检查会更多,更麻烦一些。除了检查还一个耗时的是计算 checksum。如果没有 Prequeue 则这些逻辑全部要在 softIRQ context 内完成。在 User 进程被唤醒前可能只能放很少的数据到 Receive Queue 内。而有了 Prequeue 后,softIRQ 内只需要将数据包放入队列,不做任何检查和处理,接着就能处理下一个数据包,等到用户进程被唤醒后能从 Prequeue 批量处理数据。
不过 Prequeue 是 Linux 特有的机制,近些年因为 NIC 会自动计算 checksum,不需要在收到数据过程中再计算了,所以 Prequeue 存在的意义基本只是延迟 ack 回复到用户进程内这一个。开启它实际对延迟增加并不明显: the myth of /proc/sys/net/ipv4/tcp_low_latency 、What is the linux kernel parameter tcp_low_latency?在 IPV6 内更是去掉了这个机制。
Socket Buffer 管理
sk_rcvbuf
从上面队列的描述我们发现这几个队列都是简单的链表,都没看到队列长度的限制,没有限制则数据不断到来的时候一定可能会出现收到的数据占满系统内存的情况,所以这几个队列长度肯定都是有限制的。而限制的方法是通过限制给 Socket 分配的最大占用内存量来实现的。每个 Socket 系统都会分配一个最大内存使用量,Socket 内除了收消息过程因为数据排队会占用这个最大分配的内存量配额外,发消息过程也会有排队,也会占用这个内存最大使用量配额。也就是说收发消息过程是共用这个内存使用量的。Socket 当前分配的内存使用量由 sk->sk_forward_alloc 记录。
Socket 的 sk_forward_alloc 不是一开始就分配的,而是在收到数据包放入接收队列后 sk_buff 的大小会算入 Socket 的内存使用量。发出的消息进入发出队列的时候也会算入 sk_forward_alloc。等 sk_buff 从 Socket 中取出来被处理之后,Socket 的 sk_forward_alloc 就减小了。稍后会看一下接收过程中 sk_forward_alloc 的变化过程。
为了避免收发消息过程相互影响,比如出现用户进程长时间不处理 Socket 收到的数据导致大量数据在 Socket 内排队,将 Socket 内存额度全部占满而无法发消息,分别有 sk->sk_rcvbuf 和 sk->sndbuf 限制收发消息最大占用内存量。
对收消息过程来说,Socket 占用内存量就是 Receive Queue、Prequeue、Backlog、Out of order 队列内排队的 sk_buff 占用内存总数。当数据被拉取到 User Space 后,就不再占用 Socket 的内存。这里有几个需要注意的,一个是发送过程和接收过程共用分配的 Socket 内存总量 sk_forward_alloc。对收消息过程来说,Receive Queue、Prequeue、Backlog、Out of order 共同占用的内存量不能超过 sk->sk_rcvbuf。如果用户进程处理消息较慢,大量消息在 Receive Queue、Prequeue、Backlog 内排队,则 Out of order 队列的大小会受到限制,而 Out of order 队列大小会影响 TCP Receive Window 的大小,从而在用户进程处理消息慢的时候能通过减小 Receive Window 让对端减慢发消息速度。
一般来说 Socket 的 sk_rcvbuf 受到两个配置的控制:
sysctl -w net.core.rmem_max=8388608
sysctl -w net.core.rmem_default=8388608
rmem_default 是 Socket 初始时默认的 sk_rcvbuf 大小,如果你不希望用系统默认值,想为某个特殊的 Socket 单独设置 sk_rcvbuf 的大小,则能通过调用 setsockopt传递 SO_RCVBUF 设置单个 Socket 的 sk_rcvbuf 值,但是设置的值不能超过 rmem_max 上限。不过可以通过配置 SO_RCVBUFFORCE 来强制设置 sk_rcvbuf 为超过 rmem_max 的值。
net.ipv4.tcp_rmem
对于 TCP 连接来说稍微特别一些,除了 sk_rcvbuf 的限制之外,TCP 还有自己的一套 Socket 接收 Buffer 的限制机制,能根据系统当前所有 TCP 连接占用的总内存量判断系统压力级别,来决定是否能为某个 Socket 继续分配接收 Buffer。这里要区分清楚的是 sk_rcvbuf 是 Socket 接收 buffer 分配的上限,而 Socket 当前实际分配的接收 buffer 大小是 sk_rmem_alloc 记录。连接每次收到一个 sk_buff 放入 Socket 队列之后,就会增加 sk_rmem_alloc 并减少 sk_forward_alloc 的值,sk_forward_alloc 不够的时候就需要向系统申请配额。如果系统上只有一个连接,那 Socket 分配的接收 Buffer 没有达到 sk_rcvbuf 之前,系统可能都会允许给这个连接继续分配接收 buffer。但是如果系统上有几百万连接,占用了大量的内存,每个连接都分为 sk_rcvbuf 这么多接收 Buffer 的话系统可能会支撑不住,所以 TCP 的接收 Buffer 的限制机制就是在 Socket 的接收 Buffer 还未到达 sk_rcvbuf 之前就根据当前系统负载情况,在负载特别大的时候拒绝 Socket 扩大接收 buffer 的申请。
跟 tcp 连接的这个接收 Buffer 限制机制相关的配置是 net.ipv4.tcp_rmem ,是个数组,有三个值分别是 min, default, max,给 TCP Socket 分配 sk_rcvbuf 时会根据系统当前压力级别从 min, default, max 三个值中选择,用以控制 Socket 接收 Buffer 的大小。
- min 默认大小是一个 Page。限制的是 Socket 接收 Buffer 的最小值。不管系统压力如何,只要连接已分配的接收 buffer 大小 sk_rmem_alloc 小于这个值,就能允许继续分配内存。不过系统内 TCP 连接占用内存总数不能超过最高值 tcp_mem[2],下面会说;
- default 是 TCP Socket 默认的 sk_rcvbuf 大小。会取代 net.core.rmem_default 的值。TCP Socket 初始化的时候就会设置 sk_rcvbuf 为 tcp_rmem 1 的值;
- max 限制 Socket 接收 Buffer 的最大值
min、default、max 的默认值在 TCP 层初始化的时候设置。
net.ipv4.tcp_moderate_rcvbuf
TCP 有个自动调节 sk_rcvbuf 的机制,在 net.ipv4.tcp_moderate_rcvbuf 置位后开启,默认是开启的。TCP 连接建立完毕进入 ESTABLISHED 状态后会立即调整 Socket 内各种 buffer 大小,其中包括 sk_rcvbuf 和 sk_sndbuf,还会初始化 TCP 各种 window。如果默认的 sk_rcvbuf 过小会自动进行扩大。其主要是依据 TCP Receive Window 的大小在做调节。
tcp_recvmsg 内每处理完一个 sk_buff 就会通过调用 tcp_rcv_space_adjust 调节 User receive space 大小,并且如果 net.ipv4.tcp_moderate_rcvbuf开启的话就会调节 sk_rcvbuf 的大小。
如果用户通过 SO_RCVBUF 设置了 sk_rcvbuf,则会在 Socket 内设置 SOCK_RCVBUF_LOCK,从而跳过每个可能会自动设置 sk_rcvbuf 的地方:linux/net/ipv4/tcp_input.c - Elixir - Free Electrons、linux/net/ipv4/tcp_input.c - Elixir - Free Electrons。
在好些地方看到说 net.ipv4.tcp_moderate_rcvbuf 设置后 net.ipv4.tcp_rmem 就不起作用了。实际从上面机制看到这两个完全是不同的配置,一个管理的是 sk_rcvbuf 是 Socket 接收 buffer 的上限,net.ipv4.tcp_rmem则是 Socket 分配内存大小,并不太一样。
收消息过程的内存分配
先看 Backlog 比较简单,tcp_v4_rcv 内入队 Backlog 时会将 sk->sk_rcvbuf 、 sk->sk_sndbuf 之和作为 limit 参数传入 sk_add_backlog 并会在一开始就判断 Backlog 是否满了。sk_rcvqueues_full 实现相当于是在判断:
sk->sk_backlog.len + atomic_read(&sk->sk_rmem_alloc) 是否大于 sk_rcvbuf + sk_sndbuf
为什么这里 limit 是 sk_rcvbuf + sk_sndbuf 可能得在看完发消息过程后找到答案。
如果 Backlog 满了就丢弃 sk_buff,没有满会将 sk_buff 加入 Backlog 并将 sk_buff 的大小加入 sk_backlog.len。Backlog 出队时会将 sk_backlog.len 设置为 0。
再看 Prequeue 入队时候更新的是 tp->ucopy.memory,当 tp->ucopy.memory 大于 sk_rcvbuf 的时候就认为 prequeue 满了,会立即清理 prequeue。清理完后会将 tp->ucopy.memory 设置为 0。在 Prequeue 的另一个出队的地方 tcp_prequeue_process 内也有同样的逻辑,Prequeue 清理完后会设置 tp->ucopy.memory 为 0。
最后是 Receive queue,sk_buff 放入 Receive queue 后会设置当前 Socket 为该 sk_buff 的 owner,在 skb_set_owner_r 内会将数据包大小更新到 sk_rmem_alloc 中,并且会从 sk_forward_alloc 中将分配给 sk_rmem_alloc 的内存减去。
如果 sk_forward_alloc 目前没有足够的内存,则不会这么顺利的将 sk_buff 放入 Receive queue。需要走到 tcp_data_queue 去分配 sk_forward_alloc。如果此时 receive queue 是空的,则强制分配内存给 sk_forward_alloc,分配的时候会将 sk_buff 的大小圆整到 page size 的倍数。如果 receive queue 不是空,则通过 tcp_try_rmem_schedule 来尝试分配内存。可以看到如果 sk_rmem_alloc 已经大于 sk_rcvbuf,就不会尝试再新分配内存,而是直接开始 tcp_prune_queue 清理 Receive queue 以尝试挤出一点内存空间。如果 sk_rmem_alloc 还未大于 sk_rcvbuf,则进入 sk_rmem_schedule 来分配内存。sk_rmem_schedule 又会调用 __sk_mem_schedule 来完成内存分配,会进行各种检查,检查主要涉及到 net.ipv4.tcp_mem 这个配置,和 net.ipv4.tcp_rmem 一样,net.ipv4.tcp_mem 也是个数组,有三个值分别是 low, pressure, high 例如:
net.ipv4.tcp_mem = 769401 1025869 1538802
注意其单位是 Page 数,不是字节数。作用就是判断当前系统 TCP 连接占用的内存总数处在什么级别,从而在分配内存的时候决定是否允许分配。
__sk_mem_schedule 内基本逻辑如下:
- 根据需要分配的内存 size 圆整并换算为 Page 数;
- 将 sk_forward_alloc 增加 Page 数量乘以 Page 大小;
- 更新系统所有 TCP 连接占用内存的统计;
- 如果当前 TCP 连接占用内存总数(包括第 2 步这个刚分配过的内存)小于 tcp_mem 0,则直接允许分配。如果当前系统处在 presure 状态则切换回 low 状态;
- 如果当前 TCP 连接占用内存总数大于 tcp_mem 1,则系统进入 presurre 状态,并且还要继续后续判断;
- 如果当前 TCP 连接占用内存总数大于 tcp_mem 2,则直接放弃内存分配,会在 tcp_try_rmem_schedule 内开始 prune queue;
- 能走到这里当前 TCP 连接占用内存总数一定是在 tcp_mem 0 ~ 2 之间,如果已分配内存数 sk_rmem_alloc 小于 tcp_rmem[0] 则允许分配,之前说过不管连接是否处在 pressure 都允许 Socket 的接收 buffer 至少分配 tcp_rmem[0] 这么多内存;
- 如果当前不在 pressure 状态,则表示 TCP 连接占用内存总数在 tcp_mem 0 ~ 1 之间,则允许分配;
- 如果当前在 pressure 状态,则表示 TCP 连接占用内存总数在 tcp_mem 1 ~ 2 之间,如果当前系统所有 socket 分配的内存都是当前 socket 这么多,占用的内存总数是否会超过 tcp_mem 2,如果不超过则也允许分配;
- 其它情况都不允许分配,会回退 sk_forward_alloc 上增加的内存数;
__sk_mem_schedule 内前 7 步都比较直观,很容易看明白。但从 sk_has_memory_pressure 这里可能会开始有疑惑。实际上这里判断的不是 Socket 是否曾经进入过 pressure 状态,而是说当前这个 Socket 是否有 memory pressure 这个标志位。有的协议可能没有,有的协议有。TCP 协议是有的,所以这里 sk_has_memory_pressure 对 TCP 的 Socket 来说是一定存在的。它实际判断的是 struct sock_common 的 struct proto是否有初始化过 memory_pressure 这个字段。而对 TCP Socket 来说 struct proto 指向的是 tcp_proto,它是有 memory_pressure 字段的,不是 NULL,指向的是一个 int 变量。
从 struct tcp_proto 我们也能看出来 TCP Socket 是怎么执行 enter memory pressure 的,它实际调用的是 tcp.c 内的 tcp_enter_memory_pressure,而 tcp_enter_memory_pressure 就是将上述说的 tcp_memory_pressure 这个 int 从初始的 0 设置为 1,就完成了 Socket 进入 pressure 状态的标记。不同的协议可能有不同的进入 memory pressure 的方式,所以 Linux 这里是通过协议实现自己的 struct proto,在 struct proto 内注册各种回调函数,完成不同协议执行不同逻辑这个功能的。
上面第 9 步可能也需要再体会一下,它是先通过调用 sk_sockets_allocated_read_positive 到 tcp_sockets_allocated 读取了当前系统下分配了多少个 TCP Socket。这一步看到也是通过 struct proto 内注册来实现只读取 TCP Socket 数量的。读到当前系统 Socket 数量后,就假设这些 Socket 占用的内存都是当前正在分配内存的 Socket 这么多,那 TCP Socket 占用的内存总数是否会超过 tcp_mem 2 的限制。
Receive queue 内存释放
将 sk_buff 放入 Socket 的 Receive Queue 并增加 Socket 分配的 sk_rmem_alloc 时,我们会为 sk_buff 设置 destructor。在 sk_buff 从 Receive Queue 出队的时候会调用 sk_eat_skb,之后调用 __kfree_skb,再到 skb_release_all,再到 skb_release_head_state ,最终调用到 skb->destructor。skb->destructor 指向的是 sock_rfree,在 sock_rfree 内看到将 sk_buff 的大小从 sk_rmem_alloc 中减去,并加到 sk_forward_alloc 上。完成了 Socket 内存的释放。
实时通信系统并发连接数测试时需要调整的各种参数
维持大量并发连接是实时通信系统的关键能力之一,而要想测出一台服务器到底能支撑多少连接有时候会比较麻烦,需要涉及到好几个系统参数的调整,在这里希望能将遇到过的各种参数调整记录一下,以备后用。
以下所说连接均指 TCP 连接。
客户端连接数限制
首先需要明确一点是单个压测客户端(单个 IP)能承载的并发连接数是有限制的,这个上限是 65535。也就是说无论压测客户端所在机器性能有多强大,单个 IP 能和服务端建立的并发连接数就只有 65535 个,不可能更多。而从服务端角度来看,服务端能承受的并发连接数又远远不止 65535 个,只要服务器内存足够,CPU 足够强大,单机承载几十上百万的并发连接完全不是问题,所以我们经常能听到评价某些实时通信服务时候说单机能承担百万并发连接等。为什么从客户端和从服务端两个角度会得到不同的限制呢?
从网络协议层面看,需要有四个信息能唯一确定一条连接:Source IP + Source Port + Destination IP + Destination Port,客户端在创建 Socket 连接服务端的时候服务端的 Destination IP + Destination Port 是固定不变的,对客户端来说如果只有一个 IP 那 Source IP 也固定不变,能唯一确定一条连接的信息中只有 Source Port 可变,所以对客户端来说单个 IP 能创建的连接数完全取决于 Source Port 数量。而反观服务端,Destination IP 和 Destination Port 是固定的,但能连上服务端的客户端 Source IP 和 Source Port 都是可变的,所以服务端连接数量最多是 Source IP 乘以 Source Port 数量。
为了得到 Source Port 的限制数量我们可以看看 TCP Header 格式:

从上图能看到 Source Port 和 Destination Port 都只有 16 个 bit,也就是说上限都是 65535 个。
如果使用的是 IPv4,IP 协议报文的 Header 如下:

看到 Source Address 和 Destination Address 都是 32 bit,这支持的 IP 数量就多了去了在几十亿的级别。
所以,客户端单个 IP 能创建的连接上限是 65535 个,服务端单个 IP 能创建的连接数量按目前一般机器性能来看可以认为是无限。如果压测客户端性能强大,想单个客户端上与服务端创建超过 65535 个连接,唯一的方法就是扩展客户端 IP 数量,比如使用虚拟 IP。
报错信息
当因为 IP 端口不足而无法建立连接时,Java 的话会报如下错误:
Cannot assign requested address (Address not available)
Open File Descriptors 限制
ulimit 命令用于展示和设置用户进程对一些系统关键资源使用的限制。因为每一个建立的连接在 Linux 上都可视为一个打开的文件,会占用一个 File Descriptor,所以 ulimit 内各种限制中跟并发连接数最相关的是进程最大能打开的 File Descriptor 数量。这个限制经常有人和单个 IP 端口数限制搞混,认为客户端单个 IP 能建立的连接数上限为 65535 是因为 File Descriptor 限制,只要机器内存够大,将 File Descriptor 改的够大,客户端单个 IP 能建立的连接数上限就能提升,这个是不正确的。
报错信息
当因为 Open File Descriptors 数量不足受限时会报错:
Too many open files
修改方法
Linux 下,临时修改的话直接执行 ulimit -n XXXXX 即可,但这个执行完后只对当前 Shell session 有效,再次登录后会恢复原状,如果想永久有效需要修改 /etc/security/limits.conf 文件,打开该文件找到 nofile 就是 File Descriptor 限制,例如:
soft nofile 1000000
hard nofile 1000000
普通用户默认使用的是 soft 限制,并且能够通过 ulimit -n 修改 soft 限制到最大跟 hard 一样,超过 hard 的话会报错:
ulimit: open files: cannot modify limit: Operation not permitted
但普通用户只能不可逆的降低 hard 值,不能将 hard 值提高,只有 root 用户能将 hard 限制提高。目前没有看到修改 hard 值的命令,修改方法应该是只有通过系统调用 setrlimit,具体使用可以用 man 3 看看。
Mac 下修改看上去好麻烦,我没有用过本地机器做过量特别大的压测,所以没有实际做过调整,留下一些线索供以后查阅:
mac - Increase the maximum number of open file descriptors in Snow Leopard? - Super User
https://www.chrissearle.org/2016/10/01/too-many-open-files-on-osx-macos/
file-max, file-nr, nr_open
一般只要注意到 ulimit 里的 soft hard nofile 就好了,但有的时候如果真的用的连接特别特别多,可能会需要调整下面这几个值。这几个值限制的文件 Handle 最大数量都很大,默认为 1024 * 1024,但也能调整的更大:
fs.file-max = 1000000
fs.file-nr = 13920 0 1000000
fs.nr_open = 1048576
file-max 是 kernel 能分配的文件 Handle 最大数量。file-nar 有三个值,动态变化的,第一个值是当前已经分配的文件 Handle 数量,第二个值是分配但是未使用的文件 Handle 数一般都是 0,最后一个实际就是 file-max 的值,表示系统最大分配的文件 Handle 数量。当系统内文件 Handle 数超过 file-max 后,一样会报 Too many open files。
nr_open 是单个进程能分配的最大文件 Handle 数量,这个值一定比 file-max 小,并且一定要比 limits.conf 内的 soft nofile, hard nofile 大,不然 soft nofile, hard nofile 设置再大都没用。
参考:https://www.kernel.org/doc/Documentation/sysctl/fs.txt
自动分配本地端口范围
确定一个连接需要四个元素 Source IP + Source Port + Destination IP + Destination Port,一般客户端在连服务端的时候只要获取到服务端的 Destination IP 和 Destination Port 即可,Source IP 是客户端自己的 IP,客户端系统会自动分配一个 Source Port 来建立连接。而这个 Source Port 的选择范围是可通过 sysctl net.ipv4.ip_local_port_range 参数来定制的。可以执行一下这个命令来获取当前系统的设定,例如:
net.ipv4.ip_local_port_range = 49152 65535
即表示在与 remote 服务建立连接时,系统只能自动从 49152 至 65535 中选择一个作为 Local Port,也就是 Source Port。
如果希望压测客户端和服务器建立大量的连接,则需要将该范围设置的大一些,给客户端留足端口数。如果留的端口不足的话会报错。
为什么这个范围系统不能默认就设置的非常宽呢?比如默认就是 0 ~ 65535 ?
一个是因为 0 ~ 1023 是系统预留的 Well-Known Ports,普通进程就不可使用。另一个是因为当系统作为服务器使用的时候,经常需要开启一些端口比如 MySQL 会默认开启 3306 端口。如果将 net.ipv4.ip_local_port_range 范围设置的很广,比如 2000 ~ 65535 那就可能会出现在 MySQL 启动的时候 3306 端口已经被系统自动分配给了一个进程作为 Source Port 去连接另一个服务,从而导致 MySQL 因为无法绑定 3306 端口而无法启动。所以这个 net.ipv4.ip_local_port_range 需要根据你系统提供的服务情况来酌情进行调整,在写服务端程序时候开启的端口也不是能随便定的,一定要小于系统的 net.ipv4.ip_local_port_range 才行,不然就可能出现系统启动的时候待绑定端口已经被别的连接占用。
报错信息
当因为本地端口范围限制,无法分配出空闲端口时会报错:
Cannot assign requested address
这个错误信息跟端口不足时报的一样。
修改方法
Linux 系统下,执行命令:
sysctl -w net.ipv4.ip_local_port_range="15000 61000"
端口复用
TCP 连接断开之后主动发起 FIN 的一方最终会进入 TIME_WAIT 状态,处在这个状态时连接之前所占用的端口不能被下一个新的连接使用,必须等待一段时间之后才能使用。如果是单独测试并发连接峰值,减少 TIME_WAIT 连接数可能用处不大,但如果是连续的测试,每次关闭客户端准备再来下一轮测试时必须等足 TIME_WAIT 时间,如果 TIME_WAIT 时间比较长就比较烦,所以减少 TIME WAIT 对测试有一定好处。因为一般压测都是内网,所以 TIME WAIT 清理方面能稍微激进一些。TIME WAIT 相关内容可以参看:TCP TIME-WAIT。可以考虑:
- Client 开启 TCP Timestamps 后开启 net.ipv4.tcp_tw_reuse 或 net.ipv4.tcp_tw_recycle;
- 将 net.ipv4.tcp_max_tw_buckets 设置的很小,TIME WAIT 连接超过该值后直接清理。因为一般测试都在内网,没有 NAP 的情况下 Per-Host 的 Timestamp 配合 PAWS 一般能消除跨连接数据包错误到达问题;
- 考虑压测结束的时候由 Client 主动断开连接,并且设置 SO_LINGER 为 0,断开连接时候直接发 RST;
修改方法
sysctl -w net.ipv4.tcp_timestamps=1
sysctl -w net.ipv4.tcp_tw_reuse=1
sysctl -w net.ipv4.tcp_tw_recycle=1
sysctl -w net.ipv4.tcp_max_tw_buckets=10000
TCP Backlog
TCP Backlog 的相关信息可以参考,TCP Backlog。实时通信服务也属于高并发服务,在搞活动、服务重启等时候可能出现大量用户同时和服务器创建连接的情况,所以也需要酌情调整 TCP Backlog 的大小。
修改方法
临时修改执行:
sysctl -w net.core.somaxconn=2048
sysctl -w net.ipv4.tcp_syncookies=1
sysctl -w net.ipv4.tcp_max_syn_backlog=4096
永久性修改需要修改 /etc/sysctl.conf 文件,将上面修改值写在文件中。
TCP Backlog
Linux 上 TCP 握手的时候为每个独立进程维护了两个队列,一个是 Server 在收到 Client 的 SYN 并回复 SYN/ACK 之后,会将连接放入一个 incomplete sockets queue,这个队列的大小受到 net.ipv4.tcp_max_syn_backlog 的限制,超过这个队列长度之后 Server 再收到 SYN 就不会做响应,等 Client 超时之后会重传 SYN 再次尝试建立连接。需要注意的是在 net.ipv4.tcp_syncookies 置位时 net.ipv4.tcp_max_syn_backlog 参数会失效。net.ipv4.tcp_syncookies 的相关信息在下面专门说。
Client 收到 Server 的 SYN/ACK 后会回复 ACK 以确认连接建立,之后 Server 收到 Client 的 ACK 时 TCP 连接完成握手工作。Server 将连接从 incomplete sockets queue 中移出来放入另一个进程相关的等待队列称为 completely established sockets queue,在应用调用 accept 系统调用之后移出。completely established sockets queue 队列大小由应用调用 listen 系统调用时传入的 backlog 值决定。如果应用层调用 accept 不及时,新建立的连接会在 completely established sockets queue 堆积,当 completely established queue 满了之后,如果 net.ipv4.tcp_abort_on_overflow 置位,Server 无法将新创建的连接放入 completely established queue,在收到 Client 在 TCP 握手阶段最后一个 ACK 时会直接给 Client 回复 RST 关闭整条连接;如果 net.ipv4.tcp_abort_on_overflow 为 0 (默认为 0),则队列 completely established queue 满了之后 Server 不做任何事情,直接丢弃 Client 发来的 ACK,连接依然会放在 incomplete socket queue 中。
此时在 Client 看来它并不知道 ACK 被 Server 忽略了所以认为连接已经处在 Established 状态,但是连接实际是 Half-Open 的。需要注意的是 ACK 并没有重传机制,Client 发完 ACK 到 Server 后不会等着这个 ACK 被 Server ACK,而是会直接尝试发送实际数据给服务端。服务端收到数据后会将数据丢弃并重发 SYN/ACK。Client 收到 SYN/ACK 会再次回复 ACK 和重发应用层数据,如果 complete established sockets queue 一直是满的,Server 会一直这么丢弃 Client 的 ACK 并在每次收到 Client 数据时候回复 SYN/ACK 直到回复 SYN/ACK 的次数达到 net.ipv4.tcp_synack_retries 上限,接下来 Server 收到 Client 数据就不回复 SYN/ACK 而是直接回复 RST 重置整个连接。
除了 Client 在发实际数据到 Server 时 Server 会重发 SYN/ACK 之外,如果此时 Server 没有开启 net.ipv4.tcp_syncookies,Server 会有个超时时间超时后会重发 SYN/ACK,开启 SYN Cookies 之后 Server不会有这个超时重发,只有在收到 Client 数据的时候才会重发 SYN/ACK。这个下面会再次提及。
在 completely established sockets queue 满了之后,系统还会减慢接收新 Client 发来 SYN 的速度,也就是说即使 incomplete sockets queue 有空间,当 completely established sockets queue 满了之后,系统在收到 SYN 之后也会开始按一定比率丢弃 SYN 而不是回复 SYN/ACK 并将连接放入 incomplete sockets queue。也就是说 completely established queue 的长度是会影响到 incomplete sockets queue 的。下文会说 completely established sockets queue 的长度主要由应用调用系统调用 listen 时设置的 backlog 和系统的 net.core.somaxconn 参数决定,有人认为 incompletely socket queue 的长度是 backlog、net.core.somaxconn、net.ipv4.tcp_max_syn_backlog 三个参数中的最小值,实际这个倒不一定,completely established sockets queue 长度只是会影响 incomplete sockets queue 长度,但不是说 incomplete sockets queue 最长就是和 completely established sockets queue 一样。
Linux 上 listen 系统调用上有关于 backlog 的说明:
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp_max_syn_backlog. When syncookies are enabled there is no logical maximum length and this setting is ignored. See tcp(7) for more information.
If the backlog argument is greater than the value in /proc/sys/net/core/somaxconn, then it is silently truncated to that value; the default value in this file is 128. In kernels before 2.4.25, this limit was a hard coded value, SOMAXCONN, with the value 128.
需要着重关注第二段,listen 传入的 backlog 值会受到系统参数:net.core.somaxconn 的影响,如果 net.core.somaxconn 设置的小,调用 listen 时传入的 backlog 再大都没有用,都会默认使用系统的 net.core.somaxconn 值。大名鼎鼎的 Netty 默认的 backlog 值就是读取的系统 somaxconn 参数,参看这里。
从上面描述能看出来这个 backlog 值对会在短时间内建立大量连接的服务很重要,如果 backlog 非常小,服务很可能还没来的急执行 accept 呢 backlog 就满了,于是开始丢弃 Client 发来的 ACK,并且在收到 Client 数据包或者 Server 超时时重发 SYN/ACK。因为 Server 收到 Client 数据包后会直接丢弃数据,所以会给网络带来不必要的开销。另外 Server 超时重发 SYN/ACK 的话等待时间会很长,并且重传是 exponential backoff 的,等待时间会越来越长。
不过这两个开销还不是最主要的,网络开销也就是影响一些带宽,Server 的超时一般不存在因为一般会开启 SYN Cookies,最重要的影响是上面说过 completely established sockets queue 满了之后 Server 会按一定比率丢弃 Client 发来的 SYN,Client 不知道发出去的 SYN 被丢弃了,必须等足一个超时时间之后才会再次发送 SYN,一般这个超时时间是 3s,并且是 exponential backoff 的,第二次发 SYN 如果还被 Server 丢弃就要等足 9s 才会再次重发 SYN,这个时间长度就很讨厌了,在用户那里直接感受就是服务好慢,连半天连不上。这篇文章里说的 Backlog 小了之后在有大量并发连接的时候 Client 会出现 3s,9s 的延迟就是因为这个原因。 如果连接已经进入 incomplete sockets queue,Client 只要发数据上来服务端就会立即重传 SYN/ACK,所以不会直接产生延迟。
Backlog 修改方法
如果服务执行能力足够,稍微大一点的 backlog 值是有助于提高系统建立并发连接能力的。但很不幸的是,默认情况下 net.core.somaxconn 的值非常的小,只有 128,在高并发系统下很可能会让 Client 超时,很多人建议是调整到 1024 或者 2048,根据需要和测试情况也有调整到 4096 的。一般建议是将 net.core.somaxconn 设置的稍微大一些,将其作为上限来设置,这样应用可以根据自己需要在执行 listen 的时候将这个值调小。
另外需要说明的是,backlog 最大值是 65535,这个上限是内核规定的但没有文档明确说明。并且 backlog 值并不是越大越好,系统维护的建立连接的两个队列是有资源消耗的,一个是会吃一些内存,一般说是一个 entry 是 64 字节内存;另一个是会消耗 CPU,排在 completely established sockets queue 的连接都是合法的已经完全建立的连接,随时都可能有数据发上来,数据发上来后 Server 就要消耗 CPU 做处理即使这个连接还没被应用层 accept。
除了消耗资源之外,backlog 如果特别大超过应用处理能力,应用要很久才能把 backlog 清空,那这个时间 Client 可能已经超时,甚至认为连接已经失效而执行了 TCP 断开连接的流程,这个时候 Server 处理完 backlog 再想往连接写数据就写不下去了,可能报 Broken pipe。相当于 Server 费半天劲在做无用功,Client 超时后如果还有重试机制会加重 Server 负担恶性循环。
临时修改的话执行:
sysctl -w net.core.somaxconn=2048
sysctl -w net.ipv4.tcp_syncookies=1
sysctl -w net.ipv4.tcp_max_syn_backlog=65535
永久性修改的话需要修改 /etc/sysctl.conf 文件,将上面修改值写在文件中。
怎么看出来服务的 backlog 设置太小了?
netstat -s 是个神器,搞连接参数相关优化的时候这个能提供不少帮助。它实际读的是 /proc/net/netstat 这个文件,里面记录着系统内各种和网络相关的统计信息。跟 backlog 相关的是两条:
167480 times the listen queue of a socket overflowed
258209 SYNs to LISTEN sockets dropped
这两个数据分别对应着内核的 LINUX_MIB_LISTENOVERFLOWS 和 LINUX_MIB_LISTENDROPS 两个统计信息。一个还挺好用的看内核代码的地方是:linux/net/ipv4/tcp_input.c - Elixir - Free Electrons,可以搜索一下看看都是什么地方在更新这两个统计信息。
目前来看 LINUX_MIB_LISTENOVERFLOWS 都是因为 completely established sockets queue 满了丢弃 ACK 数据时会记录。LINUX_MIB_LISTENDROPS 被记录的地方太多了,有太多地方会出现 SYN 被丢弃,比如 SYN 本身格式不对,所以 LINUX_MIB_LISTENDROPS 大多数时候是大于 LINUX_MIB_LISTENOVERFLOWS 的。在网上看到很多人分析应用层 Backlog 问题的时候看的是 LINUX_MIB_LISTENDROPS 这个记录,这个是不对的,得看 LINUX_MIB_LISTENOVERFLOWS 这个。
能确认的跟 backlog 相关,会计入 LINUX_MIB_LISTENDROPS 的是下面这些地方:
- completely established queue 满了导致 SYN 被丢弃时;
- incomplete sockets queue 满了导致 SYN 被丢弃时;
所以当 netstat -s 中 XXX the listen queue of a socket overflowed 值比较大的时候就很有可能是 backlog 不合适,或者至少说明应用层没有来得及处理大量的并发连接而导致这些连接 TCP 握手时的 ACK 被丢弃了。
net.ipv4.tcp_syncookies 是干什么的?
前面说过 incomplete sockets queue 满了之后默认行为是丢弃 Client 发来的 SYN,这就给不法分子提供了一条进行恶意攻击的途径,参看: SYN flood - Wikipedia。
SYN Cookie 就是用来应对 SYN flood 的,net.ipv4.tcp_syncookies 是开启 SYN Cookie 的配置,Linux 系统会默认开启这个配置。SYN Cookie 相关内容参看这里:SYN cookies - Wikipedia、MSS。这个 wiki 里介绍的针对 SYN Cookie 的攻击挺神奇的,可以看看。
基本原理就是 Server 收到 SYN 在构造 SYN/ACK 的时候,会将 Client SYN 内的一些本来应该存在 Server 的 incomplete sockets queue 内的信息编码到 SYN/ACK 的 Sequence Number 里,这样 Server 就能完全废弃 incomplete socket queue 而在 Client 回复 ACK 的时候从 ACK 的 Sequence Number 中恢复 Client 在 SYN 中的信息,从而正常建立连接。SYN flood 时候攻击者一般只是发 SYN 而不会在收到 Server 的 SYN/ACK 的时候回复 ACK,所以 SYN Cookie 机制相当于减少了 Server 为每个收到的 SYN 保留信息的开销,并能区分出攻击者和普通用户,从而能解决 SYN flood 问题。
SYN Cookie 的成本在上面 wiki 页面也有详细描述,主要是 SYN 中会有一些 Option 字段,不能完全编码到 Sequence Number 中,一个比较关键的就是 Maximum segment size - Wikipedia。Sequence Number 中只给 MSS 留了三个 bit 的位置做编码,所以开启 SYN Cookie 之后 Server 支持的 MSS 最多只有 8 个。内核中有个叫做 msstab 的表,记录了系统内在开启 SYN Cookie 之后支持的 MSS 值。有人专门做过研究确定下来几个固定值写在 msstab 中,据说基本能覆盖绝大多数情况,所以一般认为虽然 MSS 选择少了很多但能避免 SYN flood 还是很值得的,所以 SYN Cookie 默认为开启。只有对于 MSS 特别大的网络(因为一般内核默认的 MSS 为了覆盖大多数情况设置的值都比较小,基本都在 1500 以下)开启了 SYN Cookie 之后会导致本来网络能发特别大的数据包但因为 MSS 限制而不能发,因为每个数据包都会有 TCP Header、IP Header 等信息使得网络的 overhead 升高。
在前文中说过,当 completely established sockets queue 满了之后,如果进程来不及执行 accept,收到 Client 的 ACK 后连接不会从 incomplete socket queue 中移除,而是会丢弃 ACK。正常来说 Server 回复的 SYN/ACK 是有超时机制的,在丢弃了 Client 发来的 ACK 之后会等 SYN/ACK 超时再次发送 SYN/ACK 给 Client,但是开启 SYN Cookies 之后,incomplete sockets queue 被完全废弃,Server 在收到Client 的 SYN 并回复 SYN/ACK 之后就把这个 Client 完全忘记了,所以 SYN Cookies 开启后是不会有 Server 的 SYN/ACK 超时的,必须等待 Client 主动发数据到 Server 后 Server 才会重发 SYN/ACK。对于有些应用协议如果期待 TCP 握手之后 Server 先发个数据到 Client 的话,会需要额外的超时机制去让 Client 知道自己发的 ACK 丢失了。
对 MSS 再多记录一些东西吧,TCP 的 Option 格式 在这里有说明,每个 Option 都可能有三个 field,Option-Kind、Option-Length、Option-Data。Option-Kind 就是说这个 Option 是什么 Option,Option-Length 就是这个 Option 总共占了多少字节,Option-Data 就是 Option 的值是什么。拿 MSS 来说,比如抓包得到 TCP Option 如下,Option 全长 20 字节:
0000 02 04 05 84 04 02 08 0a 6b 73 a5 ca 3b 43 02 f7 ........ ks..;C..
0010 01 03 03 07 ....
02 是 Option-Kind 表示 MSS 这个 Option,04 表示 Option-Length 是四字节,也就是说 MSS 这个 Option 就是上面前四个字节 02 04 05 84,整个 Option 是 4 字节,Option-Kind 和 Option-Length 各占一个字节,05 84 就是 Option-Data 在十进制下值为 1412 。
SYN Cookies 相关统计
netstat -s 中有三个东西跟 SYN Cookies 相关:
909660620 SYN cookies sent
867502891 SYN cookies received
635627953 invalid SYN cookies received
从字面意思也能大概理解这三个东西是干什么的。SYN cookies - Wikipedia 这里介绍过一个通过生成随机的 Sequence Number 伪造 Client 的 ACK 从而连上 Server 未开启的端口,但这个攻击会产生大量的 invalid SYN cookies received 所以如果这个值短时间内大量增加有可能是正在遭受攻击。
监控 SYN cookies sent 和 SYN cookies received 值能提前判断是否遭受 SYN flood 攻击,正常来说 Sent 和 Received 是差别不大的,用户收到 SYN/ACK 之后大部分时间都会回应 ACK,而 SYN flood 攻击时攻击者为了不建立连接从而在本机产生消耗所以不会回复 ACK,从而出现服务端在遭受 SYN flood 时,SYN cookies sent 短时间内大量增加但是 SYN cookies received 变化幅度不大的现象。
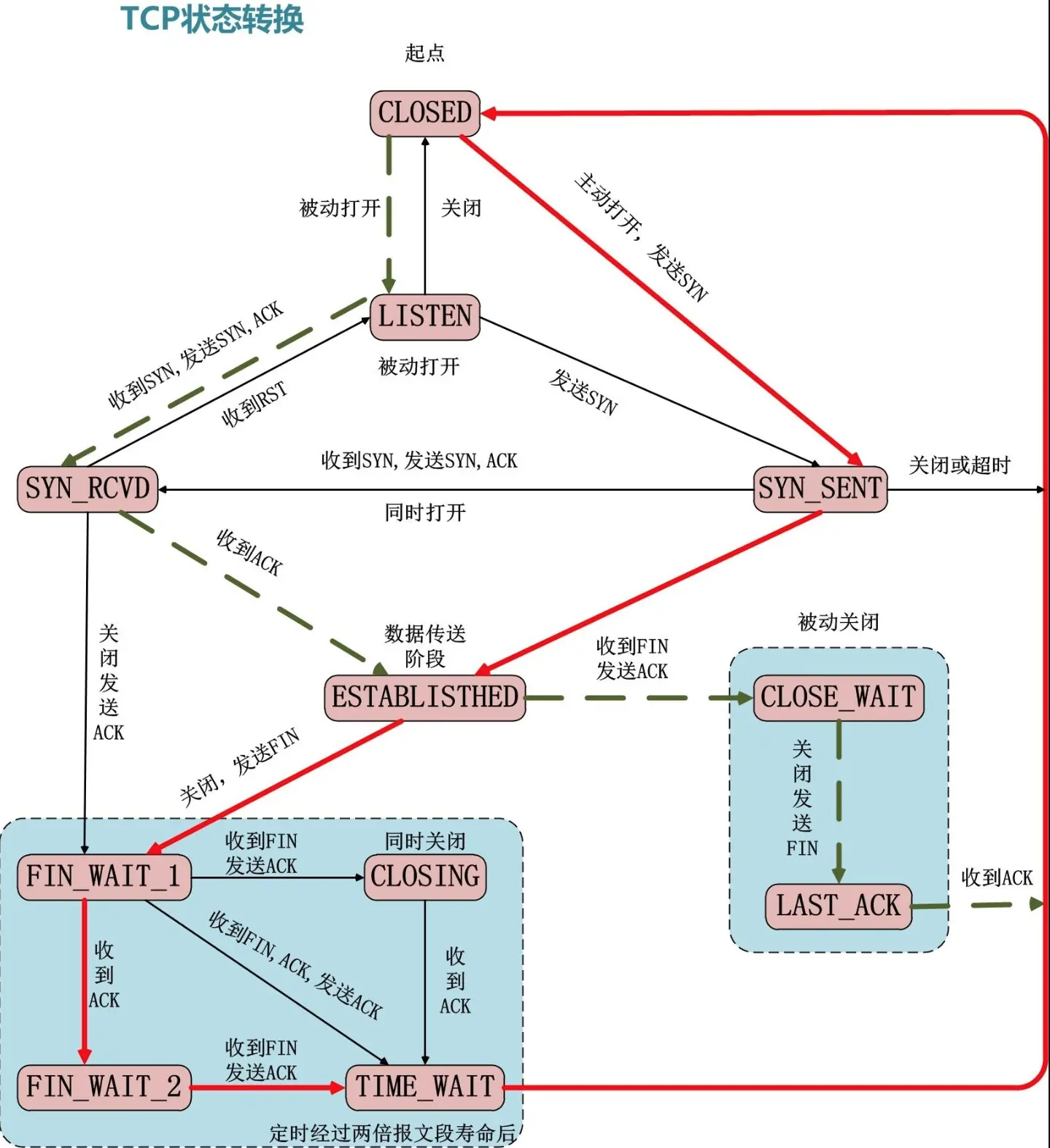
TCP TIME-WAIT
TIME-WAIT 是 TCP 挥手过程的一个状态。很多地方都对它有说明,这里只贴两个图唤起记忆。下面是 TCP 完整的状态图:
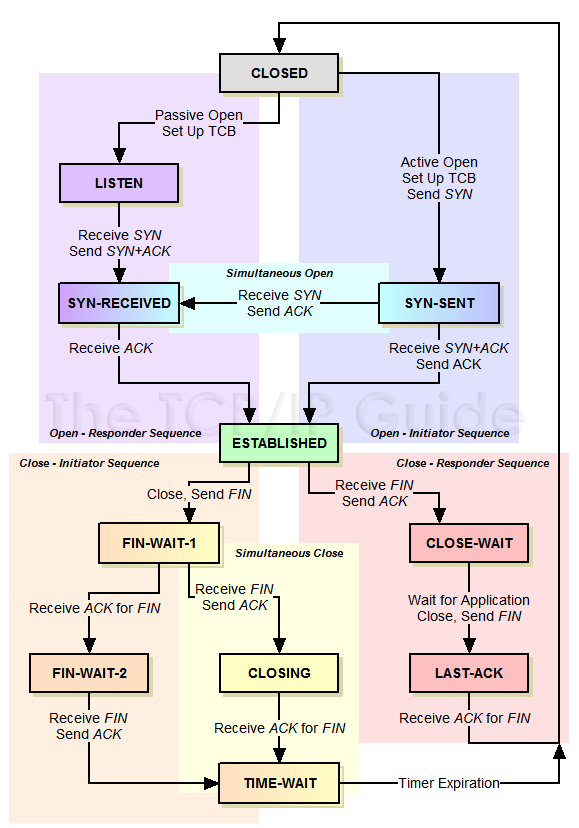
看到最下面有个 TIME-WAIT 状态。状态图可能看着不那么直观,可以看这个:
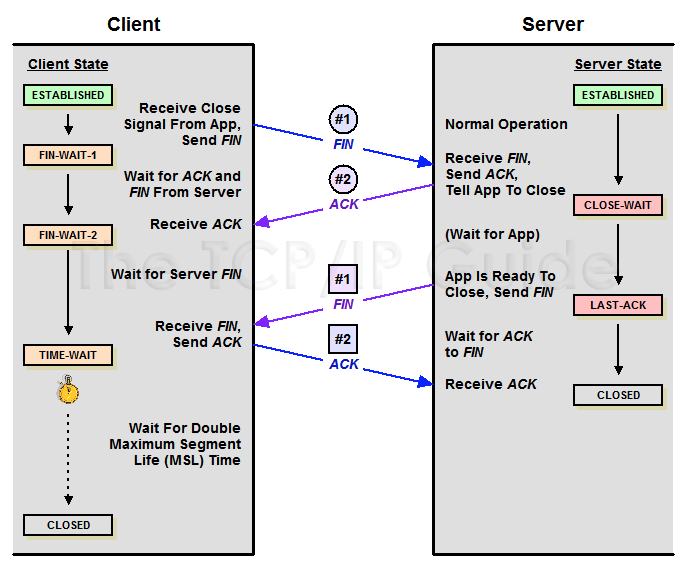
上面实际不一定是只有 Client 才能进入 TIME-WAIT 状态,而是谁发起 TCP 连接断开先发的 FIN,谁最终就进入 TIME-WAIT 状态。
TIME-WAIT 的作用
第一个作用是避免上一个连接延迟到达的数据包被下一个连接错误接收。如下图所示:

虚线将两次连接分开,两次连接都使用的同一组 TCP Tuple,即 Source IP, Source Port, Destination IP, Destination Port 组合。第一次连接中 SEQ 为 3 的数据包出现了重发,第二次连接中刚好再次使用 SEQ 为 3 这个序号的时候,第一次连接中本来发丢(延迟)的 SEQ 为 3 的数据包在此时到达,就导致这个延迟了的 SEQ 为 3 的数据包被当做正确的数据而接收,之后如果还有 SEQ 为 3 的正常数据包到达会被接收方认为是重复数据包而直接丢弃,导致 TCP 连接接收的数据错误。
这种错误可能看上去很难发生,因为必须 TCP Tuple 一致,并且 SEQ 号必须 valid 时才会发生,但在高速网络下发生的可能性会增大(因为 SEQ 号会很快被耗尽而出现折叠重用),所以需要有个 TIME-WAIT 的存在减少上面这种情况的发生,并且 TIME-WAIT 的长度还要长一些, RFC 793 - Transmission Control Protocol 要求 TIME-WAIT 长度要大于两个 MSL (Maximum segment lifetime - Wikipedia) 。MSL 是人为定下的值,就认为数据包在网络路由的时间不会超过这么长。等足两个 MSL 以保证上图第二次连接建立的时候之前发丢的 SEQ 为 3 的数据包已经在网络中丢失,不可能再出现在第二次连接中。
另一个作用是被动断开连接的一方,发出最后一个 FIN 之后进入 LAST ACK 状态。主动断开连接的一方在收到 FIN 之后回复 ACK,如果该 ACK 发丢了,被动断开连接的一方会一直处在 LAST ACK 状态,并在超时之后重发 FIN。主动断开连接的一方如果处在 TIME WAIT 状态,重复收到 FIN 后每次会重发 ACK。但如果 TIME WAIT 时间短,会进入 CLOSED 状态,此时再收到 FIN 就直接回复 RST 了。这个 RST 会导致被动断开连接的一方有个错误提示,虽然所有数据实际已经成功发到对端。
这里有个疑问,如果连接断开后 TIME WAIT 时间很短,TIME WAIT 结束之后主动断开连接一方直接发出 SYN 而被动断开连接一方还处在 LAST ACK 状态,因为 SYN 是其不期待的数据会不会触发其回复 RST 导致主动断开连接一方 connect 失败而放弃建立连接?这篇文章 说如果开启 TCP Timestamp 后处在 LAST ACK 一方会丢弃 SYN 不会回复 RST 而是等到 FIN 超时后重发 FIN,从而让主动断开连接一方回复 RST 后再次发起 SYN 最终能保证连接正常建立。但依据是哪里?在下面介绍 tcp_tw_recycle 的地方会对 Linux 内收到数据包的过程做一下梳理,但从目前来看如果连接处在 LAST ACK,收到 SYN 后如果数据包没有损坏,SEQ 号也符合要求等等各种检查都能通过,则连接什么都不会做,相当于忽略了这个 SYN,也就是说不管 TCP TImestamp 是否开启,处在 LAST ACK 时收到 SYN 都不做任何事情。
TIME WAIT 带来的问题
先引用一个名言:
The TIME_WAIT state is our friend and is there to help us (i.e., to let old duplicate segments expire in the network). Instead of trying to avoid the state, we should understand it.
据说这话的是 W. Richard Stevens 说的。也就是说 TIME WAIT 可能会给我们带来一些问题,但我们还是不要把它当成敌人,当成一个异常状态想方设法的去破坏它的正常工作,而是去利用它,理解它,让它为我们所用。这里要说 TIME WAIT 的问题只是需要我们去理解它的副作用,不是说 TIME WAIT 真的就很邪恶很讨厌。
TIME WAIT 带来的问题主要是三个:
- 端口占用,导致新的连接可能没有可用的端口;
- TIME WAIT 状态的连接依然会占用系统内存;
- 会带来一些 CPU 开销
对于第一个问题可以考虑开启下面说的 tcp_tw_reuse 甚至 tcp_tw_recycle,也能调大 net.ipv4.ip_local_port_range 以获取更多的可用端口,还可以使用多个 IP 或 Server 开启多个 port 的方法来避免没有端口可用的情况。
对于内存上的开销,进入 TIME WAIT 后应用层实际已经将连接相关信息销毁了,只是在 kernel 还维护有连接相关信息,所以内存占用只发生在 kernel 内。正常状态下的 Socket 结构比较复杂,可以看看这里 struct tcp_sock,它里面使用的是struct inet_connection_sock。Linux 为了减少 TIME WAIT 连接的开销,专门构造了更精简的 Socket 数据结构给进入 TIME WAIT 状态的连接用,参看这里 struct tcp_timewait_sock ,它里面用的是inet_timewait_sock。可以看到 TIME WAIT 状态下连接的结构要比正常连接数据结构简单不少,在内核的数据结构最多百来字节,即使有 65535 个 TIME WAIT 的连接存在也占不了多少内存,几十 M 最多了。
对于 CPU 的开销一般也不大,主要是在建立连接时在 inet_csk_get_port 函数内查找一个可用端口上的开销。
所以 TIME WAIT 带来的最主要的副作用就是会占用端口,而端口数量有限,可能导致无法创建新连接的情况。
减少 TIME WAIT 占用端口的方法
SO_LINGER
对于应用层来说调用 send() 后数据并没有实际写入网络,而是先放到一个 buffer 当中,之后慢慢的往网络上写。所以会出现应用层想要关闭一个连接时,连接的 buffer 内还有数据没写出去,需要等待这部分数据写出。调用 close() 后等待 buffer 内数据全部写出去的时间叫做 Linger Time。Linger Time 结束后开始正常的 TCP 挥手过程。
从前面介绍能看到,正常的主动断开连接一定会进入 TIME WAIT 状态,但除了正常的连接关闭之外还有非正常的断开连接的方法,可以不让连接进入 TIME WAIT 状态。方法就是给 Socket 配置 SO_LIGNER,这样在调用 close() 关闭连接的时候主动断开连接一方不是等待 buffer 内数据发完之后再发送 FIN 而是根据 SO_LINGER 参数配置的超时时间,等到最多这个超时时间这么长后,如果连接 buffer 内还有数据就直接发送 RST 强制重置连接,对方会收到 Connection Reset by peer 的错误,同时会导致主动断开连接一方所有还未来得及发送的数据全部丢弃。如果还未到 SO_LINGER 配置的超时时间连接 buffer 内的数据就全部发完了,就还是发 FIN 走正常挥手逻辑,但这样主动断开连接一方还是会进入 TIME WAIT。所以如果主动断开连接时完全不想让连接进入 TIME WAIT 状态,可以直接将 SO_LINGER 设置为 0 ,这样调用 close() 后会直接发 RST,丢弃 buffer 内所有数据,并让连接直接进入 CLOSED 状态。
从上面描述也能看出来其应用场景可能会比较狭窄。看到有地方建议是说收到错误数据,或者连接超时的时候通过这种方式直接重置连接,避免有问题的连接还进入 TIME WAIT 状态。
tcp_tw_reuse、 tcp_tw_recycle 配置和 TCP Timestamp
为了介绍这两个配置,首先需要介绍一下 TCP Timestamp 机制。
RFC 1323 和 RFC 7323 提出过一个优化,在 TCP option 中带上两个 timestamp 值:
TCP Timestamps option (TSopt):
Kind: 8
Length: 10 bytes
+-------+-------+---------------------+---------------------+
|Kind=8 | 10 | TS Value (TSval) |TS Echo Reply (TSecr)|
+-------+-------+---------------------+---------------------+
1 1 4 4
TCP 握手时,通信双方如果都带有 TCP Timestamp 则表示双方都支持 TCP Timestamp 机制,之后每个 TCP 包都需要将自己当前机器时间带在 TSval 中,并且在每次收到对方 TCP 包做 ACK 回复的时候将对方的 TSval 作为 ACK 中 TSecr 字段返回给对方。这样通信双方就能在收到 ACK 的时候读取 TSecr 值并根据当前自己机器时间计算 TCP Round Trip Time,从而根据网络状况动态调整 TCP 超时时间,以提高 TCP 性能。请注意这个 option 虽然叫做 Timestamp 但不是真实日期时间,而是一般跟操作系统运行时间相关的一个持续递增的值。更进一步信息请看 RFC 的链接。
除了对 TCP Round Trip 时间做测量外,这个 timestamp 还有个功能就是避免重复收到数据包影响正常的 TCP 连接,这个功能叫做 PAWS,在上面 RFC 中也有介绍。
PAWS (Protection Against Wrapped Sequences)
从 PAWS 的全名上大概能猜想出来它是干什么的。正常来说每个 TCP 包都会有自己唯一的 SEQ,出现 TCP 数据包重传的时候会复用 SEQ 号,这样接收方能通过 SEQ 号来判断数据包的唯一性,也能在重复收到某个数据包的时候判断数据是不是重传的。但是 TCP 这个 SEQ 号是有限的,一共 32 bit,SEQ 开始是递增,溢出之后从 0 开始再次依次递增。所以当 SEQ 号出现溢出后单纯通过 SEQ 号无法标识数据包的唯一性,某个数据包延迟或因重发而延迟时可能导致连接传递的数据被破坏,比如:
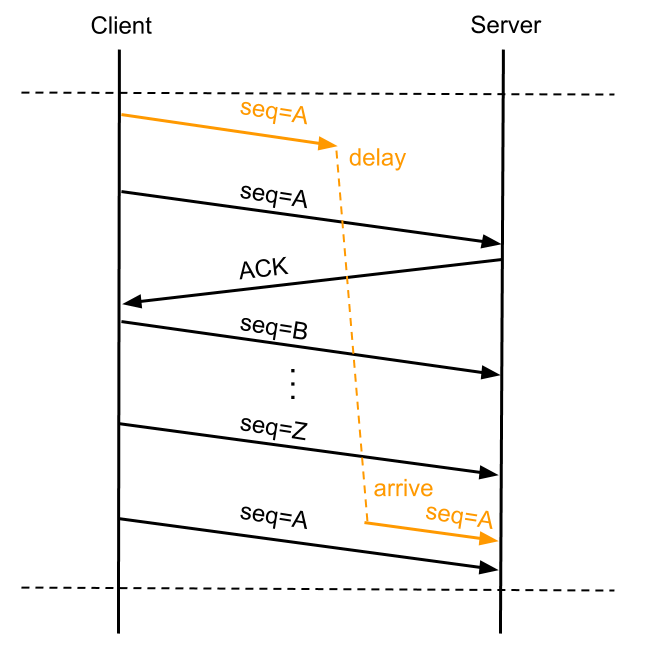
上图 A 数据包出现了重传,并在 SEQ 号耗尽再次从 A 递增时,第一次发的 A 数据包延迟到达了 Server,这种情况下如果没有别的机制来保证,Server 会认为延迟到达的 A 数据包是正确的而接收,反而是将正常的第三次发的 SEQ 为 A 的数据包丢弃,造成数据传输错误。PAWS 就是为了避免这个问题而产生的。在开启 Timestamp 机制情况下,一台机器发的所有 TCP 包的 TSval 都是单调递增的,PAWS 要求连接双方维护最近一次收到的数据包的 TSval 值,每收到一个新数据包都会读取数据包中的 TSval 值跟 Recent TSval 值做比较,如果发现收到的数据包 TSval 没有递增,则直接丢弃这个数据包。对于上面图中的例子有了 PAWS 机制就能做到在收到 Delay 到达的 A 号数据包时,识别出它是个过期的数据包而将其丢掉。tcp_peer_is_proven 是 Linux 一个做 PAWS 检查的函数。
TCP Timestamp 就像是 SEQ 号的扩展一样,用以在 SEQ 号相同时候判断两个数据包是否相同以及他们的先后关系。TCP Timestamp 时间跟系统运行时间相关,但并不完全对应,也不需要 TCP 通信双方时间一致。Timestamp 的起跳粒度可以由系统实现决定,粒度不能太粗也不能太细。粒度最粗至少要保证 SEQ 耗尽的时候 Timestamp 跳了一次,从而在 SEQ 号重复的时候能通过 Timestamp 将数据包区分开。Timestamp 跳的粒度越细,能支持的最大发送速度越高。TCP SEQ 是 32 bit,全部耗尽需要发送 232 字节的数据(RFC 7323 说是 231 字节数据,我还没弄明白为什么不是 232),如果 Timestamp 一分钟跳一次,那支持的最高发送速度是一分钟发完 232 字节数据;如果 Timestamp 一秒钟跳一次,那支持的最高发送速度是一秒钟发完 2^32 字节数据。另外,Timestamp 因为担负着测量 RTT 的职责,过粗的粒度也会降低探测精度,不能达到效果。
但是 Timestamp 本身也是有限的,一共 32 bit,Timestamp 跳的粒度越细,跳的越快,被耗尽的速度也越快。越短时间被耗尽越会出现和只靠 SEQ 来判断数据包唯一性相同的问题场景,即收到一个延迟到达的数据包后无法确认它是正常数据包还是延迟数据包。所以一般推荐 Timestamp 是 1ms 或 1s 一跳。假若是 1ms 一跳的话能支持最高 8 Tbps 的传输速度,也能在长达 24.8 天才会被耗尽。只要 MSL (Maximum segment lifetime - Wikipedia) 小于 24.8 天,通过 TCP Timestamp 机制就能拒绝同一个连接上 SEQ 相同的重复数据包。MSL 大于 24.8 天几乎不可能,一个延迟的数据包在 24.8 天后到达接收方,该数据包的 SEQ 、Timestamp 又恰好和一个正常数据包相同,这个概率非常的小。MSL 相关可以参看RFC 793 。
TCP Timestamp 机制开启之后 PAWS 会自动开启,控制 TCP Timestamp 的配置为 net.ipv4.tcp_timestamps 一般现在 Linux 系统都是开启的。因为能提升 TCP 连接性能,付出的代价相对又少。该配置看着叫 ipv4 但对 ipv6 一样有效。
Linux 上有几个跟 PAWS 相关的统计信息:
LINUX_MIB_PAWSPASSIVEREJECTED, /* PAWSPassiveRejected */
LINUX_MIB_PAWSACTIVEREJECTED, /* PAWSActiveRejected */
LINUX_MIB_PAWSESTABREJECTED, /* PAWSEstabRejected */
PAWS passive rejected 是 tcp_tw_recycle 开启后,收到 Client 的 SYN 时,因为 SYN 内的 Timestamp 没有通过 PAWS 检测而被拒绝的 SYN 数据包数量。这个稍后再说。
PAWS active rejected 是 Client 发出 SYN 后,收到 Server 的 SYN/ACK 但 SYN/ACK 中的 Timestamp 没有通过 PAWS 检测而被拒绝的 SYN/ACK 数据包数量。
PAWS established rejected 是正常建立连接后,因为数据包没有通过 PAWS 检测而被拒绝的数据包数量。
这三个定义在一起的,在uapi/linux/snmp.h 下,下面会再次介绍这些计数是什么场景下被记录的。
目前来看 netstat -s 中只展示了 PAWS established rejected 的值,另外两个没展示,需要到 /proc/net/netstat 中看:
358306 packets rejects in established connections because of timestamp
net.ipv4.tcp_tw_reuse
需要注意的是这里说的 net.ipv4.tcp_tw_reuse 和下面说的 net.ipv4.tcp_tw_recycle 都是虽然名字里有 ipv4 但对 ipv6 同样生效。
只有开启了 PAWS 机制之后开启 net.ipv4.tcp_tw_reuse 才有用,并且仅对 outgoing 的连接有效,即仅对 Client 有效。Linux 中使用到 tcp_tw_reuse 的地方是 tcp_twsk_unique 函数。它是在 __inet_check_established 内被使用,其作用是在 Client 连 Server 的时候如果已经没有端口可以使用,并且在 Client 端找到个处在 Time Wait 状态的和 Server 的连接,只要当前时间和该连接最后一次收到数据的时间差值超过 1s,就能立即复用该连接,不用等待连接 Time Wait 结束。
前面说过 Time Wait 有两个作用,一个是避免同一个 TCP Tuple 上前一个连接的数据包错误的被后一个连接接收。因为有了 PAWS 机制,TCP 收到的数据会检查 TSval 是否大于最近一次收到数据的 TSval,所以这种情况不会发生。旧连接的数据包到达接收方后因为 PAWS 检测不通过会直接被丢弃,并更新 LINUX_MIB_PAWSESTABREJECTED 计数。
另一个作用是避免主动断开连接一方最后一个回复的 ACK 丢失而被动断开连接一方一直处在 LAST ACK 状态,超时后会再次发 FIN 到主动断开连接一方。此时如果主动断开连接一方不在 Time Wait 会触发主动断开连接一方发出 RST 让被动连接一方出现一个 Connection reset by peer 的报错。不过这个实际上还好,数据至少都发完了。如果被动断开连接一方还未因超时而重发 FIN 就收到主动断开连接一方因为 tcp_tw_reuse 提前从 TIME WAIT 状态退出而发出的 SYN,被动连接一方会立即重发 FIN,主动连接一方收到 FIN 后回复 RST,之后再重发 SYN 开始正常的 TCP 握手。后一个过程图如下:
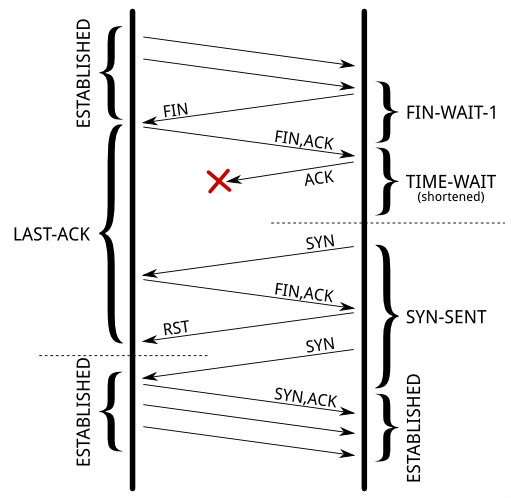
这篇文章 说没有开启 TCP Timestamp 时,被动断开连接一方处在 LAST_ACK 状态,收到 SYN 后会回复 RST;开启了 TCP Timestamp 之后,被动连接一方处在 LAST_ACK 状态收到 SYN 会丢弃这个 SYN,在 FIN 超时后再次发 FIN, ACK,这里我有些疑惑。不明白为什么 TCP Timestamp 开启之后处在 LAST ACK 状态的一方就会默认丢弃对方发来的 SYN。PAWS 只有 Timestamp 不和要求时才会丢消息,但同一台机器上没有重启的话 TSval 是逐步递增的,SEQ 号也是在原来 TIME WAIT 时存下的 SEQ 号基础上加一个偏移值得到,按说没有理由会自动丢弃 SYN 的。
还一个要注意到的是 tcp_tw_reuse 在 reuse 连接的时候新创建的连接会复用之前连接保存的最近一次收到数据的 Timestamp。这个是与下面要说的 tcp_tw_recycle 的不同点,也是为什么 tcp_tw_reuse 在使用了 NAT 的网络下是安全的,而 tcp_tw_recycle 在使用了 NAT 的网络下是不安全的。因为 tcp_tw_reuse 记录的最近一次收到数据的 Timestamp 是针对 Per-Connection 的,而 tcp_tw_recycle 记录的最近一次收到数据的 Timestamp 是 Per-Host 的,在 NAT 存在的情况下同一个 Host 后面有多少机器就说不清了,每台机器时间不同发出数据包的 TSval 也不同,PAWS 可能错误的将正常的数据包丢弃所以会导致问题,这个在下面描述 tcp_tw_recycle 的时候再继续说。
从上面描述来看 tcp_tw_reuse 还是比较安全的,一般是建议开启。不过该配置对 Server 没有用,因为只有 outgoing 的连接才会使用。每次 reuse 一个连接后会将 TWRecycled 计数加一,通过 netstat -s 能看到:
7212 time wait sockets recycled by time stamp
虽然叫做 TWRecycled 但实际它指的是 reuse 的连接数,不是下面要说的 recycled 的连接数。其反应的是 LINUX_MIB_TIMEWAITRECYCLED 这个计数,在__inet_check_established 内 reuse TIME WAIT 连接后计数
net.ipv4.tcp_tw_recycle
该配置也是要基于 TCP Timestamp,单独开启 tcp_tw_recycle 没有效果。相对 tcp_tw_reuse 来说 tcp_tw_recycle 是个更激进的参数,这个参数在 Linux 的使用参看:
linux/net/ipv4/tcp_input.c - Elixir - Free Electrons
linux/net/ipv4/tcp_minisocks.c - Elixir - Free Electrons
linux/net/ipv4/tcp_ipv4.c - Elixir - Free Electrons
理一下 TCP 收消息过程
为了说清楚 tw_recycle 的使用场景,我准备把接收消息过程理一遍,可能会写的比较啰嗦,看的时候需要静下心来慢慢看。
首先链路层收到 TCP IPv4 的数据后会走到 tcp_v4_rcv 这里,看到参数是 struct sk_buff,以后有机会记录一下,NIC 从链路接收到数据写入 Ring Buffer 后就会构造这个 struct sk_buff,并且之后在数据包的处理过程中一直复用同一个 sk_buff,避免内存拷贝。
tcp_v4_rct 首先是进行各种数据包的校验,根据数据包的 source,dst 信息找到 Socket,是个struct sock 结构。我们这里主要说 TIME WAIT,所以别的东西都先不管。主要是看到下面会调用 tcp_v4_do_rcv。在 tcp_v4_do_rcv 内会开始真的处理 sk_buff 数据内容,如果连接不是 ESTABLSHED,也不是 LISTEN 会走到 tcp_rcv_state_process函数,这个函数是专门处理 TCP 连接各种状态转换的。还是那句话,我们关心的是 TIME WAIT,所以别的也都不看,先看连接的状态转换。我们知道连接先是在 FIN-WAIT-1,收到对方 ACK 后进入 FIN-WAIT-2,再收到对方 FIN 后进入 TIME-WAIT。在 tcp_rcv_state_process 先找到 FIN-WAIT-1 这个 case,这里先会检查 acceptable 是否置位,表示收到的 sk_buff 内 ACK flag 是置位的,如果没有置位会立即返回 1 表示状态有误,之后会发 RST。即在 FIN-WAIT-1 状态下,连接期待的数据必须设置 ACK Flag,没设置就立即发 RST 重置连接。
如果一切正常,则将连接状态设置为 FIN-WAIT-2,并读取 sysctl 的 net.ipv4.tcp_fin_timeout 配置。如果 sk_buff 中没有同时设置 FIN 说明对方是先回复了 ACK,让当前连接线进入 FIN-WAIT-2,FIN 在之后的包中发过来。所以此时设置连接状态并 discard 当前 sk_buff。这里有些疑问,此时连接实际是 Half-Open 的,这里没有判断 ACK 内有没有别的数据就把 sk_buff 丢弃了,从 RFC 793 中似乎没看到说要求针对 FIN 的 ACK 内必须不能有数据。接着说,看到用 tcp_time_wait 函数将 tw_substate 设置到 FIN-WAIT-2 ,将连接设置为 TIME WAIT,并设置超时时间是 net.ipv4.tcp_fin_timeout 的值。稍后再继续说 tcp_time_wait 这个函数,还有很多可以挖掘的。
如果 sk_buff 同时设置了 FIN,说明对方是将 FIN 和 ACK 一起发来的,同一个数据包中 FIN 和 ACK 两个 Flag 都置位,此时并不立即设置 TCP 连接的状态,而是在稍后在专门处理 FIN 的逻辑中处理 TCP 状态变换。如果 FIN 和 ACK 一起设置了,不会 discard 数据包,再往下还有个 case,要注意到有个 switch 的 Fall through,也就是说连接不管在 CLOSE_WAIT, CLOSING, FIN_WAIT1, FIN_WAIT2, ESTALISHED 等最终都会进入 tcp_data_queue 来继续处理这个收到的 sk_buff。在 tcp_data_queue 中我们看到带着 FIN 的 sk_buff 会交给专门的 tcp_fin 来处理。因为在 tcp_rcv_state_process 内我们刚刚将连接状态设置为 TCP_FIN_WAIT2 所以在 tcp_fin 的 switch 内我们找到 TCP_FIN_WAIT2 的处理逻辑,即回复 ACK 并通过 tcp_time_wait 函数设置 tw_substate 为 TCP_TIME_WAIT ,将连接设置为 TIME WAIT 状态,并设置超时时间是 0。
接下来我们看看 tcp_time_wait 函数 ,这个函数完成了将连接转换到 TIME WAIT 状态的逻辑。如果 tw_recycle 、TCP Timestamp 开启,会先 Per-Host 的缓存连接最后一次收到数据的对方 TSval。将连接从普通的 struct sock 转换为 TIME WAIT 状态下连接特有的更加精简的 struct tcp_timewait_sock 结构。并 设置连接处在 TIME WAIT 的超时时间,能看到 tw_recycle 开启的话 tw_timeout 只有一个 RTO 这么长,能大幅度减少连接处在 TIME WAIT 的时间。而没有开启 tw_recycle 的话超时时间是 TIME_WAIT_LEN,该值是个不可配置的 macro。TIME WAIT 超时后会执行 tw_timer_handler将连接清理。tw_timer_handler 是在构造 inet_timewait_sock 执行 inet_twsk_alloc 将一个 TIME WAIT 的 socket 和 tw_timer_handler 关联起来的。
正常的连接使用的是 struct tcp_sock 内部第一个结构是 struct sock,TIME WAIT 的连接使用的是 struct tcp_timewait_sock 内部第一个结构是 struct inet_timewait_sock。struct sock 和 struct inet_timewait_sock 内部第一个结构都是 struct sock_common。struct sock_common 是连接相关最核心的信息,标识一个连接必须要有这个。而为了减少 TIME WAIT 连接对内存空间的占用,所以弄了精简的 struct tcp_timewait_sock 可以看到它相对 strcut tcp_sock 内容要少的多,并且内部 struct inet_timewait_sock 相对于 struct sock 来说内容也少了很多,整个结构很精简。看到 struct sock 和 struct inet_time_wait_sock 第一个结构都是 struct sock_common 所以如果是访问 struct sock_common 的内容,指向这两个 struct 的指针是能够相互转换的。这两个 struct 内部定义了很多宏,用于方便的访问 struct sock_common 的内容。比如 struct sock 内的 sk_state 和 struct inet_timewait_sock 内的 tw_state 实际都访问的是 struct sock_common 的 skc_common。
说 struct socket 等结构主要是为了说明 tcp_time_wait 内是如何将 socket 状态设置为 TIME WAIT的。一般设置 socket 状态使用的是 tcp_set_state 这个函数,比如在 tcp_rcv_state_process 内之前看到的。但 TIME WAIT 这个状态却不是 tcp_set_state 来设置的,而是在从 struct socket 构造 struct inet_timewait_sock 时设置的,构造 struct inet_timewait_sock 会默认设置 tw_state 为 TCP_TIME_WAIT。 从前面描述来看,连接在 FIN-WAIT-1 状态时收到 ACK 且 FIN 置位时,会在回复 ACK 后执行 tcp_time_wait,此时连接确实应该进入 TIME WAIT 状态;但在收到 ACK 且 FIN 没有置位的时候,连接实际处在 FIN-WAIT-2 状态却也会执行 tcp_time_wait。tcp_time_wait 内会将连接状态默认的设置为 TCP_TIME_WAIT,这没有实际反映出当前连接的实际状态,所以 struct inet_timewait_sock 内还有个 tw_substate 用以记录这个连接的实际状态。如果连接实际处在 FIN-WAIT-2,收到对方 FIN 后在 tcp_v4_rcv 内根据 sk_buff 找到 Socket,此时的 Socket 虽然使用的是 struct sock 指针,但实际指的是个 struct inet_timewait_sock,访问其 sk_state 实际访问的是 struct sock_common 的 sk_state 字段,也即 struct inet_timewait_sock 的 tw_state 字段。所以读到的当前状态是 TCP_TIME_WAIT。于是进入 tcp_timewait_state_process 函数处理数据包。当连接的 sk_state 处在 TCP_TIME_WAIT 时,所有收到的数据包均交给 tcp_timewait_state_process 处理。在 tcp_timewait_state_process 内可以看到会检查 tw_substate 是不是 TCP_FIN_WAIT2,是的话会将 tw_substate 也设置为 TCP_TIME_WAIT,并会重新设置 TIME WAIT 的 timeout 时间。设置的逻辑跟连接在 FIN-WAIT-1 下收到 ACK 且 FIN 置位时一样,会判断 tw_recycle 是否开启,开启的话 timeout 就是一个 RTO,不是的话就是 TIME_WAIT_LEN。
从上面这么一大段的描述中我们得到这么一些信息:
- 连接在进入 FIN-WAIT-2 后内核维护的 socket 就会改为和 TIME WAIT 状态时一样的精简结构,以减少内存占用
- 连接进入 FIN-WAIT-2 后为了避免对方不给回复 FIN,所以会设置 net.ipv4.tcp_fin_timeout 这么长的超时时间,超时后会按照清理 TIME WAIT 连接的逻辑清理 FIN-WAIT-2 连接
- tcp_tw_recycle 开启后,timeout 只有一个 RTO 这个正常来说是会大大低于 TCP_TIMEWAIT_LEN 的。 这里就说明 tcp_tw_recycle 是对 outgoing 和 incoming 的连接都会产生效果,不管连接是谁先发起创建的,只要是开启 tcp_tw_recycle 的机器先断开连接,其就会进入 TIME WAIT 状态(或 FIN-WAIT-2),并且会受到 tcp_tw_recycle 的影响,大幅度缩短 TIME WAIT 的时间。
tcp_tw_recycle 为什么是不安全的
跟 tcp_tw_reuse 一样,由于 PAWS 机制的存在,缩短 TIME WAIT 后同一个 TCP Tuple 上前一个连接的数据包不会被后一个连接错误的接收。TIME WAIT 另一个要处理的 LAST ACK 的问题跟 tcp_tw_reuse 也一样,不会产生很大的问题,新的连接依然能正常建立,旧连接的数据也能保证都发到对方,只是旧连接上可能会产生一个 Connection reset by peer 的错误。那 tcp_tw_recycle 是不是就是安全的呢?为什么那么多人都不推荐开启这个机制呢?
原因是前面说过 tcp_tw_reuse 新建立的连接会复用前一次连接保存的 Recent TSval 即最后一次收到数据的 Timestamp 值,这个值是 Per-Connection 的,即使有 NAT 的存在,也不会产生问题。比如当前机器是 A 要和 B C D 三台机器建立连接,假设 B C D 三台机器都在 NAT 之后,对 A 来说 B C D 使用的是相同的 IP 或者称为 Host。B C D 三台机器因为启动时间不同,A 与他们建立连接之后他们发来的 TSval 都不相同,有前有后。因为 A 是以 Per-Connection 的保存 TSval ,不会出现比如因为 C 机器时间比 B 晚,A 收到 B 的一条消息之后再收到 C 的消息而丢弃 C 的数据的情况。因为在 A 上为 B C D 三台机器分别保存了 Recent TSval,他们之间不会混淆。
但是对于 tcp_tw_recycle 来说,TIME WAIT 之后连接信息快速的被回收,Per-Connection 保存的 TSval 记录就被清除了,取而代之的是另一个 Per-Host 的 TSval cache,在这里能看到在 tcp_time_wait当 tcp_tw_recycle 和 TCP Timestamp 都开启后,连接进入 TIME WAIT 之前会将 socket 的 Timestamp 存下来,并且存储方法是 Per-Host 的。这样在 NAT 存在的场景下就有问题了,还是上面的例子,B C D 在同一个 NAT 之后,具有相同的 Host,B 先跟 A 建立连接,此时 Per-Host cache 更新为 B 的机器时间,之后 C 来跟 A 建立连接(接收 incoming 连接请求相关逻辑可以看tcp_conn_request 这个函数),读取 Per-Host Cache 后发现 C 的 SYN 中 TSval 比 Cache 的 TSval 时间要早,于是直接默默丢弃 C 的 SYN。这种情况会更新 LINUX_MIB_PAWSPASSIVEREJECTED 从而在 /proc/net/netstat 下的 PAWSPassive 看这个计数。在网上看到好些地方说到这个问题的时候都说会更新 PAWSEstab 计数,这是不对的。
除了上面场景中 A 会丢弃 C 的 SYN 之外,还有别的引起问题的场景。比如 A 跟 B 建立了连接,Per-Host TSval 更新为 B 的时间,之后又要去跟 C 建立连接( IPv4 下创建 outgoing 连接相关逻辑可以看 tcp_v4_connect 函数),A 发出 SYN 时会更新该连接的 Recent TSval 为缓存的 Per-Host TSval 时间,即 B 的时间。假设 A 这一侧网络环境比较简单,IP 只有 A 一台机器在用,于是 C 校验 A 的 SYN 通过,所以 C 会正常回复 SYN//ACK 给 A,但 SYN//ACK 到达 A 之后,因为 SYN//ACK 带着 C 的 TSval,其时间晚于 B 的时间,导致 A 直接丢弃 C 发来的 SYN/ACK,并更新 LINUX_MIB_PAWSACTIVEREJECTED 计数,该计数能在 /proc/net/netstat 下的 PAWSActive 看到。
所以,tcp_tw_recycle 是不推荐开启的,因为 NAT 在网络上大量的存在,配合 tcp_tw_recycle 会出现问题。
如果有连接由于 tcp_tw_recycle 开启而被清理的话,会更新 /proc/net/netstat的 TWKilled 计数,在 Linux 内是 LINUX_MIB_TIMEWAITKILLED,请注意和 TCPRecycled 区分。这个计数在 tw_timer_handler 中当 tw->tw_kill 有值的时候会更新,而 tw_kill 是在连接进入 TIME WAIT,schedule 清理连接任务时候被设置的,在 __inet_twsk_schedule。
跟 TIME WAIT 相关的还有一个计数叫做 TW,在 Linux 内部叫做 LINUX_MIB_TIMEWAITED。它也是在 tw_timer_handler 中被更新,可以看到只要不是 tw_kill 都会当做普通的 TW 被计数,我理解只要是正常 TIME WAIT 结束的都会计入这里,被 recycle 的会计入 TWKilled,被 reuse 的会计入 TWRecycled。但 netstat -s 对应 TW 的描述是:
69598943 TCP sockets finished time wait in fast timer
不明白这里 fast timer 是什么意思。
net.ipv4.tcp_max_tw_buckets 是什么
用于限制系统内处在 TIME WAIT 的最大连接数量,当 TIME WAIT 的连接超过限制之后连接会直接被关闭进入 CLOSED 状态,并会打印日志:
TCP time wait bucket table overflow
可以看出这个限制有些暴力,得尽量去避免。还是之前的话,TIME WAIT 是有自己的作用的,暴力干掉它对我们并没有好处。
tcp_max_tw_buckets 这个限制主要是控制 TIME WAIT 连接占用的资源数,包括内存、CPU 和端口资源。避免 denial-of-service 攻击。比如端口全部被占用处在 TIME WAIT 状态,可能会出现没有多余的端口来建立新的连接。
SO_REUSEADDR 是什么, SO_REUSEPORT 是什么
看完上面内容之后可能会和我一样产生这个疑问,因为这两个从名字上看上去跟 tcp_tw_reuse 很像。
关于 SO_REUSEADDR 和 SO_REUSEPORT 这篇文章介绍的特别好,强烈建议一看。唯一是里面关于 TIME WAIT 内容个人认为是不正确的,想先说明一下,避免以后自己再看这个文章的时候搞混淆。他说:
That's why a socket that still has data to send will go into a state called TIME_WAIT when you close it. In that state it will wait until all pending data has been successfully sent or until a timeout is hit, in which case the socket is closed forcefully.
实际上连接进入 TIME WAIT 之后是不可能再有数据发出的,因为能进入 TIME WAIT 一定是已经收到了对方的 FIN,此时对方期待的只有 ACK,发应用层数据会引起对方回复 RST。
还有这里:
The amount of time the kernel will wait before it closes the socket, regardless if it still has pending send data or not, is called the Linger Time. The Linger Time is globally configurable on most systems and by default rather long (two minutes is a common value you will find on many systems). It is also configurable per socket using the socket option SO_LINGER which can be used to make the timeout shorter or longer, and even to disable it completely.
关于 Linger Time 的描述跟 TIME WAIT 混淆了,Linger Time 并不是全局配置的,最长也不是 2 分钟,这个都是 TIME WAIT 的长度。Linger TIme 确实也有默认长度,但是个非常大的值,参看这里。所以基本能认为不设置 SO_LINGER 的话,close() 调用后会一直等到 buffer 内数据发完才会开始断开连接流程。
但是瑕不掩瑜,这篇文章把 SO_REUSEADDR 和 SO_REUSEPORT 讲的很清楚。
上面介绍过的 tcp_tw_reuse 和 tcp_tw_recycle 都是内核级参数,使用之后会在整个系统产生作用,所有创建的连接都受到影响。SO_REUSEADDR 和 SO_REUSEPORT 都是单个连接级的参数,使用后只能对单个连接产生影响,不是整个系统级别的。
SO_REUSEADDR
有两个作用:
一个是 bind() socket 时可以绑定 “any address” IPv4 下是 0.0.0.0 或在 IPv6 下是::。SO_REUSEADDR 不开启的话,这个 any address 会和机器具体使用的 IP 冲突,如果绑定的端口一致会报错。比如本地有两个网卡,IP 分别是 192.168.0.1 和 10.0.0.1。如果不开启 SO_REUSEADDR,绑定 0.0.0.0 的某个端口比如 21 之后,再想绑定某个具体的 IP 192.168.0.1 的 21 端口就不允许了。而开启 SO_REUSEADDR 之后除非是 IP 和 Port 都被绑定过才会报错。有个表:
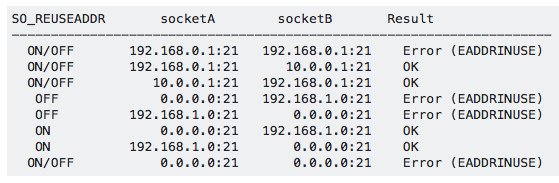
上表中全部默认使用 BSD 系统,并且是 socketA 先绑定,之后再绑定 socketB。ON/OFF表示 SO_REUSEADDR 是否开启不会影响结果。
另一个作用是当连接主动断开后进入 TIME WAIT 状态,不开启 SO_REUSEADDR 的话,TIME WAIT 状态下连接的 IP 和 Port 也是被占用的,同一个 IP 和 Port 不能再次被 bind。但是开启 SO_REUSEADDR ,连接进入 TIME WAIT 后它使用的 IP 和 Port 能再次被应用 bind。bind 时会忽略同一个 IP 和 Port 的连接是否在 TIME WAIT 状态。
需要说明的是上面 SO_REUSEADDR 的行为是 BSD 系统上的,在 Linux 上会有所不同。在 Linux 上上图第六行的绑定是不行的,即先绑定 any address 再绑定 specific address 并且端口相同会被拒绝,反过来也一样,比如先绑定 192.168.1.0:21 再绑定 0.0.0.0:21 是被拒绝的。也就是说在 Linux 上上述 SO_REUSEADDR 第一个作用是没有用的,因为不即使不设置 SO_REUSEADDR 绑定两个不同的 IP 也是允许的。SO_REUSEADDR 在 BSD 上的第二个作用和在 Linux 上相同。除此之外,Linux 上的 SO_REUSEADDR 还有第三个作用,设置后允许同一个 specific addr 和 port 被多个 socket 绑定,行为和下面要说的 SO_REUSEPORT 类似。主要是因为 Linux 3.9 之前没有 SO_REUSEPORT,但又有 SO_REUSEPORT 的使用场景,于是 SO_REUSEADDR 发展出了 SO_REUSEPORT 的能力来替代 SO_REUSEPORT,但 Linux 3.9 之后有了专门的参数 SO_REUSEPORT,SO_REUSEADDR 则保持原状。
SO_REUSEPORT
BSD 系统上设置后允许同一个 specific address, port 被多个 Socket 绑定,只要这些 Socket 绑定地址的时候都设置了 SO_REUSEPORT。听上去这个 SO_REUSEPORT 干的更像是 reuse addr 的活。如果占用 source addr 和 port 的连接处在 TIME WAIT 状态,并且没有设置 SO_REUSEPORT 那该地址和端口不能被另一个 socket 绑定。事实上 SO_REUSEPORT 和 TIME WAIT 没有什么关系,设置后能不能绑定某个端口和地址完全是看这个端口和地址现在有没有被别的连接使用,如果有则要看这个连接是否开启了 SO_REUSEPORT,跟这个连接被占用时处在 TCP 的什么状态完全无关。
在 Linux 上相对 BSD 还要求地址和端口重用必须是同一个 user 之间,如果地址和端口被某个 Socket 占用,并且这个 Socket 是另一个 user 的,那即使该 Socket 绑定时开启了 SO_REUSEPORT 也不能再次被绑定。另外 Linux 还会做一些 load balancing 的工作,对 UDP 来说一个连接的数据包会被均匀分发到所有绑定同一个 addr 和 port 的 socket 上,对于 TCP 来说是 accept 会被均匀的分发到绑定在同一个 addr 和 port 的连接上。
tcp_fin_timeout
很多地方写的说 net.ipv4.tcp_fin_timeout 将这个配置减小一些能缩短 TIME WAIT 时间,但是我们从介绍 tcp_tw_recycle 那节看到,如果没设置 tcp_tw_recycle 的话 TIME WAIT 时间是个固定值 TCP_TIMEWAIT_LEN,这个值是个 macro :
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
* state, about 60 seconds */
也就是说它的长度并不是个可配置项。
net.ipv4.tcp_fin_timeout 的定义在 struct tcp_prot 中 其默认值定义为:
#define TCP_FIN_TIMEOUT TCP_TIMEWAIT_LEN
/* BSD style FIN_WAIT2 deadlock breaker.
* It used to be 3min, new value is 60sec,
* to combine FIN-WAIT-2 timeout with
* TIME-WAIT timer.
*/
也就是说这个配置实际是去控制 FIN-WAIT-2 时间的,只是默认值恰好跟 TIME_WAIT 一致。就不贴使用这个配置的地方了,总之该配置是控制 FIN-WAIT-2 的,也就是说主动断开连接一方发出 FIN 也收到 ACK 后等待对方发 FIN 的时间,该配置并不会影响到 TIME WAIT 长度。