
安装
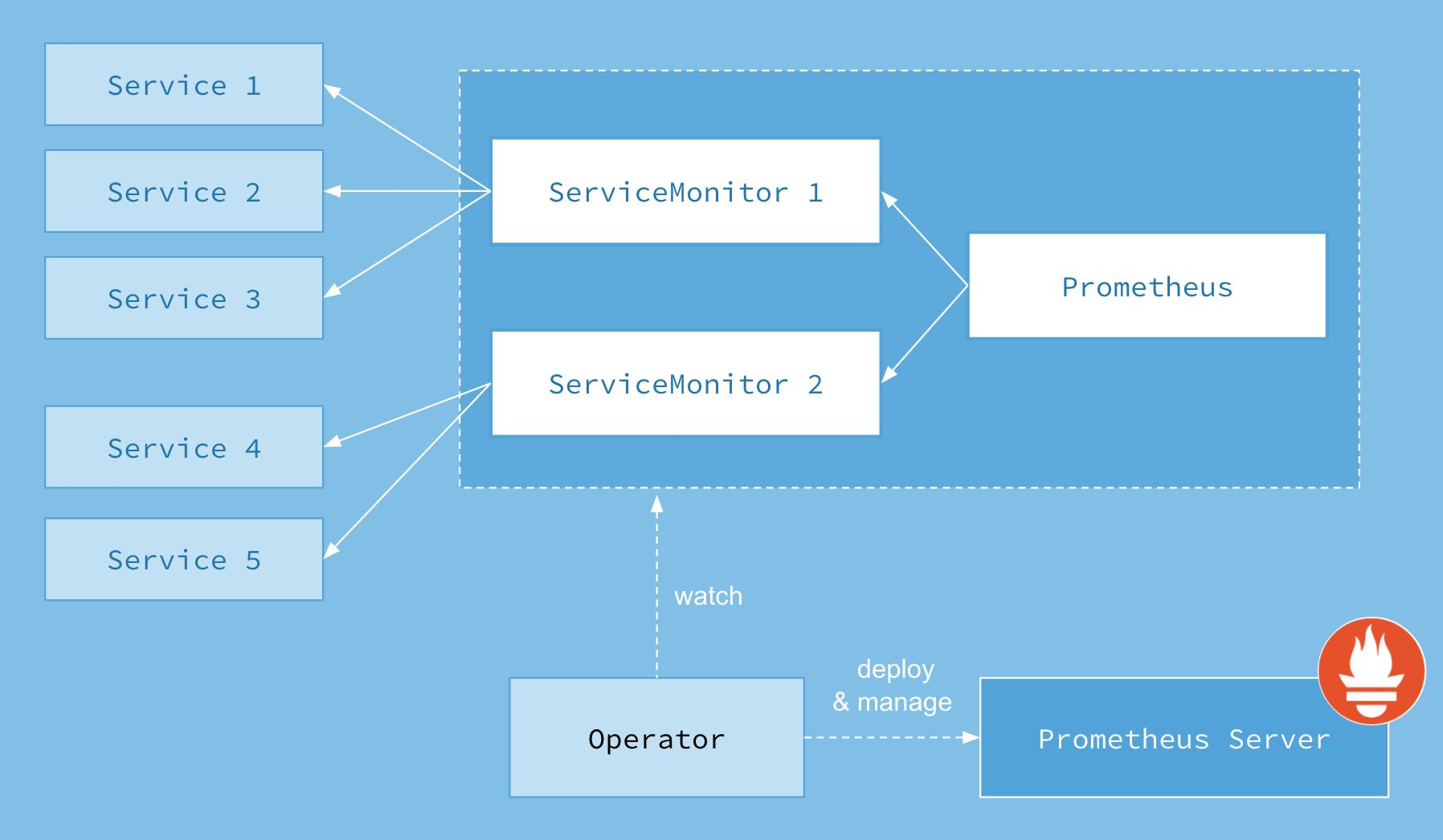
架构
兼容性
| kube-prometheus stack | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20 | Kubernetes 1.21 |
|---|---|---|---|---|
release-0.5 | ✔ | ✗ | ✗ | ✗ |
release-0.6 | ✗ | ✔ | ✗ | ✗ |
release-0.7 | ✗ | ✔ | ✔ | ✗ |
release-0.8 | ✗ | ✗ | ✔ | ✔ |
HEAD | ✗ | ✗ | ✔ | ✔ |
配置存储
可修改的配置见
manifests/setup/prometheus-operator-0prometheusCustomResourceDefinition.yaml
或
https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/api.md#prometheusspec
或
https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/custom-configuration.md
vim prometheus-prometheus.yaml
cat prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
prometheus: k8s
name: k8s
namespace: monitoring
spec:
retention: 30d # 配置日志存储时间
retentionSize: 4GB # 配置日志存储大小
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
externalLabels: {}
image: quay.io/prometheus/prometheus:v2.26.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 1
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.26.0
storage:
volumeClaimTemplate:
spec:
storageClassName: csi-rbd-sc
resources:
requests:
storage: 5Gi
安装
kubectl create -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
删除
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
暴露 Prometheus 和 Grafana 端口
将下面 service 的 ClusterIP 改为 NodePort
kubectl edit svc prometheus-k8s -n monitoring
kubectl edit svc grafana -n monitoring
自定义 Kube-Prometheus 监控项
除了 Kubernetes 集群中的一些资源对象、节点以及组件需要监控,有的时候我们可能还需要根据实际的业务需求去添加自定义的监控项,添加一个自定义监控的步骤也是非常简单的。
- 第一步:建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项;
- 第二步:为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象;
- 第三步:确保 Service 对象可以正确获取到 metrics 数据。
接下来我们就来看看如何添加 Etcd 集群的监控。无论是 Kubernetes 集群外的还是使用 Kubeadm 安装在集群内部的 Etcd 集群,我们这里都将其视作集群外的独立集群,因为对于二者的使用方法没什么特殊之处。
ServiceMonitor
prometheus-serviceMonitorEtcd.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
endpoints:
- port: port
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/kubernetes/ssl/ca.pem #证书路径 (Pod里的路径)
certFile: /etc/kubernetes/ssl/etcd.pem
keyFile: /etc/kubernetes/ssl/etcd-key.pem
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- kube-system
上面这个文件我们匹配 Kube-system 这个命名空间下面具有 k8s-app=etcd 这个label标签的Service,job label用于检索job任务名称的标签。由于证书 serverName 和 etcd 中签发的证书可能不匹配,所以添加了 insecureSkipVerify=true 将不再对服务端的证书进行校验。接下来我们直接创建这个ServiceMonitor:
# 创建资源文件
kubectl apply -f prometheus-serviceMonitorEtcd.yaml
# 查看servicemonitors资源
kubectl get servicemonitors -n monitoring |grep etcd
Service 和 Endpoints
我们需要定义一个 Service 对象和一个 Endpoints,对应资源文件如下。
prometheus-EtcdService.yaml:
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: port
port: 2379
protocol: TCP
prometheus-EtcdServiceEnpoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 172.16.230.51 #etcd节点名称
#nodeName: etcd1 #kubelet名称 (kubectl get node)显示的名称
- ip: 172.16.230.52
#nodeName: etcd2
- ip: 172.16.230.53
#nodeName: etcd3
ports:
- name: port
port: 2379
protocol: TCP
然后我们直接创建上面的 Service 对象和 Endpoints 对象:
kubectl apply -f prometheus-EtcdService.yaml
kubectl apply -f prometheus-EtcdServiceEnpoints.yaml
查看ETCD状态
kubectl describe svc -n kube-system etcd-k8s
创建完成后,稍等一会我们可以去Prometheus 里面查看targets,便会出现etcd监控信息:
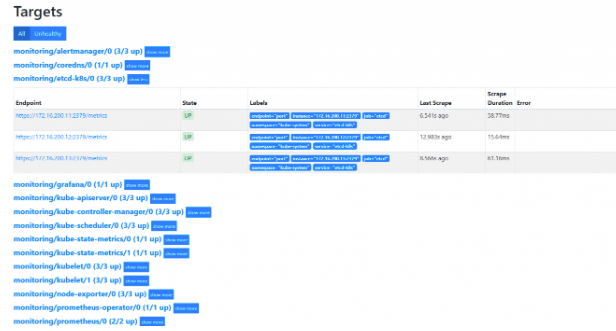
如果提示ip:2379 connection refused,首先检查本地Telnet 是否正常,在检查etcd配置文件是否是监听0.0.0.0:2379。
数据采集完成后,接下来可以在grafana中导入dashboard。这里我们可以导入 :https://grafana.com/grafana/dashboards/3070;还可以导入中文版ETCD集群插件:https://grafana.com/grafana/dashboards/9733;
Grafana数据持久化
前面我们介绍了关于prometheus的数据持久化、但是没有介绍如何针对Grafana做数据持久化;如果Grafana不做数据持久化、那么服务重启以后,Grafana里面配置的Dashboard、账号密码等信息将会丢失;所以Grafana做数据持久化也是很有必要的。
原始的数据是以 emptyDir 形式存放在pod里面,生命周期与pod相同;出现问题时,容器重启,在Grafana里面设置的数据就全部消失了。
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-storage
readOnly: false
...
volumes:
- emptyDir: {}
name: grafana-storage
从上图我们可以看出Grafana将dashboard、插件这些数据保存在/var/lib/grafana这个目录下面。做持久化的话,就需要对这个目录进行volume挂载声明。
我们把emptyDir修改为pvc方式:
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana
如果要使用一个 pvc 对象来持久化数据,我们就需要添加一个可用的 pv 供 pvc 绑定使用,grafana-volume.yaml内容如下:
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
server: 172.16.200.10
path: /mnt/lv/k8s
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
然后我们直接创建上面的PV和PVC、更新 grafana-deployment.yaml 文件即可:
kubectl apply -f grafana-volume.yaml
kubectl apply -f grafana-deployment.yaml
创建完成以后我们查看Pod状态,我们发现Pod状态一直是 CrashLoopBackOff 没有正常启动,我们再看一下这个 Pod 的日志,错误信息如下:
mkdir: cannot create directory '/var/lib/grafana/plugins': Permission denied
这个错误是 Grafana 5.1版本以后才会出现的。错误的原因很明显,就是 /var/lib/grafana 目录的权限不够。在 `` 中有这样一个属性:
securityContext:
runAsNonRoot: true
runAsUser: 65534
我们查看一下65534是哪个用户:
cat /etc/passwd | grep 65534
所以,我们只需要把 /mnt/lv/k8s 目录的用户改为 nfsnobody 就可以了。当然把属性改为 777 也没问题:
chown nfsnobody /mnt/lv/k8s
把刚才出错的那个 Pod 删除,新的 Grafana Pod 就成功启动了。然后就可以添加 Dashboard 了,现在Pod 重建也不会丢失数据了。